







堆和堆排序
要讲堆排序之前,首先就要先讲讲选择排序,堆排序在思路上实际上是选择排序是一致的。
先简单总结一下各种排序:
1. 插入排序,类比城插入牌一样,认为前面的数已经排好序了,遍历到新的数,把它插入到它应该在的位置。
2. 选择排序,每次都遍历数组,选择 未排序部分最大或最小的数字,把最小或最大的数放到最前面,然后剩下的往后各移一位
3. 冒泡排序,基本思想是將比較大的數字沉在最下面,较小的浮在上面。
堆排序实际上也是逐步选择未排序数组中最大或者最小的值,来进行排序。那么他比选择排序好在哪呢,在于他利用大顶堆或者小顶堆的结构特性加快了选择的速度。
堆结构
堆可以抽象地理解成二叉树的结构,但是只需要用数组进行存储,父节点的值总是大于或等于左右子节点的值(大顶堆)。注意到,在数组中,如果位置k为父节点,那么其左右子节点位置在 2k 和 2k+1 !!!!
如何把无序数组重构成堆有序的数组
检查所有父节点,即nums[1:length/2]当发现父节点比子节点小的时候,要将父子节点交换,即父节点下沉。
void heap(vector<int> &nums,int n){
//n表示带排列数组的长度
//检查所有父节点,即```nums[1:length/2]```当发现父节点比子节点小的时候,要将父节点和左右子节点中较大的那个交换,即父节点下沉。
for(int k=n/2;k>=1;k--)
sink(nums,k,n);
return;
}
void sink(int* nums,int parentIndex, int numsSize){
while(2*k<=n){
int j=2*k;
//找到子节点较大的那个
if(j<n && nums[j]<nums[j+1]) j++;
//如果下沉过程中,出现父节点大于等于左右子节点则停止下沉
if(nums[k]>=nums[j]) break;
//将父子节点贾环,完成下沉
swap(nums[k],nums[j]);
//换完之后,更改父节点位置,继续下沉
k=j;
}
}将堆有序的数组正确排序
将堆有序数组的第一位,也就是根节点(最大值)与最后一位交换,然后对除最后一位以外的数组重新构造堆有序数组。然后不断取出最大值也就是根节点。
void heapSort(vector<int>& nums){
int n=nums.size();
//初次堆排序
heap(nums, n);
//依次取出最大值
while(n>1){
swap(nums[1],nums[n--]);
//重新堆排序
sink(nums,1,n);
}
}优先队列
优先队列是一种变形的队列,先进但是永远是最大的数先出。每次放入一个数加入到数组最后,然后不断将其上浮(或者上述的下沉算法,直到所有的值都堆有序),顶部的值就可以一直保持是最大值。
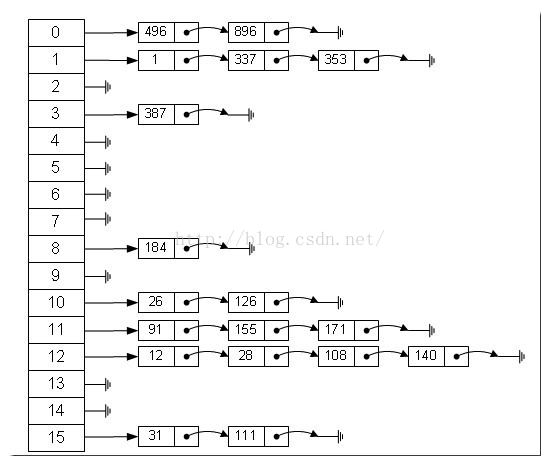
哈希表
对于数据而言,最重要的操作就是查找,插入,删除等等。数组由于其在内存中是连续存储的,所以可以通过索引在O(1)的时间内取到数据,而链表由于存储地址不连续,需要遍历,最坏需要O(n)的时间。但是对于插入而言,链表的优势却又很大。
HashTable的本质还是用数组存储数据,但如何能够做到快速插入和删除呢?
思想是通过一个函数,对给定的key做函数映射,得到一个整数,然后将该数字对要存储数据的数组长度取余,得到的结果就是存储value的数组下标。所以插入,查找,删除都只需要接近O(1)的时间。
但是一个很重要的问题是如何避免散列冲突? 即映射结果相同怎么办?
Java的HashMap使用的拉链法
数组里存链表,一旦遇到映射出来的下标已经被占用,则把该值附到链表的尾部
建立一个缓冲区,把凡是拼音重复的人放到缓冲区中。当我通过名字查找人时,发现找的不对,就在缓冲区里找。
进行再探测。就是在其他地方查找。探测的方法也可以有很多种。
3.1 在找到查找位置的index的index-1,index+1位置查找,index-2,index+2查找,依次类推。这种方法称为线性再探测。
3.2 在查找位置index周围随机的查找。称为随机在探测。
3.3 再哈希。就是当冲突时,采用另外一种映射方式来查找。
二叉树
二叉树的遍历
- 前序遍历
def preorderTraversal(self, root):
results = []
self.frontIter(root, results)
return results
def frontIter(self, root, results):
if root:
results.append(root.val)
self.frontIter(root.left, results)
self.frontIter(root.right, results)中序遍历
后序遍历
层次遍历















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









