







1st Competition of Datawhale: the car price prediction 2nd part
参赛后,上一篇文章实在是太长了。分开写第二部分。
Task4 建模调参
4.1 学习目标
了解常用的机器学习模型,并掌握机器学习模型的建模与调参流程
完成相应学习打卡任务
我是初学者,所以我的任务就是了解机器学习的建模和调参。
4.2 内容介绍
- 线性回归模型:
线性回归对于特征的要求;
处理长尾分布;
理解线性回归模型; - 模型性能验证:
评价函数与目标函数;
交叉验证方法;
留一验证方法;
针对时间序列问题的验证;
绘制学习率曲线;
绘制验证曲线; - 嵌入式特征选择:
Lasso回归;
Ridge回归;
决策树; - 模型对比:
常用线性模型;
常用非线性模型; - 模型调参:
贪心调参方法;
网格调参方法;
贝叶斯调参方法;
4.3 相关原理介绍与推荐(我本次打卡的主要学习部分)
由于相关算法原理篇幅较长,本文推荐了一些博客与教材供初学者们进行学习。
4.3.1 线性回归模型
线性回归
线性回归是一种被广泛应用的回归技术,也是机器学习里面最简单的一个模型,它有很多种推广形式,本质上它是一系列特征的线性组合,在二维空间中,你可以把它视作一条直线,在三维空间中可以视作是一个平面。
线性回归最普通的形式是
[公式]
其中x向量代表一条样本{x1,x2,x3…xn},其中x1,x2,x3代表样本的各个特征,w是一条向量代表了每个特征所占的权重,b是一个标量代表特征都为0时的预测值,可以视为模型的basis或者bias。看起来很简单的。
这里的w乘以x在线性代数中其实代表的是两个向量的内积,假设w和x均为列向量,即代表了w和x向量的内积w’x。同样的这里的x也可以是一个矩阵X,w与X也可以写成w’X,但是b也要相应的写为向量的形式。
#w是列向量 矩阵由一个个列向量构成 y = dot(w_t,X)+b
import numpy as np
w_t,b = np.array([1,2,3,4,5]),1
X = np.array([[1,1,1,1,1],[1,2,5,3,4],[5,5,5,5,5]]).T
y_hat = np.dot(w,X) + b
损失函数
线性回归的模型就是这么简单,困难的地方在于我们如何获得w和b这两个向量,在李航老师的统计学习方法中把一个学习过程分为了三部分,模型、策略、算法,为了获得w和b我们需要制定一定的策略,而这个策略在机器学习的领域中,往往描述为真实值与回归值的偏差。
[公式]
我们希望的是能够减少在测试集上的预测值f(x)与真实值y的差别,从而获得一个最佳的权重参数,因此这里采用最小二乘估计。
这里复习一下之前《数学估计方法》中留下的问题,最小方差无偏估计和最小二乘估计是不一样的,那么他们的区别在哪?最直观的地方是这里表示的是估计点与真实点的差别,而最小方差无偏估计表示的是估计点与真实数据期望的差别。
y = np.array([1.5, 3, 6])
loss = (y_hat - y)**2
优化方法
知道了策略,下一步就是要动手去做,那么怎样调整w才能使估计值与真实值的差别尽可能小呢?这里提供并实现两种经常使用的凸优化方法,最小二乘优化与梯度下降优化,详细可以参考《数学优化方法》。
最小二乘
最小二乘优化的思路是线性代数中的矩阵求导,学过导数的人都知道,如果我们想要让loss取到最小,只需要对这个式子进行求导,导数为0的地方就是极值点,也就是使loss最大或者最小的点(实际上是最小的点,因为loss一般是一个往下突的函数,w无限大的时候随便带进去一个值估计出来的值loss都很大,其实求2阶导数也可以看出来)。
任务变成了求这个

的数学问题。
这里可以参考《矩阵求导公式》里的求导方法,总之求出来是

然后求出来

这里如果XX^T可逆的话,可以变成
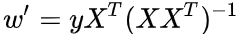
这里矩阵求导公式我也记不住,但是凭感觉应该是对的吧。
w_t = np.dot(np.dot(y,X.T), np.linalg.inv(np.dot(X,X.T)))
梯度下降
梯度下降的策略与最小二乘优化不同,它采用的不是用数学方法一步求出解析解,而是一步一步的往让loss变到最小值的方向走,直到走到那个点。
可是那个方向怎么确定呢?这里我们引入梯度的概念。
More precisely, the gradient points in the direction of the greatest rate of increase of the function, and its magnitude is the slope of the graph in that direction.
——Wikipedia
梯度方向就是增长最快的方向,如果我们想要函数值减小,只需要沿着负梯度方向走就行了。具体求这个grad的方法就是,对loss求偏导就可以啦,具体还是看《数学优化方法》。

然后再重复求偏导、走、求偏导、走就可以得到最终的权重向量w。当然这里有一点需要解释,对于一个连续可导的函数而言,越靠近我们想要的那个极值点的地方,它的梯度就越小,想象一下你蚁人在浴缸里走的时候,发现在浴缸边缘陡峭,浴缸中间平缓。因此我们在实现时只需要在走的很慢的时候停下就好啦~
while True:
grad = np.dot((np.dot(w_t,X)-y), X.t)
w_t -= 0.1 * grad
if np.linalg.norm(w_t, ord = 2) < 1e-3:
break
4.3.2 决策树模型
准备从头到尾把机器学习模型撸一遍吧,在我写好矩阵运算库之前,应该这些代码会暂时用Python写,正好再给我一些缓冲时间学学C++。
决策树,感觉没什么好讲的,按照周志华老师西瓜书上的算法流程一步一步撸下来就好了。感觉需要考虑的比较多的地方在于如何选择最优的划分特征上,里面牵扯到了一些信息论的知识,也是最近才搞懂了一些它的意义,可能后续会发在另一个专栏里。

树的建立过程明显是一个递归的过程,虽然感觉上很清晰,但是第一次用Python写树的结构,还是把我饶了进去。
如果是用C++写的话,这个算法流程应该就是一个深度优先搜索,然后在搜索的过程中通过指针建立一颗树,大概应该是这么写:
for (i : features){
p = new node(i);
father_node->p;
}
但是Python里面怎么实现树,我还是真的没有什么经验,看了看网上的实现方式,竟然是用字典嵌套做的:
tree = {}
for i in features:
node = {}
tree[i] = node
所以如果写递归建树的话,这个逻辑大概是这样的。递归生成的子树,最后要返回给父节点赋值:
def build_tree():
for i in features:
node = {}
tree[i] = build_tree()
return tree
其实也不难,只是一般不会在Python上写底层算法,所以第一次写起来不习惯而已了。
先写一些要用到的小工具:
import numpy as np
def find_most(x: np.ndarray):
return sorted([(np.sum(x == i), i) for i in np.unique(x)])[-1][-1]
def entropy(x: np.ndarray)->float:
result = 0
size = x.size
for i in np.unique(x):
p = x[x == i].size / size
result += p * np.log2(p)
return -1 * result
def gini(x: np.ndarray)->float:
result = 1
size = x.size
for i in np.unique(x):
p = x[x == i].size / size
result -= p
return result
然后写决策树:
import numpy as np
from tools import *
class decesion_tree:
def __init__(self, approach = 0):
self._approach = approach
self._tree = {}
def train(self, x: np.ndarray, y: np.ndarray):
x = np.array(x)
y = np.array(y)
features = set(range(0, x.shape[-1]))
self._tree = self._build_tree(x, y, features=features)
def predict(self, x: np.ndarray)->list:
x = np.array(x)
result = []
for sample in x:
node = self._tree
feature = list(node)[0]
while True:
feature_ins = sample[feature]
if type(node[feature][feature_ins]) == dict:
node = node[feature][feature_ins]
feature = list(node)[0]
else:
result.append(node[feature][feature_ins])
break
return result
def print(self):
print(self._tree)
def _build_tree(self, x: np.ndarray, y: np.ndarray, features: set)->dict:
if np.unique(y).shape == y.shape:
return y[0]
if not features or np.unique(x).shape == x.shape:
return find_most(y)
best_feature = self._find_best_feature(x, y, features)
node = {best_feature: {}}
dividen = x[:, best_feature]
for i in np.unique(dividen):
loc = np.where(dividen == i)
if not loc:
node[best_feature][i] = find_most(y[loc])
else:
node[best_feature][i] = self._build_tree(x[loc], y[loc], features - {best_feature})
return node
def _find_best_feature(self, x: np.ndarray, y: np.ndarray, features: set)->object:
best_feature = None
if self._approach == 0:
max_gain = -1 * np.inf
for i in features:
gain = self._information_gain(y, x[:, i])
if gain > max_gain:
max_gain = gain
best_feature = i
if self._approach == 1:
max_gain = -1 * np.inf
for i in features:
gain = self._gain_ratio(y, x[:, i])
if gain > max_gain:
max_gain = gain
best_feature = i
if self._approach == 2:
min_gini = np.inf
for i in features:
gain = self._gain_ratio(y, x[:, i])
if gain < min_gini:
min_gini = gain
best_feature = i
return best_feature
@staticmethod
def _information_gain(d: np.ndarray, a: np.ndarray)->float:
ent_d = entropy(d)
size = d.size
for i in np.unique(a):
loc = np.where(a == i)
ent_d -= d[loc].size / size * entropy(d[loc])
return ent_d
@staticmethod
def _gain_ratio(d: np.ndarray, a: np.ndarray)->float:
IV_a = 0
size = d.size
for i in np.unique(a):
loc = np.where(a == i)
IV_a -= d[loc].size / size * np.log2(d[loc].size / size)
return decesion_tree._information_gain(d, a) / IV_a
@staticmethod
def _gini_index(d: np.ndarray, a: np.ndarray)->float:
result = 0
size = d.size
for i in np.unique(a):
loc = np.where(a == i)
result += d[loc].size / size * gini(d[loc])
return result
4.3.3 GBDT模型
https://zhuanlan.zhihu.com/p/45145899
4.3.4 XGBoost模型
xgboost浅析
xgboost详解,有点太详细,太数学了,留着看吧
https://www.bilibili.com/video/BV1mZ4y1j7UJ?from=search&seid=45060046521325365
4.3.5 LightGBM模型
https://zhuanlan.zhihu.com/p/89360721
4.3.6 推荐教材:
《机器学习》 https://book.douban.com/subject/26708119/
《统计学习方法》 https://book.douban.com/subject/10590856/
《Python大战机器学习》 https://book.douban.com/subject/26987890/
《面向机器学习的特征工程》 https://book.douban.com/subject/26826639/
《数据科学家访谈录》 https://book.douban.com/subject/30129410/
4.4 代码示例(超纲了@_@!)
4.4.3 - 1 线性模型 & 嵌入式特征选择
本章节默认,学习者已经了解关于过拟合、模型复杂度、正则化等概念。否则请寻找相关资料或参考如下连接:
用简单易懂的语言描述「过拟合 overfitting」? https://www.zhihu.com/question/32246256/answer/55320482
模型复杂度与模型的泛化能力 http://yangyingming.com/article/434/
正则化的直观理解 https://blog.csdn.net/jinping_shi/article/details/52433975
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别。而嵌入式特征选择在学习器训练过程中自动地进行特征选择。嵌入式选择最常用的是L1正则化与L2正则化。在对线性回归模型加入两种正则化方法后,他们分别变成了岭回归与Lasso回归。
4.4.4 在此我们介绍了三种常用的调参方法如下:
贪心算法 https://www.jianshu.com/p/ab89df9759c8
网格调参 https://blog.csdn.net/weixin_43172660/article/details/83032029
贝叶斯调参 https://blog.csdn.net/linxid/article/details/81189154















 114
114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









