






 本文介绍了Python的Surprise库,包括其内置数据集、多种推荐算法如SVD、KNN,并展示了如何加载自定义数据、使用GridSearchCV调优算法参数、获取用户推荐以及近邻信息。此外,还讲解了如何为每个用户获取前n个推荐及如何获取用户或项目的k个最近邻。
本文介绍了Python的Surprise库,包括其内置数据集、多种推荐算法如SVD、KNN,并展示了如何加载自定义数据、使用GridSearchCV调优算法参数、获取用户推荐以及近邻信息。此外,还讲解了如何为每个用户获取前n个推荐及如何获取用户或项目的k个最近邻。
简单易用,同时支持多种推荐算法:
基础算法/baseline algorithms
基于近邻方法(协同过滤)/neighborhood methods
矩阵分解方法/matrix factorization-based (SVD, PMF, SVD++, NMF)
官方指南的使用方法:
https://surprise.readthedocs.io/en/stable/prediction_algorithms.html
一、数据集
·----------------------- 自定义数据(原文为英文,此为中文直译)
Surprise有一组内置数据集,但您当然可以使用自定义数据集。可以从文件(例如csv文件)或panda dataframe加载评级数据集。无论哪种方法,您都需要定义一个Reader对象,以便能够解析文件或数据aframe。
要从文件(例如csv文件)加载数据集,需要load_from_file()方法:
源代码https://surprise.readthedocs.io/en/stable/getting_started.html
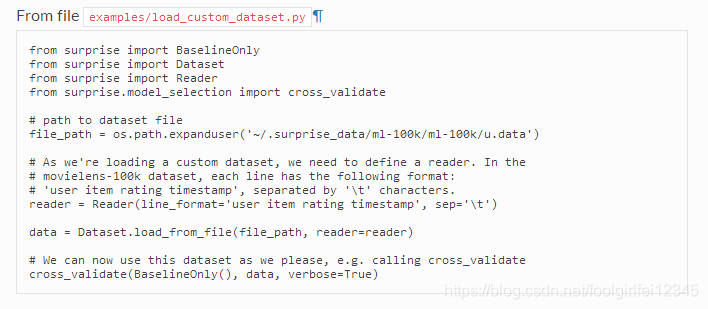
正如您在前一节中已经知道的,movielns -100k dataset是内置的,因此加载数据集的更快方法是执行data = data .load_builtin(‘ml-100k’)。我们当然会忽略这个。
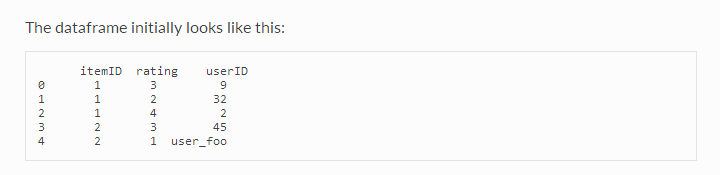
要从panda dataframe加载数据集,需要load_from_df()方法。您还需要一个Reader对象,但是必须只指定rating_scale参数。dataframe必须有三列,分别对应于用户(原始)id、条目(原始)id和按此顺序排列的评级。因此,每一行对应于给定的评级。这并不受限制,因为您可以轻松地重新排列数据aframe的列。
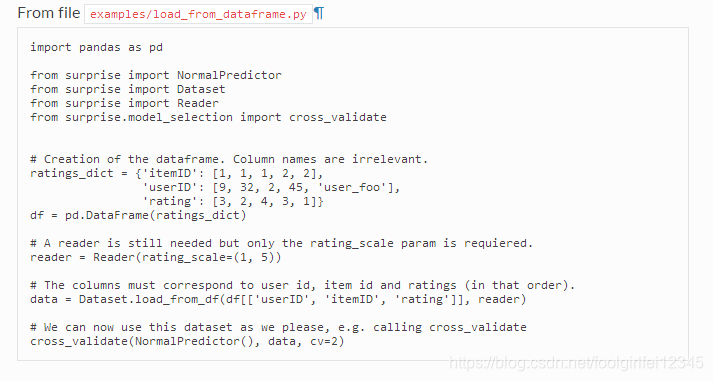
· ------------------使用GridSearchCV调优算法参数
cross_validate()函数报告给定一组参数的交叉验证过程的精度度量。如果您想知道哪个参数组合产生最好的结果,GridSearchCV类可以提供帮助。给定一个参数dict,该类将竭尽全力地尝试所有参数组合,并为任何精度度量报告最佳参数(在不同的分割上取平均值)。它深受scikit-learn的GridSearchCV的启发。下面是一个例子,我们对SVD算法的参数n_epochs、lr_all和reg_all尝试不同的值。
源代码:https://surprise.readthedocs.io/en/stable/getting_started.html
字典参数如bsl_options和sim_options需要特殊的处理。参见下面的使用示例
·------------------- 可以用命令执行
具体用:surprise -h查看使用方法
二、 预测算法
Surprise提供了一组内置算法。所有的算法都是从AlgoBase基类派生而来的,其中实现了一些关键的方法(如预测、拟合和测试)。可用预测算法的列表和详细信息可以在prediction_algorithms包文档中找到。
每个算法都是全局惊喜命名空间的一部分,因此您只需要从惊喜包中导入它们的名称:

· ------------------------------基线估计配置(Baselines estimates configuration)
详情查看:
https://surprise.readthedocs.io/en/stable/prediction_algorithms.html#baselines-estimates-configuration
· ----------------------------相似性度量的配置
详情查看:
https://surprise.readthedocs.io/en/stable/prediction_algorithms.html#baselines-estimates-configuration
·--------------------- 自定义的预测算法
创建自己的预测算法非常简单:算法只是一个从AlgoBase派生的类,它有一个估计方法。这是predict()方法调用的方法。它接受一个内部用户id,一个内部项目id(请参阅本文),并从文件中返回估计的评级ruirui:
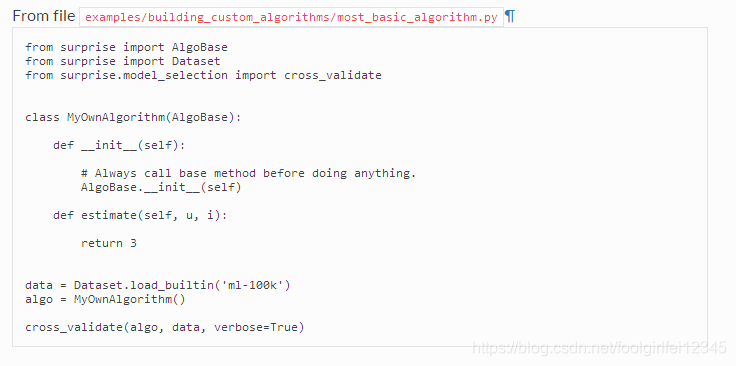
源代码:https://surprise.readthedocs.io/en/stable/building_custom_algo.html
这个算法是我们能想到的最愚蠢的算法:它只预测3的评分,而不考虑用户和项目。
·--------------------------------- 如何为每个用户获得前n个推荐,
这里是一个例子,我们检索检索MovieLens-100k数据集中每个用户具有最高评级预测的前10个项目。我们首先在整个数据集上训练一个SVD算法,然后预测所有不在训练集中的对(用户,项目)的评级。然后为每个用户检索前10名的预测。
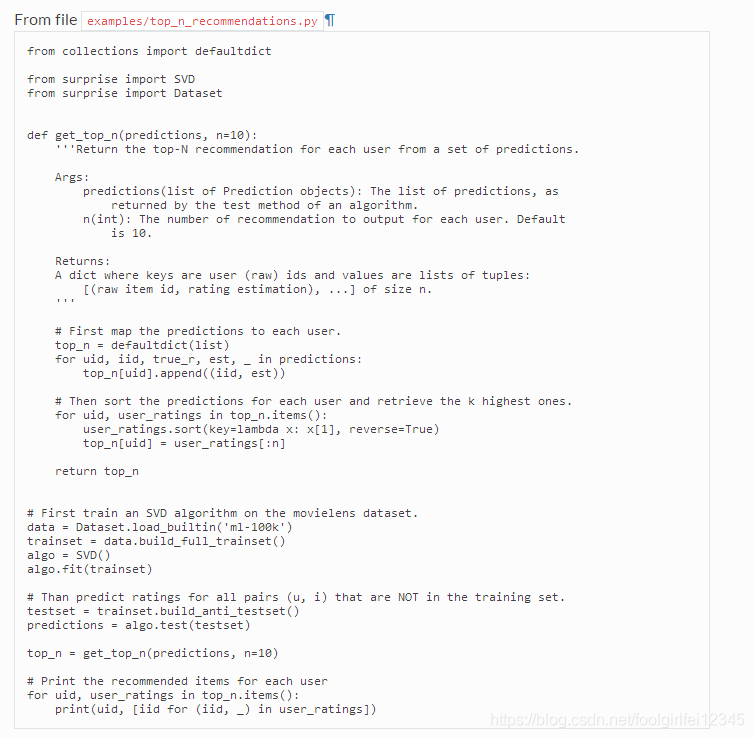
源代码:https://surprise.readthedocs.io/en/stable/FAQ.html
· -------------------------如何获取用户(或项)的k个最近邻,
可以使用算法对象的get_neighbors()方法。这只适用于使用相似性度量的算法,例如k-NN算法。下面是一个例子,我们从MovieLens-100k数据集中检索电影《玩具总动员》的10个最近的邻居。输出是
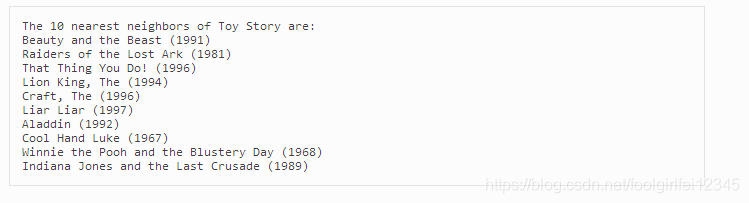
由于电影名称和它们的原始/内部id之间的转换有很多样板文件(请参阅本文),但这一切都归结于get_neighbors()的使用
源代码:https://surprise.readthedocs.io/en/stable/FAQ.html
---------------------使用自己的数据集
指南:https://surprise.readthedocs.io/en/stable/getting_started.html#load-custom
-------------------------如何自己写推荐程序
生和ids内部用户和项目有一个原始id和一个内部id。一些方法将使用/返回一个原始id(例如预测()方法),而其他一些将使用/返回一个内部id。原始id作为评级文件中定义id或熊猫dataframe。它们可以是字符串或数字。请注意,如果评级是从一个文件中读取的(这是标准场景),那么它们将被表示为字符串。知道您是否正在使用predict()或其他接受原始id作为参数的方法非常重要。在创建trainset时,每个原始id都映射到一个称为inner id的惟一整数,这更适合于操作Surprise。可以使用训练集的to_inner_uid()、to_inner_iid()、to_raw_uid()和to_raw_iid()方法在原始id和内部id之间进行转换。
-----------------------------如何优化算法参数
可以使用GridSearchCV类优化算法的参数,如下所述。在调优之后,您可能希望对算法性能进行无偏估计。您可以使用Trainset对象的build_testset()方法来构建一个可以与test()方法一起使用的测试集
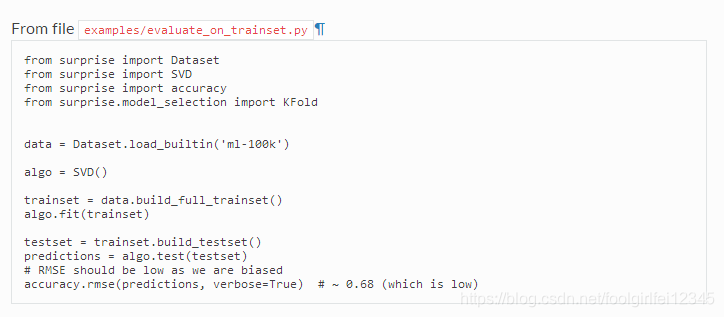
源代码:https://surprise.readthedocs.io/en/stable/FAQ.html
-------------------重复实验的方法
一些算法随机初始化它们的参数(有时使用numpy),交叉验证折叠也是随机生成的。如果需要多次复制实验,只需在程序开始时设置RNG的种子

-----------------------------数据集存储在哪里以及如何更改它?
默认情况下,通过Surprise下载的数据集将保存在 ’~/.surprise_data’ 中目录。这也是转储文件将要存储的地方。您可以通过设置’*SURPRISE_DATA_FOLDER’’*环境变量来更改默认目录。
3、prediction_algorithms package包里提供的推荐算法由
random_pred.NormalPredictor 基于训练集分布预测随机等级的算法,假设训练集为正态分布。
baseline_only.BaselineOnly 算法预测给定用户和item.knns的基线估计。KNNBasic是一种基本的协同滤波算法。.
knns.KNNWithMeans 一种基本的协同滤波算法,考虑到每个用户的平均等级。
knns.KNNWithZScore 一种基本的协同滤波算法,考虑到每个用户的z值归一化。
knns.KNNBaseline 一个基本的协同过滤算法,考虑了基线评级。
matrix_factorization.SVD 著名的SVD算法,在Netflix奖期间由Simon Funk推广。
matrix_factorization.SVDpp SVD++算法,一个扩展的SVD考虑隐式评级。
matrix_factorization.NMF 一种基于非负矩阵因子分解的协同过滤算法。
slope_one.SlopeOne 一个简单而准确的协同过滤算法。
co_clustering.CoClustering 一种基于协聚类的协同过滤算法。
在输入公式之前,您可能需要检查表法标准
You may want to check the notation standards before diving into the formulas.
(翻译的不太对,自己看吧)

















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









