










fio下发的请求大小不确定
问题描述
fio --filename=/dev/xxx_dev --direct=1 --rw=write --bs=1M --ioengine=libaio --iodepth=1 --runtime=60 --numjobs=1 --time_based --group_reporting --name="test xxx" --eta-newline=1
承接fio引发的一些问题,在使用blk_queue_max_hw_sectors设置最大扇区后,本以为全部搞定了,但用fio测试块设备速度时,却发现速度有时候180MB,有时候700MB,开启驱动打印后发现虽然bs设置为1M,但有时候执行下发的请求大小就不是1M,是一些奇奇怪怪的数字,nlb为3d8,6ef之类的,而且如果刚开始不是7ff,则一直不是7ff,如果刚开始是7ff,则一直是7ff。故打算找到问题的原因,并使速度一直维持在700MB。
调用栈
首先我想的是在请求大小为1M与请求大小不是1M的函数调用栈是不是有一些差异,故在驱动中插入dump_stack,输出大小为1M时的函数调用栈和不为1M的调用栈,发现调用栈一致
# 请求大小不为1MB
[ +0.000007] request received: pos=279856 bytes=368640 cur_bytes=4096 dir=W
[ +0.000002] CPU: 3 PID: 3623 Comm: fio Kdump: loaded Tainted: G OE 5.4.18-35-generic #21-KYLINOS
[ +0.000001] Hardware name: GITSTAR GITSTAR-MF20A/GM9-2665, BIOS 03.12 02/15/22 23:09:42
[ +0.000001] Call trace:
[ +0.000004] dump_backtrace+0x0/0x178
[ +0.000001] show_stack+0x14/0x20
[ +0.000002] dump_stack+0xac/0xd0
[ +0.000005] hps_queue_rq+0xf4/0x160 [Hps]
[ +0.000002] blk_mq_dispatch_rq_list+0x9c/0x5e8
[ +0.000002] blk_mq_do_dispatch_sched+0x60/0x100
[ +0.000001] blk_mq_sched_dispatch_requests+0x158/0x1b8
[ +0.000003] __blk_mq_run_hw_queue+0x90/0x158
[ +0.000001] __blk_mq_delay_run_hw_queue+0x1d4/0x1d8
[ +0.000002] blk_mq_run_hw_queue+0x9c/0x120
[ +0.000001] blk_mq_sched_insert_requests+0x84/0x150
[ +0.000002] blk_mq_flush_plug_list+0x100/0x160
[ +0.000002] blk_flush_plug_list+0xdc/0x110
[ +0.000001] blk_finish_plug+0x30/0x40
[ +0.000002] blkdev_write_iter+0xb4/0x138
[ +0.000001] aio_write+0xd8/0x180
[ +0.000002] io_submit_one+0x604/0x8a8
[ +0.000001] sys_io_submit+0x168/0x238
[ +0.000002] el0_svc_naked+0x30/0x34
[ +0.000002] push sq cmd to fifo
[ +0.000001] fifo avail: 65536
[ +0.000001] SQ info:opc b slba 44530 nlb 2cf cid 154 buf fa100000
# 请求大小为1MB
[ +0.000159] request received: pos=901120 bytes=1048576 cur_bytes=4096 dir=W
[ +0.000004] CPU: 3 PID: 3677 Comm: fio Kdump: loaded Tainted: G OE 5.4.18-35-generic #21-KYLINOS
[ +0.000001] Hardware name: GITSTAR GITSTAR-MF20A/GM9-2665, BIOS 03.12 02/15/22 23:09:42
[ +0.000001] Call trace:
[ +0.000005] dump_backtrace+0x0/0x178
[ +0.000002] show_stack+0x14/0x20
[ +0.000002] dump_stack+0xac/0xd0
[ +0.000008] hps_queue_rq+0xf4/0x160 [Hps]
[ +0.000005] blk_mq_dispatch_rq_list+0x9c/0x5e8
[ +0.000002] blk_mq_do_dispatch_sched+0x60/0x100
[ +0.000002] blk_mq_sched_dispatch_requests+0x158/0x1b8
[ +0.000002] __blk_mq_run_hw_queue+0x90/0x158
[ +0.000002] __blk_mq_delay_run_hw_queue+0x1d4/0x1d8
[ +0.000002] blk_mq_run_hw_queue+0x9c/0x120
[ +0.000001] blk_mq_sched_insert_requests+0x84/0x150
[ +0.000002] blk_mq_flush_plug_list+0x100/0x160
[ +0.000002] blk_flush_plug_list+0xdc/0x110
[ +0.000002] blk_finish_plug+0x30/0x40
[ +0.000002] blkdev_write_iter+0xb4/0x138
[ +0.000002] aio_write+0xd8/0x180
[ +0.000002] io_submit_one+0x604/0x8a8
[ +0.000003] sys_io_submit+0x168/0x238
[ +0.000003] el0_svc_naked+0x30/0x34
[ +0.000214] send sq cmd
[ +0.000002] SQ info:opc b slba dc000 nlb 7ff cid 50 buf fa100000
回顾nvme_set_queue_limits函数
以nvme驱动作为对照组,在nvme驱动中插入打印语句,看nvme驱动有没有类似情况,没发现这种情况,倒是结束时会出现一些其他大小的请求。
然后想想,不如把nvme_set_queue_limits函数设置的函数都设置一下吧。
首先输出一些nvme驱动中各set函数的参数,照猫画虎在自己写的驱动里用一下
static void nvme_set_queue_limits(struct nvme_ctrl *ctrl,
struct request_queue *q)
{
bool vwc = false;
if (ctrl->max_hw_sectors) {
u32 max_segments =
(ctrl->max_hw_sectors / (ctrl->page_size >> 9)) + 1;
max_segments = min_not_zero(max_segments, ctrl->max_segments);
blk_queue_max_hw_sectors(q, ctrl->max_hw_sectors);
blk_queue_max_segments(q, min_t(u32, max_segments, USHRT_MAX));
printk(KERN_WARNING "max_hw_sectors %d max_segments %d",
ctrl->max_hw_sectors,
min_t(u32, max_segments, USHRT_MAX));
}
if ((ctrl->quirks & NVME_QUIRK_STRIPE_SIZE) &&
is_power_of_2(ctrl->max_hw_sectors))
blk_queue_chunk_sectors(q, ctrl->max_hw_sectors);
blk_queue_virt_boundary(q, ctrl->page_size - 1);
if (ctrl->vwc & NVME_CTRL_VWC_PRESENT)
vwc = true;
blk_queue_write_cache(q, vwc, vwc);
printk(KERN_WARNING "mask %d vwc %d", ctrl->page_size - 1, vwc);
}
[ +0.002594] max_hw_sectors 2048 max_segments 127
[ +0.000002] mask 4095 vwc 0
相关函数介绍
/**
* blk_queue_max_segments - set max hw segments for a request for this queue
* @q: the request queue for the device
* @max_segments: max number of segments
*
* Description:
* Enables a low level driver to set an upper limit on the number of
* hw data segments in a request.
**/
void blk_queue_max_segments(struct request_queue *q, unsigned short max_segments);
/**
* blk_queue_virt_boundary - set boundary rules for bio merging
* @q: the request queue for the device
* @mask: the memory boundary mask
**/
void blk_queue_virt_boundary(struct request_queue *q, unsigned long mask);
/**
* blk_queue_write_cache - configure queue's write cache
* @q: the request queue for the device
* @wc: write back cache on or off
* @fua: device supports FUA writes, if true
*
* Tell the block layer about the write cache of @q.
*/
void blk_queue_write_cache(struct request_queue *q, bool wc, bool fua);
驱动设置前后成员值对比
PRINT_INFO("before: max sector:%d max seg:%d mask:%d", queue_max_sectors(xxx_dev->queue),
queue_max_segments(xxx_dev->queue), queue_virt_boundary(xxx_dev->queue));
blk_queue_max_hw_sectors(xxx_dev->queue, (1 << 20) / (1 << 9)); // 最大1M数据
blk_queue_max_segments(xxx_dev->queue, 127);
blk_queue_virt_boundary(xxx_dev->queue, 4096 - 1);
blk_queue_write_cache(xxx_dev->queue, 0, 0);
PRINT_INFO("after: max sector:%d max seg:%d mask:%d", queue_max_sectors(xxx_dev->queue),
queue_max_segments(xxx_dev->queue), queue_virt_boundary(xxx_dev->queue));
[ +0.000073] before: max sector:255 max seg:128 mask:0
[ +0.000002] after: max sector:2048 max seg:127 mask:4095
可惜设置完成后这种情况还是会出现,过几天再研究一下, 从函数调用栈 起始扇区 生成的请求大小等方面找原因。
研究内核调用栈
[ +0.000005] hps_queue_rq+0xf4/0x160 [Hps]
[ +0.000002] blk_mq_dispatch_rq_list+0x9c/0x5e8
[ +0.000002] blk_mq_do_dispatch_sched+0x60/0x100
[ +0.000001] blk_mq_sched_dispatch_requests+0x158/0x1b8
[ +0.000003] __blk_mq_run_hw_queue+0x90/0x158
[ +0.000001] __blk_mq_delay_run_hw_queue+0x1d4/0x1d8
[ +0.000002] blk_mq_run_hw_queue+0x9c/0x120
[ +0.000001] blk_mq_sched_insert_requests+0x84/0x150
[ +0.000002] blk_mq_flush_plug_list+0x100/0x160
[ +0.000002] blk_flush_plug_list+0xdc/0x110
[ +0.000001] blk_finish_plug+0x30/0x40
[ +0.000002] blkdev_write_iter+0xb4/0x138
[ +0.000001] aio_write+0xd8/0x180
[ +0.000002] io_submit_one+0x604/0x8a8
[ +0.000001] sys_io_submit+0x168/0x238
[ +0.000002] el0_svc_naked+0x30/0x34
对于以上调用栈从后往前推,看请求大小的变化
static inline unsigned int blk_rq_bytes(const struct request *rq)
{
return rq->__data_len;
}
/*
* Returns true if we did some work AND can potentially do more.
*/
bool blk_mq_dispatch_rq_list(struct request_queue *q, struct list_head *list,
bool got_budget)
{
struct blk_mq_hw_ctx *hctx;
struct request *rq, *nxt;
/*
* Now process all the entries, sending them to the driver.
*/
do {
struct blk_mq_queue_data bd;
rq = list_first_entry(list, struct request, queuelist); // 从链表中取出相应请求
hctx = rq->mq_hctx;
list_del_init(&rq->queuelist);
bd.rq = rq;
/*
* Flag last if we have no more requests, or if we have more
* but can't assign a driver tag to it.
*/
if (list_empty(list))
bd.last = true;
else {
nxt = list_first_entry(list, struct request, queuelist);
bd.last = !blk_mq_get_driver_tag(nxt);
}
ret = q->mq_ops->queue_rq(hctx, &bd); // 调用驱动定义的queue_rq函数
if (unlikely(ret != BLK_STS_OK)) { // 返回错误,调用blk_mq_end_request函数
errors++;
blk_mq_end_request(rq, BLK_STS_IOERR);
continue;
}
queued++;
} while (!list_empty(list));
// 看到注释中的scsi很奇怪
/*
* Only SCSI implements .get_budget and .put_budget, and SCSI restarts
* its queue by itself in its completion handler, so we don't need to
* restart queue if .get_budget() fails to get the budget.
*
* Returns -EAGAIN if hctx->dispatch was found non-empty and run_work has to
* be run again. This is necessary to avoid starving flushes.
*/
static int blk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx)
{
struct request_queue *q = hctx->queue;
struct elevator_queue *e = q->elevator;
LIST_HEAD(rq_list);
do {
struct request *rq;
if (e->type->ops.has_work && !e->type->ops.has_work(hctx))
break;
rq = e->type->ops.dispatch_request(hctx);
/*
* Now this rq owns the budget which has to be released
* if this rq won't be queued to driver via .queue_rq()
* in blk_mq_dispatch_rq_list().
*/
list_add(&rq->queuelist, &rq_list);
} while (blk_mq_dispatch_rq_list(q, &rq_list, true));
return ret;
}
看到blk_mq_do_dispatch_sched注释中的SCSI,就觉得有点不对劲,故查看nvme驱动调用栈与本驱动调用第一个不同的函数
[ +0.000002] nvme_queue_rq.cold+0x28/0x97 [nvme]
[ +0.000002] __blk_mq_try_issue_directly+0x116/0x1c0
[ +0.000001] blk_mq_request_issue_directly+0x4b/0xe0
[ +0.000001] blk_mq_try_issue_list_directly+0x46/0xb0
[ +0.000001] blk_mq_sched_insert_requests+0xae/0x100
[ +0.000001] blk_mq_flush_plug_list+0x1e8/0x290
[ +0.000001] blk_flush_plug_list+0xe3/0x110
[ +0.000001] blk_finish_plug+0x26/0x34
[ +0.000001] blkdev_write_iter+0xbd/0x140
[ +0.000001] aio_write+0xec/0x1a0
[ +0.000005] hps_queue_rq+0xf4/0x160 [Hps]
[ +0.000002] blk_mq_dispatch_rq_list+0x9c/0x5e8
[ +0.000002] blk_mq_do_dispatch_sched+0x60/0x100
[ +0.000001] blk_mq_sched_dispatch_requests+0x158/0x1b8
[ +0.000003] __blk_mq_run_hw_queue+0x90/0x158
[ +0.000001] __blk_mq_delay_run_hw_queue+0x1d4/0x1d8
[ +0.000002] blk_mq_run_hw_queue+0x9c/0x120
[ +0.000001] blk_mq_sched_insert_requests+0x84/0x150
[ +0.000002] blk_mq_flush_plug_list+0x100/0x160
[ +0.000002] blk_flush_plug_list+0xdc/0x110
[ +0.000001] blk_finish_plug+0x30/0x40
[ +0.000002] blkdev_write_iter+0xb4/0x138
[ +0.000001] aio_write+0xd8/0x180
// 查看nvme回溯栈与本驱动回溯栈的第一个不同函数
void blk_mq_sched_insert_requests(struct blk_mq_hw_ctx *hctx,
struct blk_mq_ctx *ctx,
struct list_head *list, bool run_queue_async)
{
struct elevator_queue *e;
struct request_queue *q = hctx->queue;
/*
* blk_mq_sched_insert_requests() is called from flush plug
* context only, and hold one usage counter to prevent queue
* from being released.
*/
percpu_ref_get(&q->q_usage_counter);
e = hctx->queue->elevator;
if (e && e->type->ops.insert_requests)
e->type->ops.insert_requests(hctx, list, false);
else {
/*
* try to issue requests directly if the hw queue isn't
* busy in case of 'none' scheduler, and this way may save
* us one extra enqueue & dequeue to sw queue.
*/
if (!hctx->dispatch_busy && !e && !run_queue_async) {
blk_mq_try_issue_list_directly(hctx, list); // nvme驱动
if (list_empty(list))
goto out;
}
blk_mq_insert_requests(hctx, ctx, list);
}
blk_mq_run_hw_queue(hctx, run_queue_async); // 本驱动
out:
percpu_ref_put(&q->q_usage_counter);
}
可以看出区分点在于hctx->queue->elevator
查看请求队列初始化时对elevator成员的处理
// 初始化队列时是否设置elevator成员
struct request_queue *blk_mq_init_queue(struct blk_mq_tag_set *set)
{
struct request_queue *uninit_q, *q;
uninit_q = blk_alloc_queue_node(GFP_KERNEL, set->numa_node);
/*
* Initialize the queue without an elevator. device_add_disk() will do
* the initialization.
*/
q = blk_mq_init_allocated_queue(set, uninit_q, false);
return q;
}
struct request_queue *blk_mq_init_allocated_queue(struct blk_mq_tag_set *set,
struct request_queue *q,
bool elevator_init)
{
if (elevator_init)
elevator_init_mq(q);
}
elevator_init为false,并不初始化elevator成员
全局搜索elevator_init_mq函数使用情况
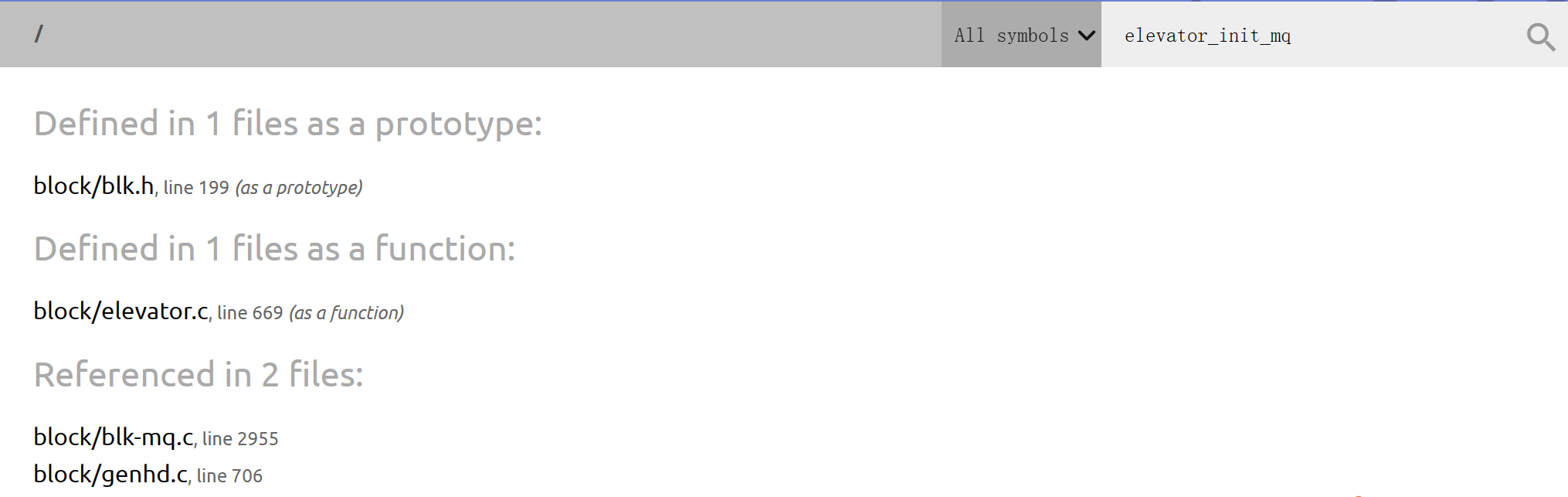
另外一次使用为:
// 在另外一处使用elevator_init_mq函数
void device_add_disk(struct device *parent, struct gendisk *disk,
const struct attribute_group **groups)
{
__device_add_disk(parent, disk, groups, true);
}
/**
* __device_add_disk - add disk information to kernel list
* @parent: parent device for the disk
* @disk: per-device partitioning information
* @groups: Additional per-device sysfs groups
* @register_queue: register the queue if set to true
*
* This function registers the partitioning information in @disk
* with the kernel.
*
* FIXME: error handling
*/
static void __device_add_disk(struct device *parent, struct gendisk *disk,
const struct attribute_group **groups,
bool register_queue)
{
/*
* The disk queue should now be all set with enough information about
* the device for the elevator code to pick an adequate default
* elevator if one is needed, that is, for devices requesting queue
* registration.
*/
if (register_queue)
elevator_init_mq(disk->queue);
}
nr_hw_queues不等于1则e=NULL
/*
* For a device queue that has no required features, use the default elevator
* settings. Otherwise, use the first elevator available matching the required
* features. If no suitable elevator is find or if the chosen elevator
* initialization fails, fall back to the "none" elevator (no elevator).
*/
void elevator_init_mq(struct request_queue *q)
{
struct elevator_type *e;
if (!elv_support_iosched(q))
return;
if (unlikely(q->elevator))
return;
if (!q->required_elevator_features)
e = elevator_get_default(q);
else
e = elevator_get_by_features(q);
}
/*
* For single queue devices, default to using mq-deadline. If we have multiple
* queues or mq-deadline is not available, default to "none".
*/
static struct elevator_type *elevator_get_default(struct request_queue *q)
{
if (q->nr_hw_queues != 1)
return NULL;
return elevator_get(q, "mq-deadline", false);
}
相关博客,可以简要阅读一下:
Linux block 层详解(3)- IO请求处理过程
mq-deadline调度器原理及源码分析
Multi-Queue Block IO Queueing Mechanism (blk-mq)
尝试直接将nr_hw_queues设置成2,看是否可以解决该问题且不产生新的问题
BLK_MQ_F_NO_SCHED
在驱动中打印elevator相关信息,发现是bfq而不是mq-deadline
PRINT_INFO("elevator:%p name %s",disk->queue->elevator,disk->queue->elevator->type->elevator_name);
elevator:00000000e697a3e1 name bfq
查看nvme驱动queue如何设置使得elevator为NULL (admin queue硬件队列为1)
static int nvme_alloc_admin_tags(struct nvme_dev *dev)
{
if (!dev->ctrl.admin_q) {
dev->admin_tagset.ops = &nvme_mq_admin_ops;
dev->admin_tagset.nr_hw_queues = 1;
dev->admin_tagset.queue_depth = NVME_AQ_MQ_TAG_DEPTH;
dev->admin_tagset.timeout = ADMIN_TIMEOUT;
dev->admin_tagset.numa_node = dev_to_node(dev->dev);
dev->admin_tagset.cmd_size = nvme_pci_cmd_size(dev, false);
dev->admin_tagset.flags = BLK_MQ_F_NO_SCHED; // 关键一行
dev->admin_tagset.driver_data = dev;
if (blk_mq_alloc_tag_set(&dev->admin_tagset))
return -ENOMEM;
dev->ctrl.admin_tagset = &dev->admin_tagset;
dev->ctrl.admin_q = blk_mq_init_queue(&dev->admin_tagset);
if (IS_ERR(dev->ctrl.admin_q)) {
blk_mq_free_tag_set(&dev->admin_tagset);
return -ENOMEM;
}
if (!blk_get_queue(dev->ctrl.admin_q)) {
nvme_dev_remove_admin(dev);
dev->ctrl.admin_q = NULL;
return -ENODEV;
}
} else
blk_mq_unquiesce_queue(dev->ctrl.admin_q);
return 0;
}
查看BLK_MQ_F_NO_SCHED使用
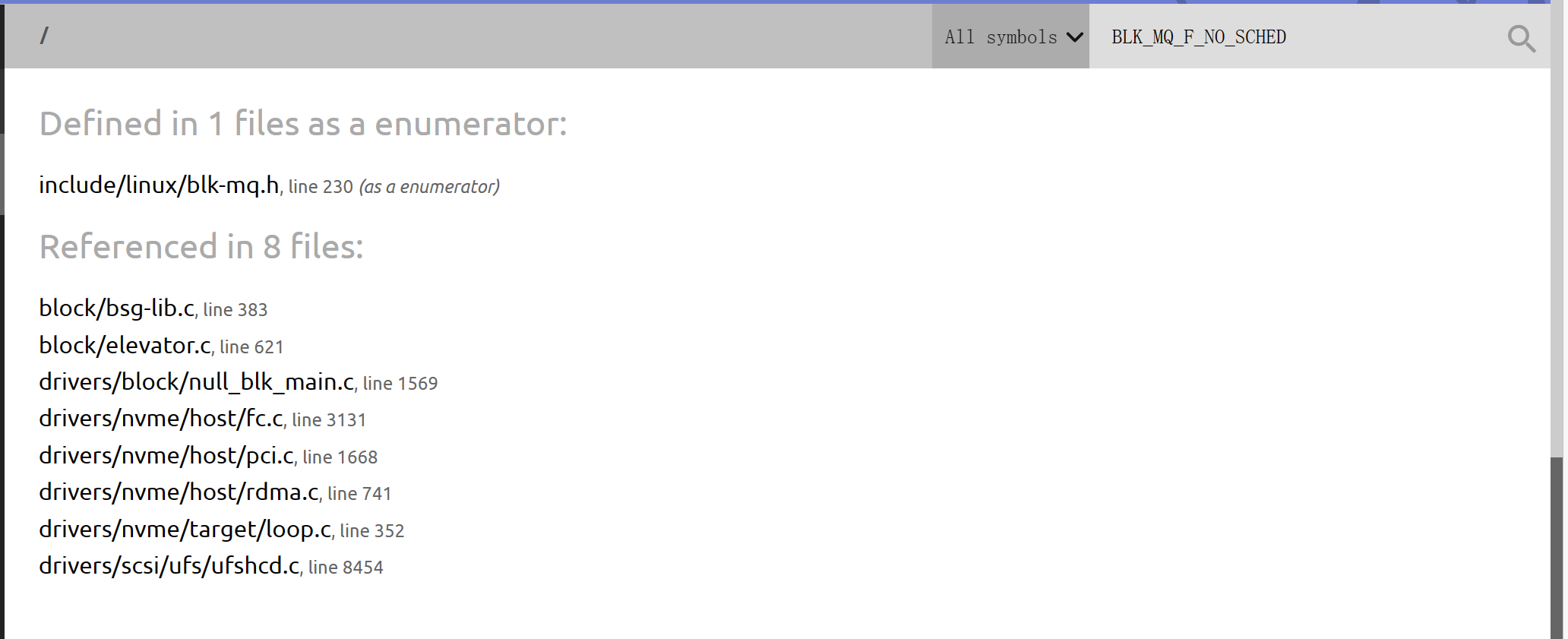
static inline bool elv_support_iosched(struct request_queue *q)
{
if (!q->mq_ops ||
(q->tag_set && (q->tag_set->flags & BLK_MQ_F_NO_SCHED)))
return false;
return true;
}
void elevator_init_mq(struct request_queue *q)
{
struct elevator_type *e;
if (!elv_support_iosched(q))
return;
也就是说设置一下BLK_MQ_F_NO_SCHED就可以了
设置完成后再次打印相关信息,发现 %p与%llx的结果不一样 (飞腾处理器+麒麟操作系统)
PRINT_INFO("elevator:%llx",disk->queue->elevator);
// 输出 elevator:0
PRINT_INFO("elevator:%p",disk->queue->elevator);
// 输出 elevator:00000000353e5884
PRINT_INFO("elevator:%p",disk->queue->elevator);
int* p = NULL;
PRINT_INFO("%llx %p",p,p);
/* 输出
elevator:000000009037421b
0 000000009037421b
*/
ubuntu虚拟机输出
#include <stdio.h>
int main() {
int a = 123;
int* p = 0x0;
int c = 0x1234;
int* p_c = (int*)0x12345678;
printf("p: %p %p %p\n", a, p, 0x1234);
printf("llx: %llx %llx %llx\n", a, p, 0x1234);
printf("p: %p %p %p\n", &a, &p, 0x1234);
printf("llx: %llx %llx %llx\n", &a, &p, 0x1234);
printf("p: %p %p\n", c, p_c);
printf("llx: %llx %llx\n", c, p_c);
}
/*
p: 0x7b (nil) 0x1234
llx: 7b 0 1234
p: 0x7fff635f9fd0 0x7fff635f9fd8 0x1234
llx: 7fff635f9fd0 7fff635f9fd8 1234
p: 0x1234 0x12345678
llx: 1234 12345678
*/
有些时候输出不一样,有些时候输出一样,故建议不要用%p,用%llx保险一点
不过倒霉的是,即使设置了BLK_MQ_F_NO_SCHED,函数调用栈也变得与nvme驱动一致,还是会出现不一致请求大小的情况。
打算从请求起始扇区号,请求大小修改轨迹之类的点尝试解决该问题
















 9506
9506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











