







1、Python 执行 JavaScript 代码
- 通过 Python 模块 execjs 来执行 js 文件,适用于基本的JavaScript操作。PyExecJS 是对 execjs 库的封装,提供更多功能和更好的性能。PyExecJS 一代已经停止更新,二代(PyExecJS2)在 Apr 29, 2022也停止更新。安装 PyExecJS:pip install PyExecJS2 PyExecJS:https://pypi.org/search/?q=PyExecJS
- 通过 Python 调用 node.js(需要先安装 node.js)
import subprocess
result = subprocess.check_output(["node", "-e", node_script], text=True)
print(result) # 输出:5 - 使用浏览器引擎执行 js:Selenium 和 Playwright
- STPyV8 是基于 PyV8(在已经停止更新) 的分支,已更改为最新的 Google V8 引擎和 Python3 。安装:pip install stpyv8
- quickjs:pypi:https://pypi.org/search/?q=quickjs
pip install quickjs
pip install pyquickjs
使用方法:https://github.com/hjdhnx/pyquickjs/blob/main/test_quickjs.py - Js2Py:是用纯 python 编写并实现 JavaScript 核心,没有任何依赖关系。可以将 JavaScript 转换为 Python 代码。Js2Py 能够翻译和执行几乎任何 JavaScript 代码。安装:pip install Js2Py
pypi 搜索 javascript,就可以找到对应的 Python 包
python 嵌入 js 引擎的包,不需要再单独安装 nodejs
- PythonMonkey:https://pypi.org/project/pythonmonkey/
- Duktape:https://pypi.org/search/?q=Duktape
- thquickjs:https://pypi.org/project/thquickjs/
- Python Mini Racer:https://pypi.org/project/mini-racer/
通过 PyExecJS 执行 js
execjs 只支持一些常规的 js:https://blog.csdn.net/weixin_42081389/article/details/99984352
import execjs
print(execjs.get().name)
运行结果:Node.js (v8)
如果你成功安装好 PyExecJS 库和Nodejs 的话其结果就是 Nodejs(V8)。当然,如果安装的是其他的JavaScript运行环境,结果也会有所不同。
示例:
import execjs
js_str = '''
function add(x, y){
return x + y;
}
'''
test = execjs.compile(js_str)
# call 即调用 js 函数,add 为 js_str 中的函数名,1,2 为所需要的参数。
result = test.call('add', 1, 2)
print(result)对简单的话,可以用Python 完全重写一遍。但是现实情况往往不是这样的,一般来说,一些加密相关的方法通常会引用一些相关标准库,比如说JavaSript就有一个广泛使用的库叫作 crypto-js,这个库实现了很多主流的加密算法,包括对称加密、非对称加密、字符编码等。比如对于AES 加密通常我们需要输入待加密文本和加密密钥,实现如下:
const ciphertext = CryptoJS.AES.encrypt(message, key).toString();
示例 :https://spa7.scrape.center/

打开 Sources 面板,可以非常轻易地找到加密字符串的生成逻辑。首先声明一个球员相关的列表,然后对于每一个球员,调用加密算法对其信息进行加密。可以添加断点看看。可以看到,getToken 方法的输人就是单个球员的信息,就是上述列表的一个元素对象,然后this.key就是一个固定的字符串。整个加密逻辑就是提取球员的名字、生日、身高、体重,接着先进行Base64编码,然后进行DES加密,最后返回结果。加密算法是怎么实现的呢?其实就是依赖了cryptojs 库,使用CryptoJS对象来实现的。
那么,CryptoJS 这个对象是哪里来的呢?

就是网站直接引用了crypto-js库。执行 <script src="js/crypto-js.min.js"></script> 后,crypto-js 就被注人浏览器全局环境下,因此我们就可以在别的方法里直接使用 CryptoJS 对象里的方法了。
因此,要模拟执行的内容就是以下两部分
- 模拟运行 crypto-js.min.js 里面的 JavaScript,用于声明 CryptoJS 对象
- 模拟运行 getToken 方法的定义,用于声明 getToken 方法。
接下来,把 crypto-js.min.js 里面的代码 getToken 方法的代码都复制粘贴到一个 JavaScript 文件里面,比如就叫作 crypto.js
crypto.js 代码

Python 代码
import execjs
import json
item = {
'name': '凯文-杜兰特',
'image': 'durant.png',
'birthday': '1988-09-29',
'height': '208cm',
'weight': '108.9KG'
}
js_file = 'crypto.js'
node = execjs.get()
# compile 方法返回一个 JavaScript 的上下文对象.
# 接着调用node的compile方法这里给它传人刚才定义的crypto.js文件的文本内容
# compile方法会返回一个JavaScript的上下文对象, 这里将其赋给ctx。
# 执行到这里,其实就可以理解为ctx对象里面就执行过了crypto-js.min.js,CryptoJS就声明好了,
# 然后紧接着 getToken 方法的声明代码也被执行,所以getToken方法也定义好了
# 到此,完成了一些初始化工作。
ctx = node.compile(open(js_file).read())
js_func = f"getToken({json.dumps(item, ensure_ascii=False)})"
print(js_func)
result = ctx.eval(js_func)
print(result)
但是运行后报错:execjs._exceptions.ProgramError: ReferenceError: CryptoJS is not defined
CryptoJS 未定义? 明明执行过 crypto-js.min.js 里面的内容了呀? 问题其实出在 crypto-js.min.js,可以看到其中声明了一个 JavaScript 的自执行方法,
什么是自执行方法呢? 就是声明了一个方法然后紧接着调用执行:!(function(a,b){console.log("result", a, b)))(1,2)
同理 crypto-js.min.js 也符合这个格式,它接收 t 和 e 两个参数,
- t 就是 this,其实就是浏览器中的 window 对象
- e 就是一个 function (用于定义CryptoJS的核心内容)

"object" == typeof exports
? module.exports = exports = e()
: "function" == typeof define && define.amd
? define([], e)
: t.CryptoJS = e()
在Node.js 中,其实 exports 用来将一些对象的定义导出。这里 "object"== typeof exports 的结果其实就是 true,所以就执行了 module.exports = exports =e() 这段代码,这相当于把 e() 作为整体导出,而这个 e() 其实就对应后面的整个 function。function里面定义了加密相关的各个实现其
实就指代整个加密算法库。
但是在浏览器中其结果就不一样了,浏览器环境中并没有 exports 和 define 这两个对象。所以上述代码在浏览器中最后执行的就是 t.CryptoJS =e() 这段代码,其实这里就是把 CryptoJS 对象挂载到this 对象上面,而 this 就是浏览器中的全局 window 对象后面就可以直接用了。如果我们把代码放在浏览器中运行,那没有任何问题。然而我们使用的 PyExecJS 是依赖于一个 Nodejs 执行环境的所以上述代码其实执行的是 module.exports=exports=e() 这里面并没有声明 CryptoJS 对象也没有把 CryptoJS 挂载到全局对象里面所以后面我们再调用 CryptoJS 就自然而然出现了未定义的错误了。
怎么办呢? 其实很简单,直接声明一个 CtyptoJS 变量,然后手动声明一下它的初始化不就好了吗?所以我们可以把代码稍作修改,改成如下内容:

这样就成功得到加密字符串了,成功模拟JavaScript的调用完成了某个加密算法的运行过程。
通过 node 执行 js
方法 1:
上面 PyExecJS 的执行环境是 Nodejs,但在调用过程中发现还是不太方便,可能会出现上面的变量未定义的问题。既然是 Nodejs 环境,为什么不直接用 Nodejs 来执行 JavaScript。
main.js
const CryptoJS = require("./crypto")
function getToken(player) {
let key = CryptoJS.enc.Utf8.parse(this.key)
const {name, birthday, height, weight} = player
let base64Name = CryptoJS.enc.Base64.stringify(CryptoJS.enc.Utf8.parse(name))
let encrypted = CryptoJS.DES.encrypt(`${base64Name}${birthday}${height}${weight}`, key, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
})
return encrypted.toString()
}
const player = {
name: '凯文-杜兰特',
image: 'durant.png',
birthday: '1988-09-29',
height: '208cm',
weight: '108.9KG'
}
console.log(getToken(player))
执行结果

再来看下面代码
"object" == typeof exports
? module.exports = exports = e()
: "function" == typeof define && define.amd
? define([], e)
: t.CryptoJS = e()
在 Nodes 中定义了exports 这个对象,它用来将一些对象的定义导出。这里 "object" == typeof exports 的结果其实就是 true,所以就执行了 module.exports = exports = e() 这段代码这样就相当于把 e() 作为整体导出了,而这个 e() 其实就对应这后面的整个 function。function里面定义了加密相关的各个实现,其实就指代整个加密算法库。
既然在 crypto.js 里面声明了这个导出,那么怎么导人呢? require 就是导入的意思,导人之后我们把它赋值为了整个 CryptoJS 变量,其实它就代表整个 CryptoJS 加密算法库了。
正是因为我们在Nodejs中有和exports配合的require的调用并将结果赋值给 CryptoJS 变量我们才完成了 CryptoJS 的初始化。因此后面我们就能调用CryptoJS 里面的DESen等各个对象的方法来进行一些加密和编码操作了。
CryptoJS 初始化完成了,接下来 getToken 方法其实就是调用CryptoJS 里面的各个对象的方法实现了整个加密流程,整个逻辑和上一节是一样的。
方法 2:
import os
import subprocess
os.environ['NODE_PATH'] = '/usr/local/lib/node_modules/'
sig_1 = subprocess.getoutput('node js_code.js')
sig_2 = subprocess.run('node js_code.js', shell=True).stdout
javascript 传参
function func(prev){
console.log(prev);
}
let v1 = process.argv[2];
lset data = func(v1);
console.log(data);
// process.argv 返回一个数组,其中包含当Node.js进程启动时传入的命令行参数
// 第一个是启动是process.execPath
// 第二个是执行的JavaScript文件的路径
// 其余的则是任何额外输入的参数
console.log(process.argv);

暴露 node web http 服务
- :https://juejin.cn/post/7101870857467166728
- :https://www.zhihu.com/question/598058730
- :https://juejin.cn/post/7066763942407700510
Express.js:Express 是目前最流行的 Node.js web 框架,提供非常简单的方式来创建Web服务器,且功能足够强大并且足够的轻量,专注于服务器的核心功能。
Node.js Express 框架:https://www.runoob.com/nodejs/nodejs-express-framework.html
示例代码:
const CryptoJS = require("./crypto")
function getToken(player) {
let key = CryptoJS.enc.Utf8.parse(this.key)
const {name, birthday, height, weight} = player
let base64Name = CryptoJS.enc.Base64.stringify(CryptoJS.enc.Utf8.parse(name))
let encrypted = CryptoJS.DES.encrypt(`${base64Name}${birthday}${height}${weight}`, key, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
})
return encrypted.toString()
}
// server.js
const express = require("express")
const app = express()
const port = 3000
// 解析此应用程序的 JSON 数据。必须放在路由处理代码之前
app.use(express.json())
app.get('/get/', (req, res) => {
res.send('Hello World!')
})
app.post('/post/', (req, resp) => {
const req_body = req.body;
let encrypt_data = getToken(req_body);
resp.send(encrypt_data);
})
app.listen(port, () => {
console.log(`Example app listening on port ${port}`)
})通过 Playwright 执行 js
示例:https://spa2.scrape.center/
添加XHR断点并通过调用栈找到 token 的生成人口

e = Object(i["a"])(this.$store.state.url.index, a);
i["a"] 如下:

大致可以看到,这里又掺杂了时间、SHA1、Base64、列表等各种操作。要深人分析,还是需要花费一些时间的。现在,可以说核心方法已经找到了,参数我们也知道怎么构造了,就是方法内部比较复杂,但我们想要的其实就是这个方法的运行结果,即最终的 token。这时候大家可能就产生了这样的疑问:
- 怎么在不分析该方法逻辑的情况下拿到方法的运行结果呢? 该方法完全可以看成黑盒
- 要直接拿到方法的运行结果,就需要模拟调用了,怎么模拟调用呢?
- 这个方法并不是全局方法,所以没法直接调用,该怎么办呢?
其实是有方法的。
- 模拟调用当然没有问题,问题是在哪里模拟调用。根据上文的分析,既然浏览器中都已经把上下文环境和依赖库都加载成功了,为何不直接用浏览器呢?
- 怎么模拟调用局部方法呢? 很简单,只需要将局部方法挂载到全局window对象上不就好了吗?
- 怎么把局部方法挂载到全局 window 对象上呢? 最简单的方法就是直接改源码。
- 既然已经在浏览器中运行了,又怎么改源码呢? 当然可以,比如利用 playwright 的 Request Interception 机制将想要替换的任意文件进行替换即可。
实现 Object(i["a"])的全局挂载。只需要将其赋值给 window对象的一个属性即可,属性名称任意,但是不能跟现有的属性冲突。
// 先执行代码,加载 Object(i["a"]),加载完成后就完成了初始化
var a = (this.page - 1) * this.limit, e = Object(i["a"])(this.$store.state.url.index, a);
// 将 i["a"] 全局挂载到 window 对象的属性。这里假设挂到到 encrypt 属性
window.encrypt = Object(i["a"]);
// 以后不管在任何地方调用 window.encrypt 方法就相当于调用了Object(i["a"])方法。
将修改后的整个JavaScript代码文件保存到本地并将其命名为 chunk.js。接下来我们利用 playwright 启动一个浏览器并使用 Request Interception 将 JavaScript 文件替换
import time import requests from playwright.sync_api import sync_playwright BASE_URL = 'https://spa2.scrape.center' INDEX_URL = BASE_URL + '/api/movie/?limit={limit}&offset={offset}&token={token}' MAX_PAGE = 10 LIMIT = 10 context = sync_playwright().start() browser = context.chromium.launch() page = browser.new_page() page.route( "/js/chunk-10192a00.243b8b7.js", lambda route: route.fulfill(path="./chunk.js") ) page.goto(BASE_URL) def get_token(offset): arg_1 = '/api/movie' arg_2 = offset result = page.evaluate(f'()=>{{return window.encrypt("{arg_1}","{arg_2}")}}') return result for i in range(MAX_PAGE): offset = i * LIMIT token = get_token(offset) index_url = INDEX_URL.format(limit=LIMIT, offset=offset, token=token) resp = requests.get(index_url) print(f'resp ---> {resp.json()}')
- 第一个参数是原本加载的文件路径,比如原本加载的 JavaScript 路径为 /js/chunk-10192a00.243cb8b7.js
- 第二个参数利用 route 的 fulfill 方法指定本地的文件也就是我们修改后的文件chunk.js
这样 playwright 加载 /js/chunk-10192a00.243cb8b7.js 文件的时候其内容就会被替换为我们本地保存的 chunk.js 文件。当执行之后,Object(i["a"])也就被挂载给 window 对象的 encrypt 属性了,所以调用 window.encrypt 方法就相当于调用了 0bject(i["a"])方法了。

在node.js中 补 浏览器环境
安装 jsdom 来补充浏览器环境
npm install jsdom -g
安装 canvas
npm install canvas -g

2、自实现分布式爬虫
url_pool.py
参考:https://www.yuanrenxue.com/crawler/news-crawler-urlpool.html
# -*- coding: utf-8 -*-
# @Author : 佛祖保佑, 永无 bug
# @Date :
# @File : url_pool.py
# @Software: PyCharm
# @description : XXX
import time
import redis
import pickle
import urllib.parse as urlparse
class UrlDB(object):
"""使用 redis 来存储 URL"""
status_failure = b'0'
status_success = b'1'
def __init__(self, db_name):
# self.name = db_name + '.urldb'
# self.db = leveldb.LevelDB(self.name)
self.name = db_name if db_name else 'redis_hashmap'
self.db = redis.StrictRedis()
def set_success(self, url=None):
if isinstance(url, str):
url = url.encode('utf8')
try:
self.db.hset(self.name, url, self.status_success)
status = True
except BaseException as be:
status = False
return status
def set_failure(self, url):
if isinstance(url, str):
url = url.encode('utf8')
try:
self.db.hset(self.name, url, self.status_failure)
status = True
except BaseException as be:
status = False
return status
def has(self, url):
if isinstance(url, str):
url = url.encode('utf8')
try:
attr = self.db.hget(self.name, url)
return attr
except BaseException as be:
pass
return False
class UrlPool(object):
""" 使用 UrlPool 来抓取和管理URLs"""
def __init__(self, pool_name):
self.name = pool_name
self.db = UrlDB(pool_name)
self.waiting = dict() # {host: set([urls]), } 按host分组,记录等待下载的URL
self.pending = dict() # {url: pended_time, } 记录已被取出(self.pop())但还未被更新状态(正在下载)的URL
self.failure = dict() # {url: times,} 记录失败的URL的次数
self.failure_threshold = 3
self.pending_threshold = 10 # pending的最大时间,过期要重新下载
self.waiting_count = 0 # self.waiting 字典里面的url的个数
self.max_hosts = ['', 0] # [host: url_count] 目前pool中url最多的host及其url数量
self.hub_pool = dict() # {url: last_query_time, } 存放hub url
self.hub_refresh_span = 0
self.load_cache()
pass
def __del__(self):
self.dump_cache()
def load_cache(self,):
path = self.name + '.pkl'
try:
with open(path, 'rb') as f:
self.waiting = pickle.load(f)
cc = [len(v) for k, v in self.waiting.items()]
print('saved pool loaded! urls:', sum(cc))
except BaseException as be:
pass
def dump_cache(self):
path = self.name + '.pkl'
try:
with open(path, 'wb') as f:
pickle.dump(self.waiting, f)
print('self.waiting saved!')
except BaseException as be:
pass
def set_hubs(self, urls, hub_refresh_span):
self.hub_refresh_span = hub_refresh_span
self.hub_pool = dict()
for url in urls:
self.hub_pool[url] = 0
def set_status(self, url, status_code):
if url in self.pending:
self.pending.pop(url)
if status_code == 200:
self.db.set_success(url)
return
if status_code == 404:
self.db.set_failure(url)
return
if url in self.failure:
self.failure[url] += 1
if self.failure[url] > self.failure_threshold:
self.db.set_failure(url)
self.failure.pop(url)
else:
self.add(url)
else:
self.failure[url] = 1
self.add(url)
def push_to_pool(self, url=None):
host = urlparse.urlparse(url).netloc
if not host or '.' not in host:
print('try to push_to_pool with bad url:', url, ', len of ur:', len(url))
return False
if host in self.waiting:
if url in self.waiting[host]:
return True
self.waiting[host].add(url)
if len(self.waiting[host]) > self.max_hosts[1]:
self.max_hosts[1] = len(self.waiting[host])
self.max_hosts[0] = host
else:
self.waiting[host] = set([url])
self.waiting_count += 1
return True
def add(self, url=None, always=False):
if always:
return self.push_to_pool(url)
pended_time = self.pending.get(url, 0)
if time.time() - pended_time < self.pending_threshold:
print('being downloading:', url)
return
if self.db.has(url):
return
if pended_time:
self.pending.pop(url)
return self.push_to_pool(url)
def add_many(self, url_list=None, always=False):
if isinstance(url_list, str):
print('urls is a str !!!!', url_list)
self.add(url_list, always)
else:
for url in url_list:
self.add(url, always)
def pop(self, count=None, hub_percent=50):
print('\n\tmax of host:', self.max_hosts)
# 取出的url有两种类型:hub=1, 普通=0
url_attr_url = 0
url_attr_hub = 1
# 1. 首先取出hub,保证获取hub里面的最新url.
hubs = dict()
hub_count = count * hub_percent // 100
for hub in self.hub_pool:
span = time.time() - self.hub_pool[hub]
if span < self.hub_refresh_span:
continue
hubs[hub] = url_attr_hub # 1 means hub-url
self.hub_pool[hub] = time.time()
if len(hubs) >= hub_count:
break
# 2. 再取出普通url
left_count = count - len(hubs)
urls = dict()
for host in self.waiting:
if not self.waiting[host]:
continue
url = self.waiting[host].pop()
urls[url] = url_attr_url
self.pending[url] = time.time()
if self.max_hosts[0] == host:
self.max_hosts[1] -= 1
if len(urls) >= left_count:
break
self.waiting_count -= len(urls)
print('To pop:%s, hubs: %s, urls: %s, hosts:%s' % (count, len(hubs), len(urls), len(self.waiting)))
urls.update(hubs)
return urls
def size(self,):
return self.waiting_count
def empty(self,):
return self.waiting_count == 0
def test():
pool = UrlPool('crawl_url_pool')
urls = [
'http://1.a.cn/xyz',
'http://2.a.cn/xyz',
'http://3.a.cn/xyz',
'http://1.b.cn/xyz-1',
'http://1.b.cn/xyz-2',
'http://1.b.cn/xyz-3',
'http://1.b.cn/xyz-4',
]
pool.add_many(urls)
# del pool
# pool = UrlPool('crawl_url_pool')
urls = pool.pop(5)
urls = list(urls.keys())
print('pop:', urls)
print('pending:', pool.pending)
pool.set_status(urls[0], 200)
print('pending:', pool.pending)
pool.set_status(urls[1], 404)
print('pending:', pool.pending)
if __name__ == '__main__':
test()
ezpymysql.py
:https://www.yuanrenxue.com/crawler/news-crawler-mysql-tool.html
# file: ezpymysql.py
# Author: veelion
"""A lightweight wrapper around PyMySQL.
only for python3
"""
import time
import logging
import traceback
import pymysql
import pymysql.cursors
version = "0.7"
version_info = (0, 7, 0, 0)
class Connection(object):
"""A lightweight wrapper around PyMySQL."""
def __init__(self, host, database, user=None, password=None,
port=0, max_idle_time=7 * 3600, connect_timeout=10,
time_zone="+0:00", charset="utf8mb4", sql_mode="TRADITIONAL"):
self.host = host
self.database = database
self.max_idle_time = float(max_idle_time)
args = dict(
use_unicode=True, charset=charset, database=database,
init_command=('SET time_zone = "%s"' % time_zone),
cursorclass=pymysql.cursors.DictCursor,
connect_timeout=connect_timeout, sql_mode=sql_mode
)
if user is not None:
args["user"] = user
if password is not None:
args["passwd"] = password
# We accept a path to a MySQL socket file or a host(:port) string
if "/" in host:
args["unix_socket"] = host
else:
self.socket = None
pair = host.split(":")
if len(pair) == 2:
args["host"] = pair[0]
args["port"] = int(pair[1])
else:
args["host"] = host
args["port"] = 3306
if port:
args['port'] = port
self._db = None
self._db_args = args
self._last_use_time = time.time()
try:
self.reconnect()
except BaseException as be:
logging.error("Cannot connect to MySQL on %s", self.host, exc_info=True)
def _ensure_connected(self):
# Mysql by default closes client connections that are idle for
# 8 hours, but the client library does not report this fact until
# you try to perform a query and it fails. Protect against this
# case by preemptively closing and reopening the connection
# if it has been idle for too long (7 hours by default).
if self._db is None or (time.time() - self._last_use_time > self.max_idle_time):
self.reconnect()
self._last_use_time = time.time()
def _cursor(self):
self._ensure_connected()
return self._db.cursor()
def __del__(self):
self.close()
def close(self):
"""Closes this database connection."""
if getattr(self, "_db", None) is not None:
self._db.close()
self._db = None
def reconnect(self):
"""Closes the existing database connection and re-opens it."""
self.close()
self._db = pymysql.connect(**self._db_args)
self._db.autocommit(True)
def query(self, query, *parameters, **kwparameters):
"""Returns a row list for the given query and parameters."""
cursor = self._cursor()
try:
cursor.execute(query, kwparameters or parameters)
result = cursor.fetchall()
return result
finally:
cursor.close()
def get(self, query, *parameters, **kwparameters):
"""Returns the (singular) row returned by the given query.
"""
cursor = self._cursor()
try:
cursor.execute(query, kwparameters or parameters)
return cursor.fetchone()
finally:
cursor.close()
def execute(self, query, *parameters, **kwparameters):
"""Executes the given query, returning the lastrowid from the query."""
cursor = self._cursor()
try:
cursor.execute(query, kwparameters or parameters)
return cursor.lastrowid
except Exception as e:
if e.args[0] == 1062:
pass
else:
traceback.print_exc()
raise e
finally:
cursor.close()
insert = execute
# =============== high level method for table ===================
def table_has(self, table_name, field, value):
if isinstance(value, str):
value = value.encode('utf8')
sql_str = f'SELECT {field} FROM {table_name} WHERE {field}="{value}"'
d = self.get(sql_str)
return d
def table_insert(self, table_name, item):
"""item is a dict : key is mysql table field"""
fields = list(item.keys())
values = list(item.values())
field_str = ','.join(fields)
val_str = ','.join(['%s'] * len(item))
for i in range(len(values)):
if isinstance(values[i], str):
values[i] = values[i].encode('utf8')
sql_str = f'INSERT INTO {table_name} ({field_str}) VALUES({val_str})'
try:
last_id = self.execute(sql_str, *values)
return last_id
except Exception as e:
if e.args[0] == 1062:
# just skip duplicated item
pass
else:
traceback.print_exc()
print('sql:', sql)
print('item:')
for i in range(len(fields)):
vs = str(values[i])
if len(vs) > 300:
print(fields[i], ' : ', len(vs), type(values[i]))
else:
print(fields[i], ' : ', vs, type(values[i]))
raise e
def table_update(self, table_name, updates, field_where, value_where):
"""updates is a dict of {field_update:value_update}"""
upsets = []
values = []
for k, v in updates.items():
s = '%s=%%s' % k
upsets.append(s)
values.append(v)
upsets = ','.join(upsets)
sql_str = f'UPDATE {table_name} SET {upsets} WHERE {field_where}="{value_where}"'
self.execute(sql_str, *values)
if __name__ == '__main__':
db = Connection(
'localhost',
'db_name',
'user',
'password'
)
# 获取一条记录
sql = 'select * from test_table where id=%s'
data = db.get(sql, 2)
# 获取多天记录
sql = 'select * from test_table where id>%s'
data = db.query(sql, 2)
# 插入一条数据
sql = 'insert into test_table(title, url) values(%s, %s)'
last_id = db.execute(sql, 'test', 'http://a.com/')
# 或者
last_id = db.insert(sql, 'test', 'http://a.com/')
# 使用更高级的方法插入一条数据
item = {
'title': 'test',
'url': 'http://a.com/',
}
last_id = db.table_insert('test_table', item)
functions.py
# -*- coding: utf-8 -*-
# @Author : 佛祖保佑, 永无 bug
# @Date :
# @File : functions.py
# @Software: PyCharm
# @description : XXX
import re
import requests
import cchardet
import traceback
import urllib.parse as urlparse
async def fetch(session=None, url=None, headers=None, timeout=9, binary=False):
_headers = {
'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; '
'Windows NT 6.1; Win64; x64; Trident/5.0)'),
}
_headers = headers if headers else _headers
try:
async with session.get(url, headers=_headers, timeout=timeout) as response:
status_code = response.status
html_bin_or_text = ''
html_content = await response.read()
if not binary:
encoding = cchardet.detect(html_content)['encoding']
html_bin_or_text = html_content.decode(encoding, errors='ignore')
request_url = str(response.url)
except Exception as e:
msg = 'Failed download: {} | exception: {}, {}'.format(url, str(type(e)), str(e))
print(msg)
html_bin_or_text = ''
status_code = -1
request_url = url
return status_code, html_bin_or_text, request_url
def downloader(url=None, timeout=10, headers=None, debug=False, binary=False):
_headers = {
'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; '
'Windows NT 6.1; Win64; x64; Trident/5.0)'),
}
_headers = headers if headers else _headers
request_url = url
try:
r = requests.get(url, headers=_headers, timeout=timeout)
if binary:
html_bin_or_text = r.content
else:
encoding = cchardet.detect(r.content)['encoding']
html_bin_or_text = r.content.decode(encoding, errors='ignore')
status_code = r.status_code
request_url = r.url
except BaseException as be:
if debug:
traceback.print_exc()
msg = 'failed download: {}'.format(url)
print(msg)
html_bin_or_text = b'' if binary else ''
status_code = -1
return status_code, html_bin_or_text, request_url
g_bin_postfix = {
'exe', 'doc', 'docx', 'xls', 'xlsx', 'ppt', 'pptx', 'pdf',
'jpg', 'png', 'bmp', 'jpeg', 'gif', 'zip', 'rar', 'tar',
'bz2', '7z', 'gz', 'flv', 'mp4', 'avi', 'wmv', 'mkv', 'apk'
}
g_news_postfix = ['.html?', '.htm?', '.shtml?', '.shtm?']
def clean_url(url=None):
# 1. 是否为合法的http url
if not url.startswith('http'):
return ''
# 2. 去掉静态化url后面的参数
for np in g_news_postfix:
p = url.find(np)
if p > -1:
p = url.find('?')
url = url[:p]
return url
# 3. 不下载二进制类内容的链接
up = urlparse.urlparse(url)
path = up.path
if not path:
path = '/'
postfix = path.split('.')[-1].lower()
if postfix in g_bin_postfix:
return ''
# 4. 去掉标识流量来源的参数
# badquery = ['spm', 'utm_source', 'utm_source', 'utm_medium', 'utm_campaign']
good_queries = []
for query in up.query.split('&'):
qv = query.split('=')
if qv[0].startswith('spm') or qv[0].startswith('utm_'):
continue
if len(qv) == 1:
continue
good_queries.append(query)
query = '&'.join(good_queries)
url = urlparse.urlunparse((
up.scheme,
up.netloc,
path,
up.params,
query,
'' # crawler do not care fragment
))
return url
g_pattern_tag_a = re.compile(r'<a[^>]*?href=[\'"]?([^> \'"]+)[^>]*?>(.*?)</a>', re.I | re.S | re.M)
def extract_links_re(url=None, html=None):
"""use re module to extract links from html"""
news_links = set()
tag_a_list = g_pattern_tag_a.findall(html)
for tag_a in tag_a_list:
link = tag_a[0].strip()
if not link:
continue
link = urlparse.urljoin(url, link)
link = clean_url(link)
if not link:
continue
news_links.add(link)
return news_links
def init_file_logger(f_name=None):
# config logging
import logging
from logging.handlers import TimedRotatingFileHandler
ch = TimedRotatingFileHandler(f_name, when="midnight")
ch.setLevel(logging.INFO)
# create formatter
fmt = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'
formatter = logging.Formatter(fmt)
# add formatter to ch
ch.setFormatter(formatter)
logger = logging.getLogger(f_name)
# add ch to logger
logger.addHandler(ch)
return logger
if __name__ == '__main__':
temp_url = 'http://news.baidu.com/'
t_status_code, t_html, t_url = downloader(url=temp_url)
print(f'[{t_status_code}, {t_url}]:{len(t_html)}')
config.py
db_host = 'localhost'
db_db = 'crawler'
db_user = 'your-user'
db_password = 'your-password'3、同步、异步、分布式
新闻爬虫 ( 同步 )
news_sync.py
# -*- coding: utf-8 -*-
# @Author : 佛祖保佑, 永无 bug
# @Date :
# @File : news_sync.py
# @Software: PyCharm
# @description : XXX
import urllib.parse as urlparse
import lzma
import farmhash
import traceback
from ezpymysql import Connection
from url_pool import UrlPool
import functions as fn
import config
class NewsCrawlerSync:
def __init__(self, name):
self.db = Connection(
config.db_host,
config.db_db,
config.db_user,
config.db_password
)
self.logger = fn.init_file_logger(name + '.log')
self.url_pool = UrlPool(name)
self.hub_hosts = None
self.load_hubs()
def load_hubs(self,):
sql = 'select url from crawler_hub'
data = self.db.query(sql)
self.hub_hosts = set()
hubs = []
for d in data:
host = urlparse.urlparse(d['url']).netloc
self.hub_hosts.add(host)
hubs.append(d['url'])
self.url_pool.set_hubs(hubs, 300)
def save_to_db(self, url, html):
url_hash = farmhash.hash64(url)
sql = f'select url from crawler_html where urlhash={url_hash}'
d = self.db.get(sql, url_hash)
if d:
if d['url'] != url:
msg = 'farm_hash collision: %s <=> %s' % (url, d['url'])
self.logger.error(msg)
return True
if isinstance(html, str):
html = html.encode('utf8')
html_lzma = lzma.compress(html)
sql = 'insert into crawler_html(urlhash, url, html_lzma) values(%s, %s, %s)'
good = False
try:
self.db.execute(sql, url_hash, url, html_lzma)
good = True
except Exception as e:
if e.args[0] == 1062:
# Duplicate entry
good = True
pass
else:
traceback.print_exc()
raise e
return good
def filter_good(self, urls):
good_links = []
for url in urls:
host = urlparse.urlparse(url).netloc
if host in self.hub_hosts:
good_links.append(url)
return good_links
def process(self, url, is_hub):
status, html, redirected_url = fn.downloader(url)
self.url_pool.set_status(url, status)
if redirected_url != url:
self.url_pool.set_status(redirected_url, status)
# 提取hub网页中的链接, 新闻网页中也有“相关新闻”的链接,按需提取
if status != 200:
return
if is_hub:
new_links = fn.extract_links_re(redirected_url, html)
good_links = self.filter_good(new_links)
print(f"{len(good_links)} / {len(new_links)}, good_links/new_links")
self.url_pool.add_many(good_links)
else:
self.save_to_db(redirected_url, html)
def run(self,):
while 1:
urls = self.url_pool.pop(5)
for url, is_hub in urls.items():
self.process(url, is_hub)
if __name__ == '__main__':
crawler = NewsCrawlerSync('sync_spider')
crawler.run()
新闻爬虫 ( 异步 )
news_async.py
# -*- coding: utf-8 -*-
# @Author : 佛祖保佑, 永无 bug
# @Date :
# @File : news_async.py
# @Software: PyCharm
# @description : XXX
import traceback
import time
import asyncio
import aiohttp
import urllib.parse as urlparse
import farmhash
import lzma
# import uvloop
# asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
import sanicdb
from url_pool import UrlPool
import functions as fn
import config
class NewsCrawlerAsync:
def __init__(self, name):
self.hub_hosts = set()
self._workers = 0
self._workers_max = 30
self.logger = fn.init_file_logger(name + '.log')
self.url_pool = UrlPool(name)
self.loop = asyncio.get_event_loop()
self.session = aiohttp.ClientSession(loop=self.loop)
self.db = sanicdb.SanicDB(
config.db_host,
config.db_db,
config.db_user,
config.db_password,
loop=self.loop
)
async def load_hubs(self, ):
sql = 'select url from crawler_hub'
data = await self.db.query(sql)
hubs = []
for d in data:
host = urlparse.urlparse(d['url']).netloc
self.hub_hosts.add(host)
hubs.append(d['url'])
self.url_pool.set_hubs(hubs, 300)
async def save_to_db(self, url, html):
url_hash = farmhash.hash64(url)
sql = 'select url from crawler_html where urlhash=%s'
d = await self.db.get(sql, url_hash)
if d:
if d['url'] != url:
msg = 'farmhash collision: %s <=> %s' % (url, d['url'])
self.logger.error(msg)
return True
if isinstance(html, str):
html = html.encode('utf8')
html_lzma = lzma.compress(html)
sql = 'insert into crawler_html(urlhash, url, html_lzma) values(%s, %s, %s)'
good = False
try:
await self.db.execute(sql, url_hash, url, html_lzma)
good = True
except Exception as e:
if e.args[0] == 1062:
# Duplicate entry
good = True
pass
else:
traceback.print_exc()
raise e
return good
def filter_good(self, urls):
good_links = []
for url in urls:
host = urlparse.urlparse(url).netloc
if host in self.hub_hosts:
good_links.append(url)
return good_links
async def process(self, url, is_hub):
status, html, redirected_url = await fn.fetch(self.session, url)
self.url_pool.set_status(url, status)
if redirected_url != url:
self.url_pool.set_status(redirected_url, status)
# 提取hub网页中的链接, 新闻网页中也有“相关新闻”的链接,按需提取
if status != 200:
self._workers -= 1
return
if is_hub:
new_links = fn.extract_links_re(redirected_url, html)
good_links = self.filter_good(new_links)
print(f"{len(good_links)} / {len(new_links)}, good_links / new_links")
self.url_pool.add_many(good_links)
else:
await self.save_to_db(redirected_url, html)
self._workers -= 1
async def loop_crawl(self):
await self.load_hubs()
last_rating_time = time.time()
counter = 0
while 1:
to_pop = self._workers_max - self._workers
tasks = self.url_pool.pop(to_pop)
if not tasks:
print('no url to crawl, sleep')
await asyncio.sleep(3)
continue
for url, is_hub in tasks.items():
self._workers += 1
counter += 1
print('crawl:', url)
asyncio.ensure_future(self.process(url, is_hub))
gap = time.time() - last_rating_time
if gap > 5:
rate = counter / gap
print(f'\tloop_crawl() rate:{round(rate, 2)}, counter: {counter}, workers: {self._workers}')
last_rating_time = time.time()
counter = 0
if self._workers > self._workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
def run(self):
try:
self.loop.run_until_complete(self.loop_crawl())
except KeyboardInterrupt:
print('stopped by yourself!')
del self.url_pool
pass
if __name__ == '__main__':
nc = NewsCrawlerAsync('async_spider')
nc.run()
分布式爬虫 ( CS 模型 )
server.py
# -*- coding: utf-8 -*-
# @Author : 佛祖保佑, 永无 bug
# @Date :
# @File : server.py
# @Software: PyCharm
# @description : XXX
from sanic import Sanic
from sanic import response
from my_url_pool import UrlPool
url_pool = UrlPool(__file__)
# 初始化 url_pool,根据你的需要进行修改
hub_urls = []
url_pool.set_hubs(hub_urls, 300)
url_pool.add('https://news.sina.com.cn/')
# init
main_app = Sanic(__name__)
@main_app.listener('after_server_stop')
async def cache_url_pool(app=None, loop=None):
global url_pool
print('caching url_pool after_server_stop')
del url_pool
print('bye!')
@main_app.route('/task')
async def task_get(request=None):
count = request.args.get('count', 10)
try:
count = int(count)
except BaseException as be:
count = 10
urls = url_pool.pop(count)
return response.json(urls)
@main_app.route('/task', methods=['POST', ])
async def task_post(request=None):
result = request.json
url_pool.set_status(result['url'], result['status'])
if result['url_real'] != result['url']:
url_pool.set_status(result['url_real'], result['status'])
if result['new_urls']:
print('receive URLs:', len(result['new_urls']))
for url in result['new_urls']:
url_pool.add(url)
return response.text('ok')
if __name__ == '__main__':
main_app.run(host='0.0.0.0', port=8080, debug=False, access_log=False, workers=1)
pass
client.py
# -*- coding: utf-8 -*-
# @Author : 佛祖保佑, 永无 bug
# @Date :
# @File : client.py
# @Software: PyCharm
# @description : XXX
import re
import cchardet
import traceback
import time
import json
import asyncio
import urllib.parse as urlparse
import aiohttp
# import uvloop
# asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
p_tag_a = re.compile(r'<a[^>]*?href=[\'"]?([^> \'"]+)[^>]*?>(.*?)</a>', re.I | re.S | re.M)
def extract_links_re(url, html):
new_links = set()
aa = p_tag_a.findall(html)
for a in aa:
link = a[0].strip()
if not link:
continue
link = urlparse.urljoin(url, link)
if not link.startswith('http'):
continue
new_links.add(link)
return new_links
class CrawlerClient:
def __init__(self, ):
self._workers = 0
self.workers_max = 20
self.server_host = 'localhost'
self.server_port = 8080
self.headers = {'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; '
'Windows NT 6.1; Win64; x64; Trident/5.0)')}
self.loop = asyncio.get_event_loop()
self.queue = asyncio.Queue(loop=self.loop)
self.session = aiohttp.ClientSession(loop=self.loop)
async def download(self, url, timeout=25):
status_code = 900
html = ''
url_now = url
try:
async with self.session.get(url_now, headers=self.headers, timeout=timeout) as response:
status_code = response.status
html = await response.read()
encoding = cchardet.detect(html)['encoding']
html = html.decode(encoding, errors='ignore')
url_now = str(response.url)
except BaseException as be:
# traceback.print_exc()
print('=== exception: ', be, type(be), str(be))
msg = 'Failed download: {} | exception: {}, {}'.format(url, str(type(be)), str(be))
print(msg)
return status_code, html, url_now
async def get_urls(self, ):
count = self.workers_max - self.queue.qsize()
if count <= 0:
print('no need to get urls this time')
return None
url = f'http://{self.server_host}:{self.server_port}/task?count={count}'
try:
async with self.session.get(url, timeout=3) as response:
if response.status not in [200, 201]:
return
jsn = await response.text()
urls = json.loads(jsn)
msg = f'get_urls() to get [{count}] but got[{len(urls)}], @{time.strftime("%Y-%m-%d %H:%M:%S")}'
print(msg)
for kv in urls.items():
await self.queue.put(kv)
print('queue size:', self.queue.qsize(), ', _workers:', self._workers)
except BaseException as be:
traceback.print_exc()
return
async def send_result(self, result):
url = f'http://{self.server_host}:{self.server_port}/task'
try:
async with self.session.post(url, json=result, timeout=3) as response:
return response.status
except BaseException as be:
traceback.print_exc()
pass
@staticmethod
def save_html(url, html):
print('saved:', url, len(html))
@staticmethod
def filter_good(urls):
"""根据抓取目的过滤提取的URLs,只要你想要的"""
good = []
for url in urls:
if url.startswith('http'):
good.append(url)
return good
async def process(self, url, is_hub):
status, html, url_now = await self.download(url)
self._workers -= 1
print('downloaded:', url, ', html:', len(html))
if html:
new_urls = extract_links_re(url, html)
new_urls = self.filter_good(new_urls)
self.save_html(url, html)
else:
new_urls = []
result = {
'url': url,
'url_real': url_now,
'status': status,
'new_urls': new_urls,
}
await self.send_result(result)
async def loop_get_urls(self, ):
print('loop_get_urls() start')
while 1:
await self.get_urls()
await asyncio.sleep(1)
async def loop_crawl(self, ):
print('loop_crawl() start')
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, url_level = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, url_level))
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
def start(self):
try:
self.loop.run_until_complete(self.loop_crawl())
except KeyboardInterrupt:
print('stopped by yourself!')
pass
def run():
ant = CrawlerClient()
ant.start()
if __name__ == '__main__':
run()
google 翻译
google 翻译:https://translate.google.cn/
# -*- coding: utf-8 -*-
# @Author : 佛祖保佑, 永无 bug
# @Date :
# @File : translate_google.py
# @Software: PyCharm
# @description : XXX
import requests
import urllib3
urllib3.disable_warnings()
def google_translate(kw=None):
url = 'https://translate.google.cn/_/TranslateWebserverUi/data/batchexecute?rpcids=MkEWBc&hl=zh-CN'
custom_headers = {
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8'
}
# kw = 'this is a test'
payload = f"f.req=[[[\"MkEWBc\",\"[[\\\"{kw}\\\",\\\"auto\\\",\\\"zh-CN\\\",true],[null]]\",null,\"generic\"]]]&"
resp = requests.post(url, data=payload, headers=custom_headers)
print(resp.status_code)
print(resp.text)
pass
if __name__ == '__main__':
kw_list = [
'I love u', 'hello, baby', 'king',
'this is a test'
]
for item in kw_list:
google_translate(kw=item)
pass
百度 翻译

查看 basetrans 请求。
( 多请求几次,可以发现 sign 每次都不一样,所以需要 逆向 sign )

使用 postman 来精简请求参数,看那些参数是必须的,那些参数是可以直接删除的。精简后参数
- 请求URL:https://fanyi.baidu.com/basetrans
- 请求头:Content-Type: application/x-www-form-urlencoded
Cookie: BAIDUID=AF87393A8DB7C8FED7859A909FF081A3:SL=0:NR=50:FG=1;
User-Agent: Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Mobile Safari/537.36 - 请求 body:query=king&from=en&to=zh&token=94c55bca8b920035077b58d58ba32bea&sign=612765.899756
postman 生成的 Python 代码:
import requests
url = "https://fanyi.baidu.com/basetrans"
payload = "query=king&from=en&to=zh&token=94c55bca8b920035077b58d58ba32bea&sign=612765.899756"
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'BAIDUID=AF87393A8DB7C8FED7859A909FF081A3:SL=0:NR=50:FG=1;',
'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Mobile Safari/537.36'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)JS 断点调试

打断点,然后通过调用堆栈追踪 sign 是怎么生成的。。。
因为 多个 ajax 请求都会走 b.send(e.data ? e.data:null) 这个函数,所以需要点击好几次 "跳转到下一个断点" 才能看到 sign 值。
如果想直接断点就能看到 sign 值,则可以添加 "URL包含" 断点。

这里使用 "跳转到下一个断点" 来追踪 sign 值。

生成 sign 的函数

点击 P(e) 函数,查看函数实现

方法 1:直接使用 Python 实现这个函数的逻辑
方法 2:把 js 代码扣出来,直接 Python 执行
代码太多,这里直接 扣 js 代码
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var e = o.charAt(t + 2);
e = e >= "a" ? e.charCodeAt(0) - 87 : Number(e),
e = "+" === o.charAt(t + 1) ? r >>> e : r << e,
r = "+" === o.charAt(t) ? r + e & 4294967295 : r ^ e
}
return r
}
function sign(r) {
var t = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === t) {
var a = r.length;
a > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(a / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var C = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), h = 0, f = C.length, u = []; f > h; h++)
"" !== C[h] && u.push.apply(u, e(C[h].split(""))),
h !== f - 1 && u.push(t[h]);
var g = u.length;
g > 30 && (r = u.slice(0, 10).join("") + u.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + u.slice(-10).join(""))
}
var l = void 0
, d = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
// l = null !== i ? i : (i = o.common[d] || "") || "";
l = "320305.131321201";
for (var m = l.split("."), S = Number(m[0]) || 0, s = Number(m[1]) || 0, c = [], v = 0, F = 0; F < r.length; F++) {
var p = r.charCodeAt(F);
128 > p ? c[v++] = p : (2048 > p ? c[v++] = p >> 6 | 192 : (55296 === (64512 & p) && F + 1 < r.length && 56320 === (64512 & r.charCodeAt(F + 1)) ? (p = 65536 + ((1023 & p) << 10) + (1023 & r.charCodeAt(++F)),
c[v++] = p >> 18 | 240,
c[v++] = p >> 12 & 63 | 128) : c[v++] = p >> 12 | 224,
c[v++] = p >> 6 & 63 | 128),
c[v++] = 63 & p | 128)
}
for (var w = S, A = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), b = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), D = 0; D < c.length; D++)
w += c[D], w = n(w, A);
return w = n(w, b),
w ^= s,
0 > w && (w = (2147483647 & w) + 2147483648),
w %= 1e6,
w.toString() + "." + (w ^ S)
}
console.log(sign('king'))执行结果:

也可以直接在 Chrome 上的 console 中执行 js

Python 直接调用 JS 代码( js_code = r"""js代码""" 中 r 不能少 )
// l = null !== i ? i : (i = o.common[d] || "") || ""; // l 的值 等于 gkt,通过调试可知,这是个固定值
l = "320305.131321201"; // 直接 令 l = "320305.131321201";
# @Author : 佛祖保佑, 永无 bug
# @Date :
# @File : translate_baidu.py
# @Software: PyCharm
# @description : XXX
import execjs
import requests
js_code = r"""
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var e = o.charAt(t + 2);
e = e >= "a" ? e.charCodeAt(0) - 87 : Number(e),
e = "+" === o.charAt(t + 1) ? r >>> e : r << e,
r = "+" === o.charAt(t) ? r + e & 4294967295 : r ^ e
}
return r
}
function sign(r) {
var t = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === t) {
var a = r.length;
a > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(a / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var C = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), h = 0, f = C.length, u = []; f > h; h++)
"" !== C[h] && u.push.apply(u, e(C[h].split(""))),
h !== f - 1 && u.push(t[h]);
var g = u.length;
g > 30 && (r = u.slice(0, 10).join("") + u.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + u.slice(-10).join(""))
}
var l = void 0
, d = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
// l = null !== i ? i : (i = o.common[d] || "") || "";
l = "320305.131321201";
for (var m = l.split("."), S = Number(m[0]) || 0, s = Number(m[1]) || 0, c = [], v = 0, F = 0; F < r.length; F++) {
var p = r.charCodeAt(F);
128 > p ? c[v++] = p : (2048 > p ? c[v++] = p >> 6 | 192 : (55296 === (64512 & p) && F + 1 < r.length && 56320 === (64512 & r.charCodeAt(F + 1)) ? (p = 65536 + ((1023 & p) << 10) + (1023 & r.charCodeAt(++F)),
c[v++] = p >> 18 | 240,
c[v++] = p >> 12 & 63 | 128) : c[v++] = p >> 12 | 224,
c[v++] = p >> 6 & 63 | 128),
c[v++] = 63 & p | 128)
}
for (var w = S, A = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), b = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), D = 0; D < c.length; D++)
w += c[D], w = n(w, A);
return w = n(w, b),
w ^= s,
0 > w && (w = (2147483647 & w) + 2147483648),
w %= 1e6,
w.toString() + "." + (w ^ S)
}
console.log(sign('king'))
"""
js_func = execjs.compile(js_code)
def bd_translate(kw=None):
url = "https://fanyi.baidu.com/basetrans"
sign = js_func.call('sign', kw)
payload = f"query={kw}&from=en&to=zh&token=94c55bca8b920035077b58d58ba32bea&sign={sign}"
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'BAIDUID=AF87393A8DB7C8FED7859A909FF081A3:SL=0:NR=50:FG=1;',
'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Mobile Safari/537.36'
}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
print(response.json()['trans'][0]['dst'])
if __name__ == '__main__':
kw_list = [
'hello baby', 'I love u',
'king'
]
for item in kw_list:
bd_translate(kw=item)
pass
执行结果:

有道 翻译
:https://blog.csdn.net/DCSDA/article/details/137020704
:https://blog.csdn.net/qq_49268524/article/details/136679113
使用 crypto 模块进行加密和解密:https://blog.csdn.net/qq_53931766/article/details/130233527
主要参数 sign 值加密 -----> md5加密
response 响应数据 data 解密 -----> AES解密
目标网址:https://fanyi.youdao.com/index.html#/TextTranslate
接口分析
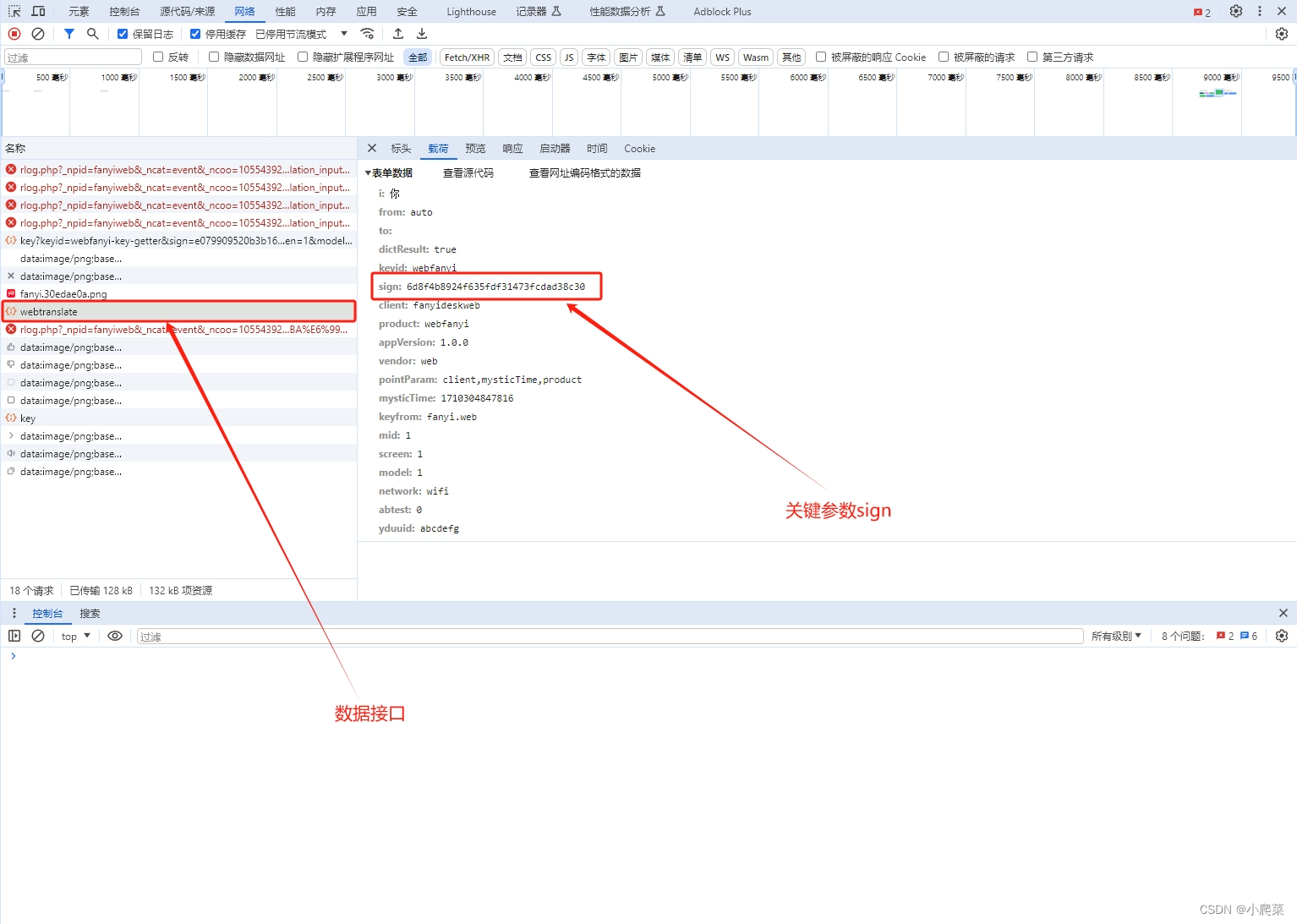
看 调用顺序
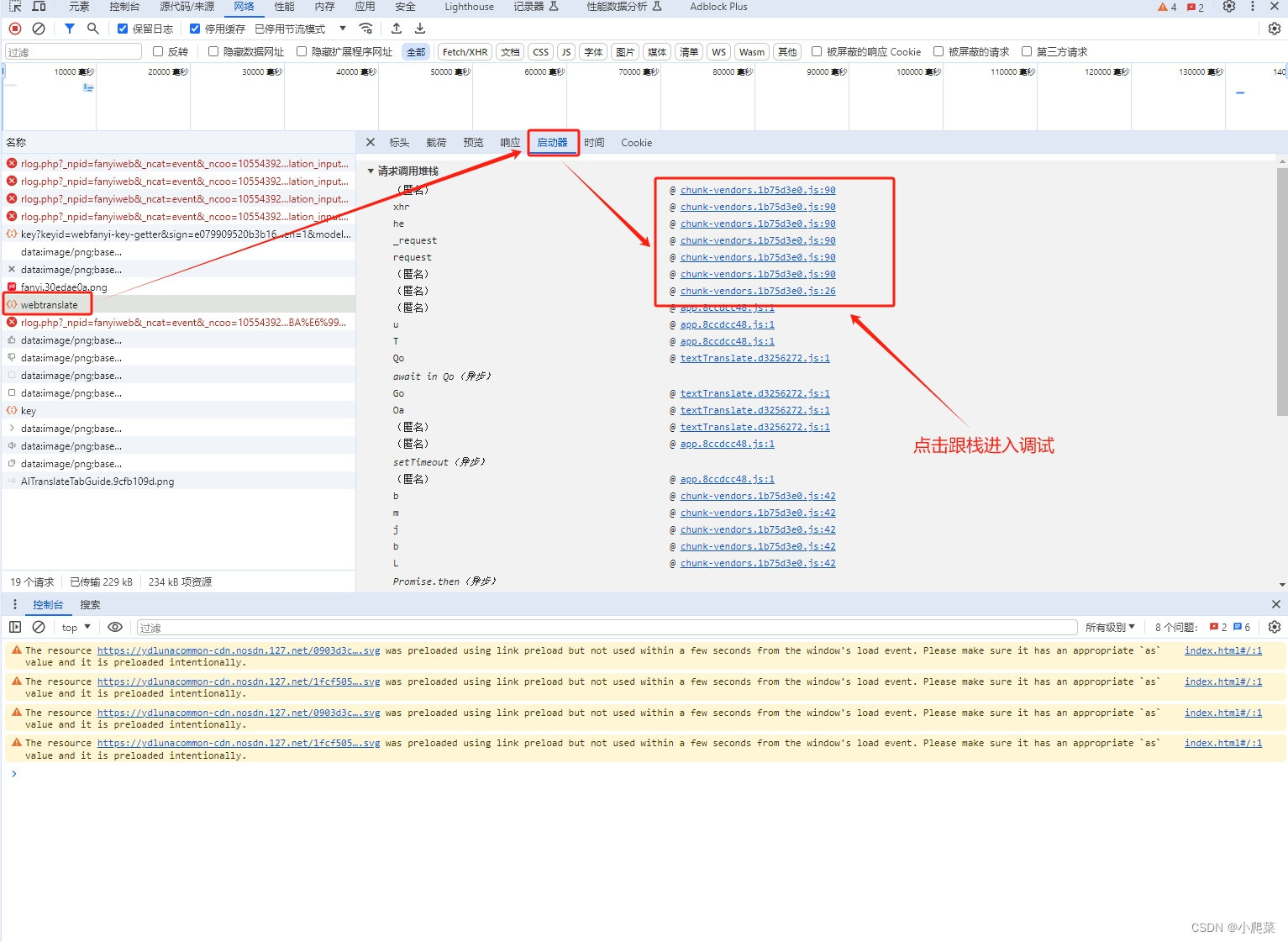
定位 关键 位置
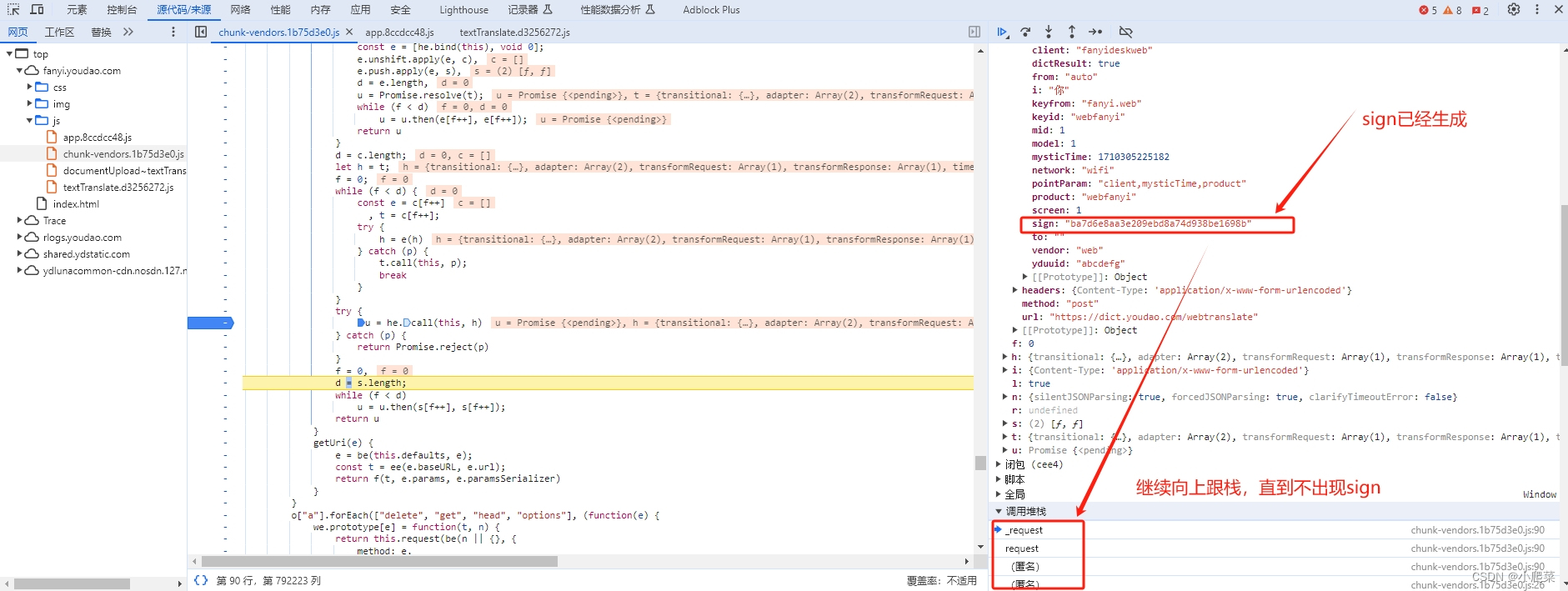
追踪 堆栈,查找调用位置
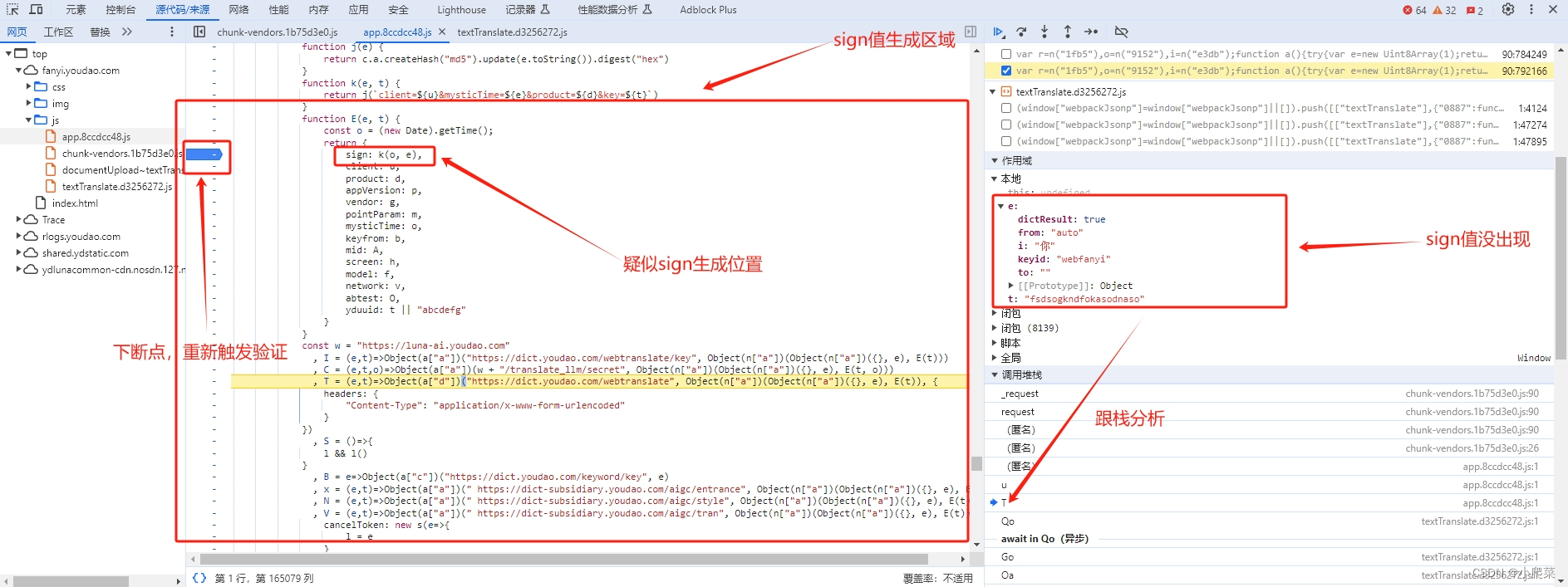
继续往上追踪调用堆栈
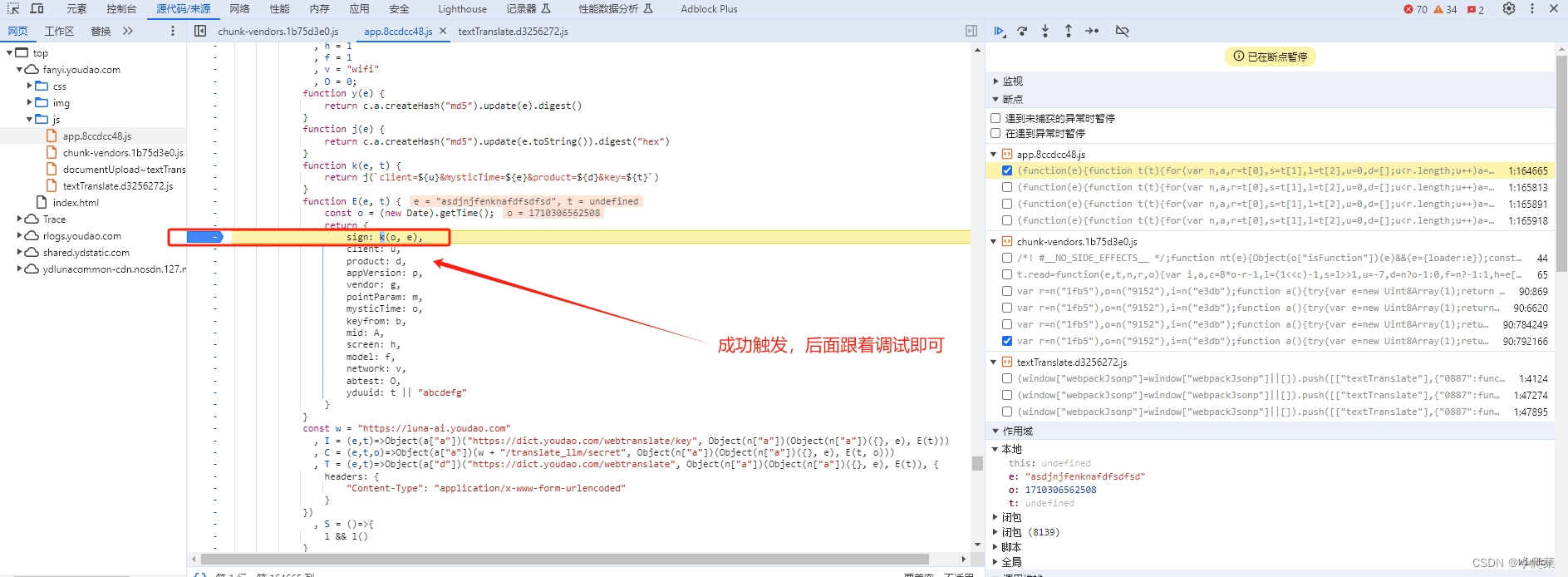
sign 值生成逻辑
// c.a为crypto加密模块,直接导包替换就好
function j(e) {
return c.a.createHash("md5").update(e.toString()).digest("hex")
}
function k(e, t) {
return j(`client=${u}&mysticTime=${e}&product=${d}&key=${t}`)
}
const o = (new Date).getTime();
let e = 'fsdsogkndfokasodnaso'
// sign值生成
// e为固定值
// o为时间戳
sign = k(o, e)
整合封装代码:set_post_data.js
const Crypto = require("crypto");
const u = "fanyideskweb",
d = "webfanyi",
m = "client,mysticTime,product",
p = "1.0.0",
g = "web",
b = "fanyi.web",
A = 1,
h = 1,
f = 1,
v = "wifi",
O = 0;
function j(e) {
return Crypto.createHash("md5").update(e.toString()).digest("hex")
}
function k(e, t) {
return j(`client=${u}&mysticTime=${e}&product=${d}&key=${t}`)
}
function set_post_data(txt) {
const o = (new Date).getTime();
let e = 'fsdsogkndfokasodnaso'
return {
i: txt,
from: 'auto',
to: '',
dictResult: 'true',
keyid: 'webfanyi',
sign: k(o, e),
client: u,
product: d,
appVersion: p,
vendor: g,
pointParam: m,
mysticTime: o,
keyfrom: b,
mid: A,
screen: h,
model: f,
network: v,
abtest: O,
yduuid: "abcdefg"
}
}
使用 python 调用验证请求
import requests
import execjs
cookies = {....}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': 'https://fanyi.youdao.com',
'Pragma': 'no-cache',
'Referer': 'https://fanyi.youdao.com/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
with open('./set_post_data.js', 'r', encoding='utf-8') as f:
set_post_data_code = f.read()
data = execjs.compile(set_post_data_code).call('set_post_data', txt)
response = requests.post('https://dict.youdao.com/webtranslate', headers=headers, cookies=cookies, data=data)
print(response.text)
执行结果

数据解密
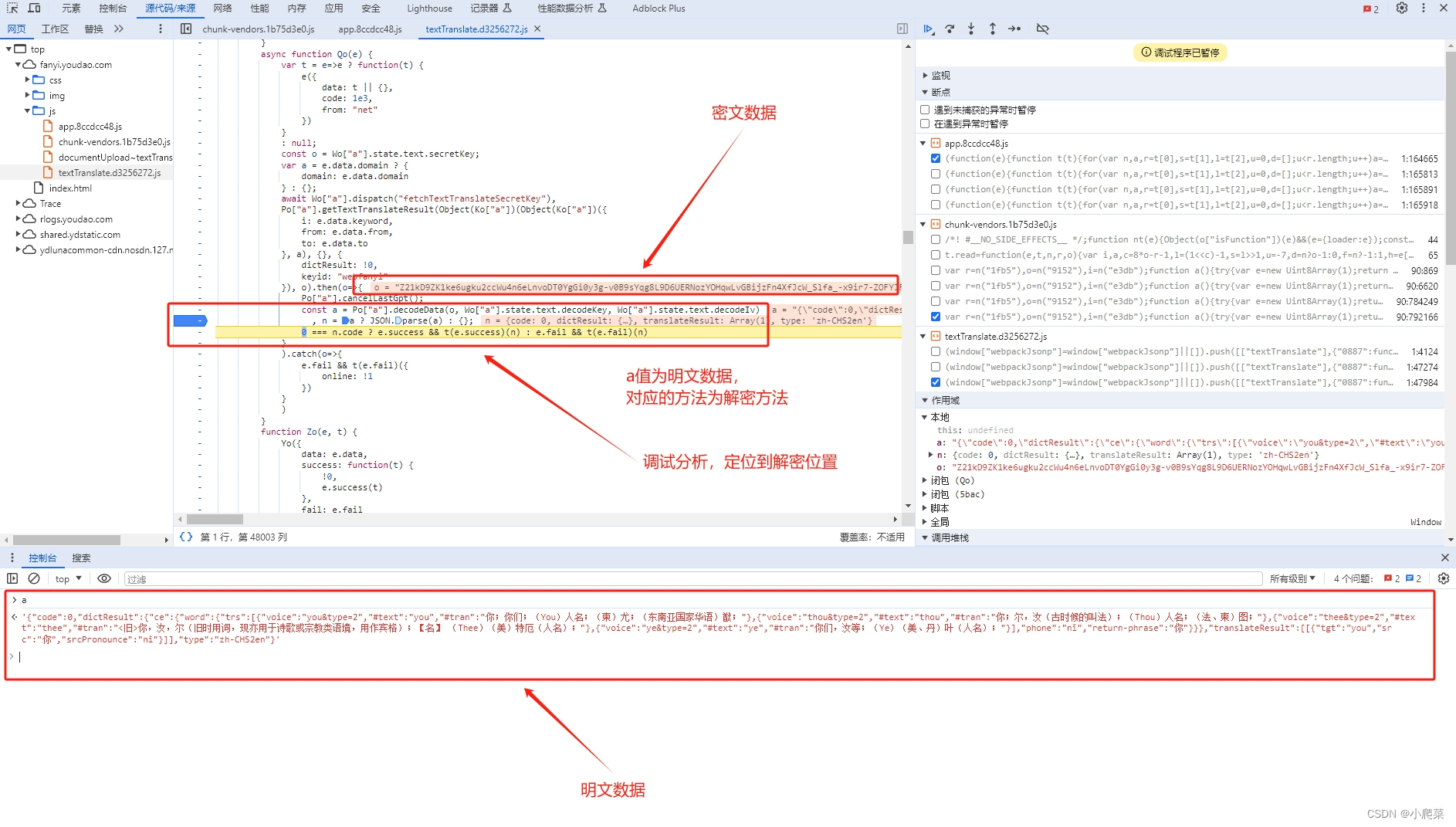
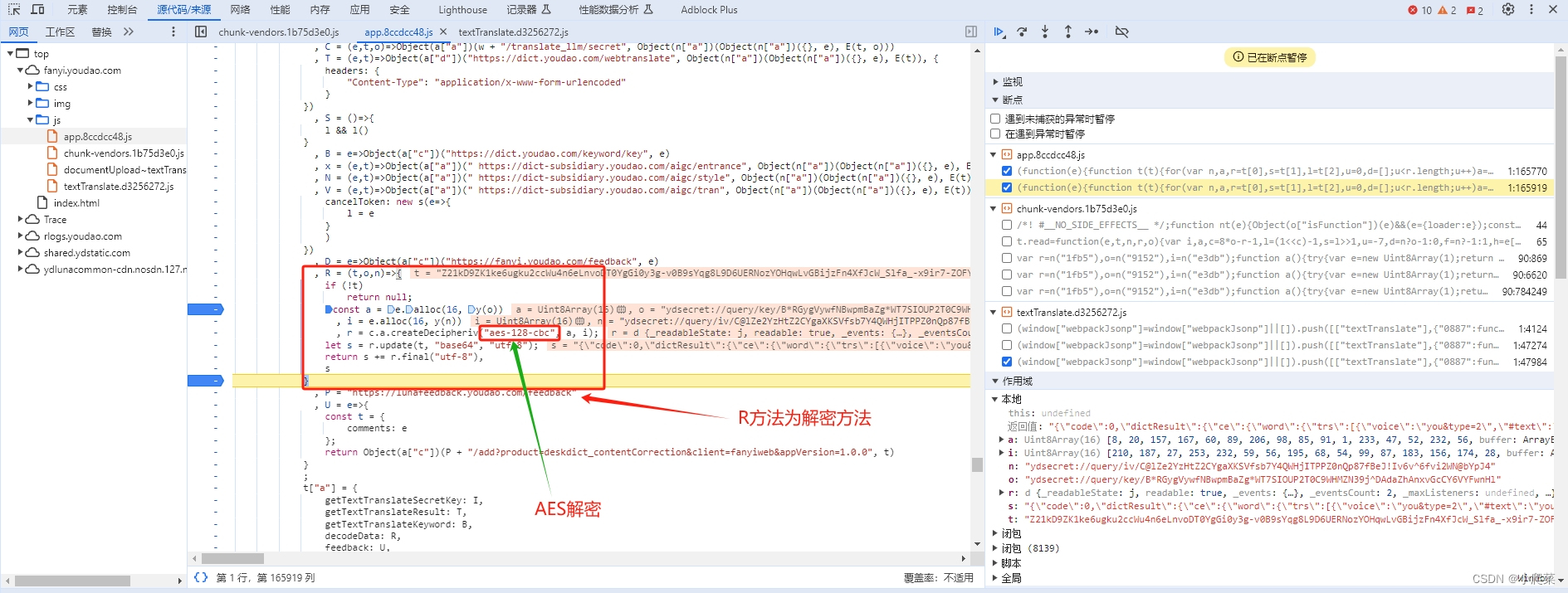
解密 js 分析
//解密分析
// c.a为crypto加密模块,直接导包替换就好
function y(e) {
return c.a.createHash("md5").update(e).digest()
}
R = (t,o,n)=>{
if (!t)
return null;
const a = e.alloc(16, y(o))
, i = e.alloc(16, y(n))
, r = c.a.createDecipheriv("aes-128-cbc", a, i);
let s = r.update(t, "base64", "utf-8");
return s += r.final("utf-8"),
s
}
// t为加密数据data
// o为key值
// n为iv值
// 固定值可写死
let o = "ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl";
// 固定值可写死
let n = "ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4";
整合封装代码:get_data.js
const Crypto = require("crypto");
function y(e) {
// 使用 md5 算法创建一个哈希对象
return Crypto.createHash("md5")
// 更新哈希对象的内容为参数 e
.update(e)
// 获取哈希值并返回
.digest()
}
function get_data(data){
// 定义变量o,存储密钥
let o = "ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl";
// 定义变量n,存储初始化向量
let n = "ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4";
// 调用函数y,传入密钥o,将返回值赋给变量a
const a = y(o)
// 调用函数y,传入初始化向量n,将返回值赋给变量i
, i = y(n)
// 创建解密器r,使用AES-128-CBC算法,密钥为a,初始化向量为i
, r = Crypto.createDecipheriv("aes-128-cbc", a, i);
// 使用解密器r对传入的base64编码的数据data进行解密,结果以utf-8编码
let s = r.update(data, "base64", "utf-8");
// 将解密器r的最终结果以utf-8编码添加到s中,并返回s
return s += r.final("utf-8"),
s
}
用 python 实现
import base64
from Crypto.Cipher import AES
import hashlib
def decode_data(text):
# 偏移量
decodeiv = "ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4"
# 秘钥
decodekey = "ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl"
# 先把密匙和偏移量进行md5加密 digest()是返回二进制的值
key = hashlib.md5(decodekey.encode(encoding='utf-8')).digest()
iv = hashlib.md5(decodeiv.encode(encoding='utf-8')).digest()
# AES解密 CBC模式解密
aes_en = AES.new(key, AES.MODE_CBC, iv)
# 将已经加密的数据放进该方法
data_new = base64.urlsafe_b64decode(text)
# 参数准备完毕后,进行解密
a = aes_en.decrypt(data_new).decode('utf-8').strip()
return a
整合代码使用 python 调用
import requests
import execjs
import json
def youdao_translation(txt, headers, cookies):
try:
with open('./set_post_data.js', 'r', encoding='utf-8') as f:
set_post_data_code = f.read()
data = execjs.compile(set_post_data_code).call('set_post_data', txt)
response = requests.post('https://dict.youdao.com/webtranslate', headers=headers, cookies=cookies, data=data)
if response.status_code != 200:
raise Exception(f"无法获得翻译状态码: {response.status_code}")
with open('./get_data.js', 'r', encoding='utf-8') as f:
get_data_code = f.read()
result = execjs.compile(get_data_code).call('get_data', response.text)
print(json.loads(result)['translateResult'][0][0]['tgt'])
except FileNotFoundError:
print("没有找到一个所需的JS文件.")
except execjs.ProgramError:
print("日志含义执行JavaScript代码失败.")
except requests.RequestException:
print("建立网络失败")
if __name__ == '__main__':
cookies = {....}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': 'https://fanyi.youdao.com',
'Pragma': 'no-cache',
'Referer': 'https://fanyi.youdao.com/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
youdao_translation('你好', headers, cookies)
最终代码
import json
import execjs
import requests
from thquickjs.thquickjs import QuickJS
"""
pip install thquickjs
"""
qjs = QuickJS()
js_code_1 = """
const Crypto = require("crypto");
const u = "fanyideskweb",
d = "webfanyi",
m = "client,mysticTime,product",
p = "1.0.0",
g = "web",
b = "fanyi.web",
A = 1,
h = 1,
f = 1,
v = "wifi",
O = 0;
function j(e) {
return Crypto.createHash("md5").update(e.toString()).digest("hex")
}
function k(e, t) {
return j(`client=${u}&mysticTime=${e}&product=${d}&key=${t}`)
}
function set_post_data(txt) {
const o = (new Date).getTime();
let e = 'fsdsogkndfokasodnaso'
return {
i: txt,
from: 'auto',
to: '',
useTerm: 'false',
dictResult: 'true',
keyid: 'webfanyi',
sign: k(o, e),
client: u,
product: d,
appVersion: p,
vendor: g,
pointParam: m,
mysticTime: o,
keyfrom: b,
mid: A,
screen: h,
model: f,
network: v,
abtest: O,
yduuid: "abcdefg"
}
}
"""
js_code_2 = """
const Crypto = require("crypto");
function y(e) {
// 使用 md5 算法创建一个哈希对象
return Crypto.createHash("md5")
// 更新哈希对象的内容为参数 e
.update(e)
// 获取哈希值并返回
.digest()
}
function get_data(data){
// 定义变量o,存储密钥
let o = "ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl";
// 定义变量n,存储初始化向量
let n = "ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4";
// 调用函数y,传入密钥o,将返回值赋给变量a
const a = y(o)
// 调用函数y,传入初始化向量n,将返回值赋给变量i
, i = y(n)
// 创建解密器r,使用AES-128-CBC算法,密钥为a,初始化向量为i
, r = Crypto.createDecipheriv("aes-128-cbc", a, i);
// 使用解密器r对传入的base64编码的数据data进行解密,结果以utf-8编码
let s = r.update(data, "base64", "utf-8");
// 将解密器r的最终结果以utf-8编码添加到s中,并返回s
return s += r.final("utf-8"), s
}
"""
def get_post_data(txt="hello"):
json_dict = execjs.compile(js_code_1).call('set_post_data', txt)
return json_dict
def get_data(resp_text):
result = execjs.compile(js_code_2).call('get_data', resp_text)
return result
def web_translate(raw_text='hello'):
post_data = get_post_data(raw_text)
url = 'https://dict.youdao.com/webtranslate'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': 'https://fanyi.youdao.com',
'Pragma': 'no-cache',
'Referer': 'https://fanyi.youdao.com/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
cookies = {
"OUTFOX_SEARCH_USER_ID": "-1579084576@61.173.21.108",
# "OUTFOX_SEARCH_USER_ID_NCOO": "1234777574.1625025",
# "DICT_DOCTRANS_SESSION_ID": "ODk3ZTY4NzAtMTUyMS00MzBhLWFkYjAtZGJiZWZmOGI0MGIx"
}
response = requests.post(url, headers=headers, cookies=cookies, data=post_data)
resp_text = response.text
decrypt_text = get_data(resp_text)
data_dict = json.loads(decrypt_text)
# print(data_dict)
print(f'原始文本 ---> {raw_text}')
print(f'翻译文本 ---> {data_dict["translateResult"][0][0]["tgt"]}')
pass
if __name__ == '__main__':
web_translate('hello')
web_translate('this is a test')
web_translate('今天是个好天气')
pass执行结果
原始文本 ---> hello
翻译文本 ---> 你好
原始文本 ---> this is a test
翻译文本 ---> 这是一个测试
原始文本 ---> 今天是个好天气
翻译文本 ---> It's a fine day today
百度指数 js 破解
分析过程参考:https://blog.csdn.net/wang785994599/article/details/97135979
Python爬虫 - 简单抓取百度指数:https://zhuanlan.zhihu.com/p/78634149
Python 代码实现( 直接从浏览器拿到登录后的Cookie复制粘贴到代码中 ):
# -*- coding: utf-8 -*-
import requests
import execjs
import urllib3
# 禁用警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
js_string = '''
function decrypt(t, e) {
for (var n = t.split(""), i = e.split(""), a = {}, r = [], o = 0; o < n.length / 2; o++)
a[n[o]] = n[n.length / 2 + o];
for (var s = 0; s < e.length; s++)
r.push(a[i[s]]);
return r.join("")
}
'''
headers = {
"Cookie": "直接从浏览器拿到登录后的Cookie复制粘贴",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/75.0.3770.142 Safari/537.36"
}
data_url = 'https://index.baidu.com/api/SearchApi/index?word={}&area=0&days=7'
uniq_id_url = 'https://index.baidu.com/Interface/ptbk?uniqid={}'
keys = ["all", "pc", "wise"]
class BDIndex(object):
def __init__(self):
self.session = self.get_session()
pass
@staticmethod
def get_session():
"""
初始化 session 会话
:return:
"""
session = requests.session()
session.headers = headers
session.verify = False
return session
@staticmethod
def decrypt(key, data):
"""
得到解密后的数据
:param key: key
:param data: key 对应的 value
:return:
"""
js_handler = execjs.compile(js_string)
return js_handler.call('decrypt', key, data)
def get_bd_index(self, key_word):
"""
得到百度指数
:param key_word:
:return:
"""
response = self.session.get(data_url.format(key_word)).json()
uniq_id = self.session.get(
uniq_id_url.format(response.get("data").get("uniqid"))
).json().get("data")
result = []
data_dict = response.get("data").get("userIndexes")[0]
for key in keys:
decrypt_data = self.decrypt(uniq_id, data_dict.get(key).get("data"))
result.append({key: decrypt_data})
return result
if __name__ == '__main__':
bd = BDIndex()
d = bd.get_bd_index("杨幂")
print(d)
运行结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









