







汇总博客:MIT6.824 2022
lab地址
lab4内容比较多,建议先读几遍实验介绍,以确保完全理解实验内容
The main challenge in this lab will be handling reconfiguration – changes in the assignment of shards to groups. Within a single replica group, all group members must agree on when a reconfiguration occurs relative to client Put/Append/Get requests. For example, a Put may arrive at about the same time as a reconfiguration that causes the replica group to stop being responsible for the shard holding the Put’s key. All replicas in the group must agree on whether the Put occurred before or after the reconfiguration. If before, the Put should take effect and the new owner of the shard will see its effect; if after, the Put won’t take effect and client must re-try at the new owner. The recommended approach is to have each replica group use Raft to log not just the sequence of Puts, Appends, and Gets but also the sequence of reconfigurations. You will need to ensure that at most one replica group is serving requests for each shard at any one time.
4A
4A部分的实现比较简单,把lab3的代码拿来改改就可以了,大体框架一模一样。主要的实现就是rebalance。
刚开始我实现了一个还算简洁的rebalance算法,前面所有测试都过了,但最后一个测试Test: Check Same config on servers …却无法通过。

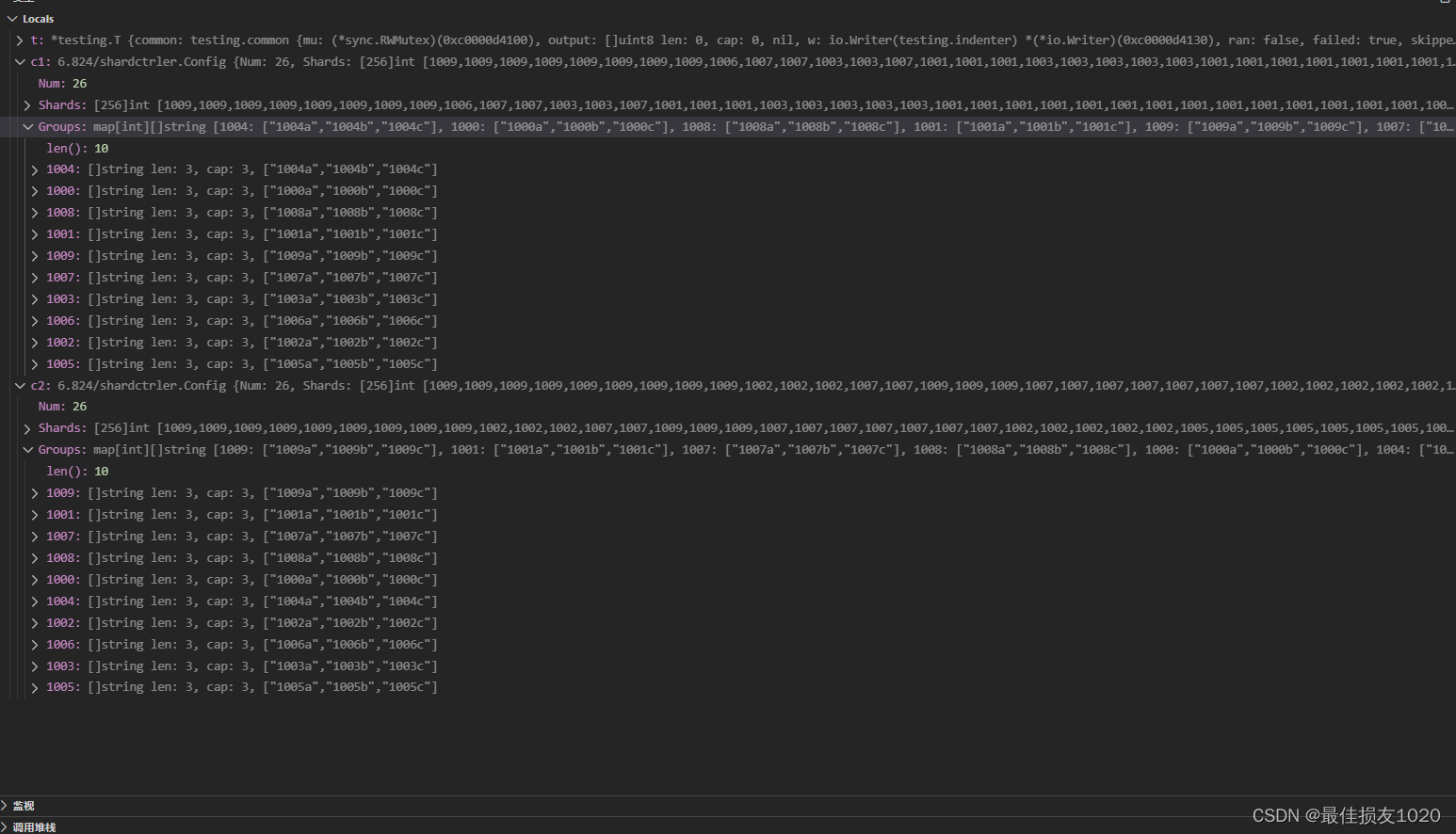
虽然各个节点拥有分区数一样,但具体分区的拥有者却不一致,后面才发现go中的map的遍历顺序竟然是随机的。
【Golang】如何有序地遍历 Map
这也就是Hint中not deterministic的意思
The code in your state machine that performs the shard rebalancing needs to be deterministic. In Go, map iteration order is not deterministic.
然后我使用博客的第一种方法,将 Map 中的 key 拿出来,放入 slice 中做排序。
以Join为例,简要介绍我的reblance算法(臃肿)
分配的原理:最后的分区分布一定是[mean,mean,...,mean+1,mean+1]
问题的关键是哪些节点为mean+1,哪些节点为mean
如果当前节点的分区数超过mean,那么将它设置为mean+1可以减少移动量
若还有分区未分配完,则任意找到分区数为mean的节点,将其分区数设为mean+1
通过这个原理,可以得到节点-分区数映射
现在已知节点-分区数映射,如何正确设置分区数组
复制上次的分区-节点数组,遍历两次数组
第一次遍历:
1 如果分区对应节点当前分区数大于0,同样将该分区分配给该节点,分区数-1
2 如果分区对应节点当前分区数等于0,将该分区标记为未分配(0)
第二次遍历:
将所有未分配的分区分配出去
其他:
为简化代码,可以直接向Start函数传递RPC的arg,applyCh接收任务中将msg.Command强制类型转换各个请求参数
index, _, isLeader := sc.rf.Start(*args)
switch op := msg.Command.(type) {
case JoinArgs:
case LeaveArgs:
case MoveArgs:
case QueryArgs:
}
NShards的疑惑:按理来说,分区数应该设的比节点数大很多,故我将其设为256,但4B的TestStaticShards测试却要求分区数为10,这样ndone才一定为5。由于节点数可能大于分区数,有些节点可能并没有相应的分区,故Leave操作中需进行一些额外的操作,加入分区数为0的节点。
参考代码
client.go
type Clerk struct {
servers []*labrpc.ClientEnd
// Your data here.
serverNumber int // 服务器节点数
clientId int64 // 随机生成的客户端ID
currentSeqNum int64 // 当前序列号
lastLeader int // 上次成功连接的leader
}
func nrand() int64 {
max := big.NewInt(int64(1) << 62)
bigx, _ := rand.Int(rand.Reader, max)
x := bigx.Int64()
return x
}
func MakeClerk(servers []*labrpc.ClientEnd) *Clerk {
ck := new(Clerk)
ck.servers = servers
// Your code here.
ck.serverNumber = len(servers)
ck.clientId = nrand() // 生成随机的ID
ck.currentSeqNum = 0
ck.lastLeader = 0
return ck
}
func (ck *Clerk) Query(num int) Config {
args := QueryArgs{Num: num, ClientId: ck.clientId, SequenceNum: atomic.AddInt64(&ck.currentSeqNum, 1)}
for {
// 首先尝试上次成功的leader
for i := ck.lastLeader; i < ck.lastLeader+ck.serverNumber; i++ {
srv := ck.servers[i%ck.serverNumber]
var reply QueryReply
ok := srv.Call("ShardCtrler.Query", &args, &reply)
if ok && reply.Status == OK {
ck.lastLeader = i % ck.serverNumber
return reply.Config
}
}
time.Sleep(100 * time.Millisecond)
}
}
func (ck *Clerk) Join(servers map[int][]string) {
args := JoinArgs{Servers: servers, ClientId: ck.clientId, SequenceNum: atomic.AddInt64(&ck.currentSeqNum, 1)}
for {
// 首先尝试上次成功的leader
for i := ck.lastLeader; i < ck.lastLeader+ck.serverNumber; i++ {
srv := ck.servers[i%ck.serverNumber]
var reply JoinReply
ok := srv.Call("ShardCtrler.Join", &args, &reply)
if ok && reply.Status == OK {
ck.lastLeader = i % ck.serverNumber
return
}
}
time.Sleep(100 * time.Millisecond)
}
}
func (ck *Clerk) Leave(gids []int) {
args := LeaveArgs{GIDs: gids, ClientId: ck.clientId, SequenceNum: atomic.AddInt64(&ck.currentSeqNum, 1)}
for {
// 首先尝试上次成功的leader
for i := ck.lastLeader; i < ck.lastLeader+ck.serverNumber; i++ {
srv := ck.servers[i%ck.serverNumber]
var reply LeaveReply
ok := srv.Call("ShardCtrler.Leave", &args, &reply)
if ok && reply.Status == OK {
ck.lastLeader = i % ck.serverNumber
return
}
}
time.Sleep(100 * time.Millisecond)
}
}
func (ck *Clerk) Move(shard int, gid int) {
args := MoveArgs{Shard: shard, GID: gid, ClientId: ck.clientId, SequenceNum: atomic.AddInt64(&ck.currentSeqNum, 1)}
for {
// 首先尝试上次成功的leader
for i := ck.lastLeader; i < ck.lastLeader+ck.serverNumber; i++ {
srv := ck.servers[i%ck.serverNumber]
var reply MoveReply
ok := srv.Call("ShardCtrler.Move", &args, &reply)
if ok && reply.Status == OK {
ck.lastLeader = i % ck.serverNumber
return
}
}
time.Sleep(100 * time.Millisecond)
}
}
common.go
// The number of shards.
const NShards = 10 // 4B测试TestStaticShards的要求
// A configuration -- an assignment of shards to groups.
// Please don't change this.
type Config struct {
Num int // config number
Shards [NShards]int // shard -> gid
Groups map[int][]string // gid -> servers[]
}
type Err string
const ( // 错误类型
OK = "OK"
ErrNoKey = "ErrNoKey"
ErrWrongLeader = "ErrWrongLeader"
ErrTimeout = "ErrTimeout"
ErrOldRequest = "ErrOldRequest" // 未出现
ErrLogFull = "ErrLogFull" // 未用到
)
type ReqResult struct { // 命令执行返回
SequenceNum int64 // 命令序列号
Status Err // 命令执行状态
Config Config // 命令执行结果
}
type JoinArgs struct {
Servers map[int][]string // new GID -> servers mappings
// 附带client id与序列号
ClientId int64
SequenceNum int64
}
type JoinReply struct {
Status Err
}
type LeaveArgs struct {
GIDs []int
// 附带client id与序列号
ClientId int64
SequenceNum int64
}
type LeaveReply struct {
Status Err
}
type MoveArgs struct {
Shard int
GID int
// 附带client id与序列号
ClientId int64
SequenceNum int64
}
type MoveReply struct {
Status Err
}
type QueryArgs struct {
Num int // desired config number
// 附带client id与序列号
ClientId int64
SequenceNum int64
}
type QueryReply struct {
Status Err
Config Config
}
server.go
const Debug = true
func DPrintf(format string, a ...interface{}) (n int, err error) {
if Debug {
log.Printf(format, a...)
}
return
}
const (
GeneralPollFrequency = 5 * time.Millisecond // 轮询时间
TimeoutThreshold = 200 * time.Millisecond // 超时阈值
SnapshotPollFrequency = 100 * time.Millisecond // 快照轮询时间
)
type ShardCtrler struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
// Your data here.
configs []Config // indexed by config num
currentConfigNumber int // 当前配置编号
clientCache map[int64]ReqResult // 存放各个客户端最新结果
commitIndex int
dead int32
}
func ConfigCopy(config Config) Config { // 复制节点配置
newConfig := config
newConfig.Groups = make(map[int][]string)
for gid, name := range config.Groups {
newConfig.Groups[gid] = name
}
return newConfig
}
// Join Leave Move Query函数处理流程完全一致
func (sc *ShardCtrler) Join(args *JoinArgs, reply *JoinReply) {
requestBegin := time.Now()
sc.mu.Lock()
index, _, isLeader := sc.rf.Start(*args) // 开始协商用户请求
sc.mu.Unlock()
if !isLeader { // 当前节点不是leader节点,返回错误
reply.Status = ErrWrongLeader
return
}
for {
sc.mu.Lock()
outCycle := false
cache := sc.clientCache[args.ClientId]
if cache.SequenceNum < args.SequenceNum { // 仍未执行相应请求
if sc.commitIndex >= index { // 相应位置出现了其他的命令
reply.Status = ErrWrongLeader
outCycle = true
} else if time.Since(requestBegin) > TimeoutThreshold { // 等待超时
reply.Status = ErrTimeout
outCycle = true
}
} else if cache.SequenceNum == args.SequenceNum { // 请求执行成功
reply.Status = cache.Status
outCycle = true
} else if cache.SequenceNum > args.SequenceNum {
reply.Status = ErrOldRequest
outCycle = true
}
sc.mu.Unlock()
if outCycle {
return
}
time.Sleep(GeneralPollFrequency)
}
}
func (sc *ShardCtrler) Leave(args *LeaveArgs, reply *LeaveReply) {
requestBegin := time.Now()
sc.mu.Lock()
index, _, isLeader := sc.rf.Start(*args) // 开始协商用户请求
sc.mu.Unlock()
if !isLeader { // 当前节点不是leader节点,返回错误
reply.Status = ErrWrongLeader
return
}
for {
sc.mu.Lock()
outCycle := false
cache := sc.clientCache[args.ClientId]
if cache.SequenceNum < args.SequenceNum { // 仍未执行相应请求
if sc.commitIndex >= index { // 相应位置出现了其他的命令
reply.Status = ErrWrongLeader
outCycle = true
} else if time.Since(requestBegin) > TimeoutThreshold { // 等待超时
reply.Status = ErrTimeout
outCycle = true
}
} else if cache.SequenceNum == args.SequenceNum { // 请求执行成功
reply.Status = cache.Status
outCycle = true
} else if cache.SequenceNum > args.SequenceNum {
reply.Status = ErrOldRequest
outCycle = true
}
sc.mu.Unlock()
if outCycle {
return
}
time.Sleep(GeneralPollFrequency)
}
}
func (sc *ShardCtrler) Move(args *MoveArgs, reply *MoveReply) {
requestBegin := time.Now()
sc.mu.Lock()
index, _, isLeader := sc.rf.Start(*args) // 开始协商用户请求
sc.mu.Unlock()
if !isLeader { // 当前节点不是leader节点,返回错误
reply.Status = ErrWrongLeader
return
}
for {
sc.mu.Lock()
outCycle := false
cache := sc.clientCache[args.ClientId]
if cache.SequenceNum < args.SequenceNum { // 仍未执行相应请求
if sc.commitIndex >= index { // 相应位置出现了其他的命令
reply.Status = ErrWrongLeader
outCycle = true
} else if time.Since(requestBegin) > TimeoutThreshold { // 等待超时
reply.Status = ErrTimeout
outCycle = true
}
} else if cache.SequenceNum == args.SequenceNum { // 请求执行成功
reply.Status = cache.Status
outCycle = true
} else if cache.SequenceNum > args.SequenceNum {
reply.Status = ErrOldRequest
outCycle = true
}
sc.mu.Unlock()
if outCycle {
return
}
time.Sleep(GeneralPollFrequency)
}
}
func (sc *ShardCtrler) Query(args *QueryArgs, reply *QueryReply) {
requestBegin := time.Now()
sc.mu.Lock()
index, _, isLeader := sc.rf.Start(*args) // 开始协商用户请求
sc.mu.Unlock()
if !isLeader { // 当前节点不是leader节点,返回错误
reply.Status = ErrWrongLeader
return
}
for {
sc.mu.Lock()
outCycle := false
cache := sc.clientCache[args.ClientId]
if cache.SequenceNum < args.SequenceNum { // 仍未执行相应请求
if sc.commitIndex >= index { // 相应位置出现了其他的命令
reply.Status = ErrWrongLeader
outCycle = true
} else if time.Since(requestBegin) > TimeoutThreshold { // 等待超时
reply.Status = ErrTimeout
outCycle = true
}
} else if cache.SequenceNum == args.SequenceNum { // 请求执行成功
reply.Status = cache.Status
reply.Config = cache.Config // 返回请求配置
outCycle = true
} else if cache.SequenceNum > args.SequenceNum {
reply.Status = ErrOldRequest
outCycle = true
}
sc.mu.Unlock()
if outCycle {
return
}
time.Sleep(GeneralPollFrequency)
}
}
func (sc *ShardCtrler) Kill() {
sc.rf.Kill()
// Your code here, if desired.
atomic.StoreInt32(&sc.dead, 1)
}
// 判断ShardCtrler生命状态
func (sc *ShardCtrler) killed() bool {
z := atomic.LoadInt32(&sc.dead)
return z == 1
}
// needed by shardkv tester
func (sc *ShardCtrler) Raft() *raft.Raft {
return sc.rf
}
// 获取各个GID对应的分区数目
func getNodeMap(Shards [NShards]int) map[int]int {
ans := make(map[int]int)
for i := 0; i < NShards; i++ {
if Shards[i] != 0 {
ans[Shards[i]]++
}
}
return ans
}
// 遍历map找到当前分区数不为0的GID,number为GID-分区数,gids为GID升序序列
func findNotZeroNode(numbers map[int]int, gids []int) int {
for _, gid := range gids {
times := numbers[gid]
if times != 0 {
return gid
}
}
log.Panicf("findNotZeroNode: can't find GID")
return -1
}
// 获取map中key的升序排列
func getSortKeys(m map[int]int) []int {
var keys []int
for k := range m {
keys = append(keys, k)
}
sort.Ints(keys)
return keys
}
// 获取新的节点-分区映射,oldShards为上次的节点-分区映射,newNode为新加入的节点,number为当前节点数
func getNewShardForJoin(oldShards [NShards]int, newNode []int, number int) [NShards]int {
oldShardMap := getNodeMap(oldShards)
oldSortGID := getSortKeys(oldShardMap)
newShardMap := make(map[int]int)
mean := NShards / number
reminder := NShards - number*mean
/*
分配的原理:最后的分区分布一定是[mean,mean,...,mean+1,mean+1]
问题的关键是哪些节点为mean+1,哪些节点为mean
如果当前节点的分区数超过mean,那么将它设置为mean+1可以减少移动量
若还有分区未分配完,则任意找到分区数为mean的节点,将其分区数设为mean+1
*/
for _, gid := range oldSortGID {
times := oldShardMap[gid]
if times > mean && reminder > 0 { // 当前分区数超过mean且未分配完
newShardMap[gid] = mean + 1
reminder--
} else {
newShardMap[gid] = mean
}
}
for _, gid := range newNode { // 将新加入的节点设为mean
newShardMap[gid] = mean
}
newSortGID := getSortKeys(newShardMap)
if reminder > 0 { // 找到分区数为mean的节点,将其分区数设置为mean+1
for _, gid := range newSortGID {
times := newShardMap[gid]
if reminder == 0 {
break
}
if times == mean {
newShardMap[gid] = mean + 1
reminder--
}
}
}
/*
现在已知节点-分区数映射,如何正确设置分区数组
复制上次的分区-节点数组,遍历两次数组
第一次遍历:
1 如果分区对应节点当前分区数大于0,同样将该分区分配给该节点,分区数-1
2 如果分区对应节点当前分区数等于0,将该分区标记为未分配(0)
第二次遍历:
将所有未分配的分区分配出去
*/
newShards := oldShards
// 第一次遍历
for shard, gid := range newShards {
if newShardMap[gid] > 0 {
newShardMap[gid]--
} else {
newShards[shard] = 0
}
}
newShardMap[0] = 0
curAssignNode := 0
// 第二次遍历
for shard, gid := range newShards {
if gid == 0 { // 未分配分区
if newShardMap[curAssignNode] == 0 { // 该节点分区为0,寻找下一个非0节点
curAssignNode = findNotZeroNode(newShardMap, newSortGID)
}
newShards[shard] = curAssignNode
newShardMap[curAssignNode]--
}
}
return newShards
}
func getNewShardForLeave(oldShards [NShards]int, leaveNode []int, number int, group map[int][]string) [NShards]int {
if number == 0 {
return [NShards]int{}
}
oldShardMap := getNodeMap(oldShards)
for gid, _ := range group {
if _, exist := oldShardMap[gid]; !exist { // 加入尚未有任何分区的节点
oldShardMap[gid] = 0
}
}
for _, gid := range leaveNode { // 删除离去节点kv项
delete(oldShardMap, gid)
}
newShardMap := make(map[int]int)
sortGID := getSortKeys(oldShardMap)
oldMean := NShards / (number + len(leaveNode)) // 之前的均值
mean := NShards / number // 当前的均值
reminder := NShards - number*mean // 余数
// leave的原理与join类似,在确定分布为[mean,mean..mean+1,mean+1]的情况下,尽可能较小移动量
for _, gid := range sortGID {
times := oldShardMap[gid]
if times > oldMean && reminder > 0 {
newShardMap[gid] = mean + 1
reminder--
} else {
newShardMap[gid] = mean
}
}
if reminder > 0 {
for _, gid := range sortGID {
times := newShardMap[gid]
if reminder == 0 {
break
}
if times == mean {
newShardMap[gid] = mean + 1
reminder--
}
}
}
// 同样进行两次遍历
newShards := oldShards
// 第一次遍历
for shard, gid := range newShards {
if newShardMap[gid] > 0 {
newShardMap[gid]--
} else { // 不存在的元素为0值
newShards[shard] = 0 // 标记为未分配
}
}
newShardMap[0] = 0
curAssignNode := 0
// 第二次遍历
for shard, gid := range newShards {
if gid == 0 { // 未分配分区
if newShardMap[curAssignNode] == 0 { // 该节点分区为0,寻找下一个非0节点
curAssignNode = findNotZeroNode(newShardMap, sortGID)
}
newShards[shard] = curAssignNode
newShardMap[curAssignNode]--
}
}
return newShards
}
// 接受raft消息
func (sc *ShardCtrler) receiveTask() {
for !sc.killed() {
msg := <-sc.applyCh
sc.mu.Lock()
if msg.CommandValid { // 普通的日志消息
sc.commitIndex = msg.CommandIndex
switch op := msg.Command.(type) {
case JoinArgs:
cache := sc.clientCache[op.ClientId] // 查看相应客户端缓存
if cache.SequenceNum < op.SequenceNum { // 执行请求,自动覆盖之前的结果
oldConfig := sc.configs[sc.currentConfigNumber]
sc.currentConfigNumber++
var newConfig Config
newConfig.Num = sc.currentConfigNumber
newConfig.Groups = map[int][]string{}
var newNode []int
// 添加参数中的映射
for gid, name := range op.Servers {
newConfig.Groups[gid] = name
newNode = append(newNode, gid)
}
// 添加上次配置的映射
for gid, name := range oldConfig.Groups {
newConfig.Groups[gid] = name
}
newConfig.Shards = getNewShardForJoin(oldConfig.Shards, newNode, len(newConfig.Groups))
sc.configs = append(sc.configs, newConfig)
sc.clientCache[op.ClientId] = ReqResult{SequenceNum: op.SequenceNum, Status: OK}
}
case LeaveArgs:
cache := sc.clientCache[op.ClientId] // 查看相应客户端缓存
if cache.SequenceNum < op.SequenceNum { // 执行请求,自动覆盖之前的结果
oldConfig := sc.configs[sc.currentConfigNumber]
sc.currentConfigNumber++
var newConfig Config
newConfig.Num = sc.currentConfigNumber
newConfig.Groups = make(map[int][]string)
// 添加上次的映射
for gid, name := range oldConfig.Groups {
newConfig.Groups[gid] = name
}
// 删除离开节点的映射
for _, leaveGid := range op.GIDs {
delete(newConfig.Groups, leaveGid)
}
newConfig.Shards = getNewShardForLeave(oldConfig.Shards, op.GIDs, len(newConfig.Groups), newConfig.Groups)
sc.configs = append(sc.configs, newConfig)
sc.clientCache[op.ClientId] = ReqResult{SequenceNum: op.SequenceNum, Status: OK}
}
case MoveArgs:
cache := sc.clientCache[op.ClientId] // 查看相应客户端缓存
if cache.SequenceNum < op.SequenceNum { // 执行请求,自动覆盖之前的结果
oldConfig := sc.configs[sc.currentConfigNumber]
sc.currentConfigNumber++
newConfig := ConfigCopy(oldConfig)
newConfig.Num = sc.currentConfigNumber
newConfig.Shards[op.Shard] = op.GID
sc.configs = append(sc.configs, newConfig)
sc.clientCache[op.ClientId] = ReqResult{SequenceNum: op.SequenceNum, Status: OK}
}
case QueryArgs:
cache := sc.clientCache[op.ClientId] // 查看相应客户端缓存
if cache.SequenceNum < op.SequenceNum { // 执行请求,自动覆盖之前的结果
if op.Num < 0 || op.Num > sc.currentConfigNumber {
sc.clientCache[op.ClientId] = ReqResult{SequenceNum: op.SequenceNum, Config: ConfigCopy(sc.configs[sc.currentConfigNumber]), Status: OK}
} else {
sc.clientCache[op.ClientId] = ReqResult{SequenceNum: op.SequenceNum, Config: ConfigCopy(sc.configs[op.Num]), Status: OK}
}
}
}
}
sc.mu.Unlock()
}
}
func StartServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister) *ShardCtrler {
sc := new(ShardCtrler)
sc.me = me
sc.configs = make([]Config, 1)
sc.configs[0].Groups = map[int][]string{}
labgob.Register(JoinArgs{})
labgob.Register(LeaveArgs{})
labgob.Register(MoveArgs{})
labgob.Register(QueryArgs{})
sc.applyCh = make(chan raft.ApplyMsg)
sc.rf = raft.Make(servers, me, persister, sc.applyCh)
// Your code here.
sc.clientCache = map[int64]ReqResult{}
go sc.receiveTask()
return sc
}
4B
4B比较复杂,写了几天才写出来,问题的难点在于:
一:有太多节点之间的交互了,当一个节点需要分区数据时,应该向哪个节点请求数据呢?
二:不同节点的配置版本不一样,如何处理不同版本的节点数据交互
即使看了MIT 6.824 LAB 4B(分布式shard database)这篇文章,还是云里雾里
对于第一个问题,有一个简单的解决方法便是只与leader进行交互,其他节点只通过raft日志获取数据。当然,这只是稍微缩小了问题域,当一个节点从config m 跳到了config n
1 它什么时候认为自己不需要向其他节点获取数据呢?
2 如果它认为自己需要获取数据,它向谁获取呢?
3 如果向前面版本config的分区数据拥有者获取数据,例如n-1的拥有者,它一定拥有这个数据吗?
4 即使n-1的拥有者leader回复它未拥有该分区,也不代表该集群真的没有该分区数据,leader的状态并不可信,只是拥有最长日志,但未必提交了,故状态不一定是最新的。
5 存在一种可能,所有集群监听的配置发生了断层,也就是说大家都没有看到0-n的配置,当前节点就是分区的第一任拥有者呢?它根本不需要向之前配置的拥有者请求数据
对于第二个问题,你很难确信自己已经想明白了不同配置号的请求逻辑,你无法证明这一点。
所以,我采用一种笨方法,拼命地加约束,以至于我能自以为解决问题。
- 集群与集群之间只有leader进行通信
- 每次配置只加一,保证集群经历了每一次的配置
- 集群只在所有负责分区数据均已到达且其余数据均已被取走才更新配置
- 仅仅在节点配置一致时才转移分区数据
- 不直接修改ShardKV状态,通过将命令加入raft日志来进行状态的修改
第二第三点的相关代码如下
func (kv *ShardKV) completeMigrate() bool {
for _, status := range kv.shardStatus {
if status == ResponsibleButNotOwn || status == IrresponsibleButOwn {
return false
}
}
return true
}
func (kv *ShardKV) configListenTask() { // 配置监听线程
for {
select {
case <-kv.done:
return
default:
_, isLeader := kv.rf.GetState()
kv.mu.Lock()
if isLeader && kv.completeMigrate() {
newConfig := kv.mck.Query(kv.config.Num + 1) // 只查看下一任配置
if newConfig.Num == kv.config.Num+1 {
DPrintf("%d %d add new config cmd %v ", kv.gid, kv.me, newConfig)
kv.rf.Start(newConfig) // 最多更新至下一任配置
}
}
kv.mu.Unlock()
time.Sleep(GeneralInterval)
}
}
}
raft日志的操作类型有:
type AddShardCmd struct {
ConfigNum int // 配置号
Shard int // 分区号
KVData map[string]string // 分区数据
ClientCache map[int64]ReqResult // 客户端最新结果
}
type DeleteShardCmd struct {
ConfigNum int // 配置号
Shard int // 分区号
}
switch data := msg.Command.(type) {
case GetArgs:
case PutAppendArgs:
case shardctrler.Config: // 配置更新
case AddShardCmd: // 增加分区数据
case DeleteShardCmd: // 删除分区数据
代码介绍
简要地介绍代码结构,我的代码中有许多不必要的约束,但我也懒得去掉这些约束,首先是RPC处理函数
Get/PutAppend: 在处理客户端请求前判断分区状态,看是否拥有且负责该分区数据
kv.mu.Lock()
switch kv.shardStatus[shard] {
case IrresponsibleAndNotOwn: // 错误的组
reply.Status = ErrWrongGroup
case IrresponsibleButOwn: // 错误的组
reply.Status = ErrWrongGroup
case ResponsibleButNotOwn: // 等待分区数据到达
reply.Status = ErrWaitShardData
case ResponsibleAndOwn:
index, _, isLeader = kv.rf.Start(*args) // 开始协商用户请求
if !isLeader {
reply.Status = ErrWrongLeader
} else {
exitFunc = false
}
}
kv.mu.Unlock()
if exitFunc {
return
}
Migrate: 请求分区数据的RPC处理函数,只在leader且配置相同时传递分区数据
type MigrateArgs struct { // 分区数据迁移参数
ConfigNum int // 请求者配置号
GID int // 请求者ID
Shard int // 请求分区号
}
type MigrateReply struct { // 分区数据迁移返回
Status Err // 返回状态
KVData map[string]string // 分区数据
ClintCache map[int64]ReqResult // 客户端最新结果
}
func (kv *ShardKV) Migrate(args *MigrateArgs, reply *MigrateReply) {
_, isLeader := kv.rf.GetState()
if !isLeader {
reply.Status = ErrWrongLeader
return
}
kv.mu.Lock()
defer kv.mu.Unlock()
// 与预期的分区数据请求者信息一致,将数据移交给该节点
if kv.config.Num == args.ConfigNum && kv.config.Shards[args.Shard] == args.GID && kv.shardStatus[args.Shard] == IrresponsibleButOwn {
DPrintf("%d shard migrate from %d-%d to %d success. config num is %d\n", args.Shard, kv.gid, kv.me, args.GID, kv.config.Num)
reply.KVData = copyMapKV(kv.kvDatas[args.Shard])
reply.ClintCache = copyMapCache(kv.clientCache)
reply.Status = OK
return
}
DPrintf("%d shard migrate from %d-%d to %d failed. config num is %d arg config num is %d shard status is %v\n", args.Shard, kv.gid, kv.me, args.GID, kv.config.Num, args.ConfigNum, kv.shardStatus)
reply.Status = ErrShardStatus
return
}
可以优化的点:是否一定需要leader才传递数据呢?
Delete: 当前不负责但拥有的数据已被其他节点得到,可以不再保持该分区数据
type DeleteArgs struct { // 删除分区参数
ConfigNum int // 请求者配置号
MigrateSuccessShard []int // 请求者拥有的分区号
}
type DeleteReply struct { // 删除分区返回
}
func (kv *ShardKV) Delete(args *DeleteArgs, reply *DeleteReply) {
_, isLeader := kv.rf.GetState()
if !isLeader {
return
}
kv.mu.Lock()
defer kv.mu.Unlock()
if kv.config.Num <= args.ConfigNum { // 请求者配置号比当前配置号更新或一致
for _, shard := range args.MigrateSuccessShard {
if kv.shardStatus[shard] == IrresponsibleButOwn { // 表示该数据已成功转移至其他节点
DPrintf("%d-%d send delete %d shard cmd. config num is %d", kv.gid, kv.me, shard, kv.config.Num)
kv.rf.Start(DeleteShardCmd{ConfigNum: kv.config.Num, Shard: shard}) // 删除分区数据命令
}
}
}
return
}
如果在配置更高或相等的集群发现了该分区数据,那么该分区数据一定成功传递到了另一个集群
StartServer起的一些定时任务
configListenTask: 定时监听配置,在满足条件时进行配置更新
func (kv *ShardKV) completeMigrate() bool {
for _, status := range kv.shardStatus {
if status == ResponsibleButNotOwn || status == IrresponsibleButOwn {
return false
}
}
return true
}
func (kv *ShardKV) configListenTask() { // 配置监听线程
for {
select {
case <-kv.done:
return
default:
_, isLeader := kv.rf.GetState()
kv.mu.Lock()
if isLeader && kv.completeMigrate() {
newConfig := kv.mck.Query(kv.config.Num + 1) // 只查看下一任配置
if newConfig.Num == kv.config.Num+1 {
DPrintf("%d %d add new config cmd %v ", kv.gid, kv.me, newConfig)
kv.rf.Start(newConfig) // 最多更新至下一任配置
}
}
kv.mu.Unlock()
time.Sleep(GeneralInterval)
}
}
}
注意配置更新的条件,每次更新只更新一个版本
requestShardTask: 定时请求当前未获得的分区数据
func (kv *ShardKV) requestShardTask() { // 请求分区线程
for {
select {
case <-kv.done:
return
default:
_, isLeader := kv.rf.GetState()
if isLeader {
kv.mu.Lock()
for shard, status := range kv.shardStatus {
if status == ResponsibleButNotOwn {
go func(shard int, lastConfig shardctrler.Config) {
args := MigrateArgs{ConfigNum: lastConfig.Num + 1, GID: kv.gid, Shard: shard}
oldOwner := lastConfig.Shards[shard] // 向上一任拥有者请求分区数据
for _, server := range lastConfig.Groups[oldOwner] {
reply := MigrateReply{}
ok := kv.make_end(server).Call("ShardKV.Migrate", &args, &reply)
if ok && reply.Status == OK {
DPrintf("%d %d send add %d shard cmd.", kv.gid, kv.me, shard)
// 增加分区数据命令
kv.rf.Start(AddShardCmd{ConfigNum: lastConfig.Num + 1, Shard: shard, KVData: reply.KVData, ClientCache: reply.ClintCache})
return
}
}
}(shard, kv.lastConfig)
}
}
kv.mu.Unlock()
}
time.Sleep(GeneralInterval)
}
}
}
当集群需要分区数据时,只需要向上一任拥有者请求分区数据,由于配置更新条件且每次只加一,分区数据一定会在各个版本的拥有者中传递,若请求分区失败,代表上一任拥有者配置尚未更新,需等待该集群迁移完成所有的分区数据,并实现配置同步。由于加的一些约束,几个集群配置最低的集群会拖慢所有集群,导致整个系统无法取得进展,故debug时只需要搞清楚为什么配置最低的节点没能更新配置,大部分时间是因为未收到分区数据删除的确认,无法保证自己已将分区数据成功转移出去,故卡死在当前配置。
notifyDeleteTask: 定时提醒其他集群删除已成功传递的分区数据
func (kv *ShardKV) notifyDeleteTask() { // 提醒其他分组删除相应分区
for {
select {
case <-kv.done:
return
default:
_, isLeader := kv.rf.GetState()
if isLeader {
kv.mu.Lock()
ownShards := []int{}
for shard, status := range kv.shardStatus {
if status == ResponsibleAndOwn || status == IrresponsibleButOwn { // 当前拥有这些分区数据
ownShards = append(ownShards, shard)
}
}
args := DeleteArgs{ConfigNum: kv.config.Num, MigrateSuccessShard: ownShards}
for gid, servers := range kv.allReplicaNode {
if gid != kv.gid {
for _, server := range servers {
reply := DeleteReply{}
go kv.make_end(server).Call("ShardKV.Delete", &args, &reply)
}
}
}
kv.mu.Unlock()
}
}
time.Sleep(GeneralInterval)
}
}
notifyDeleteTask与Delete函数是配置更新的关键
raft日志处理函数receiveTask
// 接受raft消息
func (kv *ShardKV) receiveTask() {
for {
select {
case <-kv.done:
return
case msg := <-kv.applyCh:
{
kv.mu.Lock()
if msg.CommandValid { // 普通的日志消息
kv.commitIndex = msg.CommandIndex
switch data := msg.Command.(type) {
case GetArgs:
shard := key2shard(data.Key)
cache := kv.clientCache[data.ClientId] // 查看相应客户端缓存
if cache.SequenceNum < data.SequenceNum && kv.shardStatus[shard] == ResponsibleAndOwn {
value, exist := kv.kvDatas[shard][data.Key]
if !exist {
kv.clientCache[data.ClientId] = ReqResult{SequenceNum: data.SequenceNum, Status: ErrNoKey}
} else {
kv.clientCache[data.ClientId] = ReqResult{SequenceNum: data.SequenceNum, Status: OK, Value: value}
}
}
case PutAppendArgs:
shard := key2shard(data.Key)
cache := kv.clientCache[data.ClientId] // 查看相应客户端缓存
if cache.SequenceNum < data.SequenceNum && kv.shardStatus[shard] == ResponsibleAndOwn {
if data.Op == "Put" {
kv.kvDatas[shard][data.Key] = data.Value
kv.clientCache[data.ClientId] = ReqResult{SequenceNum: data.SequenceNum, Status: OK}
} else {
kv.kvDatas[shard][data.Key] += data.Value
kv.clientCache[data.ClientId] = ReqResult{SequenceNum: data.SequenceNum, Status: OK}
}
}
case shardctrler.Config:
if kv.config.Num < data.Num {
DPrintf("%d %d update config.old config:%v new config:%v", kv.gid, kv.me, kv.config, data)
for i := 0; i < shardctrler.NShards; i++ {
oldOwner := kv.config.Shards[i]
newOwner := data.Shards[i]
if newOwner == kv.gid && oldOwner != kv.gid {
if oldOwner == 0 { // 第一任拥有者
kv.shardStatus[i] = ResponsibleAndOwn
kv.kvDatas[i] = make(map[string]string) // 初始化map
} else { // 等待上一任拥有者的分区数据
kv.shardStatus[i] = ResponsibleButNotOwn
}
}
if newOwner != kv.gid && oldOwner == kv.gid {
if kv.shardStatus[i] == ResponsibleAndOwn {
kv.shardStatus[i] = IrresponsibleButOwn
} else { // 不可能发生
kv.shardStatus[i] = IrresponsibleAndNotOwn
}
}
}
kv.lastConfig = kv.config
kv.config = data
for gid, servers := range data.Groups { // 更新见到的所有节点
kv.allReplicaNode[gid] = servers
}
}
case AddShardCmd:
if kv.config.Num == data.ConfigNum && kv.shardStatus[data.Shard] == ResponsibleButNotOwn { // 预期的分区数据到达
DPrintf("%d %d add new %d shard data. config num is %d", kv.gid, kv.me, data.Shard, kv.config.Num)
kv.kvDatas[data.Shard] = copyMapKV(data.KVData)
kv.shardStatus[data.Shard] = ResponsibleAndOwn
for id, res := range data.ClientCache { // 更新最新客户端结果
if kv.clientCache[id].SequenceNum < res.SequenceNum {
kv.clientCache[id] = res
}
}
}
case DeleteShardCmd:
DPrintf("before:%d %d delete %d shard data. config num is %d shard status:%v", kv.gid, kv.me, data.Shard, kv.config.Num, kv.shardStatus)
if kv.config.Num == data.ConfigNum && kv.shardStatus[data.Shard] == IrresponsibleButOwn {
kv.shardStatus[data.Shard] = IrresponsibleAndNotOwn
kv.kvDatas[data.Shard] = nil
DPrintf("after: %d %d delete %d shard data. config num is %d shard status:%v", kv.gid, kv.me, data.Shard, kv.config.Num, kv.shardStatus)
}
}
} else if msg.SnapshotValid { // 快照消息
r := bytes.NewBuffer(msg.Snapshot)
d := labgob.NewDecoder(r)
var commitIndex int
var clientCache map[int64]ReqResult
var kvDatas [shardctrler.NShards]map[string]string
var config shardctrler.Config
var shardStatus [shardctrler.NShards]ShardStatus
var allNode map[int][]string
if d.Decode(&commitIndex) != nil || d.Decode(&clientCache) != nil || d.Decode(&kvDatas) != nil || d.Decode(&config) != nil || d.Decode(&shardStatus) != nil || d.Decode(&allNode) != nil {
log.Panicf("snapshot decode error")
} else {
DPrintf("%d %d recv snapshot. shard status:%v", kv.gid, kv.me, shardStatus)
kv.commitIndex = commitIndex
kv.clientCache = clientCache
kv.kvDatas = kvDatas
kv.config = config
kv.lastConfig = kv.mck.Query(config.Num - 1)
kv.shardStatus = shardStatus
kv.allReplicaNode = allNode
// 更新lastSnapshotIndex
kv.lastSnapshotIndex = commitIndex
}
}
// 检查raft state大小,生成快照
if kv.maxraftstate > 0 && kv.persister.RaftStateSize() > kv.maxraftstate && kv.commitIndex > kv.lastSnapshotIndex {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(kv.commitIndex)
e.Encode(kv.clientCache)
e.Encode(kv.kvDatas)
// 将以下数据编码至快照
e.Encode(kv.config)
e.Encode(kv.shardStatus)
e.Encode(kv.allReplicaNode)
snapshot := w.Bytes()
kv.rf.Snapshot(kv.commitIndex, snapshot)
kv.lastSnapshotIndex = kv.commitIndex
}
kv.mu.Unlock()
}
}
}
}
一些可以优化的点:Get不需要去重处理,同时删除多个分区数据
debug记录
debug经验所得:
1 raft日志中加入map类型数据,提交后需copy,要不然持久化与对map操作会产生竞态
2 leader的状态未必可信,也不一定是集群最新结果
3 快照需包含提交日志全部改变状态,快照效果应与正常日志迭代完全一致(最关键,最重要的一点)
以下简要介绍一下debug经历
我通过两种方法来进行debug,一个是在合适的地方加上打印语句,二是通过vscode自带的调试功能分析各个线程的状态。
刚开始我还是使用for !kv.killed()的方式控制goroutine的生命周期,但我在用vscode查看goroutine时,那些已经dead的receiveTask任务仍然卡在kv.applyCh这一步,导致有很多receiveTask,而我一般是通过这个任务来查看各个集群当前状态。所以我将代码改成了for select default格式,使用done管道来控制goroutine生命周期,这样receiveTask就少挺多的

data race
/usr/local/go/src/encoding/gob/encode.go:301 +0x3be
encoding/gob.(*Encoder).encode()
/usr/local/go/src/encoding/gob/encode.go:703 +0x2b8
encoding/gob.(*Encoder).EncodeValue()
/usr/local/go/src/encoding/gob/encoder.go:251 +0x768
encoding/gob.(*Encoder).Encode()
/usr/local/go/src/encoding/gob/encoder.go:176 +0x15a
6.824/labgob.(*LabEncoder).Encode()
/root/mit6.824/6.824/src/labgob/labgob.go:36 +0x5e
6.824/raft.(*Raft).persist() // e.Encode(rf.log)
/root/mit6.824/6.824/src/raft/raft.go:105 +0xf8
6.824/raft.(*Raft).AppendEntries()
/root/mit6.824/6.824/src/raft/raft.go:358 +0x102f
runtime.call32()
/usr/local/go/src/runtime/asm_amd64.s:725 +0x48
reflect.Value.Call()
/usr/local/go/src/reflect/value.go:368 +0xc7
6.824/labrpc.(*Service).dispatch()
/root/mit6.824/6.824/src/labrpc/labrpc.go:496 +0x47b
6.824/labrpc.(*Server).dispatch()
/root/mit6.824/6.824/src/labrpc/labrpc.go:420 +0x26a
6.824/labrpc.(*Network).processReq.func1()
/root/mit6.824/6.824/src/labrpc/labrpc.go:240 +0x9c
Previous write at 0x00c0001fa630 by goroutine 45:
runtime.mapassign_faststr()
/usr/local/go/src/runtime/map_faststr.go:203 +0x0
6.824/shardkv.(*ShardKV).receiveTask() // 对kv数据进行修改
/root/mit6.824/6.824/src/shardkv/server.go:323 +0x1306
6.824/shardkv.StartServer.func1()
/root/mit6.824/6.824/src/shardkv/server.go:463 +0x39
raft日志中加入map类型数据,提交后需copy,要不然持久化与对map操作会产生竞态
我卡了很久的bug在于TestConcurrent3测试
func TestConcurrent3(t *testing.T) {
fmt.Printf("Test: concurrent configuration change and restart...\n")
cfg := make_config(t, 3, false, 300)
defer cfg.cleanup()
ck := cfg.makeClient()
cfg.join(0)
n := 10
ka := make([]string, n)
va := make([]string, n)
for i := 0; i < n; i++ {
ka[i] = strconv.Itoa(i)
va[i] = randstring(1)
ck.Put(ka[i], va[i])
}
var done int32
ch := make(chan bool)
ff := func(i int, ck1 *Clerk) {
defer func() { ch <- true }()
for atomic.LoadInt32(&done) == 0 {
x := randstring(1)
ck1.Append(ka[i], x)
va[i] += x
}
}
for i := 0; i < n; i++ {
ck1 := cfg.makeClient()
go ff(i, ck1)
}
t0 := time.Now()
for time.Since(t0) < 12*time.Second {
cfg.join(2)
cfg.join(1)
time.Sleep(time.Duration(rand.Int()%900) * time.Millisecond)
cfg.ShutdownGroup(0)
cfg.ShutdownGroup(1)
cfg.ShutdownGroup(2)
cfg.StartGroup(0)
cfg.StartGroup(1)
cfg.StartGroup(2)
time.Sleep(time.Duration(rand.Int()%900) * time.Millisecond)
cfg.leave(1)
cfg.leave(2)
time.Sleep(time.Duration(rand.Int()%900) * time.Millisecond)
}
time.Sleep(2 * time.Second)
atomic.StoreInt32(&done, 1)
for i := 0; i < n; i++ {
<-ch
}
for i := 0; i < n; i++ {
check(t, ck, ka[i], va[i])
}
fmt.Printf(" ... Passed\n")
}
在这个测试中进行了许多次的重启操作,测试过程中某个集群的配置总是无法更新,卡在某个版本,导致迁移分区数据一直失败。例,以下情况,100版本为26 101版本为27,102版本为25,102由于某个分区为IrresponsibleButOwn无法更新配置。
00:44:57 migrate failed: 8 shard from 102 to 101 shard status is 0
00:44:57 request config:27 my config:25
00:44:57 migrate failed: 4 shard from 100 to 101 shard status is 2
00:44:57 request config:27 my config:26
00:44:57 migrate failed: 8 shard from 102 to 101 shard status is 0
00:44:57 request config:27 my config:25
00:44:57 migrate failed: 9 shard from 102 to 101 shard status is 0
00:44:57 request config:27 my config:25
00:44:57 migrate failed: 4 shard from 100 to 101 shard status is 2
00:44:57 request config:27 my config:26
00:44:58 migrate failed: 9 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 8 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 4 shard from 100 to 101 shard status is 2
00:44:58 request config:27 my config:26
00:44:58 migrate failed: 9 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 4 shard from 100 to 101 shard status is 2
00:44:58 request config:27 my config:26
00:44:58 migrate failed: 8 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 9 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 8 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 4 shard from 100 to 101 shard status is 2
00:44:58 request config:27 my config:26
00:44:58 migrate failed: 9 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 8 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 4 shard from 100 to 101 shard status is 2
00:44:58 request config:27 my config:26
00:44:58 migrate failed: 9 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 8 shard from 102 to 101 shard status is 0
00:44:58 request config:27 my config:25
00:44:58 migrate failed: 4 shard from 100 to 101 shard status is 2
00:44:58 request config:27 my config:26
当时我的设计与现在有一些不同,关于确认分区数据已成功转移,我采用的方法是集群A向集群B请求分区数据,等待分区数据后加入raft日志,在raft日志处理函数AddShardCmd的分支里启动一个协程,该协程定时向集群A发送删除分区消息,直到集群A的分区状态改变(从IrresponsibleButOwn到IrresponsibleAndNotOwn)。
实际上集群B的所有节点都会起一个协程监督集群A完成分区状态的改变,所以大部分情景下整个系统都能正常,但碰到这种多次重启的场景,有可能raft直接用快照掩盖了普通的日志,但快照处理中并不会启动协程,这就是一种不一致性,所以快照处理的效果应该与日志一条一条处理时一致。
所以我就换了与现在类似的方法,定时向其他集群发送删除分区消息,但这还有一点小坑,我开始直接向config中的Groups成员广播删除分区消息,但可能节点已离开Groups,所以一直收不到消息。所以我使用allReplicaNode成员变量记录见到的所有节点地址,并在receiveTask的shardctrler.Config分支中更新该成员变量。不过我没有在快照中保存allReplicaNode的状态的值,这又是日志处理与快照处理的不一致性,所以这个实验最令我印象深刻的就是保持日志处理与快照处理的状态一致性
通过截图与代码参考
通过截图
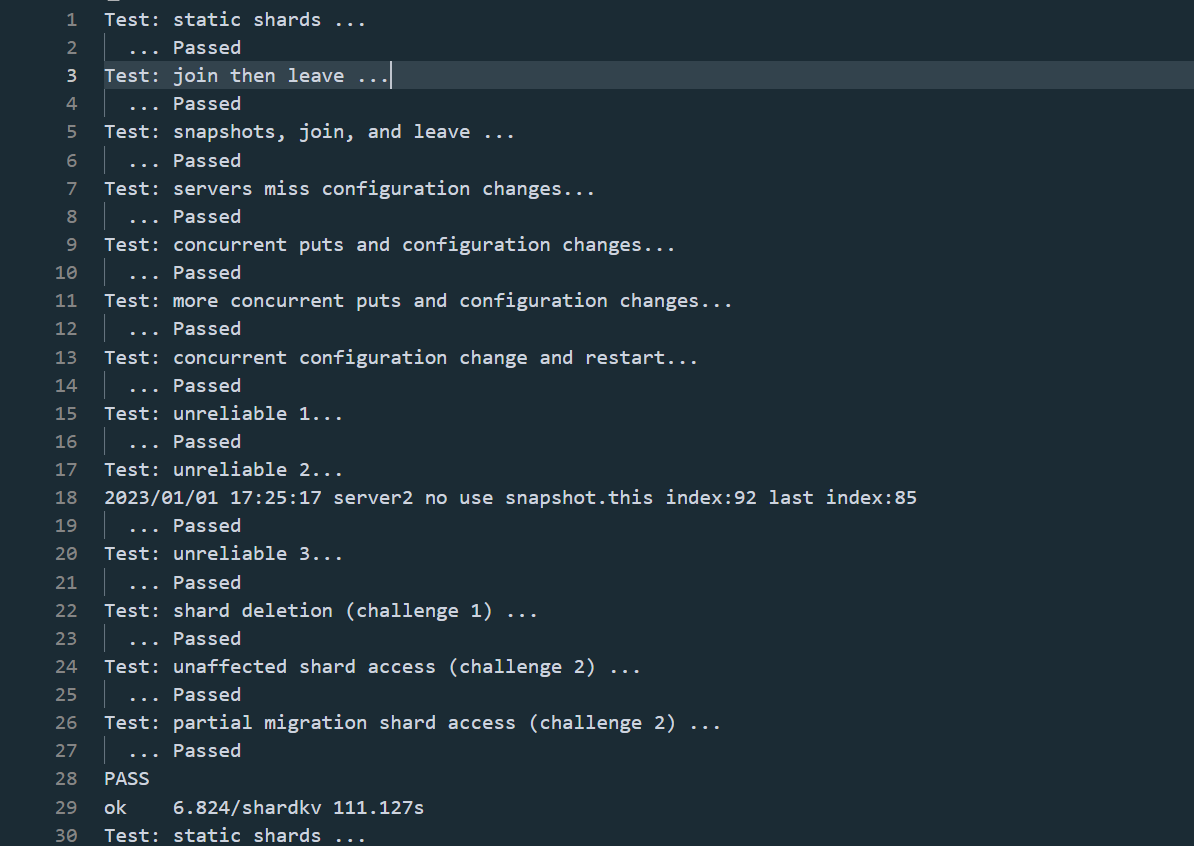
通过396次测试,本来想跑1000次,被我随手关掉了vscode,也就懒得跑了,当作基本正确吧!
代码参考:
client.go
package shardkv
//
// client code to talk to a sharded key/value service.
//
// the client first talks to the shardctrler to find out
// the assignment of shards (keys) to groups, and then
// talks to the group that holds the key's shard.
//
import (
"crypto/rand"
"math/big"
"sync/atomic"
"time"
"6.824/labrpc"
"6.824/shardctrler"
)
//
// which shard is a key in?
// please use this function,
// and please do not change it.
//
func key2shard(key string) int {
shard := 0
if len(key) > 0 {
shard = int(key[0])
}
shard %= shardctrler.NShards
return shard
}
func nrand() int64 {
max := big.NewInt(int64(1) << 62)
bigx, _ := rand.Int(rand.Reader, max)
x := bigx.Int64()
return x
}
type Clerk struct {
sm *shardctrler.Clerk
config shardctrler.Config
make_end func(string) *labrpc.ClientEnd
// You will have to modify this struct.
clientId int64 // 随机生成的客户端ID
currentSeqNum int64 // 当前序列号
}
//
// the tester calls MakeClerk.
//
// ctrlers[] is needed to call shardctrler.MakeClerk().
//
// make_end(servername) turns a server name from a
// Config.Groups[gid][i] into a labrpc.ClientEnd on which you can
// send RPCs.
//
func MakeClerk(ctrlers []*labrpc.ClientEnd, make_end func(string) *labrpc.ClientEnd) *Clerk {
ck := new(Clerk)
ck.sm = shardctrler.MakeClerk(ctrlers)
ck.make_end = make_end
// You'll have to add code here.
ck.clientId = nrand() // 生成随机的ID
ck.currentSeqNum = 1
return ck
}
//
// fetch the current value for a key.
// returns "" if the key does not exist.
// keeps trying forever in the face of all other errors.
// You will have to modify this function.
//
func (ck *Clerk) Get(key string) string {
args := GetArgs{Key: key, ClientId: ck.clientId, SequenceNum: atomic.AddInt64(&ck.currentSeqNum, 1)}
for {
shard := key2shard(key)
gid := ck.config.Shards[shard]
if servers, ok := ck.config.Groups[gid]; ok {
// try each server for the shard.
for si := 0; si < len(servers); si++ {
srv := ck.make_end(servers[si])
var reply GetReply
ok := srv.Call("ShardKV.Get", &args, &reply)
if ok && (reply.Status == OK || reply.Status == ErrNoKey) {
return reply.Value
}
if ok && (reply.Status == ErrWrongGroup) {
break
}
// ... not ok, or ErrWrongLeader
}
}
time.Sleep(100 * time.Millisecond)
// ask controler for the latest configuration.
ck.config = ck.sm.Query(-1)
}
return ""
}
//
// shared by Put and Append.
// You will have to modify this function.
//
func (ck *Clerk) PutAppend(key string, value string, op string) {
args := PutAppendArgs{Key: key, Value: value, Op: op, ClientId: ck.clientId, SequenceNum: atomic.AddInt64(&ck.currentSeqNum, 1)}
for {
shard := key2shard(key)
gid := ck.config.Shards[shard]
if servers, ok := ck.config.Groups[gid]; ok {
for si := 0; si < len(servers); si++ {
srv := ck.make_end(servers[si])
var reply PutAppendReply
ok := srv.Call("ShardKV.PutAppend", &args, &reply)
if ok && reply.Status == OK {
return
}
if ok && reply.Status == ErrWrongGroup {
break
}
// ... not ok, or ErrWrongLeader
}
}
time.Sleep(100 * time.Millisecond)
// ask controler for the latest configuration.
ck.config = ck.sm.Query(-1)
}
}
func (ck *Clerk) Put(key string, value string) {
ck.PutAppend(key, value, "Put")
}
func (ck *Clerk) Append(key string, value string) {
ck.PutAppend(key, value, "Append")
}
common.go
package shardkv
//
// Sharded key/value server.
// Lots of replica groups, each running Raft.
// Shardctrler decides which group serves each shard.
// Shardctrler may change shard assignment from time to time.
//
// You will have to modify these definitions.
//
const (
OK = "OK"
ErrNoKey = "ErrNoKey"
ErrWrongGroup = "ErrWrongGroup"
ErrWrongLeader = "ErrWrongLeader"
ErrTimeout = "ErrTimeout"
ErrWaitShardData = "ErrWaitShardData " // 等待分区数据
ErrWaitTargetUpdateConfig = "ErrWaitTargetUpdateConfig" // 等待对方更新配置
ErrWaitDelete = "ErrWaitDelete"
ErrShardStatus = "ErrShardStatus"
ErrUnexpectedNode = "ErrUnexpectedNode"
ErrOldRequest = "ErrOldRequest" // 未出现
ErrLogFull = "ErrLogFull" // 未用到
)
type Err string
// Put or Append
type PutAppendArgs struct {
Key string
Value string
Op string // "Put" or "Append"
// 附带client id与序列号
ClientId int64
SequenceNum int64
}
type PutAppendReply struct {
Status Err
}
type GetArgs struct {
Key string
// 附带client id与序列号
ClientId int64
SequenceNum int64
}
type GetReply struct {
Status Err
Value string
}
type ReqResult struct { // 命令执行返回
SequenceNum int64 // 命令序列号
Status Err // 命令执行状态
Value string // 命令执行结果
}
type MigrateArgs struct { // 分区数据迁移参数
ConfigNum int // 请求者配置号
GID int // 请求者ID
Shard int // 请求分区号
}
type MigrateReply struct { // 分区数据迁移返回
Status Err // 返回状态
KVData map[string]string // 分区数据
ClintCache map[int64]ReqResult // 客户端最新结果
}
type DeleteArgs struct { // 删除分区参数
ConfigNum int // 请求者配置号
MigrateSuccessShard []int // 请求者拥有的分区号
}
type DeleteReply struct { // 删除分区返回
}
server.go
package shardkv
import (
"bytes"
"log"
"sync"
"time"
"6.824/labgob"
"6.824/labrpc"
"6.824/raft"
"6.824/shardctrler"
)
const Debug = true
func DPrintf(format string, a ...interface{}) (n int, err error) {
if Debug {
log.Printf(format, a...)
}
return
}
const (
GeneralPollFrequency = 5 * time.Millisecond // 轮询时间
TimeoutThreshold = 200 * time.Millisecond // 超时阈值
SnapshotPollFrequency = 100 * time.Millisecond // 快照轮询时间
ConfigListenFrequency = 100 * time.Millisecond // 查询当前配置频率
GeneralInterval = 100 * time.Millisecond // 通用间隔
)
type ShardStatus int
const ( // 分区状态
IrresponsibleAndNotOwn ShardStatus = iota
IrresponsibleButOwn
ResponsibleAndOwn
ResponsibleButNotOwn
)
type AddShardCmd struct {
ConfigNum int // 配置号
Shard int // 分区号
KVData map[string]string // 分区数据
ClientCache map[int64]ReqResult // 客户端最新结果
}
type DeleteShardCmd struct {
ConfigNum int // 配置号
Shard int // 分区号
}
type ShardKV struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
make_end func(string) *labrpc.ClientEnd
gid int
ctrlers []*labrpc.ClientEnd
maxraftstate int // snapshot if log grows this big
// Your definitions here.
done chan struct{}
persister *raft.Persister
mck *shardctrler.Clerk // 配置客户端
lastConfig shardctrler.Config // 上次的配置
config shardctrler.Config // 当前配置
kvDatas [shardctrler.NShards]map[string]string // 各分区kv数据
clientCache map[int64]ReqResult // 存放各个客户端最新结果
commitIndex int // server当前commit index
lastSnapshotIndex int // 上次快照的commit index
shardStatus [shardctrler.NShards]ShardStatus // 各分区状态
allReplicaNode map[int][]string // 见到的所有节点
}
func copyMapKV(data map[string]string) map[string]string { // 复制kv数据
newData := make(map[string]string)
for key, value := range data {
newData[key] = value
}
return newData
}
func copyMapCache(data map[int64]ReqResult) map[int64]ReqResult { // 复制客户端最新结果
newData := make(map[int64]ReqResult)
for id, res := range data {
newData[id] = res
}
return newData
}
func (kv *ShardKV) Get(args *GetArgs, reply *GetReply) {
shard := key2shard(args.Key)
exitFunc := true
var index int
var isLeader bool
kv.mu.Lock()
switch kv.shardStatus[shard] {
case IrresponsibleAndNotOwn: // 错误的组
reply.Status = ErrWrongGroup
case IrresponsibleButOwn: // 错误的组
reply.Status = ErrWrongGroup
case ResponsibleButNotOwn: // 等待分区数据到达
reply.Status = ErrWaitShardData
case ResponsibleAndOwn:
index, _, isLeader = kv.rf.Start(*args) // 开始协商用户请求
if !isLeader {
reply.Status = ErrWrongLeader
} else {
exitFunc = false
}
}
kv.mu.Unlock()
if exitFunc {
return
}
requestBegin := time.Now()
for {
kv.mu.Lock()
outCycle := false
cache := kv.clientCache[args.ClientId]
if cache.SequenceNum < args.SequenceNum { // 仍未执行相应请求
if kv.commitIndex >= index { // 相应位置出现了其他的命令
reply.Status = ErrWrongLeader
outCycle = true
} else if time.Since(requestBegin) > TimeoutThreshold { // 等待超时
reply.Status = ErrTimeout
outCycle = true
}
} else if cache.SequenceNum == args.SequenceNum { // 请求执行成功
reply.Status = cache.Status
reply.Value = cache.Value
outCycle = true
} else if cache.SequenceNum > args.SequenceNum {
reply.Status = ErrOldRequest
outCycle = true
}
kv.mu.Unlock()
if outCycle {
return
}
time.Sleep(GeneralPollFrequency)
}
}
func (kv *ShardKV) PutAppend(args *PutAppendArgs, reply *PutAppendReply) {
shard := key2shard(args.Key)
exitFunc := true
var index int
var isLeader bool
kv.mu.Lock()
switch kv.shardStatus[shard] {
case IrresponsibleAndNotOwn: // 错误的组
reply.Status = ErrWrongGroup
case IrresponsibleButOwn: // 错误的组
reply.Status = ErrWrongGroup
case ResponsibleButNotOwn: // 等待分区数据到达
reply.Status = ErrWaitShardData
case ResponsibleAndOwn:
index, _, isLeader = kv.rf.Start(*args) // 开始协商用户请求
if !isLeader {
reply.Status = ErrWrongLeader
} else {
exitFunc = false
}
}
kv.mu.Unlock()
if exitFunc {
return
}
requestBegin := time.Now()
for {
kv.mu.Lock()
outCycle := false
cache := kv.clientCache[args.ClientId]
if cache.SequenceNum < args.SequenceNum { // 仍未执行相应请求
if kv.commitIndex >= index { // 相应位置出现了其他的命令
reply.Status = ErrWrongLeader
outCycle = true
} else if time.Since(requestBegin) > TimeoutThreshold { // 等待超时
reply.Status = ErrTimeout
outCycle = true
}
} else if cache.SequenceNum == args.SequenceNum { // 请求执行成功
reply.Status = cache.Status
outCycle = true
} else if cache.SequenceNum > args.SequenceNum {
reply.Status = ErrOldRequest
outCycle = true
}
kv.mu.Unlock()
if outCycle {
return
}
time.Sleep(GeneralPollFrequency)
}
}
func (kv *ShardKV) Migrate(args *MigrateArgs, reply *MigrateReply) {
_, isLeader := kv.rf.GetState()
if !isLeader {
reply.Status = ErrWrongLeader
return
}
kv.mu.Lock()
defer kv.mu.Unlock()
// 与预期的分区数据请求者信息一致,将数据移交给该节点
if kv.config.Num == args.ConfigNum && kv.config.Shards[args.Shard] == args.GID && kv.shardStatus[args.Shard] == IrresponsibleButOwn {
DPrintf("%d shard migrate from %d-%d to %d success. config num is %d\n", args.Shard, kv.gid, kv.me, args.GID, kv.config.Num)
reply.KVData = copyMapKV(kv.kvDatas[args.Shard])
reply.ClintCache = copyMapCache(kv.clientCache)
reply.Status = OK
return
}
DPrintf("%d shard migrate from %d-%d to %d failed. config num is %d arg config num is %d shard status is %v\n", args.Shard, kv.gid, kv.me, args.GID, kv.config.Num, args.ConfigNum, kv.shardStatus)
reply.Status = ErrShardStatus
return
}
func (kv *ShardKV) Delete(args *DeleteArgs, reply *DeleteReply) {
_, isLeader := kv.rf.GetState()
if !isLeader {
return
}
kv.mu.Lock()
defer kv.mu.Unlock()
if kv.config.Num <= args.ConfigNum { // 请求者配置号比当前配置号更新或一致
for _, shard := range args.MigrateSuccessShard {
if kv.shardStatus[shard] == IrresponsibleButOwn { // 表示该数据已成功转移至其他节点
DPrintf("%d-%d send delete %d shard cmd. config num is %d", kv.gid, kv.me, shard, kv.config.Num)
kv.rf.Start(DeleteShardCmd{ConfigNum: kv.config.Num, Shard: shard}) // 删除分区数据命令
}
}
}
return
}
//
// the tester calls Kill() when a ShardKV instance won't
// be needed again. you are not required to do anything
// in Kill(), but it might be convenient to (for example)
// turn off debug output from this instance.
//
func (kv *ShardKV) Kill() {
kv.rf.Kill()
// Your code here, if desired.
close(kv.done)
}
func (kv *ShardKV) completeMigrate() bool {
for _, status := range kv.shardStatus {
if status == ResponsibleButNotOwn || status == IrresponsibleButOwn {
return false
}
}
return true
}
func (kv *ShardKV) configListenTask() { // 配置监听线程
for {
select {
case <-kv.done:
return
default:
_, isLeader := kv.rf.GetState()
kv.mu.Lock()
if isLeader && kv.completeMigrate() {
newConfig := kv.mck.Query(kv.config.Num + 1) // 只查看下一任配置
if newConfig.Num == kv.config.Num+1 {
DPrintf("%d %d add new config cmd %v ", kv.gid, kv.me, newConfig)
kv.rf.Start(newConfig) // 最多更新至下一任配置
}
}
kv.mu.Unlock()
time.Sleep(GeneralInterval)
}
}
}
func (kv *ShardKV) requestShardTask() { // 请求分区线程
for {
select {
case <-kv.done:
return
default:
_, isLeader := kv.rf.GetState()
if isLeader {
kv.mu.Lock()
for shard, status := range kv.shardStatus {
if status == ResponsibleButNotOwn {
go func(shard int, lastConfig shardctrler.Config) {
args := MigrateArgs{ConfigNum: lastConfig.Num + 1, GID: kv.gid, Shard: shard}
oldOwner := lastConfig.Shards[shard] // 向上一任拥有者请求分区数据
for _, server := range lastConfig.Groups[oldOwner] {
reply := MigrateReply{}
ok := kv.make_end(server).Call("ShardKV.Migrate", &args, &reply)
if ok && reply.Status == OK {
DPrintf("%d %d send add %d shard cmd.", kv.gid, kv.me, shard)
// 增加分区数据命令
kv.rf.Start(AddShardCmd{ConfigNum: lastConfig.Num + 1, Shard: shard, KVData: reply.KVData, ClientCache: reply.ClintCache})
return
}
}
}(shard, kv.lastConfig)
}
}
kv.mu.Unlock()
}
time.Sleep(GeneralInterval)
}
}
}
func (kv *ShardKV) notifyDeleteTask() { // 提醒其他分组删除相应分区
for {
select {
case <-kv.done:
return
default:
_, isLeader := kv.rf.GetState()
if isLeader {
kv.mu.Lock()
ownShards := []int{}
for shard, status := range kv.shardStatus {
if status == ResponsibleAndOwn || status == IrresponsibleButOwn { // 当前拥有这些分区数据
ownShards = append(ownShards, shard)
}
}
args := DeleteArgs{ConfigNum: kv.config.Num, MigrateSuccessShard: ownShards}
for gid, servers := range kv.allReplicaNode {
if gid != kv.gid {
for _, server := range servers {
reply := DeleteReply{}
go kv.make_end(server).Call("ShardKV.Delete", &args, &reply)
}
}
}
kv.mu.Unlock()
}
}
time.Sleep(GeneralInterval)
}
}
// 接受raft消息
func (kv *ShardKV) receiveTask() {
for {
select {
case <-kv.done:
return
case msg := <-kv.applyCh:
{
kv.mu.Lock()
if msg.CommandValid { // 普通的日志消息
kv.commitIndex = msg.CommandIndex
switch data := msg.Command.(type) {
case GetArgs:
shard := key2shard(data.Key)
cache := kv.clientCache[data.ClientId] // 查看相应客户端缓存
if cache.SequenceNum < data.SequenceNum && kv.shardStatus[shard] == ResponsibleAndOwn {
value, exist := kv.kvDatas[shard][data.Key]
if !exist {
kv.clientCache[data.ClientId] = ReqResult{SequenceNum: data.SequenceNum, Status: ErrNoKey}
} else {
kv.clientCache[data.ClientId] = ReqResult{SequenceNum: data.SequenceNum, Status: OK, Value: value}
}
}
case PutAppendArgs:
shard := key2shard(data.Key)
cache := kv.clientCache[data.ClientId] // 查看相应客户端缓存
if cache.SequenceNum < data.SequenceNum && kv.shardStatus[shard] == ResponsibleAndOwn {
if data.Op == "Put" {
kv.kvDatas[shard][data.Key] = data.Value
kv.clientCache[data.ClientId] = ReqResult{SequenceNum: data.SequenceNum, Status: OK}
} else {
kv.kvDatas[shard][data.Key] += data.Value
kv.clientCache[data.ClientId] = ReqResult{SequenceNum: data.SequenceNum, Status: OK}
}
}
case shardctrler.Config:
if kv.config.Num < data.Num {
DPrintf("%d %d update config.old config:%v new config:%v", kv.gid, kv.me, kv.config, data)
for i := 0; i < shardctrler.NShards; i++ {
oldOwner := kv.config.Shards[i]
newOwner := data.Shards[i]
if newOwner == kv.gid && oldOwner != kv.gid {
if oldOwner == 0 { // 第一任拥有者
kv.shardStatus[i] = ResponsibleAndOwn
kv.kvDatas[i] = make(map[string]string) // 初始化map
} else { // 等待上一任拥有者的分区数据
kv.shardStatus[i] = ResponsibleButNotOwn
}
}
if newOwner != kv.gid && oldOwner == kv.gid {
if kv.shardStatus[i] == ResponsibleAndOwn {
kv.shardStatus[i] = IrresponsibleButOwn
} else { // 不可能发生
kv.shardStatus[i] = IrresponsibleAndNotOwn
}
}
}
kv.lastConfig = kv.config
kv.config = data
for gid, servers := range data.Groups { // 更新见到的所有节点
kv.allReplicaNode[gid] = servers
}
}
case AddShardCmd:
if kv.config.Num == data.ConfigNum && kv.shardStatus[data.Shard] == ResponsibleButNotOwn { // 预期的分区数据到达
DPrintf("%d %d add new %d shard data. config num is %d", kv.gid, kv.me, data.Shard, kv.config.Num)
kv.kvDatas[data.Shard] = copyMapKV(data.KVData)
kv.shardStatus[data.Shard] = ResponsibleAndOwn
for id, res := range data.ClientCache { // 更新最新客户端结果
if kv.clientCache[id].SequenceNum < res.SequenceNum {
kv.clientCache[id] = res
}
}
}
case DeleteShardCmd:
DPrintf("before:%d %d delete %d shard data. config num is %d shard status:%v", kv.gid, kv.me, data.Shard, kv.config.Num, kv.shardStatus)
if kv.config.Num == data.ConfigNum && kv.shardStatus[data.Shard] == IrresponsibleButOwn {
kv.shardStatus[data.Shard] = IrresponsibleAndNotOwn
kv.kvDatas[data.Shard] = nil
DPrintf("after: %d %d delete %d shard data. config num is %d shard status:%v", kv.gid, kv.me, data.Shard, kv.config.Num, kv.shardStatus)
}
}
} else if msg.SnapshotValid { // 快照消息
r := bytes.NewBuffer(msg.Snapshot)
d := labgob.NewDecoder(r)
var commitIndex int
var clientCache map[int64]ReqResult
var kvDatas [shardctrler.NShards]map[string]string
var config shardctrler.Config
var shardStatus [shardctrler.NShards]ShardStatus
var allNode map[int][]string
if d.Decode(&commitIndex) != nil || d.Decode(&clientCache) != nil || d.Decode(&kvDatas) != nil || d.Decode(&config) != nil || d.Decode(&shardStatus) != nil || d.Decode(&allNode) != nil {
log.Panicf("snapshot decode error")
} else {
DPrintf("%d %d recv snapshot. shard status:%v", kv.gid, kv.me, shardStatus)
kv.commitIndex = commitIndex
kv.clientCache = clientCache
kv.kvDatas = kvDatas
kv.config = config
kv.lastConfig = kv.mck.Query(config.Num - 1)
kv.shardStatus = shardStatus
kv.allReplicaNode = allNode
// 更新lastSnapshotIndex
kv.lastSnapshotIndex = commitIndex
}
}
// 检查raft state大小,生成快照
if kv.maxraftstate > 0 && kv.persister.RaftStateSize() > kv.maxraftstate && kv.commitIndex > kv.lastSnapshotIndex {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(kv.commitIndex)
e.Encode(kv.clientCache)
e.Encode(kv.kvDatas)
// 将以下数据编码至快照
e.Encode(kv.config)
e.Encode(kv.shardStatus)
e.Encode(kv.allReplicaNode)
snapshot := w.Bytes()
kv.rf.Snapshot(kv.commitIndex, snapshot)
kv.lastSnapshotIndex = kv.commitIndex
}
kv.mu.Unlock()
}
}
}
}
//
// servers[] contains the ports of the servers in this group.
//
// me is the index of the current server in servers[].
//
// the k/v server should store snapshots through the underlying Raft
// implementation, which should call persister.SaveStateAndSnapshot() to
// atomically save the Raft state along with the snapshot.
//
// the k/v server should snapshot when Raft's saved state exceeds
// maxraftstate bytes, in order to allow Raft to garbage-collect its
// log. if maxraftstate is -1, you don't need to snapshot.
//
// gid is this group's GID, for interacting with the shardctrler.
//
// pass ctrlers[] to shardctrler.MakeClerk() so you can send
// RPCs to the shardctrler.
//
// make_end(servername) turns a server name from a
// Config.Groups[gid][i] into a labrpc.ClientEnd on which you can
// send RPCs. You'll need this to send RPCs to other groups.
//
// look at client.go for examples of how to use ctrlers[]
// and make_end() to send RPCs to the group owning a specific shard.
//
// StartServer() must return quickly, so it should start goroutines
// for any long-running work.
//
func StartServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxraftstate int, gid int, ctrlers []*labrpc.ClientEnd, make_end func(string) *labrpc.ClientEnd) *ShardKV {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(GetArgs{})
labgob.Register(PutAppendArgs{})
labgob.Register(shardctrler.Config{})
labgob.Register(AddShardCmd{})
labgob.Register(DeleteShardCmd{})
kv := new(ShardKV)
kv.me = me
kv.maxraftstate = maxraftstate
kv.make_end = make_end
kv.gid = gid
kv.ctrlers = ctrlers
// Your initialization code here.
// Use something like this to talk to the shardctrler:
// kv.mck = shardctrler.MakeClerk(kv.ctrlers)
kv.applyCh = make(chan raft.ApplyMsg)
kv.rf = raft.Make(servers, me, persister, kv.applyCh)
kv.done = make(chan struct{})
kv.persister = persister
kv.mck = shardctrler.MakeClerk(kv.ctrlers)
kv.config.Num = 0
kv.config.Groups = map[int][]string{}
kv.clientCache = make(map[int64]ReqResult)
for i := 0; i < shardctrler.NShards; i++ {
kv.shardStatus[i] = IrresponsibleAndNotOwn
}
kv.allReplicaNode = make(map[int][]string)
// 开启一系列线程
go kv.receiveTask()
go kv.configListenTask()
go kv.requestShardTask()
go kv.notifyDeleteTask()
return kv
}
















 3148
3148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











