







自己总结了常用的部分算子,方便自己理解和查阅
Spark RDD算子列表
1. collectAsMap
2.count,countByKey,countByValue
3. filter,filterByRange
4.flatMapValues
5.foldByKey
6.foreachPartition, foreach
7.keyBy ,keys,values
8.aggregate ,aggregateByKey
9.mapPartitionsWithIndex
10.reduceByKey和groupByKey区别
1.collectAsMap
scala> val rdd = sc.parallelize(List(("a", 1), ("b", 2)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[7] at parallelize at <console>:27
scala> rdd.collectAsMap
res5: scala.collection.Map[String,Int] = Map(b -> 2, a -> 1)
scala> 2.count,countByKey,countByValue
scala> val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> rdd1.count //个数长度
res0: Long = 5
scala> rdd1.countByKey
res1: scala.collection.Map[String,Long] = Map(a -> 1, b -> 2, c -> 2)
scala> rdd1.countByValue //这个有点特别
res2: scala.collection.Map[(String, Int),Long] = Map((b,2) -> 2, (c,2) -> 1, (a,1) -> 1, (c,1) -> 1)3. filter,filterByRange
filter是符合条件的留下
filterByRange(key1,key2) 在key1和key2之间(包括key1和key2)的留下
scala> val rdd1 = sc.parallelize(List(("e", 5), ("c", 3), ("d", 4), ("c", 2), ("a", 1)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[12] at parallelize at <console>:27
scala> val rdd3=rdd1.filter(_._2>3).collect
rdd3: Array[(String, Int)] = Array((e,5), (d,4))
scala> val rdd2 = rdd1.filterByRange("b", "d") //是先排好序,区间是前闭后闭
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[14] at filterByRange at <console>:29
scala> rdd2.collect
res6: Array[(String, Int)] = Array((c,3), (d,4), (c,2))
scala> 4.flatMapValues
flatMapValue:能把
key="a" value="1 2" =>
key=“a” "1"
key="a" "2"
scala> val rdd3 = sc.parallelize(List(("a", "1 2"), ("b", "3 4")))
rdd3: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[21] at parallelize at <console>:27
scala> rdd3.flatMapValues(_.split(" ")).collect
res10: Array[(String, String)] = Array((a,1), (a,2), (b,3), (b,4))5.foldByKey
foldByKey:相同的key进入一组,相同key对应的value可以实现字符串的拼接
scala> val rdd1 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[25] at parallelize at <console>:27
scala> val rdd2=rdd1.map(x=>(x.length,x))
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[26] at map at <console>:29
scala> rdd2.collect
res12: Array[(Int, String)] = Array((3,dog), (4,wolf), (3,cat), (4,bear))
scala> val rdd3=rdd2.foldByKey("")(_+_).collect
rdd3: Array[(Int, String)] = Array((4,wolfbear), (3,dogcat))
scala> 6.foreachPartition, foreach
与map方法类似,map是对rdd中的每一个元素进行操作,而mapPartitions(foreachPartition)则是对rdd中的每个分区的迭代器进行操作。如果在map过程中需要频繁创建额外的对象(例如将rdd中的数据通过jdbc写入
数据库
,map需要为每个元素创建一个链接而mapPartition为每个partition创建一个链接),则mapPartitions效率比map高的多。
7.keyBy ,keys,values
keyBy:以传入的参数作为key,以原来的值作为value
scala> val rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[32] at parallelize at <console>:27
scala> val rdd2 = rdd1.keyBy(_.length)
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[33] at keyBy at <console>:29
scala> rdd2.collect
res14: Array[(Int, String)] = Array((3,dog), (6,salmon), (6,salmon), (3,rat), (8,elephant))
以第一个字母作为key
scala> val rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[38] at parallelize at <console>:27
scala> val rdd2 = rdd1.keyBy(_(0))
rdd2: org.apache.spark.rdd.RDD[(Char, String)] = MapPartitionsRDD[39] at keyBy at <console>:29
scala> rdd2.collect
res17: Array[(Char, String)] = Array((d,dog), (s,salmon), (s,salmon), (r,rat), (e,elephant))keys,values
keys是把所有的key都收集起来
values是把所有的value都收集起来
scala> val rdd1 = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> val rdd2 = rdd1.map(x => (x.length, x))
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[1] at map at <console>:29
scala> rdd2.keys.collect
res0: Array[Int] = Array(3, 5, 4, 3, 7, 5)
scala> rdd2.values.collect
res1: Array[String] = Array(dog, tiger, lion, cat, panther, eagle)8.aggregate ,aggregateByKey
这二个比较重要:
8.1aggregate
aggregate:
1.是可以给你一个对每个区内计算的机会,它比reduceBy更灵活
2.aggregate(0)(_+_,_+_) 0是默认值 第一个参数是
区内计算 第二个参数是不同区内汇总
3.初始值问题: 有n个分区,要执行n+1次
理解初始值
scala> val rdd1=sc.parallelize(List(-1,-2,-3,4),2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:27
scala> rdd1.aggregate(0)(math.max(_,_),_+_)
res8: Int = 4
第二个分区的值为: 0 -3 4
聚合值为 : 0 0 4
最后的值为 0+0+4=4
理解任务的并行
scala> val rdd3 = sc.parallelize(List("12","23","345","4567"),2)
rdd3: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[14] at parallelize at <console>:27
scala> rdd3.aggregate("")((x,y) => math.max(x.length, y.length).toString, (x,y) => x + y)
res10: String = 24结果:可能是24,也可能是42,因为二个任务并行,说不定那个任务先执行完毕
aggregate 入门题目
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:27
scala> rdd1.aggregate(0)(_+_, _+_)
res3: Int = 45
深入理解aggregate初始值
scala> val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[6] at parallelize at <console>:27
scala> rdd2.aggregate("|")(_ + _, _ + _)
res5: String = ||abc|def
可以抽象的理解第一个分区的初始值: "|" "d" "e" "f" 第二个分区计算结果: |def
可以抽象的理解汇总分区的初始值: "|" "abc" "def" 汇总结果 :| +|abc+|def
aggregate 经典题目
scala> val rdd3 = sc.parallelize(List("12","23","345","4567"),2)
rdd3: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[8] at parallelize at <console>:27
scala> rdd3.aggregate("")((x,y) => math.max(x.length, y.length).toString, (x,y) => x + y)
res7: String = 24
scala>
scala> val rdd4 = sc.parallelize(List("12","23","345",""),2)
rdd4: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[9] at parallelize at <console>:27
scala> rdd4.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
res8: String = 10
scala>
scala> val rdd5 = sc.parallelize(List("12","23","","345"),2)
rdd5: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[10] at parallelize at <console>:27
scala> rdd5.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
res9: String = 11提一个概念:函数的完整性
结果为:10或者01
分析:第一个分区:“” “12” “23”
不是从三个钟选最小的再toString 而是两两比较toString再去第三个比较
8.2 aggregateByKey
根据相同的key进行区内可以计算
scala> val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
pairRDD: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[14] at parallelize at <console>:27
scala> def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
| iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
| }
func2: (index: Int, iter: Iterator[(String, Int)])Iterator[String]
scala> pairRDD.mapPartitionsWithIndex(func2).collect
res13: Array[String] = Array([partID:0, val: (cat,2)], [partID:0, val: (cat,5)], [partID:0, val: (mouse,4)], [partID:1, val: (cat,12)], [partID:1, val: (dog,12)], [partID:1, val: (mouse,2)])
scala> pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
res14: Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,6))
scala> val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
pairRDD: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[6] at parallelize at <console>:27
scala> pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect
res6: Array[(String, Int)] = Array((dog,100), (cat,200), (mouse,200))
第一个分区正常值:(cat ,(2,5)) (mouse,4)
考虑默认值情况:(cat ,(2,5,100)) (mouse,(4,100))
第一个分区计算完结果 :(cat ,100)(mouse ,100)
第二个分区正常值:(cat ,12) (mouse,2) (dog,12)
考虑默认值情况:(cat ,(12,100)) (mouse,(2,100)) (dog,(12,100))
第二个分区计算完结果 :(cat ,100)(mouse ,100)(dog,100))
注意汇总阶段不需要考虑默认值
第三阶段计算前:(cat ,100)(mouse ,100) (cat ,100)(mouse ,100)(dog,100))
第三阶段结算后:(cat ,200)(mouse ,200)(dog,100))
总结aggregate和aggreateByKey区别:
总结aggregate和aggreateByKey区别:
aggregate在汇总阶段会考虑默认值
aggreateByKey在汇总阶段不会考虑默认值

![]()
![]()
参考:http://blog.csdn.net/zongzhiyuan/article/details/49965021
9.mapPartitionsWithIndex
mapPartitionsWithIndex 可以查看每个分区的内容
1.首先自定义一个函数func
2.mapPartitionsWithIndex(func)
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> rdd1.mapPartitionsWithIndex(func1).collect
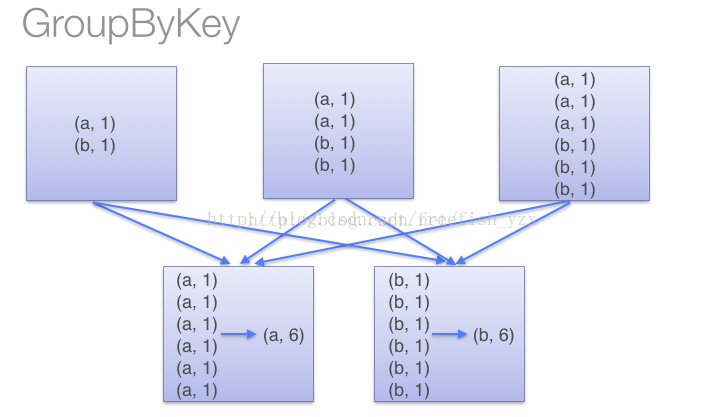
res0: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:0, val: 4], [partID:1, val: 5], [partID:1, val: 6], [partID:1, val: 7], [partID:1, val: 8], [partID:1, val: 9])10.reduceByKey和groupByKey区别
groupByKey不在每个区内计算,直接去汇总
reduceByKey在每个区内计算,再去汇总
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)、combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html














 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









