







一、 实验环境
- 操作系统:CentOS6.5
- Hadoop版本:hadoop-2.7.2
- JDK版本:jdk-8u73-linux-x64
二、 搭建步骤
1.安装操作系统:使用VitualBox安装CentOS6.5操作系统,安装方式选择为默认。(硬盘大小为20G,默认使用全部空间会对其做成LVM)。
2.通过以下命令修改当前主机名称:
vim /etc/sysconfig/network修改完成后重启机器。
3.配置网络:
① 开机不启动NetworkManager服务:
chkconfig NetworkManager off ② 停掉NetworkManager服务:
/etc/init.d/NetworkManager stop ③ 编辑网卡配置文件
vim /etc/sysconfig/network-scripts/ifcfg-eth0 内容编辑如下:
DEVICE=eth0
HWADDR=08:00:27:71:30:C0
TYPE=Ethernet
UUID=af0e8611-c438-4aa6-923c-ab55b3380478
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.0.15
NETMASK=255.255.255.04.关闭防火墙并设为开机不启动:
① 关闭防火墙服务:
/etc/init.d/iptables stop ② 开机不启动防火墙:
chkconfig NetworkManager off5.配置JDK环境:
① 将jdk-8u73-linux-x64.tar.gz包解压到/opt当中:
tar -xvf jdk-8u73-linux-x64.tar.gz -C /opt/ ② 配置系统环境变量:
vim /etc/profile 在/etc/profile文件中添加如下行:
export JAVA_HOME=/opt/jdk1.8.0_73
export JRE_HOME=${JAVA_HOME}/jre
export PATH=${JAVA_HOME}/bin:$PATH 保存退出,然后使用如下命令更新当前终端的环境变量配置
source /etc/profile 完成之后,使用如下命令来确认配置是否成功
java -version 若配置成功,则如下图所示:

6.在/下依次创建新文件夹,并将hadoop程序压缩包解压到该文件夹当中。
mkdir -p /hadoop/program && tar -xvf hadoop-2.7.2.tar.gz -C /hadoop/program/7.将含有hadoop常用命令的目录添加到环境变量中
vim /etc/profile 在最后添加如下字段:
export HADOOP_HOME=/hadoop/program/hadoop-2.7.2
export PATH=$HADOOP_HOME/bin:${PATH}保存重启,然后使用source命令更新当前终端配置。
8.配置hadoop:
hadoop的配置文件都在程序目录下中的etc/hadoop文件夹当中,对应我当前机器的绝对路径为/hadoop/program/hadoop-2.7.2/etc/hadoop文件夹。搭建hadoop伪分布式环境需要修改5个配置问价,如下:
① core-site.xml
*该配置文件指定**NameNode地址**以及hadoop运行时产生文件的的存放地址*。 修改configuration标签:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
</configuration>
② hadoop-env.sh
该配置文件主要指定hadoop运行时的环境变量,在该文件中,修改默认的JAVA_HOME对应值:
export JAVA_HOME=/opt/jdk1.8.0_73 ③ hdfs-site.xml
通过该配置文件指定文件存放副本的数量,修改configuration标签对应值(保存1份副本):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration> ④ mapred-site.xml
指定mapreduce的运行方法(YARN),修改configuration标签如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>⑤ yarn-site.xml
通过该配置文件指定NodeManager获取数据的方式使shuffle,和指定YARN ResourceManager的地址,修改configuration标签如下。
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
</configuration>
三、 启动Hadoop
1.初始化HDFS文件系统:
hdfs namenode -format2.启动HDFS和MapReduce,相应的启动脚本在hadoop程序目录中的sbin文件夹中,分别执行start-hdfs.sh和start-yarn.sh脚本。
四、 测试Hadoop
1.通过浏览器方式对HDFS和MapReduce进行访问,HDFS默认的浏览器访问端口为为50070,MapReduce默认的访问端口为8088。访问成功如图所示:
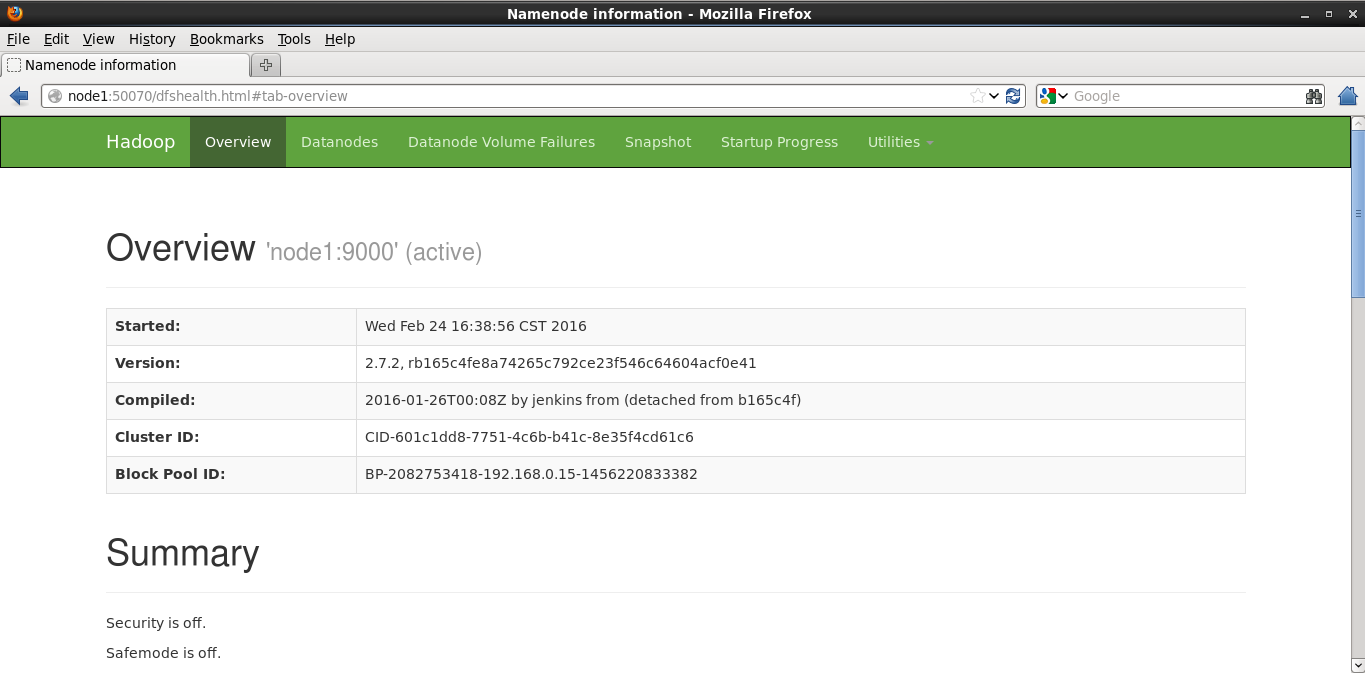
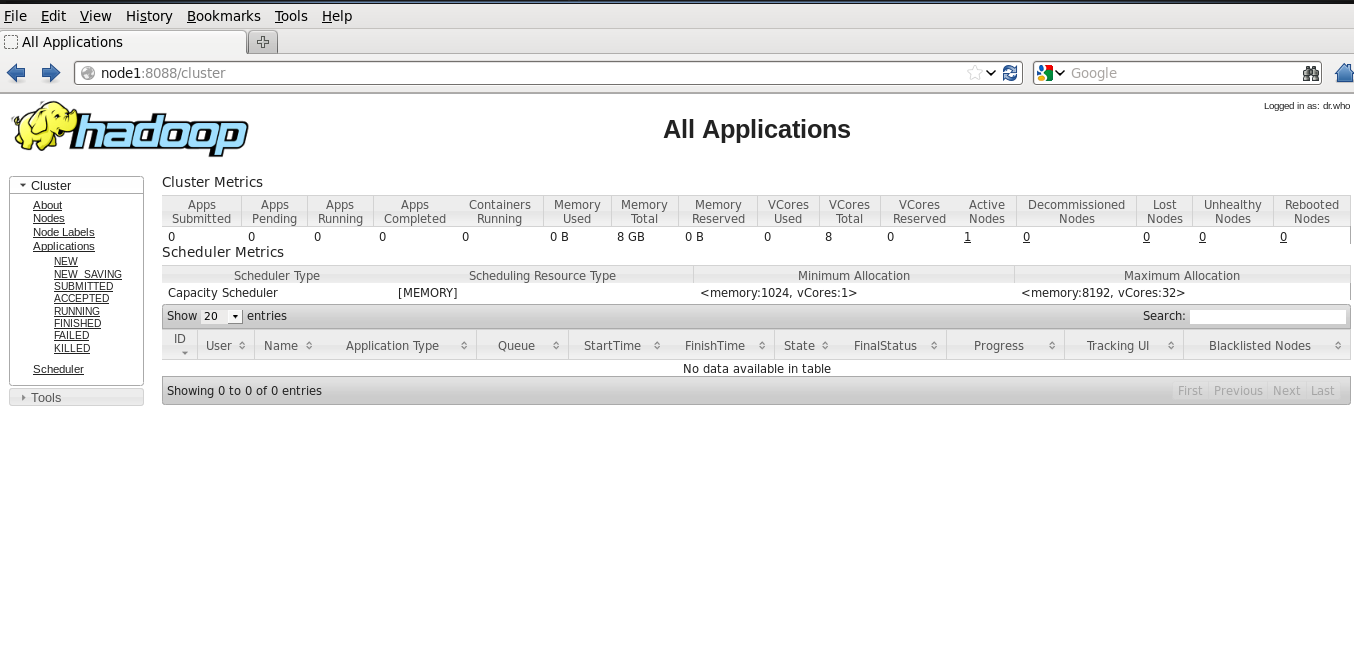
2.将文件上传到HDFS当中,使用命令:
hadoop fs -put 文件名称 hdfs://node1:9000/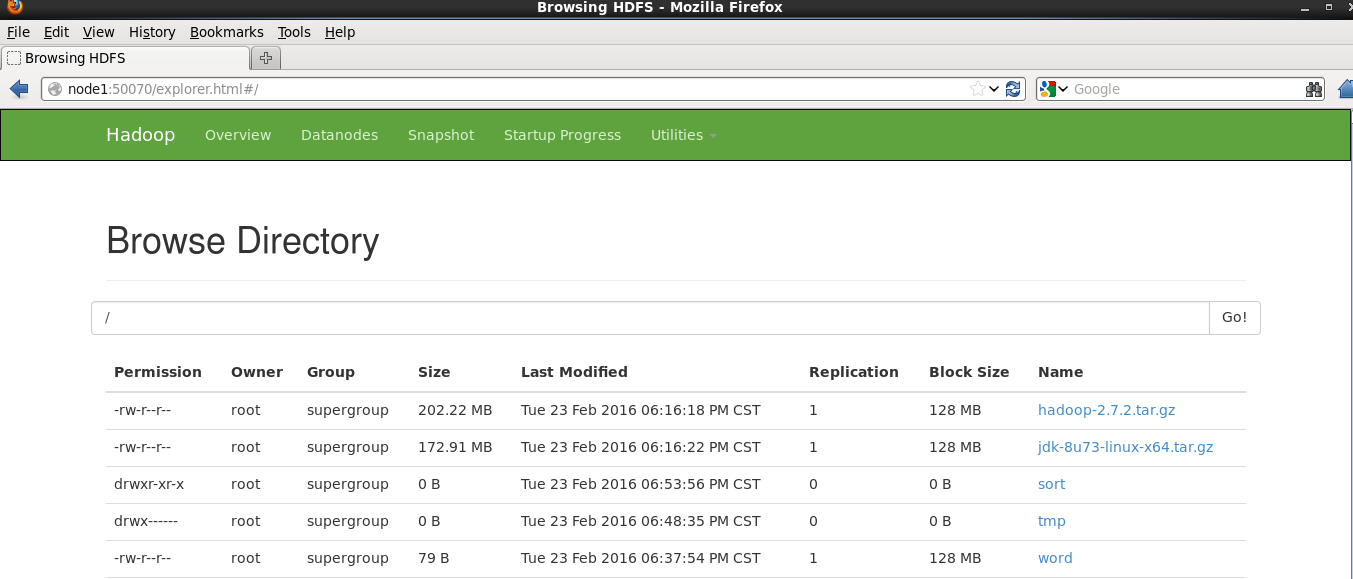
在Utilities标签页下可以看到上传的文件的信息。
3.使用MapReduce进行简单的数据分析,使用Hadoop程序目录下的share/hadoop/mapreduce/中的测试jar文件hadoop-mapreduce-examples进行测试:
hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount hdfs://node1:word hdfs://node1:wordout执行成功后,可以看到在HDFS下有的wokdout文件:
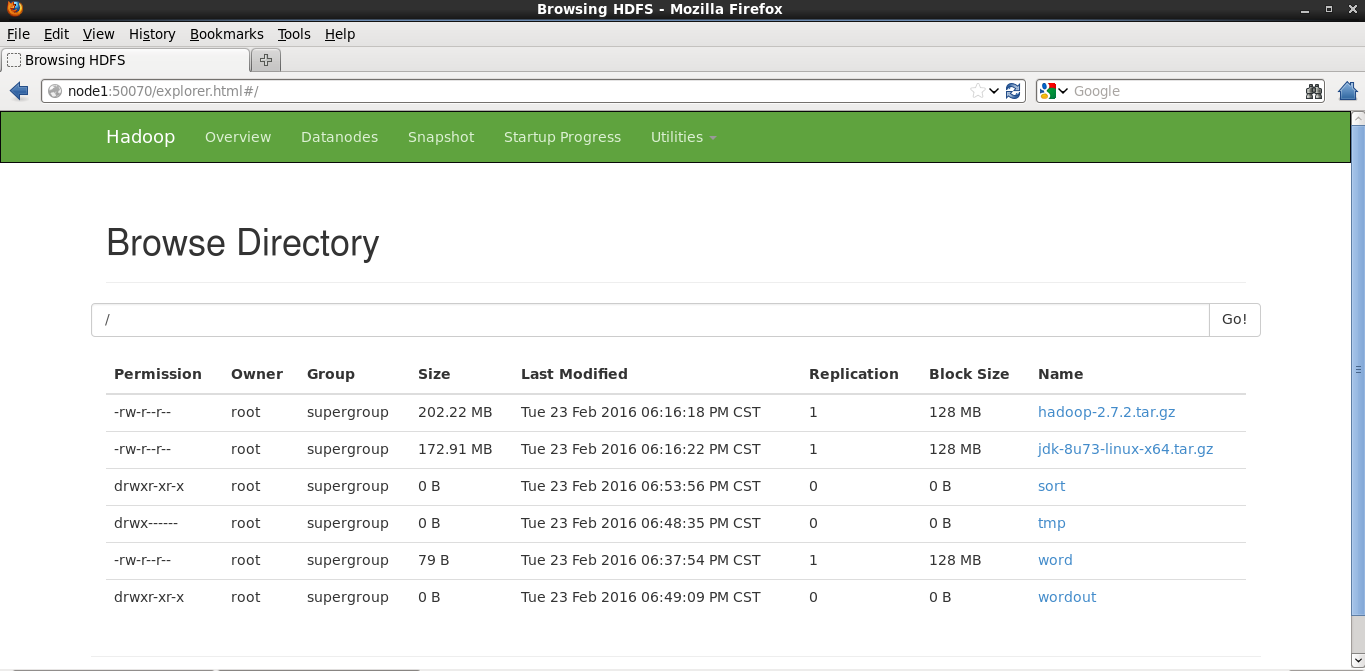
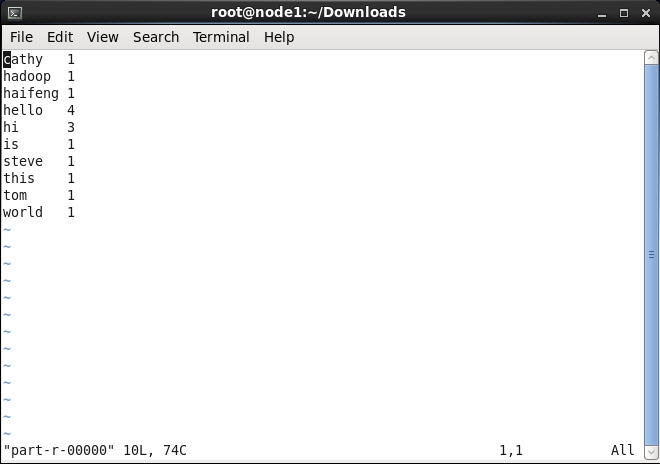
下载下来进行查看,可以看到:















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









