







一、standalone模式
解压缩flink-1.1.0.1-bin-scala_2.12.tgz,进入conf目录。
1)修改conf/flink-conf.yaml 文件
通用配置:
jobmanager.rpc.address:作业管理远程过程调用地址,同时也是默认的jobmanager节点
job.manager.rpc.address
jobmanager.heap.size: JVM大小
taskmanager.memory.process.size: taskmanager的总内存(包含jvm和堆外内存)
taskmanager.numberOfTaskSlots: 一个taskmanager有多少个槽位,(一个任务经理 同时可以并行处理的task个数,或者说工位个数)
parallelism.default: 集群任务的默认并行度
HA配置:
fault tolerance and checkpoint 配置:
Rest & webfrontend 配置:
rest.port: 8081 apache flink dashboard 页面端口
Advanced配置:
- conf/slaves
仅添加slave节点
3)分发安装包到其他节点
4)启动
./bin/start-cluster.sh
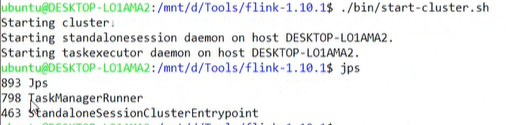
5)提交任务
注:flink program内的每一个语句都可以设置setParallelism(),比如,wordCount代码内的内一个语句后添加.setParallelism(2);
方式一:
- 将jar包提交到web

- 指定入口类、参数、并行度(执行时并行度以更细粒度为准,代码级,作业级、集群级别)等

slot 和 task并行度:如果使用默认的slot为1,但是提交的job中,存在同个阶段的task并行度大于1,作业将不能运行下去,会处于等待状态。需要提高slot,或者降低并行度。

方式二:控制台提交job
./bin/flink run -c com.xxx.StreamWordCount -p 3 …/Flink_wordcount.jar --host localhost -port 7777
运行的作业:./bin/flink list
取消某个作业: ./bin/flink cancel [jobID]
二、Yarn模式
要求hadoop版本2.2以上,且有hdfs。
flink on yarn
将flink-shaded-hadoop-2-uber-2.7.5.jar放到 flink 的conf/下。
1)Session-cluster模式
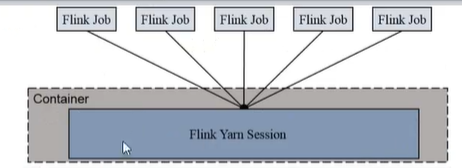
适合规模小、执行时间短作业,fifo。
启动:

提交job,同standalone
yarn job页面上查看application
yarn application kill 取消任务
2)Per-job-cluster模式:
一个job对应一个flink集群,单独占用资源,适合规模大、长时间运行。
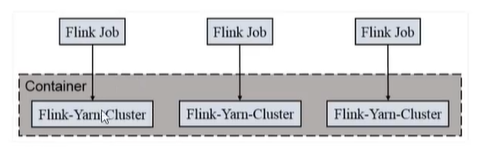
启动方式:
1)启动hadoop集群
2)不起的yarn-session,直接执行job
./flink run -m yarn-cluster -c …StreamWordCount Flink-wordcount-xxx.jar --host --port















 1481
1481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









