










返回文档首页
(一)简介
代码下载: git clone git://git.code.sf.net/p/redy/code redy-code
这一章的内容有:
输入缓冲区的设计与实现
(二)扫描器简介
在前面的章节当中,我们都是从终端下输入字符串,然后来判断该字符串属于那类型的词文,在这一章里面,我将讲述怎么从源程序文件中效率的读取字符序列,并在后面把这些字符序列交给扫描器转化为词文。在编译原理里面,实现这一过程的方法叫做扫描器。扫描器在对字符序列识别时,采用的是贪心算法,即尽可能识别字符序列。例如字符序列145572.2545不会被识别成:整数、点号、整数这三个词文,而是被识别成浮点数。
在实现扫描器这前,我们先实现一个输入缓冲区
(三)输入缓冲区的设计与实现
(1)简介
在扫描器扫描文件的时候,每一次从文件中读取一个字符,判断该字符是否能被识别,在C库里面可能通过fgetc()实现从文件中读取一个字符,但是这样做的效率太低,调用getchar的时候,函数内部发生了很多我们不知道的事情,例如系统调用或者是调用其它的函数。第二个原因不能使用fgetc()是因为扫描器采用的最大识别的方法,例如时我们识别字符序列254.INC,扫描器在扫描254后,判断出254是一个整数,但是还会继续向下扫描,直到扫描到字符 'I' 时才出现错误,这时就需要重新回到最后一次识别到完整词文的位置,把该词文交给语法分析系统处理。然后从该词文后面重新开始识别新的词文。而扫描器扫描的是字符流,如果使用getc()就意为着我们只能从流中获取下一个字符,但不能让流回到原来的某个位置。
(2)输入缓冲区设计
因为扫描器采用的是最大识别的方法,而且字符的读取在词法分析阶段是频率很高,这就为我们输入缓冲区的设计提出了几个要求
- 对某个位置标记,以便可以重新回到标记的位置开始读取字符
- 提供一段空间,用于数据缓冲来提高词法分析的效率
- 从输入缓冲区获取我们已经识别到的词文的内容
(3)输入缓冲区的实现
第一步,用一个结构体来表示输入缓冲区
struct lex_file { FILE* l_file; char* l_buf; int l_buf_cap; int l_buf_size; int l_begin; int l_mark; int l_read_pos; };
在结构体lex_file里面总共有7个成员,
- l_file表示读取字符序列的文件
- l_buf用于缓存从文件中读取的字符序列,以提高词法识别的效率
- l_buf_cap用于表示整个缓冲区的长度
- l_buf_size表于从文件中读取的数据的长度
- l_begin表示扫描器在扫描当前词文时的开始位置
- l_mark用于对缓冲区的某个位置标记,以便可以重新回到该位置开始读取字符
- l_read_pos表示当前的读取位置
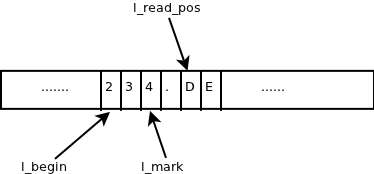
下面一张图片是扫描器在扫描字符 234.DE 时,l_begin,l_mark,l_read_pos指向的位置
第二步,有了缓冲区的数据结构,接下来就是为该数据结构制定接口的时候。
a)输入缓冲区的创建与销毁
输入缓冲区的创建有两种方法,一种从指定的文件名中创建输入缓冲区,别一是从已经打开的文件中创建缓冲区,在他们内部都调用lf_init()来对输入缓冲区进行初始化
输入缓冲区的创建代码:
void lf_init(struct lex_file* lf,FILE* file) { lf->l_file=file; lf->l_buf=(char*)malloc(LEX_FILE_DEFAULT_SIZE); lf->l_buf_cap=LEX_FILE_DEFAULT_SIZE; lf->l_buf_size=0; lf->l_begin=0; lf->l_mark=0; lf->l_read_pos=0; }; struct lex_file* lf_create(char* file_name) { FILE* file=fopen(file_name,"r"); if(file==NULL) { return NULL; } struct lex_file* lf=(struct lex_file*)malloc(sizeof(*lf)); lf_init(lf,file); return lf; } struct lex_file* lf_stream_create(FILE* file) { if(file==NULL) { BUG("NULL Pointer"); return NULL; } struct lex_file* lf=(struct lex_file*)malloc(sizeof(*lf)); lf_init(lf,file); return lf; };
输入缓冲区的销毁代码
void lf_destory(struct lex_file* lf) { free(lf->l_buf); free(lf); }
b)从文件中读取数据到缓冲区
读取数据到缓冲区的过程分
1)判断缓冲区中是否存数据,如果没有直接从文件中读取数据
2)计算缓冲区的可用空间,看是否能在读取LEX_FILE_DEFALUT_SIZE/2大小的数据,如果不能,则把缓冲区扩大成为原来的2倍,这种情况可能发生在识别一个长字符串词文时。
3)移除已使用过作费的的数据,为新读入的数据腾出空间,把有效的数据移到缓冲区的开头。
4)读取新数据到缓冲区
代码为:
int lf_load_data(struct lex_file* lf) { int readbyte; if(lf->l_buf_size==0) { readbyte=fread(lf->l_buf,sizeof(char),LEX_FILE_DEFAULT_SIZE,lf->l_file); lf->l_buf_size=readbyte; return readbyte; } int begin=lf->l_begin; int mark=lf->l_mark; int read_pos=lf->l_read_pos; int buf_cap=lf->l_buf_cap; int buf_used=read_pos-begin; int buf_free=buf_cap-buf_used; if(buf_free<LEX_FILE_DEFAULT_SIZE/2) { char* new_buf=(char*)malloc(lf->l_buf_cap*2); memcpy(new_buf,lf->l_buf+begin,buf_used); free(lf->l_buf); lf->l_buf=new_buf; lf->l_buf_cap=lf->l_buf_cap*2; } else { int i; char* buf=lf->l_buf; for(i=0;i<buf_used;i++) { buf[i]=buf[i+begin]; } } lf->l_begin=0; lf->l_mark=mark-begin; lf->l_read_pos=read_pos-begin; readbyte=fread(lf->l_buf+buf_used,sizeof(char),lf->l_buf_cap-buf_used,lf->l_file); lf->l_buf_size=buf_used+readbyte; return readbyte; }
c)从输入缓冲区中读取一个字符
先判断读取位置是否以到达缓冲区数据尾端,如果是则从文件中加载数据
代码为:
static inline char lf_next_char(struct lex_file* lf) { if(lf->l_read_pos>=lf->l_buf_size) { if(lf_load_data(lf)==0) { return EOF; } } return lf->l_buf[lf->l_read_pos++]; }
d)对当前读取位置进行标记,以便以后可以重新回到该位置进行读写
代码为:
static inline void lf_mark(struct lex_file* lf) { lf->l_mark=lf->l_read_pos; }
e)回到标记位置
代码为:
static inline void lf_back_to_mark(struct lex_file* lf) { lf->l_read_pos=lf->l_mark; } static inline void lf_reset_to_mark(struct lex_file* lf) { lf->l_begin=lf->l_mark; lf->l_read_pos=lf->l_mark; }
到现在,我们已经完成一个高效率的输入缓冲区。















 1846
1846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









