







文章目录
Runable 和 Callable
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
- Runable 不带泛型
- 抽象方法为run,没有返回值
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
- Callable 带泛型,泛型为任务返回类型
- 抽象方法为call方法,带返回值
Runable 没有返回值,其在执行时出现异常,我们的主线程也是没法得知的,可以用它执行简单的任务,Callable 带返回值,且如果执行时出现异常,我们的主线程也是可以得知的,可以用于执行比较复杂的任务。
Callable 需要借助 Future 才能在多线程情况下对结果、过程进行操作。
Future1.5+
Future 定义了异步计算并返回结果的一系列方法,还提供了在任务执行前后可以取消任务的操作方法,Future 接口定义如下
// 泛型 V 表示要返回的数据的类型
public interface Future<V> {
/**
* 尝试取消执行此任务。如果任务已完成、已取消或由于其他原因无法取消,则此尝试将失败。
* 如果尝试成功:
* 1. 在调用cancel时此任务尚未启动,则不应运行此任务
* 2. 在调用cancel时此任务已经启动,根据 mayInterruptIfRunning
* 参数判断是否中断线程来停止任务
*
* cancel 成功后,后续调用 isDone 方法都将返回 true
* 如果当前方法返回 true,那么后续调用 isCancelled 方法都将返回 true
*
* @param mayInterruptIfRunning 线程执行中是否中断线程执行
* @return 如果任务无法取消(通常是因为它已经正常完成),返回 false;否则返回 true
*/
boolean cancel(boolean mayInterruptIfRunning);
/**
* 如果此任务在正常完成之前被取消,则返回true
*
* @return 如果此任务在正常完成之前被取消,则返回true
*/
boolean isCancelled();
/**
* 如果此任务已完成,则返回true。
* 注:任务完成的情况如下:
* 1. 正常终止
* 2. 异常
* 3. 取消
* 以上情况方法都将返回true
*/
boolean isDone();
/**
* 等待计算结果并返回
*
* @return 返回计算结果
* @throws CancellationException 如果被取消
* @throws ExecutionException 执行任务过程中出现异常
* (实际的异常会通过 ExecutionException 包装后抛出)
* @throws InterruptedException 当前线程被打断时抛出
*/
V get() throws InterruptedException, ExecutionException;
/**
* 等待计算结果并返回,有最长等待时间
*
* @param timeout 最长等待结果返回的时间
* @param unit 等待时间的单位
* @return 计算结果
* @throws CancellationException 如果被取消
* @throws ExecutionException 执行任务过程中出现异常
* (实际的异常会通过 ExecutionException 包装后抛出)
* @throws InterruptedException 当前线程被打断时抛出
* @throws TimeoutException 超过等待时间没有返回结果
*/
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
FutureTask1.5+
FutureTask 是 Future 接口的一个基本实现。其继承关系如下图:
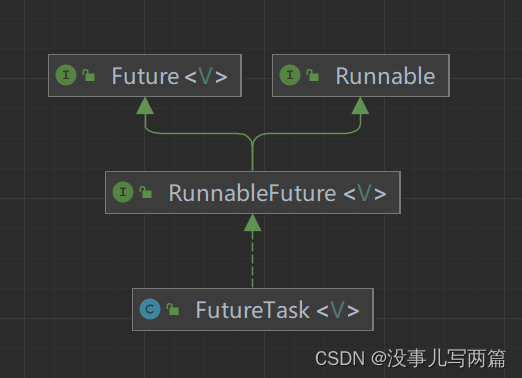
通过继承关系图我们可以知道,FutureTask 实现了 RunnableFuture 接口,间接也实现了 Runnable 接口,意味着我们可以将 FutureTask 提交给线程或线程池执行。
示例
造一台跑车需要5个任务,1.造骨架(1s);2. 造发动机(5s);3. 造轮胎(1s); 4. 组装(2s);
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.concurrent.CustomizableThreadFactory;
import java.util.concurrent.*;
@Slf4j
public class Test1 {
/**
* 造一台跑车需要5个任务,1.造骨架(1s);2. 造发动机(5s);3. 造轮胎(1s); 4. 组装(2s);
* @param args
*/
public static void main(String[] args) throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
FutureTask<String> task1 = new FutureTask<>(()->{
System.out.println("开始生产骨架");
TimeUnit.SECONDS.sleep(1);
System.out.println("骨架生产完成");
return "汽车骨架";
});
FutureTask<String> task2 = new FutureTask<>(()->{
System.out.println("开始生产引擎");
TimeUnit.SECONDS.sleep(5);
System.out.println("引擎生产完成");
return "汽车引擎";
});
FutureTask<String> task3 = new FutureTask<>(()->{
System.out.println("开始生产轮胎");
TimeUnit.SECONDS.sleep(1);
System.out.println("轮胎生产完成");
return "汽车轮胎";
});
// 定义一个线程池来执行这些任务
ThreadPoolExecutor pool = null;
try {
pool = new ThreadPoolExecutor(2, 5, 10, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(15), new CustomizableThreadFactory("My-Car-Factory-"));
pool.execute(task1);
pool.execute(task2);
pool.execute(task3);
// 等待结果(此处会陷入阻塞,导致组装方法会等待这3个任务都执行完成后才会执行)
String skeleton = task1.get();
String engine = task2.get();
String tire = task3.get();
Car car = Car.assemble(skeleton, engine, tire);
System.out.println("组装完成!");
System.out.println(car);
System.out.println("总共执行时间:" + (System.currentTimeMillis() - start));
}finally {
if(pool != null)
pool.shutdown();
}
}
@Data
static class Car{
/**
* 骨架
*/
private String skeleton;
/**
* 发动机
*/
private String engine;
/**
* 轮胎
*/
private String tire;
private Car(){
}
/**
* 组装方法
*/
public final static Car assemble(String skeleton,String engine,String tire){
Car car = new Car();
car.setSkeleton(skeleton);
car.setEngine(engine);
car.setTire(tire);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return car;
}
}
}
实际上,ThreadPoolExecutor 的 submit 方法 底层就是通过FutureTask,实现的,所以我们的示例可以简化如下:
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.concurrent.CustomizableThreadFactory;
import java.util.concurrent.*;
@Slf4j
public class Test2 {
/**
* 造一台跑车需要5个任务,1.造骨架(1s);2. 造发动机(5s);3. 造轮胎(1s); 4. 组装(2s);
* @param args
*/
public static void main(String[] args) throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
// 定义一个线程池来执行这些任务
ThreadPoolExecutor pool = null;
try {
pool = new ThreadPoolExecutor(2, 5, 10, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(15), new CustomizableThreadFactory("My-Car-Factory-"));
Future<String> task1 = pool.submit(()->{
System.out.println("开始生产骨架");
TimeUnit.SECONDS.sleep(1);
System.out.println("骨架生产完成");
return "汽车骨架";
});
Future<String> task2 = pool.submit(()->{
System.out.println("开始生产引擎");
TimeUnit.SECONDS.sleep(5);
System.out.println("引擎生产完成");
return "汽车引擎";
});
Future<String> task3 = pool.submit(()->{
System.out.println("开始生产轮胎");
TimeUnit.SECONDS.sleep(1);
System.out.println("轮胎生产完成");
return "汽车轮胎";
});
// 等待结果(此处会陷入阻塞,导致组装方法会等待这3个任务都执行完成后才会执行)
String skeleton = task1.get();
String engine = task2.get();
String tire = task3.get();
Car car = Car.assemble(skeleton, engine, tire);
System.out.println("组装完成!");
System.out.println(car);
System.out.println("总共执行时间:" + (System.currentTimeMillis() - start));
}finally {
if(pool != null)
pool.shutdown();
}
}
@Data
static class Car{
/**
* 骨架
*/
private String skeleton;
/**
* 发动机
*/
private String engine;
/**
* 轮胎
*/
private String tire;
private Car(){
}
/**
* 组装方法
*/
public final static Car assemble(String skeleton,String engine,String tire){
Car car = new Car();
car.setSkeleton(skeleton);
car.setEngine(engine);
car.setTire(tire);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return car;
}
}
}
Fork/Join1.7+
在 Fork/Join 之前,我们在线程池中执行的线程之间是没有直接的关联的,这种情况下,如果我们某一个线程的执行需要另一个线程的执行结果,就没有办法实现,所有 JDK1.7 引入了 Fork/Join 框架。
Fork/Join 的核心思想就是分治算法:将一个规模较大的问题分解为多个规模较小的子问题,这些子问题之间相互独立且与原问题的性质相同。将所有子问题的解求出来,原问题的解也就求出来了。比如:我们要计算全国的总人口,只需要分别将各个省的总人口计算出来就行了。与之类似的一个更简单的例子就是斐波拉契数列 F(n)= F(n-1) + F(n-2) ,F(1) = 1,F(2)=1
ForkJoinPool1.7+ 线程池
用于运行 ForkJoinTasks 的 ExecutorService。ForkJoinPool 与其他类型的 ExecutorService 的区别主要在于采用了工作窃取:池中的所有线程都试图找到并执行提交到池中的任务。
工作窃取指的是允许空闲线程从繁忙线程的工作队列中窃取任务。一般情况下,工作线程是从它自己对应的工作队列(WorkQueue 是 ForkJoinPool 的内部类)的头部获取任务执行,但当它的工作队列为空时会从其他繁忙的工作线程的工作队列的尾部窃取任务来执行。工作窃取是ForkJoinPool的性能保证的关键之一

任务的类型
- IO 密集型:IO 操作比较耗时,导致总体占用较多时间,数据库读写、文件读写、网络通信等任务都属于 IO 密集型任务
对于 IO 密集型任务,一般会将最大线程数设置为 CPU 核心数很多倍。IO 读写速度相比于 CPU 计算的速度要慢很多,如果设置的线程数较少,线程可能都在处理 IO 操作,导致 CPU 资源的浪费。如果设置较多的线程数,当一部分线程在等待 IO 的时候,这部分线程不需要 CPU 资源,其他的线程就可以利用 CPU 资源去执行其他任务。我们大多数的任务都属于 IO 密集型任务。
- CPU 密集型:CPU 密集型任务也称为计算密集型任务,包括加密、解密、压缩和计算等一系列需要大量耗费 CPU 资源的任务
对于 CPU 密集型的任务,并不是设置越多的线程性能越高,因为在计算时需要使用 CPU,极端情况下,CPU 是没有空闲时间的,如果线程数设置过多,反而由于线程之间对 CPU 资源的争抢造成不必要的上下文切换导致性能下降。
ForkJoinPool 源码注解提到,ForkJoinPool 执行 IO 密集型任务可能会出现问题,所以 ForkJoinPool 建议用于执行 CPU 密集型任务,我们的大多数任务其实都是 IO 密集型任务,所以 ForkJoinPool 本身在实际应用中相对较少。
实例化方式
- 构造方法
/**
*
* @param parallelism 并行度级别(默认是 CPU 核数)
* @param factory 创建线程的工厂,默认 ForkJoinPool 的内部类 DefaultForkJoinWorkerThreadFactory
* @param handler 线程执行时出现错误时的处理程序。(默认 null)
* @param asyncMode true 先进先出,false 后进先出(默认 false)
* @throws IllegalArgumentException 如果并行度小于或等于零,或大于实现限制
* @throws NullPointerException 如果 factory 参数为空
* @throws SecurityException 如果存在 security manager 且没有权限
*/
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode)
- 静态方法 commonPool()
该方法直接返回一个静态 ForkJoinPool common,common 在 ForkJoinPool 的静态代码块中初始化
common = java.security.AccessController.doPrivileged (new java.security.PrivilegedAction<ForkJoinPool>() { public ForkJoinPool run() { return makeCommonPool(); }});其中 doPrivileged 是一个静态 native 方法,最终就是获取
public static native <T> T doPrivileged(PrivilegedAction<T> action);
注:非特殊要求的情况下,使用 commonPool() 方法获取 ForkJoinPool 实例即可。
ForkJoinTask1.7+
ForkJoinTask 是个抽象类,一般情况下,我们需要继承其两个子类中的一个。在分治算法思想下,我们可以理解为每个 ForkJoinTask 任务就是一个子计算,且执行子计算由 ForkJoinPool 线程池中的线程运行
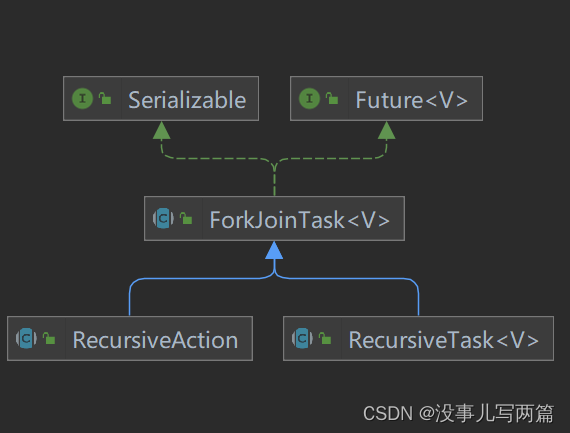
- RecursiveAction 无返回值的任务
- RecursiveTask 有返回值的任务
- CountedCompleter 在任务完成后会触发执行 onCompletion 方法
示例
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.TimeUnit;
@Slf4j
public class ForkJoinTest1 {
public static void main(String[] args) {
int n = 10;
// 获取默认的静态线程池
long start = System.currentTimeMillis();
ForkJoinPool pool = ForkJoinPool.commonPool();
MyForkTask fn = new MyForkTask(n);
pool.execute(fn);
System.out.println("fork/join 执行结果:" + fn.join());
System.out.println("fork/join 执行时间:" + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
System.out.println("递归执行结果:" + fn(n));
System.out.println("递归执行时间:" + (System.currentTimeMillis() - start));
}
/**
* 递归方式
* @param n
* @return
*/
public static final int fn(int n){
/*try {
// 休眠模拟计算时长
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}*/
if(n == 1 || n == 2){
return 1;
}
return fn(n - 1) + fn(n - 2);
}
static class MyForkTask extends RecursiveTask<Integer>{
/**
* 表示第n项
*/
private int n;
public MyForkTask(int n){
this.n = n;
}
@Override
protected Integer compute() {
/*try {
// 休眠模拟计算时长(当计算时间比较长的时候,ForkJoin 的优势就体现出来了)
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}*/
if(n == 1 || n == 2){
return 1;
}
MyForkTask fn_1 = new MyForkTask(n - 1);
MyForkTask fn_2 = new MyForkTask(n - 2);
// 执行分支计算
fn_1.fork();
// 执行分支计算
fn_2.fork();
// F(n)= F(n-1) + F(n-2)
return fn_1.join() + fn_2.join();
}
}
}
注:如果不加休眠时长,好像递归方式比 forkjoin 方式更快,因为每一个分支都计算都太快了,forkjoin 方式会有线程切换带来的时间开销,导致执行相对较慢。但如果将我们示例中注释掉的休眠时间加上,你会发现 forkjoin 的方式会快很多。
执行 ForkJoinTask 任务的几个方法
- ForkJoinPool 的 submit、execute、invoke 方法(在我们自定义的 ForkJoinTask 外部使用)
- execute:异步执行 ForkJoinTask ,返回 void。表示不需要返回结果
- submit:异步执行 ForkJoinTask,并返回 ForkJoinTask 对象本身(其实就是 Future 对象),之后可在适当的地方调用 get 或 jion 方法获取结果
- invoke:异步执行 ForkJoinTask,并直接等待返回结果(内部直接调用了 join 方法)
- ForkJoinTask 的 fork 和 join 方法
- fork 用于在 ForkJoinTask 任务内部异步执行其他 ForkJoinTask 任务。
- join 获取任务的计算结果
join 与 get 方法的区别:
- 在遇到计算异常时,join 抛出的是 RuntimeException。而 get 方法 抛出的是 ExecutionException
- 在线程被打断时,join 不会抛出 InterruptedException。
















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









