









首先启动solr
solr.cmd start
SolrClient
主要通过SolrClient来连接到Solr服务器
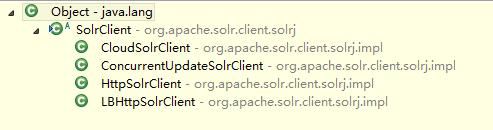
SolrClient有4个实现类
CloudSolrClient
SolrJ client class to communicate with SolrCloud. Instances of this class communicate with Zookeeper to discover Solr endpoints for SolrCloud collections, and then use the {@link BHttpSolrClient} to issue requests.
用来连接到SolrCloud的
ConcurrentUpdateSolrClient
ConcurrentUpdateSolrClient buffers all added documents and writes them into open HTTP connections. This class is thread safe. Params from {@link UpdateRequest} are converted to http request parameters. When params change between UpdateRequests a new HTTP request is started.
线程安全的SolrClient
LBHttpSolrClient
LBHttpSolrClient or “LoadBalanced HttpSolrClient” is a load balancing wrapper around {@link HttpSolrClient}. This is useful when you have multiple Solr servers and the requests need to be Load Balanced among them.
负载均衡的HttpSolrClient
HttpSolrClient
A SolrClient implementation that talks directly to a Solr server via HTTP
通过HTTP直接连接到Solr服务器
SolrClient
javaDoc解释
There are two ways to use an HttpSolrClient:
1) Pass a URL to the constructor that points directly at a particular core
SolrClient client = new HttpSolrClient("http://my-solr-server:8983/solr/core1");
QueryResponse resp = client.query(new SolrQuery(":"));
In this case, you can query the given core directly, but you cannot query any other cores or issue CoreAdmin requests with this client.
2) Pass the base URL of the node to the constructor
SolrClient client = new HttpSolrClient("http://my-solr-server:8983/solr");
QueryResponse resp = client.query("core1", new SolrQuery(":"));
In this case, you must pass the name of the required core for all queries and updates, but you may use the same client for all cores, and for CoreAdmin requests.

正确的实现方式
在查询中指出collection(我的collection为mycollections)
String url = "http://localhost:8983/solr";
SolrClient client = new HttpSolrClient.Builder(url).build();
QueryResponse resp = client.query("mycollections", new SolrQuery("*:*"));在连接url中指出collection
String url = "http://localhost:8983/solr/mycollections";
SolrClient client = new HttpSolrClient.Builder(url).build();
QueryResponse resp = client.query(new SolrQuery("*:*"));管理员客户端的查询结果

看一下程序的运行结果
{
responseHeader = {
status = 0,
QTime = 0,
params = {
q = * : * ,
wt = javabin,
version = 2
}
},
response = {
numFound = 1,
start = 0,
docs = [SolrDocument {
id = 123456,
info = [我爱北京天安门],
_version_ = 1544602190025326592
}
]
}
}顺利连接到服务器
添加/更新
定义一个文章实体,包括id,标题,时间,作者,内容
import java.util.Arrays;
import java.util.Date;
import org.apache.solr.client.solrj.beans.Field;
import org.springframework.data.annotation.Id;
public class Article {
@Id
@Field
private String id;
@Field
private String[] title;
@Field
private Date[] time;
@Field
private String[] author;
@Field
private String[] info;
// 省略getter和setter
}初始化
private static SolrClient client;
private static String url;
static {
url = "http://localhost:8983/solr/mycollections";
client = new HttpSolrClient.Builder(url).build();
}添加/更新方法
/**
* 保存或者更新solr数据
*
* @param res
*/
public static boolean saveSolrResource(Article article) {
DocumentObjectBinder binder = new DocumentObjectBinder();
SolrInputDocument doc = binder.toSolrInputDocument(article);
try {
client.add(doc);
System.out.println(client.commit());
} catch (Exception e) {
e.printStackTrace();
return false;
}
return true;
}测试
Article article = new Article();
article.setId("123456");
article.setTitle(new String[] {"测试solr"});
article.setAuthor(new String[]{"程高伟"});
article.setTime(new Date[]{new Date()});
article.setInfo(new String[]{"The Files screen lets you browse & view the various configuration files"});
saveSolrResource(article);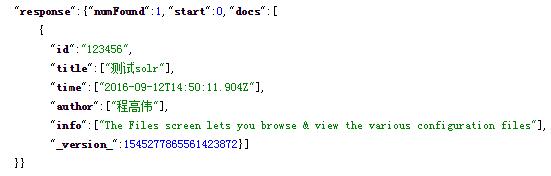
如果id相同则是修改操作
删除
/**
* 删除solr 数据
*
* @param id
*/
public static boolean removeSolrData(String id) {
try {
client.deleteById(id);
client.commit();
} catch (Exception e) {
e.printStackTrace();
return false;
}
return true;
}根据id删除
查询
SolrQuery query = new SolrQuery();
query.setQuery("程高伟");
QueryResponse rsp = client.query(query);
List<Article> articleList = rsp.getBeans(Article.class);
System.out.println(articleList);结果
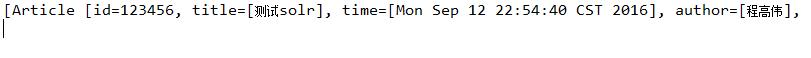
Solr还有很多高级功能。
目前存在的问题是只能是字符串,而且是字符串数组。
还有自定义schema好好研究一下。
参考文献
http://wiki.apache.org/solr/Solrj#Reading_Data_from_Solr
http://101.110.118.72/archive.apache.org/dist/lucene/solr/ref-guide/apache-solr-ref-guide-6.1.pdf














 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









