






在进行测试的过程中,我们的样品数量有很多,但是不同的样品测试完就形成了一个独立的文件,不同样品会形成不同的文件,因此,有时在进行数据处理之前,需要将这些数据列表进行合并统一分析,本文上传我的方法:
本文的内容一共分为文件打开,数据合并,数据保存三部分
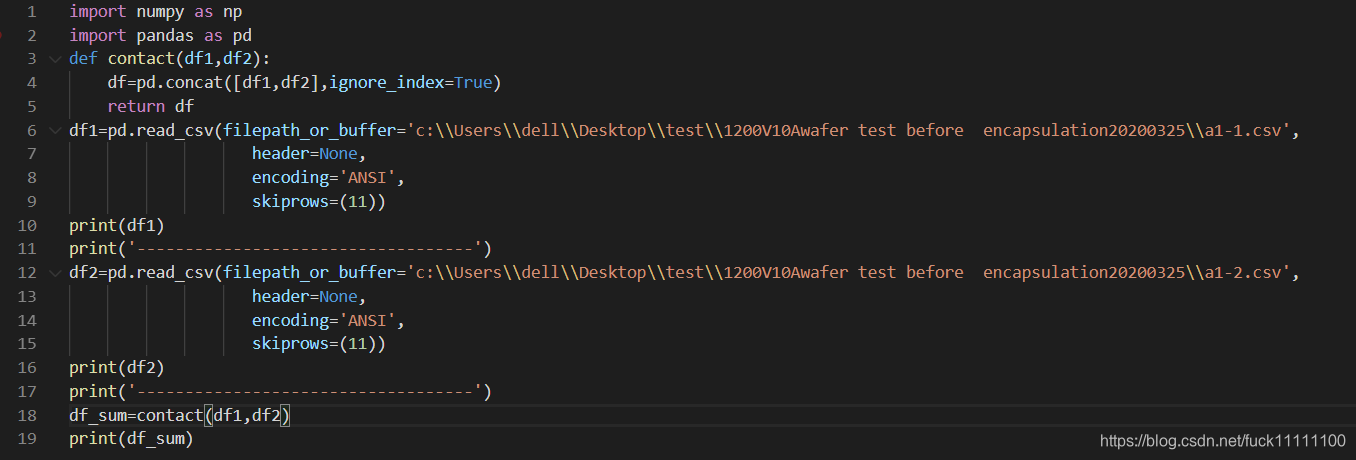
1 文件打开:
**#打开文件
def open(file_csv):
df=pd.read_csv(filepath_or_buffer='c:\\Users\\dell\\Desktop\\test.csv',
header=None,
encoding='ANSI',
skiprows=(11))
return df
为了使程序的的可读性变强,我们选择将功能打包成函数,每个函数只完成一个操作,以上代码的含义是:
定义一个open(file_csv)的函数:
函数的主体就是pd.read_csv()函数,参数是filepath_or_buffer=文件的物理地址,这里可以用相对地址或者绝对地址,只是斜杠的方向不同;
header=None意思读入的表格没有列名,这样方便我们后续自己定义;
encoding="ANSI"这是解码方式,也可以是UTF-8,这要根据具体的文件解码方式来选择;
skiprows=(11)是我选择跳过最开始的10行,因为他们不是我所需要的数据,并且会影响我需要数据的列名排列,因此这里选择跳过他们,这里需要注意:
skiprows=(11)是跳过最开始的0-11行,
skiprows=[0,2,5]是跳过0,2,5共分立的3行;
然后返回表格df
2 数据合并:
#合并数据
def contact(df1,df2):
df=pd.concat([df1,df2],ignore_index=True)
return df
定义一个contact()的函数,用来连接df1和df2这两个表格形成一个新的表格,这两个表格拥有相同的索引;
所使用的是pd.concat()函数,这里要特别注意是concat不是contact噢,写错的话会报属性错误:
AttributeError: module 'pandas' has no attribute 'contcat'
[df1,df2]参数包括需要连接的数据对象,可以是列表或者字典,用[ ]括起来;
axis参数表示连接轴的方向,默认是0,沿着 行方向;
join参数表示连接方式,默认是"outer"是两个数据的并集;
ignore_index=True:意思是不沿着连接轴保留索引而产生一段新的索引
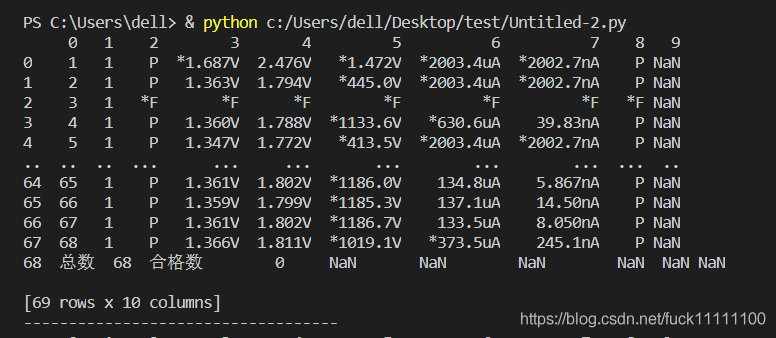
效果如下图所示:
df1:
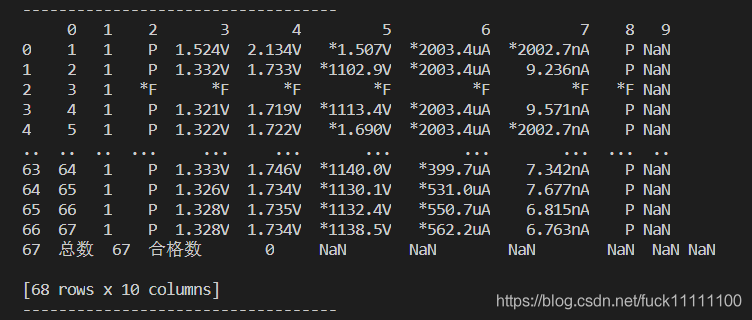
df2:
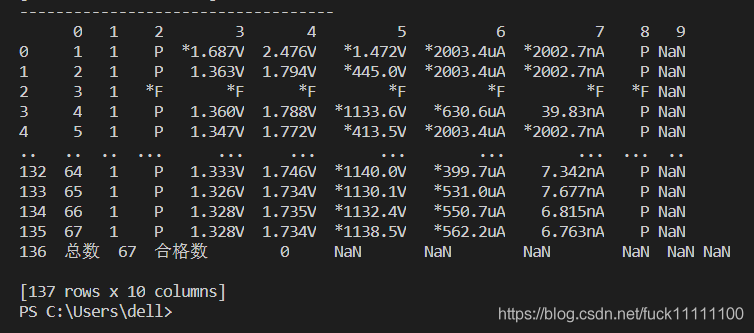
contact(df1,df2)
代码样子:
3 数据保存
#数据保存
df_sum.to_csv(path_or_buf='c:\\Users\\dell\\Desktop\\test.csv',index=False)
使用的是保存为csv文件的函数,path_or_buf参数说明保存的地址,index=False使得索引行不在文件中占单独的一行,这样当我们调用该文件进行绘图时就不会出现可恶的unnamed:0行出现干扰
无干扰:
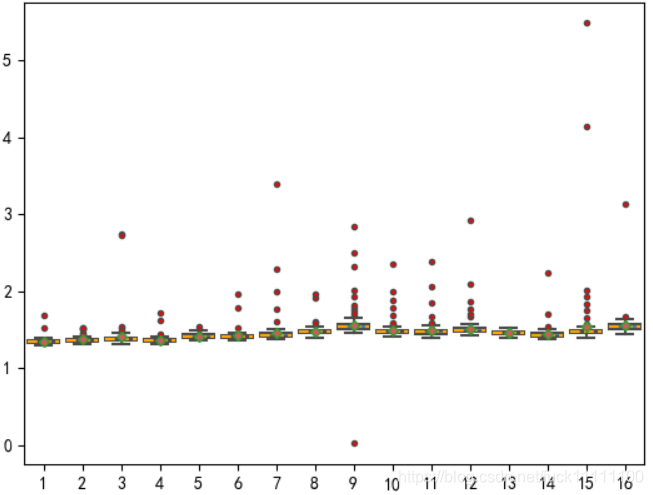
有干扰:
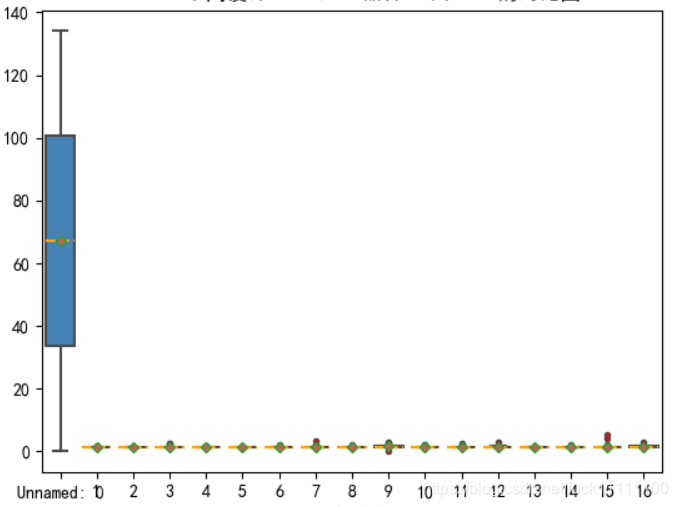
由上图对比,可以发现这种unnamed:0列非常影响图像表达效果,要引起注意**

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











