






最近发现几个查询失效的问题,原因是通过Excel导入的用户数据忘了去掉空格,想通过sql语句把数据统计处理掉,去掉包含的空格,数据及语句如下

模糊LIKE查询
SELECT * FROM `user` WHERE name like '% %'
更新
update `user` set name =REPLACE(name,' ','')
看似没啥问题,也查到了一些包含空格的数据并处理掉。返回表中一看,怎么还有包含空格的数据,并且之前的SQL无论如何也查询不出来
通过在SQL中采用REGEXP正则查询却又能查询出来
SELECT * FROM `user` WHERE name REGEXP '[[:blank:]]'
如下

经过一翻找原因,又是思考mysql配置,又是字段类型,没啥问题。然后考虑是否UTF8字符编码问题,通过十六进制结果对比之前like '% %'查询到的结果,发现空格的十六进制编码不一样
可以被like '% %'匹配的,空格的编码是20
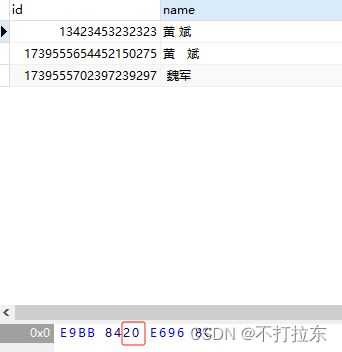
而不能匹配的是E38080
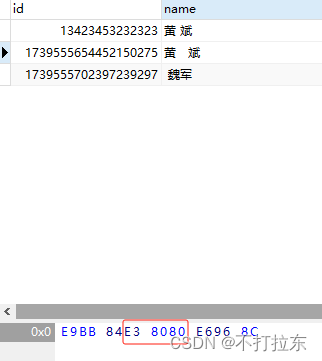
通过资料很容易发现,原来导入的数据中有的空格是全角空格,而我这用的半角空格,因此无法匹配
切换全角输入再查询
SELECT * FROM `user` WHERE name LIKE '% %';
发现还是有问题,怎么只查询到中间的这条黄 斌,而下面的 魏军,无论半角,全角都查不到呢。
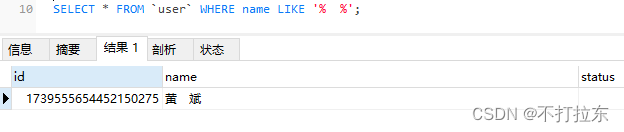
而 魏军的编码又是E28085,这又是什么呢

通过查询了解
这三个不同的十六进制编码分别代表三种不同类型的空格或间距字符,在Unicode字符集中有不同的用途和外观:
\x20(十进制32)是普通空格(Space, U+0020),这是最常见的空格类型,也是ASCII字符集中定义的标准空格,通常在英> 语和其他拉丁字母文字中用于单词间的间隔。
\xE3\x80\x80(十进制918304)是全角空格(Ideographic Space, U+3000),在日本汉字和其他东亚文字中常用,它的宽度与CJK字符(中日韩统一表意文字)相同,通常用于这些语言的文字排版中,以保持整体布局的一致性。
\xE2\x80\x85(十进制8203)是非breaking narrow space(En Space, U+2005),它是一种相对窄的、不可换行的空间符号,其宽度小于普通空格但大于thin space,常用于精确的排版布局中,特别是在数字、度量单位等需要固定间距的地方,保证美观的同时防止换行时断开不应该分开的部分。
总结一下区别:
- 普通空格(U+0020)是最常见的,用于英文文本中;
- 全角空格(U+3000)主要用于东亚语言排版,宽度与汉字相当;
- 非breaking narrow space(U+2005)是一个窄的、排版上使用的特殊空格,用于保持特定距离而又不希望自动换行的位置。
- 由于数据来源千奇百怪,为了谨慎,查询带空格的SQL语句请使用
SELECT * FROM `user` WHERE name REGEXP '[[:blank:]]'
有意思的是,通过查询资料说 'REGEXP ‘[[:blank:]]’ 在MySQL中仅匹配普通半角空格(U+0020)和水平制表符(U+0009),并不会匹配全角空格(U+3000)和窄非-breaking空格(U+2005),然而实际上可以查询到。不知道这跟版本或系统有无关系,有人发现可以来评论中讨论一下


















 3706
3706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









