







配置自动切换模式
(1)配置zookeeper集群
(2)开启自动切换模式
在hdfs-site.xml中配置dfs.ha.automatic-failover.enabled参数
(3)配置zookeeper实例
在core-site.xml中配置ha.zookeeper.quorum
(4)初始化zookeeper
(5)启动journalnode,namenode和datanode
(6)启动zkfc
根据主机名可以判断每一条命令是在那个节点执行,是用哪个用户执行的
例子:
[hadoop@master opt]$
mater主机
hadoop用户
2) 解压
[hadoop@master opt]$ mv zookeeper-3.4.6.tar.gz /opt
[hadoop@master opt]$ tar -zxvf zookeeper-3.4.6.tar.gz
3) 修改配置文件
[hadoop@master conf]$ cd /opt/zookeeper-3.4.6/conf
[hadoop@master conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@master conf]$ vi zoo.cfg
dataDir=/opt/zookeeper/data
server.1=hadoop04:8001:8002
server.2=slave1:8001:8002
server.3=slave2:8001:8002
4)将zookeeper软件copy到规划好的节点
[hadoop@master opt]$ scp -r zookeeper-3.4.6 hadoop04:/opt
[hadoop@master opt]$ scp -r zookeeper-3.4.6 slave1:/opt
[hadoop@master opt]$ scp -r zookeeper-3.4.6 slave2:/opt
5)在hadoop04、slave1、slave2上创建链接
[hadoop@hadoop04 opt]$ ln -s zookeeper-3.4.6 zookeeper
[hadoop@slave1 opt]$ ln -s zookeeper-3.4.6 zookeeper
[hadoop@slave2 opt]$ ln -s zookeeper-3.4.6 zookeeper
6)修改环境变量
On master
[hadoop@master ~]$ vi .bash_profile
[hadoop@master ~]$ vi .bash_profile
. ~/.bashrc
fi# User specific environment and startup programs
PATH=$PATH:$HOME/bin
export PATH
export JAVA_HOME=/usr/java/default
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
#Hadoop1.0
#export HADOOP1_HOME=/home/hadoop/hadoop
#export PATH=$HADOOP1_HOME/bin:$PATH
#export HADOOP_CONF_DIR=${HADOOP1_HOME}/conf
#Hadoop2.0
export HADOOP2_HOME=/opt/hadoop
export HADOOP_CONF_DIR=${HADOOP2_HOME}/etc/hadoop
export HADOOP_MAPRED_HOME=${HADOOP2_HOME}
export YARN_CONF_DIR=${HADOOP2_HOME}/etc/hadoop
export HADOOP_YARN_HOME=${HADOOP2_HOME}
export HADOOP_COMMON_HOME=${HADOOP2_HOME}
export HADOOP_HDFS_HOME=${HADOOP2_HOME}
export HDFS_CONF_DIR=${HADOOP2_HOME}/etc/hadoop
export PATH=$HADOOP2_HOME/bin:$HADOOP2_HOME/sbin:$PATH
#Ant
export ANT_HOME=/home/hadoop/apache-ant-1.8.0
export PATH=$ANT_HOME/bin:$PATH
#zookeeper
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
7)同步环境变量
[hadoop@master ~]$ scp -r .bash_profile hadoop04:~
[hadoop@master ~]$ scp -r .bash_profile slave1:~
[hadoop@master ~]$ scp -r .bash_profile slave2:~
8)在hadoop04、slave1、slave2创建目录
[hadoop@hadoop04 ~]$ mkdir -p /opt/zookeeper/data
[hadoop@master ~]$ slaves.sh mkdir -p /opt/ zookeeper /data 《===相当于在slave1和slave2节点执行了mkdir命令
小技巧:使用slaves.sh 可以简单的在slave节点同意执行命令
9)创建myid文件
[hadoop@hadoop04 ~]$ cd /opt/ zookeeper /data/
[hadoop@hadoop04 data]$ echo 1 > myid
[hadoop@slave1 ~]$ cd /opt/ zookeeper /data/
[hadoop@slave1 data]$ echo 2 > myid
[hadoop@slave2 hadoop]$ cd /opt/ zookeeper /data/
[hadoop@slave2 data]$ echo 3 > myid
10) 启动zookeeper
[hadoop@hadoop04 ~]$ zkServer.sh start
[hadoop@slave1 ~]$ zkServer.sh start
[hadoop@slave2 ~]$ zkServer.sh start
11)修改zoo.cfg,添加一条日志记录 《===只是为了报错有日志生成,可以不加
[hadoop@master conf]$ vi zoo.cfg
dataLogDir=/opt/zookeeper/log
12)停掉所有其他服务
On master
[hadoop@master hadoop]$ hadoop-daemons.sh --hostnames 'slave1 slave2 hadoop04' stop journalnode
[hadoop@master hadoop]$ hadoop-daemons.sh stop datanode
[hadoop@master hadoop]$ hadoop-daemons.sh --hostnames 'hadoop04 master'stop namenode
13)打开自动切换模式
[hadoop@master ~]$ cd /opt/hadoop/etc/hadoop/
[hadoop@master hadoop]$ vi hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name><value>true</value>
</property>
[hadoop@master hadoop]$ vi core-site.xml
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop04:2181,slave1:2181,slave2:2181</value>
</property>
将这两个文件拷贝到hadoop04服务器
[hadoop@master hadoop]$ scp -r hdfs-site.xml hadoop04:/opt/hadoop/etc/hadoop/
[hadoop@master hadoop]$ scp -r core-site.xml hadoop04:/opt/hadoop/etc/hadoop/
14)Zookeeper的初始化
[hadoop@master hadoop]$ hdfs zkfc –formatZK
[hadoop@hadoop04 data]$ zkCli.sh
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[hadoop-ha, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha
[ns1][zk: localhost:2181(CONNECTED) 2] get /hadoop-ha/ns1
cZxid = 0x100000003
ctime = Tue Mar 21 02:40:13 EDT 2017
mZxid = 0x100000003
mtime = Tue Mar 21 02:40:13 EDT 2017
pZxid = 0x100000003
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
[zk: localhost:2181(CONNECTED) 3]
15)启动所有服务
[hadoop@master hadoop]$ hadoop-daemons.sh --hostnames 'slave1 slave2 hadoop04' start journalnode
[hadoop@master hadoop]$ hadoop-daemons.sh --hostnames 'hadoop04 master' start namenode
[hadoop@master hadoop]$ hadoop-daemons.sh start datanode
16)在两个namenode节点启动zkfc
[hadoop@master hadoop]$ hadoop-daemons.sh --hostnames 'hadoop04 master' start zkfc
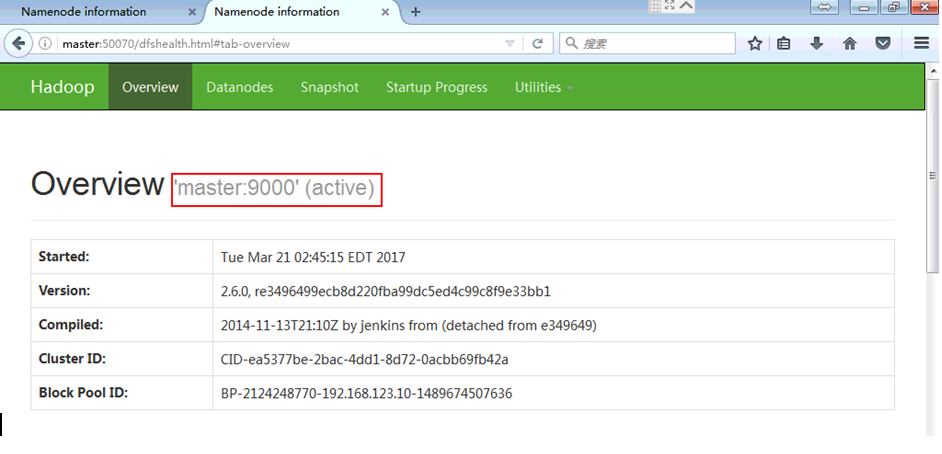
17)
on hadoop04
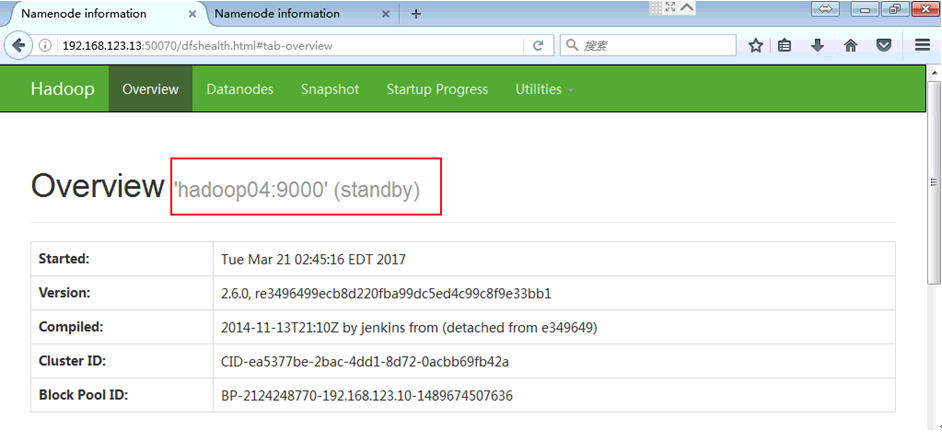
on master
18)模拟测试将当前active状态的namenode节点kill掉
[hadoop@master hadoop]$ jps
3436 Jps
2760 NameNode
2952 DFSZKFailoverController
[hadoop@master hadoop]$ kill -9 2760
[hadoop@master hadoop]$
19)
on hadoop04
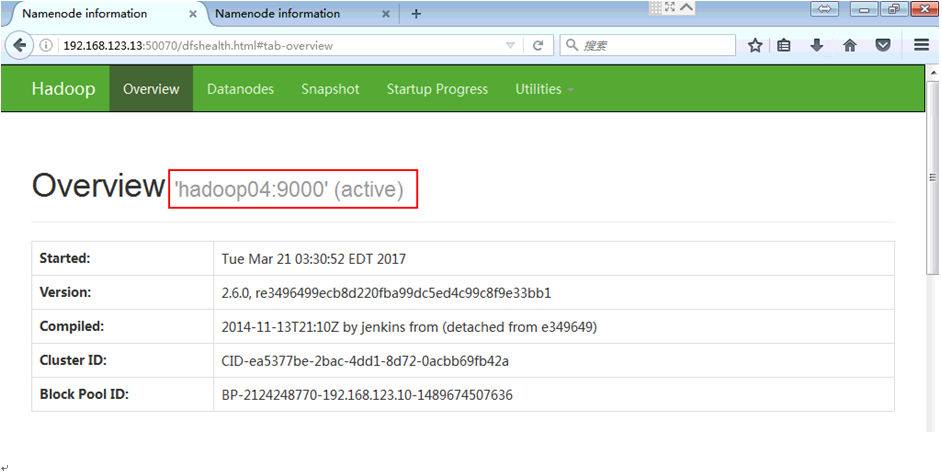
on master

切换成功
20)创建目录
[hadoop@master hadoop]$ hdfs dfs -mkdir hdfs://ns1/test
[hadoop@master ~]$ hdfs dfs -put a.txt hdfs://ns1/test
[hadoop@master ~]$ hdfs dfs -ls hdfs://ns1/test
Found 1 items
-rw-r--r-- 2 hadoop supergroup 6 2017-03-21 03:32 hdfs://ns1/test/a.txt
[hadoop@master ~]$
由于我们在core-site.xml配置了
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
因此,我们可以直接指定目录,不需要加hdfs://ns1这个前缀了
[hadoop@master ~]$ hdfs dfs -ls /test
Found 1 items
-rw-r--r-- 2 hadoop supergroup 6 2017-03-21 03:32 /test/a.txt
基于zk自动切换,环境搭建完成















 3706
3706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









