







免费大餐不久就将结束。对此,你有何打算,做好下一步准备了么?
对主要的处理器厂商以及架构,包括 Intel 、 AMD 和 Sparc 、 PowerPC[ 译注 1] 来说,改善 CPU 性能的传统方法,如提升时钟速度和指令吞吐量,基本已走到尽头,现在开始向超线程和多核架构靠拢。而且这两个特性(特别是多核)已经在部分芯片实现,如 PowerPC 和 Sparc IV ; Intel 和 AMD 也将在 2005 年内赶上。 2004 年 In-Stat/MDR 秋季处理器论坛 [ 译注 2] 的主题就是多核设备,很多公司都展示了改进和新研发的多核处理器。不过,要将 2004 年称为多核年,显然还不够理直气壮。
多核将引领软件研发发生基础性变化,特别对接下来几年里那些面向一般应用、运行在 PC 和低端服务器上的应用软件(在今天已经销售出去的软件里占有很大比例)而言。在这篇文章里,我想就多核为何突然对软件产生重要影响,以及并发巨变如何影响我们和我们未来编写软件方式的问题展开讨论。
我可以这么说:免费大餐已经结束一两年了,但我们现在才开始意识到这个问题。
免费的性能大餐
业界存在一个有趣的现象:“安迪送,比尔取。” [ 译注 3] 无论处理器性能提升多少,软件都有办法迅速吞噬。 CPU 速度十倍于前,软件就有十倍于前的活要干(或者肆无忌惮猛增软件的工作量,导致性能下降)。在过去几十年里,由于 CPU 、内存和硬盘特别是 CPU 厂商强力推进主流系统向更新更快的方向发展,大多数软件不做版本升级,甚至原封不动,就可轻松而持续地享受处理器性能提升的成果。尽管时钟速度不是衡量系统性能的唯一和最好的标尺,但其重要意义不容忽视。我们见证了 CPU 的发展历史:从 500MHz 到 1GHz ,然后再到 2GHz ,不断提高。今天,主流计算机已经进入 3GHz 时代。
不过,有一个很关键的问题:这种提升模式什么时候会走到尽头?尽管莫尔定律预言了历史上的指数式增长,但我们很清楚指数式增长不可能永远维持,因为硬件毕竟受物理极限约束;光速是不可能更快的 [ 译注 4] 。所以增长必然放缓,最后停滞。顺便说明一点,莫尔定律的主要描述对象是晶体管集成密度,但在一些相关的领域,如时钟速度方面,也出现了类似的指数式增长;甚至在别的领域有更快的增长速度,例如著名的数据存储量爆炸。不过这些重要趋势需要另一篇文章来分析了。
如果你是一个软件开发人员,那么你可能一直在免费享受桌面计算机性能提升的大餐。某些操作会成为应用程序性能的瓶颈?“你过虑了”,我们对这样的回答耳熟能详,“未来处理器将更为强劲,而现在的应用程序速度倒是日益被非 CPU 吞吐量和内存速度因素扼杀,比如 I/O 、网络和数据库等等。”真的是这样么?
要在过去,这的确没错。但在以后,就完全不对了。
我有两个消息要告诉大家。第一个是好消息,处理器性能仍然会不断提高。第二个则是坏消息,至少在短时间内,处理器性能的提升,不再能像以往那样让现在的应用程序继续免费获益。
过去 30 年里, CPU 设计者主要从三个方面提高 CPU 性能,头两个就是从线性执行流程上考虑的:
1 、时钟速度
2 、执行优化
3 、缓存
提升时钟速度将增大单位时间的时钟周期数。让 CPU 跑得更快,就意味着能让同样工作或多或少更快完成。
优化指令执行,可以在每个时钟周期内完成更多工作。目前的 CPU 中,一些指令被不同程度地做了优化,如管线、分支预测、同一时钟周期内执行更多指令,甚至指令流再排序支持乱序执行等 [ 译注 5] 。引入这些技术的目的是让指令流更好、更快执行,降低延迟时间,挖掘每一时钟周期内芯片的工作潜能。
在这里,有必要对指令再排序作个简单说明。我刚才提到的部分指令优化手段,其实已远非普通意义上的优化。这些优化可能改变程序原意,造成程序不响应程序员的正常要求。这可是个大问题。 CPU 设计师都是心智健全且经过严格训练的好同志,正常情况下,他们连苍蝇都不愿伤害,自然也无意破坏你的程序。而在最近几年里,尽管知道指令重组有破坏程序语义的风险,但为了提升每个时钟周期内的工作效率,他们已经习惯于积极开展这类有风险的优化工作。难道海德先生 [ 译注 6] 复活了?当然不是。这种积极性清楚表明,芯片设计师承受了交付速度更快 CPU 的巨大压力;在这种压力下,为了让软件跑得更快,他们不得不冒改变程序意思,甚至应用崩溃的风险。 拿两个有名的例子来说——写操作再排序和读操作再排序 [ 译注 7] 。 允许处理器对写操作再排序是非常令人吃惊的,让大多数程序员意外,一般来说这个特性必须关闭,因为在写操作被处理器武断地再排序条件下,程序员很难保证程 序正确执行。读操作再排序也有明显的问题,但大多数情况下这个特性是开启的;因为相对来说它更容易把握一些,而且人们对性能的要求,让操作系统和操作环境 设计师只能选择让程序员在一定程度吃点苦头,毕竟,这比直接放弃性能优化机会的罪责小一些。
第三个是增大与 RAM 分离的片内高速缓存。 RAM 一直比 CPU 慢很多,因此让数据近可能靠近处理器就很重要——当然那就是片内了 [ 译注 8] 。片内缓存持续飚升了很多年,现在的主流芯片商出售的 CPU 都带有 2M 甚至更高的二级缓存。值得一提的是,今后,三种提升 CPU 性能的传统手段里,增加缓存将硕果仅存。我会在后面更详细说明缓存的重要性。
我写这么多的意思是什么呢?
最重要的是我们必须认识到,传统性能提升方法与并发没有直接关系。过去任何方法带来的速度提升,无论是顺序(非并行的单线程或单进程)、还是并发执行的程序,都能直接受益。这点很重要,我们目前大量的程序都是单线程的,而且在未来仍然有重要的存在价值。
当然,适当时候,我们重新编译程序,可以利用 CPU 的新指令(如 MMX 、 SSE[ 译注 9] )和新特性提升系统性能。但总的来说,即使放弃使用新指令和新特性,不做任何更改,老程序在新 CPU 也会跑得更快,让人心花怒放。
曾经的世界是这般美好,可如今,她就要变了颜色。
为什么我们今天没有 10GHz 芯片
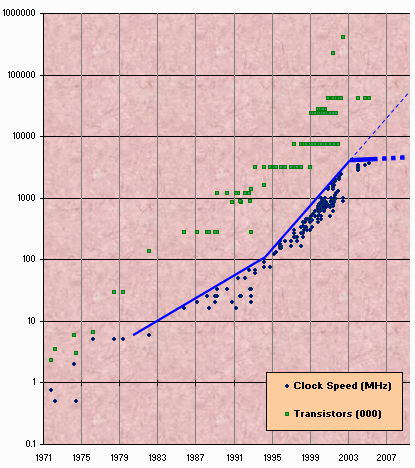
其实, CPU 性能提升在两年前就开始碰壁,但大多数人到了最近才有所觉察。
我这里有份来自 Intel 的数据(当然你可以从其他厂商得到类似数据)。图中反映了 Intel 芯片的时钟速度和晶体管集成规模演变历史。晶体管集成数至少就目前而言仍在继续上升,但时钟速度的情况就不同了。
我们从图中可以看到,大概在 2003 年初,一路高歌猛进的 CPU 时钟速度突然急刹车。受制于一些物理学问题,如散热(发热量太大且难以驱散)、功耗(太高)以及泄漏问题 [ 译注 10] 等,时钟速度的提升已经越来越难。
你目前在工作站上用的 CPU 时钟速度是多少? 10GHz 么? 2001 年 8 月 Intel 芯片就达到 2GHz ,按照 2003 年前的 CPU 发展趋势推算,到 2005 年初,我们就能拥有第一块 10GHz 的 Pentium 芯片。但实际上没办到。而且情况好像越来越糟——我们根本就不知道到底在什么时候这样的芯片可以出现。
那么放低期望, 4GHz 又如何呢?目前我们已到 3.4GHz ——那么 4GHz 已经不远了吧?唉,好像 4GHz 也遥不可及。可能你知道, Intel 首先于 2004 年中将 4GHz 芯片的发布时间推迟到 2005 年,而到了 2004 年秋季,则彻底取消了 4GHz 计划 [ 译注 11] 。在本文写作的同时, Intel 宣布计划到 2005 年早期,实现到 3.73GHz (即图中的右上最高处)的微量提升。所以,至少就目前来说,时钟速度的竞赛实际上结束了, Intel 和其他大多数处理器厂商将把旺盛的精力投入到多核等方向去。
也许,我们某天在主流 PC 里能装上 4GHz 的 CPU ,但 2005 年别想。 Intel 实验室里的确已经有运行在更高速度的芯片——不过代价是惊人的,比如庞大数量的冷却装置。你想不久在你的办公室里就有这样的冷却设备,坐飞机的时候,就把它们放在你膝盖上?别做梦了!
莫尔定律与新一代处理器
“没有免费的午餐。”——摘自 R. A. Heinlein 的小说《 The Moon Is a Harsh Mistress 》。
莫尔定律玩完了?这个问题很有趣,严格地讲,还不能这么说。尽管和所有的指数式增长方式一样,莫尔定律总有一天会走到尽头,但最近这些年,还没有这样的危险。芯片工程师在榨取时钟周期内剩余价值时的确碰了壁,不过晶体管集成量仍在暴涨,所以从这个角度说, CPU 近期仍将遵循莫尔定律,系统吞吐量继续提高。
关键的变化,即本文的中心,是今后几代处理器性能提升所走的道路将完全不同。同时,大多数现在的应用软件将不再可能不作大规模重构,就能像过去那样从处理器免费获益。
接下来数年里,新型芯片的性能提升将主要从三个方面入手,其中仅有一个沿袭是过去的:
1 、超线程
2 、多核
3 、缓存
超线程,是指在单个 CPU 内,并行两个或多个线程。超线程 CPU 已经发布了,支持并行执行一些指令。不过这种 CPU 还是存在短板,虽然给它增加了部分硬件如寄存器,但它和绝大多数普通 CPU 一样,缓存、整数和浮点运算器仍然是唯一的。有资料表明,写得较好的多线程应用,在超线程 CPU 上能获得 5% - 15% 的性能提升;假设趋于理想状态,即多线程程序写得好到极点,那么性能可以提高 40% 。不错了,不过还是做不到成倍提升,而且对单线程应用毫无帮助。
多核,主要是指在一块芯片上运行两个或多个处理器。部分芯片如 Sparc 和 PowerPC 目前已经推出了多核版本。 Intel 和 AMD 也计划在 2005 年内初步实现,具体时间取决于它们的系统集成水平,功能则是一样的。 AMD 初期在性能设计可能更具优势,如更好的支持功能单片内集成,而 Intel 基本上就打算将两颗 Xeon 胶合在一块片子上了事。所以刚开始的时候,这种双核芯片与一个真正的双 CPU 系统在性能几乎没有差别,仅仅在价格上前者更为便宜,毕竟它的主板上不需要两个插槽和额外胶合件;另外,即便理想状态,这种架构也无法达到双倍速度,且无益于单线程应用,而只有写得较好的多线程应用能得到好处。
最后一个是片内缓存,还能像预期那样在近期继续上升。三个方法中,仅有这个可以让现有应用全面受益。片内缓存有令人难以置信的重要性和对大多数现有应用的超高价值,原因很简单,那就是“空间就是速度”。 CPU 和主存交互的代价是巨大的,如果能避免,那就尽量不要和它打交道。在目前的系统里,从主存获取数据所花时间,通常是从缓存获得数据的 10 到 50 倍。 很让人吃惊吧,因为很多人都以为内存已经足够快。其实这不过是与硬盘和网络相比,而不是运行在更高速度的片内缓存。应用程序的工作与缓存间的适配程度,和 我们是荣辱与共的。很多年来,不重构程序,仅仅提高缓存大小就拯救了现有应用,给它们带来新生。软件操纵的数据和为新增功能而加入的代码越来越多,性能敏 感的操作必须继续与缓存适配。套用经济大萧条时期老人常念叨的一句话:“缓存为王。”
顺带说件发生在我的编译器小组的趣事,算是“空间就是速度”的一个佐证。 32 位和 64 位编译器将同样的代码分别编译成 32 位和 64 位程序。 64 位 CPU 有多得多的寄存器和其他代码优化特性,因此运行其上的 64 位编译器先天的获得极大性能提升。这当然很好。而数据的情况又如何呢?换到 64 位平台上,内存中绝大部分数据的大小并未发生变化,唯一例外的就是指针,指针占用了两倍于以前的空间。因此,我们的编译器和绝大多数 32 位应用相比,挥舞指针就费力得多。现在的指针耗用 8 个而不是 4 个字节,空间净增加,结果我们发现 64 位编译器的工作集 [ 译注 12] 大小显著增加。工作集增大导致性能下降,差不多抵消了更快的 CPU 和更多寄存器带来的性能优势。就在我写这篇文章的时候, 64 和 32 位编译器正以同样的速度运行,尽管程序代码完全一样而且 64 位处理器先天能力更强。这就是“空间就是速度”。
缓存能,但超线程和多核 CPU 对现在的绝大多数应用,几乎不会有任何影响。
综上所述,硬件的变化到底会给软件开发方式带来怎样的影响呢?你可能已经有了初步答案了。让我们更深入研究,明白其厉害所在。
对软件来说,这意味一次巨变
上世纪 90 年代初,我们开始学着理解对象。在主流软件开发领域里,从结构化到面向对象编程是过去 20 甚至可以说 30 年来最重要的变革。这期间也发生了其他一些变化,例如近来诞生的的确让人着迷的 WebServices ,但我们中绝大多数人在职业生涯里从未有过见识像面向对象那样基础而深刻改变软件开发方式的机会。
现在,机会来了。
也 从现在开始,性能大餐就不再免费了。虽然托缓存增大的福,我们还能在半路上捡到普通的性能提升丸,但如果你希望你的应用程序在新的处理器里能继续获得爆炸 性的性能提升,那就需要你好好编写并发程序了(通常是多线程的)。说比做容易啊,也不是所有问题都天生可以通过并行解决,而且并发编程的难度也是很大的。
肯定有人嚷嚷开了:“并发?并不是什么新鲜玩意嘛!人们不早就在写这样的程序了么?”是的,小部分程序员的确写过。
别忘了,至少从上世纪 60 年代晚期的 Simula 开始,人们就在写面向对象程序。但到了 90 年代,面向对象才成功发动革命并夺取统治地位。为什么呢?工业是受现实需求驱动的,为了解决越来越大的问题,必须编写越来越大的系统,这样的系统需要越来越强劲的 CPU 和存储设备支持,硬件系统也恰逢其时地逐步提供了这样的支持。面向对象编程擅长抽象和依赖管理,所以成为了开发经济、可靠和可重用的大型软件的必备利器。
并发编程差不多也有同样漫长的历史可以追溯,很早的时候,我们就开始编写协程、管程 [ 译注 13] 以及其他与并发有关的东西。近 10 年来,我们也发现有越来越多的程序员在编写并发应用(有多线程的,也有多进程的)系统。但是发生整体转向性的巨变,目前还不具备条件,需假以时日。现有大量的单线程应用,仍然有巨大的存在价值,这点我会在后面说明。
说 点题外话,当前“下一次软件开发革命”这样的词语多如牛毛,让大家眼花缭乱,其实这是商家宣传自己新技术所作的广告,不要理睬它。新技术通常都很吸引人, 有时候也很有用,但软件开发方式的重大变革必然来源于在真正得到爆发式广泛应用前就存在并经过多年缓慢成长、先进而稳定的技术。这个过程是绕不掉的。变革 所依赖的基础技术必须足够成熟(包括有固定的厂商和工具支持);通常,这个成熟稳定过程至少要花费 7 年的时间,新技术在广泛应用时才不会有潜在的性能悬崖和陷阱。所以,像面向对象这样的软件开发变革,也必须在各项技术经过多年甚至几十年磨砺后才能发生。即便在好莱坞,绝大多数的一夜成名,也仍然是多年努力后发生重大突破的表面象征。
并发将是软件开发史上的又一个重大变革 。很多专家仍然在这个变革是否比面向对象还大的问题上争论不休。这样的争论最好还是留给学问家吧。技术工作者最感兴趣的是和面向对象一样,编程方式的变化程度、编程技术的复杂性和学习曲线问题。
并发之正反二面
并发技术(特别是多线程)在主流软件里大多应用在两个方面。第一类是天然就彼此独立的、逻辑上分离的控制流程,比如在我设计的数据库复制服务器里,每个复制 Session 都放在各自的线程里,彼此完全独立的,不会工作于同一条数据记录上。第二类不像第一类那么常见。为了系统提升性能,像利用多 CPU 平台的能力,挖掘应用程序其他部分的潜能等,我们也会编写并发代码。在我的数据库复制服务器里,多个独立的线程在多 CPU 平台上就工作得很好。
然而,并发编程也是要付出代价的。一些很明显的问题相对来说无关紧要,比如锁定。对资源的锁定降低了系统的性能,但如果你能找到办法最小化甚至消除资源共享,让操作真正并行,从而明智得当地使用锁,那么从并发执行得到的收益,要远大于在同步上蒙受的损失。
更重要的问题,大概就是并非所有应用都适用并行。这点我会在后面说明。
应该说,最大的问题,就是并发编程本身的难度了。程序员必须将脑子里的编程模型转化为可靠的程序,这比实现顺序执行的传统程序难得多。
任 何学习过并发的人都认为自己已经理解并发,早早结束寻找他们认为不可能但实际潜在的竞争冲突和他们其实仍没闹明白的问题。如果开发人员认真学习和思考并发 编程,就会发现通过合理组织的内部测试能发现大多数的竞争冲突问题,这个时候,无论是在知识水平还是心情愉悦度上,他们都能达到一个新的高度。不过,除了 经过理解为什么和怎么进行真正压力测试的行家测试过的、已经正式发布的软件,都会存在部分在普通测试中无法捕获的潜伏并发问题。这些问题只有在真正的多处 理器系统上才会暴露出来,因为在这样的环境里,多个线程不是在单处理器上切换,而是真正的并发运行,大量新问题就会涌现。而偏偏又有很多人自以为已经真正 理解如何编写并发程序,真是让人忐忑不安啊。我见过不少项目组,他们的程序在很多用户那里即便施以极端苛刻的压力测试,都能出色工作,但某天一个用户部署 了真正的多处理器机器后,深层次的竞争冲突甚至程序崩溃问题马上出现。 CPU 发 展到今天,重构你的应用,让它们多线程运行在真正的多核计算机上,的确像逼迫初学游泳的人一下子跳入深水——直达终点,似乎有点残忍,但只有真正并行的环 境,才能更容易暴露出你的问题。再说了,即使你组织了一个能真正编写可靠并行代码的团队,也不能说就不会出现问题。例如,并发代码运行可能非常安全,但 (在多核的机子上)却不比在单核的机子上跑得快。其典型原因就是线程未被合理分离,共享了单一资源,造成程序执行顺序化。这类问题是相当微妙而复杂的。
结 构化程序员学习面向对象(什么是对象?什么是虚函数?我如何使用继承?知道“是什么”和“怎么办”外,还得问一句:“如何保证理论上正确的设计在实践中的 正确性?”)是一个飞跃,同样的,顺序思维的程序员学习并发(什么是竞争冲突?什么是死锁?它是怎么出现的,我如何避免它?什么样的构造在我看来是并行的 但实际上顺序化了程序?在“是什么”和“怎么办”外,还要回答同样的问题:“如何保证理论上正确的设计在实践中的正确性?”)也是一个飞跃。
现在的大量程序员并没有真正理解并发,就像 15 年前大量程序员没有真正理解对象一样。 但并发编程模式是可以学习的,尤其是我们要坚持基于消息和锁的编程;一旦真正理解了并发,就会发现它并不比面向对象难多少,很容易觉得那是自然而然的。我们需要为我们自己和我们的团队做好训练投资和时间的准备。
有必要说明一点,我在上面故意将并发编程模式限定在消息和锁基础上。其实也有在语言级就直接支持的无锁编程,比如 Java5 和很流行的 C++ 编译器。但对于程序员来说,无锁比有锁并发编程难得多。大多数情况下,只需要系统和库编写者理解无锁编程就行了,虽然事实上每个人都可以从无锁系统和库获益。老实说,即便有锁编程,也有点碰运气的味道呢。
对我们来说这到底意味着什么
好了,回到正题,将问题归纳一下。
1 、我们已经讨论清楚的、最重要结论是:如果应用程序想充分利用 CPU 吞吐增加量,那它们就必然日益需要并发 ,这种形势逐渐明朗,并将在接下来的数年里深入发展。 Intel 已经扬言未来他们会推出集成 100 颗内核的芯片,那么单线程应用最多就只能利用这种芯片 1/100 的潜在生产力。“哦,性能没那么重要吧,计算机总是跑得越来越快”的论调已经变得天真而可疑,甚至在未来不久将完全错误。
目 前,并不是所有的应用都需要(或者更准确的说,只有应用中重要的作业才需要)并行。像编译这类的问题,是必须要考虑并行的,而其他则不一定。请看这个有趣 的例子:一个女人需要九个月才能生产一个小孩,并不代表九个女人能花一个月生出一个孩子。你以前可能接触过类似的推导,但有没有感觉这个问题意犹未尽呢? 如果有人再和你就此讨论,我向你推荐一个刁钻的问题:从这个命题你能断定“女人-小孩”是一个非并行问题么?通常,人们会下意识地认为它天然就不是一个并 行问题,但实际上并不完全是这样。如果目的是生一个小孩,它的确是一个非并行问题;但如果是生产多个小孩,那么它就是一个标准的并行问题了!所以说,目标 不同,结论就大相径庭。在考虑你的软件是否和如何使用并行时,千万别忘了面向目标原则。
2 、可能不那么明显的结论是: CPU 将很可能日益成为应用程序性能的瓶颈 。当然,不是所有应用都会这样,目前还未明显受制于 CPU 能力的应用在未来虽然可能受到 CPU 影响, CPU 也不会一夜之间成为它们的镣铐。但“ I/O 、网络和数据库瓶颈”似乎快走到谷底,因为在这些领域,条件仍在迅速改善(如 GB 级 WiFi 网络等等);而与此形成对比的是, CPU 性能提升技术已走到峰点。请注意,我们的 CPU 目前在 3GHz 徘 徊。所以,除了指望缓存在未来继续扩大(这可真是一个大好消息),现在的单线程应用不太可能跑得更快。其他方面的性能提升手段,虽然未来还可能继续发挥作 用,不过已经无法和过去相提并论了。芯片设计师正在拼命寻找新办法提高管线利用率,降低数据加载延迟,但在这些领域,长在低枝的果子早已被摘光。而应用程 序新需求的增加不但不稍事休息,反而神经质地加速猛冲。我们只好逼迫程序做更多的事情,而程序则只有威逼 CPU ,压垮它,除非程序能并发执行。
应对如此巨变,我们现在有两条路可以走。一是面向并发重构应用,二是勤俭持家,小心规划代码,让它吃更少的食,干更多的活。这就引出了第三个有趣的话题。
3 、提升程序效率、优化其性能将越来越重要 ,而不是反道而行。已经高度重视性能优化的语言将获得重生,其他的语言赶紧奋起直追,朝着效率和优化努力吧。面对长期增长的需求,希望面向性能努力的语言和系统能为我们分忧。
4 、最后一点,编程语言和系统将不得不尽快做好面向并发的准备 。 Java 语言从一开始就支持并发编程,虽然还存在不少问题以致不得不发布多个后续版本提升并发程序的正确性和效率。 C++ 长期以来被用于编写大型多线程系统,但它却没有对并发的标准支持( ISO C++ 标准甚至有意未提及线程 [ 译注 14] ),因此,并发目前只能在一些不可移植的特定平台和库基础上实现(而且实现还不够完善,比如静态变量只能初始化一次,这就要求编译器自动加锁,但很多 C++ 的实现里并不生成锁)。另外,目前还存在多种并行编程标准,例如 pthreads 和 OpenMP[ 译注 15] , 其中一些支持隐式并行,另一些显式支持。让编译器分析单线程程序并自动生成并行代码的隐式并行方式当然美妙而优雅,不过这类自动转化工具的结果代码质量还 无法与人工编写的显式并行代码媲美。目前的并发编程主要以锁为基础,这种方式也很难把握,常常要赌几分运气。总之,我们迫切需要一个比目前语言提供的更高 抽象层次的、统一的并发编程模式。关于这点,以后我还有更多的话要说。
总结
如果你以前对并发未加注意,那么现在是时候了,仔细分析应用的设计,挑出现在和不久就可能过于依赖 CPU 能力的操作,研究这些部分如何从并发得益。你和你的团队,现在也该深入学习和了解并发编程的要求、不足、风格和专业概念了。
少部分应用天然适用于并行,但大多数不是的。即便你知道程序受制于 CPU 的位置,可能也很难找到将这部分操作并行化的办法。所有这些问题,要求我们加快对并行的思考和研究。隐式并行编译器能帮点小忙,但不能指望太多,它不可能比得上尽你所能将顺序化程序转化为显式并行和多线程版本后的效果的。
感 谢仍未停止的缓存扩大和管线少量优化,免费饭菜在今后还能有一点,不过从今天开始,餐馆无偿提供的只有小菜和饭后小点心了。菜谱上仍然有优质可口的鱼片, 但现在要享受它就得付费——设计精细化、代码更复杂,而且要加倍测试。对于多数应用来说,这是个好消息,尽管要辛勤耕耘,但回报是丰厚的,因为并发可以让 应用继续从处理器能力暴增中充分受益。
译注 1
处理器发展历史上,精简指令集( RISC , Reduced Instruction Set Computer )阵营曾向微特尔( Wintel , Microsoft + Intel )阵营发动过三波声势浩大的微电脑盟主争霸战。
上世纪 70 年代以来,对处理器的要求更为全面,不单是提升速度就能满足,比如低耗能、小体积,加强数值运算、支持多媒体功能等。复杂指令集( CISC , Complex Reduced Instruction Set Computer )的微指令多且长度不统一,造成解码器线路复杂;加上受当时制造工艺的限制,如果在芯片上直接集成高速缓存和其他部件,体积和价格都将变得难以想象。
RISC 应运而生。因为 RISC 指令精简、线路精简,所以芯片体积和能耗降低,腾出空间也可容纳更多寄存器;另外指令定长,通过硬件加速,还可提升效能。 RISC 学术界从一开始就分为两派: Berkeley RISC (伯克利大学 RISC 计划)和 Stanford MIPS (斯坦福大学 MIPS 计划。 MIPS , Microprocessor without Interlocked Pipeline Stages ,无内部互锁流水级的微处理器。我国龙芯即 MIPS 架构)。
Sun 公司引进了 RISC 技术,在此基础上制定了 Sparc ( Scalable Processor Architecture ,可扩展处理器体系结构)微处理器体系结构规范,并于 1985 年推出了相应处理器。 1988 年, Sun 领头组建了 Sparc 联盟,口号是“ RISC + UNIX vs CISC + DOS ”,藉此发动第一次争霸冲击。后因市场迟迟未见销量,加上 Sun 在技术上又留了一手,导致联盟最后只剩 Sun 自己和德州仪器。
1990 年, MIPS 研究开花结果,开发团队成立了同名公司 MIPS ,并于 1991 年建立了 ACE ( Advanced Computing Environment )联盟,主要成员有 Digital (迪吉多)、 SGI ( Silicon Graphics ,视算科技)和 Compaq (康柏)。 Compaq 当时市场低迷,且 Intel 对 Compaq 展开了游说,因此 Compaq 最先退出了联盟;而 Digital 又忙于 Alpha 芯片的开发。主要成员离心离德, 1992 年,第二次联盟以 SGI 收购 MIPS 草草收场。
IBM 从 1975 年开始精简指令集芯片研究,也就是后来的 PowerPC 。 1992 年, IBM 与 Motorola (摩托罗拉)、 Apple Computer (苹果)宣布合组 Power 联盟。刚开始, Power 联盟引用学界评比论文,直指x86复杂指令集结构无法应付未来信息需求,而媒体也纷纷发难斥责x86电脑效能低劣,操作介面不便,都表示支持大胆改革的 Power 联盟。形势危机,当时 Intel 的总裁葛洛夫甚至认为 Intel 已陷入死亡之谷,如果应对失措,“ Intel ”将成为历史名词。 Power 联盟洋洋得意。
但在接下来的三年里, Power 联盟迟迟不能统一平台标准,操作系统开发进度也严重滞后。到 1994 年, Intel 推出了 Pentium 芯片,微软的 Windows 95 也大功告成。尽管当时的 Pentium 逊于 PowerPC , Windows 95 界面也不如 Macintosh ,但前二者相互支援,前后兼容,不断改进,而后二者却不够统一,用户没有安全感。形势急转直下, Power 联盟大跌眼镜。
第一波攻击, Sun 退回到工作站;第二波攻击, SGI 退回绘图工作站;第三波攻击至今, IBM 还在服务端处理器领域靠 PowerPC 苦撑。
顺带说一句, Intel 和 AMD 主要走的都是 CISC 路线。但处理器发展到现在,各方面技术已经相互融合,不存在绝对 CISC 或者 RISC 的芯片了。
译注 2
In-Stat : www.instat.com ,全球著名的行业研究机构, Reed Business Information 出版集团成员公司之一, Reed Elsevier 的战略组成部分;涉及半导体、电信和电子消费品等领域的研究、评估与预测。
MDR : MicroDesign Resources ,原属美国 Ziff-Davis 电子出版集团, 1999 年被 Reed Elsevier 收购。
In-Stat/MDR 主办《 Microprocessor Report 》(《微处理器报告》)杂志,三周刊; Microprocessor Forum (微处理器论坛)每年 10 月在加利福尼亚州 San Jose 举行。
译注 3
原句为: Andy giveth, and Bill taketh away.
Andy : Andy Grove ,安迪·格鲁夫, 1968 年和罗伯特·诺宜斯( Robert Noyce )、戈登·摩尔( Gordon Moore )共同创立 Intel 。
Bill : Bill Gates ,比尔·盖茨, 1975 年和保罗·艾伦( Paul Allen )创立 Microsoft 。
译注 4
大概是 2001 年看到过一则新闻,到网上搜了一下,内容大致如下:
澳大利亚教授韦伯领导的研究小组利用位于夏威夷的世界最大的天文望远镜“凯克”观测 17 颗不同的类星体。由于这些类星体距离地球 120 亿 光年,它们在宇宙形成初期发出的光线到今天才抵达地球。在长途旅行中,部分光线被星系间的气云吸收。光线的吸收情况既能反映星系气云的性质,也能反映出光 的变化情况,这其中就包括光的速度以及决定光速的光谱线精细结构常数。结果,韦伯等人发现,精细结构常数发生了微小的变化。从理论上说,这意味着光速有可 能发生过改变。消息公布后,不少物理学家对此发现持谨慎态度。韦伯及同事希望用位于智利的另一个大型天文望远镜来证实他们的结果,据称要得出最终结论尚需 2 至 3 年的时间。
不过到目前为止,似乎还没看到他们的最终结论。
译注 5
管线: pipelining ,或流水线。 CPU 的管线并不是数据输入输出使用的物理线路,而是指指令执行的流程。一条指令必须被分解为多个执行步骤,每个步骤占用一个时钟周期。例如最基础的管线是 5 级的:( 1 )取指令,( 2 )对指令译码,( 3 )演算出操作数,( 4 )执行指令,( 5 )将结果存储到高速缓存。前三步由指令控制器( ICU )完成,后两步由运算器( ALU 或 FPU )完成。管线可以细化,例如苹果的 G4 处理器采用了 7 级管线, AMD 2500+ 处理器 10 级, Intel 公司的 P3 到 10 级, P4 到 20 级, P4-E 甚至高达 31 级。管线加长,则每级任务量减小,执行所需时间缩短,因此时钟周期可以缩短,即时钟速度加快。设管线为 N 级,时钟速度为 TMIPS ( T 百万次 / 秒),那么平均完成一条指令所花费时间为 N/T (当 然要求芯片的确在每个周期内能完成各管线级的任务),因此理论上只要时钟速度加快,则芯片处理能力上升。但问题是管线执行时总有出错(如分支预测失败)的 可能,一旦出错,整个管线就要全部清空,然后从第一级重新执行,在这种情况下,长管线的全部花费时间通常比短管线多。这就是部分 AMD 芯片比 Intel 相同甚至更高主频的芯片实际速度要快的原因。
分支预测: branch prediction 。解决管线中条件转移引起管线停顿的问题。例如第一条指令是条件转移,那么需要等其判断结果出来后才能执行下一条指令,分支预测可预测判断结果,然后尽快执行其他指令,从而不致管线停顿。当然预测也有出错的时候,预测失败将导致管线清空,从头执行。目前预测准确度可达 90% ,进一步提高分支预测准确率是正在研究的重要课题。
乱序执行: out-of-order execution 。 解决管线中指令相关引起管线停顿的问题。后序指令需要正在执行指令的结果,因此无法立即处理后序指令,这叫做指令相关,造成其他处理单元的停顿,白白损失 时钟周期。解决办法是立即找出其他不相关指令来执行,最后由重新排列单元将各执行单元的结果按原来指令顺序重新排列。很显然,乱序执行是有风险的。
译注 6
出自美国电影《化身博士》 (Dr. Jekyll and Mr. Hyde ,有 1931 和 1941 两个版本 ) 。 故事讲述哲基尔医生相信每个人都同时拥有两极化的个性——好的一面与邪恶的一面。如果将这两种个性分开成为截然不同的两个人,这两个灵魂都将获得释放。他 随后成功地用化学实验将自身邪恶的一面转化成为海德先生,此先生犯下了可怕的罪行。但当他想要停止用药时,却惊恐的发现一切为时已晚……
译注 7
读 / 写操作再排序都属乱序执行。看下面一段原始指令代码:
(p1)br label // 分支判断。若为 true 则跳转到 label ,否则继续执行
ld8 r9 r5 // 从 r5 所指地址空间读取 8 个字节到 r9
add r2 r9 r3 // 将 r9 和 r3 中值求和,并存入 r2
其中 ld , load ; r , register 。
因为 load 操作较耗时间,通常花费几个时钟周期才能完成。因此从提高效率的角度看,应该在处理器空闲的情况下,尽早加载此操作。比如简单再排序优化后:
ld8 r9 r5
(p1)br label
add r2 r9 r3
如果分支判断结果为 false ,流程发生跳转,那么可以直接舍弃 r9 的结果值,即 ld8 白做了;但如果未发生跳转,则 ld 尽早执行,提高了流程整体效率。
当然, CPU 实际工作远比上面例子复杂。比如将 ld 提前,但如果 ld 失败怎么办?有依赖关系的指令呢,能否乱序?在多线程应用里,乱序还可能引起其他一些问题,比如 Java 中的 Double-Checked Locking失败 。
不光 CPU 支持乱序执行,现在的很多编译器也开始做乱序优化,而且重心有逐渐从硬件转到软件的趋势。
有两篇资料可以参看: Scaling Itanium® Architecture for Higher Performance (特别是其中的如何处理指令依赖值得了解)和 Verified Optimizations for the Intel IA-64 Architecture 。
译注 8
片内,英文为 on the die 或 On-Die 。 Die :裸芯; Chip :包装后的芯片。类似有 On-Chip 、 Off-Die/Chip 。
译注 9
MMX : MultiMedia eXtension ,多媒体扩展。 Intel 在 1996 年 3 月份正式公布了 MMX 技术的细节,并于 1997 年 1 月正式向全球推出基于 MMX 技术的 166MHz 和 200MHz Pentium 芯片, AMD 也几乎在同时推出了支持 MMX 技术的第六代处理器 AMD K6 。
MMX 技术是 Intel 针对× 86 体系的一次重大扩充,使计算机同多媒体相关任务的综合处理能力提高了 1.5 ~ 2 倍。它不仅是 Intel 自 i386 面世以来对 CPU 体系结构的一次显著改进,同时也是 IT 界对多媒体数据处理等专用芯片及功能板卡的一次成功挑战。
SSE : Streaming SIMD (单指令多数据) Extensions ,是 Intel 针对 AMD K6-2 引入的“ 3D NOW !”技术,于 l999 年在 Pentium3 中引入的 SIMD 扩展指令集,业界也称为 MMX2 ,在多媒体数据处理(特别是 3D )和浮点运算等能力上全面加强。
译注 10
目前频率最高的处理器是 Intel P4 570J , 3.8GHz ,上升非常缓慢。
CPU 频率越高,所需电能和发热量越多;而晶体管越小,耗电和热量越低。制造工艺进步,可能让晶体管更小,从而让 CPU 在相同或一定程度内提高的能耗下达到更高频率。从这个角度说,提升 CPU 频率的瓶颈是制造工艺。
于是, Intel 推出了了 90nm 工艺的 Prescott 核心 Pentium4 ,其理论频率将能达到 6GHz !然而世事难料,在 90nm 工艺晶体管里,由于电介质厚度太低无法阻挡电子的穿越,造成了严重的电流泄漏问题,随之带来的就是大量的电能消耗和废热。如果强行提升频率,则发热激增, CPU 经不起如此的高烧。
泄漏电流问题并非不可解决,但绝不能在短时间办到。至此,芯片厂商提升系统性能的思路开始发生重大变化,即转向多核。
有关电流泄漏和应对策略的详情,可参看: NetBurst的继承者 Core微处理器架构技术解析 。
译注 11
在 IDF05 ( Intel Developer Forum 2005 )上。 Intel 首席执行官 Craig Barrett 就取消 4GHz 芯片计划一事,半开玩笑当众单膝下跪致歉。

译注 12
Working Set ,记录了操作系统为进程提交的内存的总量。
译注 13
并发编程语言( Concurrent Language )中的术语。
协同程序( coroutines ),或协程。用以实现协作式多任务,于上世纪 60 年代提出。同属一个协程的多个进程,在同一时刻只能有一个处于运行状态。协程属于一种并发进程创建方式,其他方式还有 Fork/join 、 Cobegin/coend 和进程显式申明( Process declarations )等。
并发进程之间的通信方式主要有两种方式:变量共享( shared variables )和消息传递( message passing )。其他还包括抽象于更高层次的远程过程调用( remote procedure call , RPC )等。
通信就离不开同步。同步方法主要包括:信号量( semaphores )、条件临界区( conditional critical regions )、管程( monitors )、互斥( mutual exclusion )、路径表达式( path expressions )、原子事务( atomic transactions )和汇集( rendezvous )等。
其中的管程是位于低级同步控制手段之上的一种对象化管理工具。信号量的使用是无结构的,很不方便;条件临界区相对于信号量更结构化,但同步控制代码仍然非常分散,不利于管理。因此引入了管程,它实现了共享资源的集中管理,封装了共享资源以及施于其上的操作。
译注 14
因为某些原因(如竞争条件下静态变量初始化问题),线程还未被列入 ISO C++ 标准。目前在不同的平台上,都有线程的专门实现,短时间内难以完全统一。
不过 Boost 线程库目前差不多具有准标准身份。
译注 15
并行编程中必须考虑的两个问题是被处理数据和任务间通讯。经过用户的选择与市场的淘汰,现在的并行编程标准基本上趋向以下三种:
1 、数据并行。特点,各任务处理的数据彼此分离,任务间通过消息传递进行通讯;数据分离和消息传递工作由编译器完成。
HPF ( High Performance Fortran ,高性能 Fortran )是典型的数据并行编程语言。因为目前的编译器技术对实际应用中各种不规则问题的解决方案仍不够理想,加上专注于数据并行,因此 HPF 未获广泛应用。
2 、消息传递。特点,各任务处理的数据彼此分离,任务间通过消息传递进行通讯;数据分离和消息传递工作由程序员和用户完成,因此对程序员要求很高。这种模式非常适用于消息传递的体系结构(如机群系统),用户和程序员主要需考虑的是通讯同步和通讯性能问题。
并行虚拟机( PVM , Parallel Virtual Machine )和消息传递接口( MPI , Message Passing Interface )是两种广泛使用的消息传递并行编程标准。其中 PVM 侧重异构环境下的可移植性和互操作性; MPI 更强调性能,但在异构环境下有不同的实现。几乎所有的高性能计算系统都支持 PVM 和 MPI 。
3 、共享内存。特点,各任务处理的数据实现内存共享,任务间也通过共享数据实现通讯;数据共享可由程序员或编译器完成。共享内存并行编程主要应用在对称多处理器( SMP , Symmetric Multi Processors )系统上。
OpenMP ( Open MultiProcessing 由 X3H5 发展而来)和 PThread ( POSIX Thread )都是 共享内存并行编程的实现。
OpenMP 由 1993 年建立的 X3H5 标准发展而来,目前已成共享内存并行编程的实际工业标准,得到 DEC 、 Intel 、 IBM 和 Sun 等厂商广泛支持。它 在 Forthan 、 C/C++ 得到了实现,主要支持隐式并行编程,即编译器实现并行。
PThread 主要在 Unix 系统上使用。 Unix 的实现系统很多,比如 Linux 、 FreeBSD 、 Solaris 、 Mac OS X 等。要在众多“类 UNIX ”上开发跨平台的多线程应用,绝非易事,因此制定了 POSIX Thread 标准。 David R. Butenhof ( Boost 库发起者之一, ISO C++ 标准委员会成员)的《 Programming with POSIX Threads 》这本书,可以说是 Unix 上编写多线程应用的必备参考书。对其他平台并行程序开发也有很高参考价值。
总的来说,共享内存并行编程与目前大多数的多线程程序员思维习惯最为接近,是程序员从单核转向多核系统需付代价最小的方案。但专家仍有不同意见,比如 Herb Sutter 就不看好 OpenMP ,因为共享内存并行编程本质上并没有太多改进,仍然依赖数据资源的锁定,这会带来性能问题。 消息传递并行有性能优势,但对程序员的要求又太高了。所有这些难题,还需要研究并行和各种标准、库的专家继续努力解决。
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









