










0.前言
本文参考博客:http://www.51itong.net/eclipse-hadoop2-7-0-12448.html
搭建开发环境前保障已经搭建好hadoop的伪分布式。可参考上个博客:
http://blog.csdn.net/xummgg/article/details/51173072
1.下载安装eclipse
下载网址:http://www.eclipse.org/downloads/

因为运行在ubuntu下,所以下载linux 64为的版本(支持javaEE),下载后默认放在当前用户的Downloads。
解压,命令如下:

解压后可以在/usr/local下看到:
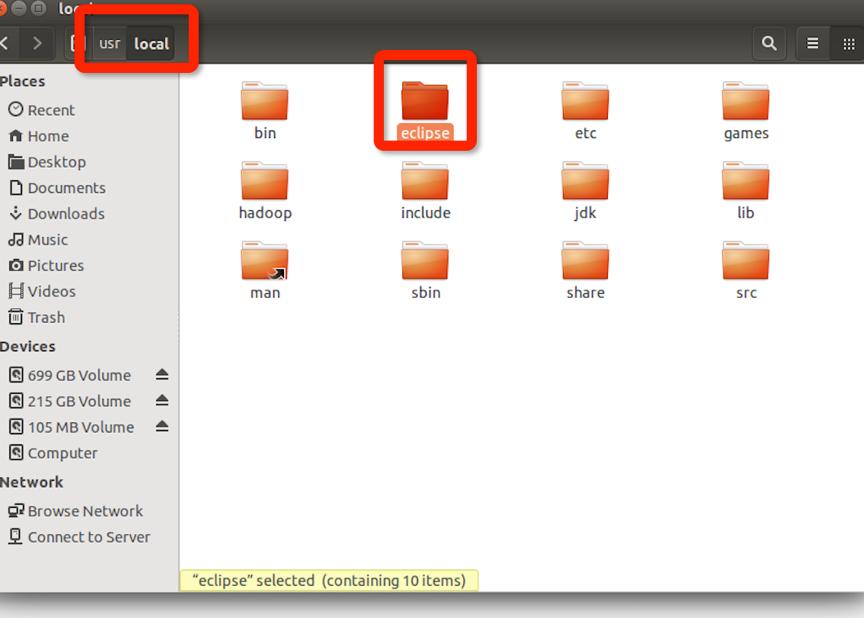
因为,要加入新jar包进入eclipse,所以把ecplise文件夹权限,设置高权限。

2.下载hadoop插件
2.6.4插件hadoop-eclipse-plugin-2.6.4.jar 下载地址:
http://download.csdn.net/download/tondayong1981/9437360
下载完成后,把插件放到eclipse/plugins目录下

用sudo要输入用户密码。
3.设置eclipse
运行eclipse

打开window->preferences
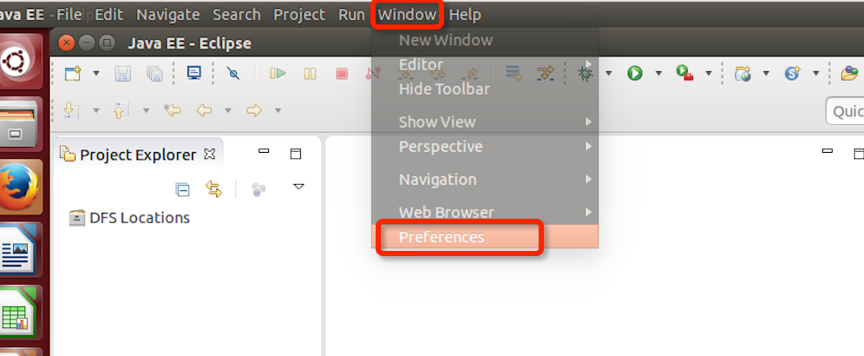
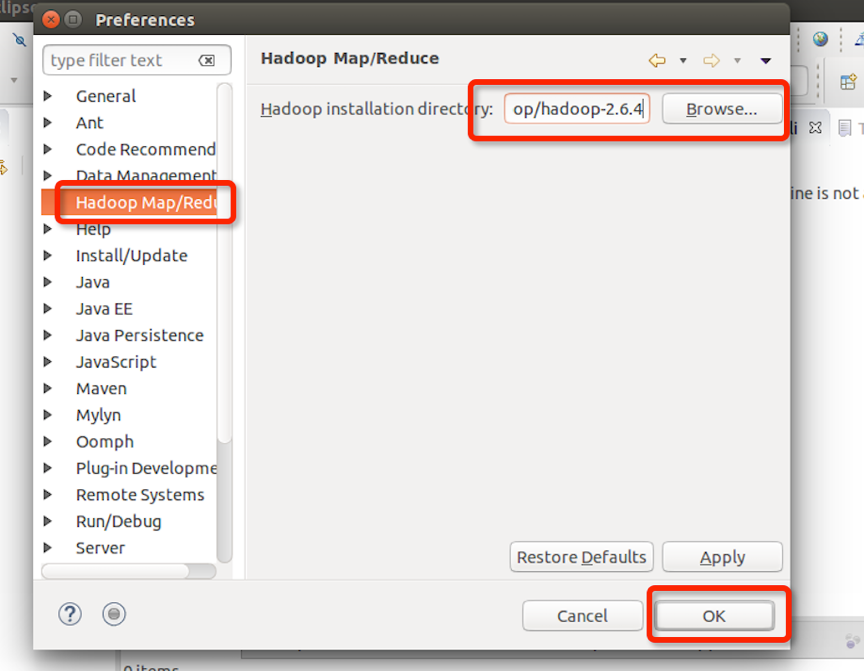
可以看到多了个Hadoop Map/Reduce,设置本机的hadoop目录,我的目录时/usr/local/hadoop/hadoop-2.6.4/ ,如下图所示:
4.配置Map/Reduce Locations
注意:配置前先在后台运行起hadoop,即开启hadoop伪分布式的dfs和yarn,参考上一个博客。
Eclipse中打开Windows—Open Perspective—Other
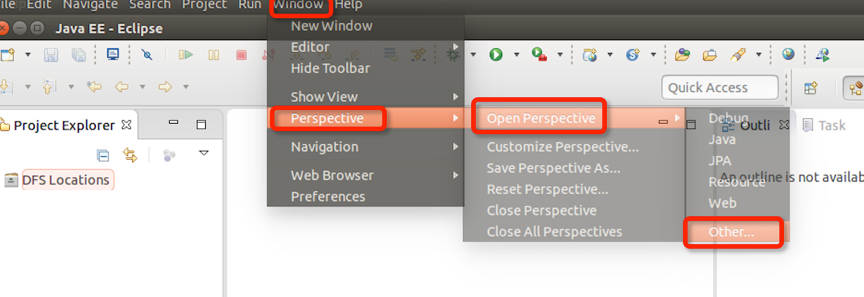
选择Map/Reduce,点击OK
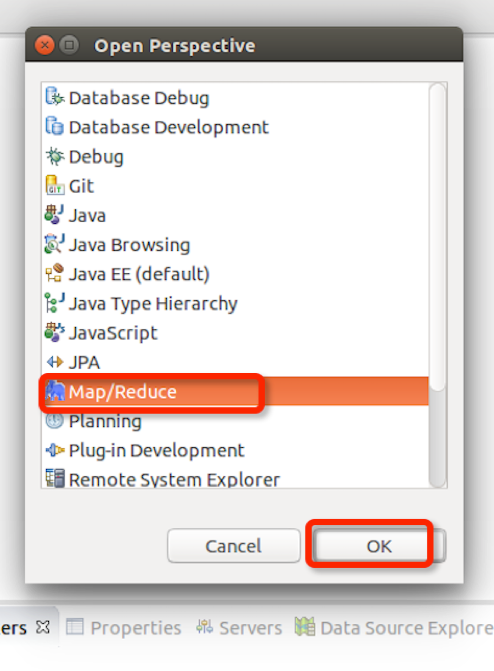
在右下方看到如下图所示

点击Map/Reduce Location选项卡,点击右边蓝色小象图标,打开Hadoop Location配置窗口。
输入Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。如下图:
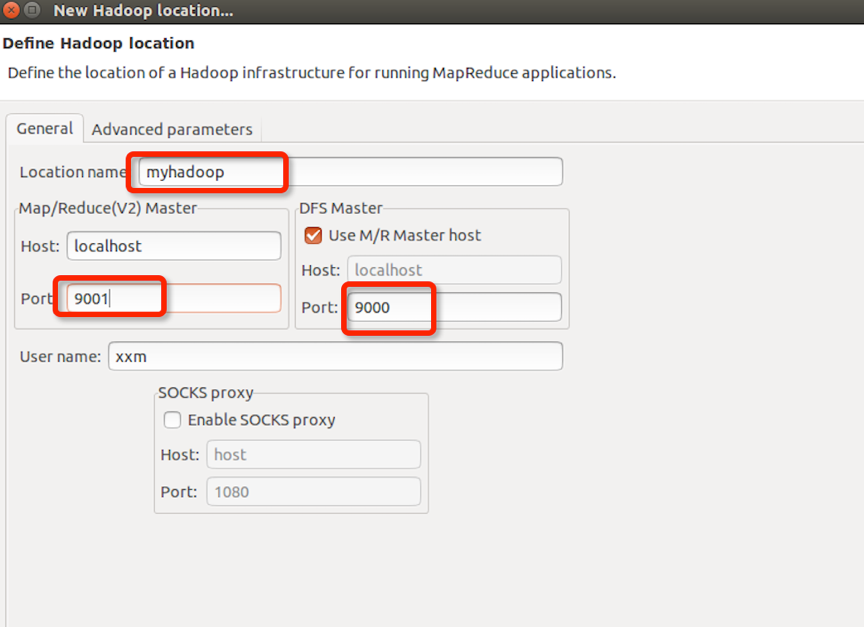
点击”Finish”按钮,关闭窗口。
点击左侧的DFSLocations—>myhadoop(上一步配置的location name),如能看到user,表示安装成功。这样eclipse就连接上了分布式文件系统,可以在eclipse里做查看,方便编程。
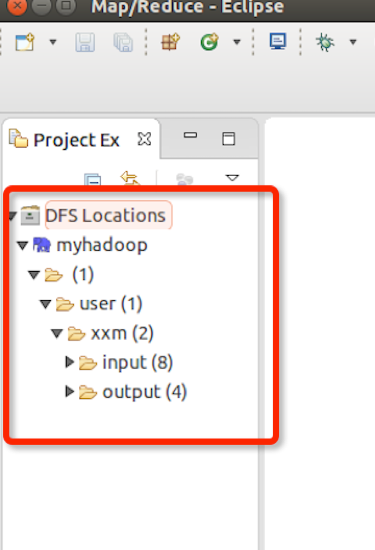
5.新建WordCount项目
点击File—>Project:
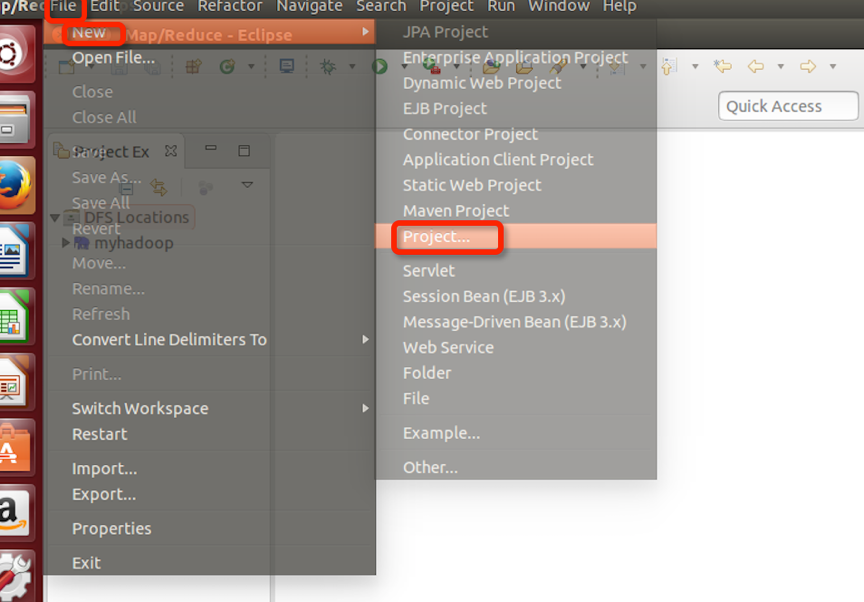
选择Map/Reduce Project,点next进入下一步:
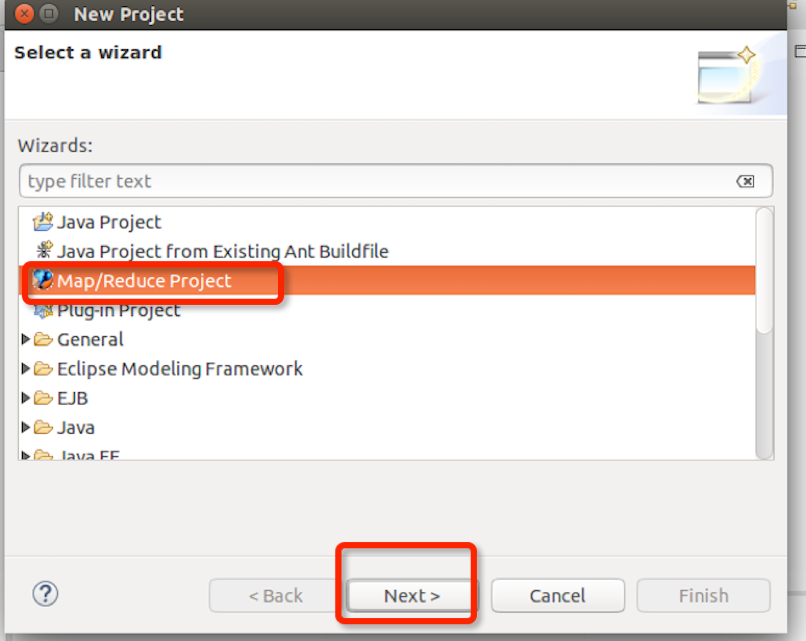
输入项目名称WordCount,点finish完成:
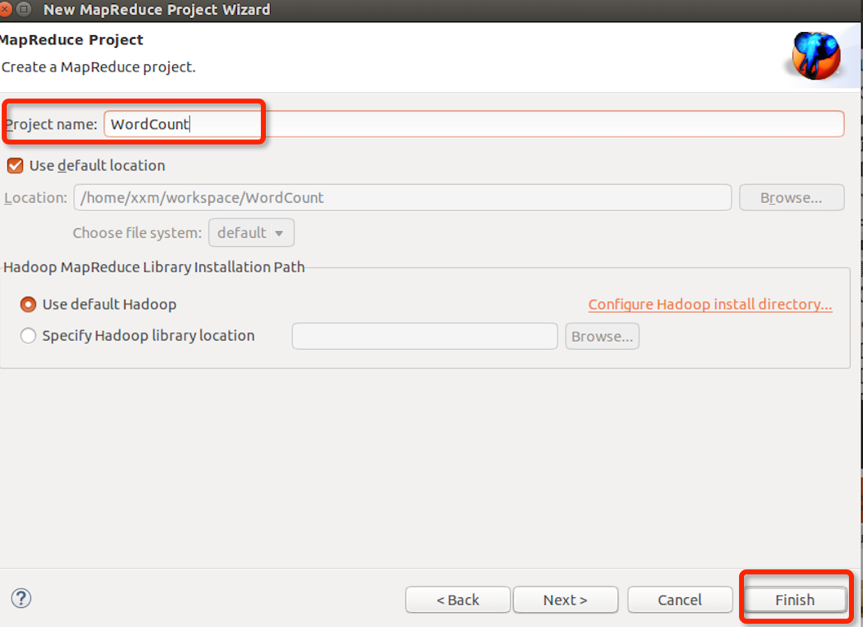
在WordCount项目里右键src新建class,包名com.xxm(请自行命明),类名为WordCount:
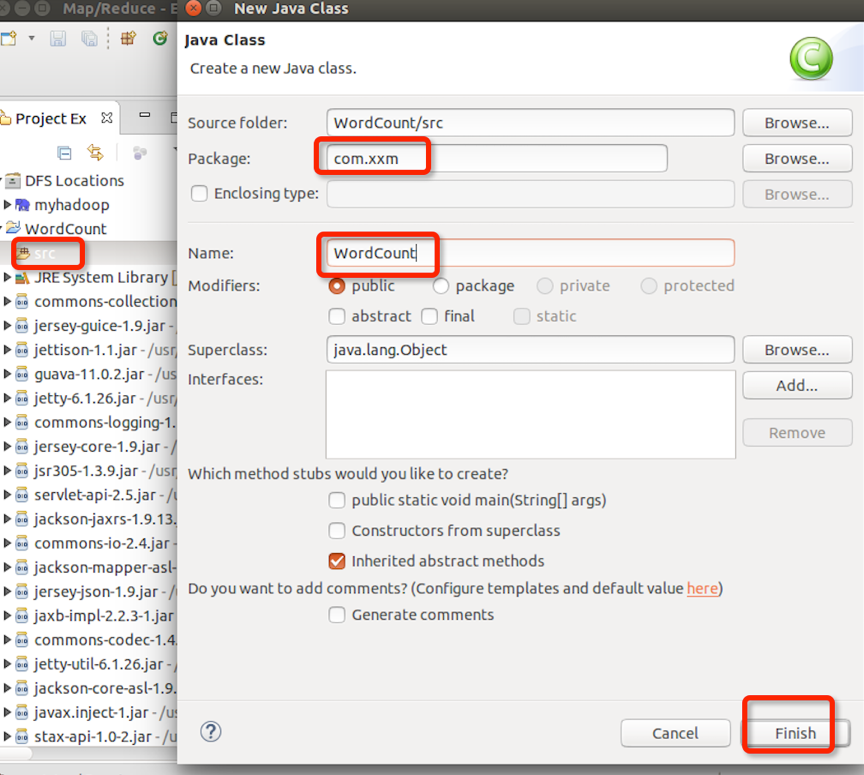
代码如下:
package com.xxm;//改为自己的包名
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 描述:WordCount explains by xxm
* @author xxm
*/
public class WordCount{
/**
* Map类:自己定义map方法
*/
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* LongWritable, IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类
* 都能够被串行化从而便于在分布式环境中进行数据交换,可以将它们分别视为long,int,String 的替代品。
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* Mapper类中的map方法:
* protected void map(KEYIN key, VALUEIN value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* Context类:收集Mapper输出的<k,v>对。
*/
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
/**
* Reduce类:自己定义reduce方法
*/
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* Reducer类中的reduce方法:
* protected void reduce(KEYIN key, Interable<VALUEIN> value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* Context类:收集Reducer输出的<k,v>对。
*/
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
/**
* main主函数
*/
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();//创建一个配置对象,用来实现所有配置
Job job = new Job(conf, "wordcount");//新建一个job,并定义名称
job.setOutputKeyClass(Text.class);//为job的输出数据设置Key类
job.setOutputValueClass(IntWritable.class);//为job输出设置value类
job.setMapperClass(Map.class); //为job设置Mapper类
job.setReducerClass(Reduce.class);//为job设置Reduce类
job.setInputFormatClass(TextInputFormat.class);//为map-reduce任务设置InputFormat实现类
job.setOutputFormatClass(TextOutputFormat.class);//为map-reduce任务设置OutputFormat实现类
FileInputFormat.addInputPath(job, new Path(args[0]));//为map-reduce job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));//为map-reduce job设置输出路径
job.waitForCompletion(true); //运行一个job,并等待其结束
}
}
- 1
在WordCount项目里右键src新建class,包名com.xxm(请自行命明),类名为WordCount:
6.运行
运行前保证分布式文件系统里的input目录下有文件,如果是HDFS刚格式化过,也请参考《搭建Hadoop伪分布式》教程,创建和上传input文件以及里面的内容。
在WordCount的代码区域,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹地址参数:
hdfs://localhost:9000/user/xxm/input hdfs://localhost:9000/user/xxm/output/wordcount3
如下图所示:

点击Run。
结果可以重连接myhadoop后进入output双击查看。也可以用HDFS命令get下来看。重连接myhadoop方法:在项目管理窗口,右键蓝色小象,选reconnect。
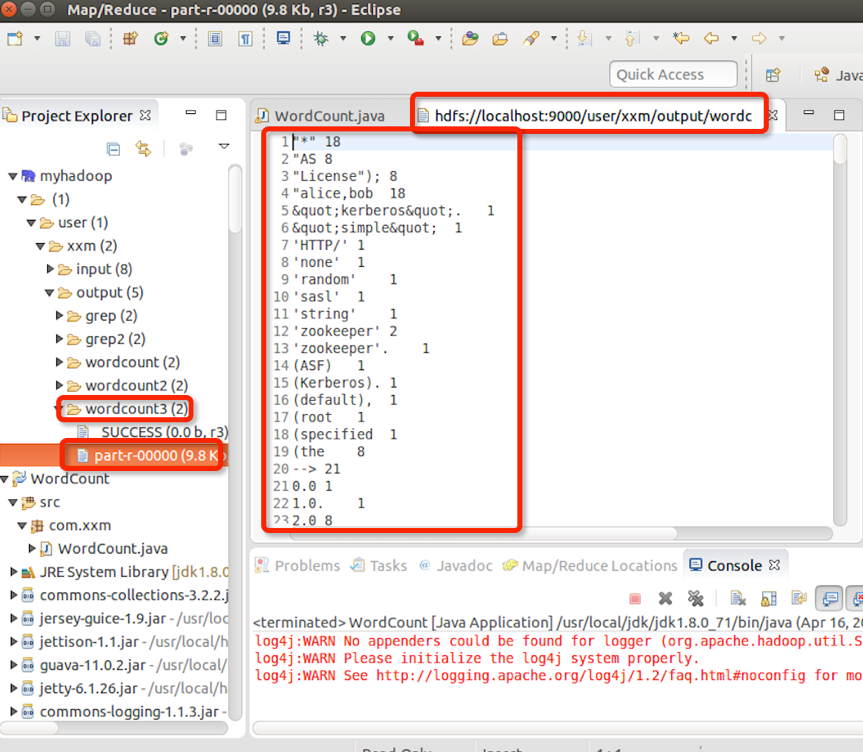
到此hadoop的eclipse开发环境搭建完成。
7.关联hadoop源码
还是在hadoop的下载网站下载源码:
http://hadoop.apache.org/releases.html
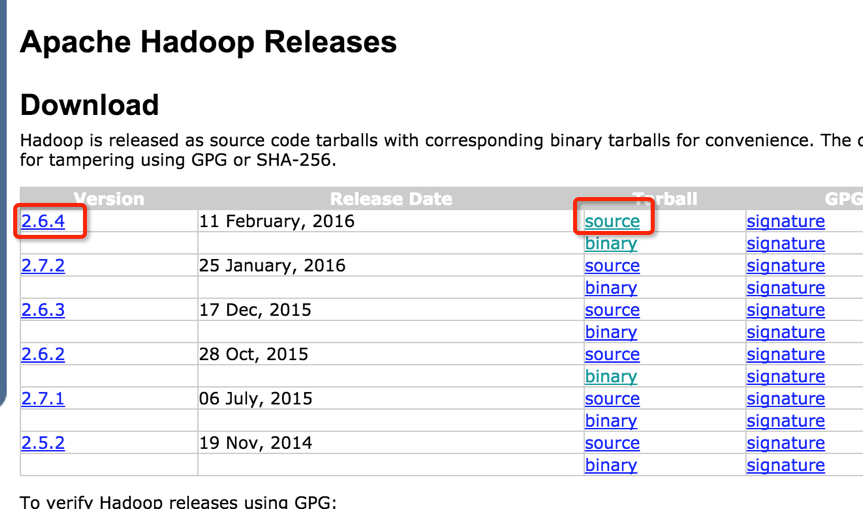
下载后解压到/usr/hadoop文件夹里:
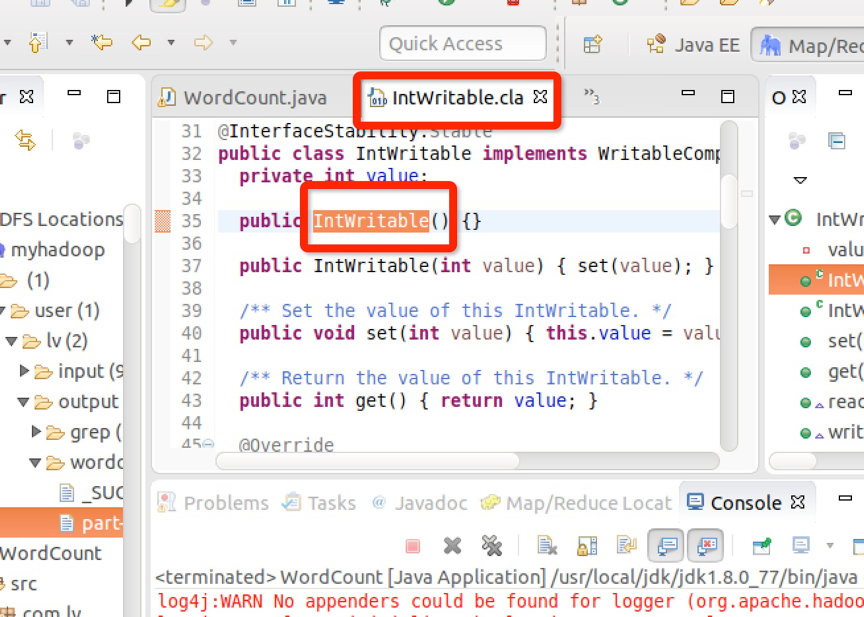
如下图所示,选择了一个hadoop的InWritable函数,右击查看源程序:
0.前言
本文参考博客:http://www.51itong.net/eclipse-hadoop2-7-0-12448.html
搭建开发环境前保障已经搭建好hadoop的伪分布式。可参考上个博客:
http://blog.csdn.net/xummgg/article/details/51173072
1.下载安装eclipse
下载网址:http://www.eclipse.org/downloads/
因为运行在ubuntu下,所以下载linux 64为的版本(支持javaEE),下载后默认放在当前用户的Downloads。
解压,命令如下:
解压后可以在/usr/local下看到:
因为,要加入新jar包进入eclipse,所以把ecplise文件夹权限,设置高权限。
2.下载hadoop插件
2.6.4插件hadoop-eclipse-plugin-2.6.4.jar 下载地址:
http://download.csdn.net/download/tondayong1981/9437360
下载完成后,把插件放到eclipse/plugins目录下
用sudo要输入用户密码。
3.设置eclipse
运行eclipse
打开window->preferences
可以看到多了个Hadoop Map/Reduce,设置本机的hadoop目录,我的目录时/usr/local/hadoop/hadoop-2.6.4/ ,如下图所示:
4.配置Map/Reduce Locations
注意:配置前先在后台运行起hadoop,即开启hadoop伪分布式的dfs和yarn,参考上一个博客。
Eclipse中打开Windows—Open Perspective—Other
选择Map/Reduce,点击OK
在右下方看到如下图所示
点击Map/Reduce Location选项卡,点击右边蓝色小象图标,打开Hadoop Location配置窗口。
输入Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。如下图:
点击”Finish”按钮,关闭窗口。
点击左侧的DFSLocations—>myhadoop(上一步配置的location name),如能看到user,表示安装成功。这样eclipse就连接上了分布式文件系统,可以在eclipse里做查看,方便编程。
5.新建WordCount项目
点击File—>Project:
选择Map/Reduce Project,点next进入下一步:
输入项目名称WordCount,点finish完成:
在WordCount项目里右键src新建class,包名com.xxm(请自行命明),类名为WordCount:
代码如下:
package com.xxm;//改为自己的包名
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 描述:WordCount explains by xxm
* @author xxm
*/
public class WordCount{
/**
* Map类:自己定义map方法
*/
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* LongWritable, IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类
* 都能够被串行化从而便于在分布式环境中进行数据交换,可以将它们分别视为long,int,String 的替代品。
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* Mapper类中的map方法:
* protected void map(KEYIN key, VALUEIN value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* Context类:收集Mapper输出的<k,v>对。
*/
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
/**
* Reduce类:自己定义reduce方法
*/
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* Reducer类中的reduce方法:
* protected void reduce(KEYIN key, Interable<VALUEIN> value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* Context类:收集Reducer输出的<k,v>对。
*/
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
/**
* main主函数
*/
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();//创建一个配置对象,用来实现所有配置
Job job = new Job(conf, "wordcount");//新建一个job,并定义名称
job.setOutputKeyClass(Text.class);//为job的输出数据设置Key类
job.setOutputValueClass(IntWritable.class);//为job输出设置value类
job.setMapperClass(Map.class); //为job设置Mapper类
job.setReducerClass(Reduce.class);//为job设置Reduce类
job.setInputFormatClass(TextInputFormat.class);//为map-reduce任务设置InputFormat实现类
job.setOutputFormatClass(TextOutputFormat.class);//为map-reduce任务设置OutputFormat实现类
FileInputFormat.addInputPath(job, new Path(args[0]));//为map-reduce job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));//为map-reduce job设置输出路径
job.waitForCompletion(true); //运行一个job,并等待其结束
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
6.运行
运行前保证分布式文件系统里的input目录下有文件,如果是HDFS刚格式化过,也请参考《搭建Hadoop伪分布式》教程,创建和上传input文件以及里面的内容。
在WordCount的代码区域,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹地址参数:
hdfs://localhost:9000/user/xxm/input hdfs://localhost:9000/user/xxm/output/wordcount3
如下图所示:
点击Run。
结果可以重连接myhadoop后进入output双击查看。也可以用HDFS命令get下来看。重连接myhadoop方法:在项目管理窗口,右键蓝色小象,选reconnect。
到此hadoop的eclipse开发环境搭建完成。
7.关联hadoop源码
还是在hadoop的下载网站下载源码:
http://hadoop.apache.org/releases.html
下载后解压到/usr/hadoop文件夹里:
如下图所示,选择了一个hadoop的InWritable函数,右击查看源程序:
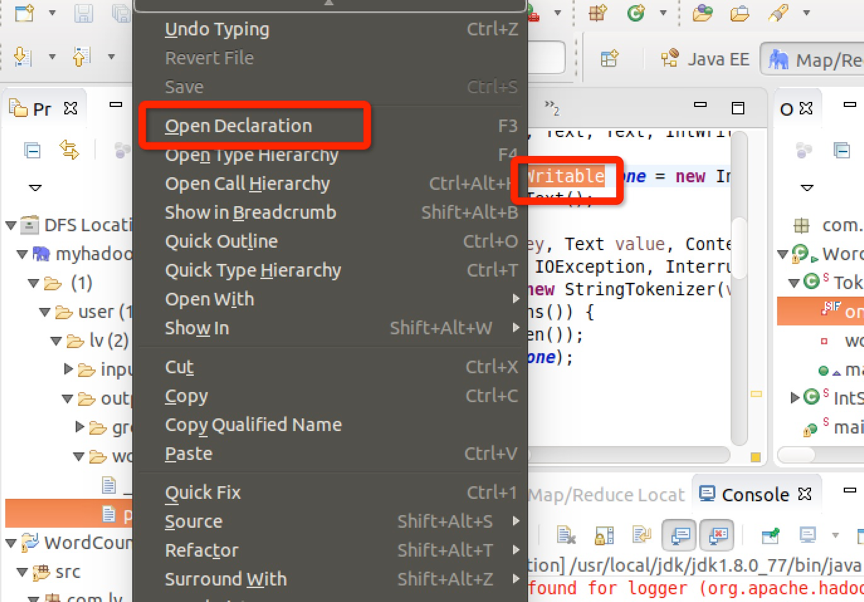
结果源程序不能找到,所以要做源程序的关联。点击Attach Source:
将hadoop-2.6.4-src源码关联,点击ok:
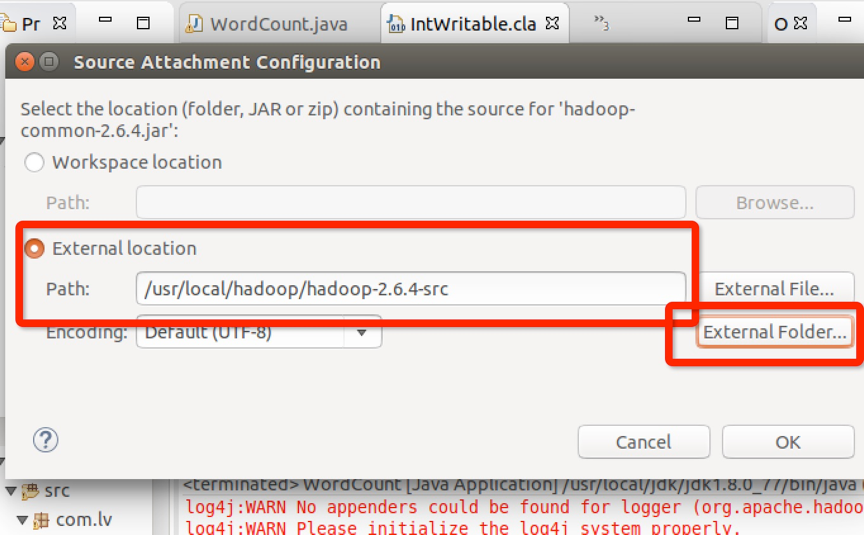
跳转后可以看到InWritable函数已经可以看到源码了:
到此源码关联成功。
XianMing
结果源程序不能找到,所以要做源程序的关联。点击Attach Source:
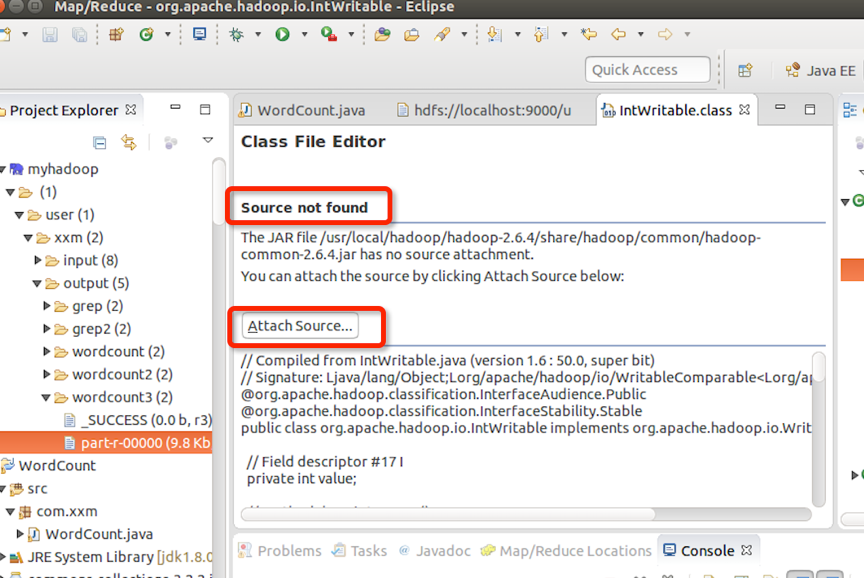
将hadoop-2.6.4-src源码关联,点击ok:
跳转后可以看到InWritable函数已经可以看到源码了:
到此源码关联成功。
XianMing















 6203
6203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









