







一、排序算法
插入排序
#include "stdafx.h"
/*
比较:
每个元素插入到已排序的数组中,每次从数组中拿一个要插入的元素,从数组位置0开始到此元素位置中找到此数据的插入位置,腾出此插入位置
移动:
腾出插入位置时需要移动,移动次数为此元素位置到插入位置之间的距离。
临时变量:
要比较元素位置的整型临时变量
*/
void InsertSortE(int a[],int nInsertVal,int n);
void InsertSort(int src[],int n)
{
for (int i = 0; i < n; ++i)// 将每个数插入到已排序数组中
{
InsertSortE(src,src[i],i);
}
}
void InsertSortE(int a[],int nInsertVal,int n)// 参数n指数组位置坐标最大值,即从0开始
{
int i;
for (i = 0; i < n; ++i)// 从0到n中,找某一元素的插入位置
{
if (nInsertVal < a[i])// 找到插入数组位置
{
for (int j = n; j > i; --j)// 腾出插入位置,腾出数组位置n到i
{
a[j] = a[j-1];
}
break;// 必不可少,找到断点循环应停止
}
}
a[i] = nInsertVal;
}
void PrintArray(int *p,int n)
{
for (int i = 0; i < n; ++i)
{
printf("%d\t",*(p+i));
}
printf("\n");
}
int _tmain(int argc, _TCHAR* argv[])
{
int src[] = {3,1,9,4,56,23,98,0};
printf("转换前:\n");
PrintArray(src,8);
InsertSort(src,8);
printf("转换后:\n");
PrintArray(src,8);
getch();
return 0;
}- void bubbleSort(T* a,int n)
- {
- for(int i = 0;i < n - 1;i++)
- {
- for(int j = 0;j < n - i - 1;j++)
- {
- if(a[j] > a[j + 1])
- {
- T temp = a[j];
- a[j] = a[j + 1];
- a[j + 1] = temp;
- }
- }
- }
- }
选择排序的不稳定性分析:
选择排序每次找剩余未排序元组中的最小值,并和前面的元素交换位置,这样的元素交换破坏了稳定性。例如: 5 8 5 2 9 ,第一次找到的最小元素 2 ,与第一个 5 交换位置,则第一个 5 和中间的 5 顺序就变了,所以不稳定了。
总结:选择排序是原地不稳定排序,平均时间复杂度 O(n2)
- 代码如下:
- //文件selectSort.h
- //选择排序
- template <class T>
- void selectSort(T* a,int n)
- {
- for(int i = 0;i < n - 1;i++)
- {
- //记下最小值(最小值初始为a[i])
- T min = a[i];
- //记下下标
- int k = i;
- for(int j = i + 1;j < n;j++)
- {
- if(a[j] < min)
- {
- min = a[j];
- k = j;
- }
- }
- //交换(当最小值不是第一个的时候)
- if(k != i)
- {
- T temp = a[i];
- a[i] = a[k];
- a[k] = temp;
- }
- }
- }
归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
归并排序是稳定的排序.即相等的元素的顺序不会改变.
int is1[n],is2[n];// 原数组is1,临时空间数组is2,n为个人指定长度
void mergeSort(int a,int b)// 下标,例如数组int is[5],全部排序的调用为mergeSort(0,4)
{
if(a<b)
{
int mid=(a+b)/2;
mergeSort(a,mid);
mergeSort(mid+1,b);
merge(a,mid,b);
}
}1. void merge(int low,int mid,int high)
2. {
3. int i=low,j=mid+1,k=low;
4. while(i<=mid&&j<=high)
5. if(is1[i]<=is1[j]) // 此处为排序顺序的关键,用小于表示从小到大排序
6. is2[k++]=is1[i++];
7. else
8. is2[k++]=is1[j++];
9. while(i<=mid)
10. is2[k++]=is1[i++];
11. while(j<=high)
12. is2[k++]=is1[j++];
13. for(i=low;i<=high;i++)// 写回原数组
14. is1[i]=is2[i];
15. }

示例
|
A[0]
|
A[1]
|
A[2]
|
A[3]
|
A[4]
|
A[5]
|
A[6]
|
|
49
|
38
|
65
|
97
|
76
|
13
|
27
|
intpartitions(int a[],int low,int high)
{
int pivotkey=a[low];
//a[0]=a[low];
while(low<high)
{
while(low<high && a[high]>=pivotkey)
--high;
a[low]=a[high];
while(low<high && a[low]<=pivotkey)
++low;
a[high]=a[low];
}
//a[low]=a[0];
a[low]=pivotkey;
return low;
}
void qsort(int a[],int low,int high)
{
int pivottag;
if(low<high)
{ //递归调用
pivottag=partitions(a,low,high);
qsort(a,low,pivottag-1);
qsort(a,pivottag+1,high);
}
}
void quicksort(int a[],int n)
{
qsort(a,0,n);
}
//简单示例
#include <stdio.h>
//#include <math.h>
#include "myfunc.h" //存放于个人函数库中
main()
{
int i,a[11]={0,11,12,5,6,13,8,9,14,7,10};
for(i=0;i<11;printf("%3d",a[i]),++i);
printf("\n");
quicksort(a,10);
for(i=0;i<11;printf("%3d",a[i]),++i);
printf("\n");
}
堆排序
堆排序 转自:http://www.cnblogs.com/dolphin0520/archive/2011/10/06/2199741.html
堆排序是利用堆的性质进行的一种选择排序。下面先讨论一下堆。
1.堆
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2]
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
2.堆排序的思想
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
操作过程如下:
1)初始化堆:将R[1..n]构造为堆;
2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。
因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
下面举例说明:
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到
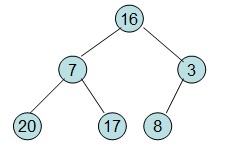


 20和16交换后导致16不满足堆的性质,因此需重新调整
20和16交换后导致16不满足堆的性质,因此需重新调整
 这样就得到了初始堆。
这样就得到了初始堆。
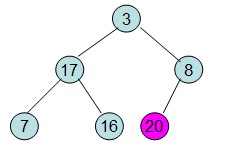 此时3位于堆顶不满堆的性质,则需调整继续调整
此时3位于堆顶不满堆的性质,则需调整继续调整










/*堆排序(大顶堆) 2011.9.14*/ #include <iostream> #include<algorithm> using namespace std; void HeapAdjust(int *a,int i,int size) //调整堆 { int lchild=2*i; //i的左孩子节点序号 int rchild=2*i+1; //i的右孩子节点序号 int max=i; //临时变量 if(i<=size/2) //如果i是叶节点就不用进行调整 { if(lchild<=size&&a[lchild]>a[max]) { max=lchild; } if(rchild<=size&&a[rchild]>a[max]) { max=rchild; } if(max!=i) { swap(a[i],a[max]); HeapAdjust(a,max,size); //避免调整之后以max为父节点的子树不是堆 } } } void BuildHeap(int *a,int size) //建立堆 { int i; for(i=size/2;i>=1;i--) //非叶节点最大序号值为size/2 { HeapAdjust(a,i,size); } } void HeapSort(int *a,int size) //堆排序 { int i; BuildHeap(a,size); for(i=size;i>=1;i--) { //cout<<a[1]<<" "; swap(a[1],a[i]); //交换堆顶和最后一个元素,即每次将剩余元素中的最大者放到最后面 //BuildHeap(a,i-1); //将余下元素重新建立为大顶堆 HeapAdjust(a,1,i-1); //重新调整堆顶节点成为大顶堆 } } int main(int argc, char *argv[]) { //int a[]={0,16,20,3,11,17,8}; int a[100]; int size; while(scanf("%d",&size)==1&&size>0) { int i; for(i=1;i<=size;i++) cin>>a[i]; HeapSort(a,size); for(i=1;i<=size;i++) cout<<a[i]<<""; cout<<endl; } return 0; }
希尔排序
缩小增量法
#include<iostream>
using namespace std;
void HealSort(int *a,int length)
{
int b[1000]={0};
int k=length/2;
int i,j,temp;
while(k>0)
{
for(i=0;i<length-k;i++)
{
j=k+i;
while(j>=k) //小组内排序,以j递减的k的方式,从小组头开始排序,后面再添加组员进来,依次向前比较,插入到合适的位置。
{
if(a[j]<a[j-k])
{
temp=a[j];
a[j]=a[j-k];
a[j-k]=temp;
j=j-k;
}
else
break;
}
}
k=k/2;
}
}
int main()
{
int a[10]={15,6,28,89,61,92,43,24,47,510};
HealSort(a,10);
for(int i=0;i<10;i++)
{
cout<<a[i]<<" ";
}
cout<<endl;
system("pause");
return 0;
}算法分析
优劣
时间性能
稳定性
希尔分析
/********************************************************************************************************/
逆序:
字符串逆序:http://www.cnblogs.com/graphics/archive/2011/03/09/1977717.html
原地逆序
英文叫做in-place reverse。这是最常考的,原地逆序意味着不允额外分配空间,主要有以下几种方法,思想都差不多,就是将字符串两边的字符逐个交换,如下图。给定字符串"abcdef",逆序的过程分别是交换字符a和f,交换字符b和e,交换字符c和d。
 一 设置两个指针,分别指向字符串的头部和尾部,然后交换两个指针所指的字符,并向中间移动指针直到交叉。
char* Reverse(char* s)
{
// p指向字符串头部
char* p = s ;
// q指向字符串尾部
char* q = s ;
while( *q )
++q ;
q -- ;
// 交换并移动指针,直到p和q交叉
while(q > p)
{
char t = *p ;
*p++ = *q ;
*q-- = t ;
}
return s ;
}
一 设置两个指针,分别指向字符串的头部和尾部,然后交换两个指针所指的字符,并向中间移动指针直到交叉。
char* Reverse(char* s)
{
// p指向字符串头部
char* p = s ;
// q指向字符串尾部
char* q = s ;
while( *q )
++q ;
q -- ;
// 交换并移动指针,直到p和q交叉
while(q > p)
{
char t = *p ;
*p++ = *q ;
*q-- = t ;
}
return s ;
}
二 用递归的方式,需要给定逆序的区间,调用方法:Reverse(s, 0, strlen(s)) ;
// 对字符串s在区间left和right之间进行逆序,递归法
void Reverse( char* s, int left, int right )
{
if(left >= right)
return s ;
char t = s[left] ;
s[left] = s[right] ;
s[right] = t ;
Reverse(s, left + 1, right - 1) ;
}三 非递归法,同样指定逆序区间,和方法一没有本质区别,一个使用指针,一个使用下标。
// 对字符串str在区间left和right之间进行逆序
char* Reverse( char* s, int left, int right )
{
while( left < right )
{
char t = s[left] ;
s[left++] = s[right] ;
s[right--] = t ;
}
return s ;
}不允许临时变量的原地逆序
使用异或操作
// 使用异或操作对字符串s进行逆序
char* Reverse(char* s)
{
char* r = s ;
//令p指向字符串最后一个字符
char* p = s;
while (*(p + 1) != '\0')
++p ;
// 使用异或操作进行交换
while (p > s)
{
*p = *p ^ *s ;
*s = *p ^ *s ;
*p = *p-- ^ *s++ ;
}
return r ;
}
按单词逆序
给定一个字符串,按单词将该字符串逆序,比如给定"This is a sentence",则输出是"sentence a is This",为了简化问题,字符串中不包含标点符号。
分两步
1 先按单词逆序得到"sihT si a ecnetnes"
2 再整个句子逆序得到"sentence a is This"
对于步骤一,关键是如何确定单词,这里以空格为单词的分界。当找到一个单词后,就可以使用上面讲过的方法将这个单词进行逆序,当所有的单词都逆序以后,将整个句子看做一个整体(即一个大的包含空格的单词)再逆序一次即可,如下图所示,第一行是原始字符换,第二行是按单词逆序后的字符串,最后一行是按整个句子逆序后的字符串。

代码
// 对指针p和q之间的所有字符逆序
void ReverseWord(char* p, char* q)
{
while(p < q)
{
char t = *p ;
*p++ = *q ;
*q-- = t ;
}
}
// 将句子按单词逆序
char* ReverseSentence(char* s)
{
// 这两个指针用来确定一个单词的首尾边界
char* p = s ; // 指向单词的首字符
char* q = s ; // 指向空格或者 '\0'
while(*q != '\0')
{
if (*q == '')
{
ReverseWord(p, q - 1) ;
q++ ; // 指向下一个单词首字符
p = q ;
}
else
q++ ;
}
ReverseWord(p, q - 1) ; // 对最后一个单词逆序
ReverseWord(s, q - 1) ; // 对整个句子逆序
return s ;
}逆序打印
还有一类题目是要求逆序输出,而不要求真正的逆序存储。这题很简单,有下面几种方法,有的方法效率不高,这里仅是提供一个思路而已。
先求出字符串长度,然后反向遍历即可。
{
int len = strlen(s) ;
for ( int i = len - 1 ; i >= 0 ; -- i)
cout << s[i];
}
如果不想求字符串的长度,可以先遍历到末尾,然后在遍历回来,这要借助字符串的结束符'\0
void ReversePrint(const char* s) { const char* p = s ; while (*p) *p++ ; --p ; //while结束时,p指向'\0',这里让p指向最后一个字符 while (p >= s) { cout <<*p ; --p ; } }
对于上面第二种方法,也可以使用递归的方式完成。
{
if ( * (s + 1 ) != ' \0 ' )
ReversePrint(s + 1 ) ;
cout << * s ;
}
查找子串
/*参考代码*/
/* Programming Exercise 11-7 */
#include <stdio.h>
#define LEN 20
char * string_in(const char * s1, const char * s2);
int main(void)
{
char orig[LEN] = "transportation";
char * find;
puts(orig);
find = string_in(orig, "port");
if (find)
puts(find);
else
puts("Not found");
find = string_in(orig, "part");
if (find)
puts(find);
else
puts("Not found");
getch();
return 0;
}
#include <string.h> /*此函数中有些地方不明,请加以指点,谢谢!*/
char * string_in(const char * s1, const char * s2)
{
int l2 = strlen(s2); /* 这部分是何用意?成立吗?*/
int tries; /* maximum number of comparisons */
int nomatch = 1; /* set to 0 if match is found */
tries = strlen(s1) + 1 - l2; /*此部分有何作用?*/
if (tries > 0)
while (( nomatch = strncmp(s1, s2, l2)) && tries--)
s1++;
if (nomatch)
return NULL;
else
return (char *) s1; /* cast const away */
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









