









从这里开始的内容相对复杂。中文看上去可能都有些乱乱的,我可是英文和中文一起看的,呕吐感更强烈了,但是本着技术上身学霸无敌的态度,强忍呕吐坚持学习。(苦笑。。。)
选举 Election
基本概念
貌似这个词我们已经比较陌生了。。上一次选举还是在小学四年级当选中队委。。。
之前大概简述了mongoDB的Replica在运行的时候会实现高可用性,实现高可用性的一个前提就是对客户端全透明的选举制度,当然,虽然说对客户端全透明,但是如果真正开始做选举的话,所有的节点会进入Read-only状态,保证没有数据会在选举的时候被写入,保证选举过程不会出现数据的同步导致选举结束的附加rollback动作。因为mongoDB的Replica中,只有Primary才可以进行Writes,所以一旦一个Primary不可用就一定要进行一个选举来抉择出新的Primary,再次实现健康的Replica集群。
选举的时点
集群启动时
一般,选举发生在mongoDB的Replica启动的瞬间,后面会慢慢说到启动mangoDB以及各种运用。当一个Replica集群启动的时候,是没有一个Primary的集群状态,启动后,所有的节点开始进行第一轮选举,选举过后,Primary出现,Secondary也出现,一个健康集群产生。
发生不可达时
当对一个Primary出现不可及的时候,会出现一轮选举。
什么叫做不可及?又引发了一个概念。那就是集群中的心跳检测(Hear Beats)
●心跳 Heart Beats
所谓心跳,就是一个心跳线程。我们很多架构都需要用心跳来check服务器的状况,比如WAS中有一个生死check的心跳线程。mongoDB亦然。集群的members之间会相互利用心跳每2秒检测整个集群的状态,如果出现了一个节点超过10秒没有反映,那么这个节点将被标记为不可及状态。如果这个节点是Primary的话,那么可以断定Primary为不可及状态,第一个发现这个状态的Secondary的节点就可以发起一轮投票。需要注意的是,前面我们所说的Priority=0的节点即使发现了Primary的不可及,也是不能发起投票的。
Heartbeats
Replica set members send heartbeats (pings) to each other every two seconds. If a heartbeat does not return within 10 seconds, the other members mark the delinquent member as inaccessible.
发生优先级差异时
这个又回到上一节说到的Priority的设定。题外话,说起民主,其实民主也是有附加价值的,如果实现绝对的民主那绝对是扯淡,任何民主都会有成本和付出,也都会有权值附加在里面的,所以实现民主其实实现的也是一个相对民主,呵呵,这个离我们还太远,不扯了,言归正传。
我们的集群中,机器和机器之间可能会有这样那样的差异,我们总会期望某些机器能够在选举中有更多机会成为Primary,而有些机器则希望一直去做Secondary的工作,所以,mongoDB提供了一个Priority的设定,让我们可以侧面去影响投票的结果。注意,在老版本的mongoDB中,是可以动态调整votes投票数这个属性的,也就是说你可以人为的去加票,但是新版本中早已设置为Deprecated的了。再说句题外话,mongoDB的这个设计其实很体现出西方价值观念的体现,选举的制度设定好,这个是神圣不可侵犯的,选举的目标定好,不会影响票数,只影响舆论效果和不可见的权威影响票选结果,所以从系统设计的角度也能看出社会形态,呵呵。
继续言归正传,下面的解释说明了出现优先级差异的时候会引发选举的一个场景。简要来说,当一个有着高优先级的Secondary节点其数据已经达到最新的10秒内的数据状态的时候,集群就会触发一个选举,使得高优先级的节点很容易成为Primary。
Priority Comparisons
The priority setting affects elections. Members will prefer to vote for members with the highest priority value.
Members with a priority value of 0 cannot become primary and do not seek election. For details, see Priority 0 Replica Set Members.
A replica set does not hold an election as long as the current primary has the highest priority value or no secondary with higher priority is within 10 seconds of the latest oplog entry in the set.
If a higher-priority member catches up to within 10 seconds of the latest oplog entry of the current primary, the set holds an election in order to provide the higher-priority node a chance to become primary.
Link to:http://docs.mongodb.org/manual/core/replica-set-elections/
而说到”10秒最新数据状态”,就又引发出一个新的概念 ↓
●操作时间 Optime
嗯,直接翻吧,实在没有什么自己的语言组织了。optime就是操作时间,即从oplog获取的最后的一个操作的时间戳。这个时间戳越新那么你和Primary的操作就越一致,一般我们自己搭建的小集群这个时间戳都是一致的,因为没有那么大的量和网络带宽问题拖垮我们的迷你集群。
Optime
The optime is the timestamp of the last operation that a member applied from the oplog. A replica set member cannot become primary unless it has the highest (i.e. most recent) optime of any visible member in the set.
OK,大概当下这个版本的mongoDB触发选举也就以上酱了。
选举的规则
一票否决权
嗯。没错,一票否决的话全盘否决。貌似是山寨安理会的制度?
7个投票席位
mongoDB可以支持12个节点的Replica(包括Primary)。但是,12个节点中,只可以有7个席位投票哦。那么剩下的5个咋办?mongoDB中有一个属性叫做non-voting,就是不可投(赞成)票。之前我们所说的Priority=0和Hidden虽然被阉割掉当选的权利,但是人家是可以投票的哦。好,明确了,12个席位,7个可以投票。但,虽然剩余的5个可能被我们设置为non-voting不可投(赞成)票,但是人家可是不可投赞成票哦,否定票是可以投的哦。小小的凌乱感。究其原因,如果投票的节点太多,因为是一票否定,会导致达到投票临界状态时有可能因为酱或酿的原因半天无法投票出来,影响效率,前文也说过,投票的时候整个集群是Read-only的,无法接受Write操作,这种状态时间一长,选举对于客户端可就不是透明的了。
需要注意的坑爹英文单词:veto:否决票。vote:赞成票
到这里,暂时休息一下,有必要总结一下12个节点中的各种角色了↓
●12个节点各种角色的中途总结
读写角度:
| 节点类型 | 接收Write | 接收Read |
|---|---|---|
| Primary | O | O |
| Secondary | × | O |
属性的动作角度:
| 属性类型 | 读取oplog | 接收Read |
|---|---|---|
| Priority=0 | O | O |
| Hidden | O | × |
| Arbiter | × | × |
| non-voting | O | O |
参选投票角度:
| 属性类型 | 当选Primary | 赞成票vote | veto否决票 |
|---|---|---|---|
| Priority=0 | × | O | O |
| Hidden | × | O | O |
| Arbiter | × | O | ? (未核实) |
| non-voting | O | × | O |
关于Arbiter是否可以投出否定票(veto)暂时没有得到核实,毕竟Arbiter的作用是用来充数(下面马上要说)和投关键赞成票用的。今后有机会再来探讨这个。实在不行在mongoDB的Jira上面问一下。。。
可投票的条件
上文说到,一票否决,那么当选必须要全票通过咯。还有啥可说的呢?其实这里是困扰我很久的地方。在mongoDB权威指南这本书中曾经写了这么一个场景1,我在之前的mongoDB的replica概念中也写过这个场景,讲的是投票的时候出现了2v2的情况,打了个平手,那么久需要Arbiter出来投关键一票了。等等,之前不是说过一票否决么?现在4个节点,加入一个Arbiter变成了5个,3:2的比例,和投票又有啥关系?因为投票的话肯定是5个节点中4个可以参选,一个当选的话剩下4个都得投自己才可以啊,3:2有什么意义?有点乱有点乱。我到这里也有点乱了。还好,document解惑。
先看mongoDB的在线document的一段话:
A replica set member cannot become primary unless it can connect to a majority of the members in the replica set. For the purposes of elections, a majority refers to the total number of votes, rather than the total number of members.
●大多数(Majority)
上面的这段话没有前因后果可能突然拿过来有点唐突。首先,我们先拿出来一个概念,英文叫做Majority,中文翻译为“大多数”。mongoDB的在线document的这里写到的Majority Required to Elect a New Primary就是我们书中所说的“大多数”这个概念。下文是从Majority的补集“容错率”来讲的。用白话来说就是,一个集群中,挂掉几个节点以后,剩余的节点还可以按照mongoDB的rules进行选举。从下表中看到,例如一个3节点的集群,最多可以挂掉1个,剩余2个;一个5节点的集群最多可以挂掉2个,剩余3个。。。以此类推。mongoDB权威指南中也有类似的表2。所以,对于mongoDB来讲,存活的节点必须要大于总结点数的一半以上的时候,由这些存活的节点才可以选举出一个Primary,或者换句话来讲,从一个节点出发,它自己能够联通的节点(包括它自己)达到了下表中的Majority Required to Elect a New Primary的数量时候,才可以触发一个选举,如果数量不够,那么选举被迫终止,所有的节点都变成了Secondary了。
表1-1:
Consider Fault Tolerance
Fault tolerance for a replica set is the number of members that can become unavailable and still leave enough members in the set to elect a primary. In other words, it is the difference between the number of members in the set and the majority needed to elect a primary. Without a primary, a replica set cannot accept write operations. Fault tolerance is an effect of replica set size, but the relationship is not direct. See the following table:
| Number of Members. | Majority Required to Elect a New Primary. | Fault Tolerance. |
|---|---|---|
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
多节点说明与深入解惑
明白了什么是大多数,现在可以来看几个具体的例子再来明确选举的过程和动作。
三节点P(Primary)S(Secondary)模式
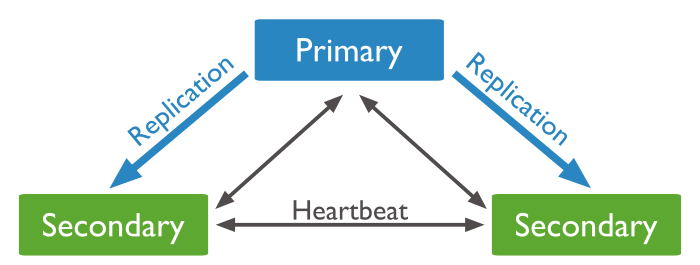
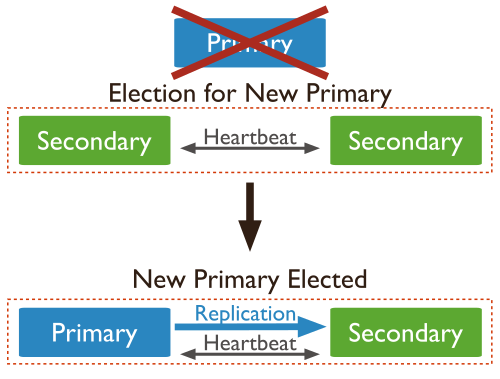
官图很清晰易懂咯。Primary挂掉了,两个S选举后变成了一个P和一个S。
三节点PSA(Arbiter)模式
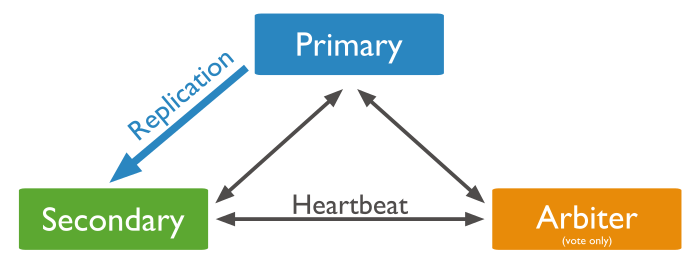
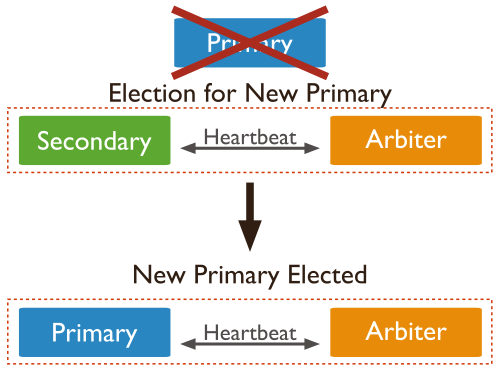
官图很清晰易懂咯。Primary挂掉了,一个S一个A选举后变成了一个P和一个A。注意,如果成为酱紫的话,A是无法进行负载的咯,P接收到了数据即使写入oplog中,A也无反应,毕竟A只为投票而生。
四节点及以上模式
好的。其实这个标题是个不太正确的标题,怎么讲呢?其实也不是很错误。mongoDB有一段话:
Odd Number of Voting Members
Ensure that the replica set has an odd number of voting members. If you have an even number of voting members, deploy an arbiter so that the set has an odd number.
这段话在讲,我们要把自己的节点数做成奇数个而不是偶数个。这个节点数是包括Primary和Secondary以及Arbiter的所有的节点。比如下图,本来我们的P+S为4个节点,而人为加了一个A成为了5个节点,变成了一个奇数的节点群组。
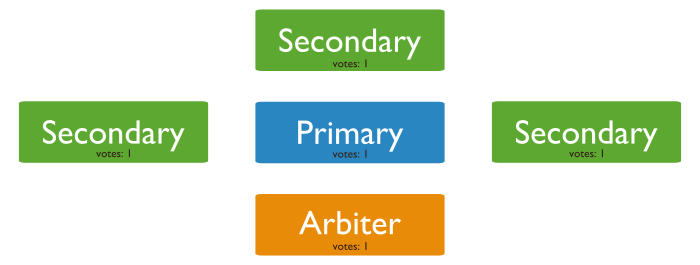
按照mongoDB的理论来说,应该把节点设置为奇数个,why?下面再说。
多节点DC分布模式以及奇偶数最终大解惑
先看图。

这是一个典型的分DC的场景。
DC:DataCenter的简称
S:Secondary的简称
P:Primary的简称
DC1有3个节点,DC2有1个节点,DC3有1个节点。
一般正常情况运行的时候,DC1的Primary接受读写,DC1的S们从oplog中读取命令跟随,DC2和DC3的S们亦然。
DC的断网的场合
DC3向外通信挂掉
某一天DC3的network出问题了,和DC1和DC2无法联通了,这个时候,对于DC3的S来说,它无法联通Primary了,投票?No!DC3的S的Priority=0是无法提出投票要求的。那么DC3的network断了对于其他两个DC没有影响。
DC2向外通信挂掉
某一天DC2的network出问题了,DC2的S是Priority>0的所以可以投票。But,DC2的S可以联通的节点个数只有它自己。总共有5个节点,现在可以联通的只有1个节点,不符合需要联通“大都数”3个节点(看上表1-1)的要求,所以也不会投票,不会把DC2的S变成P。
DC1向外通信挂掉
某一天DC1的network出现了问题,没反应。。。为啥?没有S会觉得与P断了连接。因为DC1中的两个S都还在与P通信。而且符合Majority大多数3个互联的前提。
Primary挂掉DC正常
某日,Primary突然挂掉,network正常,S们连接不上老大了,剩余的S们有4台,可以互相联通,符合大多数原则,那么开始投票,新的Primary将在DC1和DC2中产生。然后继续处理。
Primary挂掉DC全部挂掉的极端情况
某日,最悲催的。Primary挂了,然后所有DC也无法互相通信了,DC1中只有2个点可以联通,不符合3这个大多数的数量,那么选举不可以,则不选举,集群只能接受读操作而写操作挂掉。
而,如何避免?我的想法:做一个改进DC1中5个节点,DC2中1个节点,DC3中1个节点。那么即使出现了Primary全部挂掉DC之间通信不可的情况,用DC1的剩余的4个S一然可以选举出一个P进行继续工作。数数总共的节点个数,7个。貌似和mongoDB的可投票个数一样,是巧合么?还是mongoDB考虑了这种终极模式?未知。
至今未提到的奇数偶数的大解惑
其实,奇数偶数之分其实算是一个推荐。这个问题我是研究了很久,翻了不少国外研究mongoDB的哥们的文章才得出的结论。
我们如果使用一个4个节点的Replica。1个Primary3个Secondary的配置,没有IDC的地理限制,所有的节点都在一个机房中。此时Primary挂掉,剩下3个Secondary无法联通Primary,3个节点符合4个Replica的“大多数”的要求,那么可以进行选举。选出来一个Primary然后带着剩余的2个Secondary继续处理,没有问题。偶数也没问题呀,而且实际操作的场合也没有问题,后面会有实机操作的记录,我也会验证。
说到这里,来看一下原生的mongoDB中所写到的触发选举发生的条件:
Election Triggering Events
Replica sets hold an election any time there is no primary. Specifically, the following:
•the initiation of a new replica set.
集群初始化的时候
•a secondary loses contact with a primary. Secondaries call for elections when they cannot see a primary.
一个Secondary节点无法联通Primary的时候。Secondaries们会要求选举,当它们无法看到Primary的时候
•a primary steps down.
唯一的那个Primary挂掉的场合
Link to:http://docs.mongodb.org/manual/core/replica-set-elections/
还有一个前提中的前提条件,就是上面的表1-1所列出的,1-5个节点的Majority的数量,这个Majority的数量即是此Replica集群存活的最小数目。把表拿下来继续说:
| Number of Members. | Majority Required to Elect a New Primary. | Fault Tolerance. |
|---|---|---|
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
首先,我们可以很清晰地看到偶数节点的Majority的数量除以总节点数的数量都大于奇数的Majority的数量除以总节点数量。即Majority(Even)/Total(Even) > Majority(Odd)/Total(Odd),那么从需要最小存活率上面来讲,偶数节点的使用率高,效率低下。可参看下面这篇文章:
http://dbversity.com/mongodb-why-we-need-odd-number-nodes-in-rs/
其次,也是很重要的一个原因。如果我们是偶数节点,假设我们放置节点在两个IDC,那么会出现2:2的放置情况,这个时候如果两个IDC之间的网络断开,那么会出现什么情况?每一个节点可以连接的节点数量都是2,不符合4个节点的最小连接数量(Majority)=3这个标准,那么整个Replica集群就失去了处理能力。单如果我们是奇数个的场合永远不会出现平均分配这个情况,即使IDC通信中断了,节点数为3个那一方还是可以继续处理的,所以mongoDB会建议我们使用奇数节点,并且把Primary设置在多节点的那一个DC当中去。当然,如果我们使用4个节点,但是按照3:1放置,其实也是不会出现问题的,但是回到上面那个效率的话题,使用4个节点,挂1个还能用,挂2个就不能用了,和使用3个节点效果是一样的啊!3个节点也是挂1个可以继续用,挂2个就不能用了,为何不使用奇数结点呢?所以mongoDB建议使用奇数节点。
つづく・・・















 6084
6084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









