







Hadoop HA高可用集群搭建(2.7.2)
1.集群规划:
drguo1 192.168.80.149 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)、ResourceManager
drguo2 192.168.80.150 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)、ResourceManager
drguo3 192.168.80.151 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
drguo4 192.168.80.152 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
drguo5 192.168.80.153 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
排的好好的,显示出来就乱了!!!

2.前期准备:
准备五台机器,修改静态IP、主机名、主机名与IP的映射,关闭防火墙,安装JDK并配置环境变量(不会请看这http://blog.csdn.net/dr_guo/article/details/50886667),创建用户:用户组,SSH免密码登录SSH免密码登录(报错请看这http://blog.csdn.net/dr_guo/article/details/50967442)。
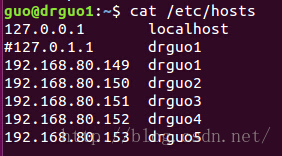
注意:要把127.0.1.1那一行注释掉,要不然会出现jps显示有datanode,但网页显示live nodes为0;
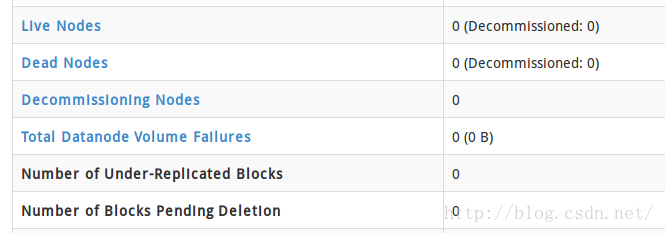
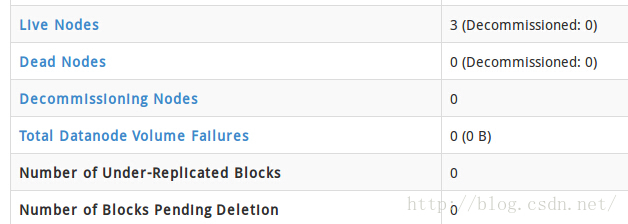
注释之后就正常了,好像有人没注释也正常,我也不知道为什么0.0
3.搭建zookeeper集群(drguo3/drguo4/drguo5)
4.正式开始搭建Hadoop HA集群
去官网下最新的Hadoop(http://apache.opencas.org/hadoop/common/stable/),目前最新的是2.7.2,下载完之后把它放到/opt/Hadoop下
- guo@guo:~/下载$ mv ./hadoop-2.7.2.tar.gz /opt/Hadoop/
- mv: 无法创建普通文件"/opt/Hadoop/hadoop-2.7.2.tar.gz": 权限不够
- guo@guo:~/下载$ su root
- 密码:
- root@guo:/home/guo/下载# mv ./hadoop-2.7.2.tar.gz /opt/Hadoop/
- guo@guo:/opt/Hadoop$ sudo tar -zxf hadoop-2.7.2.tar.gz
- [sudo] guo 的密码:
修改opt目录所有者(用户:用户组)直接把opt目录的所有者/组换成了guo。具体情况在ZooKeeper完全分布式集群搭建说过。
- root@guo:/opt/Hadoop# chown -R guo:guo /opt
设置环境变量
- guo@guo:/opt/Hadoop$ sudo gedit /etc/profile
- #hadoop
- export HADOOP_HOME=/opt/Hadoop/hadoop-2.7.2
- export PATH=$PATH:$HADOOP_HOME/sbin
- export PATH=$PATH:$HADOOP_HOME/bin
- guo@guo:/opt/Hadoop$ source /etc/profile
修改/opt/Hadoop/hadoop-2.7.2/etc/hadoop下的hadoop-env.sh
- guo@guo:/opt/Hadoop$ cd hadoop-2.7.2
- guo@guo:/opt/Hadoop/hadoop-2.7.2$ cd etc/hadoop/
- guo@guo:/opt/Hadoop/hadoop-2.7.2/etc/hadoop$ sudo gedit ./hadoop-env.sh
- export JAVA_HOME=${JAVA_HOME}#将这个改成JDK路径,如下
- export JAVA_HOME=/opt/Java/jdk1.8.0_73
- guo@guo:/opt/Hadoop/hadoop-2.7.2/etc/hadoop$ source ./hadoop-env.sh
注意:汉语注释是给你看的,复制粘贴的时候都删了!!!
修改core-site.xml
修改hdfs-site.xml
先将mapred-site.xml.template改名为mapred-site.xml然后修改mapred-site.xml
修改yarn-site.xml
修改slaves
把Hadoop整个目录拷贝到drguo2/3/4/5,拷之前把share下doc删了(文档不用拷),这样会快点。
5.启动zookeeper集群(分别在drguo3、drguo4、drguo5上启动zookeeper)
5.启动zookeeper集群(分别在drguo3、drguo4、drguo5上启动zookeeper)
6.启动journalnode(分别在drguo3、drguo4、drguo5上启动journalnode)注意只有第一次需要这么启动,之后启动hdfs会包含journalnode。
在drguo4/5启动时发现了问题,没有journalnode,查看日志发现是因为汉语注释造成的,drguo4/5全删了问题解决。drguo4/5的拼音输入法也不能用,我很蛋疼。。镜像都是复制的,咋还变异了呢。
7.格式化HDFS(在drguo1上执行)
7.格式化HDFS(在drguo1上执行)
这回又出问题了,还是汉语注释闹得,drguo1/2/3也全删了,问题解决。
注意:格式化之后需要把tmp目录拷给drguo2(不然drguo2的namenode起不来)
8.格式化ZKFC(在drguo1上执行)
9.启动HDFS(在drguo1上执行)
10.启动YARN(在drguo1上执行)
PS:
1.drguo2的resourcemanager需要手动单独启动:
1.drguo2的resourcemanager需要手动单独启动:
yarn-daemon.sh start resourcemanager
2.namenode、datanode也可以单独启动:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start
datanode
3.NN 由standby转化成active
hdfs haadmin -transitionToActive nn1 --forcemanual
大功告成!!!
3.NN 由standby转化成active
hdfs haadmin -transitionToActive nn1 --forcemanual
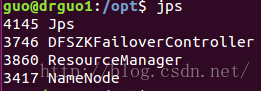
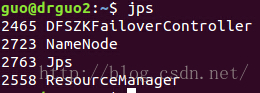
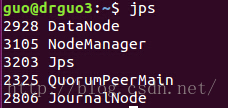
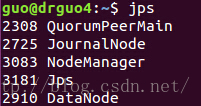
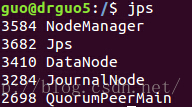
是不是和之前规划的一样0.0















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









