







文章目录
- 一 ElasticSearch介绍
- 二 ElasticSearch安装运行
- 三 curl操作ElasticSearch
- 四 使用Java操作客户端(入门)
- 4.1 新建 maven项目, 基于maven的pom 导入依赖
- 4.2 Java 操作
- 4.2.1 获取客户端
- 4.2.2 获取结果
- 4.2.3 写入数据
- 4.2.4 使用es 帮助类 来实现插入数据
- 4.2.5 搜索
- 4.2.6 更新数据
- 4.2.7 更新文档数据
- 4.2.8 删除文档数据
- 4.2.9 检索
- 4.2.10 创建索引, 使用ik分词器
- 4.2.11 创建映射器, 指定分词器
- 4.2.12 查询
- 4.2.12.1 查询所有数据
- 4.2.12.2 按条件查询
- 4.2.12.3 通配符查询
- 4.2.12.4 词条查询
- 4.2.12.5 字段匹配查询
- 4.2.12.6 id查询
- 4.2.12.7 相似度查询
- 4.2.12.8 范围查询
- 4.2.12.9 boolean查询, 需要和其他的查询结合在一起
- 4.2.12.10 排序查询, 需要指定降序排序或者升序排序
一 ElasticSearch介绍
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库–无论是开源还是私有。
但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
二 ElasticSearch安装运行
2.1 linux 安装
解压
tar -zxvf elasticsearch
在前台(foregroud)[或后台]启动 Elasticsearch
./bin/elasticsearch [-d] // 如果是后台启动可以加参数-d
测试 Elasticsearch 是否启动成功
curl 'http://localhost:9200/?pretty'
2.2 Windows安装
- 使用解压软件解压到文件夹, 推荐使用WinRAR
- 进入到解压的路径的bin目录下, 双击elasticsearch.bat, 看到以下界面
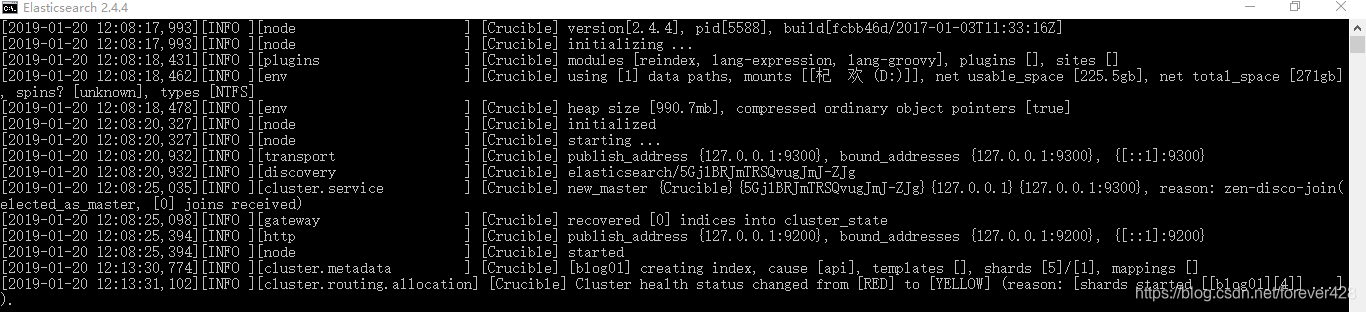
- 进入网页测试是否安装成功
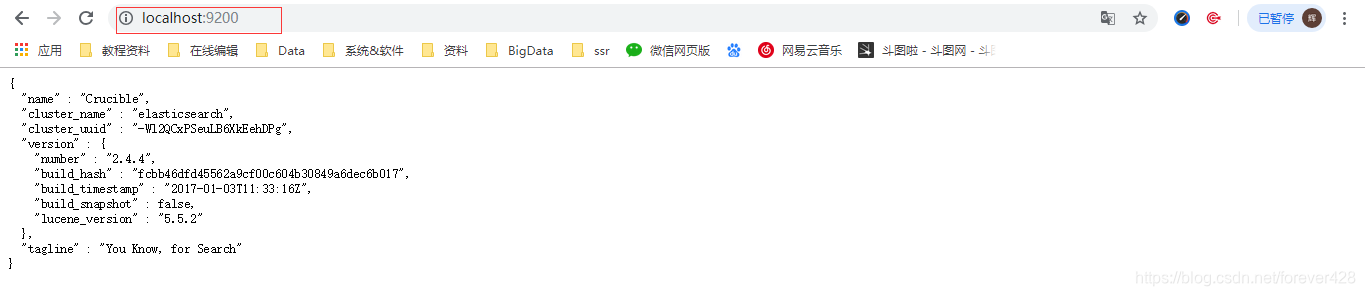
2.3 Windows安装可视化插件
2.3.1 方案一:联网的情况下,可以使用plugin命令。
- elasticsearch/bin/plugin.bat -install mobz/elasticsearch-head

- 运行es
- 打开http://localhost:9200/_plugin/head/
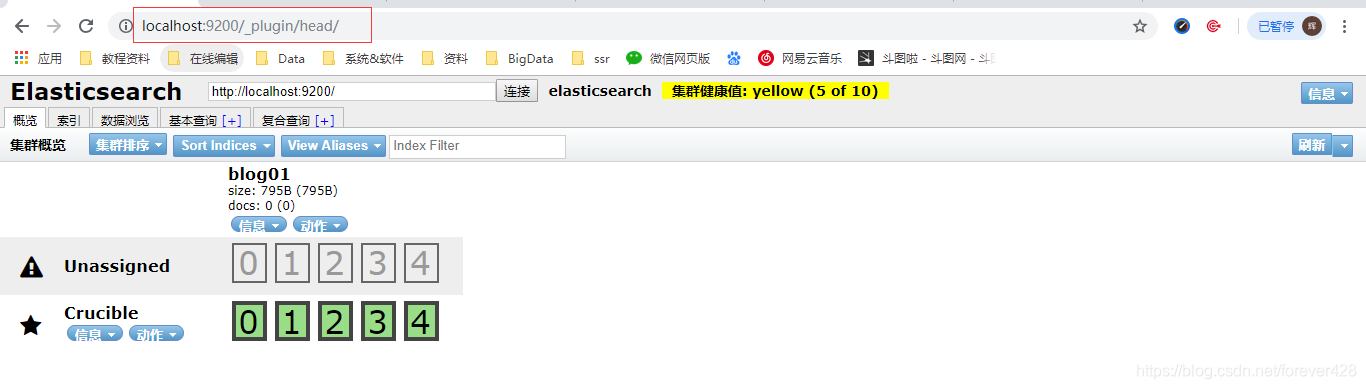
2.3.2 方案二:可以直接在git上下载源码到本地运行。
在地址栏输入es服务器的ip地址和端口,点connect就可以连接到集群。下面是连接后的视图。这是主界面,在这里可以看到es集群的基本信息(如:节点情况,索引情况)
2.4 Windows安装curl
第一步:工具下载:http://curl.haxx.se/download.html

第二步: 解压文件, 为了方便运行,不出现中文路径。
第二步:安装
【使用方式一】:在curl.exe目录中使用
解压下载后的压缩文件,通过cmd命令进入到curl.exe所在的目录。
进入到该目录后,执行curl --help测试: 
【使用方式二】:放置在system32中
解压下载好的文件,拷贝curl.exe文件到C:\Windows\System32
然后就可以在DOS窗口中任意位置,使用curl命令了。
【使用方式三】:配置环境变量(推荐)
在系统高级环境变量中,配置
CURL_HOME ----- “你的curl目录位置”
path ---- 末尾添加 “;%CURL_HOME%;”
这样与上面方式二的效果相同。
三 curl操作ElasticSearch
3.1 创建一个索引
Elasticsearch 命令的一般格式是:REST VERBHOST:9200/index/doc-type— 其中 REST VERB 是 PUT、GET 或DELETE。(使用 curlL -X 动词前缀来明确指定 HTTP 方法。)
要创建一个索引,可在你的 shell 中运行以下命令:
curl -XPUT "http://localhost:9200/blog01/"

尽管 Elasticsearch 是无模式的,但它在幕后使用了 Lucene,后者使用了模式。不过 Elasticsearch 为你隐藏了这种复杂性。实际上,你可以将 Elasticsearch 文档类型简单地视为子索引或表名称。但是,如果你愿意,可以指定一个模式,所以你可以将它视为一种模式可选的数据存储。
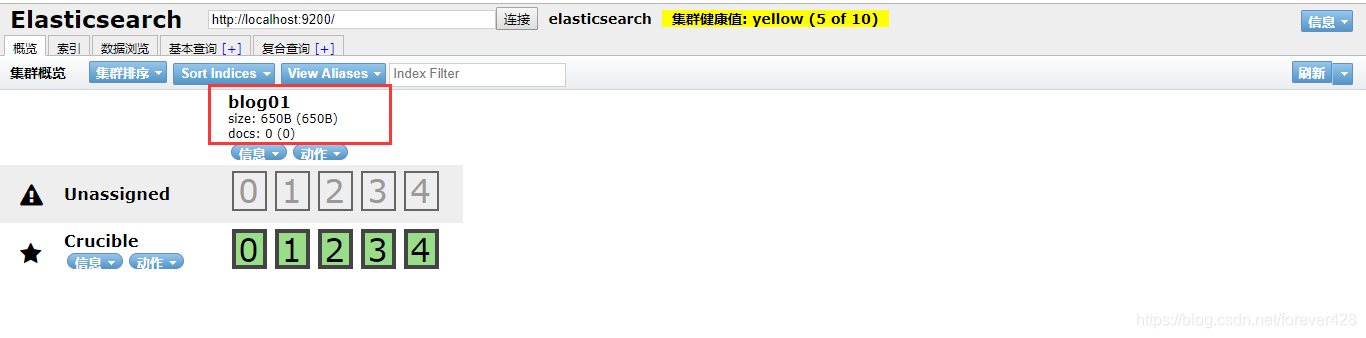
3.2 插入一个文档
要在 /blog01 索引下创建一个类型,可插入一个文档。
要将包含 “Deck the Halls” 的文档插入索引中,可运行以下命令:
curl -XPUT "http://localhost:9200/blog01/article/1" -d "{"""id""": """1""", """title""": """Whatiselasticsearch"""}"
前面的命令使用 PUT 动词将一个文档添加到 /article文档类型,并为该文档分配 ID 为1。URL 路径显示为index/doctype/ID(索引/文档类型/ID)。

3.3 查看文档
要查看该文档,可使用简单的 GET 命令:
curl -XGET "http://localhost:9200/blog01/article/1"
Elasticsearch 使用你之前 PUT 进索引中的 JSON 内容作为响应:

3.4 更新文档
如果你认识到title字段写错了,并想将它更改为 Whatislucene 怎么办?可运行以下命令来更新文档:
curl -XPUT "http://localhost:9200/blog01/article/1" -d "{"""id""": """1""", """title""": """Whatislucene"""}"

因为此命令使用了相同的唯一 ID为1,所以该文档会被更新。
3.5 搜索文档
是时候运行一次基本查询了,此查询比你运行来查找 “Get the Halls” 文档的简单 GET 要复杂一些。文档 URL 有一个内置的 _search 端点用于此用途。在标题中找到所有包含单词 lucene 的数据:
curl -XGET "http://localhost:9200/blog01/article/_search?q=title:'Whatislucene'"

3.6 检查搜索返回对象
上图中给出了 Elasticsearch 从前面的查询返回的数据。
在结果中,Elasticsearch 提供了多个 JSON 对象。第一个对象包含请求的元数据:看看该请求花了多少毫秒 (took) 和它是否超时 (timed_out)。_shards 字段需要考虑 Elasticsearch 是一个集群化服务的事实。甚至在这个单节点本地部署中,Elasticsearch 也在逻辑上被集群化为分片。在往后看可以观察到 hits 对象包含:
• total 字段,它会告诉你获得了多少个结果
• max_score,用于全文搜索
• 实际结果
实际结果包含 fields 属性,因为你将 fields 参数添加到了查询中。否则,结果中会包含 source,而且包含完整的匹配文档。_index、_type 和 _id 分别表示索引、文档类型、ID;_score 指的是全文搜索命中长度。这 4 个字段始终会在结果中返回。
3.7 删除文档
暂时不要删除该文档,知道如何删除它就行了:
curl -XDELETE "http://localhost:9200/blog01/article/1"

四 使用Java操作客户端(入门)
Elasticsearch 的 Java 客户端非常强大;它可以建立一个嵌入式实例并在必要时运行管理任务。
运行一个 Java 应用程序和 Elasticsearch 时,有两种操作模式可供使用。该应用程序可在 Elasticsearch 集群中扮演更加主动或更加被动的角色。在更加主动的情况下(称为 Node Client),应用程序实例将从集群接收请求,确定哪个节点应处理该请求,就像正常节点所做的一样。(应用程序甚至可以托管索引和处理请求。)另一种模式称为 Transport Client,它将所有请求都转发到另一个 Elasticsearch 节点,由后者来确定最终目标。
4.1 新建 maven项目, 基于maven的pom 导入依赖
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
当直接在ElasticSearch 建立文档对象时,如果索引不存在的,默认会自动创建,映射采用默认方式
- ElasticSearch 服务默认端口 9300
- Web 管理平台端口 9200
4.2 Java 操作
4.2.1 获取客户端
public class ESTest {
private Client client;
@Before
public void getClient() throws Exception {
// 设置一个hashmap集合, 用来存储配置信息
final HashMap<String, String> map = new HashMap<>();
// 配置集群名字, 如果集群名称是elasticsearch, 则无需配置
map.put("cluster.name", "es");
final Settings.Builder settings = Settings.builder().put(map);
// es 的javaapi提供的端口是9300
// 添加多个节点, 目的是为了防止其中一个实例由于网络出现问题导致传输失败, 添加多个节点后在出现网络问题后会自动启动另一个节点
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("node1"), 9300))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("node2"), 9300))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("node3"), 9300));
}
}
4.2.2 获取结果
@Test
public static void getResponse(SearchResponse searchResponse) {
// 获取搜索到的结果
SearchHits hits = searchResponse.getHits();
// 输出检索到的条数
System.out.println("查询到的数据有 " + hits.getTotalHits() + " 条");
// 遍历搜索到的结果
Iterator<SearchHit> it = hits.iterator();
while (it.hasNext()) {
SearchHit searchHit = it.next();
// 获取系统id _id
System.out.println("系统id: " + searchHit.getId());
// 获取私有id
System.out.println("私有id: " + searchHit.getSource().get("id"));
// 打印一整行数据
System.out.println("row: " + searchHit.getSourceAsString());
// 获取title
System.out.println("title: " + searchHit.getSource().get("title"));
// 获取content
System.out.println("content: " + searchHit.getSource().get("content"));
}
}
4.2.3 写入数据
4.2.3.1 使用json来创建文档并写入数据
@Test
public void createDoc_1() {
// json字符串
String source = "{\"id\":\"1\",\"title\":\"三缄其口\",\"content\":\"孔师收徒,算是震惊大陆的大事,别管是名师,还是什么,只要是修炼者,获此殊荣,必然会兴奋的东南西北都找不着。\"}";
// 创建文档, 定义索引, 文档类型, 主键id
final IndexResponse indexResponse = client.prepareIndex("blog", "article", "1").setSource(source).get();
// 获取相应信息
System.out.println("index: " + indexResponse.getIndex());
System.out.println("type: " + indexResponse.getType());
System.out.println("id: " + indexResponse.getId());
System.out.println("version: " + indexResponse.getVersion());
System.out.println("isCreated: : " + indexResponse.isCreated());
}
4.2.3.2 使用map插入数据
@Test
public void createDoc_2() {
HashMap<String, Object> source = new HashMap<>();
source.put("id", 2);
source.put("title", "悲催的林琅");
source.put("content", "两年前,屠杀他满门的时候,对方不过通玄境初期,本以为就算进步,巅峰就是极限了,没想到……和他一样,也是宗师中期");
IndexResponse indexResponse = client.prepareIndex("blog", "article", "2").setSource(source).get();
// 获取相应信息
System.out.println("index: " + indexResponse.getIndex());
System.out.println("type: " + indexResponse.getType());
System.out.println("id: " + indexResponse.getId());
System.out.println("version: " + indexResponse.getVersion());
System.out.println("isCreated: : " + indexResponse.isCreated());
client.close();
}
4.2.4 使用es 帮助类 来实现插入数据
@Test
public void createDoc_3() throws Exception {
XContentBuilder source = XContentFactory.jsonBuilder()
.startObject()
.field("id", 3)
.field("title", "Apache Hadoop")
.field("content", "The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.")
.endObject();
IndexResponse indexResponse = client.prepareIndex("blog", "article", "3").setSource(source).get();
// 获取相应信息
System.out.println("index: " + indexResponse.getIndex());
System.out.println("type: " + indexResponse.getType());
System.out.println("id: " + indexResponse.getId());
System.out.println("version: " + indexResponse.getVersion());
System.out.println("isCreated: : " + indexResponse.isCreated());
client.close();
}
4.2.5 搜索
4.2.5.1 搜索文档, 单个索引
@Test
public void getData_1() {
GetResponse getResponse = client.prepareGet("blog", "article", "1").get();
System.out.println(getResponse.getSourceAsString());
client.close();
}
4.2.5.2 搜索文档, 多个索引
public void getData_2() {
// 将需要检索的数据依次使用add方法加入
MultiGetResponse multiGetItemResponses = client.prepareMultiGet()
.add("blog", "article", "1")
.add("blog", "article", "2")
.add("blog", "article", "3")
.get();
// 遍历所有获取到的数据
for (MultiGetItemResponse multiGetItemRespons : multiGetItemResponses) {
GetResponse response = multiGetItemRespons.getResponse();
// 判断数据是否为空, 只有存在才会打印
if (response.isExists()) {
System.out.println(response.getSourceAsString());
}
}
client.close();
}
4.2.6 更新数据
4.2.6.1 使用update更新
@Test
public void updateData_1() throws Exception {
UpdateRequest request = new UpdateRequest();
request.index("blog");
request.type("article");
request.id("1");
request.doc(XContentFactory.jsonBuilder()
.startObject()
.field("id", "1")
.field("title", "Modules")
.field("content", "The project includes these modules:\n" +
"\n" +
"Hadoop Common: The common utilities that support the other Hadoop modules.\n" +
"Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.\n" +
"Hadoop YARN: A framework for job scheduling and cluster resource management.\n" +
"Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.\n" +
"Hadoop Ozone: An object store for Hadoop")
.endObject());
client.update(request).get();
client.close();
}
4.2.6.2 使用帮助类更新
@Test
public void updateData_2() throws Exception {
// 使用帮助类实现更新数据
client.update(new UpdateRequest("blog", "article", "2")
.doc(XContentFactory.jsonBuilder()
.startObject()
.field("id", "2")
.field("title", "Who Uses Hadoop?")
.field("content", "A wide variety of companies and organizations use Hadoop for both research and production. Users are encouraged to add themselves to the Hadoop PoweredBy wiki page.")
.endObject()));
client.close();
}
4.2.7 更新文档数据
设置一个查询条件, 查询id, 如果查询不到数据, 则添加, 如果查到, 则更新
@Test
public void updateData_3() throws Exception {
IndexRequest source = new IndexRequest("blog", "article", "4")
.source(XContentFactory.jsonBuilder()
.startObject()
.field("id", "4")
.field("title", "Getting Started")
.field("content", "The Hadoop documentation includes the information you need to get started using Hadoop. Begin with the Single Node Setup which shows you how to set up a single-node Hadoop installation. Then move on to the Cluster Setup to learn how to set up a multi-node Hadoop installation.")
.endObject());
// 设置更新的数据
UpdateRequest updateRequest = new UpdateRequest("blog", "article", "4")
.doc(XContentFactory.jsonBuilder()
.startObject()
.field("title", "this is update")
.endObject())
.upsert(source);
client.update(updateRequest).get();
client.close();
}
4.2.8 删除文档数据
@Test
public void delData() {
client.prepareDelete("blog", "article", "4").get();
client.close();
}
4.2.9 检索
/**
* 检索: SearchResponse, 支持各种查询
* 注意:
* es自带了分词器, 对英文单词有效果, 但是对于中文只能作为一个分字器, 即不能将中文的词汇进行分离
* 所以, 如果想要实现对中文单词进行分离, 需要用到第三方的分词器, 现在主流的分词器是IK
*/
@Test
public void search() {
SearchResponse searchResponse = client.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("this")).get();
this.getResponse(searchResponse);
client.close();
}
4.2.10 创建索引, 使用ik分词器
@Test
public void createIndex() {
// 创建索引
client.admin().indices().prepareCreate("blog").get();
// 删除索引
client.admin().indices().prepareDelete("blog").get();
}
4.2.11 创建映射器, 指定分词器
@Test
public void createIndexMapping() throws Exception {
XContentBuilder mappingBuilder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type", "integer")
.field("store", "yes")
.endObject()
.startObject("title")
.field("type", "string")
.field("store", "yes")
.field("analyzer", "ik")
.endObject()
.startObject("content")
.field("type", "string")
.field("store", "yes")
.field("analyzer", "ik")
.endObject()
.endObject()
.endObject()
.endObject();
PutMappingRequest source = Requests.putMappingRequest("blog").type("article").source(mappingBuilder);
client.admin().indices().putMapping(source).get();
client.close();
}
4.2.12 查询
4.2.12.1 查询所有数据
@Test
public void queryAll() {
SearchResponse searchResponse = client.prepareSearch("blog").setTypes("article").setQuery(QueryBuilders.matchAllQuery()).get();
this.getResponse(searchResponse);
client.close();
}
4.2.12.2 按条件查询
@Test
public void queryString() {
SearchResponse searchResponse = client.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("悲催").field("title").field("content"))
.get();
this.getResponse(searchResponse);
client.close();
}
4.2.12.3 通配符查询
@Test
public void wildcardQuery() {
SearchResponse searchResponse = client.prepareSearch("blog").setTypes("article")
.setQuery(QueryBuilders.wildcardQuery("content", "震*"))
.get();
this.getResponse(searchResponse);
client.close();
}
4.2.12.4 词条查询
@Test
public void termQuery() {
SearchResponse searchResponse = client.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.termQuery("title", "悲催"))
.get();
this.getResponse(searchResponse);
client.close();
}
4.2.12.5 字段匹配查询
@Test
public void fieldMatchQuery() {
SearchResponse searchResponse = client.prepareSearch("blog")
.setTypes("article")
// fuzziness 指的是匹配度
.setQuery(QueryBuilders.matchQuery("title", "悲催").analyzer("ik").fuzziness(1))
.get();
this.getResponse(searchResponse);
client.close();
}
4.2.12.6 id查询
@Test
public void idQuery() {
SearchResponse searchResponse = client.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.idsQuery().ids("2", "4"))
.get();
this.getResponse(searchResponse);
client.close();
}
4.2.12.7 相似度查询
@Test
public void fuzzyQuery() {
SearchResponse searchResponse = client.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.fuzzyQuery("title", "updata"))
.get();
this.getResponse(searchResponse);
client.close();
}
4.2.12.8 范围查询
@Test
public void rangeQuery() {
SearchResponse searchResponse = client.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.rangeQuery("id").gt(2).lte(3))
.get();
this.getResponse(searchResponse);
client.close();
}
4.2.12.9 boolean查询, 需要和其他的查询结合在一起
@Test
public void boolQuery() {
SearchResponse searchResponse = client.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("title", "update"))
.should((QueryBuilders.rangeQuery("id").from(1)).to(3)))
.get();
this.getResponse(searchResponse);
client.close();
}
4.2.12.10 排序查询, 需要指定降序排序或者升序排序
和bool查询类似, 需要和其他查询一起使用
@Test
public void sortQuery() {
SearchResponse searchResponse = client.prepareSearch("blog")
.setTypes("article")
.setQuery(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("title", "update"))
.must(QueryBuilders.rangeQuery("id").from(1).to(3)))
.addSort("id", SortOrder.DESC)
.get();
this.getResponse(searchResponse);
client.close();
}














 2363
2363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









