







1、爬虫工具和服务
:https://zhuanlan.zhihu.com/p/57678048
Chrome 扩展
- Web Scraper:http://webscraper.io/
- Data Scraper:https://data-miner.io/
- Listly:https://listly.io/
- AnyPicker-可视化爬虫:https://app.anypicker.com/pricing
- 迷你派采集器(新加坡公司开发,支持中文):https://doc.minirpa.net/zh/Management.html
框架
- Scrapy:https://scrapy.org/
- PySpider:https://github.com/binux/pyspider
- Apify:https://sdk.apify.com/
商业服务
- Parsehub:https://www.parsehub.com/
- http://Dexi.io:https://dexi.io/
- Octparse:https://www.octoparse.com/
- Content Grabber:http://www.contentgrabber.com/
- Mozenda:https://www.mozenda.com/
- ScraperAPI:https://www.scraperapi.com/
- Diffbot:https://www.diffbot.com/
- http://Import.io:https://www.import.io/
- http://Embed.lyhttps://embed.ly/
- ScrapeStorm https://www.scrapestorm.com/
- Shenjianshou https://www.shenjian.io/
- Zaoshu https://zaoshu.io/
实用的数据挖掘、傻瓜式爬虫工具:https://www.zhihu.com/question/352317943
Python 爬虫工具列表:https://zhuanlan.zhihu.com/p/399917739
2、Web Scraper 教程
Web Scraper 官网:https://webscraper.io/
有关webscraper的问题,看这个就够了(建议收藏):
:https://zhuanlan.zhihu.com/p/34104808
:https://blog.csdn.net/biggbang/article/details/86251526
web scraper 入门到精通之路:https://zhuanlan.zhihu.com/p/89551741
Web Scraper 系列教程:https://www.cnblogs.com/web-scraper/tag/web%20scraper/
Web Scraper 高级用法
- 如何导入别人已经写好的 Web Scraper 爬虫__06:https://www.cnblogs.com/web-scraper/p/import_export_sitemap.html
- 抓取多条内容__07:https://www.cnblogs.com/web-scraper/p/web_scraper_use_element_selector.html
- 翻页抓取「点击 更多按钮 进行翻页」__08:https://www.cnblogs.com/web-scraper/p/web_scraper_start_element_click.html
- 自动控制抓取数量 & Web Scraper 父子选择器__09:https://www.cnblogs.com/web-scraper/p/web_scraper_jiqiao.html
- 翻页抓取「滚动加载,瀑布流」类型网页__10:https://www.cnblogs.com/web-scraper/p/web_scraper_element_scroll_down.html
- 抓取表格数据__11:https://www.cnblogs.com/web-scraper/p/web_scraper_table.html
- 翻页抓取分页器翻页的网页__12:https://www.cnblogs.com/web-scraper/p/web_scraper_element_click_once.html
- 抓取二级网面__13:https://www.cnblogs.com/web-scraper/p/web_scraper_detail_page.html
- 利用 Link 选择器翻页__14:https://www.cnblogs.com/web-scraper/p/web-scraper-fanye-link.html
- CSS 选择器的使用__15:https://www.cnblogs.com/web-scraper/p/web-scraper-css.html
- 抓取属性信息__16:https://www.cnblogs.com/web-scraper/p/web-scraper-element-attribute.html
- 利用正则表达式筛选文本信息__17:https://www.cnblogs.com/web-scraper/p/web-scraper-regex.html
- 使用 CouchDB 存储数据__18:https://www.cnblogs.com/web-scraper/p/web-scraper-couchdb.html
安装 Web Scraper
因为 Web Scraper 是 Chrome 浏览器插件,当然是首推使用 Chrome,为了减少兼容性问题最好安装最新版本的 Chrome 浏览器,Windows 电脑的各大应用商店都有最新版的 Chrome 浏览器。
Web Scraper 是一款 Chrome 浏览器插件,可以不用写一行代码进行数据采集。优点:
- 门槛足够低,只要你电脑上安装了 Chrome 浏览器就可以用
- 永久免费,无付费功能,无需注册
- 操作简单,点几次鼠标就能爬取网页,真正意义上的 0 行代码写爬虫
安装 Web Scraper 插件
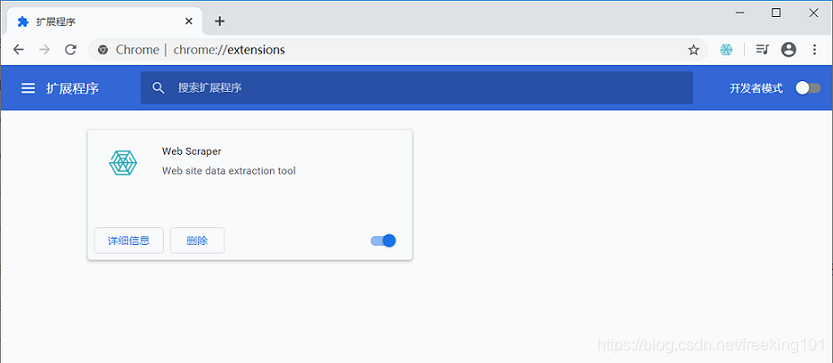
可以访问外网的同学,直接访问 "Chrome 网上应用店",搜索 Web Scraper 下载安装即可。暂时无条件访问外网,我们可以手动安装插件曲线救国一下,当然和上面比会稍微麻烦一些:首先访问 https://www.gugeapps.net/ 这个国内浏览器插件网站,搜索 Web Scraper,下载插件 ( https://www.gugeapps.net/webstore/search?key=Web+Scraper ),注意这时候插件不是直接安装到浏览器上的,而是下载到了本地。然后在浏览器的的网址输入框里输入 chrome://extensions/ ,这样就可以打开浏览器的插件管理后台:( 下图是 Chrome 装完 Web Scraper 的截图 )
MAC 和 Windows 用户:
- 如果你是 Mac 用户,首先要把这个安装包的后缀名
.crx改为.zip。再切到浏览器的插件管理后台,打开右上角的开发者模式,把Web Scraper.zip这个文件拖进去,这样就安装好了。 - 如果你是 windows 用户,你需要这样做:
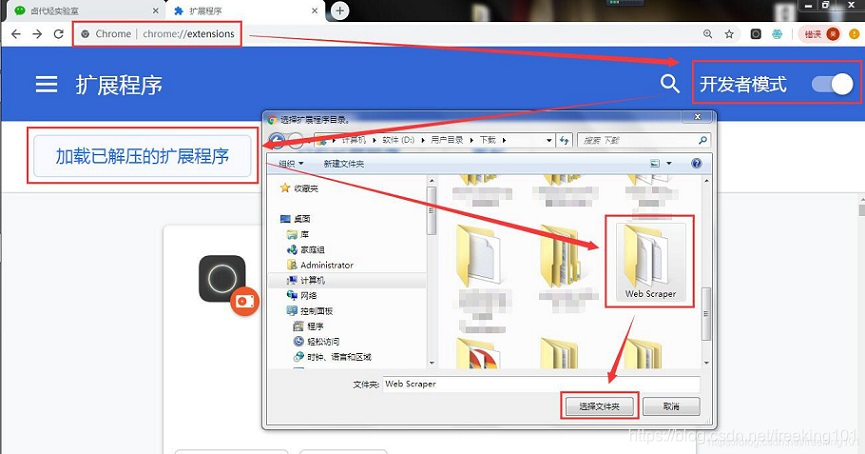
1. 把后缀为 .crx 的插件改为 .rar,然后解压缩
2. 进入 chrome://extensions/ 这个页面,开启开发者模式
3. 点击 "加载已解压的扩展程序",选择第一步中解压的文件夹,正常情况下就安装成功了。
到这里我们的 Chrome 浏览器就成功安装好 Web Scraper 插件了。
注意:webscraper 的最新版本去除了 "Download image" 选项,也就是批量下载图片的功能,最新版本现在只能抓取图片链接。
解决方案有 2 种:
- 1. 批量抓取到图片的链接,然后使用迅雷等下载工具批量下载。
- 2. 卸载掉最新的 webscraper,安装老版本。链接: https://pan.baidu.com/s/1GD6gxDWOaglCLAv0uc--yA 提取码: geif
老版本依然是有 "Download image" 这个选项的。注意不要科学上网,否则 webscraper 可能会自动更新到最新版本。
开发者模式
开启开发者模式,这个功能 https://mp.weixin.qq.com/s/Q05MV2rgXuce488-bfQTsQ 中提到过,想从普通浏览模式切换到开发者模式,只要按 F12 就可以实现(QQ 浏览器 F12 被禁掉了)。Mac 电脑也可以用 option + command + I 打开,Win 电脑可以用 Ctrl + Shift + I 打开。
控制台打开后,一般会在网页的下方显示,我们其实也可以切到网页的右边显示,具体的操作是点击后台面板右侧的 ⋮ 按钮,然后修改显示位置,具体操作如下动图。
用电脑浏览器模拟手机浏览器是一个很实用的功能。因为现在是移动互联网的时代了,大部分公司的网页都是优先支持移动端,而且手机浏览器的数据结构更清晰,更利于我们抓取数据。开启模拟手机也很简单,只要点击一下开启开发者后台左侧的手机切换图标,然后刷新就好了。
拿豆瓣这个网站演示一下。
抓取 豆瓣 电影
有人之前可能学过一些爬虫知识,总觉得这是个复杂的东西,什么 HTTP、HTML、IP 池,在这里我们都不考虑这些东西。一是小的数据量根本不需要考虑,二是这些乱七八糟的东西根本没有说到爬虫的本质。
爬虫的本质是什么?其实就是找规律。
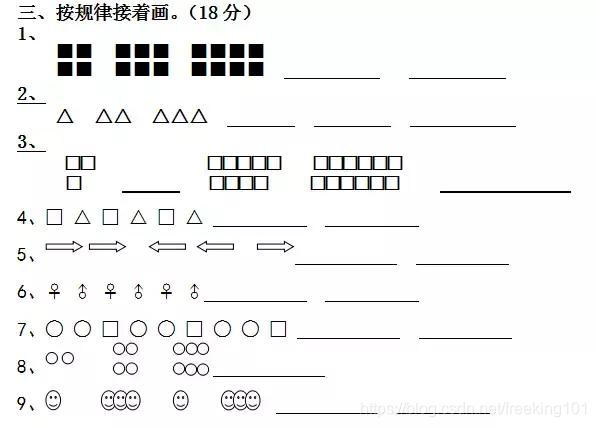
而且爬虫的找规律难度,大部分都是小学三年级的数学题水平。
我们下面拿个例子说明一下,下图历史文章的一个截图,我们可以很清晰的看到,每一条推文可以分为三大部分:标题、图片和作者,我们只要找到这个规律,就可以批量的抓取这类数据。
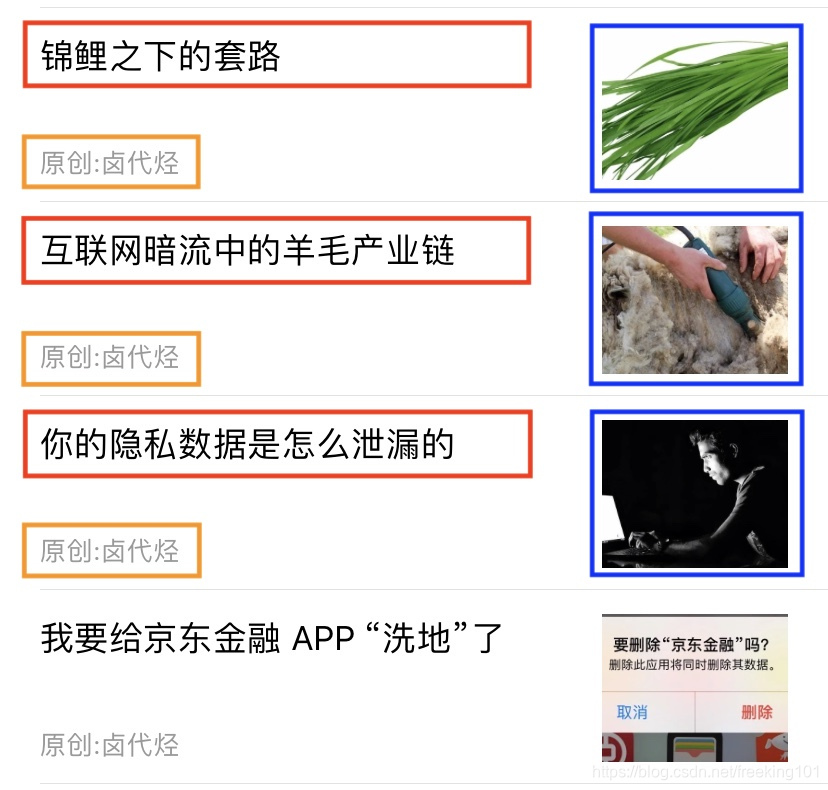
好了,理论的地方我们讲完了,下面我们开始进行实操。
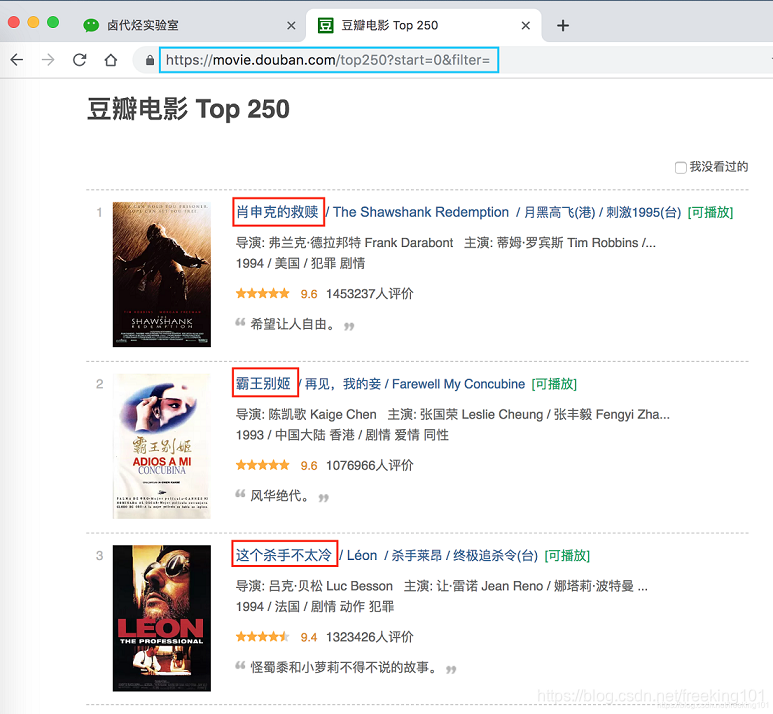
豆瓣电影 Top 250:https://movie.douban.com/top250
第一次上手,我们爬取的内容尽量简单,所以我们只爬取第一页的电影标题。
浏览器按 F12 打开控制台,并把控制台放在网页的下方,然后找到 Web Scraper 这个 Tab,点进去就来到了 Web Scraper 的控制页面。

进入 Web Scraper 的控制页面后,我们按照 Create new sitemap -> Create Sitemap 的操作路径,创建一个新的爬虫,sitemap 是啥意思并不重要,你就当他是个爬虫的别名就好了。
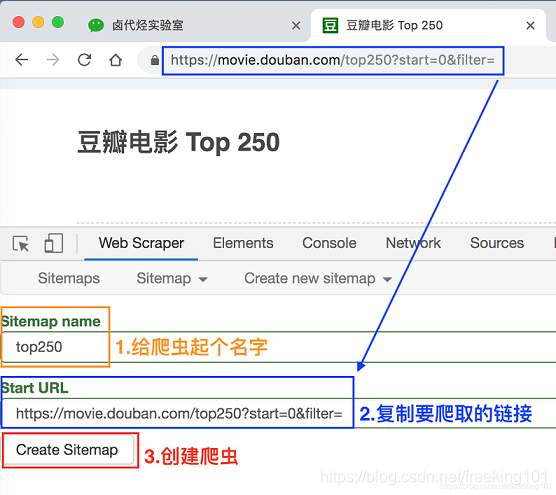
在接下来出现的输入框里依次输入爬虫名和要爬取的链接。
爬虫名可能会有字符类型的限制,我们看一下规则规避就好了,最后点击 Create Sitemap 这个按钮,创建我们的第一个爬虫。
这时候会跳到一个新的操作面板,不要管别的,我们直接点击 Add new selector 这个蓝底白字的按钮,顾名思义,创建一个选择器,用来选择我们想要抓取的元素。
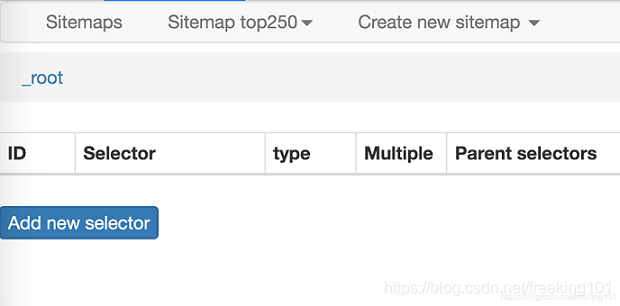
这时候就要开始正式的数据抓取环节了!我们先观察一下这个面板有些什么东西:
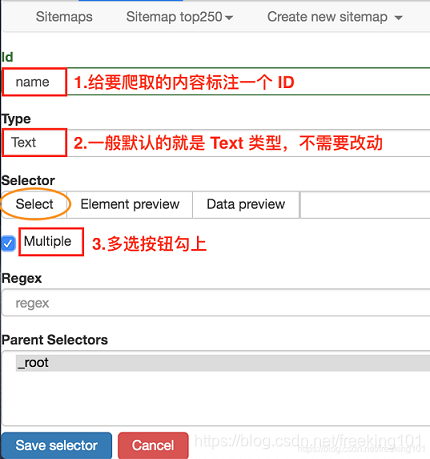
说明:
- 1. 首先有个 Id,这个就是给我们要爬取的内容标注一个 id,因为我们要抓取电影的名字,简单起见就取个 name 吧;
- 2. 电影名字很明显是一段文字,所以 Type 类型肯定是 Text,在这个爬虫工具里,默认 Type 类型就是 Text,这次的爬取工作就不需要改动了;
- 3. 我们把多选按钮 Multiple 勾选上,因为我们要抓的是批量的数据,不勾选的话只能抓取一个;
- 4. 最后我们点击黄色圆圈里的 Select,开始在网页上勾选电影名字;
当你把鼠标移动到网页时,会发现网页上出现了绿色的方块儿,这些方块就是网页的构成元素,当我们点击鼠标时,绿色的方块儿就会变为红色,表示这个元素被选中了:

这时候我们就可以进行我们的抓取工作了。
我们先选择「肖生克的救赎」这个标题,然后再选择「霸王别姬」这个标题(注意:想达到多选的效果,一定要手动选取两个以上的内容)
选完这两个标题后,向下拉动网页,你就会发现所有的电影名字都被选中了:

拉动网页检查一遍,发现所有的电影标题都被选中后,我们就可以点击 Done selecting!这个按钮,表示选择完毕;
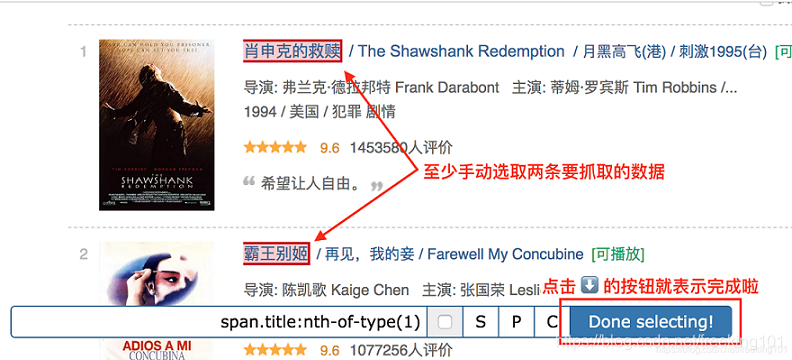
点击按钮后你会发现下图的红框位置会出现了一些字符,一般出现这个就表示选取成功了:

我们点击 Data preview 这个按钮,就可以预览我们的抓取效果了:
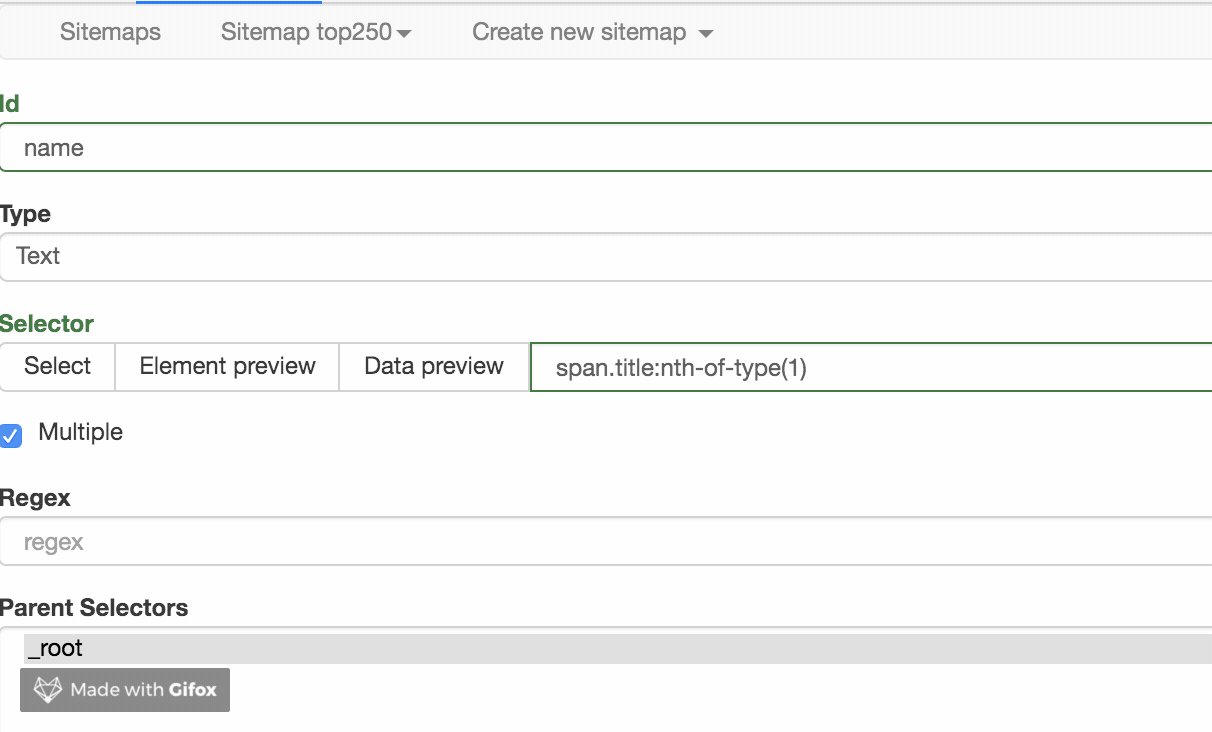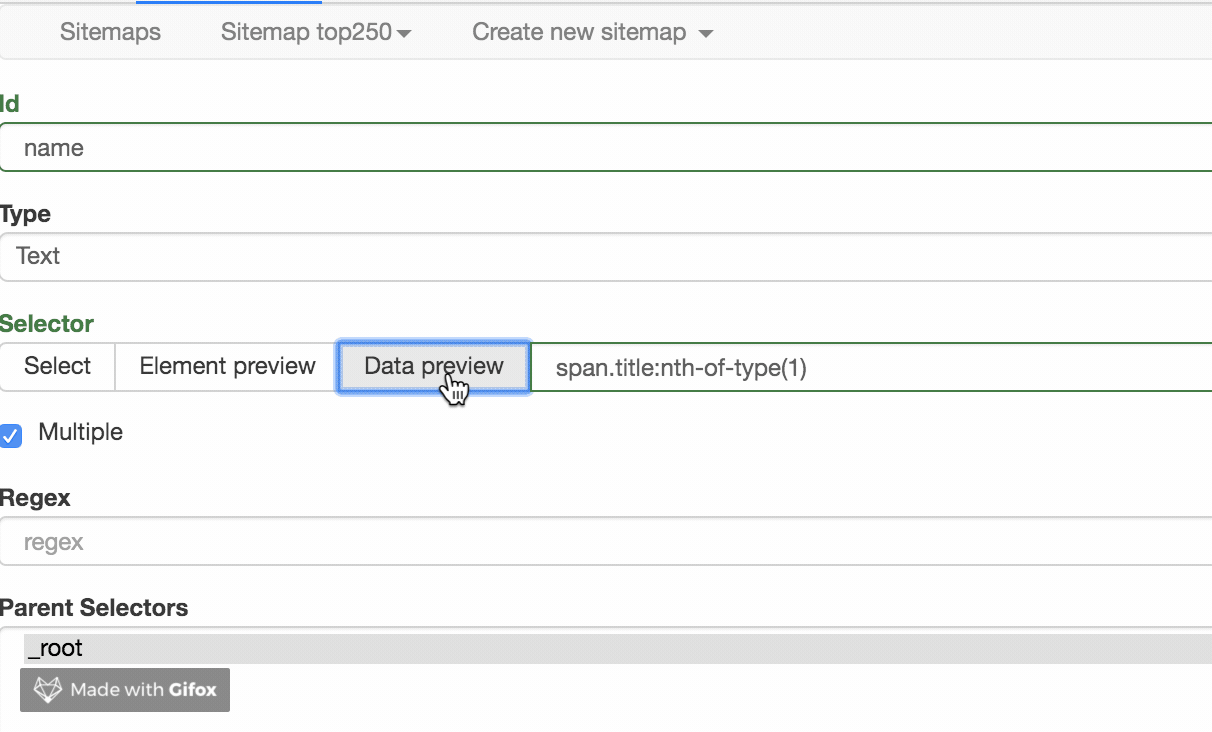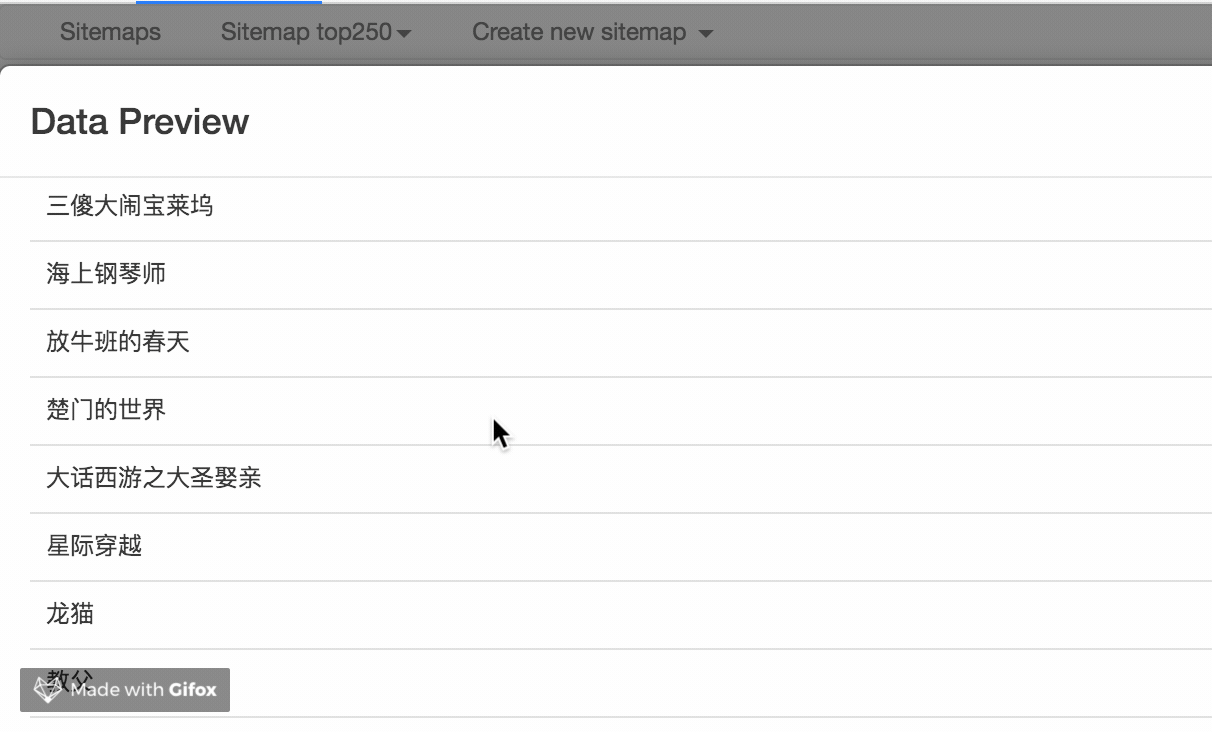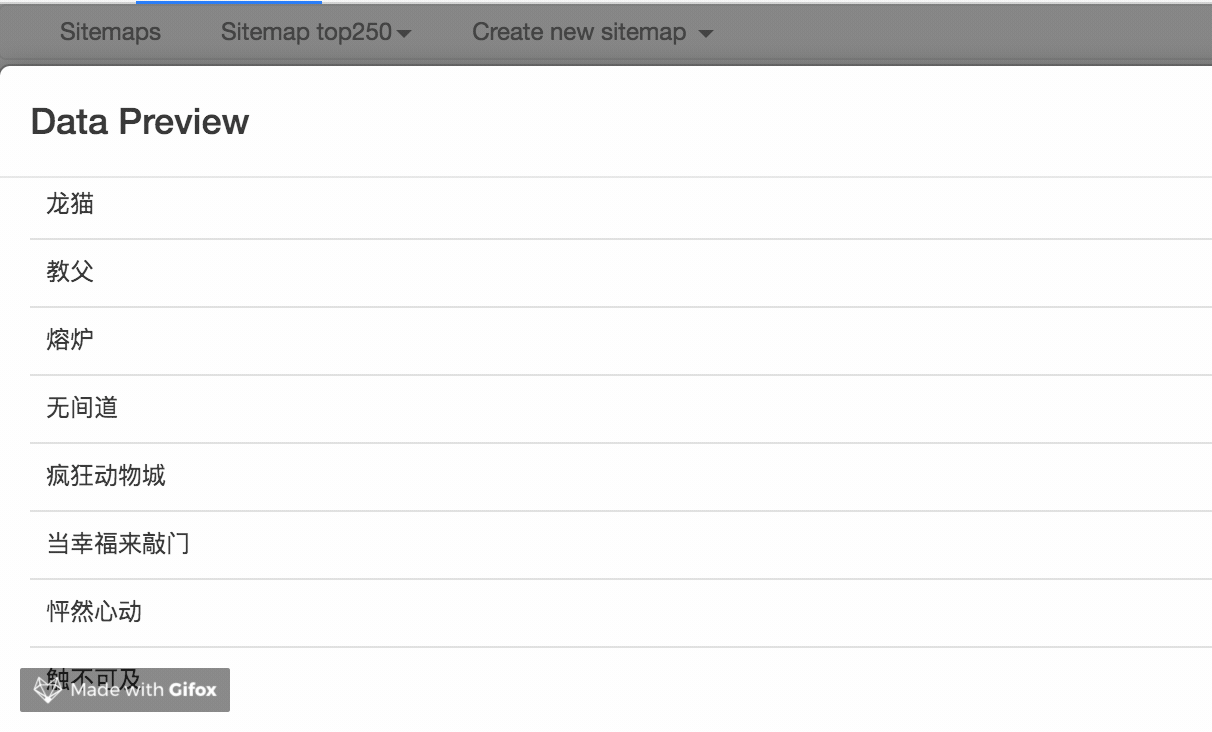
没什么问题的话,关闭 Data Preview 弹窗,翻到面板的最下面,有个 Save selector 的蓝色按钮,点击后我们会回退到上一个面板。
这时候你会发现多了一行数据,其实就是我们刚刚的操作内容被记录下来了。
在顶部的 tab 栏,有一个 Sitemap top250 的 tab,这个就是我们刚刚创建的爬虫。点击它,再点击下拉菜单里的 Scrape 按钮,开始我们的数据抓取。
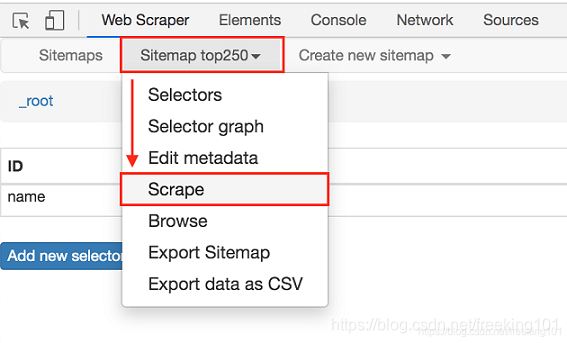
这时候你会跳到另一个面板,里面有两个输入框,先别管他们是什么,全部输入 2000 就好了。
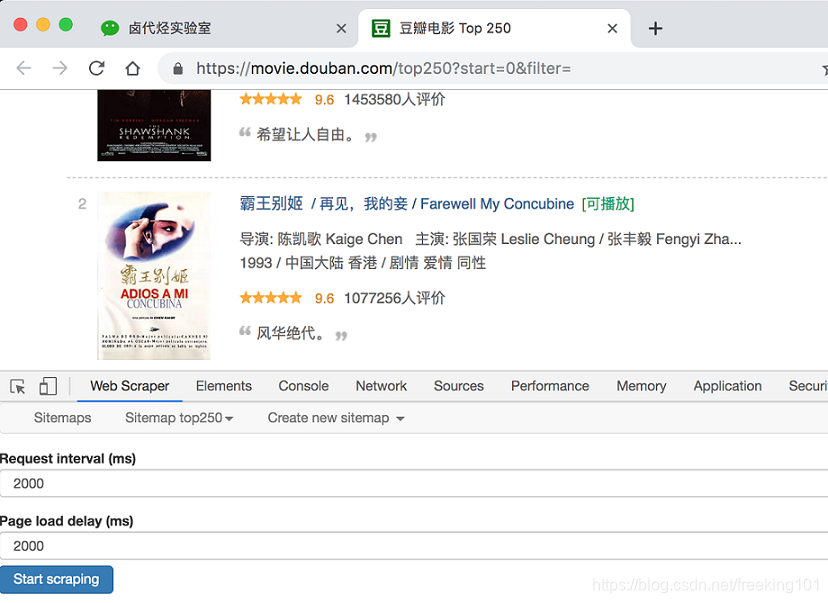
点击 Start scraping 蓝色按钮后,会跳出一个新的网页,Web Scraper 插件会在这里进行数据抓取:
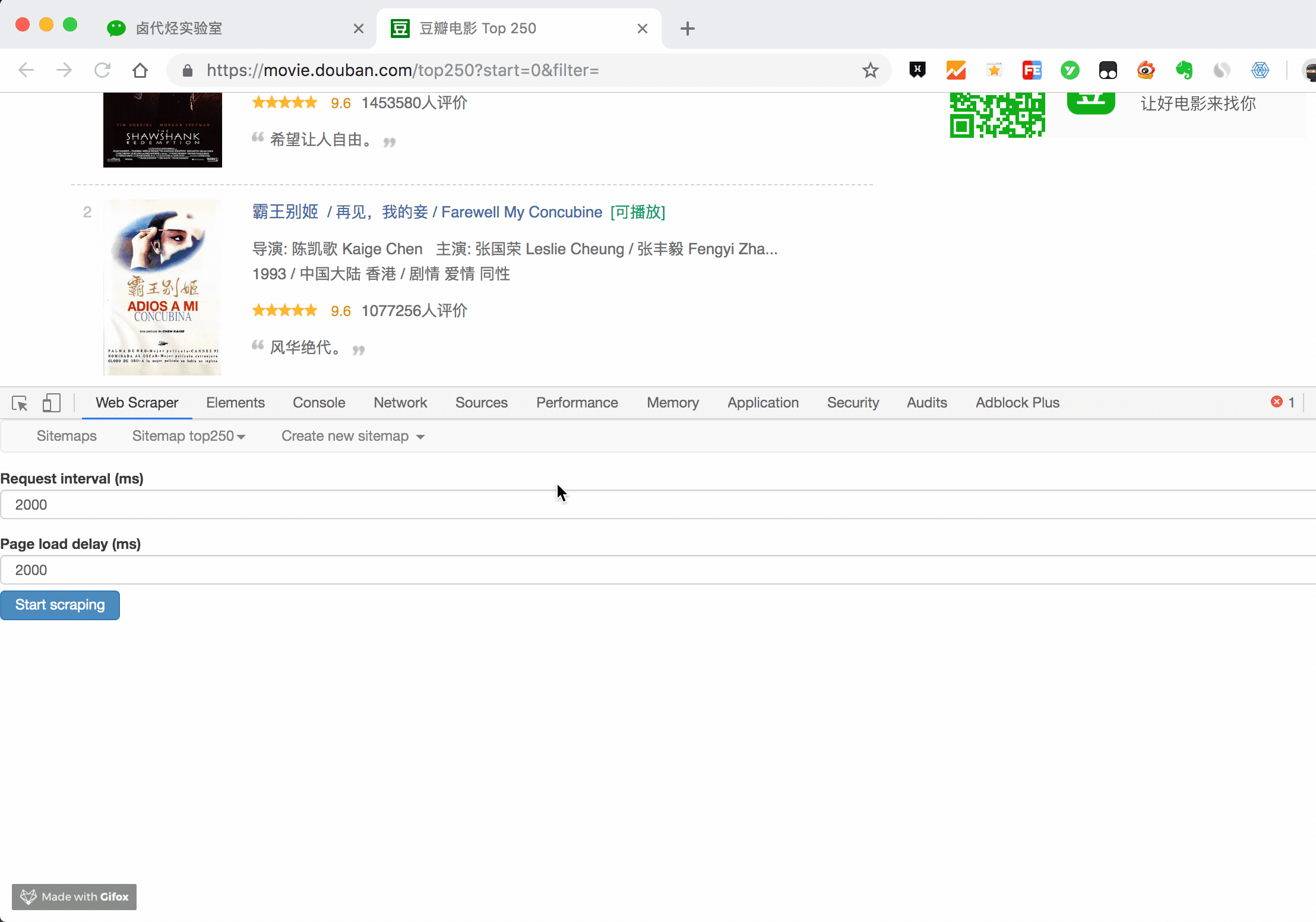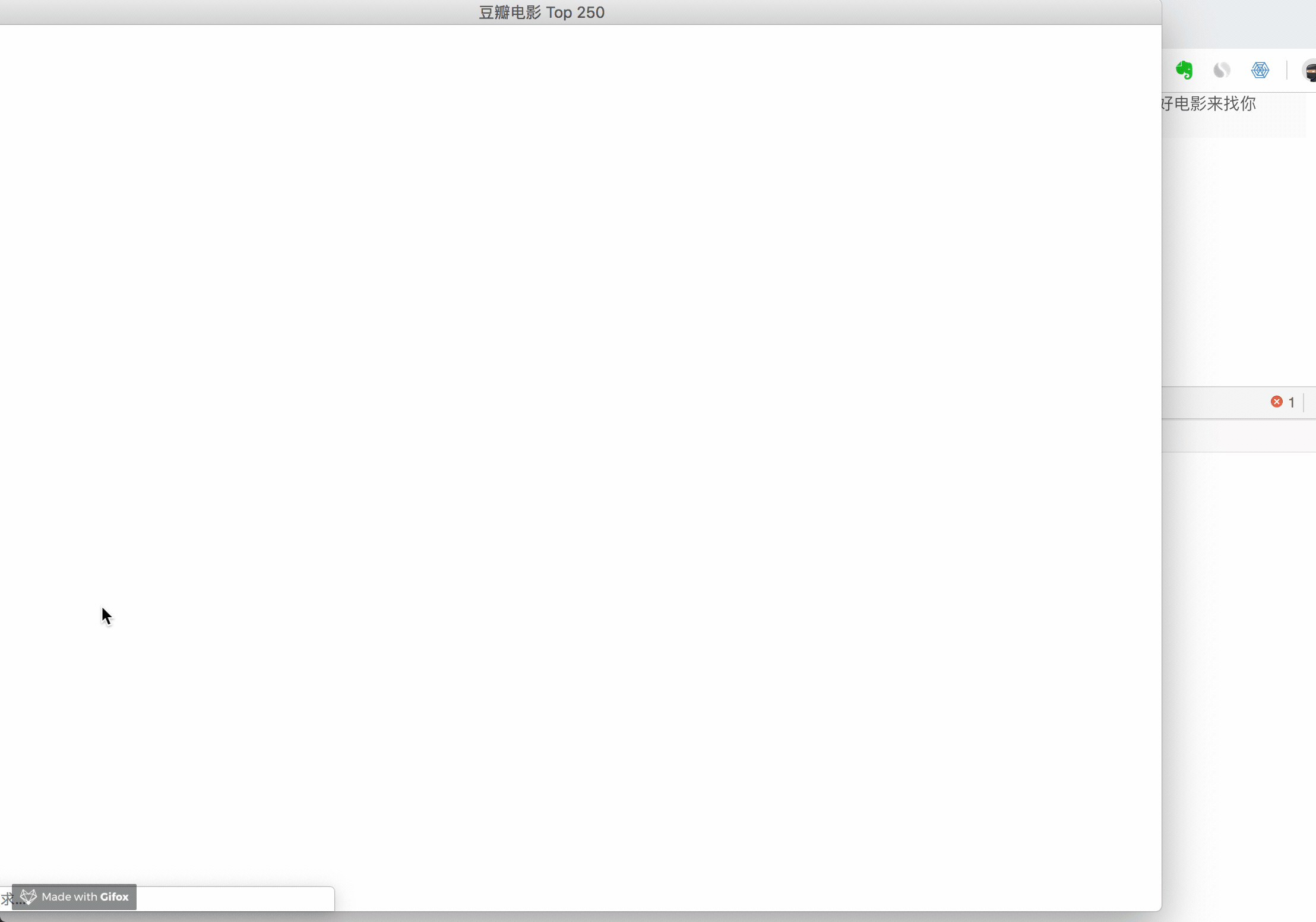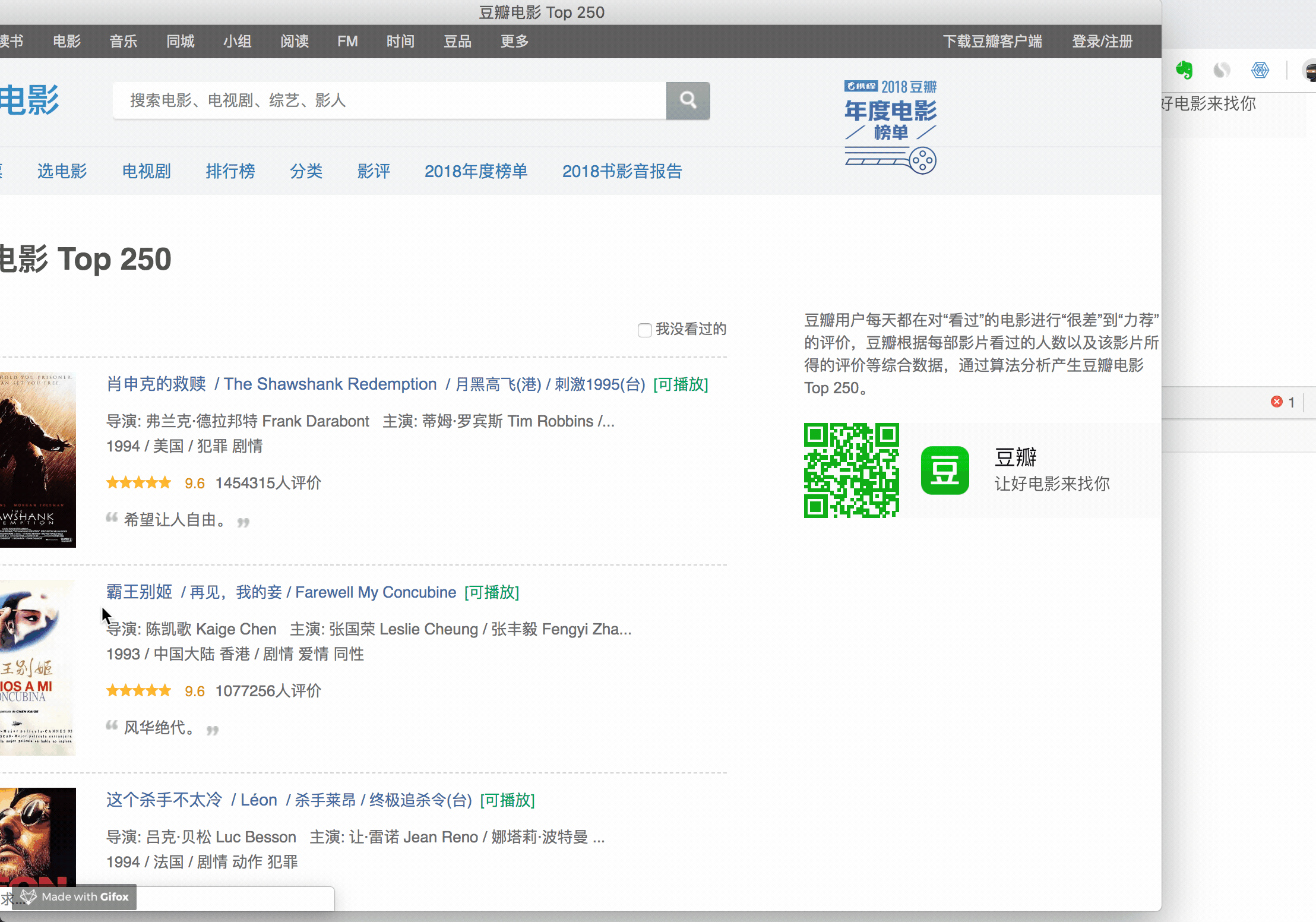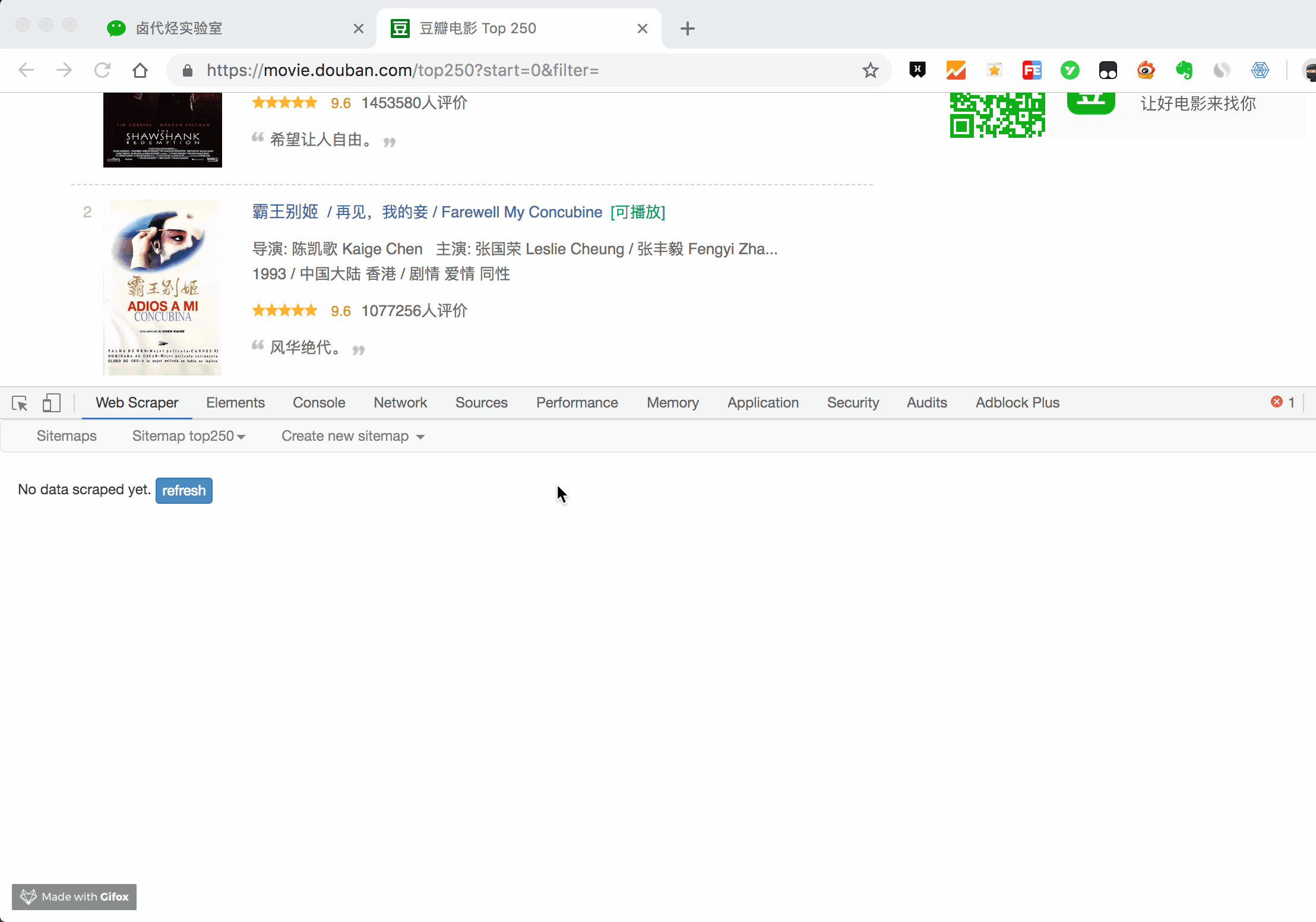
一般弹出的网页自动关闭就代表着数据抓取结束了,我们点击面板上的 refresh 蓝色按钮,就可以看到我们抓取的数据了!
在这个预览面板上,第一列是 web scraper 自动添加的编号,没啥意义;第二列是抓取的链接,第三列就是我们抓取的数据了。
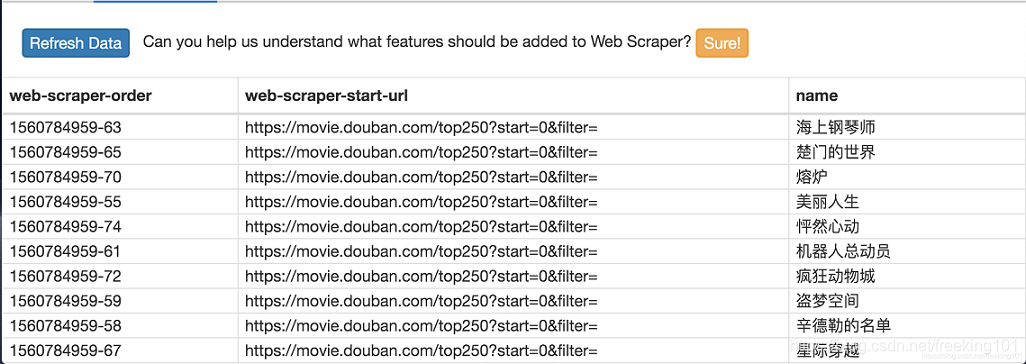
这个数据会存储在我们的浏览器里,我们也可以点击 Sitemap top250 下的 Export data as CSV,这样就可以导出成 .csv 格式的数据,这种格式可以用 Excel 打开,我们可以用 Excel 做一些数据格式化的操作。
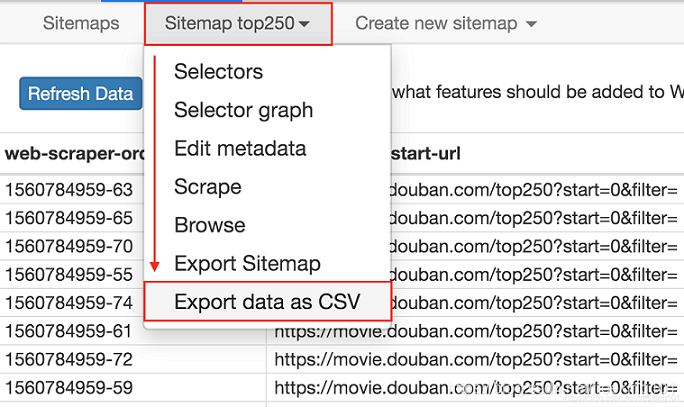
这里爬取了豆瓣电影TOP250 的第 1 页数据(也就是排名最高的 25 部电影),
下面讲解如何抓取所有的电影名。
抓取 多页 数据
https://www.cnblogs.com/web-scraper/p/web_scraper_douban_top250_movie.html
链接分析。先看看第一页的豆瓣网址链接:https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com这个很明显就是个豆瓣的电影网址,没啥好说的top250这个一看就是网页的内容,豆瓣排名前 250 的电影,也没啥好说的?后面有个start=0&filter=,根据英语提示来看,好像是说筛选(filter),从 0 开始(start)
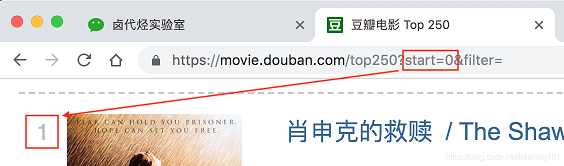
再看看第二页的网址链接,前面都一样,只有后面的参数变了,变成了 start=25,从 25 开始;
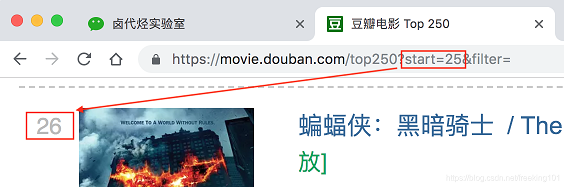
我们再看看第三页的链接,参数变成了 start=50 ,从 50 开始;
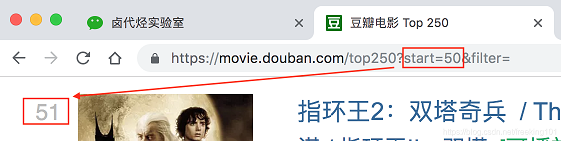
分析 3 个链接我们很容易得出规律:
- start=0,表示从排名第 1 的电影算起,展示 1-25 的电影
- start=25,表示从排名第 26 的电影算起,展示 26-50 的电影
- start=50,表示从排名第 51 的电影算起,展示 51-75 的电影
- …...
- start=225,表示从排名第 226 的电影算起,展示 226-250 的电影
规律找到了就好办了,只要技术提供支持就行。随着深入学习,你会发现 Web Scraper 的操作并不是难点,最需要思考的其实还是这个找规律。
控制链接参数翻页
Web Scraper 针对这种通过超链接数字分页获取分页数据的网页,提供了非常便捷的操作,那就是范围指定器。
比如说你想抓取的网页链接是这样的:
http://example.com/page/1http://example.com/page/2http://example.com/page/3
你就可以写成 http://example.com/page/[1-3],把链接改成这样,Web Scraper 就会自动抓取这三个网页的内容。
当然,你也可以写成 http://example.com/page/[1-100],这样就可以抓取前 100 个网页。
那么像我们之前分析的豆瓣网页呢?它不是从 1 到 100 递增的,而是 0 -> 25 -> 50 -> 75 这样每隔 25 跳的,这种怎么办?
http://example.com/page/0http://example.com/page/25http://example.com/page/50
其实也很简单,这种情况可以用 [0-100:25] 表示,每隔 25 是一个网页,100/25=4,爬取前 4 个网页,放在豆瓣电影的情景下,我们只要把链接改成下面的样子就行了;
https://movie.douban.com/top250?start=[0-225:25]&filter=
这样 Web Scraper 就会抓取 TOP250 的所有网页了。
抓取数据
解决了链接的问题,接下来就是如何在 Web Scraper 里修改链接了,很简单,就点击两下鼠标:
1.点击 Stiemaps,在新的面板里点击 ID 为 top250 的这列数据:

2.进入新的面板后,找到 Stiemap top250 这个 Tab,点击,再点击下拉菜单里的 Edit metadata:
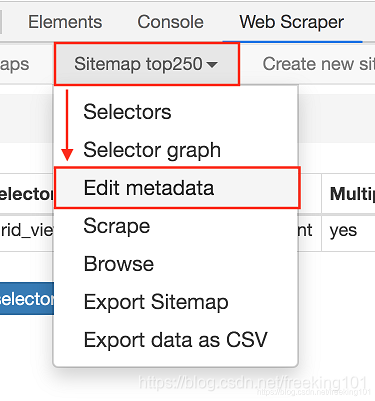
3.修改原来的网址,图中的红框是不同之处:
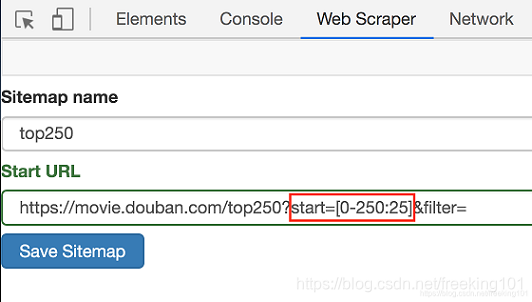
修改好了超链接,我们重新抓取网页就好了。操作和上文一样,我这里就简单复述一下:
- 点击
Sitemap top250下拉菜单里的Scrape按钮 - 新的操作面板的两个输入框都输入 2000
- 点击
Start scraping蓝色按钮开始抓取数据 - 抓取结束后点击面板上的
refresh蓝色按钮,检测我们抓取的数据
如果你操作到这里并抓取成功的话,你会发现数据是全部抓取下来了,但是顺序都是乱的。
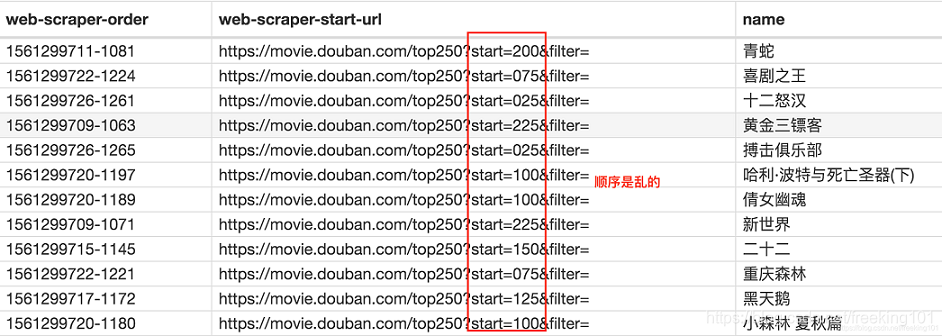
我们这里先不管顺序问题,因为这个属于数据清洗的内容了,我们现在的专题是数据抓取。先把相关的知识点讲完,再攻克下一个知识点,才是更合理的学习方式。
3、浏览器 自动化 Automa
Automa 是一款低代码/无代码的浏览器扩展,用于进行浏览器自动化操作:自动填写表格、执行重复性任务、截图、抓取网站数等。 Automa 的文档。
Chrome:https://kutt.appinn.net/wvcmQD
官网:https://kutt.appinn.net/GwZXEr
GitHub:https://kutt.appinn.net/tmpQjO
在 Automa,每一个完整的动作被叫做一个 Workflow,而每一个条件则叫 Block,只需要把几个 Block 组合起来,就变成了 Workflow。
一般功能
- 触发块
- 延时块
- 导出数据块
- 重复块
- HTTP 请求块
- 循环数据块
- 块组
- 剪贴板块
- 插入数据块
浏览器功能
- 激活标签页块
- 新标签页块
- 新窗口块
- 代理块
- 返回/前进块
- 关闭标签页/窗口块
- 截图块
- 处理对话框块
- 处理下载块
网络功能
- 点击块
- 获取文本块
- 链接块
- 从元素中获取指定属性的值
- 表单块
- Javascript 块
- 触发事件块
- 上传文件块
在线服务
- Google Sheets 块
只需要将这些块组合起来就可以了。至于具体能干什么,目前有一些在线的 Workflows 可以体验,但的确没什么创意,安装量第一的 Workflow 居然是一个搜索演示,就是帮你搜索几个莫名其妙的关键词,让你看着:

















 1985
1985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









