







一.sql 示例
假设有如下数据
SELECT
"1" as id,"001" as card,1 as sequenceNo, 1 as resultStatus
UNION ALL
SELECT
"2" as id,"001" as card,2 as sequenceNo, 2 as resultStatus
UNION ALL
SELECT
"3" as id,"001" as card,3 as sequenceNo, 3 as resultStatus
UNION ALL
SELECT
"4" as id,"002" as card,1 as sequenceNo, 1 as resultStatus
UNION ALL
SELECT
"5" as id,"002" as card,2 as sequenceNo, 3 as resultStatus
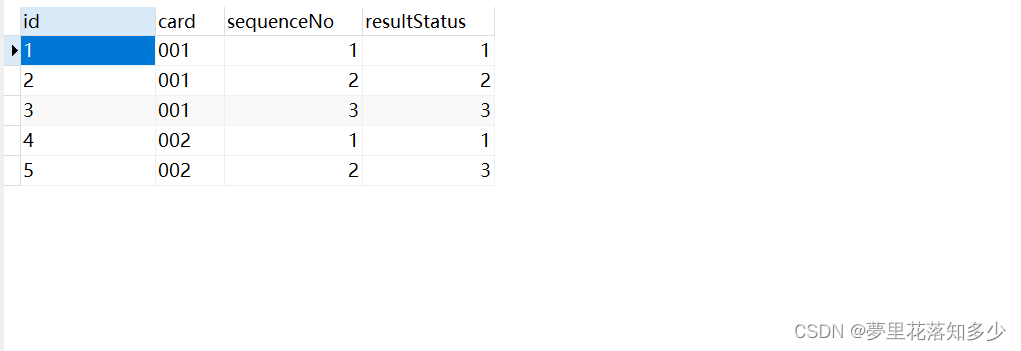
需要拿到每个card最大的sequenceNo,那么sql这么写
SELECT max(sequenceNo),aa.card from aa GROUP BY aa.card
es 的 写法
{
"from": 0,
"size": 0,
"query": {
"bool": {
"must": [
{
"terms": {
"card": [
"aa",
""
]
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"aggregations": {
"cardAsName": {
"terms": {
"field": "card",
"size": 9999,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false
},
"aggregations": {
"maxSequenceNo": {
"max": {
"field": "sequenceNo"
}
}
}
}
}
}
es代码说明
size: 表示不需要查询的hits结果,因为group by 的结果集在aggregations 的 buckets
aggregations: 聚合查询,可以嵌套,第一层是group by ,第二层可以理解是对这个group by 的结果进行max,和上面的sql效果一样
maxSequenceNo:别名,随便取
max: 代表是用的 max 函数
结果示例
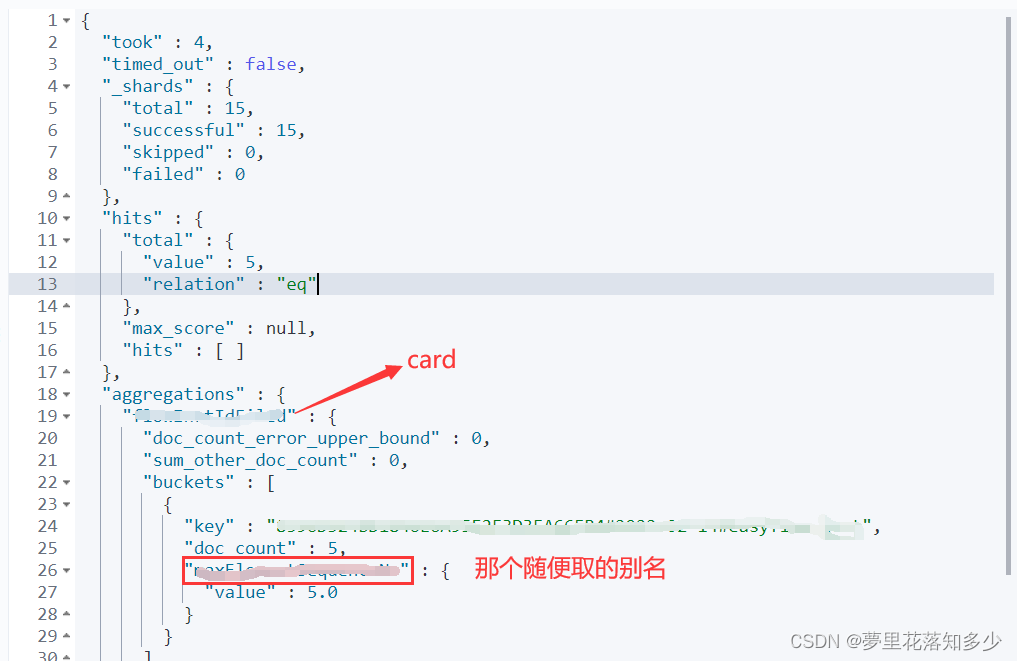
java查询代码示例
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//聚合查询,不需要hits
searchSourceBuilder.from(0);
searchSourceBuilder.size(0);
TermsAggregationBuilder termsBuilder = AggregationBuilders.terms("groupName")
.field("field1")
.size(9999);
termsBuilder.subAggregation(AggregationBuilders.max("maxNo")
.field("field2"));
List<FieldSortBuilder> fieldSorts = new ArrayList<>();
//按大小排序
fieldSorts.add(new FieldSortBuilder("maxNo").order(SortOrder.DESC));
termsBuilder.subAggregation(new BucketSortPipelineAggregationBuilder("bucket_field", fieldSorts)
//这里才是真正的分页参数
.from(request.getOffsetStart())
.size(request.getPageSize()));
searchSourceBuilder.aggregation(termsBuilder);
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
searchSourceBuilder.query(boolQueryBuilder);
SearchRequest searchRequest = new SearchRequest("you es index ");
SearchRequest searchRequest = new SearchRequest(index);
SearchResponse source = searchRequest.source(searchSourceBuilder);
//结果处理
Terms terms = (Terms) source.getAggregations()
.asMap()
.get("groupName");
List<? extends Terms.Bucket> termsBuckets = terms.getBuckets();
for (Terms.Bucket termsBucket : termsBuckets) {
String key = termsBucket.getKeyAsString();
ParsedMax parsedMax = (ParsedMax) termsBucket.getAggregations()
.asMap()
.get("maxNo");
long maxNo = (long) parsedMax.getValue();
}
如果需要返回其他字段,需要 结合 top_hits 取第一条文档
JAVA代码示例
//对结果top取第一条
TopHitsAggregationBuilder topHitsAggregationBuilder = AggregationBuilders.topHits("TOP_HIT_NO_NAME")
.from(0)
.size(1)
.fetchSource(new String[] {"field1",
"field2"}, null)
.sort(new FieldSortBuilder("field1").order(SortOrder.DESC)
.unmappedType("long"));
//解析示例
SearchResponse source = es结果;
Terms terms = (Terms) source.getAggregations()
.asMap()
.get(FLOW_INSTANCE_ID_ANOTHER_NAME);
Terms terms = (Terms) source.getAggregations()
.asMap()
.get("groupName");
List<? extends Terms.Bucket> termsBuckets = terms.getBuckets();
for (Terms.Bucket termsBucket : termsBuckets) {
String key= termsBucket.getKeyAsString();
ParsedTopHits parsedTopHits = (ParsedTopHits) termsBucket.getAggregations()
.asMap()
.get("TOP_HIT_NO_NAME");
SearchHit hit = parsedTopHits.getHits()
.getHits()[0];
Object flowNodeExecStatus = hit.getSourceAsMap()
.get("field1");
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









