







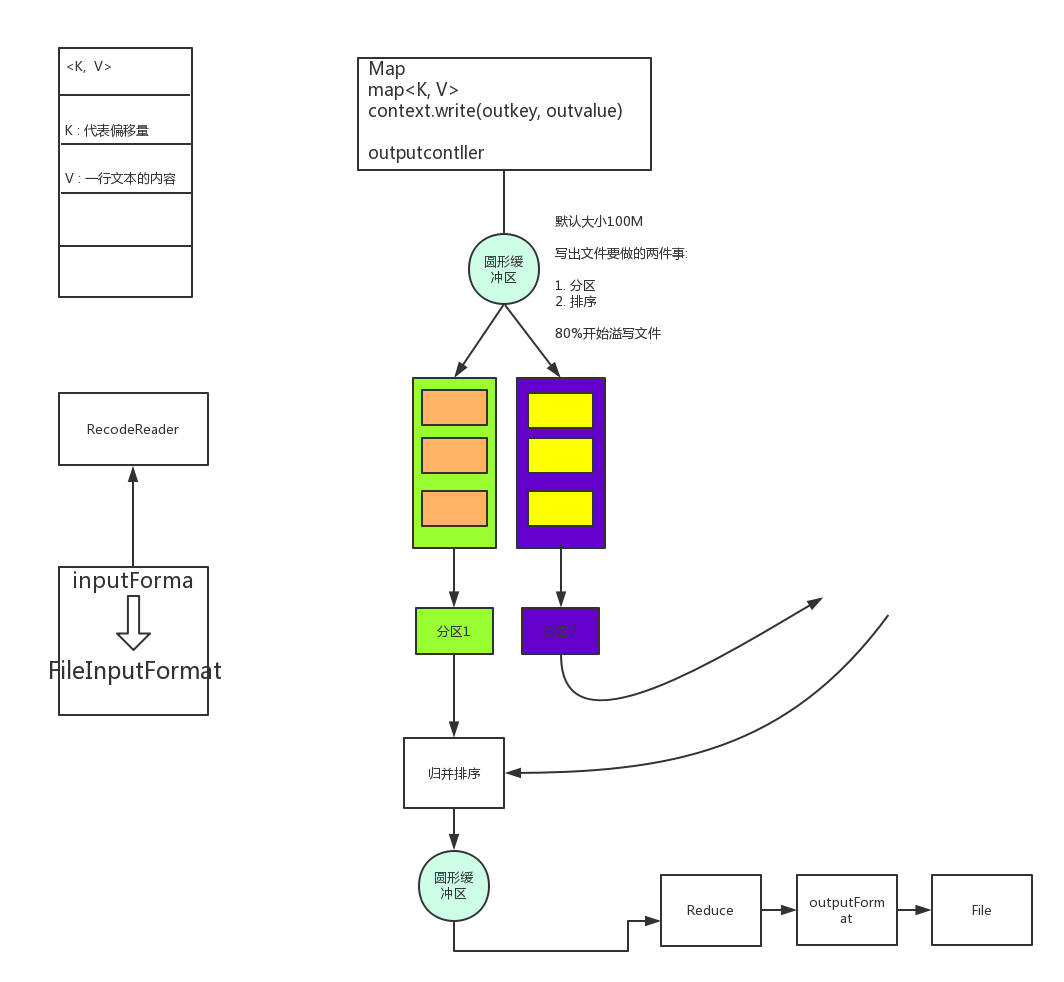
MapReduce工作流程
Combiner
Combiner对于使用, 严格来说, 最适合的场景就是合并数量
Combiner 输出的类型为K,V对. reduce的K,V对类型一致
实例: 实现Combiner
分析: 要想实现 Combiner 则需要继承一个reducer类, 在dirver 类中设置Combiner类
- 继承Reducer类, 实现重载reduce方法
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
- 在主函数Driver中设置Combiner类
job.setCombinerClass(WordCountCombiner.class);
在运行结果中可以看到Combiner的变化
Combine input records=429
Combine output records=100
二次排序

自定义序列化
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Driver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Driver.class);
job.setMapperClass(SecondSortMap.class);
job.setReducerClass(SecondSortReduce.class);
job.setGroupingComparatorClass(SecondSortGroup.class);
job.setMapOutputKeyClass(CustomKey.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
实现map
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SecondSortMap extends Mapper<LongWritable, Text, CustomKey, Text> {
private CustomKey outputkey = new CustomKey();
private Text outputValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(",");
outputkey.setWord1(words[0]);
outputkey.setWord2(words[1]);
outputkey.setWord3(words[2]);
outputValue.set(words[2]);
//System.out.println(outputkey+outputValue.toString());
context.write(outputkey, outputValue);
}
}
实现reduce
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SecondSortReduce extends Reducer<CustomKey, Text, Text, Text> {
Text outputkey = new Text();
Text outputValue = new Text();
@Override
protected void reduce(CustomKey key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String tmp = "";
for (Text value : values) {
tmp += value.toString() + ",";
}
outputkey.set(key.getWord1());
outputValue.set(tmp.substring(0, tmp.length() - 1));
context.write(outputkey, outputValue);
}
}
实现分组
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class SecondSortGroup extends WritableComparator {
@Override
public int compare(WritableComparable a, WritableComparable b) {
// TODO Auto-generated method stub
CustomKey key1 = (CustomKey) a;
CustomKey key2 = (CustomKey) b;
System.out.print(key1.getWord1());
System.out.print(key2.getWord1());
System.out.println(key1.getWord1().compareTo(key2.getWord1()));
return key1.getWord1().compareTo(key2.getWord1());
}
public SecondSortGroup() {
// TODO Auto-generated constructor stub
super(CustomKey.class, true);
}
}
实现主函数Driver
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Driver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Driver.class);
job.setMapperClass(SecondSortMap.class);
job.setReducerClass(SecondSortReduce.class);
job.setGroupingComparatorClass(SecondSortGroup.class);
job.setMapOutputKeyClass(CustomKey.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}














 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









