







一、集成学习概念:
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)。集成学习将个体学习器采用某种策略结合。个体学习器通常由现有的学习算法从训练数据产生。如决策树、BP神经网络等。
集成中只包含同一种个体学习器叫做同质集成(homogeneous ensemble);集成中的个体学习器由不同学习算法生成,叫做异质集成。
1.分类器之间应该有差异性;
2.每个分类器的精度必须大于0.5;
如果使用的分类器没有差异,那么集成起来的分类结果是没有变化的。分类器的精度p<0.5,随着集成规模的增加,分类精度不断下降;如果精度大于p>0.5,那么最终分类精度可以趋向于1。

二、个体学习器的概念:使用简单的学习算法对数据训练产生的,如决策树算法、神经网络算法等。
三、boosting算法指将弱学习算法组合成强学习算法,它的思想起源于Valiant提出的PAC(Probably Approximately Correct)学习模型。
基本思想:
1.首先赋予每个训练样本相同的初始化权重,在此训练样本分布下训练出一个弱分类器;
2.利用该弱分类器更新每个样本的权重,分类错误的样本认为是分类困难样本,权重增加,反之权重降低,得到一个新的样本分布;
3.在新的样本分布下,在训练一个新的弱分类器,并且更新样本权重,重复以上过程T次,得到T个弱分类器。
通过改变样本分布,使得分类器聚集在那些很难分的样本上,对那些容易错分的数据加强学习,增加错分数据的权重。这样错分的数据再下一轮的迭代就有更大的作用(对错分数据进行惩罚)。
bagging:给定包含m个样本的数据集,我们做有放回抽样(即自助采样法 bootstrap sampling),经过m次随机采样得到m个样本的采样集。这样我们可以采样出T个含m个训练样本的采样集。基于每个采样集训练出一个基学习器,对这些基学习器进行组合。
可以做一个简单的估计,样本在m次采样中始终不被采到的概率是: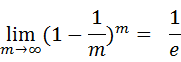 ,近似等于36.8%。这些样本可以作为验证集来对泛化性能进行“包外估计”。为此需要记录每个基分类器所使用的训练样本。
,近似等于36.8%。这些样本可以作为验证集来对泛化性能进行“包外估计”。为此需要记录每个基分类器所使用的训练样本。
四、集合策略
1.平均法
- 简单平均法
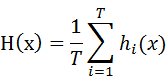
- 加权平均
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1816
1816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









