






参考书籍:《网络是怎样连接的》
浏览器生成消息
现在,我们经常会在浏览器上访问各种各样的信息,而为了获取这些信息,我们通常需要wifi和流量。在这背后,信息是如何通过网络传输的呢?
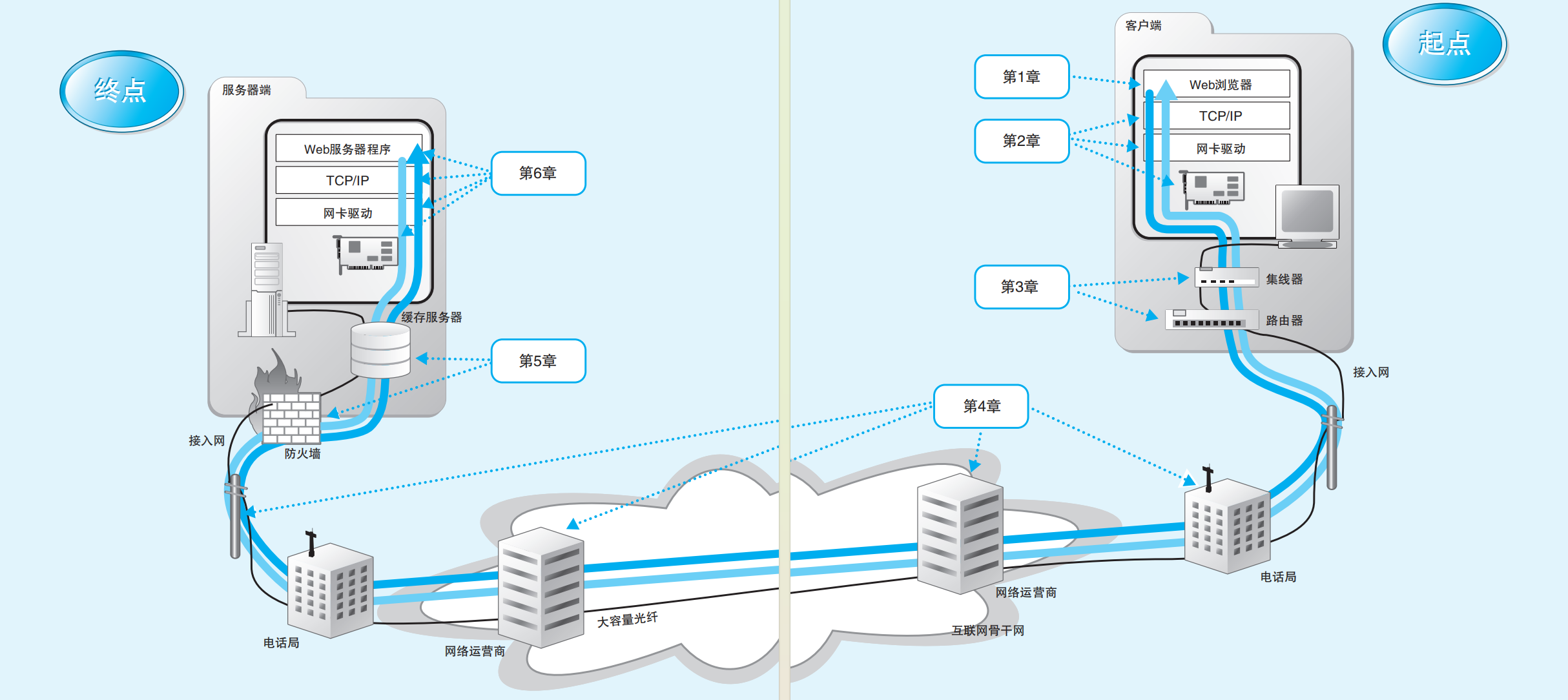
我们可以将浏览器和服务器的交互视作一个简单的模型,请求-响应模型
浏览器发送请求:请给我xxx信息
服务器返回响应:给你xxx信息
而我们申请报销或者请假,都需要填表。也就是说,要用一个规范化的语言表达我们的诉求。而浏览器要发送的请求信息也要遵守规范,比如说HTTP协议(超文本传输协议)
扩展时刻
浏览器发送请求信息时要遵守的规范并不只有HTTP协议,这具体取决于我们使用浏览器做什么。
-
如果是访问WEB服务器,当然遵守HTTP协议
-
如果是去FTP服务器上下载文件,遵守的就是FTP协议
-
如果是发送电子邮件,遵守的就是电子邮件的协议
因此,我们也可以得出,浏览器是具有多种功能的客户端。
生成HTTP请求信息
我们在请假时,往往需要填写本人信息、请假事由,同时还要知道请假单要送到哪里。
浏览器在生成HTTP请求信息时,也需要知道要获取什么信息,要向哪里请求获取信息。而告诉浏览器的,就是URL,也就是我们平常说的网址。
URL的格式为:
协议名://用户名:密码@服务器域名:端口号/文件路径/文件名
示例:
http://user:password@www.glasscom.com:80/dir/file1/htm网址中的用户名、密码、端口号、文件路径和文件名都是可以省略的,文件名省略时就取服务器中文件路径下的默认文件。
知道了请求内容和服务器域名,浏览器就要根据HTTP协议生成请求信息了。
HTTP规定请求信息中包括请求方法 + URI,即对什么(URI)做什么(请求方法)。请求方法包括GET(获取信息)和POST(上传表单)等等
HTTP规定响应信息中要包含响应码,比较常见的是404(文件信息找不到)。而绝大部分成功响应的响应码用户是看不到的,一般是2开头的三位数字。
当我们要访问某个网站时,服务器返回的一般是前端代码,浏览器渲染后成了我们看到的网站界面。如果你看到的网站中包含图片,那么你在访问这个网站时,浏览器向服务器发送了不止一个请求。
-
服务器返回网站代码
-
浏览器在渲染代码时预留出显示图片的空间
-
再次访问服务器(以图片名为URI)
-
服务器返回图片
如果网站中有多个图片,那么就要请求多次。因为一次请求只能获取一个URI。也就是说如果一个网站有3张图片,那么向服务器请求的次数 = 访问网站1次 + 访问图片3次 = 4次
通过这些知识,你也可以理解为什么在网卡时,图片要比网站中其它内容加载更慢,因为他们还在等待服务器的响应。
向DNS服务器查询WEB服务器IP地址
我们在URL中可以知道服务器的域名,但是我们并不使用域名去寻找服务器,而是先用域名找到对应的IP地址,再通过IP地址找到服务器。
为什么不能使用域名去找服务器呢? 因为域名长度不定,而且要用很长的字节来表示,这会导致路由器的硬件实现变得复杂且效率低下 为什么要使用域名? 因为IP地址难以记忆,虽然你也可以在网址上写IP地址而不是写域名
IP地址类似于门牌号,它包含了网络号和主机号,网络号类似于xx楼,主机号类似于xx室。IP地址标注了计算机在网络中所处的位置。
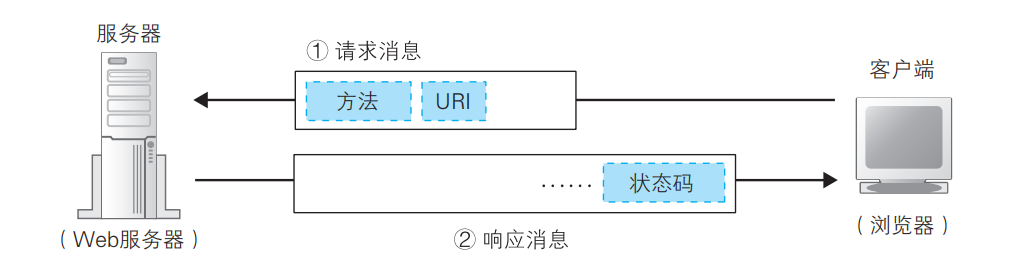
IP地址源于网络的构造。集线器将多个计算机连接起来,构成一个子网;路由器将多个子网连接起来,构成网络。子网的唯一标识就是网络号,而计算机的唯一标识就是主机号。
IP地址拥有固定长度,即32比特。但IP地址中哪一部分是网络号,哪一部分是主机号呢?我们用附加信息子网掩码来表示。
IP地址主体(十进制表示): 10.11.12.13
与IP地址主体相同的格式来表示掩码:10.11.12.13/255.255.255.0
采用网络号比特数来表示子网掩码: 10.11.12.13/24将子网掩码255.255.255.0以二进制形式表示出来,为1的部分对应的IP地址均为网络号,为0的部分对应的IP地址为主机号
IP地址主体(二进制表示): 0000 1010 0000 1011 0000 1100 0000 1101
与IP地址主体相同的格式的子网掩码 1111 1111 1111 1111 1111 1111 0000 0000 //255.255.255.0
网络号 0000 1010 0000 1011 0000 1100 -> 10.11.12
主机号 0000 1101 -> 13采用网络号比特数24就意味着从左到右有24位为网络号,两种子网掩码格式含义相同
如果主机号部分为0,则意味着该地址代表着整个子网 -> 10.11.12.0
如果主机号部分均为1,则意味着该地址表示对整个子网广播 -> 10.11.12.255 // 广播即表示向子网上的所有设备发送包了解了IP地址,我们就该聊聊如何将域名转换为IP地址,这个过程称为域名解析,使用DNS(域名服务系统)
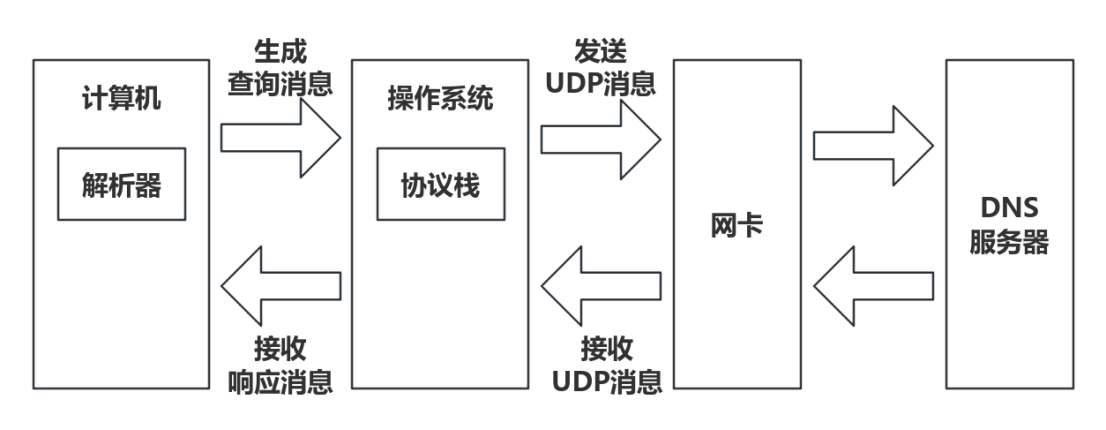
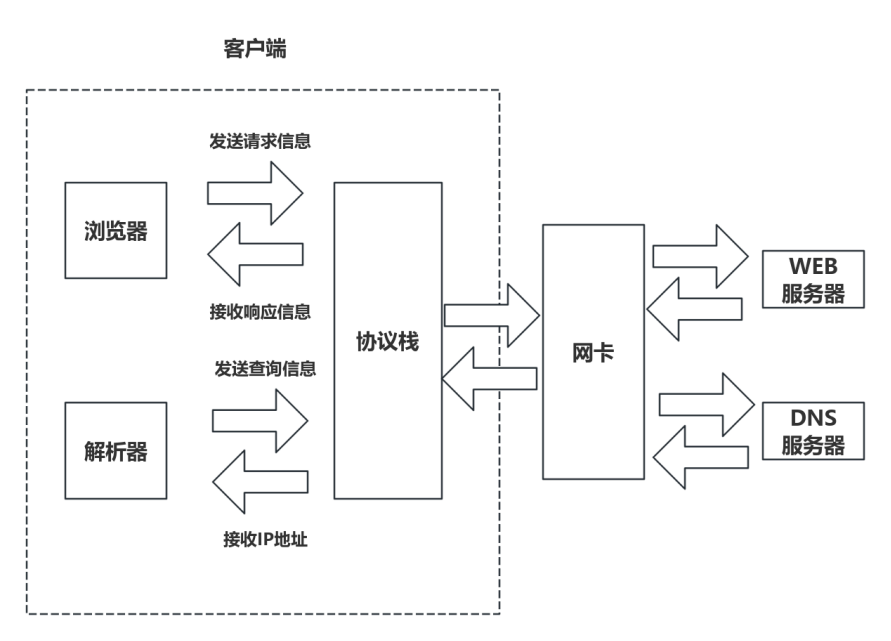
计算机上有DNS客户端,我们将它称为解析器。它实际上由操作系统的Socket库提供。计算机通过解析器生成查询信息,操作系统的协议栈接到查询信息后发送UDP信息至DNS服务器;DNS服务器按照原路线返回查询到的IP地址。
-
在此次查询过程中,DNS服务器的IP地址已经被存储在计算机中,因此解析器可以直接调用。
-
操作系统中的Socket库是调用网络功能的程序集合
-
解析器同浏览器一样,只负责生成请求信息,发送请求信息的操作由操作系统协议栈负责
全世界DNS服务器的大接力
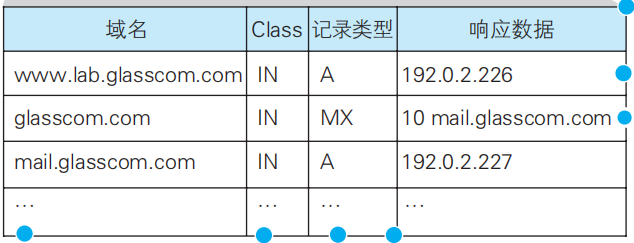
解析器生成的查询信息,其中包括域名、网络类型Class、记录类型
-
网络类型:现在均为互联网IN
-
记录类型:A表示域名对应的是IP地址,MX表示域名对应的是邮件服务器……
DNS服务器会根据查询信息从域名与IP地址的对照表中找到对应记录并返回IP地址;如果记录类型是MX,则会先找到其服务器的域名地址,再根据域名地址找到IP地址。对照表保存在DNS服务器的配置文件中。
但根据沉浸在网络多年的经验,我们应该明白域名的数量是庞大的。如此多的域名不会都保存在一个DNS服务器中,域名会以分层次的结构存储在DNS服务器中。
例如www.lab.glasscom.com,com作为最顶层的DNS服务器,保存着glasscom服务器的IP地址;glasscom中保存着lab服务器的IP地址;lab中保存着www服务器的地址。因此,我们可以得出结论,域名将以从后往前、句号分隔的方式逐层保存在DNS服务器中。www.lab.glasscom.com的IP地址自然保存在www服务器中。但com之上还有根域,一般在网址中会被省略。
如果将域名比作一家公司,那么类似于com集团glasscom公司lab部门com组。
而计算机查询域名的IP地址,首先会从距离自己最近的DNS服务器中查找;如果找不到,就会从根域逐层往下查找。从根域中找到com,再从com中找到glasscom,然后从glasscom中找到lab,从lab中找到www,最后从www中找到对应的IP地址。
类似于你在学校要找一名同学,你首先从自己的班级里找,发现找不到;你就去问校长,校长说是xx学院的;你再去找院长,院长说是xx年级的;你去找年级段长,段长说是xx班的;你最后去找班长,班长就直接把人交给你了(纯属虚构,只是更方便理解)。
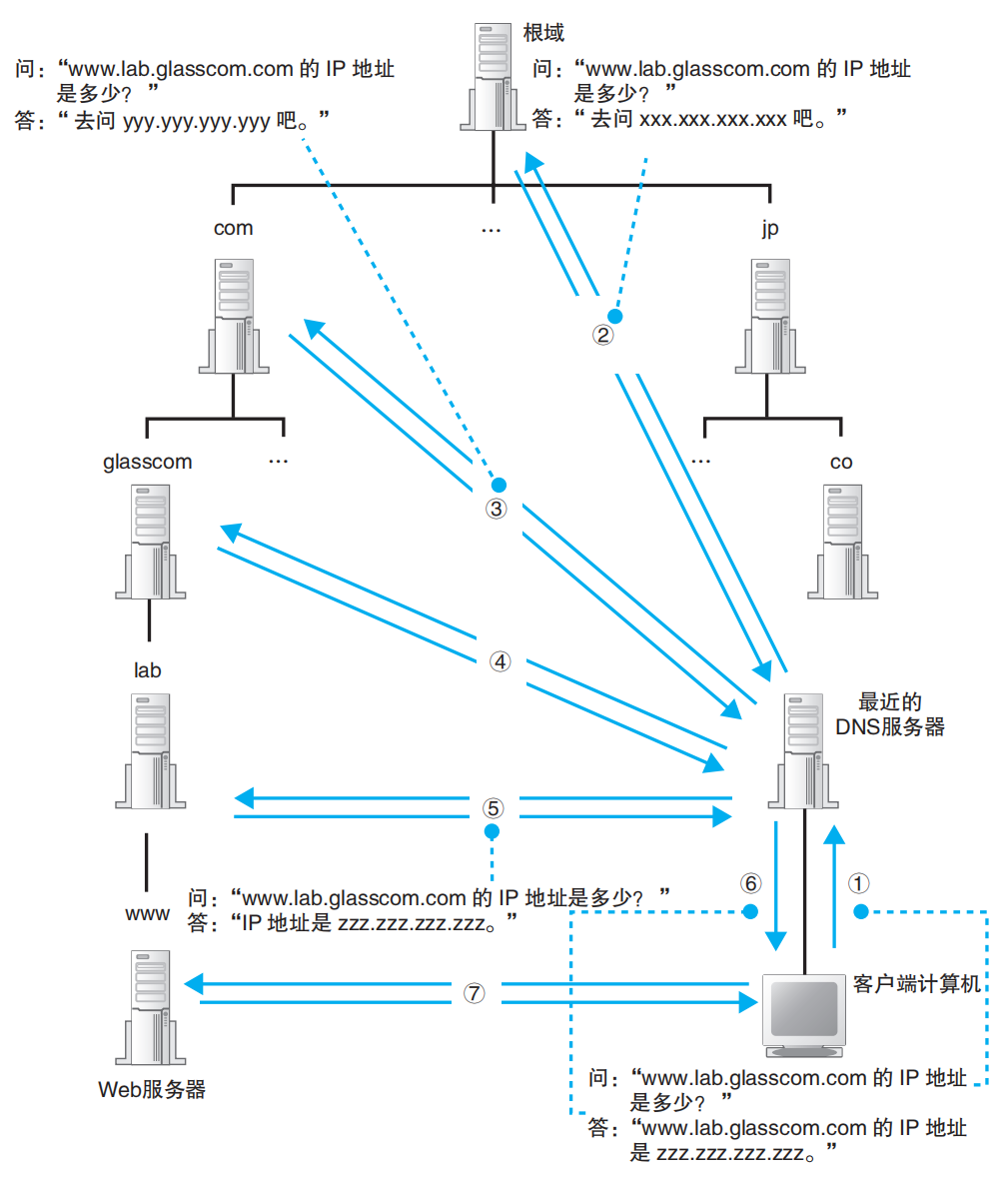
在真实情况中,一个DNS服务器可以掌管多个域名,上述内容只是为了方便理解。
DNS服务器中具有缓存功能,可以记住查询过的域名的IP地址,方便下次快速查询。但DNS服务器有可能更新域名对应的IP地址,因此缓存信息变得不再正确。缓存信息都是有期限的,过期就删除。同时,DNS服务器会提示响应信息是缓存信息还是查询而来的。
委托协议栈发送消息
同向DNS服务器发送查询信息一样,向web服务器发送请求信息也需要使用Socket库中的程序组件。不同的是,向DNS服务器发送查询信息只需一个程序组件,向web服务器发送请求信息需要按指定顺序调用多个程序组件。
收发数据的流程如下:
-
服务端创建套接字,并使其处于等待状态
-
客户端创建套接字
-
客户端的套接字通过管道连接到服务端的套接字(客户端发起)
-
通过管道收发数据
-
断开管道并删除套接字(客户端或服务端任意一方发起)
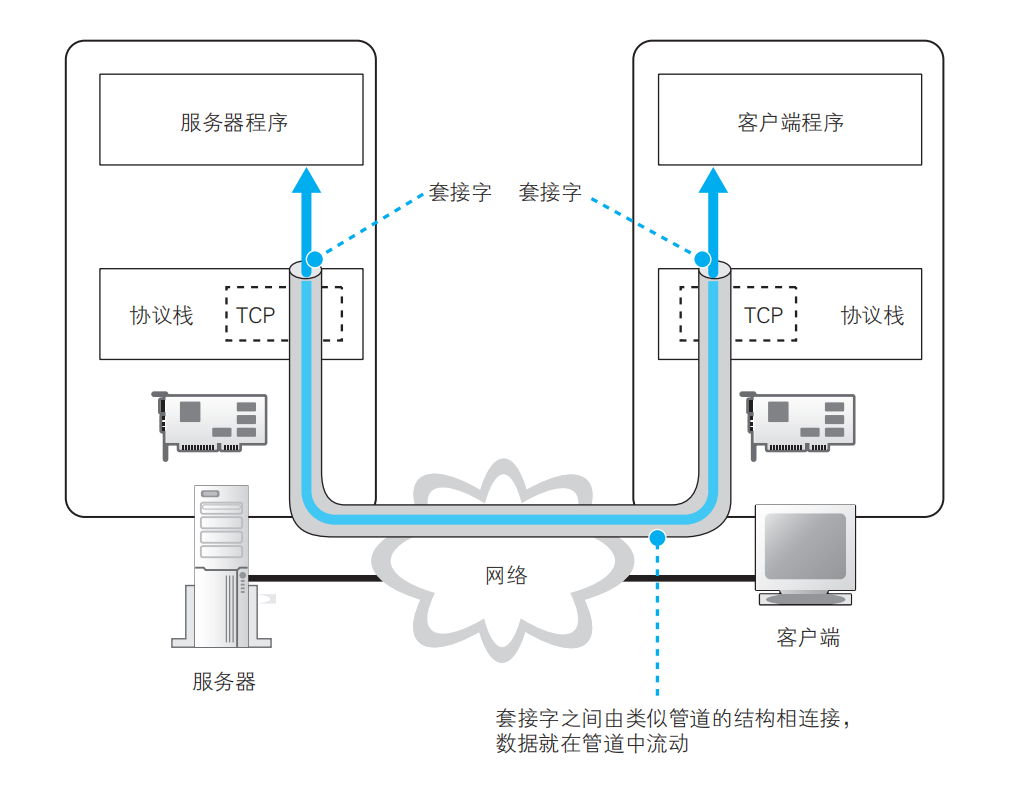
创建套接字的过程中,会返回套接字的描述符,描述符是用来计算机内部识别套接字的。
我们在使用计算机时,很有可能同时运行多个窗口,存在多个套接字向web服务器发送请求,因此需要描述符来识别套接字。而服务器中也有许多套接字,端口号就是客户端识别服务器指定套接字的标识。推而广之,端口号是通信另一方识别套接字的标识,描述符是计算机内部识别套接字的标识。
连接套接字的过程中,操作系统Socket库通过描述符、服务器IP地址、端口号来执行连接操作。而端口号一般是事先规定好的,比如WEB是80号端口,电子邮件是25号端口。而连接后,服务器也需要知道客户端的端口号,因此,在客户端创建套接字时,协议栈已经为套接字分配了端口号,并会在连接过程中将端口号告知服务器。
传递数据的过程中,协议栈根据给定的描述符找到对应的套接字,根据套接字内的信息确定通信对象,之后将数据传递出去。接收数据时,协议栈将响应信息放到应用程序内部的内存空间,称为接收缓存区。
断开阶段,客户端和服务端哪一方先执行断开连接都有可能,需要根据应用种类来确定。之前,一次连接只能获取一次数据,现在可以在一次连接中收发多个请求和响应,这提高了效率。















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









