







原文出处:http://www.gotw.ca/publications/concurrency-ddj.htm
译文发表于《程序员》2006.11。
免费大餐不久就将结束。对此,你有何打算,做好下一步准备了么?
对主要的处理器厂商以及架构,包括Intel、AMD和Sparc、PowerPC[译注1]来说,改善CPU性能的传统方法,如提升时钟速度和指令吞吐量,基本已走到尽头,现在开始向超线程和多核架构靠拢。而且这两个特性(特别是多核)已经在部分芯片实现,如PowerPC和Sparc IV;Intel和AMD也将在2005年内赶上。2004年In-Stat/MDR秋季处理器论坛[译注2]的主题就是多核设备,很多公司都展示了改进和新研发的多核处理器。不过,要将2004年称为多核年,显然还不够理直气壮。
多核将引领软件研发发生基础性变化,特别对接下来几年里那些面向一般应用、运行在PC和低端服务器上的应用软件(在今天已经销售出去的软件里占有很大比例)而言。在这篇文章里,我想就多核为何突然对软件产生重要影响,以及并发巨变如何影响我们和我们未来编写软件方式的问题展开讨论。
我可以这么说:免费大餐已经结束一两年了,但我们现在才开始意识到这个问题。
免费的性能大餐
业界存在一个有趣的现象:“安迪送,比尔取。”[译注3]无论处理器性能提升多少,软件都有办法迅速吞噬。CPU速度十倍于前,软件就有十倍于前的活要干(或者肆无忌惮猛增软件的工作量,导致性能下降)。在过去几十年里,由于CPU、内存和硬盘特别是CPU厂商强力推进主流系统向更新更快的方向发展,大多数软件不做版本升级,甚至原封不动,就可轻松而持续地享受处理器性能提升的成果。尽管时钟速度不是衡量系统性能的唯一和最好的标尺,但其重要意义不容忽视。我们见证了CPU的发展历史:从500MHz到1GHz,然后再到2GHz,不断提高。今天,主流计算机已经进入3GHz时代。
不过,有一个很关键的问题:这种提升模式什么时候会走到尽头?尽管莫尔定律预言了历史上的指数式增长,但我们很清楚指数式增长不可能永远维持,因为硬件毕竟受物理极限约束;光速是不可能更快的[译注4]。所以增长必然放缓,最后停滞。顺便说明一点,莫尔定律的主要描述对象是晶体管集成密度,但在一些相关的领域,如时钟速度方面,也出现了类似的指数式增长;甚至在别的领域有更快的增长速度,例如著名的数据存储量爆炸。不过这些重要趋势需要另一篇文章来分析了。
如果你是一个软件开发人员,那么你可能一直在免费享受桌面计算机性能提升的大餐。某些操作会成为应用程序性能的瓶颈?“你过虑了”,我们对这样的回答耳熟能详,“未来处理器将更为强劲,而现在的应用程序速度倒是日益被非CPU吞吐量和内存速度因素扼杀,比如I/O、网络和数据库等等。”真的是这样么?
要在过去,这的确没错。但在以后,就完全不对了。
我有两个消息要告诉大家。第一个是好消息,处理器性能仍然会不断提高。第二个则是坏消息,至少在短时间内,处理器性能的提升,不再能像以往那样让现在的应用程序继续免费获益。
过去30年里,CPU设计者主要从三个方面提高CPU性能,头两个就是从线性执行流程上考虑的:
1、时钟速度
2、执行优化
3、缓存
提升时钟速度将增大单位时间的时钟周期数。让CPU跑得更快,就意味着能让同样工作或多或少更快完成。
优化指令执行,可以在每个时钟周期内完成更多工作。目前的CPU中,一些指令被不同程度地做了优化,如管线、分支预测、同一时钟周期内执行更多指令,甚至指令流再排序支持乱序执行等[译注5]。引入这些技术的目的是让指令流更好、更快执行,降低延迟时间,挖掘每一时钟周期内芯片的工作潜能。
在这里,有必要对指令再排序作个简单说明。我刚才提到的部分指令优化手段,其实已远非普通意义上的优化。这些优化可能改变程序原意,造成程序不响应程序员的正常要求。这可是个大问题。CPU设计师都是心智健全且经过严格训练的好同志,正常情况下,他们连苍蝇都不愿伤害,自然也无意破坏你的程序。而在最近几年里,尽管知道指令重组有破坏程序语义的风险,但为了提升每个时钟周期内的工作效率,他们已经习惯于积极开展这类有风险的优化工作。难道海德先生[译注6]复活了?当然不是。这种积极性清楚表明,芯片设计师承受了交付速度更快CPU的巨大压力;在这种压力下,为了让软件跑得更快,他们不得不冒改变程序意思,甚至应用崩溃的风险。拿两个有名的例子来说——写操作再排序和读操作再排序[译注7]。允许处理器对写操作再排序是非常令人吃惊的,让大多数程序员意外,一般来说这个特性必须关闭,因为在写操作被处理器武断地再排序条件下,程序员很难保证程序正确执行。读操作再排序也有明显的问题,但大多数情况下这个特性是开启的;因为相对来说它更容易把握一些,而且人们对性能的要求,让操作系统和操作环境设计师只能选择让程序员在一定程度吃点苦头,毕竟,这比直接放弃性能优化机会的罪责小一些。
第三个是增大与RAM分离的片内高速缓存。RAM一直比CPU慢很多,因此让数据近可能靠近处理器就很重要——当然那就是片内了[译注8]。片内缓存持续飚升了很多年,现在的主流芯片商出售的CPU都带有2M甚至更高的二级缓存。值得一提的是,今后,三种提升CPU性能的传统手段里,增加缓存将硕果仅存。我会在后面更详细说明缓存的重要性。
我写这么多的意思是什么呢?
最重要的是我们必须认识到,传统性能提升方法与并发没有直接关系。过去任何方法带来的速度提升,无论是顺序(非并行的单线程或单进程)、还是并发执行的程序,都能直接受益。这点很重要,我们目前大量的程序都是单线程的,而且在未来仍然有重要的存在价值。
当然,适当时候,我们重新编译程序,可以利用CPU的新指令(如MMX、SSE[译注9])和新特性提升系统性能。但总的来说,即使放弃使用新指令和新特性,不做任何更改,老程序在新CPU也会跑得更快,让人心花怒放。
曾经的世界是这般美好,可如今,她就要变了颜色。
为什么我们今天没有10GHz芯片
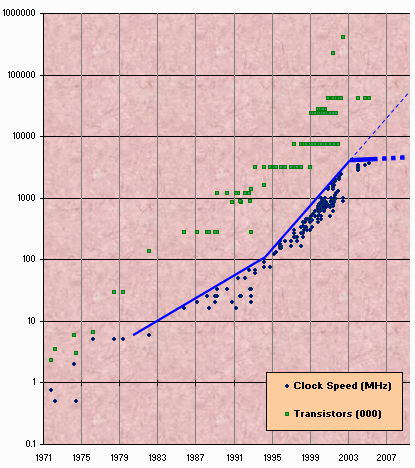
其实,CPU性能提升在两年前就开始碰壁,但大多数人到了最近才有所觉察。
我这里有份来自Intel的数据(当然你可以从其他厂商得到类似数据)。图中反映了Intel芯片的时钟速度和晶体管集成规模演变历史。晶体管集成数至少就目前而言仍在继续上升,但时钟速度的情况就不同了。
我们从图中可以看到,大概在2003年初,一路高歌猛进的CPU时钟速度突然急刹车。受制于一些物理学问题,如散热(发热量太大且难以驱散)、功耗(太高)以及泄漏问题[译注10]等,时钟速度的提升已经越来越难。
你目前在工作站上用的CPU时钟速度是多少?10GHz么? 2001年8月Intel芯片就达到2GHz,按照2003年前的CPU发展趋势推算,到2005年初,我们就能拥有第一块10GHz的Pentium芯片。但实际上没办到。而且情况好像越来越糟——我们根本就不知道到底在什么时候这样的芯片可以出现。
那么放低期望,4GHz又如何呢?目前我们已到3.4GHz——那么4GHz已经不远了吧?唉,好像4GHz也遥不可及。可能你知道,Intel首先于2004年中将4GHz芯片的发布时间推迟到2005年,而到了2004年秋季,则彻底取消了4GHz计划[译注11]。在本文写作的同时,Intel宣布计划到2005年早期,实现到3.73GHz(即图中的右上最高处)的微量提升。所以,至少就目前来说,时钟速度的竞赛实际上结束了,Intel和其他大多数处理器厂商将把旺盛的精力投入到多核等方向去。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6863
6863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









