







进程与线程学习笔记
1、系统调用
在程序状态字(Program Status Word, PSW)寄存器中有一个二进制位控制CPU的两种工作模式(内核态和用户态)。在内核态运行时,CPU可以执行指令集中的每一条指令,操作系统在内核态下运行,从而可以访问整个硬件。用户程序在用户态下运行,仅允许执行整个指令集中的一个子集。一般而言,在用户态中有关I/O和内存保护的所有指令都是禁止的。为了从操作系统中获得服务,用户程序使用系统调用(system call)陷入内核,TRAP(陷阱)指令把用户态切换成内核态,并启用OS,当有关工作完成之后,在系统调用后面的指令把控制权返回给用户程序。
下面列出了一些重要的 POSIX 系统调用
| pid = fork() | 创建与父进程相同的子进程 |
| pid = waitpid(pid, &statloc, options) | 等待一个进程终止 |
| s = execve(name, argv, environp) | 替换一个进程的地址空间 |
| exit(status) | 中止进程执行并返回状态 |
| s = kill(pid, signal) | 发送信号给一个进程 |
| fd = open(file, how, …) | 打开一个文件供读、写或两者 |
| s = close(fd) | 关闭一个打开的文件 |
| n = read(fd, buffer, nbytes) | 把数据从一个文件读到缓冲区 |
| n = write(fd, buffer, nbytes) | 把数据从缓冲区写到一个文件中 |
| position = lseek(fd, offset, whence) | 移动文件指针 |
| s = stat(name, &buf) | 获取文件的状态信息 |
| s = mkdir(name, mode) | 创建一个新目录 |
| s = rmdir(name) | 删除一个空目录 |
在Unix中,系统调用和系统调用所使用的库过程之间几乎是一一对应的关系。且进程之间存在层次关系,称为进程树,所有进程都属于以init(OS启动进程)为根的一棵树。
在Windows中,我们通过API获得操作系统的服务,但大部分API和系统调用不存在对应关系。且不存在父进程和子进程的概念,进程创建之后,创建者和被创建者是平等的。
注意:fork()创建一个原有进程的精确副本,子进程可以通过execve()替换不同的映像文件,从而执行不同的程序;waitpid()用于挂起调用进程,直到其它(特定的)进程退出。kill()供用户进程发送信号,若一个进程准备好捕捉一个特定的信号,那么,在信号到来时,运行一个信号处理程序,如果该进程没有准备好,那么信号的到来会杀死该进程。
2、进程
进程(process)本质上是正在执行的一个程序,是容纳运行一个程序所需要所有信息的容器。与一个进程相关的是进程的地址空间(address space)和进程表(process table)。进程的地址空间包括代码段、数据段、堆栈段。下面画出了进程的三种状态,以及状态之间的切换:
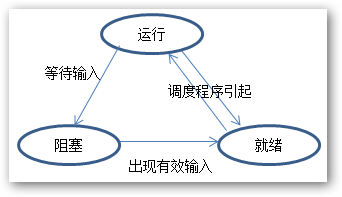
在多任务系统中,CPU使用某种调度算法在不同进程间来回快速切换,就好像这几个进程在并发执行一样。进程间的切换是通过中断(interrupt)来实现的。OS维护一张表格,即进程表,每个进程占用一个进程表项(也称进程控制块),该表项包含了进程状态的重要信息,包括程序计数器(保存了下一条指令的内存地址)、堆栈指针、内存分配状况、所打开文件的状态、账号和调度信息,以及其他在进程由运行态转换到就绪态或阻塞态时必须保存的信息,从而保证该进程随后能再次启动,就像从未被中段过一样。
线程是把进程的两项功能——独立分配资源与被调度分派执行分离开来。进程作为系统资源分配和保护的独立单位,不需要频繁地切换。线程作为系统调度和分派的基本单位,能轻装运行,会被频繁地调度和切换。
3、线程(thread)
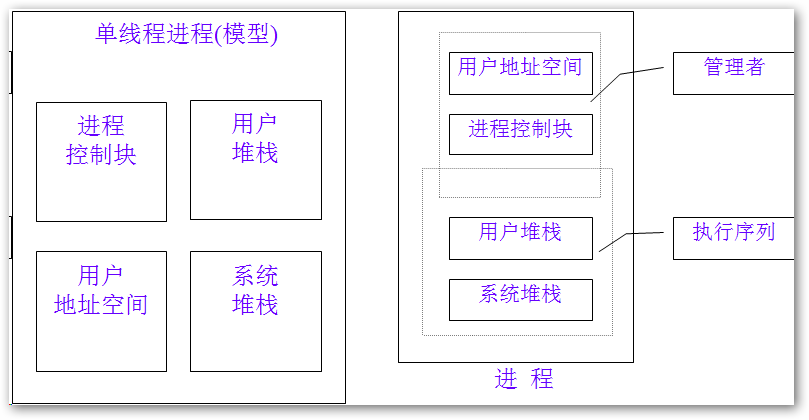
在传统的操作系统中,进程有一个地址空间和一个控制线程;而在多线程系统中,一个进程的地址空间中同时运行多个控制线程。

多线程的优点:
(1) 应用程序中往往同时发生着多种活动,其中某些活动随时间的推移会被阻塞。通过将这些应用程序分解成可以准并运行的多个顺序线程,程序设计模型会变得更加简单。
(2) 线程比进程更轻量级,更容易创建和撤销。
(3) 如果应用程序中存在大量的计算和I/O处理,拥有多个线程允许这些活动彼此重叠进行,从而会加快程序执行的速度。
(4) 在多CPU系统中,多线程可以实现真正的并行运算。
在同一个进程中并行运行多个线程,是对在同一台计算机上并行运行多个进程的模拟。因此,线程也被称为轻量级进程(lightweight process)。与进程调度类似,CPU在线程之间快速切换,制造了线程并行运行的假象。不同的进程之间有独立的地址空间,而线程之间有完全一样的地址空间,这意味着它们共享同样的全局变量。
由于各个线程都可以访问进程地址空间的每一个内存地址,所以一个线程可以读、写,甚至清除另一个线程的堆栈。也就是说,线程之间是没有保护的。我们知道,不同的进程可能属于不同的用户所拥有,它们之间可能存在敌意。但用户创建多线程是为了它们之间的合作而不是彼此争斗。除了共享地址空间外,所有线程还共享同一个打开的文件集、子进程、报警以及相关信号等。但要注意的是,每个线程都有自己的堆栈、程序计数器、寄存器等信息,这些不是共享的。
下面列出了几个 POSIX 线程标准
| Pthread_create | 创建一个新线程 |
| Pthread_exit | 结束调用的线程 |
| Pthread_join | 阻塞调用线程直到某个其它(特定)线程退出 |
| Pthread_yield | 主动释放CPU从而让另外一个线程运行 |
| Pthread_attr_init | 创建并初始化一个线程的属性结构 |
| Pthread_attr_destroy | 删除一个线程的属性结构 |
与进程不同的是,无法利用时钟中断强制线程让出CPU,所以我们设法使线程行为“高尚”起来,并且随着时间的推移自动交出CPU,以便让其他线程有机会运行,这正是Pthread_yield系统调用的作用。
3.1 在用户空间中实现线程
有两种主要的方法实现线程包:在用户空间中和在内核中。前者是把整个线程包放在用户空间中,内核对线程包一无所知,仍按正常的单线程进程方式管理。
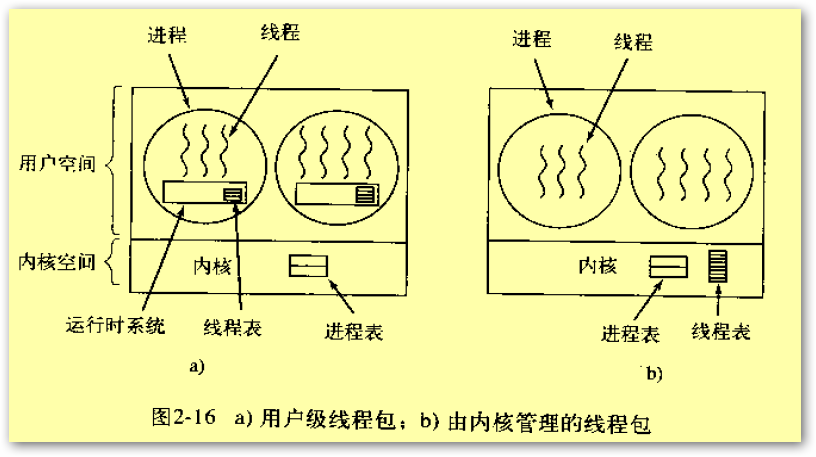
在用户空间实现线程,线程在一个运行时系统(即线程库)的顶部运行,这个运行时系统是一个管理线程的过程的集合,包括pthread_create、pthread_exit、pthread_join、pthread_yield等过程。每个进程需要其专门的线程表(thread table),用来跟踪该进程中的线程。线程表由运行时系统管理,当一个线程转换到就绪状态或阻塞状态时,在该线程表中存放重启该线程所需的信息,与内核在进程表中存放的进程的信息完全一样。
当某个线程做了一些会引起在本地阻塞的事情之后,例如等待进程中另一个线程完成某些工作,它调用一个运行时系统的过程,这个过程检查该线程是否必须进入阻塞状态。如果是,它在线程表中保持该线程的寄存器,并查看表中可运行的就绪线程,并把新线程的保存值重新装入机器的寄存器中。只要堆栈指针和程序计数器一被切换,新线程就又自动投入运行。
在用户空间中实现线程包的优点:
(1) 用户级线程包可以在不支持线程的操作系统上实现。
(2) 线程切换至少要比陷入内核要快一个数量级。在线程完成运行时,它调用thread_yield可以把该线程的信息保存在线程表中;进而,它可以调用线程调度程序来选择另一个要运行的线程。保存该线程状态的过程和调度程序都只是本地过程,所以启动它们比进行内核调用效率更高。另一方面,不需要陷阱,不需要上下文切换,也不需要对内存高速缓存进行刷新,这使得线程调度非常快捷。
(3) 允许每个进程有自己定制的调度算法。
(4) 具有较好的可扩展性,这是因为在内核空间中内核线程需要一些固定表格空间和堆栈空间,当内核线程的数量非常大,就会出现问题。
在用户空间中实现线程包的缺点:
(1) 如何实现阻塞系统调用而不影响其它线程。一种方法是使用非阻塞版本的系统调用;另一种方法是使用包装器(jacket 或 wrapper),在进行阻塞系统调用之前检查是否会引起阻塞,如果调用会被阻塞,有关的调用就不进行,代之以运行另一个线程。
(2) 在一个单独的进程内部,没有时钟中断,所以不能用轮转调度的方式调度线程。如果一个线程开始运行,那么在该进程中的其他线程就不能运行,除非第一个线程自动放弃CPU。
3.2 在内核中实现线程包
在内核中实现线程,此时不再需要运行时系统。另外,每个进程中也没有线程表,相反,在内核中用来记录系统中所有线程的线程表。当一个线程阻塞时,内核可以根据其选择,可以运行同一个进程中的另一个线程,或者运行另一个进程中的线程。而在用户级线程中,运行时系统始终运行自己进程中的线程,直到内核剥夺它的CPU为止。
内核级线程的缺点是:应用程序线程在用户态运行,而线程调度和管理在内核实现。在同一进程中,控制权从一个线程转移到另一个线程,需要用户态-内核态-用户态的模式切换,系统开销较大。
综上:用户级线程和内核级线程之间的差别在于性能。用户级线程的切换需要少量的机器指令,而内核级线程需要完整的上下文切换,修改内存映像,使高速缓存失效,这导致了若干数量级的延迟。另一方面,在使用内核级线程时,一旦线程阻塞在I/O就不需要像在用户级线程中那样将整个进程挂起。
上面我们分别研究了用户级线程和内核级线程,如果能够将两者结合起来,可以实现混合式线程,如下图所示。
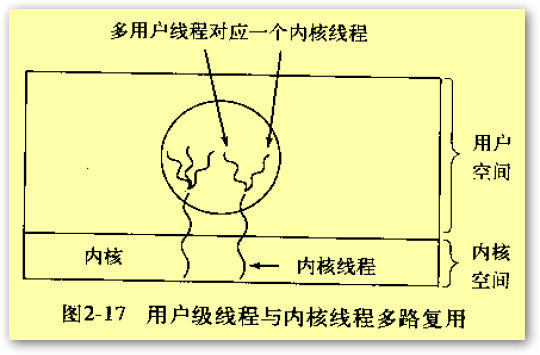
采用混合式线程,内核只识别内核级线程,并对其进行调度。其中一些内核级线程会被多个用户级线程多路复用,在这种模型中,每个内核级线程有一个可以轮流使用的用户级线程集合。
4、进程调度机制
进程切换的代价是比较高的:首先必须从用户态切换到内核态,然后保存当前进程的状态以便以后重新装载,接着通过调度程序(scheduler)选定一个新进程,之后将新进程的内存映像重新装入,最后新进程开始运行。可见,选择一个好的进程调度算法(scheduling algorithm)非常重要。通常我们将进程划分两类:I/O密集型(IO-bound)和计算密集型(computer-bound),更多的进程倾向为I/O-bound,这是因为CPU的技术进步速度远快于磁盘。
何时调度:
(1) 在创建一个新进程之后,需要决定是运行父进程还是运行子进程。
(2) 在一个进程退出时必须做出调度决策,从就绪进程队列中选择一个进程运行。
(3) 当一个进程被阻塞在I/O或信号量或其他原因时,必须选择另外一个进程运行。
(4) 在一个I/O中断发生时,必须做出调度决策。如果中断来自I/O设备,当该设备完成工作后,被阻塞等待该I/O的进程就可以成为就绪进程,等待调度。
根据如何处理时钟中断,可以把调度算法分为两类:
(1) 抢占式:进程运行某个固定时段的最大值,在该时刻结束时被挂起,并由调度程序挑选另一个进程运行(根据优先级)。
(2) 非抢占式:进程运行直至被阻塞(阻塞在I/O上或等待另一个进程),或者直到该进程自动释放CPU。
在不同类型的系统中,调度策略也不相同,下面介绍三种环境下的调度机制:
4.1 批处理系统中的调度
批处理系统主要应用商业领域或科研单位等大型机构,批处理系统的三个主要指标为:吞吐量(单位时间完成的作业数量);周转时间(平均完成每个作业所需的时间);CPU利用率。如下面所示,假如有4个作业需要处理,每个作业需要的CPU单位时间标记在括号里,这两种调度方法的吞吐量是一样的,都需要20个CPU单位时间。但周转时间不一样,第一个的周转时间为(8+12+16+20)/4=14;第二个的周转时间为(4+8+12+20)/4=11。----A(8)-----B(4)-----C(4)-----D(4)-----
----D(4)-----B(4)-----C(4)-----A(8)-----
(1) 先来先服务(非抢占式):使用一个队列记录所有就绪进程,从队列头部选择一个要运行的进程;要添加一个新的作业或阻塞一个进程,只要把该作业或进程追加到队尾即可。先来先服务对于I/O-bond进程来说,CPU利用率很低。
(2) 最短作业优先(非抢占式):如果各个作业的CPU时间是可预期的,将进程按照它们各自所需要的CPU时间排序,优先执行占用CPU时间短的作业,以达到最短的作业周转时间。
(3) 最短剩余时间优先(抢占式):最短作业优先的抢占式版本,调度程序总是选择剩余时间最短的那个进程运行。当然,有关的运行时间必须提前掌握。
4.2 交互式系统中的调度
交互式系统在个人计算机、服务器等系统中比较常见,它对响应时间和均衡性要求比较高。(1) 轮转调度:每个进程被分配一个时间段,称为时间片(quantum),即允许该进程在该时间段中运行。如果在时间片结束时刻该进程还在运行,则将剥夺CPU并分配给另一个进程。如果该进程在时间片结束前阻塞或结束,则CPU立即切换。注意:时间片设置太短会导致过多的进程切换,降低CPU效率;而设得太长又可能引起对短的交互请求的响应时间变长。
(2) 优先级调度:轮转调度隐含一个假设,即所有进程同等重要。而优先级调度给每个进程赋予一个优先级,并允许优先级高的进程先运行。为了防止高优先级进程无休止地运行下去,调度程序可以在每个时钟中断降低当前进程的优先级。例如I/O-bound进程可以被赋予较高的优先级,以改善对用户的交互性。
(3) 多级队列:
(4) 最短进程优先:从当前进程中选择需要CPU时间最短的进程运行,以获得最短的响应时间。不过,这里需要某种算法来推测各个进程的运行时间。
(5) 保证调度:假设每个进程需要的CPU时间是可预期的,系统跟踪各个进程自创建以来已使用的CPU时间,然后计算出各个进程真正获得的CPU时间和应获得的CPU时间之比,调度程序优先让这个比率值比较低的进程运行。
(6) 彩票调度:系统向将进程发放彩票,调度程序随机抽出一张彩票,拥有该彩票的进程获得资源。各个进程拥有的彩票份额与它们获得的CPU时间大致成正比。
(7) 公平分享调度:考虑进程的拥有者,做到让不同用户的进程获得大致相等的CPU时间。
4.3 实时系统中的调度
实时系统是一种时间起着主导作用的系统,它对截止时间的要求比较高。

















 8602
8602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









