









上一篇solr主要介绍了如何在控制台和命令行创建集合(Core/Collections),今天继续solr
Solr文档学习–Using the Solr Administration User Interface
首先启动solr
启动之后就可以看到上次创建的两个集合了(这次主要的操作mycollections)
在集合下面有很多的面板
我主要介绍一下Analysis,Documents和Query的使用,
Analysis
The Analysis screen lets you inspect how data will be handled according to the field, field type and dynamic field configurations found in your Schema. You can analyze how content would be handled during indexing or during query processing and view the results separately or at the same time. Ideally, you would want content to be handled consistently, and this screen allows you to validate the settings in the field type or field analysis chains.
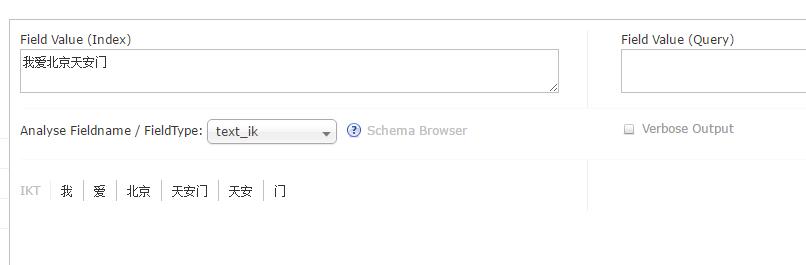
这个是用来分词的。
默认没有中文分词
配置中文分词
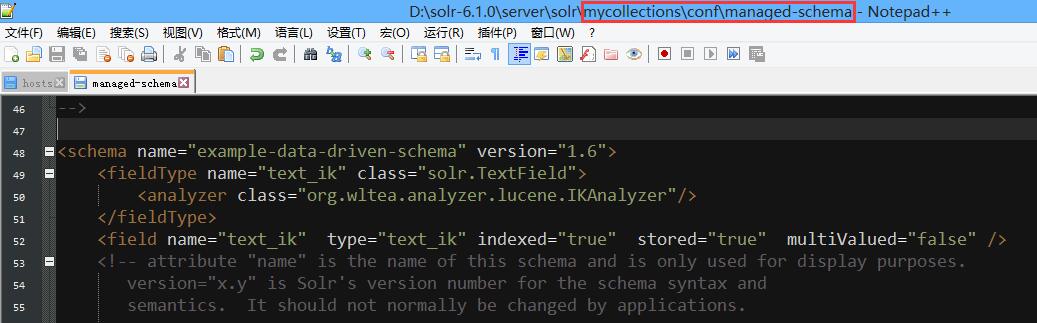
配置好并reload
Documents
The Documents screen provides a simple form allowing you to execute various Solr indexing commands in a variety of formats directly from the browser.
这个视图下我们可以建立索引
我们先在Query里查询一下
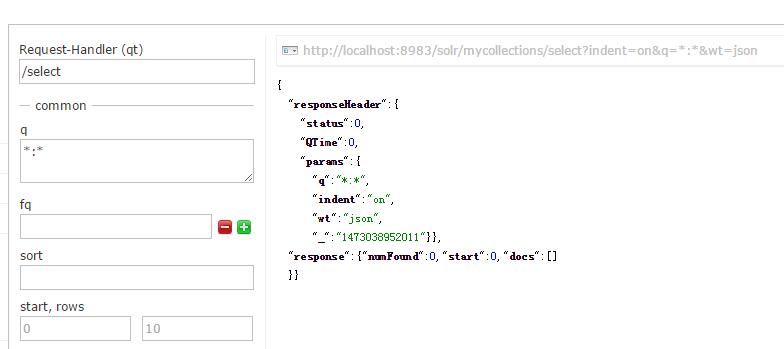
发现现在是没有任何数据的。我们开始建立索引
建立一个如下的索引
{id:123456,info:"我爱北京天安门"}

返回结果
再去Query查询一下
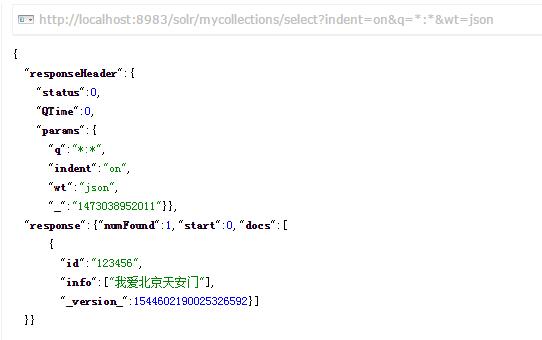
已经可以查到刚才建立的索引了
Query
You can use the screen to submit a search query to a Solr collection and analyze the results. In the example in the creenshot, a query has been submitted, and the screen shows the query results sent to the browser as JSON.
主要就是查询,可以设置很多参数。
各个参数的含义
| 字段 | 描述 |
|---|---|
| Request-handler (qt) | Specifies the query handler for the request. If a query handler is not specified, Solr processes the response with the standard query handler. |
| q | The query event. See for an explanation of this parameter. |
| fq | The filter queries. See for more information on this parameter. |
| sort | Sorts the response to a query in either ascending or descending order based on the response’s score or another specified characteristic. |
| start, rows | start is the offset into the query result starting at which documents should be returned. The default value is 0, meaning that the query should return results starting with the first document that matches. This field accepts the same syntax as the start query parameter, which is described in . is the number of rows to return. |
| fl | Defines the fields to return for each document. You can explicitly list the stored fields, functi , and you want to have returned by separating them with either a ons doc transformers comma or a space. |
| wt | Specifies the Response Writer to be used to format the query response. Defaults to XML if not specified. |
| indent | Click this button to request that the Response Writer use indentation to make the responses more readable. |
| debugQuery | Click this button to augment the query response with debugging information, including “explain info” for each document returned. This debugging information is intended to be intelligible to the administrator or programmer. |
| dismax | Click this button to enable the Dismax query parser. See for The DisMax Query Parser further information. |
| edismax | Click this button to enable the Extended query parser. See The Extended DisMax Query for further information. |
| hl | Click this button to enable highlighting in the query response. See for more Highlighting information. |
| facet | Enables faceting, the arrangement of search results into categories based on indexed terms. See for more information. |
| spatial | Click to enable using location data for use in spatial or geospatial searches. See Spatial for more information. |
| spellcheck | Click this button to enable the Spellchecker, which provides inline query suggestions based on other, similar, terms. See for more information. |
具体的含义就不多解释了。
后面再写通过java客户端实现对solr的增删改查。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









