







 本文详细介绍了Alpha-Beta算法的多种改进技术,包括吸出搜索、转移表、驳斥表、迭代深化、主变量搜索、杀手启发、历史启发和MTD(f)算法。这些技术通过优化搜索顺序、窗口大小、信息重用等方式提高搜索效率,减少搜索时间和空间开销。特别强调了迭代深化和转移表在内存管理和时间控制方面的优势,以及杀手启发和历史启发对移动择序的影响。
本文详细介绍了Alpha-Beta算法的多种改进技术,包括吸出搜索、转移表、驳斥表、迭代深化、主变量搜索、杀手启发、历史启发和MTD(f)算法。这些技术通过优化搜索顺序、窗口大小、信息重用等方式提高搜索效率,减少搜索时间和空间开销。特别强调了迭代深化和转移表在内存管理和时间控制方面的优势,以及杀手启发和历史启发对移动择序的影响。
在Alpha-Beta算法被广泛运用后,对该算法的很多改进算法也相继被提出.这些改进算法主要在以下几个方面对Alpha-Beta算法进行改进[7]:
1. 择序(ordering).在搜索博弈树时,内部结点有多个可能的移动.择序指的是搜索这些分支的顺序.择序影响着搜索叶结点的个数,使得其数目在[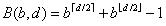 ,
,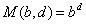 ]区间内变化.如果择序使得博弈树是随机的,那么所需搜索的叶结点的个数较多,如果择序使得博弈树是强有序的,那么所需搜索的叶结点的个数较少.
]区间内变化.如果择序使得博弈树是随机的,那么所需搜索的叶结点的个数较多,如果择序使得博弈树是强有序的,那么所需搜索的叶结点的个数较少.
在Alpha-Beta算法中,提高择序的好坏就意味着提高剪枝发生的概率.所以一个好的移动(sufficientor good move)可以定义为:
a. 导致剪枝的移动.
b. 或者如果没有导致剪枝,但是产生了最小最大值.
注意一个好的移动并不一定是最优的移动(best move),因为一个导致剪枝的移动可能引起了该子结点上的搜索停止,但是并不意味着其后的子结点的搜索不会产生一个更好的值(value).
2. 搜索窗口的大小.搜索窗口的大小指的是β和α之差.搜索窗口越小,发生剪枝的概率越大.
3. 信息的重用.保存子树的搜索结果,并审查这棵子树是否在随后的搜索中再次出现.如果该子树再次出现,那么关于子树的搜索结果的信息就可重复使用.
对Alpha-Beta算法比较常用的改进[8]将在下面介绍.
4.1 吸出搜索(Aspirationsearch)
为了保证Alpha-Beta搜索能返回最大最小值,一般将搜索的窗口设置为[-∞,+∞].如果能够同过一种有效的方法就出最大最小值的估计值V及其误差范围e,那么搜索窗口上下限可以设的更紧一些[V - e, V + e].这样做虽然可能导致搜索不能返回正确的最大最小值,但是也有可能更快地找到正确最大最小值.当发现返回的值不处在预测的范围之内时,需要重新进行搜索.如果由于缩小窗口而节省的开销大于由于重新搜索而增加的开销,则搜索速度得到了提升.
普通的Alpha-Beta搜索一般按照如下方式调用函数发起对博弈树的搜索:
1: node ← root
2: AlphaBeta(node, -∞, +∞)
吸出搜索使用如下策略发起对博弈树的搜索:
1: node ← root
2: V ← estimated_value(node)
3: e ← expected_error_limit(node)
4: alpha ← V - e
5: beta ← V + e
6: V ← AlphaBeta(node, alpha, beta)
7: if V ≥ beta then
8: V ← AlphaBeta(node, -∞, beta)
9: if V ≤ alpha then
10: V ← AlphaBeta(node, alpha, +∞)
4.2 转移表(Transposition Table)
转移表是一个大的直接访问表(direct access table),表中存储了已经搜索过的结点(或者子树)的搜索结果,包括子树的博弈值,最佳移动(best move)和位置.不管该子树是搜索完全得到了博弈值,还是只是完成部分搜索得到缩小的搜索窗口,由于重新搜索一个曾经搜索过的位置经常发生,所以使用转移表可以达到一些提高搜索效率的目的.首先,可能可以通过使用转移表来缩小搜索窗口.其次,以前的最佳移动被率先尝试,而这个移动可能曾经导致了一个剪枝,并有可能再次引发剪枝.跟进一步的,如果该子树已经搜索完成,那么根本没有必要再次搜索,只需要返回转换表中的博弈值即可.
下面的程序就是使用转移表的Alpha-Beta算法[8]:
AlphaBeta(node, alpha, beta)
1: (length, score, flag) ← Retrieve(node, node.opt)
2: if length ≥ node.depth then
3: if flag = VALID then
4: return score
5: if flag = LBOND then
6: alpha ← Max(alpha, score)
7: if alpha ≥ beta then
8: return score;
9: if depth ≤ 0 then
10: return EvaluateNe 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









