







简介
Pandas Profiling包是python里面又一个神奇的工具,它能对数据集(csv或者数据库)进行多个维度的分析,生成html格式的report,配以专业的图表,漂亮又炫酷。最关键的是,这个分析和生成report的过程是自动的,我们只需要简单的几行代码即可搞定。
如果小伙伴们已经熟悉Pandas Profiling包,那么这篇文章对您可能没太大用处,就没有必要再往下面读了。
但是。。。如果您从未听说过Pandas Profiling,或者只是听说过但没有具体见识过它的功能。那么这篇文章可能会对您有些用处。
Pandas Profiling是什么鬼
Pandas Profiling是一个python包,可让您以最少的代码创建探索性分析数据报告。
因此,如果您是手动进行探索性数据分析的数据科学家或分析师,那么使用pandas分析将为您节省大量时间,精力和键入时间。 您还记得进行数据分析时使用的所有重复代码,比如下面这些函数,是不是都已经用得想吐了:
info()
describe()
isnull()
corr()
etc.
您将不再需要再这样做。 Pandas Profiling包将为您完成此任务,并将创建数据的完整摘要报告。
安装Pandas Profiling
在DOS命令行或者Linux shell里面执行
pip install pandas-profiling
或者
pip3 install pandas-profiling
如果需要为pip设置代理,可以执行下面的语句:
pip3 --proxy http://proxyhost:8080 install pandas-profiling
或者还可以使用国内源,下载速度快很多。比如下面使用阿里云的pip源来安装:
pip3 install pandas-profiling -i https://mirrors.aliyun.com/pypi/simple/
安装该软件包需要一两分钟,您应该可以在python中使用pandas配置文件了。
创建分析报告
为了创建报告,您可以使用标准的read_csv()函数加载数据集,该函数将数据存储在Pandas Data Frame中。
然后使用ProfileReport初始化程序并将其刚刚创建的data frame作为参数传递给它。
您可以使用to_file()函数导出报告,以便对其进行检查。
import pandas as pd
from pandas_profiling import ProfileReport
df = pd.read_csv(data_file_name)
report = ProfileReport(df)
report.to_file(output_file='output.html')
让我们来看一个有真实数据的例子
我们将为真实数据集创建一个报告。 我们选择了可以从这里下载的美国新冠疫情数据集。 该数据集的大小为10MB,具有20多万行数据和6列。
让我们使用Pandas Profiling为该数据集创建一个报告。
>>> import pandas as pd
>>> from pandas_profiling import ProfileReport
>>> df = pd.read_csv('us_counties_covid19_daily.csv')
>>> report = ProfileReport(df)
>>> report.to_file(output_file='output.html')
运行此代码后,您应该会在几秒钟内看到生成报告的进度条,并且应该能够通过在浏览器中打开output.html文件来查看完整的报告。
这样就可以在新生成的output.html文件里面查看这个report了(注意output.html放在和heart.csv同一个目录下面)
Report的结构
让我们看看Pandas Profiling生成的Report中包含的内容。
-
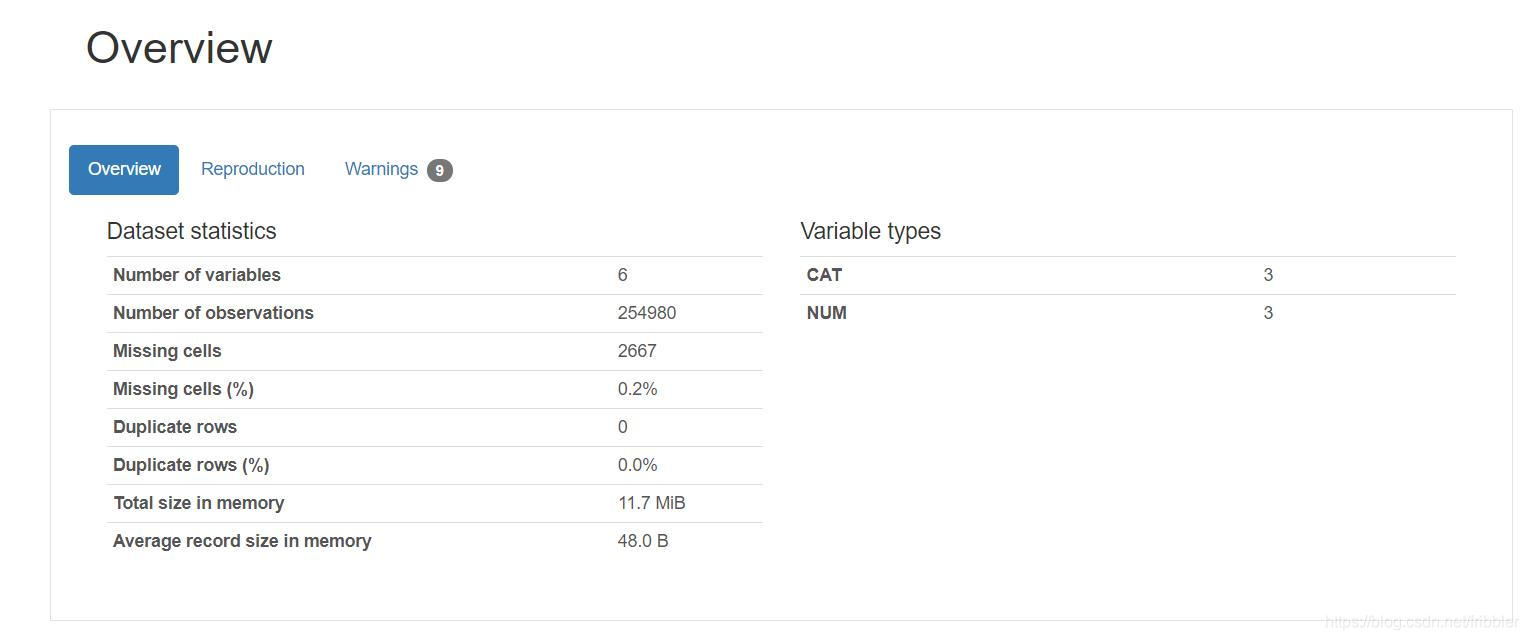
概述
在概述部分,我们应该看到三个选项卡:Overview,Reproduction和Warnings。
Overview tab页提供有关数据的基本信息,例如列和行数,数据大小,缺失值的百分比,数据类型等。
Reproduction(复制) tab页包含有关报表创建的信息。
Warnings tab页包括在生成报告时已触发的警告。
-
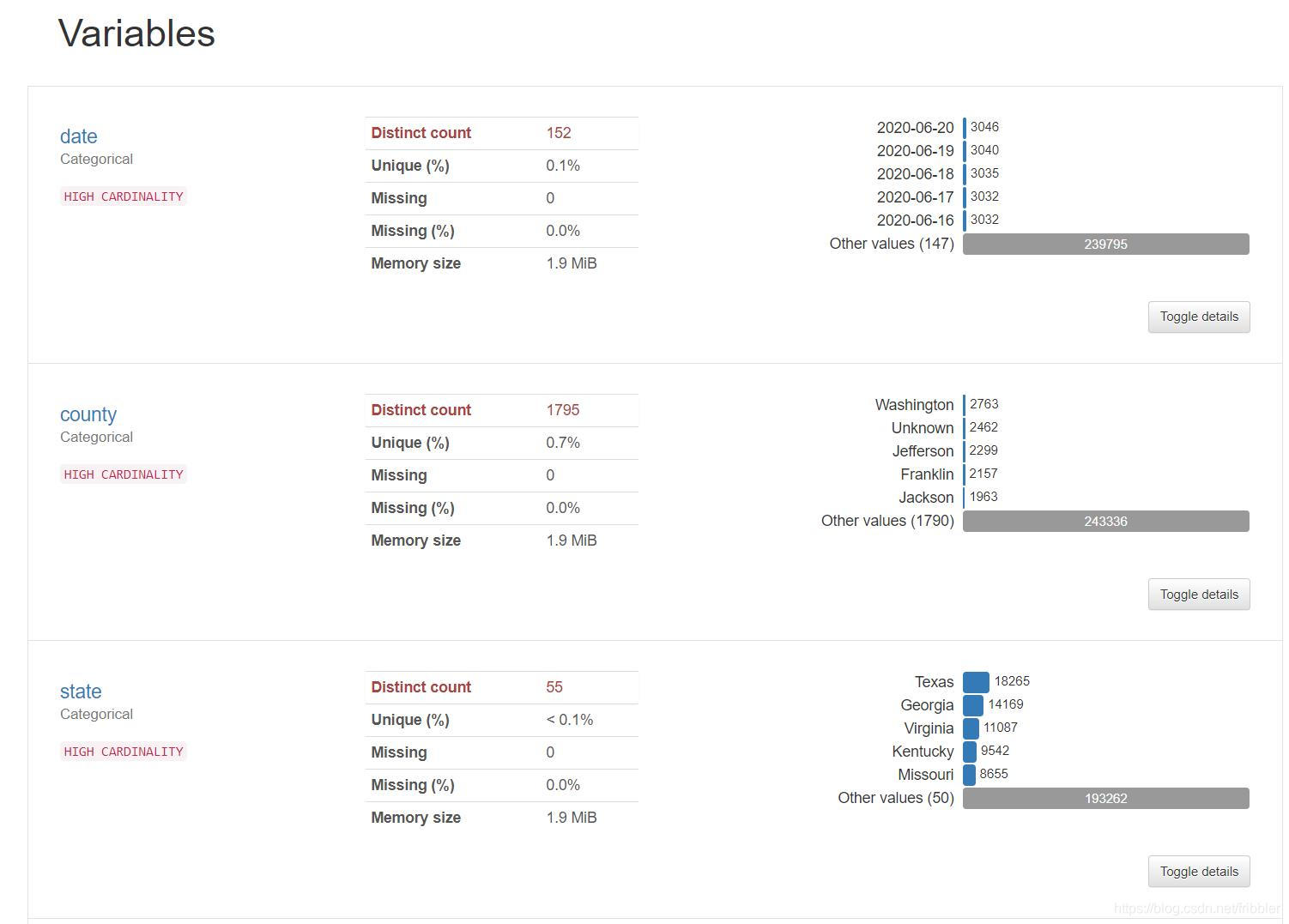
变量
本节着重于每个变量的详细分析。
如果变量是连续变量,它将显示直方图,如果是分类变量,则将显示具有值分布的条形图。
您还可以查看每个变量缺失值的百分比。
下图显示了来自心脏病数据集的年龄和性别变量分析。
-
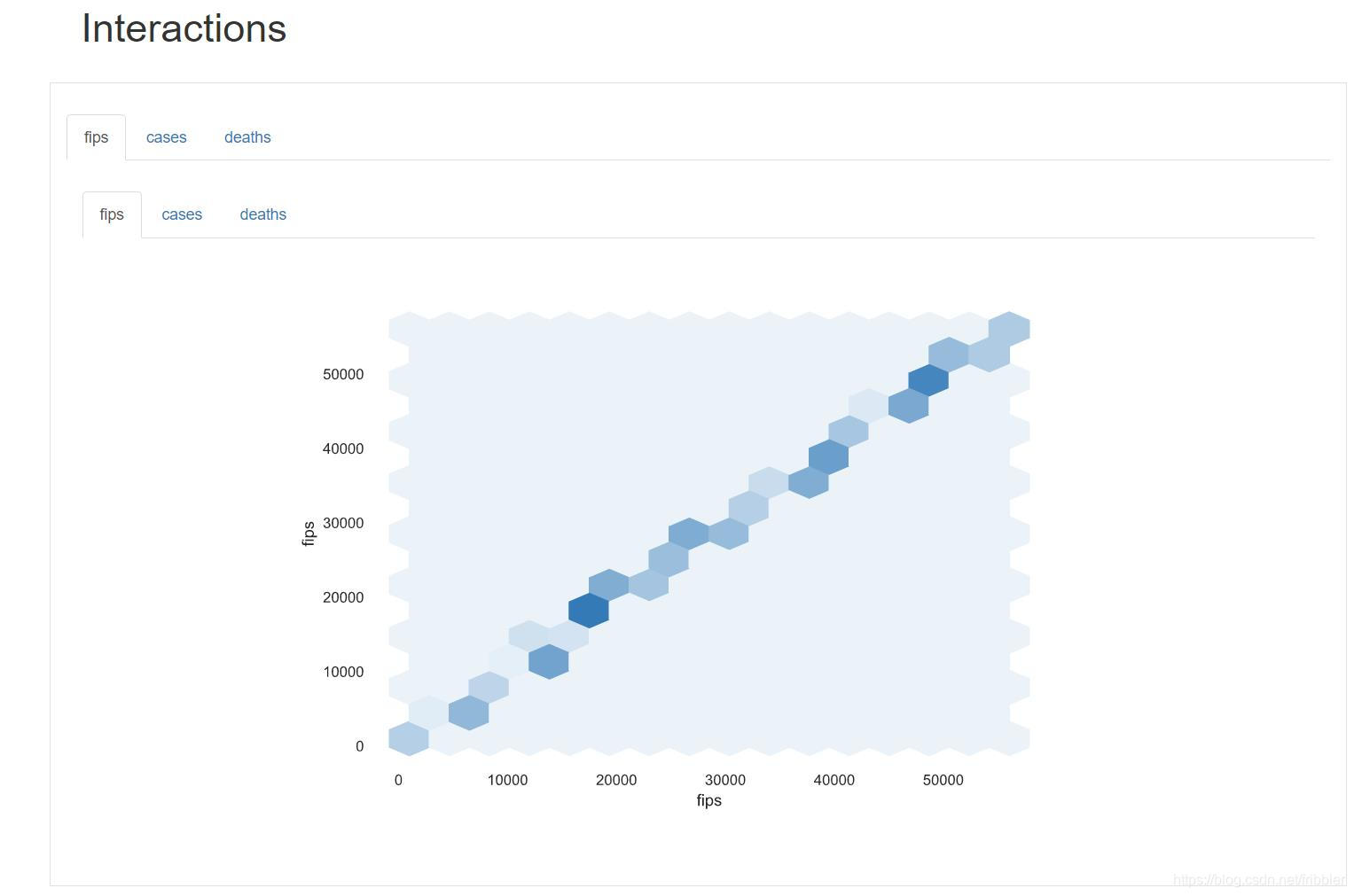
互动
交互部分重点讨论数值变量之间的双变量关系。 您可以使用选项卡选择要检查的关系对。 下图显示了年龄与胆固醇之间的关系。
-
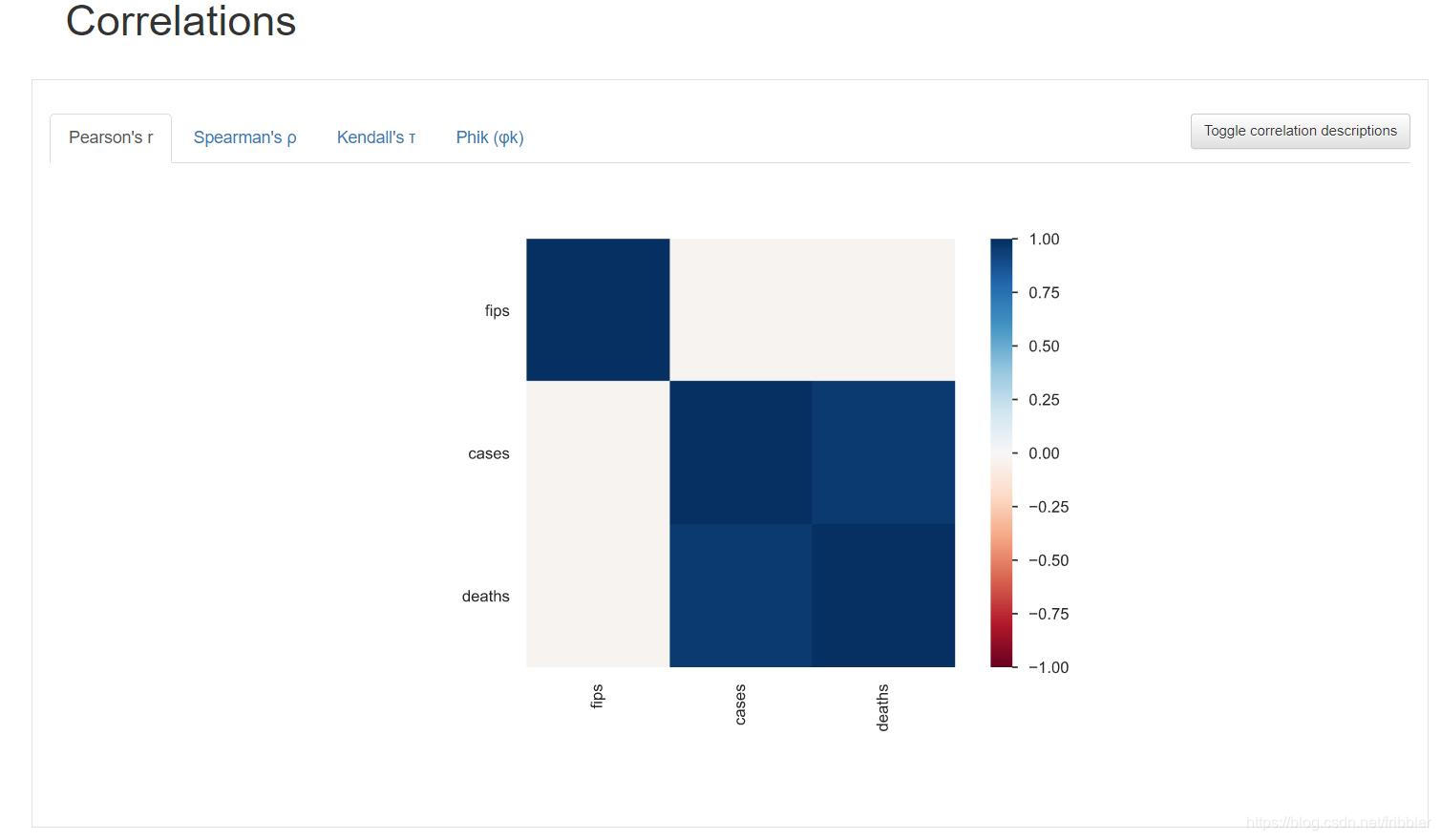
Correlations(相关性)
本节显示了不同类型的相关性。
-
缺失值
这一部分显示随着列分解而导致数据集中缺少值的部分。
我们可以看到在我的列中我们的数据集没有缺失值。
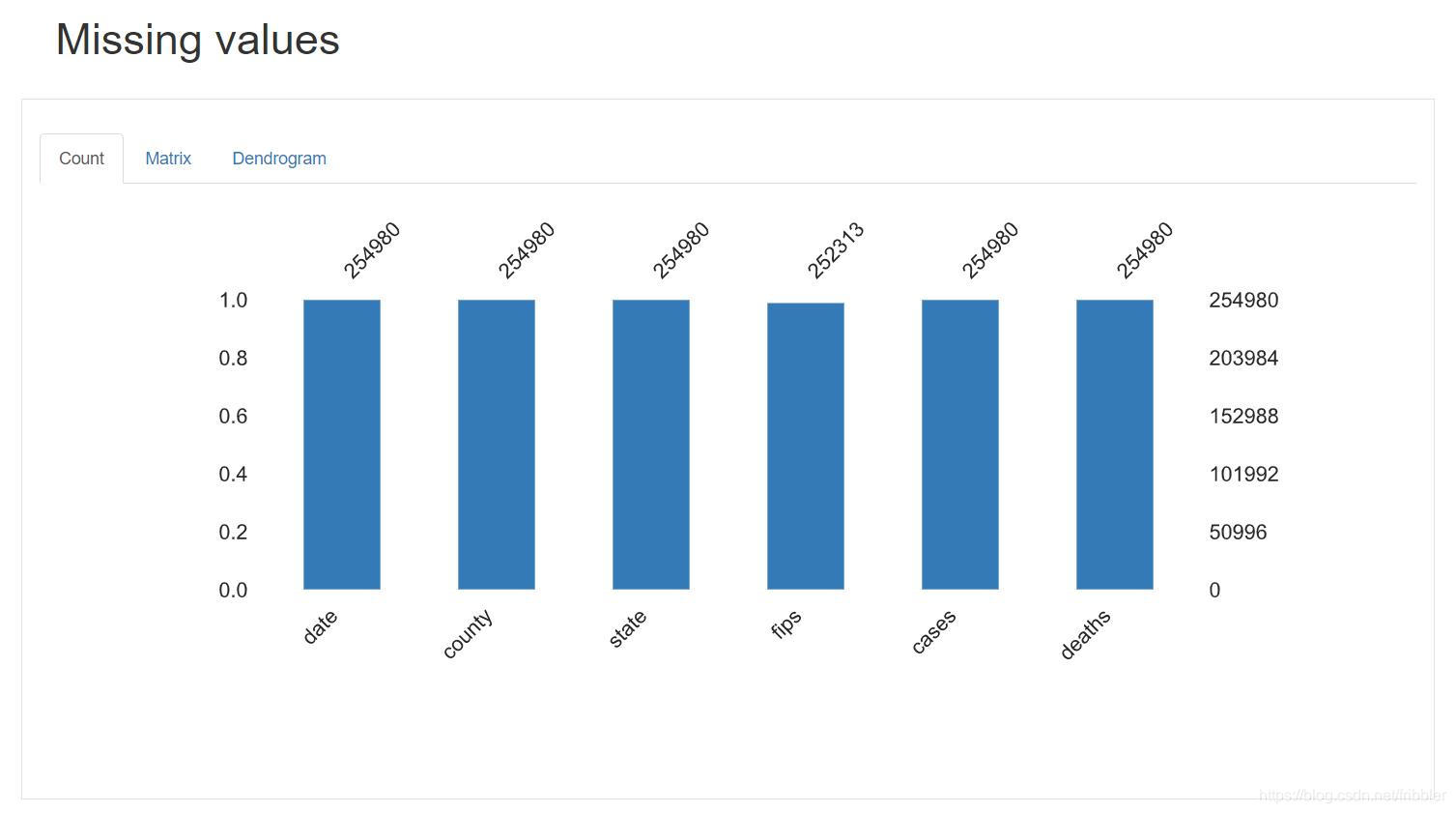
-
Sample(采样)
本节代替了手动数据分析中的head()和tail()函数。 您可以看到数据集的前10行和后10行。
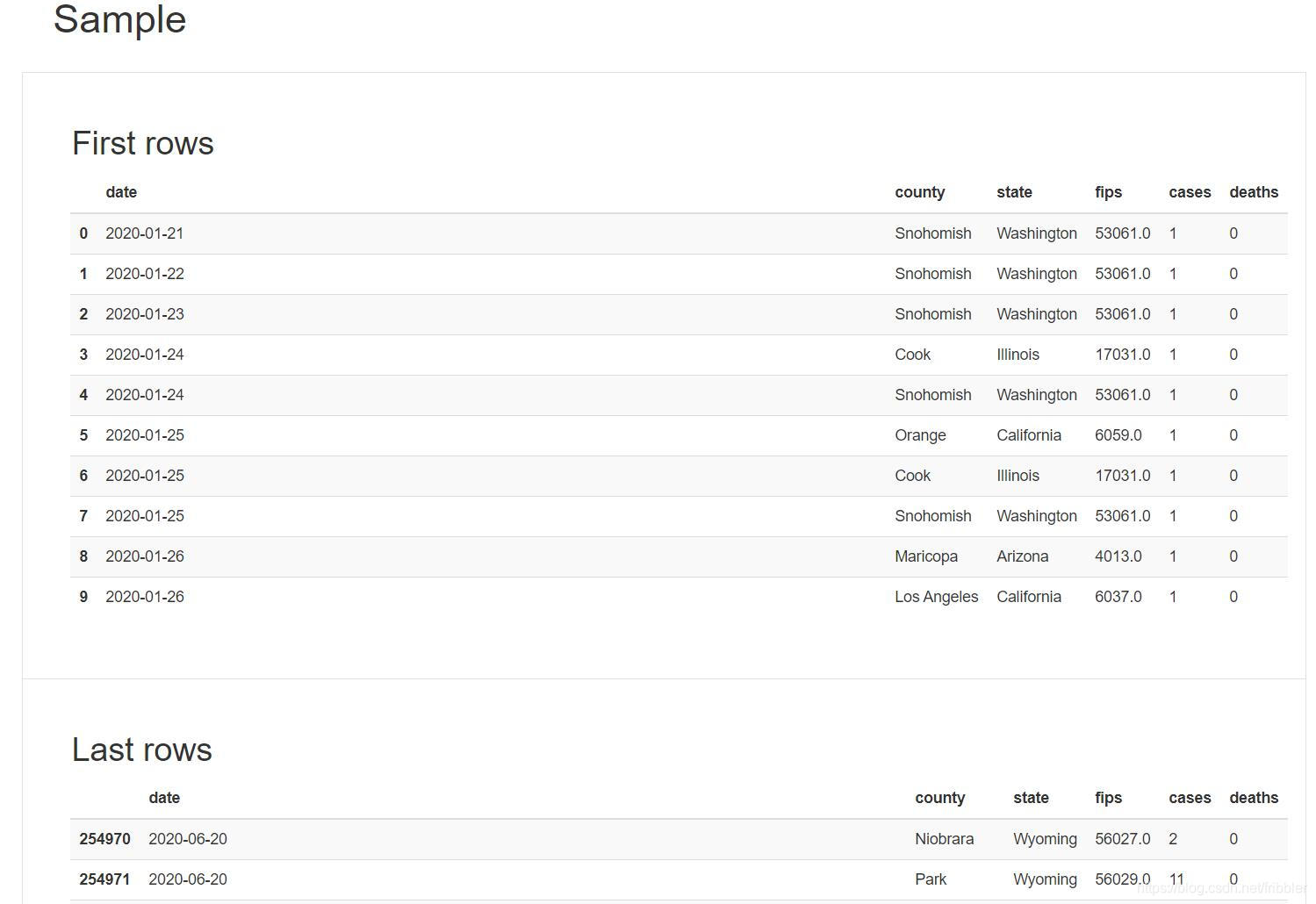
-
重复数据
本节向您显示数据集中是否有重复的值。 心脏病数据集中实际上有一个重复的条目,其详细信息显示在下面的截图中。
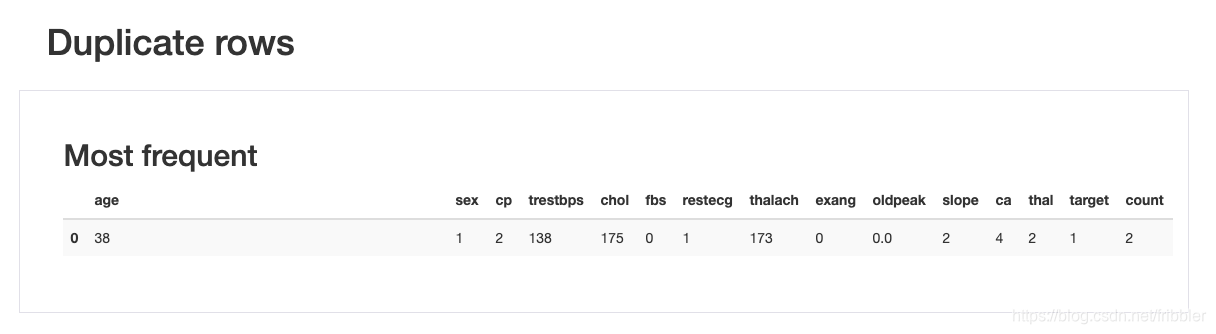
Pandas Profiling的优缺点
在本文中,我们讨论了Pandas Profiling包的优点,但是有什么缺点吗? 是的,我们来谈谈一些。
如果您的数据集很大,则创建报告将花费很长时间(在极端情况下可能需要数小时)。
我们有一些使用配置文件包的基本EDA,这是进行数据分析的良好起点,但绝对不是一个完整的探索。 通常,我们会看到更多的图形类型,例如箱线图,更详细的条形图,以及一些其他类型的可视化和探索技术,它们将揭示特定数据集的怪癖。
此外,如果您刚刚开始数据科学之旅,则值得学习如何使用熊猫本身来收集报告中包含的信息。 这样,您就可以练习编码和处理数据!
总结
在本文中,我们向您展示了如何安装和使用Pandas Profiling包。 我们甚至向您展示了对结果的快速解释。
下载美国新冠疫情数据集并自己尝试。

















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









