






概述
行业背景
近年来随着互联网业务的迅速发展以及新兴业务激增,业务数据呈现几何倍数增加,传统服务器+存储的竖井式架构已无法很好满足业务发展需求,分布式、云化技术应运而生。越来越多企业采用虚拟化与云计算技术来构建IT系统,提升IT系统的资源利用率以及缩短业务上线周期。但在应用过程中,企业面临如下挑战:
1)系统庞大,管理复杂,运维费用持续走高。
2)安装部署复杂,硬件来自多厂商,规划、部署、调优需要丰富的经验支撑。
3)多厂商设备,售后支持界面多,解决问题慢。
4)企业越来越关注成本控制、业务敏捷、风险管控,希望能拥有总成本低、新业务上线时间快、资源可弹性伸缩、安全可靠、高性能的IT系统。
ZStack Cloud应运而生
ZStack Cloud云平台(简称ZStack Cloud)是下一代云计算IaaS软件。它主要面向未来的智能数据中心,通过提供灵活完善的APIs来管理包括计算、存储和网络在内的数据中心资源。用户可以利用ZStack Cloud快速构建自己的智能云数据中心,也可以在稳定的ZStack Cloud之上搭建灵活的云应用场景,例如云桌面、PaaS、SaaS等。
技术优势
ZStack Cloud是基于私有云平台4S(Simple简单、Strong健壮、Scalable弹性、Smart智能)标准设计的下一代云平台IaaS软件。
简单(Simple)
1)简单安装部署:提供安装文件网络下载,30分钟完成从裸机到云平台的安装部署。
2)简单搭建云平台:支持云主机的批量(生成,删除等)操作,提供列表展示和滑窗详情。
3)简单实用操作:详细的用户手册,足量的帮助信息,良好的社区,标准的API提供。
4)友好UI交互:设计精良的专业操作界面,精简操作实现强大的功能。
健壮(Strong)
1)稳定且高效的系统架构设计:拥有全异步的后台架构,进程内微服务架构,无锁架构,无状态服务架构,一致性哈希环,保证系统架构的高效稳定。目前已实现:单管理节点管理上万台物理主机、数十万台云主机;而多个管理节点构建的集群使用一个数据库、一套消息总线可管理十万台物理主机、数百万台云主机、并发处理数万个API。
2)支撑高并发的API请求:ZStack Cloud单管理节点可以轻松处理每秒上万个并发API调用请求。
3)支持HA的严格要求:在网络或节点失效情况下,业务云主机可自动切换到其它健康节点运行;利用管理节点虚拟化实现了单管理节点的高可用,故障时支持管理节点动态迁移。
弹性(Scalable)
1)支撑规模无限制:单管理节点可管理从一台到上万台物理主机,数十万台云主机。
2)全API交付:ZStack Cloud提供了全套IaaS API,用户可使用这些APIs完成全新跨地域的可用区域搭建、网络配置变更、以及物理服务器的升级。
3)资源可按需调配:云主机和云存储等重要资源可根据用户需求进行扩缩容。ZStack Cloud不仅支持对云主机的CPU、内存等资源进行在线更改,还可对云主机的网络带宽、磁盘带宽等资源进行动态调整。
智能(Smart)
1)自动化运维管理:在ZStack Cloud环境里,一切由APIs来管理。ZStack Cloud利用Ansible库实现全自动部署和升级,自动探测和重连,在网络抖动或物理主机重启后能自动回连各节点。其中定时任务支持定时开关云主机以及定时对云主机快照等轮询操作。
1)在线无缝升级:5分钟一键无缝升级,用户只需升级管控节点。计算节点、存储节点、网络节点在管控软件启动后自动升级。
2)实时的全局监控:实时掌握整个云平台当前系统资源的消耗情况,通过实时监控,智能化调配,从而节省IT的软硬件资源。
产品架构
软件架构
ZStack Cloud软件架构如图1所示:
图 1. 软件架构
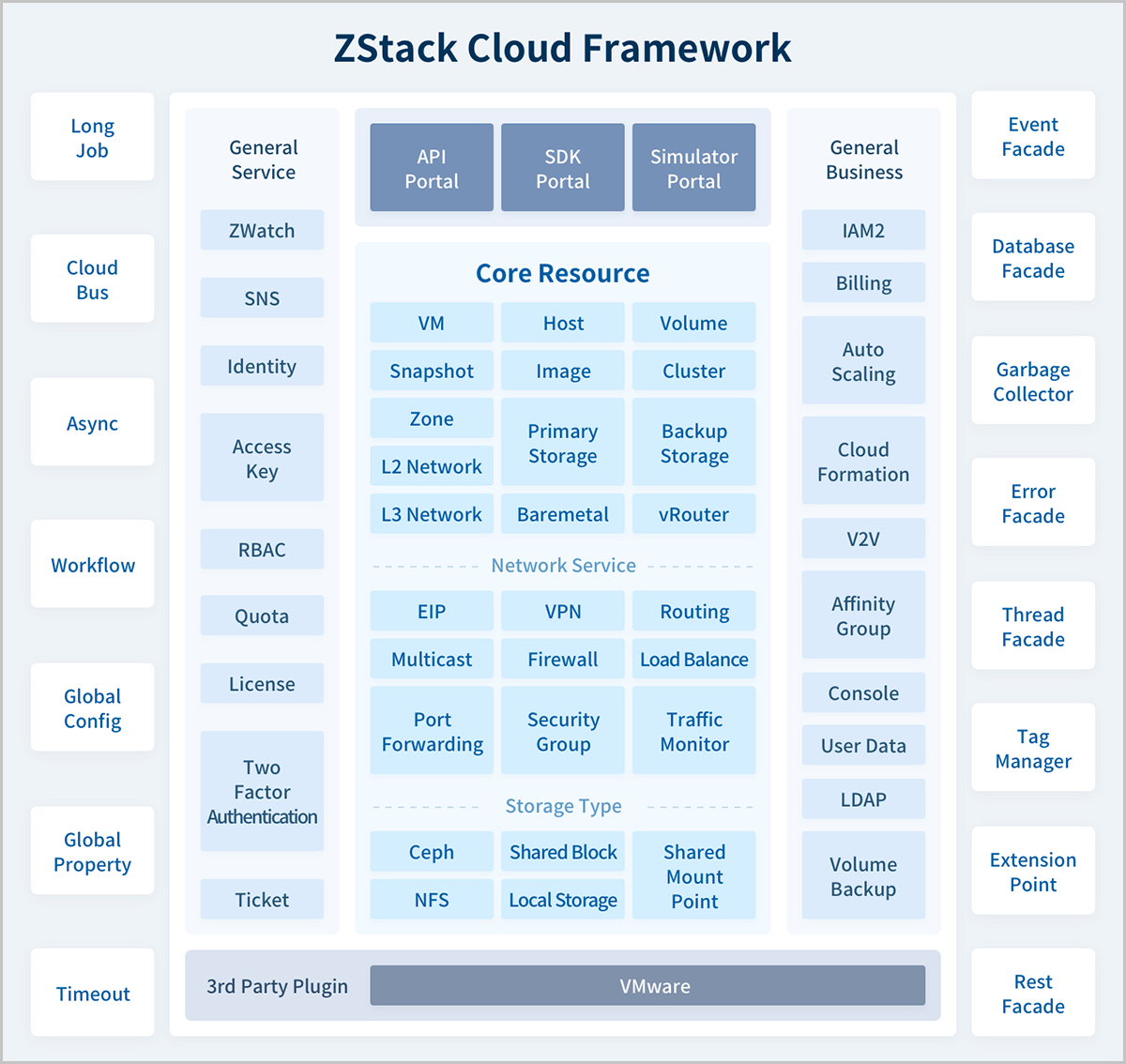
ZStack Cloud软件架构特点:
1)全异步架构:异步消息、异步方法、异步HTTP调用。
- ZStack Cloud使用消息总线进行各服务的通信连接,在调用服务时,源服务发消息给目的服务,并注册一个回调函数,然后立即返回;一旦目的服务完成任务,就会触发回调函数回复任务结果。异步消息可以并行处理。
- ZStack Cloud服务之间采用异步消息进行通信,对于服务内部,一系列相关组件或插件,也是通过异步方法来调用,调用方法与异步消息一致。
- ZStack Cloud采用的插件机制,给每个插件设置相应的代理程序。ZStack Cloud为每个请求设置了回调URL在HTTP的包头,任务结束后,代理程序会发送应答给调用者的URL。
- 基于异步消息、异步方法、异步HTTP调用这三种方式,ZStack Cloud构建了一个分层架构,保证了所有组件均能实现异步操作。
- 基于全异步架构机制,单管理节点的ZStack Cloud每秒可并发处理上万条API请求,还可同时管理上万台服务器和数十万台云主机。
2)无状态服务:单次请求不依赖其他请求。
- ZStack Cloud的计算节点代理、存储代理、网络服务、控制台代理服务、配置服务等,均不依赖其他请求,一次请求可包含所有信息,相关节点无须维护存储任何信息。
- ZStack Cloud使用一致性哈希环对管理节点、计算节点或者其他资源以UUID为唯一ID进行认证的哈希环处理,消息发送者无需知道待处理消息的服务实例,服务也无须维护、交换相关的资源信息,服务只需单纯的处理消息即可。
- ZStack Cloud管理节点间共享的信息非常少,两个管理节点即可满足高可用性和可扩展性需求。
- 无状态服务机制让系统更为健壮,重启服务器不会丢失任何状态信息,数据中心的弹性扩展和伸缩性维护更为简单。
3)无锁架构:一致性哈希算法。
- 一致性哈希算法保证了同一资源的所有消息均被同一个服务实例来处理。这种聚合消息到特定节点的方法,降低了同步与并行的复杂度。
- ZStack Cloud使用工作队列来避免竞争锁的问题,串行任务以工作队列的方式保存在内存中,工作队列可对任意资源的任意操作进行并行处理来提高系统并行度。
- ZStack Cloud基于队列的无锁架构,使得任务可以简单地控制并行度,从而提升系统性能。
4)进程内微服务:微服务解耦。
- ZStack Cloud使用消息总线对各服务进行隔离控制,例如,云主机服务、身份认证服务、快照服务、云盘服务、网络服务、存储服务等。所有的微服务都集合在管理节点的进程内,各服务之间利用消息总线进行交互,所有消息发送到消息总线后,再通过一致性哈希环选择目的服务进行转发处理。
- 进程内微服务,以星状架构实现各服务独立运行,将高度集中的控制业务进行解耦,实现了系统的高度自治和高度隔离,任何服务出现故障并不影响其他组件。可靠性与稳定性得到有效保障。
5)全插件结构:插件支持横向扩展。
- ZStack Cloud使用中任何新加入的插件对目前其他的插件没有任何影响, 均是独立自主提供服务。
- ZStack Cloud支持策略模式和观察者模式进行插件设计。策略插件会继承父类的接口然后执行具体实现;观察者插件,会注册listener进行监控内部的业务逻辑的事件变化,当应用内部发现事件时,插件会对此事件做出自响应,在插件自身的代码里执行相应的业务流。
- ZStack Cloud支持插件的横向扩展,云平台可以快速更迭,而整体系统架构依然健壮。
6)工作流引擎:顺序管理,出错回滚。
- ZStack Cloud工作流基于XML对每个工作流程进行清晰定义,在任何步骤出现错误均可按照原本执行路径进行回滚,清理掉执行过程的垃圾资源。
- 每个工作流还可以包含子工作流用于扩展业务逻辑。
7)标签系统:支持业务逻辑变更,增加资源属性。
- ZStack Cloud支持利用系统标签和插件机制对原本的业务逻辑进行扩展变更。
- 使用标签机制,可对资源进行分组划分,支持对指定标签进行资源搜索。
8)瀑布流架构:支持资源的级联操作。
- ZStack Cloud使用Cascade Framework对资源管理进行瀑布状的级联操作,对资源进行卸载或者删除时,会对相关的资源进行级联操作。
- 资源也可以通过插件形式加入到瀑布框架中,加入或者退出瀑布框架,并不影响其他资源。
- 级联机制使得ZStack Cloud的配置灵活轻便,快速满足客户资源配置的变更。
9)全自动化Ansible部署:Ansible无代理自动部署。
- ZStack Cloud使用Ansible进行无代理的全自动化安装依赖、配置物理资源,部署代理程序,全过程对用户透明,无须额外干预,可透过重连代理程序对代理进行升级。
10)全API查询:任意资源的任意属性均可查询。
- ZStack Cloud支持数百万个条件的资源查询,支持全API查询,支持任意组合。
功能架构
ZStack Cloud功能架构如图1所示:
图 1. 功能架构
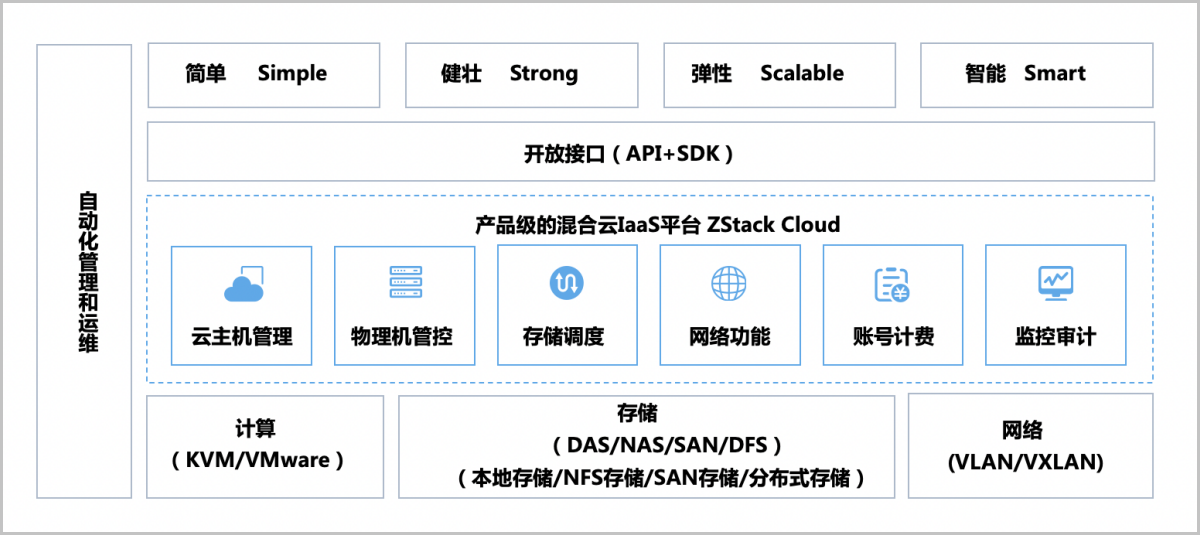
ZStack Cloud功能架构特点:
1)ZStack Cloud提供了对企业数据中心基础设施的计算、存储、网络等资源的管理,底层支持KVM和VMware虚拟化技术,支持DAS/NAS/SAN/DFS等存储类型,支持本地存储、NFS存储、SAN存储、分布式块存储,支持VLAN/VXLAN等网络模型。
2)ZStack Cloud的核心云引擎,使用消息总线同数据库MariaDB及各服务模块进行通信,提供了云主机管理、物理主机管控、存储调度、网络功能、账号计费、实时监控等功能。
3)ZStack Cloud提供了Java和Python的SDK,支持RESTful APIs进行资源调度管理。
资源结构
ZStack Cloud资源结构如图1所示:
图 1. 资源结构
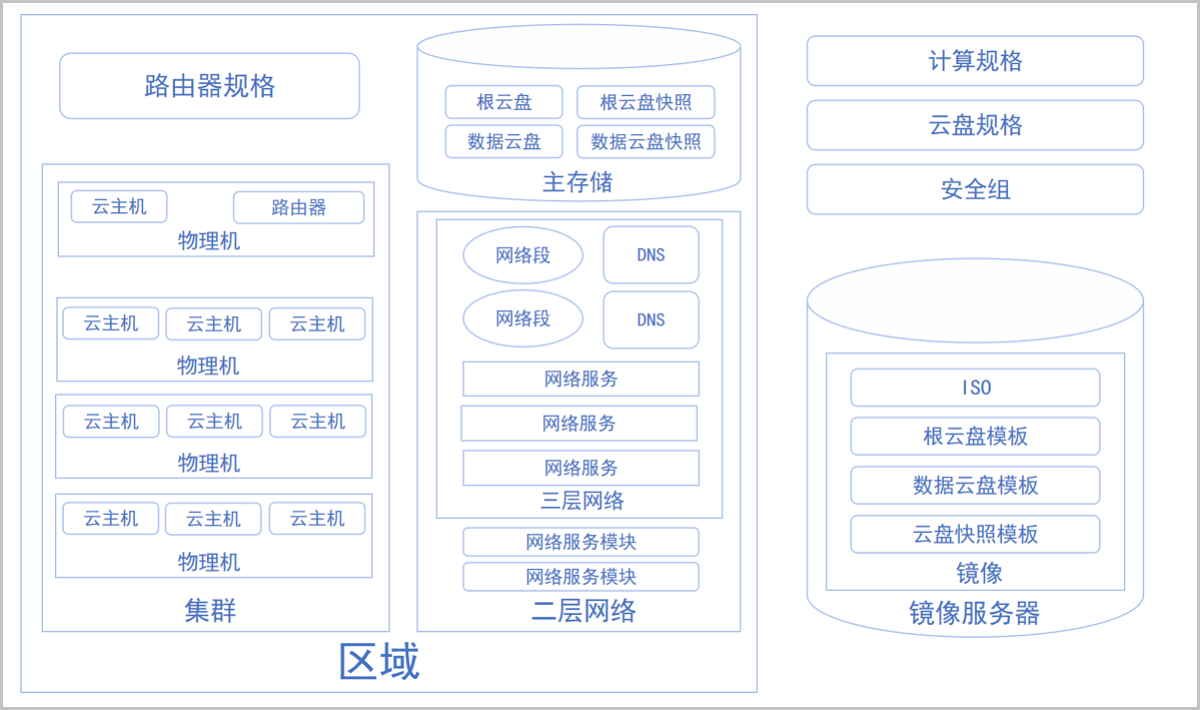
ZStack Cloud资源结构特点:
1)ZStack Cloud在本质上是云资源的配置管理系统。
2)ZStack Cloud主要包括以下资源:
2.1)区域:ZStack Cloud中最大的一个资源定义,包括集群、二层网络、主存储等资源。
2.2)集群:一组物理主机(计算节点)的逻辑集合。
2.3)物理主机:也称之为计算节点,主要为云主机实例提供计算、网络、存储等资源的物理服务器。
2.4)主存储:用于存储云主机磁盘文件(包括:根云盘、数据云盘、根云盘快照、数据云盘快照、镜像缓存等)的存储服务器。支持本地存储、NFS、Shared Mount Point、Shared Block、Ceph类型。
2.5)镜像服务器:用于保存镜像模板的存储服务器,支持镜像仓库、Sftp、Ceph类型。
2.6)VXLAN Pool:VXLAN网络中的Underlay网络,一个 VXLAN Pool可以创建多个VXLAN Overlay网络,这些Overlay网络运行在同一组Underlay网络设施上。VXLAN Pool支持软件SDN、硬件SDN两种类型。
2.7)二层网络:对应于一个二层广播域,进行二层相关的隔离。一般用物理网络的设备名称标识。支持L2NoVlanNetwork、L2VlanNetwork、VxlanNetwork、HardwareVxlanNetwork类型。
2.8)三层网络:云主机使用的网络配置,包含了IP地址范围、网关、DNS、网络服务等。
2.9)计算规格:云主机的CPU、内存、磁盘带宽或IOPS、网络带宽的数量或大小规格定义。
2.10)云盘规格:云主机使用的云盘的大小规格定义。
2.11)云主机:运行在物理主机上的虚拟机实例,具有独立的IP地址,可以访问公共网络,运行应用服务,是ZStack Cloud的核心组成部分。
2.12)镜像:云主机或云盘所使用的镜像模板文件,镜像模板包括系统云盘镜像和数据云盘镜像,其中系统云盘镜像支持ISO和Image类型, 数据云盘镜像支持Image类型。
2.13)根云盘:安装云主机操作系统的磁盘,用于支撑云主机的系统运行。
2.14)数据云盘:为云主机提供了额外的存储空间,用于云主机的存储扩展。
2.15)快照:采用增量机制对云盘在特定时间点上的数据进行备份。
2.16)网络服务模块:用于提供网络服务的模块。在UI界面已隐藏。
2.17)网络服务:给云主机提供的各种网络服务,主要包括VPC防火墙、安全组、虚拟IP、弹性IP、端口转发、负载均衡、IPsec隧道、流量监控等。
2.18)VPC防火墙:负责管控VPC网络的南北向流量,通过配置规则集和规则来管控网络的访问控制策略。
2.19)安全组:给云主机提供三层网络防火墙控制,控制TCP/UDP/ICMP等数据包进行有效过滤,对指定网络的指定云主机按照指定的安全规则进行有效控制。
2.20)路由器规格:定义路由器使用的CPU、内存、路由器镜像、管理网络、公有网络等。
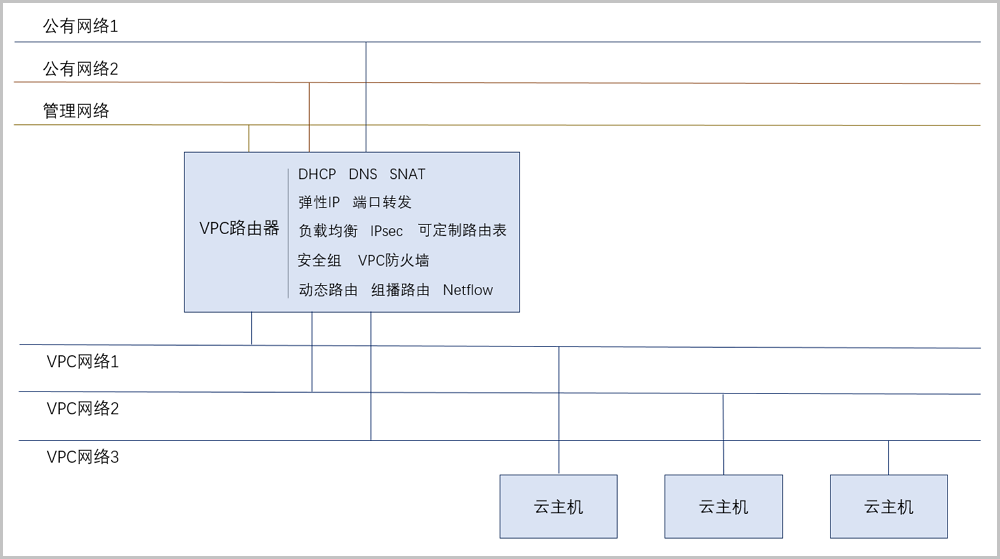
2.21)VPC路由器:基于路由器规格直接创建的路由器,拥有公有网络和管理网络,是VPC的核心。提供各种网络服务,包括:DHCP、DNS、SNAT、路由表、弹性IP、端口转发、负载均衡、IPsec隧道、动态路由、组播路由、VPC防火墙、Netflow等。
3)ZStack Cloud资源间存在以下关系:
3.1)父子关系:一个资源可以是另一个资源的父亲或孩子。例如集群和物理主机,物理主机和云主机。
3.2)兄弟关系:拥有同样父资源的资源为兄弟关系。例如集群和二层网络,集群和主存储。
3.3)祖先和后裔关系:一个资源可以是另一个资源的直系祖先或者直系后裔。例如集群和云主机,区域和物理主机。
3.4)朋友关系:一些资源与资源之间没有以上三种关系,但是这些资源在某些情境下需要分工合作,这时它们是朋友关系。例如主存储和镜像服务器,区域和镜像服务器。
说明: 主存储和镜像服务器的关系为:
- 创建VM时,主存储会从镜像服务器下载复制云主机的镜像模板文件作为缓存。
- 创建镜像时,主存储会将根云盘拷贝到镜像服务器保存为模板。
4)ZStack Cloud资源均含有以下基本属性:
4.1)UUID:通用唯一识别码UUIDv4(Universally Unique Identifier)来唯一标识一个资源。
4.2)名称:用于标记资源的可读字符串,名称可以重复,一般为必选项。
4.3)描述:也称之为简介,用于概述资源,可选项。
4.4)创建日期:资源创建的日期。
4.5)上次操作日期:资源上次被更新的时间。
5)ZStack Cloud资源一般都支持CRUD操作:
5.1)创建:创建或者添加新的资源。
5.2)查询:读取查询资源信息。
5.3)更新:更新资源信息。
5.4)删除:删除资源,ZStack Cloud使用的瀑布框架级联机制,使得父资源被删除后,相关子资源和后裔资源均会被删除。
核心设计
资源虚拟化
计算虚拟化
概述
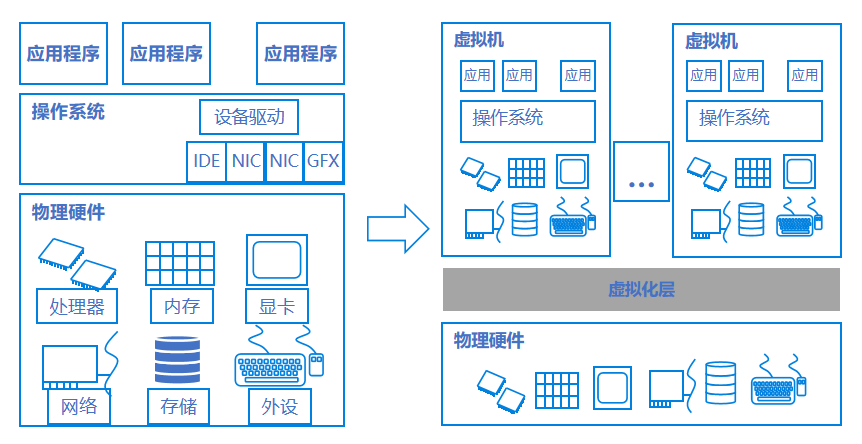
计算虚拟化是将物理服务器资源通过虚拟化技术抽象成逻辑资源,让一台物理服务器变成多台相互隔离的虚拟服务器,CPU、内存、磁盘、I/O设备等硬件资源变成虚拟化资源池进行统一动态管理,从而提高资源利用率,降低系统管理成本,让IT对业务变化更具适应力。
如图1所示:
图 1. 服务器虚拟化
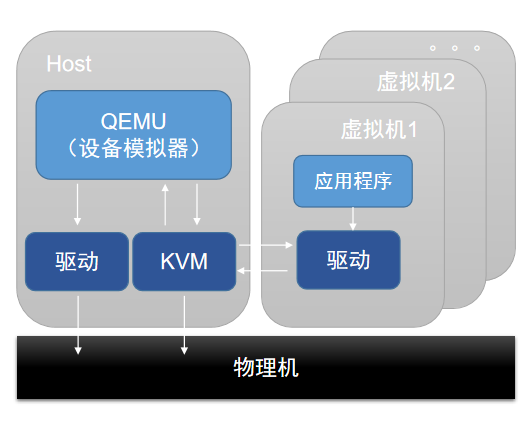
云平台支持采用基于KVM的硬件虚拟化技术。KVM是一个Linux内核模块,将Linux内核变成一个Hypervisor。KVM在Linux系统内以进程形式出现,由标准Linux调度程序进行调度,因此KVM能够使用Linux内核已有功能,例如:内存管理、CPU调度等。但是,KVM本身仅提供CPU与内存虚拟化,I/O设备虚拟化需要结合Qemu才能完成。Qemu是一个用户态的设备模拟器,为云主机提供虚拟设备模型,负责各种虚拟设备的创建、调用及管理。
如图2所示:
图 2. KVM虚拟化技术
技术特性
CPU虚拟化
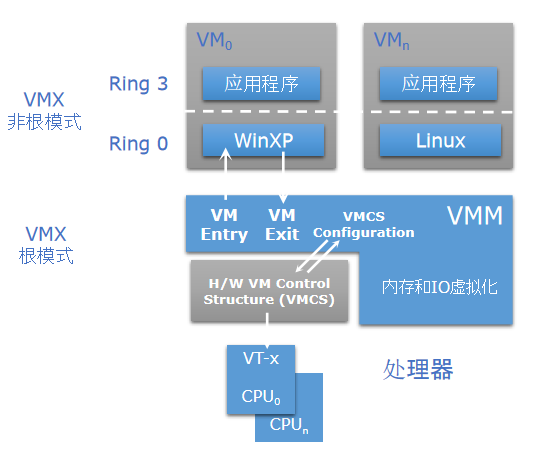
在x86体系架构上,CPU一般有4个特权级别:ring0~ring3,用于给操作系统和应用程序访问硬件。在Linux中,仅使用其中2个特权级别:ring0(内核态)、ring3(用户态)。
vmx虚拟化技术是一种基于硬件的虚拟化技术,由Intel所推出。它的全名是Virtual Machine Extensions,意味着虚拟机扩展。该技术旨在提供更高的性能和更好的虚拟化体验。
VMX根模式与VMX非根模式。对于硬件辅助虚拟化而言,为能在不对操作系统做任何修改的前提下使用云主机,CPU引入2种运行模式:VMX根模式、VMX非根模式。宿主机运行在根模式下,宿主机内核处于ring0,用户态程序处于ring3。云主机运行在非根模式下,云主机内核处于ring0,用户态程序处于ring3。
VM Exit与VM Entry。处于非根模式的云主机,当外部中断或缺页异常,或主动调用VMCALL指令来调用VMM服务时,CPU会从非根模式切换至根模式,整个过程称为VM Exit。相反,当VMM通过显式调用VMLAUNCH或VMRESUME指令切换至非根模式时,硬件自动加载云主机上下文,运行云主机指令,这一转换称为VM Entry。
如图1所示:
图 1. 非根模式与根模式
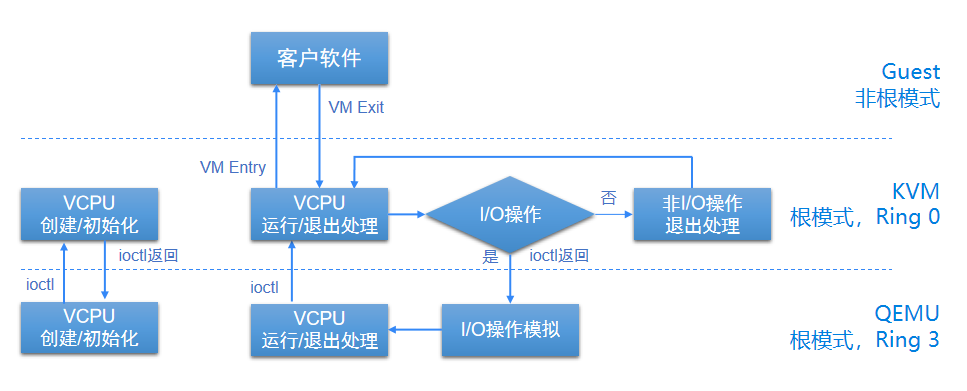
当云主机通过VM Exit从非根模式退出至根模式后,KVM会根据退出原因执行进一步操作,若是I/O操作则交由Qemu处理,若是非I/O操作则由KVM自行处理,处理完成后会通过VM Entry再次切回至云主机非根模式下运行。
如图 2所示:
图 2. 模式切换
内存虚拟化
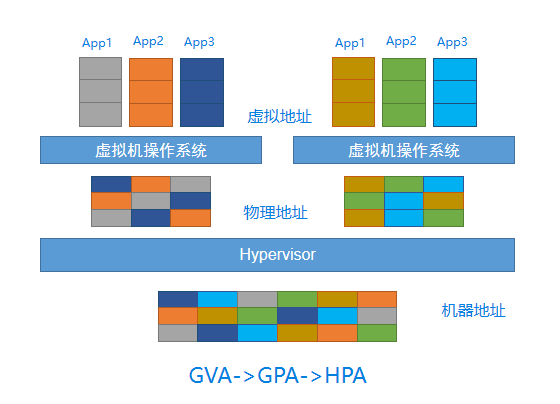
VMM负责管理和分配每个云主机的物理内存。云主机操作系统看到的是一个虚构的云主机物理地址空间,操作系统的内存管理模块负责将云主机虚拟地址(GVA)映射到云主机物理地址(GPA),其指令目标地址也是一个云主机物理地址。这样的地址在无虚拟化情况下,其实是实际物理地址。但在有虚拟化情况下,这样的地址不能被直接处理使用,需VMM先将云主机物理地址转换成一个物理机物理地址(HPA),再交由物理处理器执行。
由于引入云主机物理地址空间,内存虚拟化主要处理以下两方面问题:
- 维护云主机物理地址到宿主机物理地址之间的映射关系。
- 当云主机访问云主机物理地址时,根据映射关系,将其转换成宿主机物理地址。
如图 1所示:
图 1. GVA->GPA->HPA
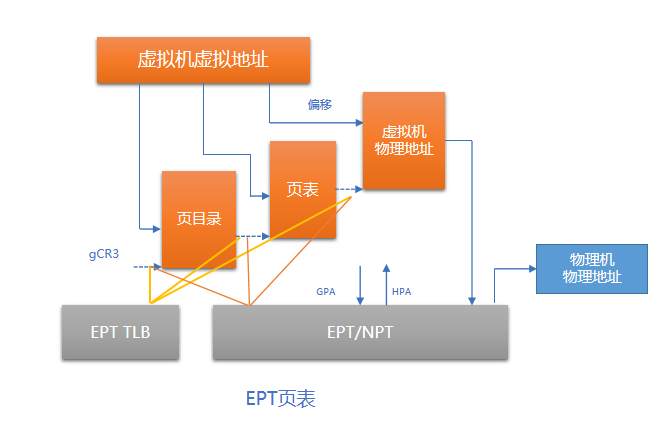
内存的硬件辅助虚拟化使用扩展页表技术,通过硬件完成云主机虚拟地址到物理机物理地址的转换。
如图 2所示:
图 2. EPT页表
设备虚拟化
设备虚拟化方式主要有三种:设备模拟、半虚拟化设备、设备直通。
设备模拟
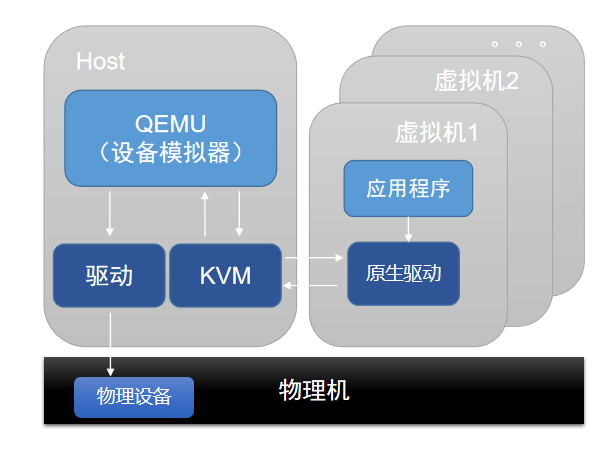
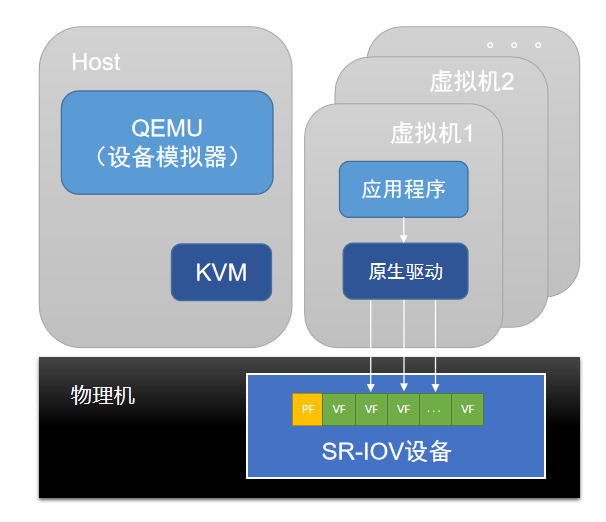
设备模拟是通过Qemu提供的设备模型,可完全模拟出与物理设备一样的接口。因此,在云主机操作系统中,使用原生驱动即可使用设备。设备模拟只能模拟出具有基本功能的设备,不支持复杂功能和模型的设备。完全模拟的设备兼容性好,但由于是纯软件模拟,性能相对较低。
如图 1所示:
图 1. 设备模拟
半虚拟化设备
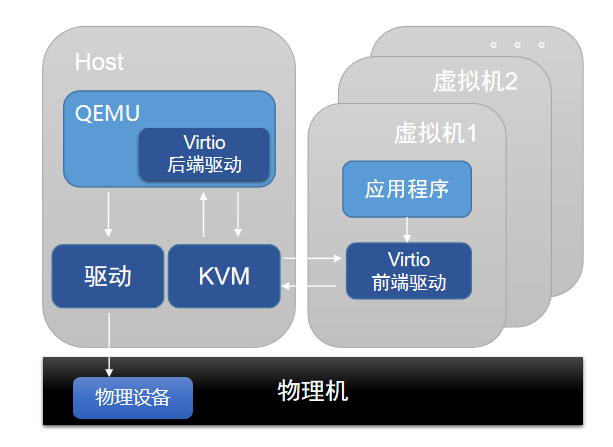
半虚拟化设备实现前后端驱动。利用云主机中的前端驱动,通过基于事务的通信机制,将请求直接发给宿主机端的后端驱动,从而很大程度上减少上下文切换的开销,性能相比完全设备模拟有较大提升。然而,Virtio后端驱动仍在Qemu中实现,在IO处理过程中会经过用户态与内核态之间的多次切换。为进一步提升性能,可将Virtio后端驱动的功能放至内核态实现,称为vhost-kernel后端,于是数据仅需经过从用户态到内核态的一次切换,就可完成数据传输,实现性能提升。
随着技术发展,将数据放入用户态处理可得到更灵活的形式。因此,在原有vhost架构中进行改动,增加vhost-user后端,搭配DPDK、SPDK中相关用户态函数库,性能进一步提升。
如图 2所示:
图 2. 半虚拟化设备
设备直通
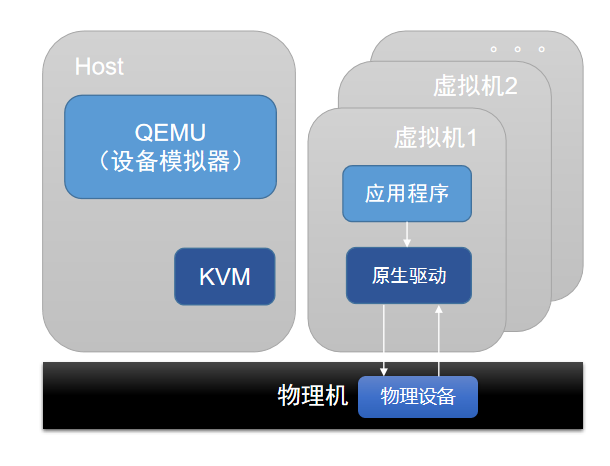
设备透传基于硬件的设备虚拟化技术,支持将PCI/PCIe物理设备直接映射到云主机的地址空间,在云主机中,使用原生设备驱动就可直接使用设备,达到近乎物理设备的性能。物理设备被透传后被云主机独享,其它云主机无法共享使用该设备。
如图 3所示:
图 3. 设备透传
SR-IOV是由PCI-SIG组织定义的PCIe规范的扩展规范,目的是通过提供一种标准规范,为云主机提供独立的内存空间、中断、DMA数据流。 SR-IOV支持单个物理PCIe设备(PF)虚拟出多个虚拟PCIe设备(VF),然后通过设备透传技术将虚拟PCIe设备直通到各云主机,以实现单个物理PCIe设备支撑多云主机的应用场景。
如图 4所示:
图 4. SR-IOV
存储虚拟化
概述
存储虚拟化是将服务器存储资源池化,实现服务器存储资源的统一整合、管理及调度,并向上层提供多种存储接口,供业务云主机根据自身的存储需求灵活分配使用资源池中的存储空间。云平台支持对接集中式存储和分布式存储。
技术特性
集中式存储
集中式存储是指将数据存储在一台或多台服务器组成的中心节点上。集中式存储所有业务均集中部署在中心节点,中心节点统一管理各分部节点数据,按需分配,数据访问仅需经过一个控制器即可实现。集中式存储分为DAS、NAS、SAN三类,可根据不同数据存储需求选择不同存储类型。
集中式存储功能优势:
- 高性能与高可靠性:集中式存储将数据存储在一台或多台服务器组成的中心节点上,有效避免数据分散风险,提高存储系统的性能与可靠性。
- 可扩展性:集中式存储可通过网络扩展来存储更多数据,存储系统可适应业务规模增长而扩展。
- 安全性:集中式存储可通过访问控制和数据加密等安全措施保护数据的安全和完整性。
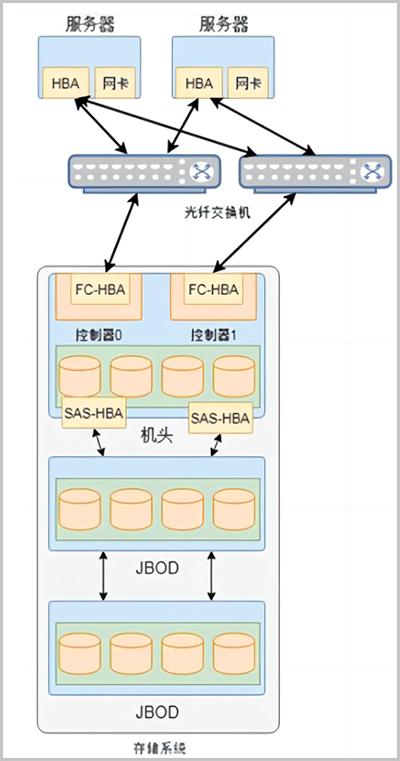
关于集中式存储架构的说明。在集中式存储架构中,机头是最核心部件。通常机头包含两个控制器,互为备用, 避免硬件故障导致整个存储系统不可用。此外,机头包含前端端口和后端端口,前端端口用于为服务器提供存储服务,后端端口用于扩充存储系统容量。通过后端端口,机头可连接更多存储设备,从而形成一个庞大的存储资源池。
如图 1所示:
图 1. 集中式存储架构
Shared Block
云平台支持对接多种集中式存储。这里主要介绍通过Shared Block主存储连接方式对接SAN存储。该方式可将用户在SAN存储上划分的LUN设备直接作为存储池,再提供给业务云主机使用。与云平台提供的另一种基于文件系统的主存储类型Shared Mount Point(SMP)不同,Shared Block具备便捷部署、灵活扩展、性能优异等优势。据实测数据显示,Shared Block可完全发挥物理磁盘的性能。目前Shared Block支持iSCSI、FC、NVMe-oF共享访问协议。
Shared Block工作原理:
- 块级访问:Shared Block可将数据分成块,每个块都有唯一的标识符。服务器通过这些标识符来读取或写入特定的数据块。
- 并行访问:多个节点可同时访问Shared Block中的不同块,从而实现并行读写操作。
- 共享性:Shared Block可被多个节点共享,使得它们可以同时访问相同的数据块。这对于分布式系统中需要共享数据的场景非常重要。
- 容错性:Shared Block通常会提供数据冗余和故障恢复机制,以确保数据的安全性和可靠性。
- 扩展性:Shared Block可通过添加更多存储节点来扩展容量和性能。
- 性能优化:Shared Block通常会采取各种技术来优化性能,例如缓存、负载均衡等。
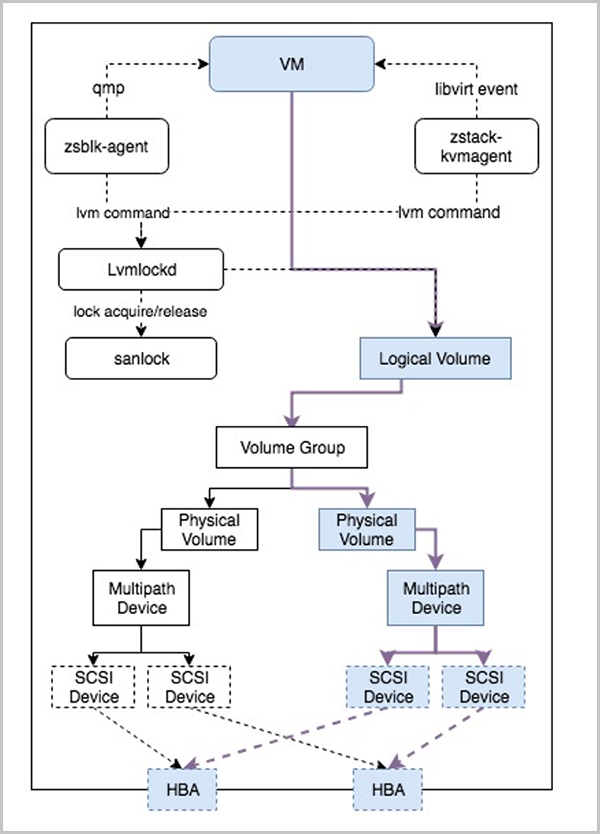
关于Shared Block架构的说明。在集中式存储上映射一个卷到物理机上,根据存储控制器的连接方式,在物理机上Multipath服务会自动把多个具有相同WWID的SCSI设备聚合成多路径块设备。云平台会去检测集群内所有物理机上拥有相同WWID的多路径设备,然后针对用户选定的卷创建出集群内的共享VG。云平台基于VG创建LV,LV实际上对应了云平台中的云盘、快照等资源。同时为了维护存储集群的一致性,云平台也提供了共享存储锁管理机制,用于维护存储心跳、节点管理、元数据管理等功能。
如图 2所示:
图 2. 共享块存储架构
Sanlock + Lvmlockd
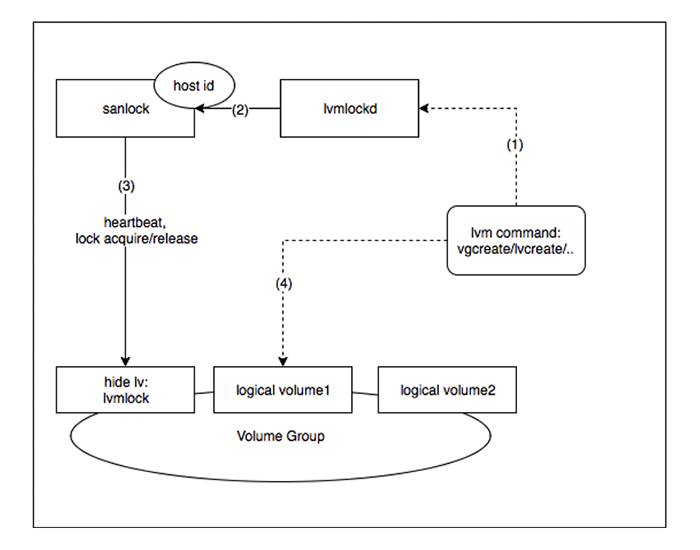
Sanlock(Shared storage lock manager),共享存储锁管理机制。实际上,它是基于Lamport的几个算法:Delta Paxos、Disk Paxos,而形成的一套租约管理机制,并且在这几个租约管理机制上实现了集群成员管理、心跳维护、仲裁和信息传递,下一步就是将这里的租约机制转换为能让LVM使用的锁,那就是Lvmlockd。
引入Sanlock + Lvmlockd后,服务器执行的大部分LVM命令,均会先将请求送到Lvmlockd。Lvmlockd会将LVM的操作翻译为Sanlock所能识别的锁操作。
针对不同资源的操作需要获取不同的锁权限,只有在获得锁权限后,才能对相应资源执行操作,这样就能确保元数据和数据的安全性。此外,整个过程无需任何中间节点协调或集中操作,是一个全分布的架构。
如图 3所示:
图 3. Sanlock + Lvmlockd
分布式存储
云平台支持对接多种分布式存储。这里主要介绍自研分布式存储。该存储支持丰富的资源管理功能,包括对服务器、硬盘、数据盘、块存储卷、存储池、存储桶等多种资源的管理。用户可通过这些功能实现拥有不同数据冗余类型的存储池、指定存储策略和访问权限的存储桶,从而快速、低成本地构建简单、稳定、安全高效的存储基础设施。
自研分布式存储功能优势:
1)弹性伸缩:支持横向扩展存储资源。在互联网+的大背景下,新兴业务蓬勃发展,数据呈现几何倍数增加,传统集中式存储应对大规模数据增长面临严峻挑战。分布式存储可通过简单添加节点来增加整个存储集群的容量和处理能力。
2)高可用性:支持多种数据冗余策略,包括副本、EC纠删码等。副本策略支持在线调整存储池副本数,将数据在多个节点上进行复制,当某个或某几个节点出现故障时,数据仍可从其他节点上获取,从而保障存储集群的可用性。结合灵活的故障域策略,即使在面临硬件故障、网络中断等不可预见的情况时,也能保证存储服务的正常运行。
3)性能优化:通过自研缓存加速技术优化数据处理性能。通过企业级NVMe SSD、SATA SSD对后端HDD设备进行读写加速,有效较低延迟,提高存储集群的I/O性能。此外,支持通过负载均衡技术将存储I/O负载均匀地分配到各个节点,确保系统资源的充分利用。
4)易于管理:提供统一便捷的管理界面和标准的RESTful API接口,帮助管理员轻松进行物理资源基本生命周期管理和维护,以及数据的运维和恢复等操作。
5)成本效益高:支持基于通用硬件部署,大大降低硬件成本。另外,由于其弹性伸缩的特性,用户可以根据业务需求动态调整存储资源,避免资源浪费,进一步降低产品使用成本。
关于自研分布式存储架构的说明。
1)硬件设备层:支持标准x86服务器、信创服务器作为底层硬件平台,同时支持利旧共池,保护既有IT资产。
2)平台层:通过故障域算法解决存储服务中的一致性哈希问题。简单而言,故障域算法在原来的哈希算法之上增加了物理部署逻辑和集群状态参数,使得在发生集群数据迁移变化时,根据物理部署情况最小化数据迁移量。比如根据输入的物理逻辑拓扑,故障域算法可以选择性地进行服务器内部迁移,或者在同一个机架/核心交换机内迁移,明显减小迁移造成的资源损耗。同时根据集群状态进行数据分布,能够充分兼容不同的存储设备。
3)数据层:采用自研缓存技术,支持使用企业级NVMe SSD、SATA SSD对后端HDD设备进行读写缓存,将高频访问的热数据存储在高速SSD设备,将冷数据通过智能刷盘策略动态调整到低速HDD设备。既提升了存储集群的整体性能,又为上层业务提供了海量存储空间。
4)接口层:支持通过RBD接口,向操作系统、云平台、数据库提供虚拟卷设备。
5)业务层:支持对接业务云平台,提供云基座。
如图 1所示:
图 1. 自研分布式存储架构
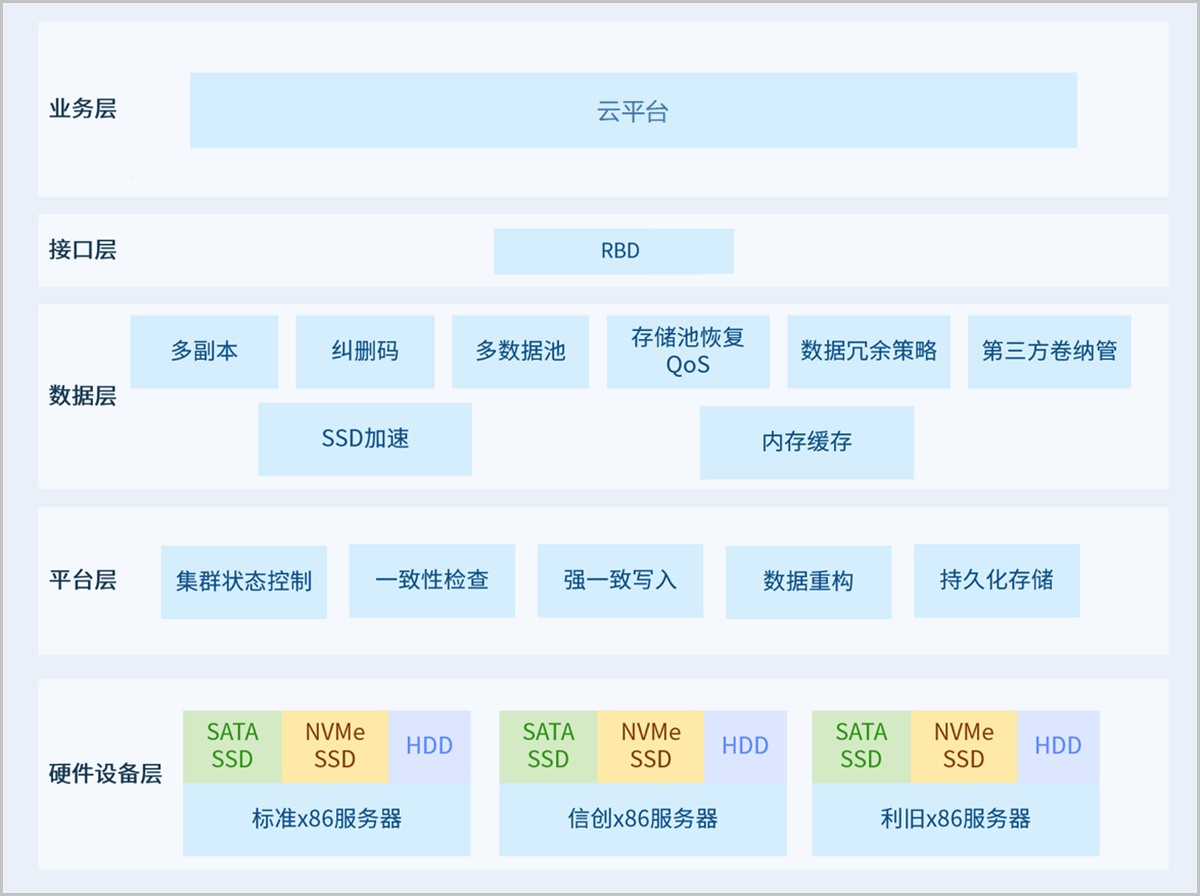
数据存储
缓存加速方案
缓存加速方案一般是指使用SSD类的缓存设备,为数据盘的核心设备HDD进行加速的方案。通过自研缓存加速技术,在优化数据处理性能、提供加速能力的同时,有着较低的资源消耗。
缓存加速方案具有以下特性:
1)低资源消耗:
- 内存:RAM要求大约为1GiB+(2%×4KiB/+0.05%)×缓存设备容量。例如,当使用4KiB(默认)缓存线大小时,RAM要求约为1GiB+2.05%×缓存设备容量。
- CPU:大多数情况下低于10%。
2)自动分区映射:
支持自动隐藏操作系统中现有的核心装备分区,如/dev/sdc1等,提高平台兼容性。
3)多级缓存:
支持将热数据从慢速的HDD设备缓存到更快的SSD设备,然后将热数据从SSD缓存到更快的RAMdisk。在这种情况下,DRAM的固定部分被分配用于缓冲,而SSD将保留为完整的缓存数据,因此DRAM数据将始终在SSD上可用。
4)支持Trim:
允许操作系统通知缓存哪些块数据不再被考虑使用,可以在内部擦除数据,并释放与该数据关联的缓存行,节省了数据刷新到后端存储所需的时间。
5)支持I/O分类:
支持基于分类粒度控制数据缓存,可动态分析每个I/O,同时确定目标文件大小。支持根据不同工作负载,匹配最佳I/O配置。
6)多缓存刷新策略:
支持3种缓存刷新策略,包括ACP (Active Cleaning Policy)、ALRU (Approximate LRU)、NOP。
自动精简配置
在数据写入逻辑卷之前,即可为上层应用程序提供比实际物理存储设备更多的虚拟存储空间,具有方便的可伸缩性,可有效利用存储空间。
存储池恢复QoS
QoS (Quality of Service) 是用于解决I/O资源分配问题的一种技术,可以用来帮助用户对I/O读写进行限速,帮助实现资源的合理分配。
在数据节点中,存在op_shardedwq队列处理各种来自上级的I/O,并且这是一个复合队列,通常包含若干子队列。I/O请求从队列出列后,通过ObjectStore接口与磁盘交互。I/O类型主要包括两大类,一类是来自客户端的业务读写I/O请求,一类是存储系统内部活动产生的I/O,包括数据节点之间的I/O请求,SnapTrim,Scrub和Recovery等。
自研分布式存储采用基于权重的优先级队列 (wpq),按照上述的I/O分类,分别存入子队列,每个prior队列在其第一个请求入队时被创建。出队时,采用权重概率的方式确定prior级别,每个队列的优先级prior作为其权重,该prior队列被选中的概率即为其权重占总权重的比例。被选中的prior队列也并不一定能出队请求,还需要根据将要出队的请求大小来确定。
支持设置存储池恢复QoS,根据用户不同业务类型提供不同恢复策略,包括:
- 低速恢复:低速恢复优先保证业务带宽,恢复所需时间较长。恢复过程中如再次出现硬件故障可能会降低数据安全级别。生产环境下建议选择低速恢复。
- 中速恢复:中速恢复保证业务带宽和恢复带宽同等优先级,恢复所需时间中等,性能饱和情况下可能会增加I/O延时。
- 高速恢复:高速恢复优先保证恢复带宽,恢复所需时间较短,性能饱和情况下可能会影响业务性能。
COW快照
自研分布式存储采用COW (Copy-On-Write) 快照技术。当启动COW快照后,系统会创建和源卷对应的快照空间,在创建COW快照后,系统会跟踪源卷的数据变化,一旦源卷数据块发生写入操作,则先将源卷数据读出并写入快照卷,然后用新数据覆盖原始数据。
COW快照原理
假设一个卷包含6个数据切片,编号分别为1~6,在某一时间点对该卷进行快照操作,生成新的快照卷。快照卷也有6个数据块,且和源卷一样指向相同的数据块物理空间。
生成快照后,有新的I/O要写入源卷,假设I/O落在源卷的第6个数据块上,这时会修改源卷的第6个物理块空间,对于COW而言,其修改步骤会进行如下几个操作:
- 首先会分配一个新的物理块,编号为7。
- 读取编号为6的物理块中的数据。
- 将读出的编号6的物理块数据写入到新分配的编号7的物理块中。
- 更新快照卷map信息,指向编号7的物理块空间。
- 更新源卷的编号6的物理块空间内的数据。
该流程过后的效果为源卷维持原状,数据仍存储在编号为1、2、3、4、5、6的物理块之中,快照卷数据存储位置则发生了变化,数据存储在编号为1、2、3、4、5、7的物理块之中,如图 1所示:
图 1. COW快照示意图

数据保护
数据冗余技术
概述
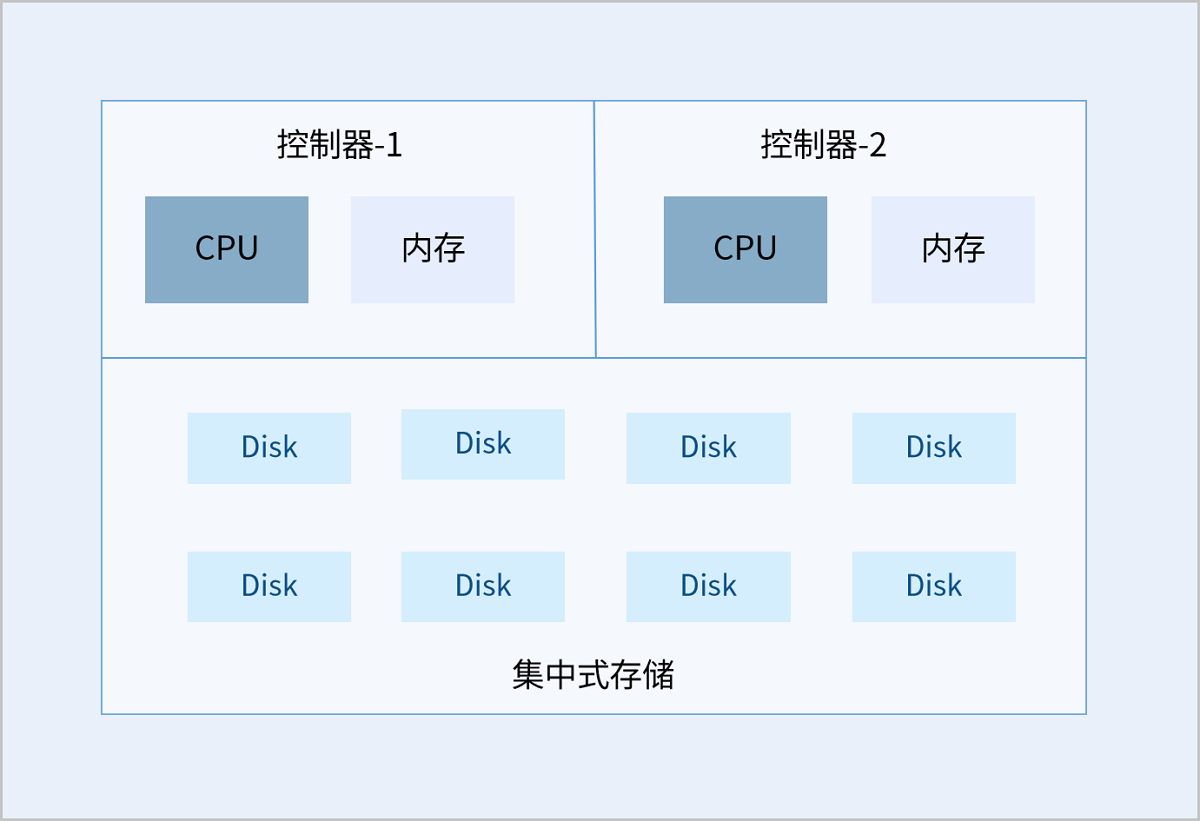
传统集中式存储使用控制器和硬盘柜来提供数据管理和读写能力,通常采用双控制器进行冗余,也有高端存储使用多控制器。存储空间可以通过控制器自带的硬盘槽位或外接扩展硬盘柜提供。传统集中式存储通常使用Raid技术,比如RAID5、RAID6、RAID10等,来保护数据。
如图 1所示:
图 1. 集中式存储示意图
自研分布式存储采用无中心的组网方式,每个存储节点都可以提供计算和存储资源,以实现更灵活的扩展性和更大的存储规模。存储节点通过通用以太网交换机互联起来,并基于分布式存储软件向上层业务提供统一的存储资源池。此外,分布式存储支持横向扩展,单集群可扩展到上千节点提供EB级别容量,适合海量数据的存储场景。
如图 2所示:
图 2. 分布式存储示意图

传统的硬盘级RAID模式将数据存放于单个节点内的不同硬盘,当整个节点发生故障时,无法有效恢复数据。为了避免数据丢失,存储系统需要将数据在节点间进行冗余保护。与传统集中式存储不同,分布式存储软件的数据冗余技术多采用多副本和纠删码技术。主要区别如下:
1)分布式存储的数据冗余技术是跨节点的,例如3副本允许2个节点同时故障而不丢失数据。RAID技术一般由单节点内的若干块容量一致的磁盘组成RAID组,只能容忍磁盘故障,不能容忍节点故障。
2)分布式存储的数据冗余技术采用全局热备的方式,不需要单独的热备盘,所有硬盘都可参与数据读写与数据重构,只要系统中有剩余空间,就可以恢复故障数据。RAID技术一般单节点至少需要准备一块热备盘以应对硬盘故障。
3)当出现硬盘故障时,分布式存储会有多块盘参与数据恢复。RAID模式只有1块热备盘能够写数据。因此分布式存储的数据恢复效率是RAID模式的几十倍,大大减少了数据恢复期间硬盘再次故障的可能性,进一步提升系统安全性。
4)分布式存储不需要额外的硬件支持,RAID模式需要独立的RAID卡。
副本
副本是一种数据保护技术,通过在不同的节点上复制相同的数据来实现数据冗余和高可用性。当一个节点发生故障时,可以使用其他节点上的副本来恢复数据。支持用户设置2~6副本,在生产环境中推荐使用3副本。
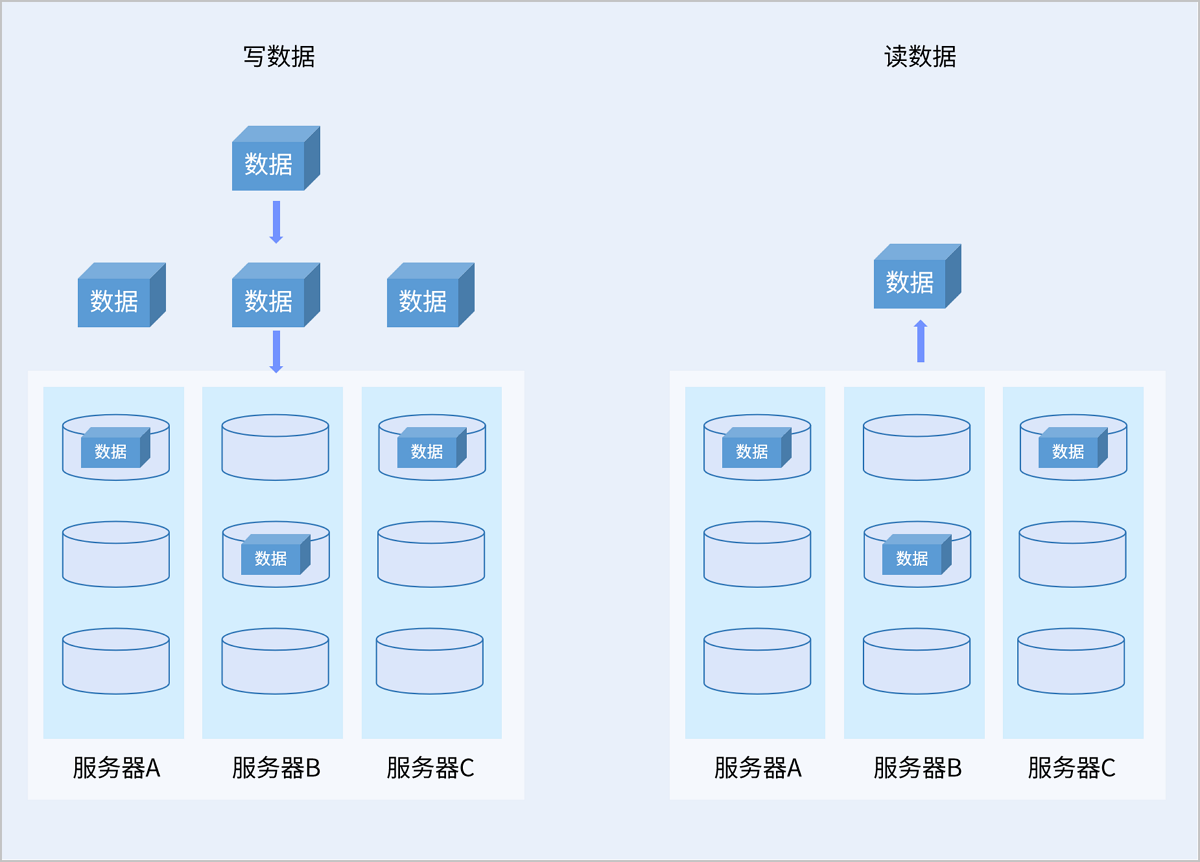
1)正常场景读写
以服务器级别的3副本冗余策略为例,写入数据时,将被系统拷贝成3份相同的副本,分别存储于三台不同的服务器上的数据盘中。读取数据时,系统将从任意一台服务器上读取数据并返回给用户。
如图 3所示:
图 3. 三副本正常读写示意图
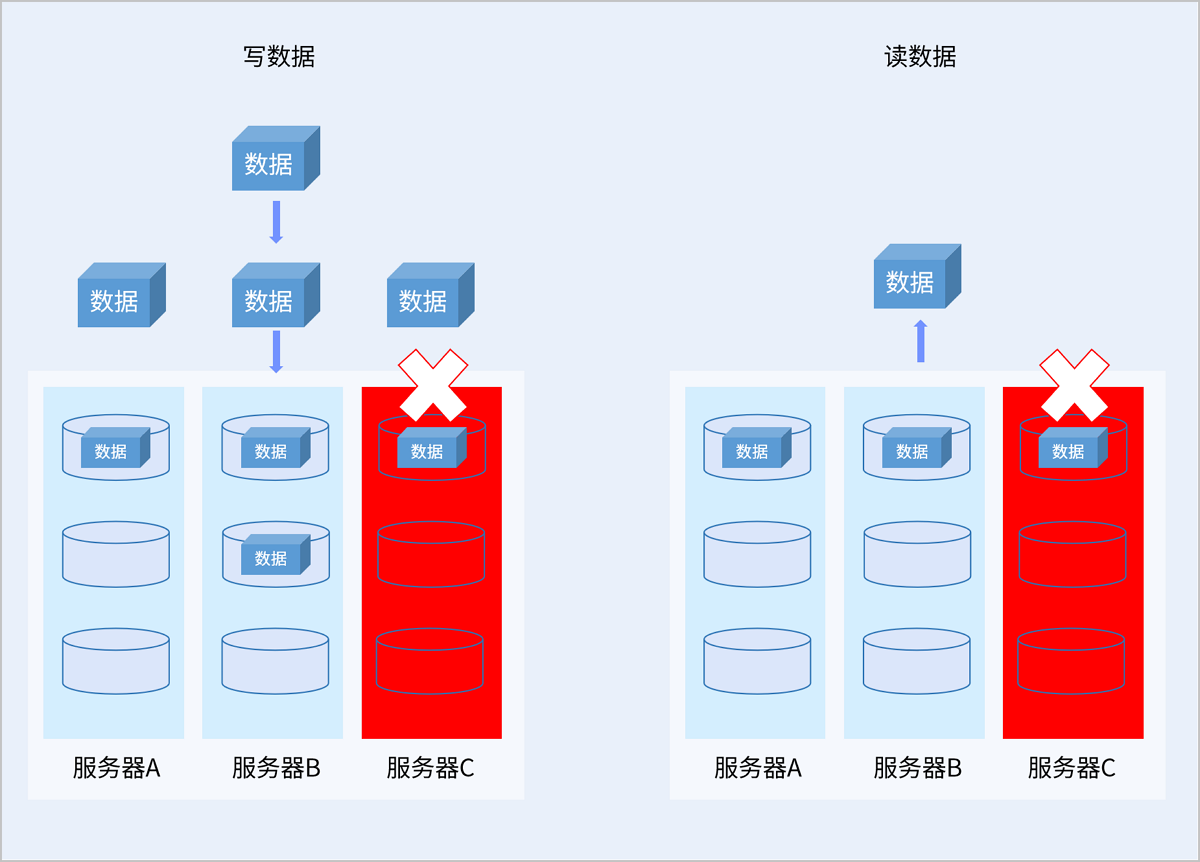
2)故障场景读写
以服务器级别的3副本冗余策略为例,当服务器C故障后,系统将在剩余的2台服务器中存储副本。读取数据时,当服务器C故障后,系统将在剩余2台服务器中读取1个副本返回给用户。
如图 4所示:
图 4. 三副本故障读写示意图
纠删码
纠删码 (Erasure Coding,简称EC) 是一种数据保护技术,通过将数据切分为K个数据块,并通过校验算法生成M个校验块,以实现数据的纠错和恢复。与传统的副本技术相比,纠删码可以在保证数据可靠性的同时,节约存储空间和网络带宽。提供三种EC推荐配置:2+1、4+2、8+3,并支持用户自定义EC策略。综合考虑可靠性和性能,推荐用户使用4+2的EC策略。
1)正常场景读写
以服务器级别的4+2 EC策略为例,写入数据时,系统将数据切分为4个相同大小的数据分片,同时通过校验算法生成2个同样大小的校验分片,系统将这6个数据分片随机存入6台服务器中。当任意2台服务器发生故障时,数据仍可正常使用。读取数据时,系统从4台服务器上的不同数据盘中读取数据块,将4个数据块拼装成完整数据后返回给用户。
图 5. EC写数据示意图
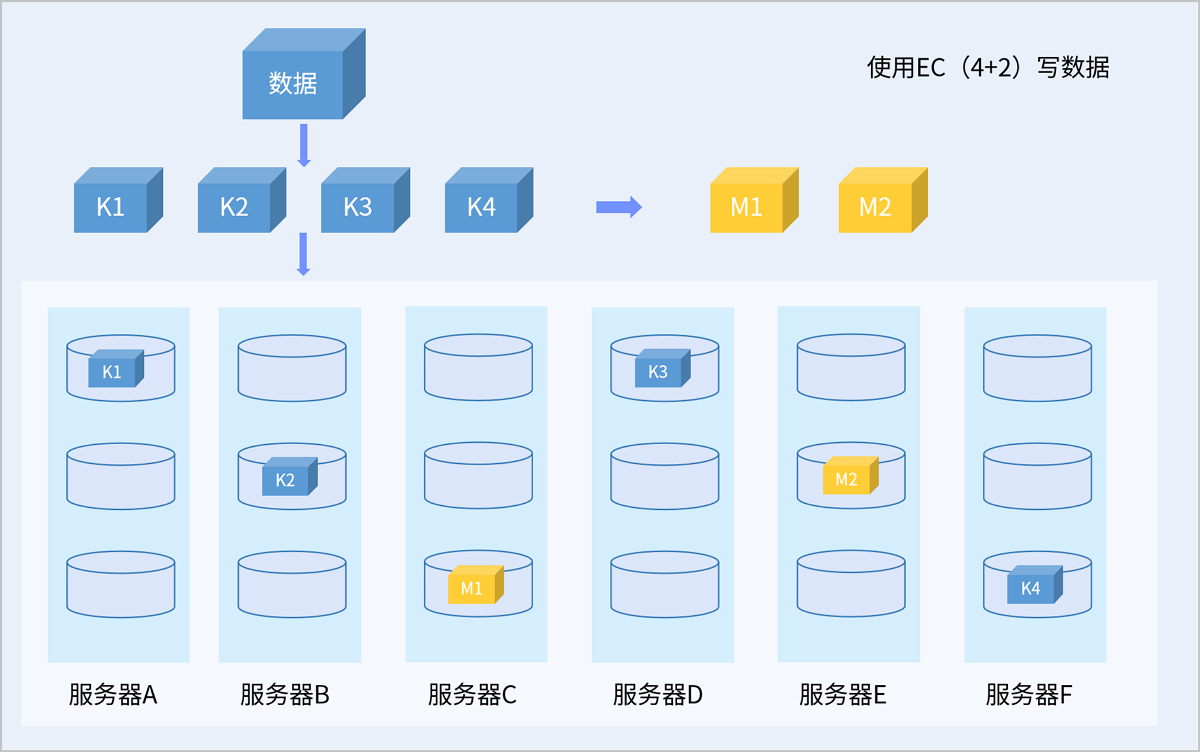
图 6. EC读数据示意图
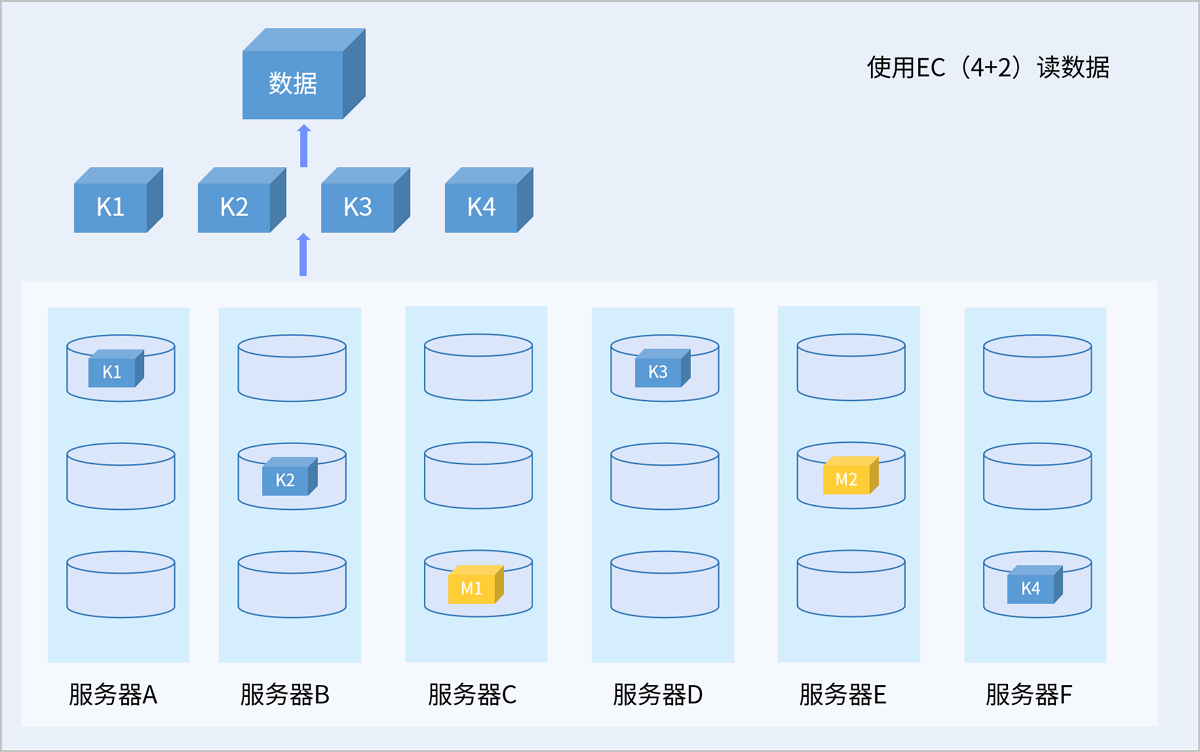
2)故障场景读写
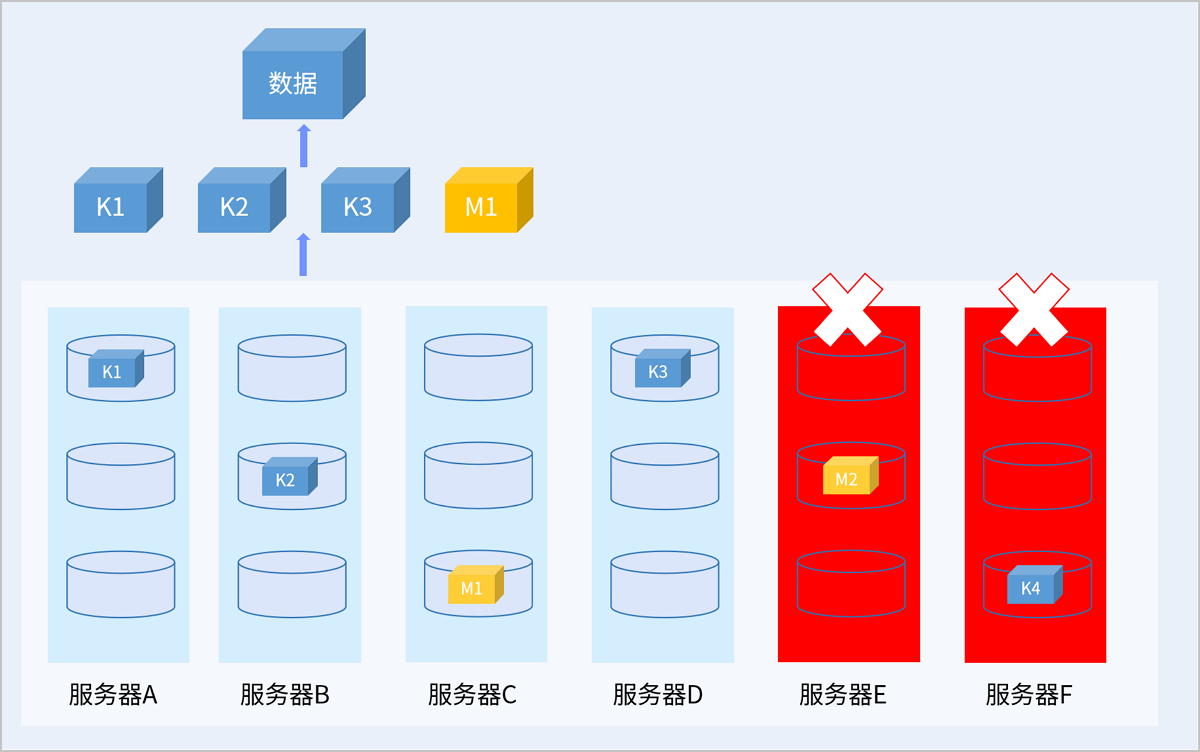
以服务器级别的4+2 EC策略为例,当故障后的剩余服务器数量小于K+M时,在故障恢复前系统会将新写入的数据存放在剩余的服务器上,保证I/O不中断的同时,可靠性级别也不降低,待故障恢复后,数据冗余策略重新恢复为K+M。读取数据时,系统会从其它正常节点读取数据,通过校验算法恢复数据返回给用户。
图 7. 故障场景EC写数据示意图
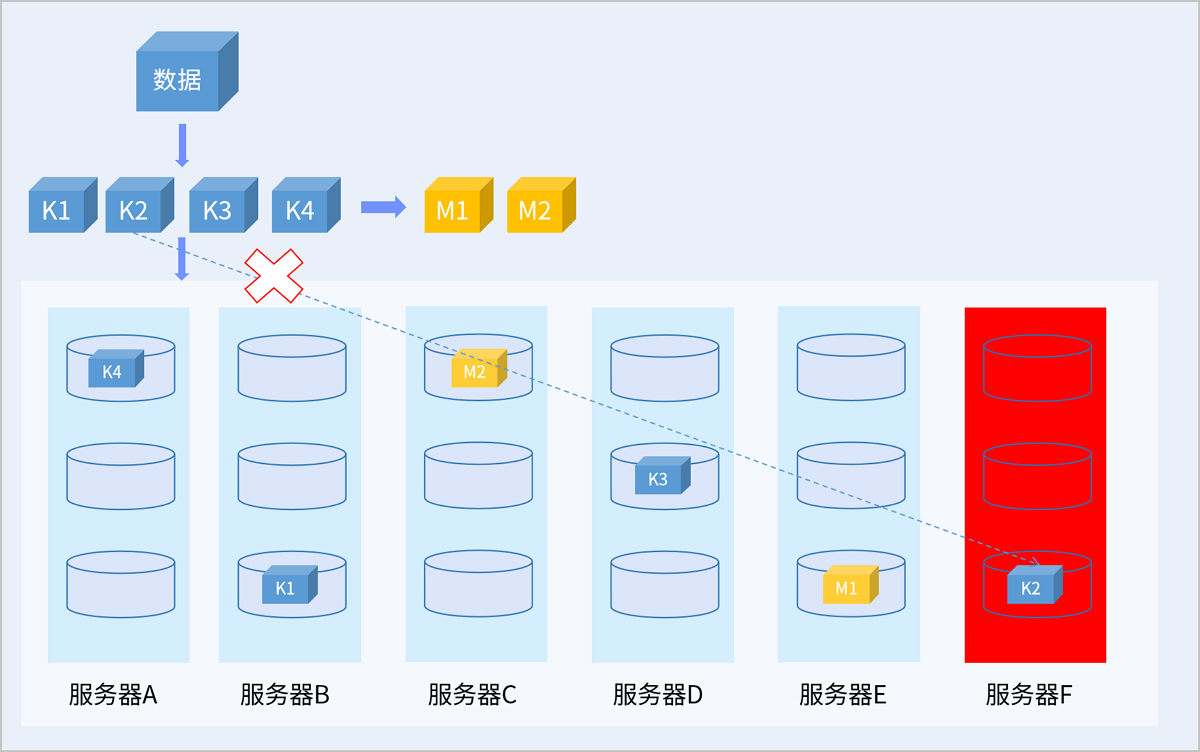
图 8. 故障场景EC读数据示意图
3)EC策略配置表
| EC策略 | 得盘率 |
|---|---|
| 2+1 | 66.67% |
| 4+2 | 66.67% |
| 8+3 | 72.73% |
| 自定义 | K/(K+M) 说明: K指数据的分片数量,即数据块数量;M指校验数据分片的数量,即校验块数量。 |
副本和纠删码对比
用户可根据实际业务需求选择副本或纠删码,二者在不同场景中有各自的优势:
1)空间利用率:
纠删码的优势较大,以4+2的EC策略为例,其得盘率约为66%,而3副本的空间利用率仅为33.3%。
2)读写性能:
副本和纠删码的读写性能在小块读写场景下有较大差异,在大块场景下,两者性能差距会逐渐缩小。纠删码在数据写入时涉及数据校验,且可能产生写惩罚,在数据读取时,因横跨多个节点,任何一个节点时延过高都可能对读写性能造成很大影响。而副本在数据读取时只需要读取1个完整分片即可,不涉及节点数据拼接。
3)重构性能:
副本的优势往往更大,因为不涉及数据校验,只是单纯的数据拷贝,所以速度较快。而纠删码的重构涉及反向校验的计算过程,所需的读写数据量和CPU计算消耗都会更大。
4)容错性能:
两种策略各有优劣势。副本方面,多副本技术可以允许(副本数-1)个非监控节点同时故障而不丢失数据;纠删码方面,以4+2的EC策略为例,可以允许2个非监控节点发生故障而不丢失数据。
故障域隔离技术
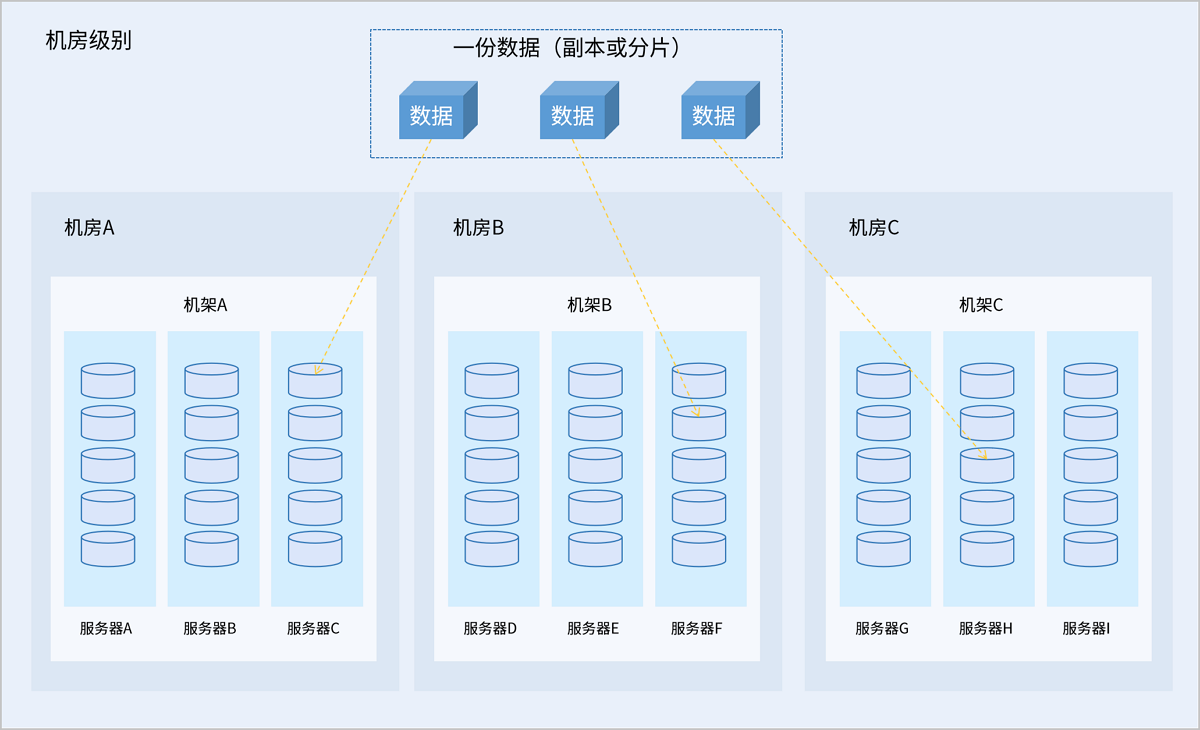
故障域是集群数据分布的最小单元。存储数据时,一份数据的不同副本或分片会被分别存储在不同故障域内,根据数据冗余策略配置,允许一定数量的故障域故障而不丢失数据,从而保障数据安全。支持服务器、机架、机房三种数据冗余级别:
- 服务器级别:集群内每台服务器为一个故障域,一份数据的不同副本或分片分别存储在不同服务器中。
- 机架级别:集群内每个机架为一个故障域,一份数据的不同副本或分片分别存储在不同机架中。推荐集群规模较大、机架数量较多的情况选择此级别。
- 机房级别:集群内每个机房为一个故障域,一份数据的不同副本或分片分别存储在不同机房中。推荐集群规模大、机房数量较多的情况选择此级别。
图 1. 服务器故障域示意图
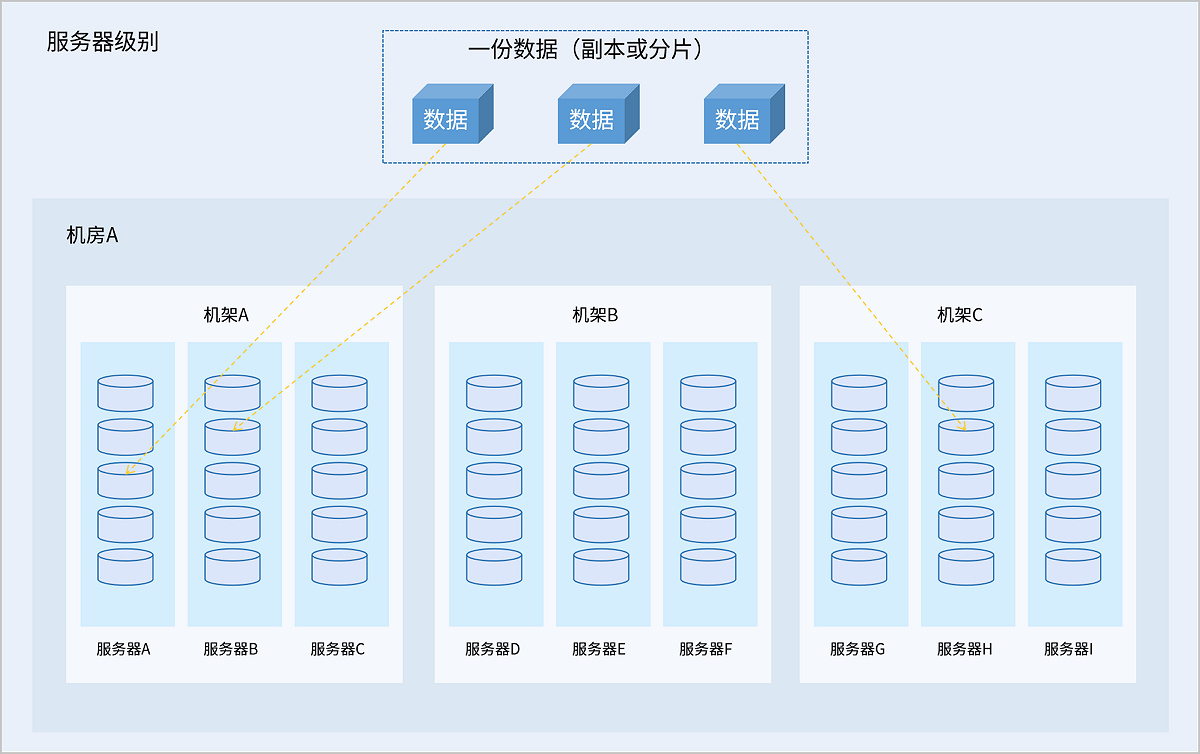
图 2. 机架故障域示意图
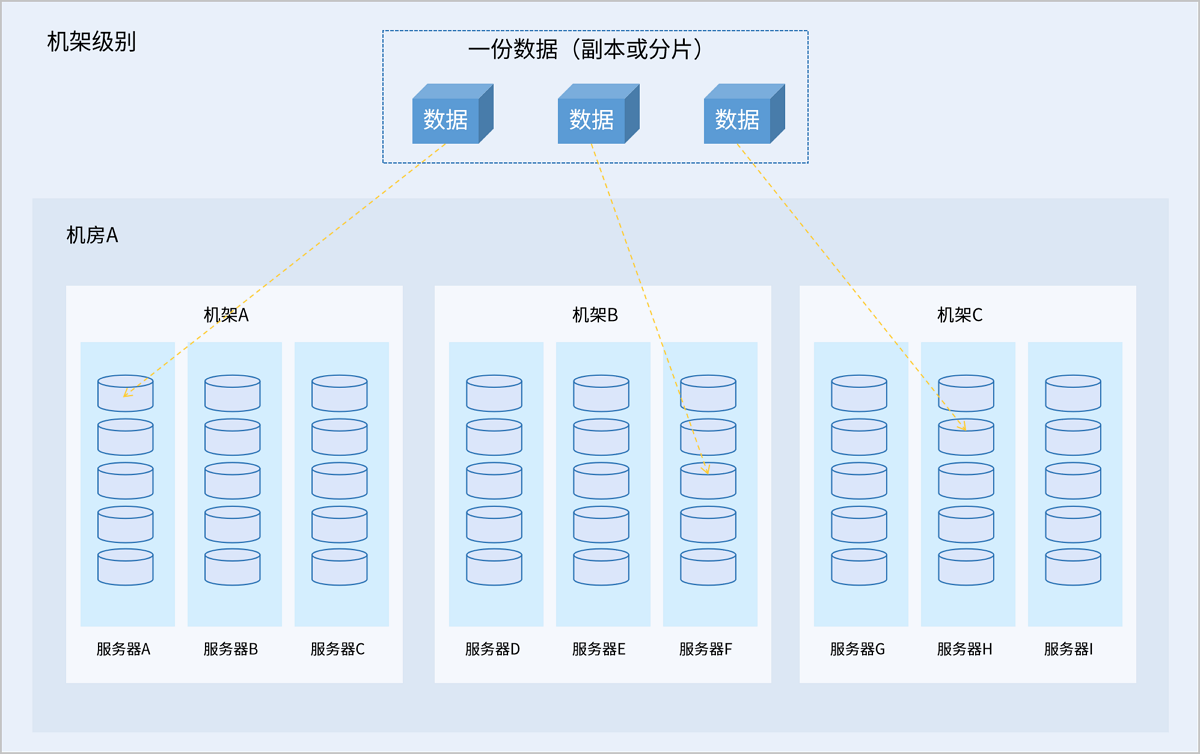
图 3. 机房故障域示意图
通过故障域隔离技术,可将故障对业务的影响限制在某个范围内,避免出现“牵一发而动全身”的情况发生,从而提高业务连续性。
通过基于故障域的扩容技术,配合合理的存储策略,可以将新扩容的节点独立成一个硬盘池,避免了数据的迁移。这种方式能够实现业务的无感扩容,向应用屏蔽了底层存储的变更细节,避免了传统存储变更时需要业务系统同时变更的情况。这样一来,运维人员及业务人员的工作量大大减少,同时也能提高系统的可靠性和性能。
数据一致性检查
自研分布式存储采用Scrub机制,通过在后台扫描来解决数据一致性检查问题。数据一致性检查是周期性行为,分为Scrub和Deep-Scrub两种类型。
- Scrub检查:针对元数据,其特点是执行时间段且执行周期频繁,建议每天执行数据一致性检查。支持自定义Scrub时间。
- Deep-Scrub检查:针对数据,其特点是执行时间较长且对I/O有一定压力,建议在业务量低谷时进行。若超过30天未完成一次Deep-Scrub检查,将发出告警提示。
集群硬件拓扑
集群拓扑是对集群物理资源实际部署方式的可视化展示,其中包含了数据中心、机房、机架、服务器等对象的逻辑实体,通过树状图的方式逐层放置,从而描述出从机房到服务器的分布关系。其中每一个树状图都有一个根节点,同时集群拓扑允许多个根节点存在。用户可在拓扑规划完成后,在创建存储池时选择对应级别的数据冗余策略。
如图 1所示:
图 1. 拓扑层级关系示意图
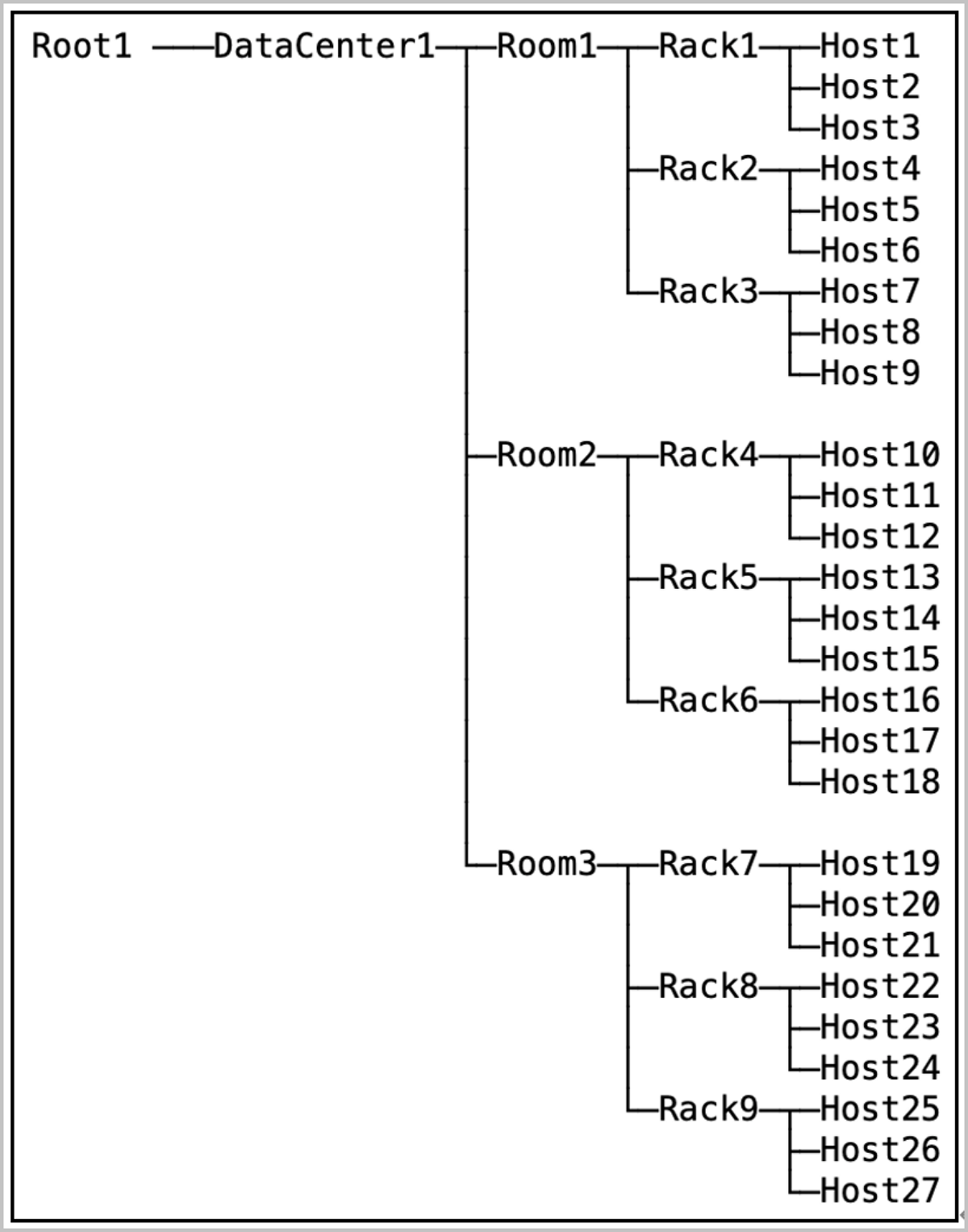
支持通过Web界面规划拓扑,各拓扑对象数量边界要求如下表所示。
| 拓扑对象 | 数量范围 |
|---|---|
| 数据中心 | 0~2 |
| 机房 | 0~100(单个数据中心下) |
| 机架 | 0~100(单个机房下) |
| 服务器 | 0~20(单个机架下) |
便捷运维
多资源池
自研分布式存储支持多资源池特性,帮助用户实现不同性能存储介质的使用和故障隔离。
每个资源池可以具有不同的属性和性能,包括副本数、数据冗余级别、存储介质等。用户可根据实际需求灵活进行资源划分和管理,提高存储效率和存储性能。
各资源池之间相互隔离,用户可基于多个资源池实现数据隔离管理。同时,单一资源池故障不会对其他资源池产生影响,有效保障数据安全和存储可靠性。
硬盘点灯
自研分布式存储支持可视化界面点灯和硬盘快速定位。当用户需对某块硬盘进行维护或更换时,可在UI上点击硬盘点灯,物理环境中该硬盘的LED灯就会亮起,指引用户快速、准确进行设备定位,提高运维效率。
硬盘S.M.A.R.T.检测
自研分布式存储支持S.M.A.R.T.检测技术,监测硬盘的健康状态、温度、固件,和硬盘写入量总计。上层业务会根据Smart Data返回的相关I/O错误和磁盘状态信息, 触发相应的告警。
数据盘维护模式
自研分布式存储支持数据盘维护模式,进行服务器或硬盘维护时,可先在UI界面使对应数据盘进入维护模式,该模式下的数据盘将停止服务和数据访问,其上的数据不会进行重平衡。
自动故障检测和报警
自研分布式存储支持自动故障监测和报警机制。该机制监控存储平台系统和各个存储服务器,检测到故障时将自动向平台发送告警消息。用户可另外添加邮箱报警器接收告警消息,以及时采取措施进行故障修复。
同时,检测到故障发生时,支持自动服务重启和数据迁移,最大程度上保障了数据的可靠、可用,从而形成高可靠、高可用的分布式存储系统。
数据重平衡
自研分布式存储支持数据重平衡,即使存储集群中的数据均衡分布在各个存储服务器下的数据盘上,从而提高存储系统的性能和可靠性。
自动数据重平衡:
- 能根据存储池设置和存储服务器的负载情况,自动有将数据从负载较高的节点转移到负载较低的节点上,以达到负载均衡的效果。
- 存储集群中有服务器发生故障,或有新服务器加入集群时,将自动进行数据迁移,从而保证数据一致性和可靠性。
手动数据重平衡:
同时支持手动数据重平衡功能,用户可根据实际的数据分布情况,手动进行数据重平衡操作。
网络虚拟化
概述
网络虚拟化是一种脱离专用网络硬件抽象出的虚拟网络技术。底层硬件仅需提供基础的数据包转发服务,网络虚拟化可提供多种网络服务,包括交换、路由、安全组和防火墙等,使网络体验同物理网络一样。
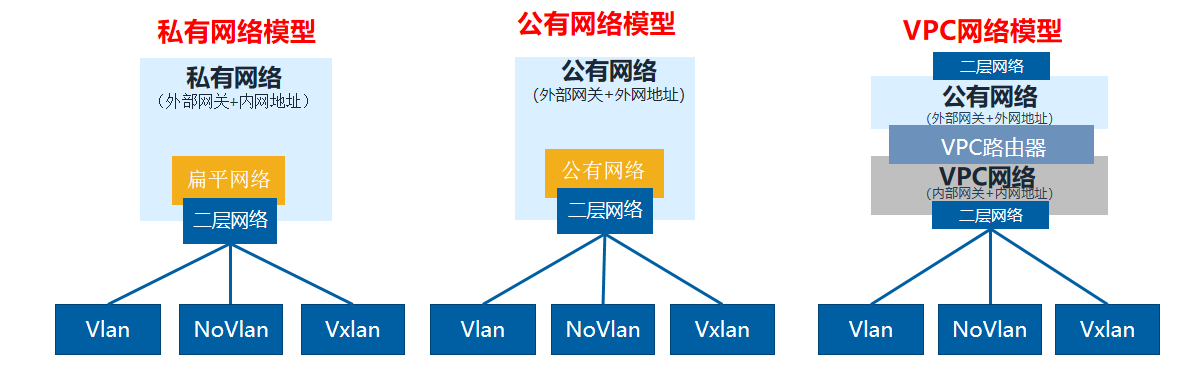
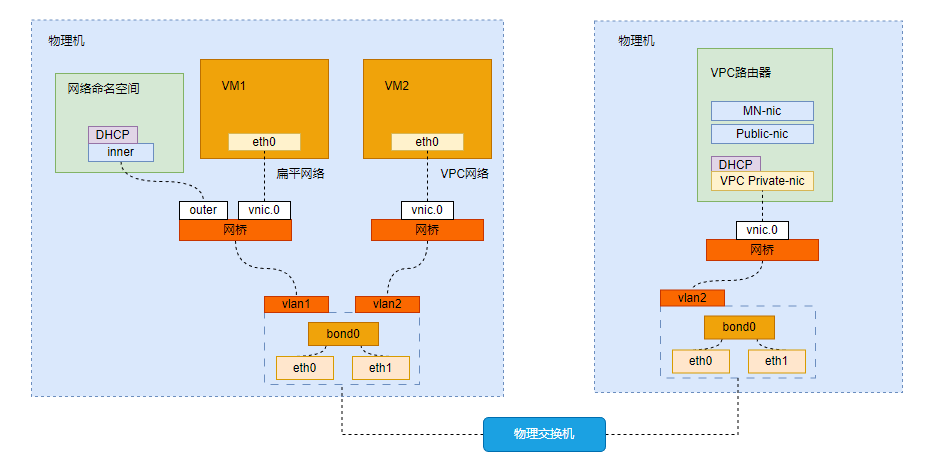
云平台将网络模型抽象为二层网络和三层网络。二层网络对应于二层广播域,提供一种二层网络隔离的方式。三层网络主要与OSI七层模型中第4层~第7层网络服务相对应。可提供二层隔离技术的NoVLAN、VLAN、VXLAN、SDN等均可作为二层网络。创建二层网络,相当于在二层网络所挂载的集群内所有物理机上,创建对应的虚拟交换机来提供广播域。在二层网络之上,创建的三层网络类型包括:扁平网络、公有网络、VPC网络。基于三层网络可提供各种网络服务,包括:DHCP、DNS、弹性IP、端口转发、负载均衡等。
如图 1所示:
图 1. 二层网络与三层网络
技术特性
三层网络
三层网络包括:扁平网络、公有网络、VPC网络。
扁平网络可给云主机分配私有网络地址,同时云主机可通过分布式EIP访问公有网络。扁平网络支持DHCP、User Data、弹性IP、安全组、端口镜像等网络服务。
VPC网络是一块可由租户自定义的网络空间,其目的是让租户在云平台上构建出一个隔离的、可自行管理配置及策略的虚拟网络环境,从而进一步提升租户在云环境中的资源安全性。VPC网络和服务由VPC路由器提供,一个VPC路由器下可提供多个相互隔离的VPC网络,给云主机提供DHCP、DNS、SNAT、路由表、弹性IP、端口转发、负载均衡、IPsec、安全组、动态路由、组播路由、VPC防火墙、Netflow等网络服务。
如图 1所示:
图 1. 三层网络
VPC路由器
VPC路由器是一种专用的云主机,运行着定制的Linux操作系统,以及管理服务代理程序。一个VPC路由器下可提供多个相互隔离的VPC网络,每个VPC路由器中包含一个管理服务代理程序,通过HTTP协议接收来自管理节点的命令来配置网络服务,可为云主机提供DHCP、DNS、SNAT、路由表、弹性IP、端口转发、负载均衡、IPsec、安全组、动态路由、组播路由、VPC防火墙、Netflow等网络服务。
如图 1所示:
图 1. VPC路由器
安全组
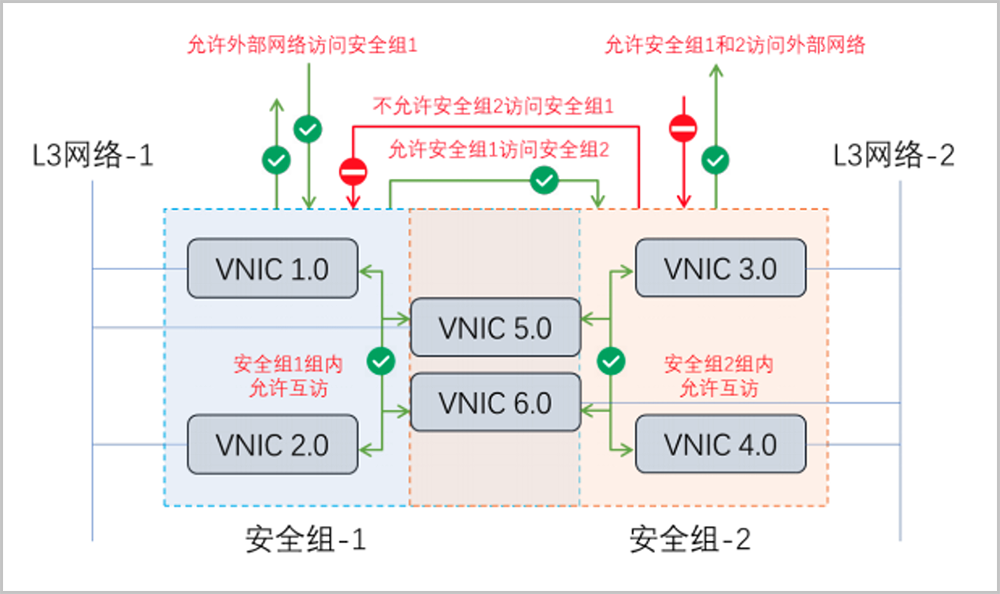
安全组实质是一个分布式防火墙,专注东西向流量管控,防护某张虚拟网卡。每次安全组规则变化、加入/删除网卡,均会导致多台云主机的安全组规则被更新。一张云主机虚拟网卡可加入多个安全组。若将某台云主机的某张虚拟网卡加入至安全组,云平台会自动向该云主机所在物理机下发Iptables规则,并主要使用Filter表。
新建安全组时,默认已配置四条规则(即:协议类型为ALL、IP地址类型为IPv4/IPv6的入口规则和出口规则),用于设置组内互通,默认规则不支持修改或删除,但支持停用,用户可按需停用默认规则,取消组内互通。此外,默认所有外部访问均禁止进入安全组内云主机,安全组内云主机访问外部不受限制。例如,用户创建两个安全组:安全组-1、安全组-2,并将虚拟网卡:vnic 1.0、vnic 2.0、vnic 5.0、vnic 6.0加入安全组-1,vnic 3.0、vnic 4.0、vnic 5.0、vnic 6.0加入安全组-2。缺省情况下规则示意见下。
如图 1所示:
图 1. 安全组规则示意-1
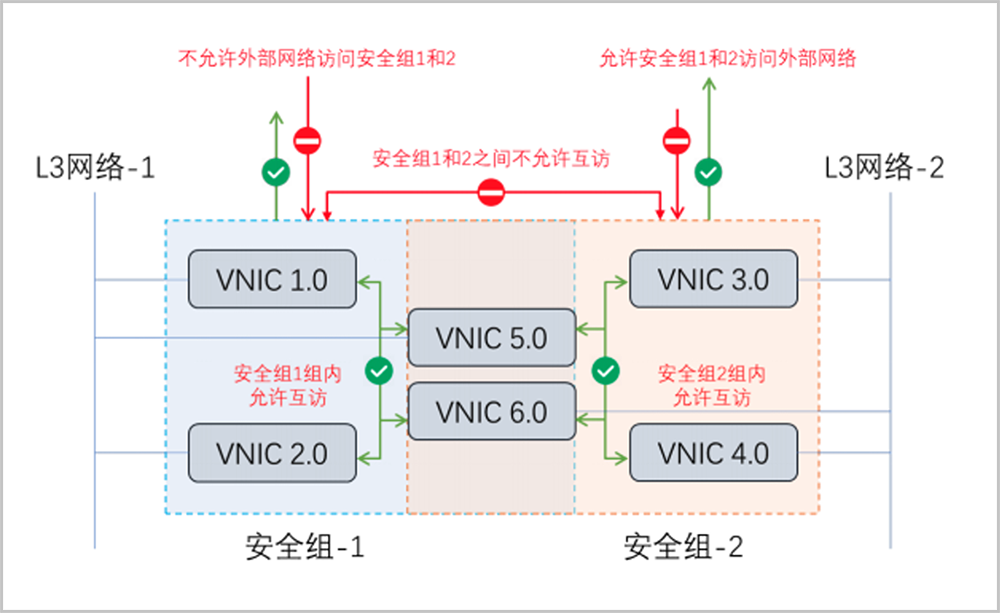
安全组同时支持白名单/黑名单模式,用户可按需配置安全组允许/拒绝规则。例如,用户配置安全组-1的规则,允许外部网络访问安全组-1;配置安全组-2的规则,允许安全组-1访问安全组-2。规则示意见下。
如图 2所示:
图 2. 安全组规则示意-2
弹性IP
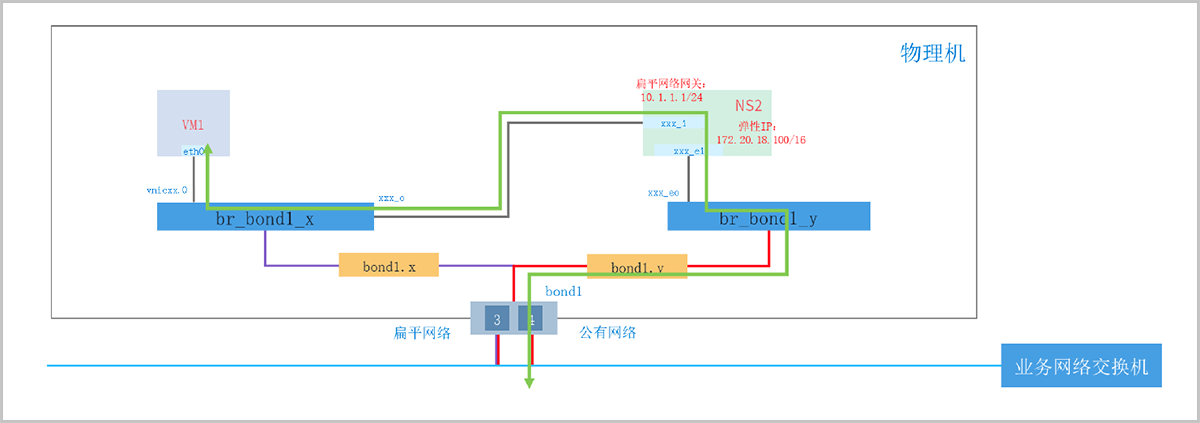
扁平网络的弹性IP由云主机所在的物理机通过Namespace和Iptables实现。
例如,用户为云主机VM1(网关10.1.1.1/24)配置了弹性IP(172.20.18.100),系统将自动在VM1所在物理机创建Namespace(br_bond1_172_20_18_100,对应NS2),并且在NS2中模拟扁平网络的网关,使用Iptables的NAT表实现NAT转换。
当外部网络访问VM1的弹性IP时,首先通过公有网络VLAN2010转发至NS2,在NS2中将目的IP地址转换成VM1的扁平网络IP地址,再将数据包通过网桥br_bond1_100转发给VM1。反之,当VM1访问外部网络时,首先通过网桥br_bond1_100转发至网关(位于NS2中),在NS2中完成源IP地址转换,再经公有网络VLAN2010转发至外部网络。
如图 1所示:
图 1. 扁平网络弹性IP原理
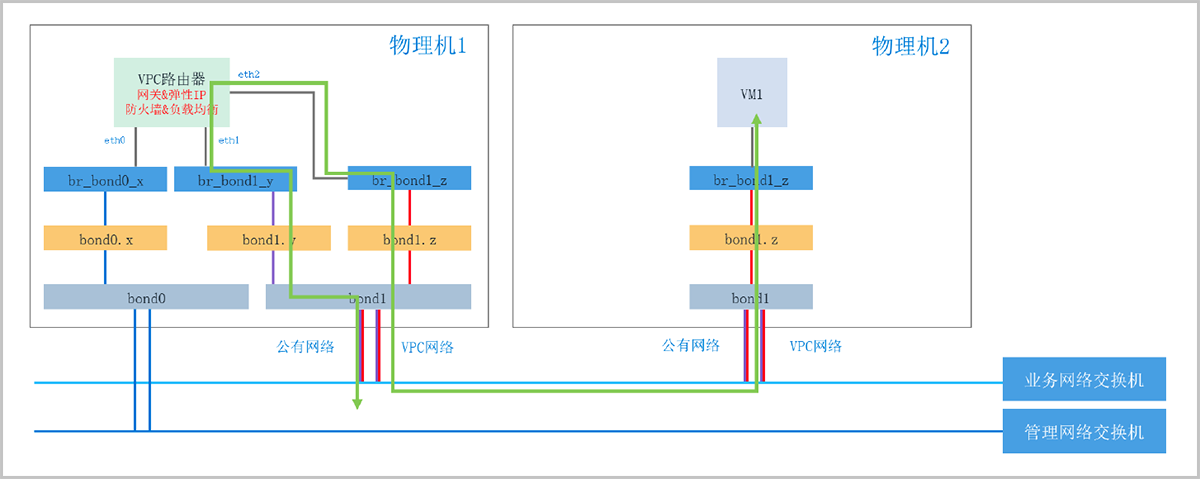
VPC网络的弹性IP由云主机所属的VPC路由器使用Iptables的NAT表实现。
例如,用户为云主机VM1配置了弹性IP。当外部网络访问弹性IP时,首先通过弹性IP所属公有网络VLAN2010转发至VPC路由器,由VPC路由器将目的IP地址转换成VM1的私网IP地址,再通过VPC网络VLAN100转发至VM1。反之,当VM1访问外部网络时,首先经过VPC网络VLAN100转发至VPC路由器,由VPC路由器将源IP地址转换成弹性IP地址,再经公有网络VLAN2010转发至外部网络。
如图 2所示:
图 2. VPC网络弹性IP原理
端口转发
端口转发是基于VPC路由器提供的三层转发服务,可将指定公有网络的IP地址端口流量转发到云主机对 应协议的端口,在公网IP地址紧缺的情况下,通过端口转发可提供多个云主机对外服务,节省公网IP地址资源。
启用SNAT服务的私有网络中,云主机可访问外部网络但不能被外部网络所访问。使用端口转发规则,允许外部网络访问SNAT后面云主机的某些指定端口。端口转发规则可动态绑定到云主机,或从云主机解绑。端口转发服务限于VPC路由器提供。
端口转发基于Iptables的NAT表实现。云平台部署端口转发服务,将自动在VPC路由器中下发Iptables规则配置。端口转发指定端口映射有两种方法:单个端口到单个端口的映射、端口区间的映射。
如图 1所示:
图 1. 端口转发原理

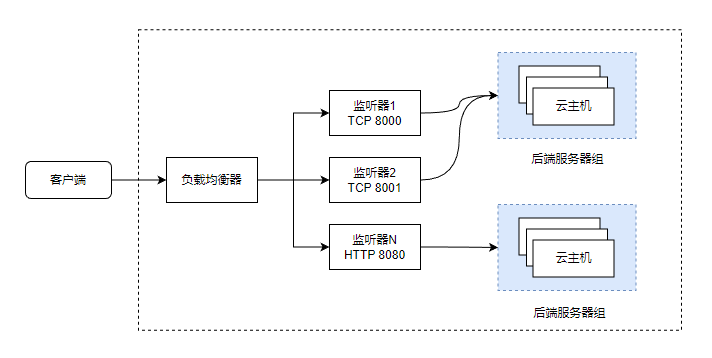
负载均衡
负载均衡提供各种灵活分配算法将全部网络请求均衡分布至后端服务器组上,通过合理管理流量分发以减轻单个服务器的负担,从而应对大流量、高并发的访问,满足客户业务场景需求。
负载均衡同时支持四层负载均衡协议(TCP/UDP)和七层负载均衡协议(HTTP/HTTPS)。
负载均衡转发前端流量至后端服务器时,支持以下算法:
- 轮询算法:按照顺序轮流分配访问请求至后端服务器。轮询是最简单的一个算法,无须关注后端服务器本身的连接数和系统负载等状态,主要应用于各个后端服务器性能差异不大的场景。
- 加权轮询算法:根据后端服务器权重转发访问请求。一般情况下,权重基于硬件配置进行设置,为静态值。权重值越高,被轮询的次数(概率)越高。加权轮询是轮询的一种特殊形式,主要应用于各个后端服务器性能差异较大的场景。
- 源地址哈希:使用客户端请求的源 IP 地址与目标 IP 地址生成唯一的哈希密钥,将请求分配给特定的后端服务器,适合后端服务器需处理客户端请求差异较大的场景。
- 最小连接算法:将新的连接请求分配到当前连接数最小的后端服务器,适用于请求占用后端服务器时间相差较大的场景,常用于长连接服务。
云平台支持基于TCP/UDP协议的四层会话保持机制,以及基于HTTP/HTTPS协议的七层会话保持机制。可识别客户端与后端服务器之间的交互关联性,将客户端访问请求定向转发至特定的后端服务器,从而保证业务会话连续性。
- 四层会话保持机制:负载均衡将同一个源IP地址的访问请求都转发至一台后端服务器上。
- 七层会话保持机制:不同负载均衡算法下,七层会话保持机制不同。轮询算法或加权轮询算法使用基于Cookie的会话保持机制,负载均衡可通过Cookie将访问请求定向转发至之前记录的后端服务器。源地址哈希算法通过哈希函数计算客户端源IP地址,同一个源IP地址的访问请求都将转发至一台后端服务器上。
如图 1所示:
图 1. 负载均衡
VPC防火墙
VPC防火墙主要用于VPC网络环境下的南北向流量管控。VPC防火墙基于Iptables实现,其规则部署在VPC路由器中。为VPC路由器开启VPC防火墙,云平台自动向VPC路由器下发默认规则(编号10000)和系统规则(编号4000- 9999)。默认规则和系统规则可保证缺省情况下VPC网络与外部网络的互访。
默认规则支持且仅支持修改,系统规则均不支持修改。此外,系统规则不支持添加或删除,但支持停用。用户配置自定义规则后,可按需修改默认规则、停用系统规则。在修改默认规则、停用系统规则前,请务必检查确认自定义规则符合预期,否则可能影响业务。
用户配置自定义规则,支持在公有网络或VPC网络上按需配置。
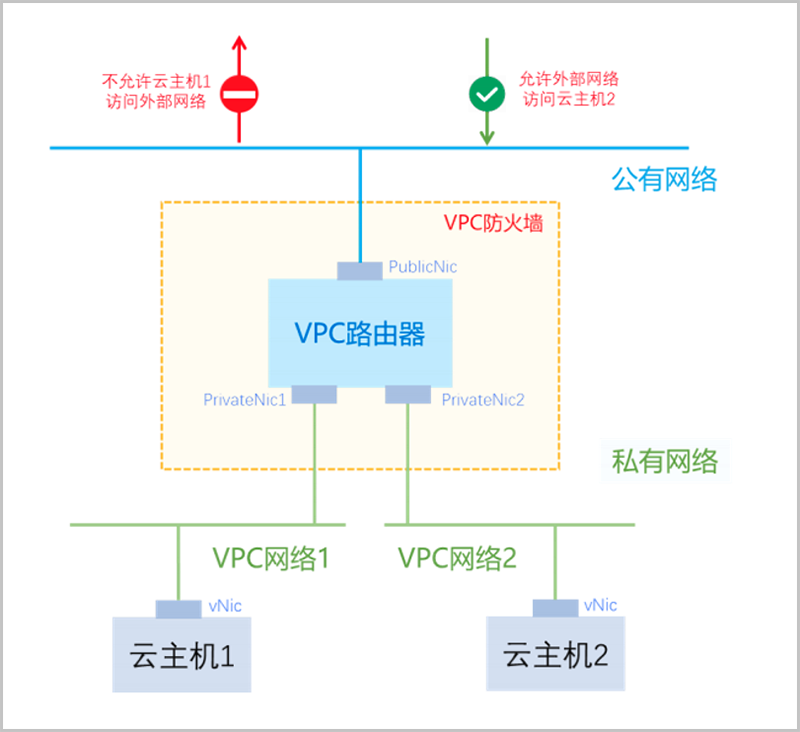
VPC网络与外部网络之间的安全规则建议配置在公有网络上。例如,不允许云主机-1访问外部网络,以及允许外部网络访问云主机-2,此时建议在公有网络的出方向配置规则。
如图 1所示:
图 1. VPC防火墙规则示意-1
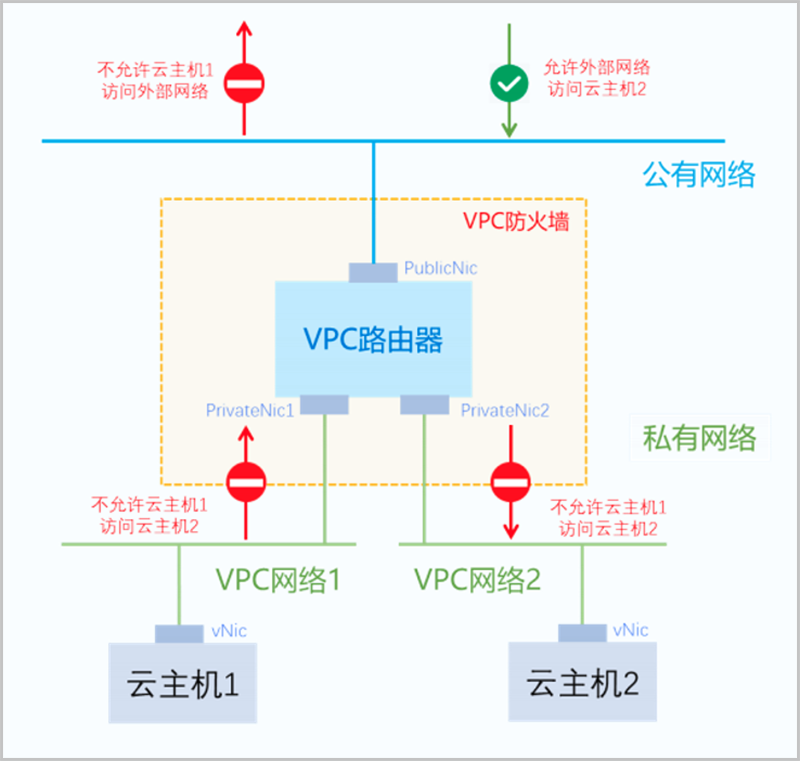
VPC网络之间的安全规则需配置在VPC网络上。例如,不允许VPC网络-1访问VPC网络-2,此时可在VPC网络-1的入方向配置拒绝规则,也可在VPC网络-2的出方向配置拒绝规则。
如图 2所示:
图 2. VPC防火墙规则示意-2
IPsec
用户在多个地域部署ZStack Cloud,或既部署ZStack Cloud私有云,又购买公有云服务。为将多云打通,IPsec是一个简单易部署方案,它可使多云网络实现三层互通,并可实现多云之间数据传输的机密性和安全性。
IPsec包含以下要点:
ESP协议
IPsec有两种模式:
- 传输模式(Transport Mode):在该模式下,通常仅IP数据包的有效载荷部分会被加密或认证。由于IP报头没有被修改或加密,因此路由保持不变。然而,当使用身份验证头时,IP地址不能通过网络地址转换(NAT)进行修改,因为这样总是会使哈希值失效。传输层和应用层总是通过哈希进行安全保护,因此它们不能以任何方式被修改,例如通过转换端口号。
- 隧道模式(Tunnel Mode):在该模式下,整个IP数据包均会被加密和认证。它会被封装到一个新的IP数据包中,并附加一个新的IP头。隧道模式用于创建虚拟专用网络,用于网络到网络通信(例如:连接各个站点的路由器)、主机到网络通信(例如:远程用户访问)以及主机到主机通信。隧道模式支持NAT穿越。
ZStack Cloud IPsec支持隧道模式,不支持传输模式。
IKE协议
IKE有两个版本:IKEv1、IKEv2。ZStack Cloud IPsec推荐使用IKEv2。IKEV2可使用四条消息完成IKEv2 SA和IPsec SA的协商,简化了IKEv1的协商过程。
IKEv2定义了三种交换:
- 初始交换(Initial Exchanges)
- 创建子SA交换(Create_Child_SA Exchange)
- 通知交换(Informational Exchange)
其中,初始交换包含两次两对消息交换:
- 第一对消息交换,以明文方式完成IKE SA的参数协商。包括协商加密和验证算法、交换临时随机数和DH交换,据此可算出加密后续IKE消息的Key。
- 第二次消息交换,以加密方式完成身份认证和IPsec SA的参数协商。IKEv2支持三种认证方式:证书认证、预配值密码(PSK)、EAP认证。ZStack Cloud支持PSK认证方式。
Netflow
Netflow实质是流量监控,即针对网络通信数据包进行管理与控制,同时进行优化与限制。流量监控的目的是允许并保证有用数据包的高效传输,同时禁止或限制非法数据包的传输,一保一限是流量监控的本质。
为了更好地收集分析网络数据包,可将一系列具有相同规则的网络数据包(Packet)分为逻辑的流(Flow)。目前业界有以下Flow相关的流量控制协议:
- Juniper® (Jflow)
- Huawei® (NetStream)
- Nokia® (Cflow)
- Ericsson® (Rflow)
- 3Com/HP® , Dell® , and Netgear® (s-flow)
Netflow是Cisco®提出的网络数据包交换技术,其对流经网络设备的IPFlow进行测量和统计的功能非常成熟,提供网络流量的会话级视图,记录下每个TCP/IP事务的信息,易于管理和易读,并成为当今互联网领域公认的最主要的IP流量分析、统计和计费行业标准。
ZStack Cloud支持使用Netflow技术对VPC路由器网卡的进出流量进行分析和监控。目前支持两种数据流输出格式:V5、V9。用户可通过自定义配置选择不同的流量格式。Netflow统计经过VPC路由器的流量,可以是VPC网络内的流量,也可以是VPC路由器所在公网的流量。
技术特性
在VPC路由器内部,使用Pmacct包实现Netflow。ZStack Cloud主要使用Pmacct的Nflog模块进行流量统计。当用户下发Netflow配置之后,Pmacct会在Iptables Raw表中添加Nflog规则,用于收集VPC网卡上所有流量,之后再根据配置信息,对指定IP进行过滤和统计。
关于Nflog的说明。
- Iptables Nflog是一种Linux内核模块,它可将网络流量日志发送到用户空间的应用程序,以便进行进一步分析和处理。当Iptables规则匹配到一条流量时,它可将该流量发送到Nflog模块,然后该模块会将该流量的一些元数据(如源IP、目标IP、端口等)和原始数据包发送至用户空间的应用程序。用户空间的应用程序可以使用libnetfilter_log库来接收这些日志,并进行进一步处理。
- Nflog模块通过一个称为Nfnetlink的机制与用户空间的应用程序进行通信。当Iptables规则触发时,内核会向用户空间发送一个Nfnetlink消息,该消息包含有关触发规则的流量的元数据和原始数据包。应用程序可使用libnetfilter_log库来接收这些消息,并进行进一步处理。
- Nflog模块可用于实现各种网络安全应用程序,如IDS(入侵检测系统)、IPS(入侵防御系统)和网络流量分析工具等。通过使用Nflog模块,这些应用程序可实时监视网络流量,并对潜在安全威胁进行快速响应。
关于Pmacct Nflog的说明。
- Pmacct是一个开源的网络流量监控工具,支持使用多种方式收集和分析网络流量数据。其中,Pmacct支持使用Nflog模块收集网络流量数据。
- 当Pmacct使用Nflog模块收集网络流量数据时,它会创建一个Nflog Socket,并将其与Iptables规则绑定。于是,当Iptables规则匹配到一条流量时,它会将该流量发送至Nflog模块,并将该流量的一些元数据(如源IP、目标IP、端口等)和原始数据包发送至Pmacct的Nflog Socket中。
- Pmacct会使用libnetfilter_log库来接收这些Nflog消息,并将它们转换为Pmacct可以理解的格式。然后,Pmacct会将这些流量数据记录到一个流量数据库中,并可使用Pmacct的命令行工具来查询和分析这些数据。
统计指标
ZStack Cloud Netflow服务默认统计的流量指标:
- src_mac:流量的源MAC地址。
- dst_mac:流量的目的MAC地址。
- vlan:流量的VALN ID。
- src_host:流量的源IP地址。
- dst_host:流量的目的IP地址。
- src_port:流量的源端口。
- dst_port:流量的目的端口。
- proto:流量的协议类型。
- tos:流量的服务类型。
- flows:流量的Entry信息。
端口镜像
端口镜像将某个端口的数据报文复制一份并转发至另一端口,再在第二个端口进行数据/流量分析。也可将流量继续转发至更远处再进行分析,从而最大程度降低对原始报文转发处理流程的影响。
原始报文通过的端口称为镜像端口,也称为被监控端口。上述第二个端口,即数据被复制到的端口,称为监控端口,也称为采集端口或观察端口。
数据报文在端口上有进/出两种方向。对于端口镜像,需复制转发以下三种方向的数据包:
- 入方向,仅对从镜像端口收到的报文进行复制转发。
- 出方向,仅对从镜像端口发出的报文进行复制转发。
- 对从镜像端口收到和发出的报文都进行复制转发。
端口镜像适用于以下场景:
- 当怀疑有攻击或有网络故障时,需获取某个端口的报文进行分析,从而排除威胁和找出故障原因。
- 需对某个端口的流量进行监控与观察,同时还需做到尽量不影响原报文转发。
技术特性
端口镜像技术最初来源于物理交换机,有SPAN(Switched Port Analyzer)、RSPAN(Remote Switched Port Analyzer)、ERSPAN(Encapsulated Remote Switched Port Analyzer)等多种镜像技术,也有多种镜像源。
- 端口:将指定端口接收或发送的报文复制到观察端口,此时的镜像被称为端口镜像。
- VLAN:将指定VLAN内所有活动接口接收的报文复制到观察端口,此时的镜像被称为VLAN镜像。
- MAC地址:将指定VLAN内源MAC地址或目的MAC地址为指定MAC地址的报文复制到观察端口,此时的镜像被称为MAC镜像。
- 报文流:将符合指定规则的报文流复制到观察端口,此时的镜像被称为流量镜像。
关于云平台端口镜像的说明。在云计算时代,基于网络虚拟化技术,在物理机上演化出许多虚拟网络设备,用户的虚拟网卡不再直接插在物理交换机上,且可能由于迁移等活动导致网卡位置频繁变动,原始在物理机上配置实现的端口镜像功能也需迁移至软件上实现,以适应上述业务变化。
ZStack Cloud网络虚拟化基于开源Linux操作系统实现,对应的端口镜像功能也基于Linux系统生态工具/库来实现。
云平台对弱化用户资源的物理位置十分重视,因此类似于交换机的ERSPAN技术,云平台的端口镜像经常需将用户某个端口的报文/流量复制转发至任意位置的设备(很多情况下使用的是虚拟资源,例如云主机),再在远端进行检测和分析。
OSPF
在ZStack Cloud中,VPC路由器至少有一个下行VPC网络用于连接云主机,至少有一个上行网络用于连接外部网络。在某些场景下,VPC路由器可能需要多个上行网络。假定VPC路由器有两个上行网络,一个连接互联网区域,一个连接专线区域。VPC路由器需要知道外部路由,才能进行路由转发。ZStack Cloud提供以下三种解决方案:
- 静态路由。路由表功能,可给VPC路由器配置外部路由,保证VPC路由器进行正确的路由转发。该方案简单,不依赖外部组件,但存在以下制约:需配置VPC路由器以及外部路由器,维护复杂。若网络Topo变化,需手动修改路由表。
- OSPF路由协议。通过在路由器之间交换路由信息,实现路由信息的自动同步。该方案可完美解决静态路由上述制约,但需维护更多功能模块,增加软件的设计开发复杂度。
- OSPF(Open Shortest Path First)是IETF组织开发的一个基于链路状态的动态路由协议。OSPFv2用于解决IPv4路由同步, OSPFv3用于解决IPv6路由同步。ZStack Cloud支持OSPFv2。
- OSPF路由协议包含以下要点:
- 源进源出。假定VPC路由器的两个上行网络是电信专线和联通专线,但运营商不会同步路由信息到云平台。在该场景下,VPC路由器将选择一条专线作为默认路由,内部主动访问外部流量使用默认路由上网,外部主动访问进来的流量(例如:EIP访问、端口转发、负载均衡、IPsec隧道等)使用源进源出功能保证流量打通。否则,可能出现联通专线进来的流量,从电信专线出去,造成网络不通。
RouterID
RouterID(路由器ID)是一个32位整数,在OSPF系统中唯一标识一台OSPF路由器。
邻居关系和邻接关系
路由器启动OSPF协议后,会定时通过打开OSPF功能的接口发送OSPF Hello报文。收到Hello报文的设备,比较Hello报文中的参数和接口参数,例如:area ID,若参数一致,则形成邻居关系。
形成邻居关系后,若两端设备成功交换DD报文和LSA报文,才建立邻接关系。不是所有的邻居关系都会变成邻接关系。
DR/BDR/DROther
在广播网或NBMA网络中,可能同时存在很多OSPF路由器,不需要两两之间形成邻接关系。因此,需要选举出DR(指定路由器)和BDR(备份指定路由器),其它的路由器则称为DRother(非指定路由器)。仅当DR、BDR、以及全部路由器形成邻接关系时,才可减少OSPF报文交换,加速路由计算。
DR和BDR通过选举算法产生,选举参数包含:OSPF接口优先级、RouterID等。在实践中尽量让物理路由器选举为DR和BDR,因为VPC路由器可能因为云平台操作导致关机,从而影响整个数据中心的网络抖动。
区域
在一个大型网络系统中,可能会出现很多问题,例如:路由信息过多、路由计算时间过长、路由收速度敛慢等。任何一个网络变化,都会导致所有路由器重新计算路由,从而引发路由震荡。
OSPF通过将大型网络划分成多个区域来解决这一问题,每个区域有一个Area ID(区域ID)。
根据LSA分发情况,区域可分为:普通区域、Stub区域、NSSA区域、Totally NSSA区域。
LSA
OSPF是基于网络Topo信息计算路由信息的协议。LSA(链路状态)用于描述网络Topo状态。
| LSA类型 | 描述 |
|---|---|
| Type 1 | 每个OSPF路由器产生一条Type 1 LSA,描述了设备的链路状态和开销,在所属的区域内传播。 |
| Type 2 | 由DR(指定路由器)生产,描述一个广播网连接的OSPF路由器,在所属的区域内传播。 |
| Type 3 | ABR(区域边界路由器)产生,把区域内网段的路由发布到其它区域。 |
| Type 4 | ABR(区域边界路由器)产生,描述到ASBR的路由信息。 |
| Type 5 | ASBR(自治域边界路由器)产生,把区域外路由发布到相关区域。 |
组播
在众多网络业务场景中,存在这样一种业务场景:一份数据需要发给多个接收者。可提供的解决方案:
- 发送源复制数据,发送多份数据。缺陷:若接收者成千上万,将给发送源造成巨大负载压力,同时发送端的网络带宽也承受巨大压力。
- 发送源发送一份广播数据,让交换机来复制。缺陷:不能跨三层进行转发,且对不是接收者的设备带来额外的CPU和网络压力。
组播技术可有效解决单点发送、多点接收的问题。事实上该技术在有线电视、实时视频会议等领域已有广泛应用。
组播技术包含以下要点:
组播地址
组播地址范围:224.0.0.0 ~ 239.255.255.255。与单播地址一样,组播地址也按用途进行了划分。
| 范围 | 用途 |
|---|---|
| 224.0.0.0 ~ 224.0.0.255 | 保留地址。例如:OSPF使用224.0.0.5,VRRP使用224.0.0.18 |
| 224.0.1.0 ~ 238.255.255.255 | 用户可用的组播地址 |
| 239.0.0.0 ~ 239.255.255.255 | 本地组播地址 |
组播成员管理
组播注册协议用来在交换机和路由器上维护组播组和组播接收者之间关系。
IPv4组播注册成员管理使用IGMP协议。IGMP协议有以下三个版本:
- IGMPv1:定义了基本的组成员查询和报告过程。
- IGMPv2:增加了组成员快速离开的机制等。
- IGMPv3:增加对SSM模型的支持等。
组播转发树
由于组播是单点发送、多点接收,需在组播源和组播接收者之间生成一个转发树。
- 源树(SPT):以组播源作为树根转发树。网络要为任何一个向该组发送报文的组播源建立一棵树,路由表的规模非常大。SPT同时适用于PIM-DM网络和PIM-SM网络。
- 共享树(RPT):以某个路由器作为树根,该路由器称为汇集点(RP),以RP到所有接收者的最短路路径所共同构成的转发树。每个组播组,网络中只维护一棵树。组播源先向树根(RP)发送数据报文,再按照共享树转发到达所有的接收者。RPT适用于PIM-SM网络。
组播路由协议
常用的组播路由协议为PIM协议。PIM协议有三种工作模式:PM-DM、PM-SM、PIM-SSM模式。
虚拟资源管理
云主机管理
云主机调度策略
云主机调度策略可为云主机分配物理机资源编排策略,用于保障业务高性能和高可用。支持将云主机加入一个云主机调度组,通过为该云主机调度组绑定调度策略实现云主机调度。
功能原理
支持将云主机加入一个云主机调度组,通过为该云主机调度组绑定调度策略实现云主机调度。
- 若绑定互斥云主机或聚集云主机策略,无需指定物理机调度组,云主机按照策略及其执行机制分配物理机。
- 若绑定云主机亲和物理机或云主机互斥物理机调度策略,需指定对应的物理机调度组,云主机按照策略及其执行机制分配物理机。
下文通过四个场景说明四类调度策略的工作原理:
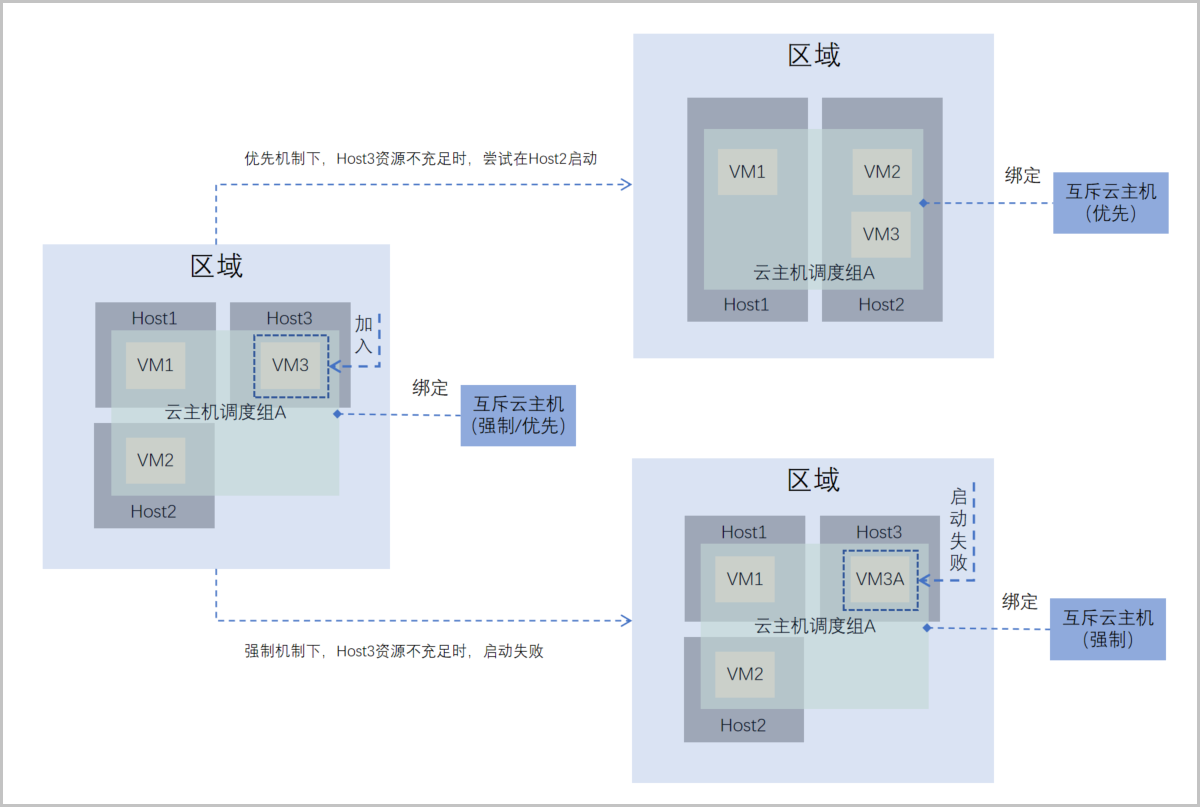
场景1:假定区域内有三台物理机Host1、Host2、和Host3。云主机调度组A已绑定互斥云主机调度策略,且云主机VM1和VM2已加入该调度组,并分别运行在物理机Host1和Host2上。此时将云主机VM3加入该调度组,不同执行机制下云主机VM3行为如下:
- 强制机制下,云主机VM3遵循与组内其他云主机强制互斥原则:
- 若物理机Host3资源充足,可正常在Host3上启动并运行。
- 若物理机Host3资源不足,无法在Host3上启动。
- 优先机制下,云主机VM3遵循与组内其他云主机尽量互斥原则,优先在Host3上启动:
- 若物理机Host3资源充足,可正常在Host3上启动并运行。
- 若物理机Host3资源不足,VM3可尝试在其他资源充足的物理机上启动。在该场景下,VM3在Host2上启动并运行。
如图 1所示:
图 1. 互斥云主机(强制/优先)
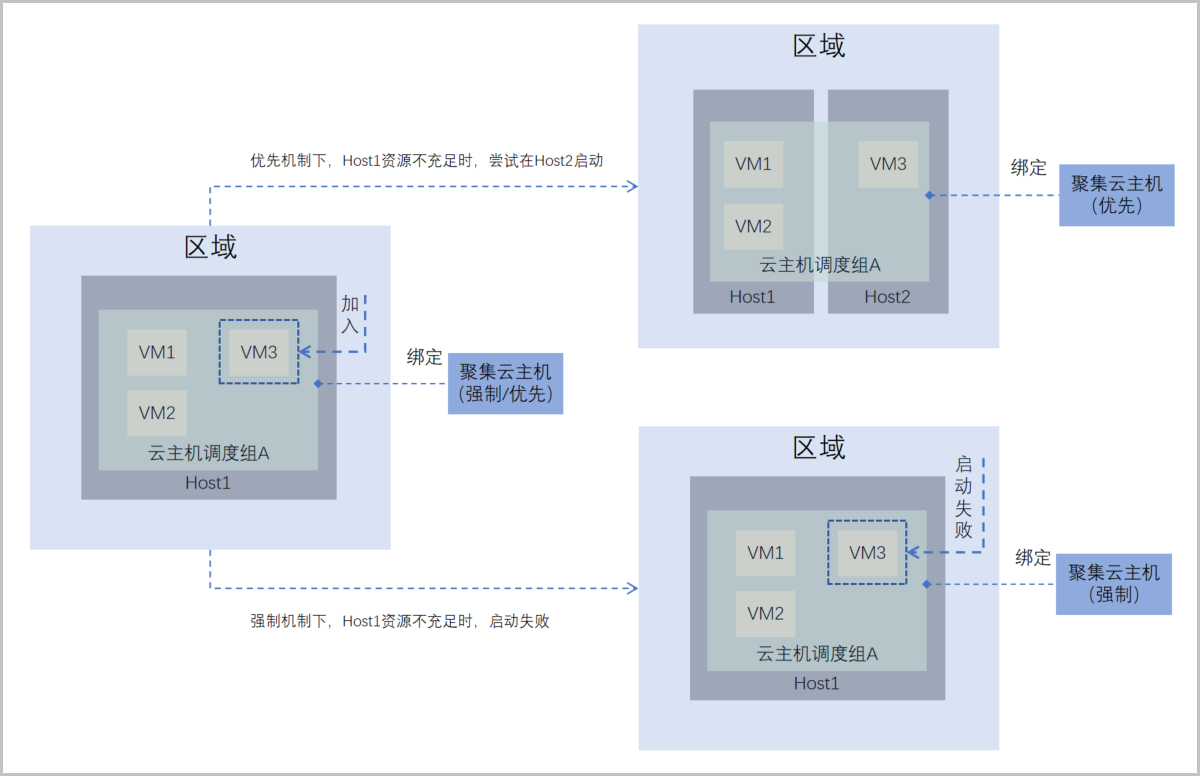
场景2:假定区域内有两台物理机Host1和Host2。云主机调度组A已绑定聚集云主机调度策略,且云主机VM1和VM2已加入该调度组,并运行在物理机Host1上。此时将云主机VM3加入该调度组,不同执行机制下云主机VM3行为如下:
- 强制机制下,云主机VM3遵循与组内其他云主机强制聚集原则:
- 若物理机Host1资源充足,可正常在Host1上启动并运行。
- 若物理机Host1资源不足,无法在Host1上启动。
- 优先机制下,云主机VM3遵循与组内其他云主机尽量聚集原则,优先在Host1上启动:
- 若物理机Host1资源充足,可正常在Host1上启动并运行。
- 若物理机Host1资源不足,VM3可尝试在其他资源充足的物理机上启动。在该场景下,VM3在Host2上启动并运行。
如图 2所示:
图 2. 聚集云主机(强制/优先)
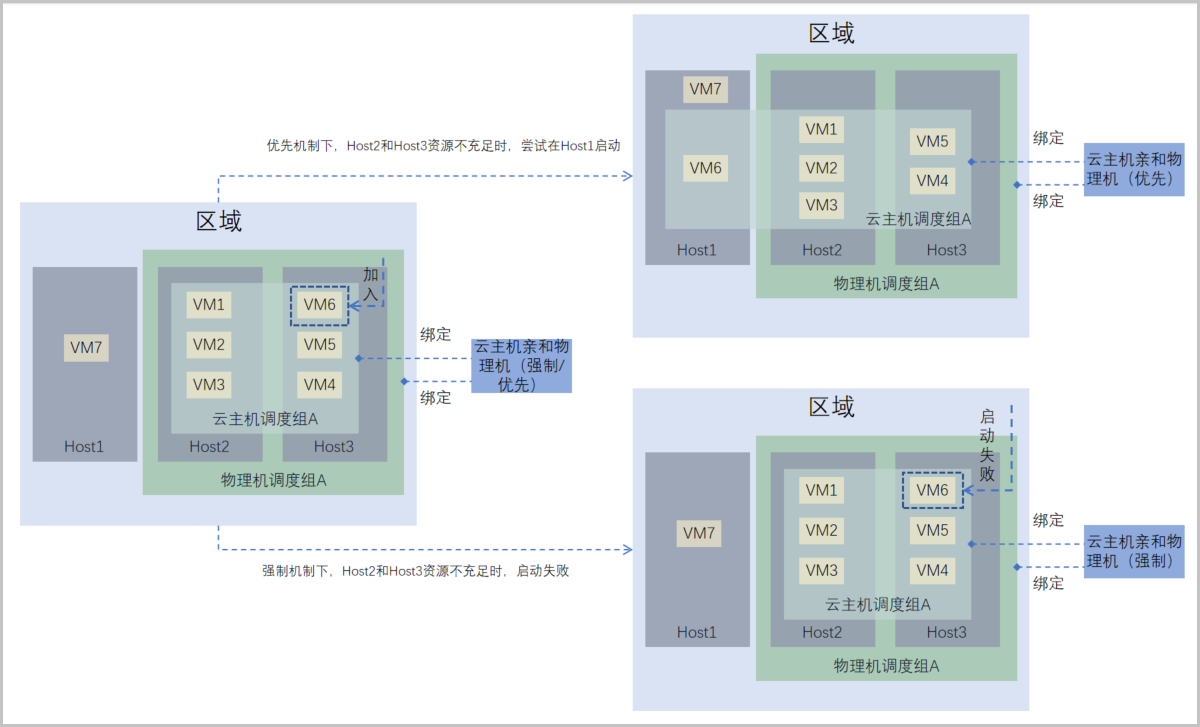
场景3:假定区域内有三台物理机Host1、Host2、和Host3。云主机调度组A已绑定云主机互斥物理机调度策略,且云主机VM1和VM2已加入该调度组,并运行在物理机Host1上。物理机调度组A也已绑定云主机互斥物理机调度策略,且物理机Host2和Host3上已加入该调度组,分别运行两台云主机。此时将云主机VM3加入云主机调度组A,不同执行机制下云主机VM3行为如下:
- 强制机制下,云主机VM3遵循与物理机调度组A内的物理机强制互斥原则:
- 若物理机Host1资源充足,可正常在Host1上启动并运行。
- 若物理机Host1资源不足,无法在Host1上启动。
- 优先机制下,云主机VM3遵循与物理机调度组A内的物理机尽量互斥原则,优先在Host1上启动:
- 若物理机Host1资源充足,可正常在Host1上启动并运行。
- 若物理机Host1资源不足,VM3可尝试在其他资源充足的物理机上启动。在该场景下,VM3在Host2上启动并运行。
如图 3所示:
图 3. 云主机互斥物理机(强制/优先)
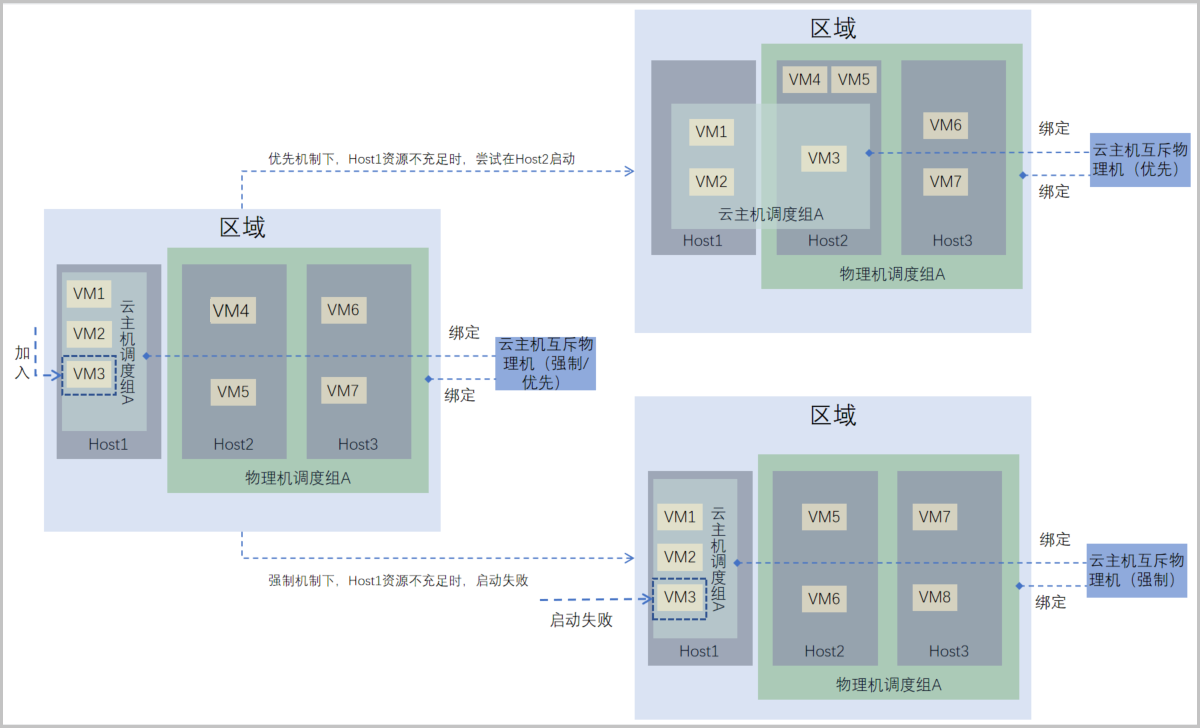
场景4:假定区域内有三台物理机Host1、Host2、和Host3。云主机调度组A已绑定云主机亲和物理机调度策略,且云主机VM1~VM5已加入该调度组,并分别运行在物理机Host2和Host3上。物理机调度组A也已绑定云主机亲和物理机调度策略,且物理机Host2和Host3上已加入该调度组。此时将云主机VM6加入云主机调度组A,不同执行机制下云主机VM6行为如下:
- 强制机制下,云主机VM3遵循与物理机调度组A内的物理机强制聚集原则:
- 若物理机Host2或Host3资源充足,可正常在Host2或Host3上启动并运行。
- 若物理机Host2和Host3资源不足,无法在Host2或Host3上启动。
- 优先机制下,云主机VM3遵循与物理机调度组A内的物理机尽量聚集原则,优先在Host2或Host3上启动:
- 若物理机Host2或Host3资源充足,可正常在Host2或Host3上启动并运行。
- 若物理机Host2和Host3资源不足,VM6可尝试在其他资源充足的物理机上启动。在该场景下,VM3在Host1上启动并运行。
如图 4所示:
图 4. 云主机亲和物理机(强制/优先)
云主机克隆
云平台提供三种云主机克隆方式以满足不同业务场景需求:链接克隆、全量克隆、快速全量克隆。
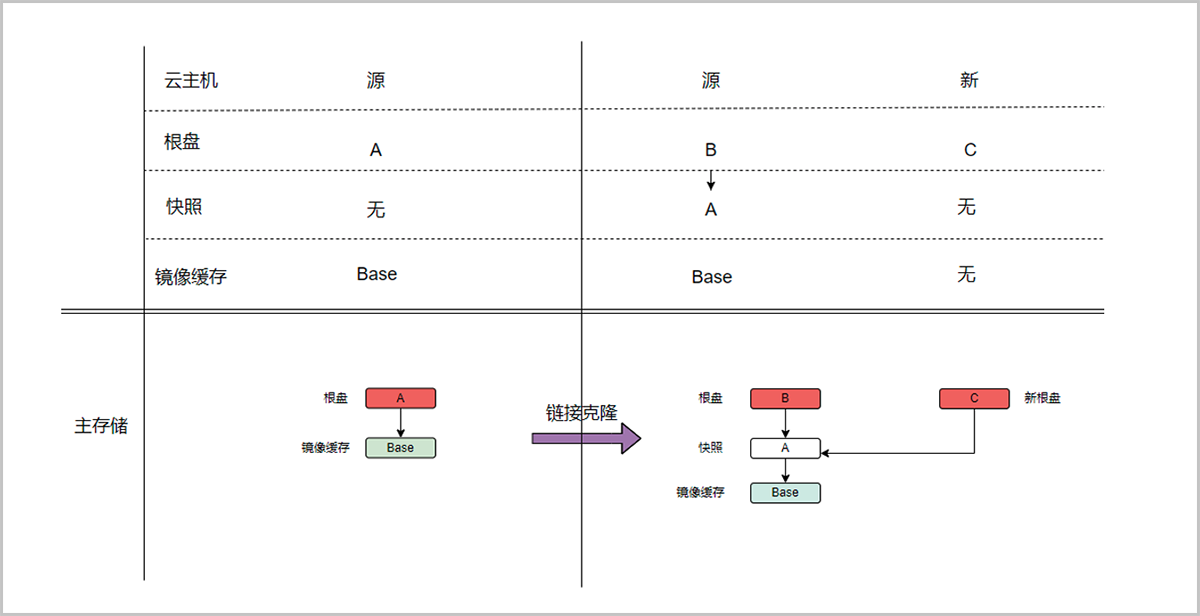
链接克隆
通过链接克隆的云主机启动速度快,占用少量存储空间。但是,链接克隆的云主机共享使用源云主机的磁盘链,因为它们之间存在依赖关系。ZStack Cloud提供的链接克隆不受限于源云主机的快照链长度,且支持各种类型的主存储。
在执行链接克隆新云主机时,无需复制源云主机的所有数据,而是在源云主机快照链的基础上创建一个新的磁盘文件并做关联作为新的云主机实例,新云主机实例共享了源云主机的快照链,这部分共享的快照链是只读的,因此通过链接克隆创建的云主机过程中并没有实际的数据拷贝,从而可以做到云主机的快速启动。
基于源云主机快照链创建出的新磁盘文件具有写时重定向的特性,即刚创建时仅占用极少的存储空间,后续当云主机实例尝试修改云主机内容时,会把修改的数据写入新的磁盘文件中,这样就不会影响源快照链的数据,确保了克隆云主机与源云主机的相对独立性。
如果想要把克隆云主机与源云主机从快照链上完全独立开来,需要使用平台提供的扁平合并功能。当做批量链接克隆时,由于多个云主机实例共享相同的只读快照链,链接克隆显著减少了存储空间的需求。
云主机链接克隆技术提供了一种有效管理云主机的方式,特别是在需要创建多个相似云主机实例时,如测试集群或桌面云VDI场景。 通过共享的快照链,链接克隆节省了存储成本,并提高了云主机的创建和管理效率。
如图 1所示:
图 1. 链接克隆
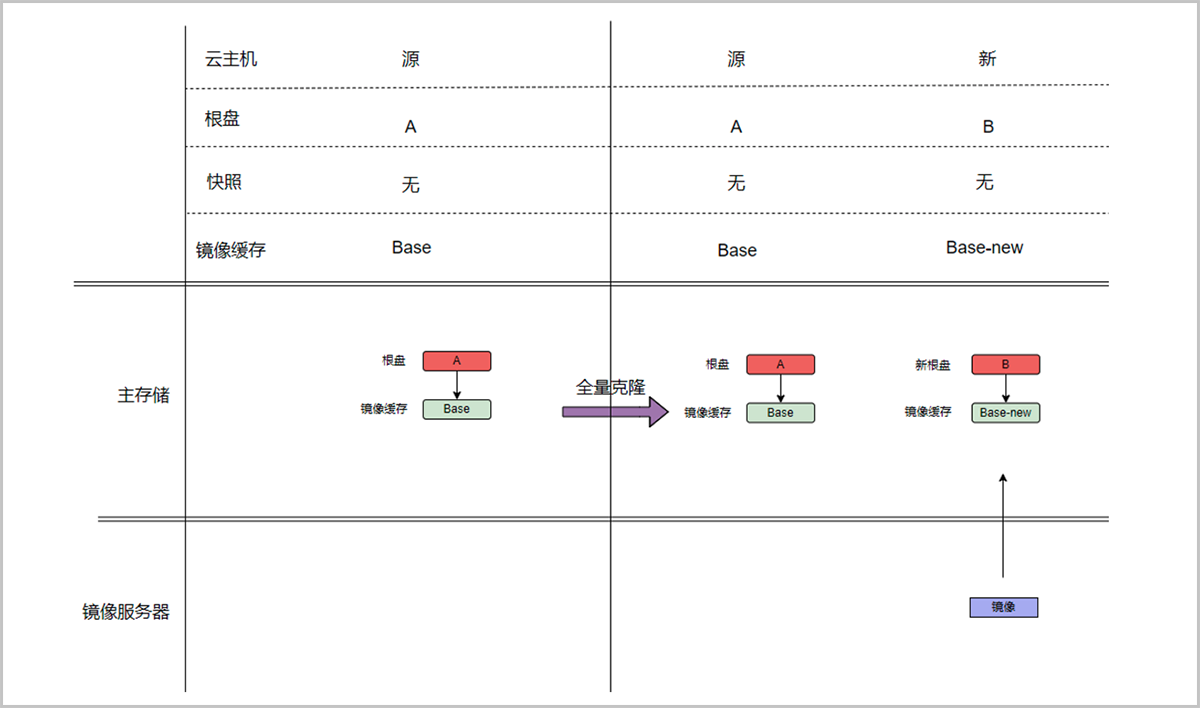
全量克隆
全量克隆是针对云主机的另一种克隆方法。与链接克隆不同,它不与源云主机共享数据,而是把源云主机做成镜像文件后来创建新的云主机实例。这个源云主机镜像是一个完整的镜像文件,包含云主机所需的所有文件和配置,并保存在镜像服务器中,随后把镜像文件推送到主存储中作为克隆云主机的镜像缓存,以此来克隆出全新的云主机。因此全量克隆的云主机不受主存储的限制,克隆的云主机可以指定与源云主机不同的主存储来启动。
全量克隆创建的云主机是完全隔离且独立的,与源云主机没有依赖关系,因此云主机性能完全不受影响,同时全量克隆通常需要更多的存储空间。但是在批量全量克隆多云主机时,ZStack Cloud做了存储优化,针对新云主机的镜像缓存只会在主存储上存储一份,避免了在主存储上消耗更多的存储资源,也提升了批量克隆时云主机的启动时间。
如图 2所示:
图 2. 全量克隆
快速全量克隆
快速全量克隆是对链接克隆和全量克隆的一种整合。它既能像链接克隆那样快速的启动克隆出来的云主机,又能像全量克隆那样保持数据独立,不与源云主机共享快照链。
在执行快速全量克隆时,在克隆初始利用链接克隆技术创建出依赖源云主机的新云主机,以此来满足快速云主机启动,随后后台会启动出一个任务来做快照合并,最终会把克隆云主机的数据完全独立出来,不依赖于源云主机,因此通过快速全量克隆的云主机具有启动速度快,数据最终独立的特点,并且克隆完成后云主机性能不受影响。
如图 3所示:
图 3. 快速全量克隆
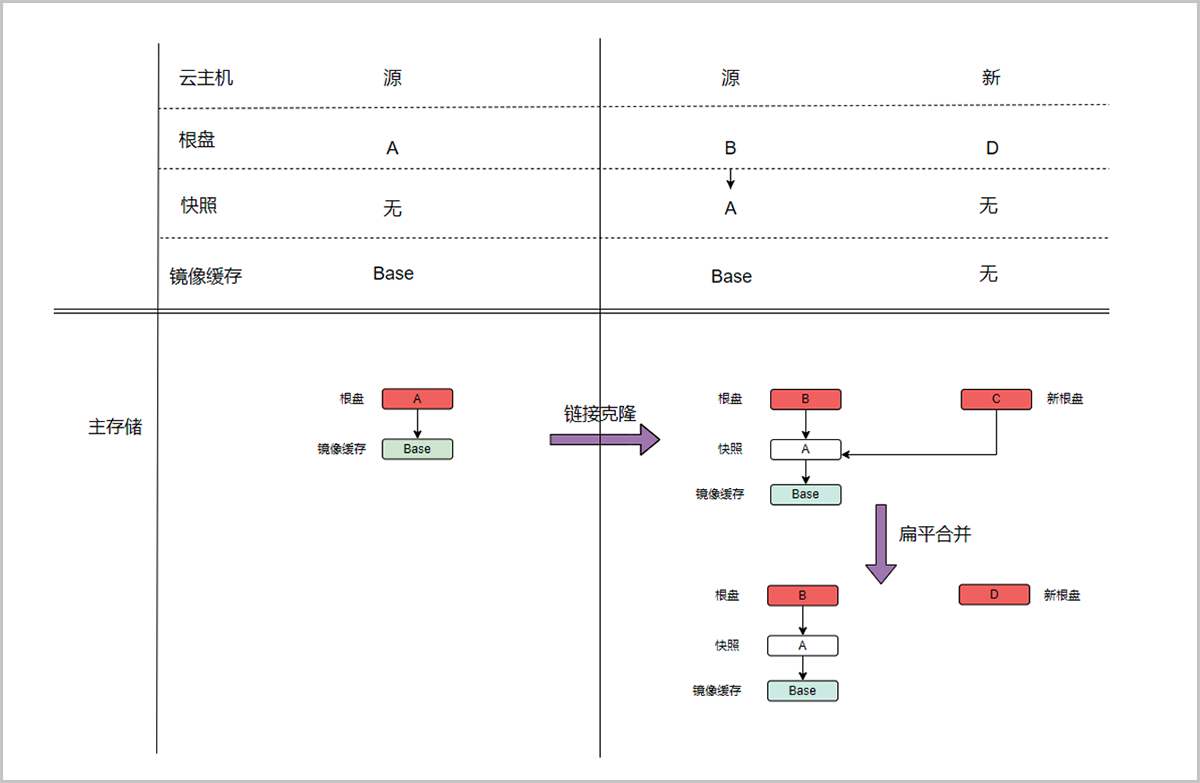
裸金属管理
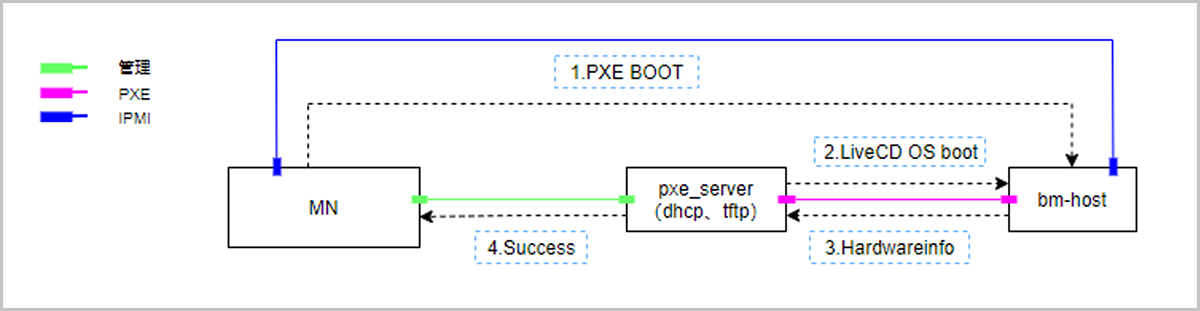
裸金属管理的网络流量模型包括管理网络、扁平网络、IPMI网络和部署网络。管理网络主要用于管理云平台相关的硬件资源。扁平网络主要用于裸金属主机的业务网络,对外提供应用服务。IPMI网络用于管理节点对裸金属设备与裸金属主机的开关机、重启、获取硬件信息等操作。部署网络用于PXE服务器通过DHCP服务下发IP地址以及通过TFTP服务传输镜像。
如图 1所示:
图 1. 裸金属管理网络拓扑
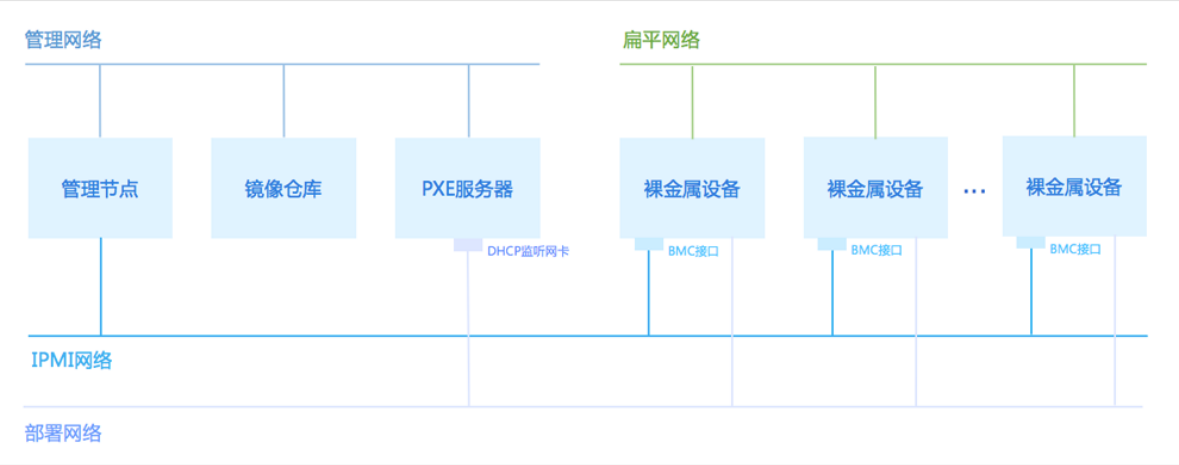
裸金属管理核心包括硬件信息获取和裸金属设备无人值守部署。
管理节点通过PXE服务器指定裸金属设备通过PXE启动。PXE服务器封装DHCP、TFTP和镜像存储服务,在裸金属设备PXE启动后通过DHCP获得IP地址,随后到TFTP服务器上,下载pxelinux.0和引导文件,并把内核加载至内存中执行,引导进LiveCD系统。在LiveCD系统中执行检测脚本,将裸金属设备的硬件信息回传至管理节点。根据回传的硬件信息,对裸金属设备设置预配置模板,包括:分区信息、设置网卡Bond、IP地址等。选择一个待安装的操作系统ISO,即可部署裸金属主机。重启裸金属设备至PXE启动,PXE部署服务器会预先下载待安装操作系统ISO,裸金属设备根据预设好的配置模板实行无人值守部署,部署完毕后会自动根据预配置模板配置网卡等信息,至此裸金属主机配置完毕。
为更好地运维裸金属主机,PXE服务器可下发裸金属监控服务,实现裸金属主机内部数据的实时监控,包括:CPU、内存、磁盘容量、磁盘IO、网卡等信息。
如图 2所示:
图 2. 裸金属管理硬件拓扑
弹性裸金属管理
弹性裸金属管理可为应用提供专属物理服务器,保障核心应用的高性能和稳定性,并结合云平台资源的弹性优势,实现灵活申请,按需使用。弹性裸金属管理融合物理机和云主机各自优势,业务应用不仅可以使用物理机超强超稳的计算能力,而且可以使用云平台内主存储、三层网络等资源。避免虚拟化开销的同时,突破云资源与物理资源的边界,提高云资源的可用性,特别适合部署传统的非虚拟化场景应用。
如图 1所示:
图 1. 裸金属发展历史
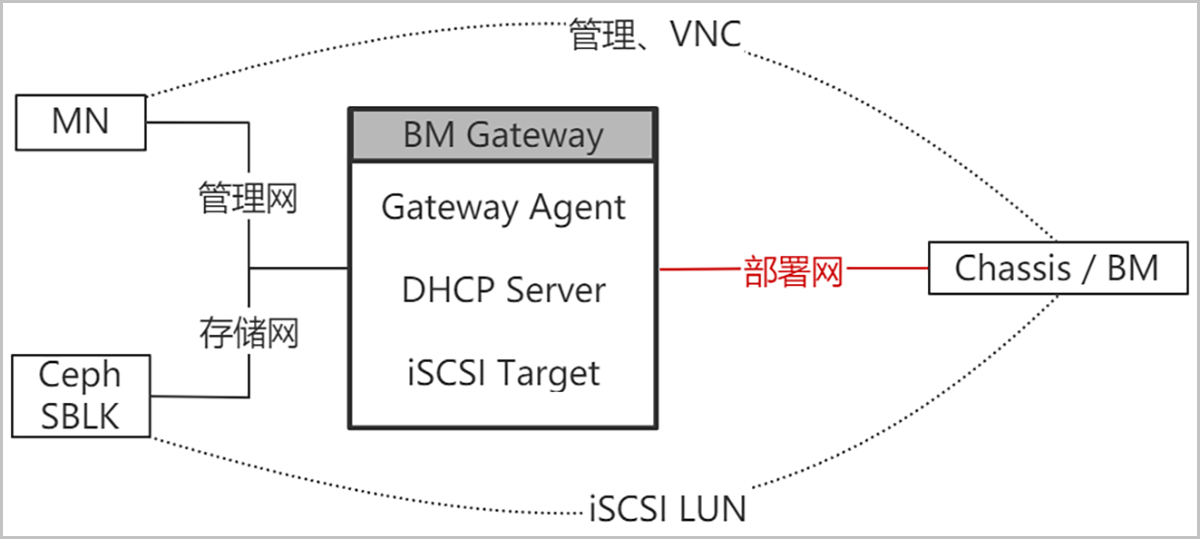
弹性裸金属架构
弹性裸金属包含以下组件:
- 存储网络:与主存储通信使用的网络。
- 部署网络:创建弹性裸金属实例时,用于PXE流程及下载镜像的专属网络。
- 管理网络:云平台管理节点通过该网络对节点进行管控,该网络与IPMI网络需互通。
- IPMI网络:服务器IPMI网络。
- 管理节点:云平台管理节点。
- 网关节点:云平台和弹性裸金属实例的流量转发节点,提供iPXE服务、DHCP服务等,可通过网关节点为弹性裸金属实例下发配置。通过网关节点接管主存储,并为弹性裸金属实例分配主存储。一个网关节点只能加载到一个弹性裸金属集群。
- 弹性裸金属集群:为裸金属节点提供单独的集群管理。
- 弹性裸金属实例:性能媲美物理服务器的云实例,结合云平台资源的弹性优势,实现灵活申请,按需使用。
- 弹性裸金属规格:弹性裸金属实例涉及的CPU、内存、CPU架构、CPU型号等规格定义。
- 裸金属节点:用于创建弹性裸金属实例,通过BMC接口以及IPMI配置进行唯一识别。
- 主存储:用于存储云主机磁盘文件(包括:根云盘、数据云盘、根云盘快照、数据云盘快照、镜像缓存等)的存储服务器。
如图 1所示:
图 1. 弹性裸金属架构

获取硬件信息
为获取裸金属节点硬件信息,管理节点会使用IPMI来引导裸金属节点从网络启动。裸金属节点启动过程中,通过PXE加载位于网关节点上的一个LiveCD系统,并通过系统中预置的脚本来获取裸金属节点硬件信息,同时把硬件信息返回给管理节点。
如图 1所示:
图 1. 获取硬件信息流程图
裸金属节点的云盘启动和控制台
裸金属节点支持使用本地磁盘或云盘作为启动源。在使用本地磁盘启动场景下,可支持使用本地系统纳管或使用平台镜像部署本地系统的方式。在使用云盘启动场景下,云盘的存储资源主要由Shared Block主存储或Ceph主存储提供。因此可兼具云平台资源弹性以及本地磁盘稳定I/O与高吞吐优势。下图实线代表实际架构,虚线代表逻辑实现。
裸金属实例的云盘启动主要依赖于裸金属网关节点上的iPXE及iSCSI Target服务实现。当创建裸金属实例选择镜像后,镜像会先被下发到云平台主存储作为镜像缓存,然后基于镜像缓存创建出裸金属对应的云盘。在网关节点上,云盘会被映射成iSCSI Target并通过部署网络暴露给裸金属节点,作为裸金属实例的根盘或数据盘。最终裸金属节点通过PXE启动,加载网关节点上暴露出来的根盘和数据盘从而实现云盘启动。
如图 1所示:
图 1. 裸金属节点的云盘启动
要实现在云平台上打开裸金属实例的控制台以及裸金属实例的实时监控,需要在裸金属实例系统中安装相应的裸金属代理服务程序。裸金属网关节点上的Nginx代理服务将来自管理节点的请求转发至裸金属代理服务程序,再将来自裸金属代理服务程序的反馈转发回管理节点,以此来实现控制台功能。
数据保护
快照管理
云平台支持ROW(Redirect-On-Write,写时重定向)以及COW(Copy-On-Write)快照机制。
- 集中式存储快照机制:本地存储/NFS/Shared Mount Point/Shared Block使用QCOW2外部快照(External Snapshot),属于ROW快照机制的一种。
- 分布式存储快照机制:企业版Ceph使用ROW快照技术。自研分布式存储使用COW快照。
集中式存储快照机制
关于QCOW2外部快照的说明。
1)快照链与快照树
通常一块磁盘对应一条快照链,支持对一块磁盘创建一棵快照树,快照树的每一个分支都是一条快照链。
如图 1所示:
图 1. 快照树
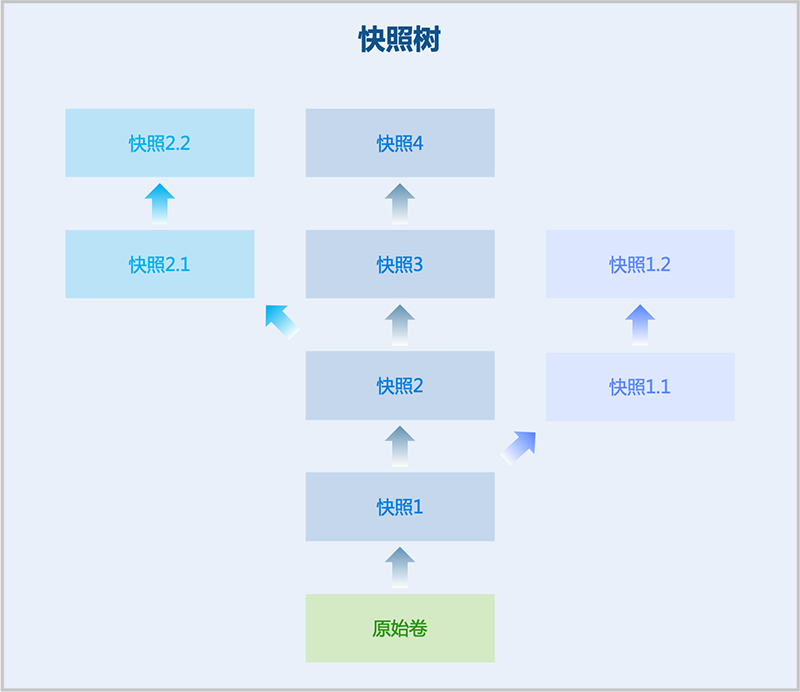
快照树包括以下信息:
说明:
- 快照链:磁盘的一组快照组成的关系链,快照树的每一个分支都是一条快照链。
- 快照节点:快照链中的一个节点,表示磁盘的一份快照。
- 快照容量:快照占用的存储空间。支持查看快照树中所有快照的总容量,以及单个快照节点的容量。
- 对于非Ceph存储,系统默认每条快照链最多有128个节点,用户可在全局设置中,通过修改云盘快照增量的最大数目自行设置快照链的最大长度。对于Ceph存储,单盘最大快照数量为32,包括手动创建及自动创建的快照。
- 快照链长度达到上限后:
- 若继续创建自动快照,系统会自动删除最早的自动快照。
- 若继续创建手动快照,用户需手动删除不需要的快照。
- 在生产环境中,建议单块磁盘的快照数量尽量控制在5以内,快照过多会影响云主机/云盘的IO性能、数据安全以及主存储容量。如需长期备份,建议使用灾备服务。
2)创建快照
当一个外部快照被创建,实质是新建一个空白的qcow2文件,该空白文件的backing file指向旧qcow2文件,旧qcow2文件置为只读,于是旧qcow2文件自身成为一个快照,后续只对新qcow2文件写入数据。
2.1)基于backing file创建单条快照链。如图 2所示:
图 2. 创建快照 单链
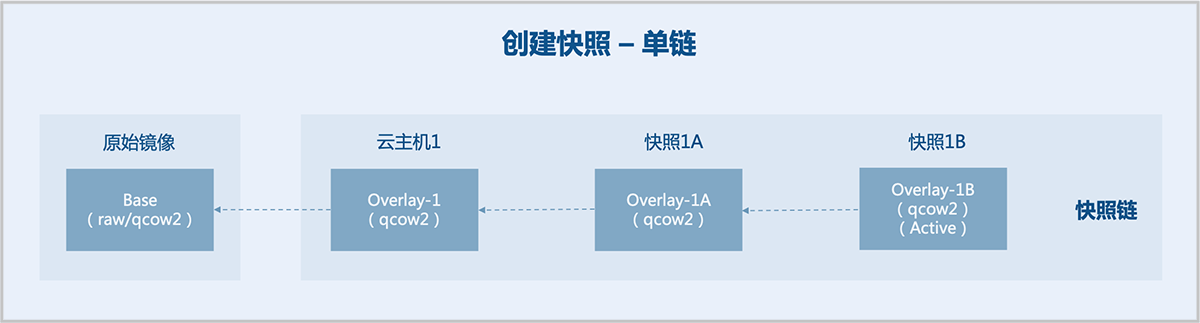
假定已有一个原始镜像(Base),以该原始镜像为模板创建云主机1,对云主机1依次创建快照1A、快照1B。
- 原始镜像:一个已制作好的磁盘镜像文件,包含完整的操作系统以及引导程序,作为Base(只读)。
- 云主机1:新建空白文件Overlay-1,backing file指向Base,Base保持为只读,于是Base成为一个快照,后续只对Overlay-1写入数据。
- 快照1A:新建空白文件Overlay-1A,backing file指向Overlay-1,Overlay-1置为只读,于是Overlay-1成为一个快照,后续只对Overlay-1A写入数据。
- 快照1B:新建空白文件Overlay-1B,backing file指向Overlay-1A,Overlay-1A置为只读,于是Overlay-1A成为一个快照,后续只对Overlay-1B写入数据。云主机1使用的是快照链内最后一个快照1B对应的磁盘文件,快照1B为Active。
2.2)基于backing file创建多条快照链。如图 3所示:
图 3. 创建快照 多链
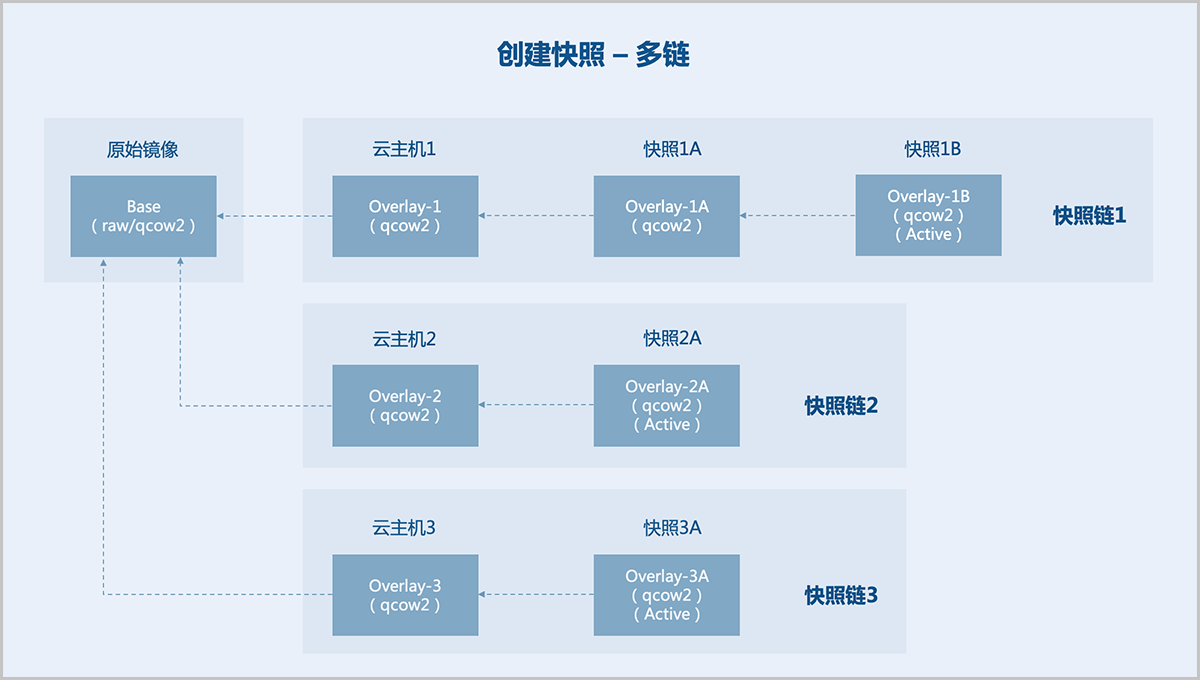
假定已有一个原始镜像(Base),以该原始镜像为模板创建云主机1、云主机2、云主机3,对云主机1依次创建快照1A、快照1B,对云主机2创建快照2A,对云主机3创建快照3A。
- 原始镜像:一个已制作好的磁盘镜像文件,包含完整的操作系统以及引导程序,作为Base(只读)。
- 快照链1:
- 云主机1:新建空白文件Overlay-1,backing file指向Base,Base保持为只读,于是Base成为一个快照,后续只对Overlay-1写入数据。
- 快照1A:新建空白文件Overlay-1A,backing file指向Overlay-1,Overlay-1置为只读,于是Overlay-1成为一个快照,后续只对Overlay-1A写入数据。
- 快照1B:新建空白文件Overlay-1B,backing file指向Overlay-1A,Overlay-1A置为只读,于是Overlay-1A成为一个快照,后续只对Overlay-1B写入数据。云主机1使用的是快照链1内最后一个快照1B对应的磁盘文件,快照1B为Active。
- 快照链2:
- 云主机2:新建空白文件Overlay-2,backing file指向Base,Base保持为只读,后续只对Overlay-2写入数据。
- 快照2A:新建空白文件Overlay-2A,backing file指向Overlay-2,Overlay-2置为只读,于是Overlay-2成为一个快照,后续只对Overlay-2A写入数据。云主机2使用的是快照链2内最后一个快照2A对应的磁盘文件,快照2A为Active。
- 快照链3:
- 云主机3:新建空白文件Overlay-3,backing file指向Base,Base保持为只读,后续只对Overlay-3写入数据。
- 快照3A:新建空白文件Overlay-3A,backing file指向Overlay-3,Overlay-3置为只读,于是Overlay-3成为一个快照,后续只对Overlay-3A写入数据。云主机3使用的是快照链3内最后一个快照3A对应的磁盘文件,快照3A为Active。
2)合并快照
外部快照之间互相依赖(每一个overlay依赖它的backing file),每个快照保存有相应数据,不可直接删除某个快照来缩短链长度。外部快照可通过向下合并(Blockcommit)或向上合并(Blockpull)两种方式来缩短链长度。
2.1)向下合并(Blockcommit)
在同一条快照链内,支持将overlays合并至backing files。
如图 4所示:
图 4. 向下合并
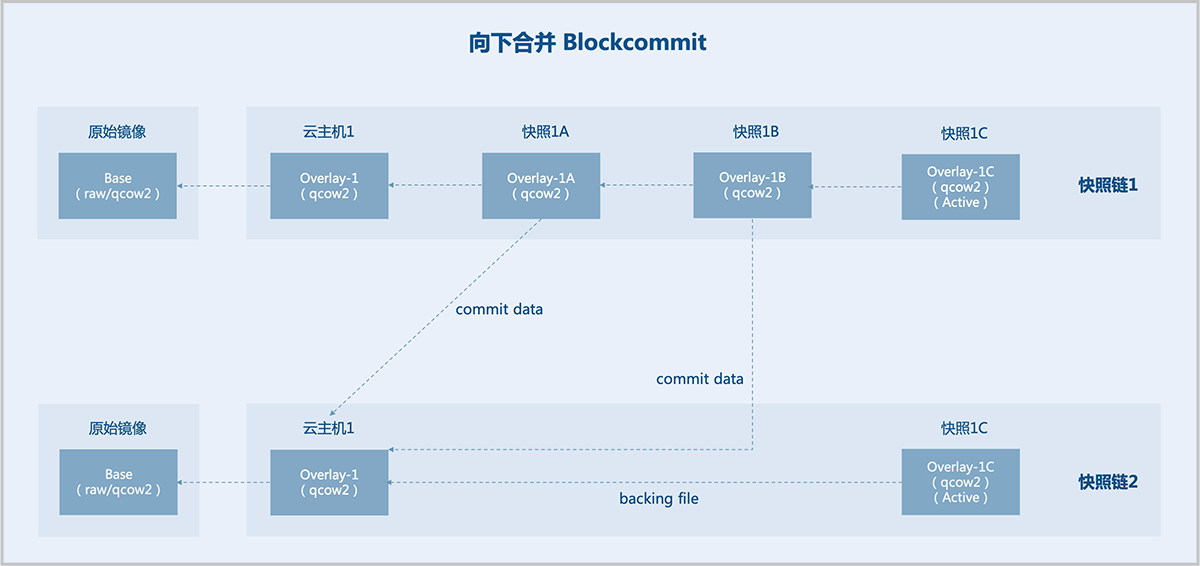
假定已有一个原始镜像(Base),基于Base创建云主机1,并对云主机1创建3个互相依赖的外部快照,即:快照1A、快照1B、快照1C。现将快照1A、快照1B向下合并至云主机1,于是快照1C(Active)的backing file直接指向云主机1,快照链缩短。快照1A、快照1B不再有用,删除即可。
2.2)向上合并(Blockpull)
在同一条快照链内,支持将backing files合并至overlays。
如图 5所示:
图 5. 向上合并
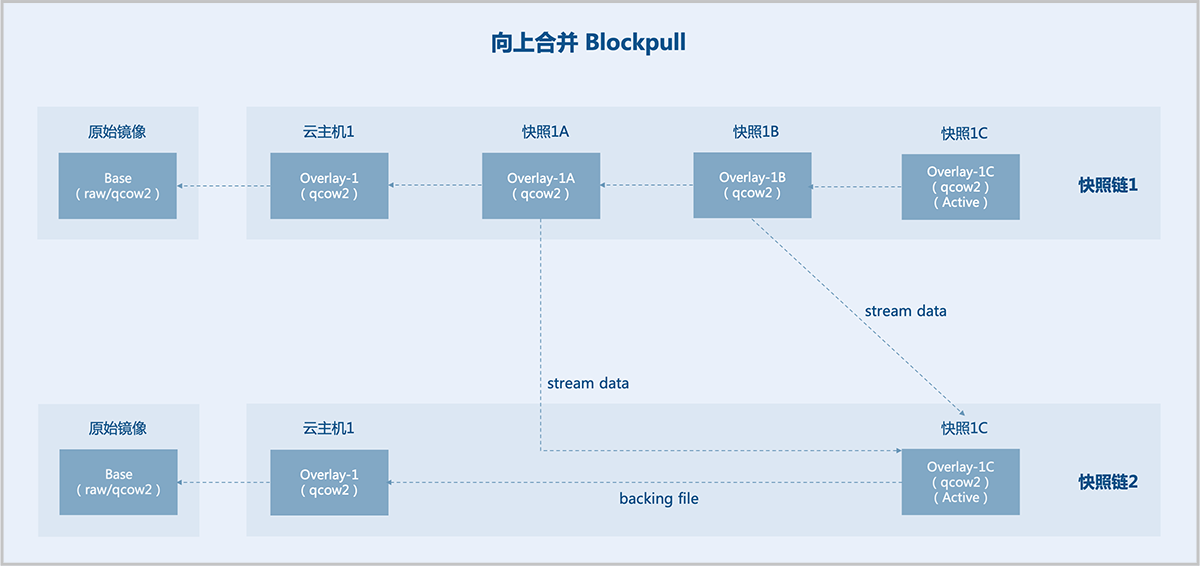
假定已有一个原始镜像(Base),基于Base创建云主机1,并对云主机1创建3个互相依赖的外部快照,即:快照1A、快照1B、快照1C。现将快照1A、快照1B向上合并至快照1C(Active),于是快照1C(Active)的backing file直接指向云主机1,快照链缩短。快照1A、快照1B不再有用,删除即可。
分布式存储快照机制
企业版Ceph使用ROW快照技术。自研分布式存储使用COW快照,详情参考:COW快照。
灾备管理
数据备份
支持基于Qemu块设备层的数据备份,各类型主存储上的云主机均支持备份。备份类型可分为:全量备份、增量备份。全量备份包含完整的数据集合,增量备份仅包含自上一次备份后所有更新的数据集合。全量备份和增量备份均仅备份真实数据。
默认情况下,备份策略是在首次全量备份后,每63个增量备份的下一次备份就会自动执行一次全量备份。这是因为增量备份之间有依赖关系,在做新的一次全量备份后,才能对之前的增量备份进行删除。这里增量备份的数量可以通过全局配置修改。实际上,系统内部有更智能灵活的应对策略来决定使用哪种合适的备份方式,以确保备份数据的安全可靠。
数据备份可分为三部分:数据复制、数据传输、数据保存。
数据复制
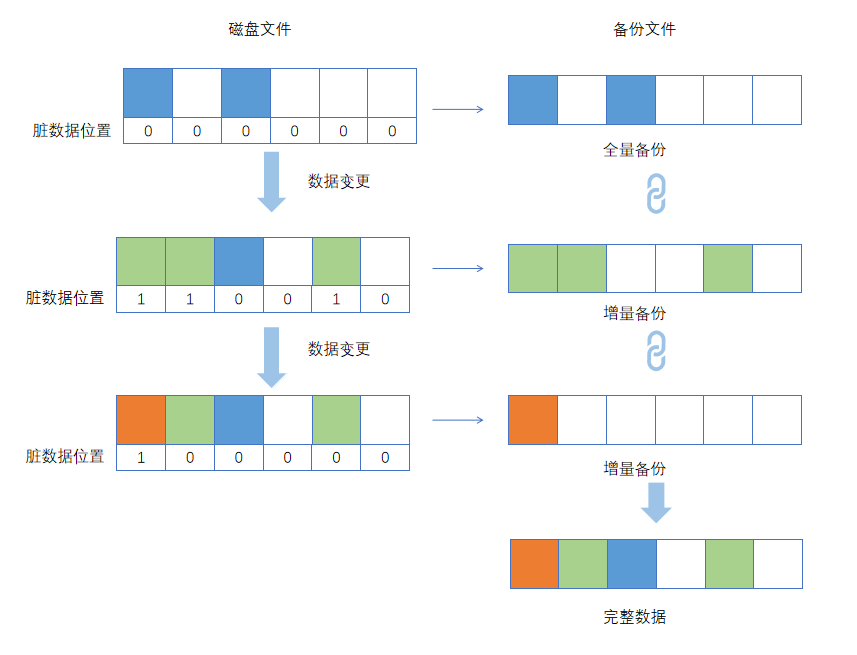
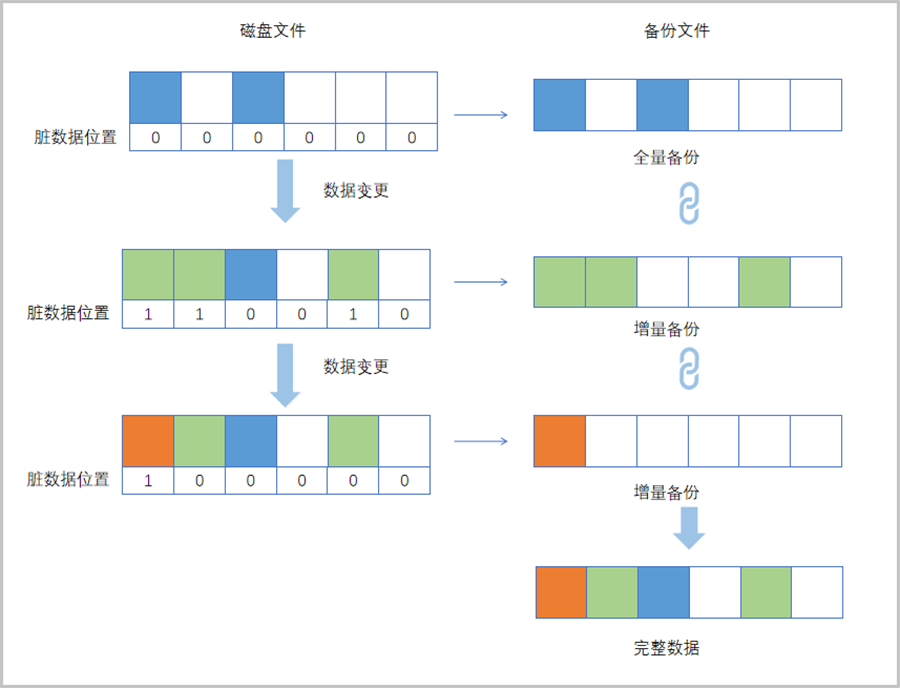
备份模块利用Qemu块设备层的脏数据跟踪功能(dirty bitmap)实现备份数据的导出。
云主机磁盘文件数据发生变化的位置被称为脏数据位置,dirty bitmap记录自上次备份后,虚拟磁盘文件上产生脏数据的所有位置记录,根据位置记录,就可导出自上次备份后所有被修改过的数据,即增量的备份数据。
最终全量备份文件和各个增量备份文件会产生一个完整的备份链,保存完整的数据。dirty bitmap存在于Qemu进程的内存中,云主机重启后就会丢失这部分信息,因此当云主机重启后的下一次备份,系统会自动选择全量备份。
如图 1所示:
图 1. dirty bitmap
数据传输
针对不同的虚拟化组件版本,支持两套不同的实现方案,主要区别在备份数据的传输上。
第一种方案。使用sshfs在计算节点上挂载远程备份服务器的备份目录,然后把备份数据导入备份服务器。sshfs是一个简单的fuse over ssh方案,数据链路由ssh会话加密,每个备份任务有单独的sshfs链路。
如图 1所示:
图 1. Data over sshfs

第二种方案。在备份服务器上使用nbd模块导出一个备份磁盘,然后在计算节点通过qemu的块设备任务(block-job),直接把备份数据导入到备份磁盘中。
如图 2所示:
图 2. Data over nbd

数据保存
备份服务器支持多种存储介质,包括:SAN、NAS、磁盘阵列以及带库等。
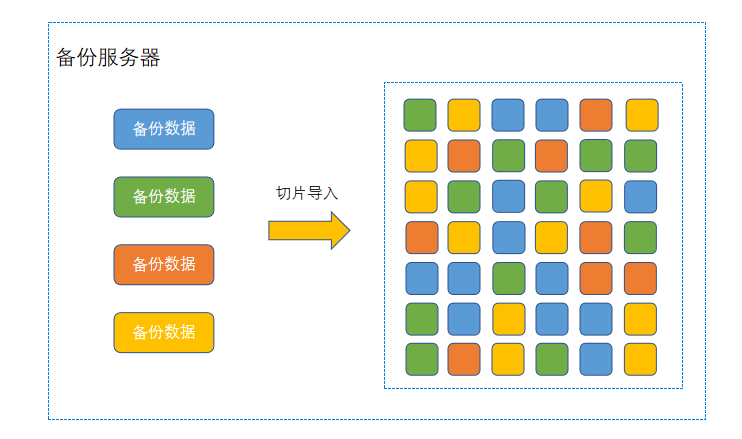
备份数据在备份服务器中是切片去重存放的,备份数据会被切分成64MB大小的数据块,然后计算hash,建立索引。拥有相同hash的数据块不会被存储多份。
如图 1所示:
图 1. 数据切片保存
数据恢复
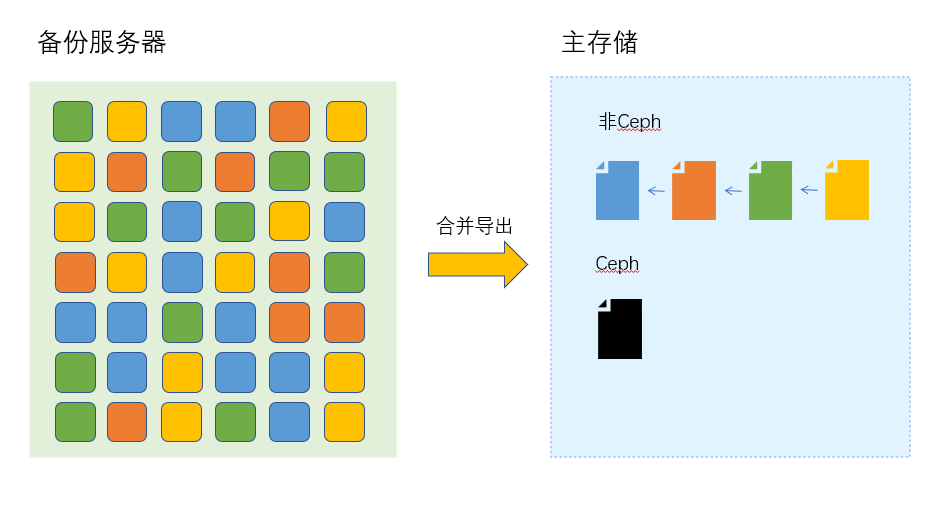
从本地备份数据恢复云主机/云盘,会把备份服务器上的切片数据合并导入主存储中,合并后的备份恢复数据会在非Ceph主存储上以磁盘链的形式存放,Ceph主存储上会把磁盘链合并成单个磁盘文件存放。 如果是新建恢复,则恢复到主存储的磁盘数据会被当作镜像缓存来创建新云主机/云盘;如果是覆盖恢复,则会把恢复到主存储的磁盘路径更新到当前云主机/云盘的数据库记录中,随后删除旧的云主机/云盘文件。
如图 1所示:
图 1. 数据恢复
CDP服务
数据备份
数据复制
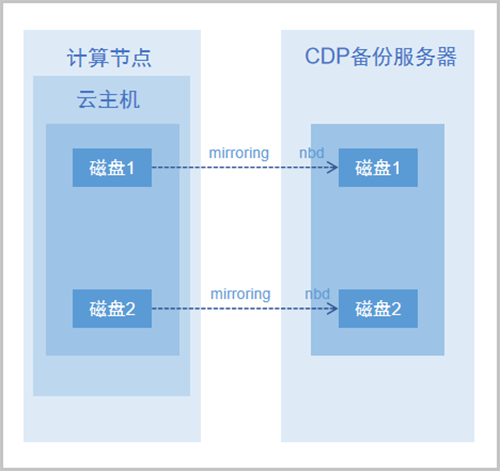
CDP模块利用Qemu块设备层的脏数据追踪功能(dirty bitmap)以及drive-mirror实现备份数据的跟踪与导出。
云主机磁盘文件数据发生变化的位置被称为脏数据位置,dirty bitmap记录自上次备份后,虚拟磁盘文件上产生脏数据的所有位置记录,根据位置记录,就可导出自上次备份后所有被修改过的数据,即增量的备份数据。
云平台提供自适应的备份导出策略,后台会根据不同情况选择导出增量数据还是全量数据。例如,由于dirty bitmap存在于Qemu进程的内存中,云主机重启后就会丢失这部分信息,因此当云主机重启后云平台会自动选择导出全量备份数据。
如图 1所示:
图 1. dirty bitmap
导出的备份数据通过drive-mirror被导入保存至CDP备份服务器上的空白qcow2磁盘文件中。空白的磁盘文件在创建CDP任务时会预先被创建出来,再通过nbd协议导出成一个网络上可访问的块设备,这样CDP备份任务就可把云主机的云盘数据持续导入至CDP备份服务器。
如图 2所示:
图 2. drive-mirror
数据恢复点
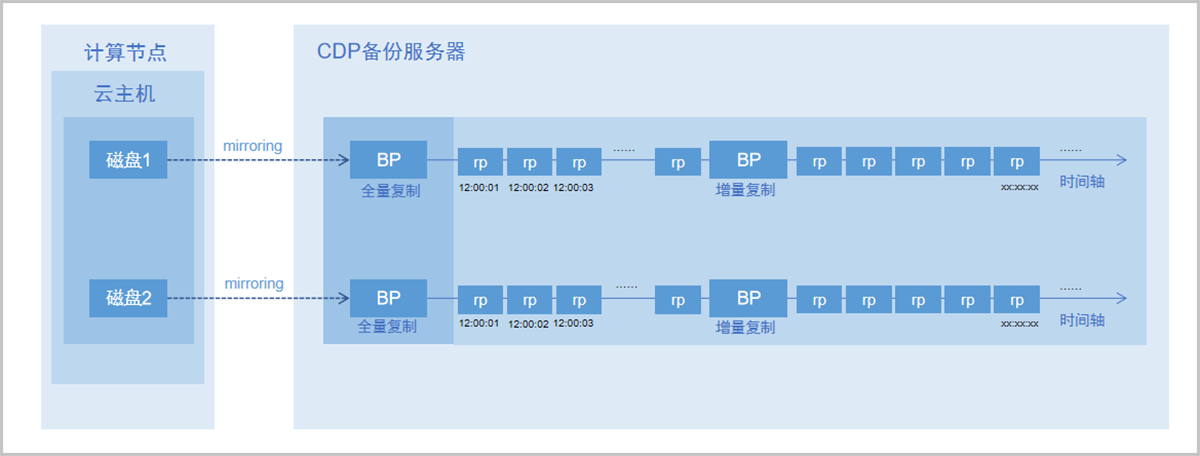
云主机数据传输至CDP备份服务器上后,以qcow2磁盘文件形式存放。针对qcow2磁盘文件会有一个Qemu存储服务来提供各种保护策略下的数据恢复点。
CDP任务的数据恢复点由BP点和RP点组成。BP点以粗粒度形式按时间定期生成外部快照(默认20分钟),RP点则可根据实际设置的CDP保护策略,最快以1秒1次记录IO变化来生成恢复点。
CDP备份服务器首先会对云主机数据进行一次全量复制生成基本BP点,后续通过Qemu持续捕获I/O数据变化,将每次变化的I/O数据打上时间戳生成RP点并保存下来。恢复点的生成都是在CDP备份服务器上做的,对原云主机无任何影响。
如图 1所示:
图 1. BP点与RP点
数据恢复
找回文件
当因误删云主机丢失部分文件时,CDP备份数据支持快速浏览备份文件,实现文件级别的数据恢复。用户可选择任意恢复点浏览恢复点中的文件和数据,也可预览文件内容,确认文件包含所需数据后,再选择下载文件或锁定恢复点做后续的数据恢复。
如图 1所示:
图 1. 找回文件

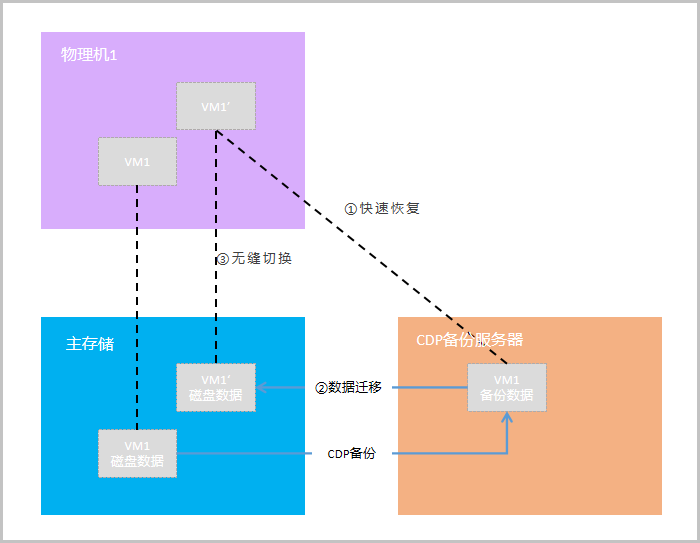
快速恢复
当云主机业务发生故障或遭受病毒需做整机数据恢复时,CDP备份数据可支持秒级快速恢复,满足业务快速恢复上线的需求。
快速恢复主要包含两个步骤:云主机快速拉起、云主机数据迁移。
在CDP备份服务器上,云主机备份数据以qcow2磁盘格式存放。为实现快速拉起,首先会将备份的qcow2磁盘通过nbd以网络块设备方式映射出来,然后云主机实例在计算节点上通过nbd来访问备份服务器上的云主机备份磁盘,此时云主机已可正常提供业务,用户可正常读写云主机。
此时由于云主机磁盘尚未存放至主存储,后台会启动一个存储迁移任务,将备份服务器上的磁盘数据同步到主存储上,在该过程中,对云主机的修改写入均会被记录为脏页,一并同步至主存储的目标磁盘中。
当同步任务发现数据全部拷贝完成后,云主机会默认将磁盘路径动态切换成主存储的路径来访问,后台迁移过程会将云主机的所有数据均同步至主存储,并且整个过程对用户完全无感知,也不会对云主机业务产生影响。
如图 1所示:
图 1. 快速恢复
备份可靠性指标
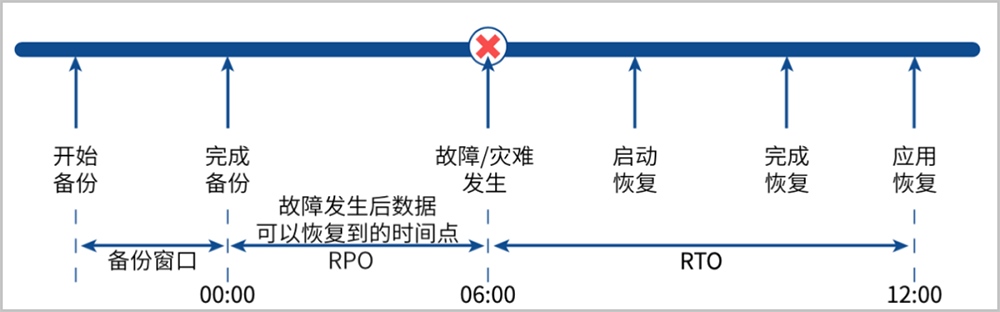
评估灾备系统可靠性有两个重要指标:RPO与RTO。RPO(Recovery Point Objective)指恢复点目标,强调灾难发生后,企业能容忍的较大数据丢失量。RTO(Recovery Time Objective)指恢复时间目标,强调发生灾难时,企业能容忍的恢复时间。
本产品CDP模块在云主机低负载情况下RPO与RTO最低均可达1秒。
如图 1所示:
图 1. RPO与RTO
运维管理
资源编排
资源编排:一款帮助云计算用户简化云资源管理和自动化部署运维的服务。通过资源栈模板,定义所需的云资源、资源间的依赖关系、资源配置等,可实现自动化批量部署和配置资源,轻松管理云资源生命周期,通过API和SDK集成自动化运维能力。
如图 1所示:
图 1. 资源编排

功能优势
- 用户只需创建资源栈模板或修改已有模板,定义所需的云资源、资源间的依赖关系、资源配置等,资源编排将通过编排引擎自动完成所有资源的创建和配置。
- 云平台提供示例模板,也可使用可视化编辑器,快速创建资源栈模板。
- 可根据业务需要,动态调整资源栈模板,从而调整资源栈以灵活应对业务发展需要。
- 如果不再需要某资源栈,可一键删除该栈及栈内所有资源。
- 可重复使用已创建的资源栈模板快速复制整套资源,无需重复配置。
- 可根据业务场景灵活组合云服务,以满足自动化运维的需求。
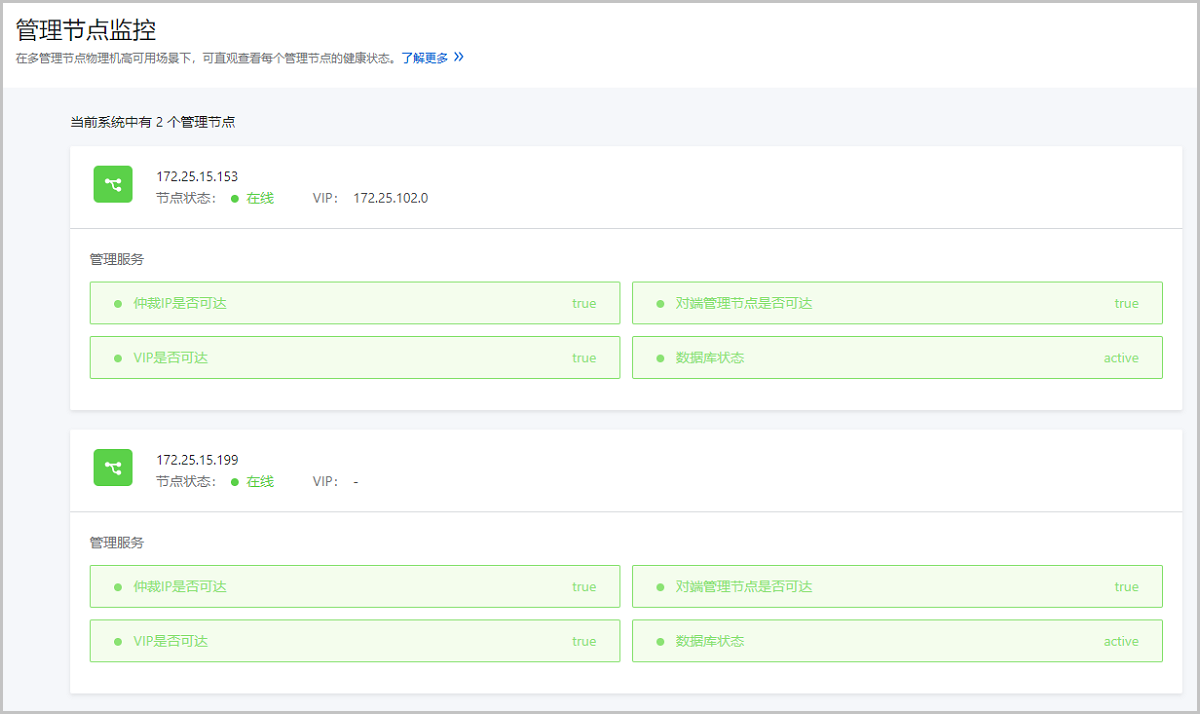
管理节点监控
在多管理节点物理机高可用场景下,可直观查看每个管理节点的健康状态。
管理节点监控支持显示多个管理节点的管理节点IP、节点状态、VIP和管理服务状态,主要包括以下管理服务:
- 仲裁IP是否可达:监控用于判断主备管理节点的仲裁IP是否可达,若不可达可能导致管理节点高可用功能失效。
- 对端管理节点是否可达:监控备管理节点是否可达,若备管理节点不可达,无法与备管理节点通信。
- VIP是否可达:监控VIP是否可达,若VIP不可达,主管理节点不能通过VIP访问UI界面。
- 数据库状态:监控数据库状态,若数据库异常或多管理节点数据库不同步,可能存在数据丢失风险,请及时恢复故障。
如图 1所示:
图 1. 管理节点监控
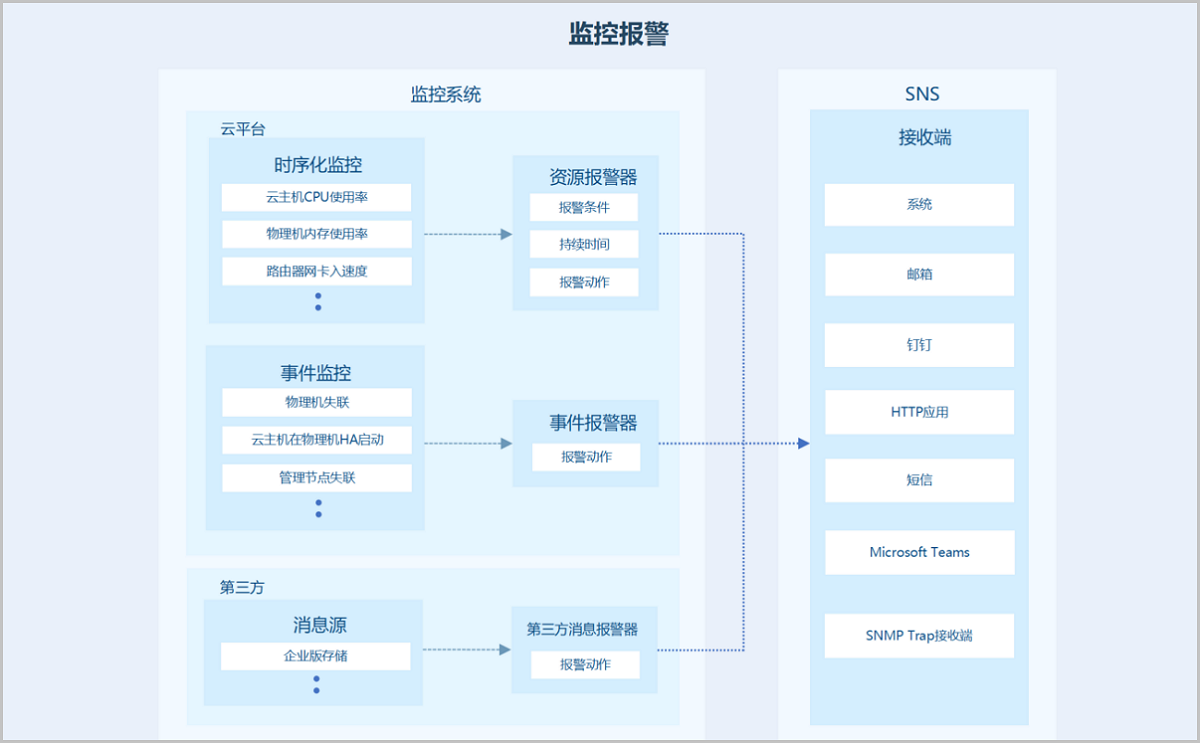
监控报警
监控报警支持对时序化数据(如资源负载数据和资源容量数据)以及系统中发生的预定义事件进行监控,并通过通知服务(SNS)推送报警消息至指定的通知对象。支持资源报警器、事件报警器和扩展报警器三种报警器类型,支持系统/邮箱/钉钉/HTTP应用/短信/Microsoft Teams通知对象类型,部分资源报警器需安装agent才能使用。
如图 1所示:
图 1. 监控报警功能框架
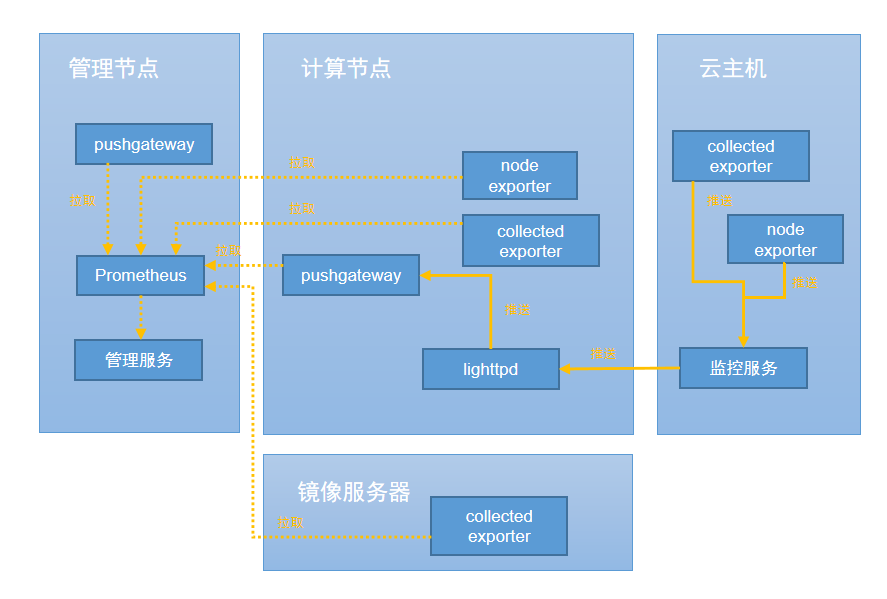
时序监控数据由Prometheus提供,在监控业务数据时,需将不同数据汇总,由Prometheus统一收集。
在Prometheus架构设计中,Prometheus服务器并不直接服务监控特定目标,其主要负责数据的收集、存储,并对外提供数据查询支持。因此,为监控到样本数据,如:物理机CPU使用率,需通过Exporter周期性采集监控样本。云平台针对不同监控目标,分别使用拉取模式和推送模式来采集监控数据。当物理机或云主机外部监控作为监控目标时,Prometheus服务会周期性使用拉取模式采集物理机上Exporter收集到的数据。另外,由于网络问题或安全问题,Prometheus无法直接访问到云主机内部或裸金属服务器内部。此时需一个pushgateway作为中间者完成中转工作。采集端仍通过Exporter采集监控数据, 并采用推送方式周期性将数据推送给pushgateway,随后Prometheus采用拉取方式采集pushgateway数据,从而完成数据的统一收集。
如图 2所示:
图 2. 监控数据采集原理
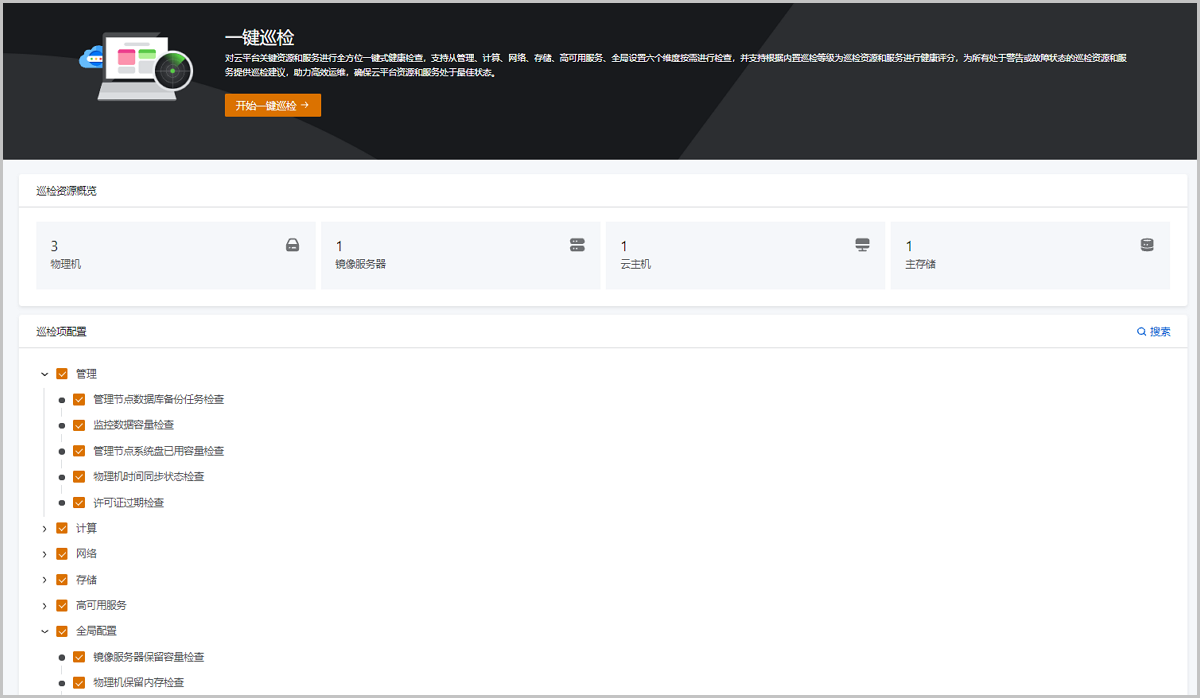
一键巡检
一键巡检支持对关键资源和服务进行全方位一键式健康检查,并根据巡检结果为巡检资源和服务进行健康评分,同时提供巡检建议和巡检报告,助力高效运维,确保云平台资源和服务处于最佳状态。一键巡检适用于需要对云平台进行集中高效运维场景。
一键巡检提供平台、计算、网络、存储、全局设置五大类别巡检项,支持对管理节点、物理机和云主机、镜像服务器和主存储、物理/虚拟网络和网卡、许可证等云平台关键资源和服务进行巡检:
- 平台:检测云平台基础服务和运行状态。
- 计算:检测云平台物理计算资源和虚拟化计算资源使用状况和运行状态。
- 网络:检测云平台物理网络和虚拟化网络配置和状态。
- 存储:检测云平台物理存储资源使用状况和运行状态。
- 全局设置:检测云平台全局性重要资源的配置情况。
用户可自定义根据类别选择巡检项进行一键巡检,启动巡检后,云平台将对所选择的巡检项涉及的资源或服务进行健康检查。一键巡检内置健康评分机制,支持对所巡检的资源或服务的健康状态进行量化评分,帮助用户直观准确把握云平台整体运行状态。
如图 1所示:
图 1. 一键巡检
运营管理
租户管理
租户管理为企业用户提供组织架构管理,以及基于项目的资源访问控制、工单管理、独立区域管理等功能。
租户管理以单独的功能模块形式提供,需提前购买租户管理模块许可证,且需在购买云平台许可证基础上使用,不可单独使用。
功能框架
租户管理包括以下子功能:平台管理、项目管理、工单管理、独立区域管理、第三方认证。
1)平台管理:
为高效管理云平台,平台成员(平台管理员/普通平台成员)可配合admin共同维护云平台。
2)项目管理:
以项目为导向进行资源规划,可为一个具体项目建立独立的资源池。通过对项目生命周期进行管理(包括确定时间、确定配额、确定权限等),以更细粒度更自动化的方式提高云资源利用率,同时加强项目成员间的协作性。
3)工单管理:
为高效为每个项目提供基础资源支持,项目成员(项目负责人/项目管理员/普通项目成员)可对云平台资源提出工单申请,根据每个项目自定义工单审批流程,对工单进行审批,最终由admin/项目负责人/部门运营管理员/自定义审批人员进行审批,支持申请云主机、删除云主机、修改云主机配置、修改项目周期和修改项目配额五种工单类型。
4)独立区域管理:
区域通常对应某地的一个真实数据中心。在对区域进行资源隔离的基础上,可对每个区域指定相应的区域管理员,实现各地机房的独立管理,同时admin可对所有区域进行巡查和管理。
5)第三方认证:
云平台提供第三方登录认证服务,支持无缝接入第三方登录认证系统,对接后第三方用户可一键免密登录云平台,便捷使用云资源。已支持对接AD/LDAP/OIDC/OAuth2/CAS协议认证系统。
功能优势
1)功能全面:为企业用户提供组织架构管理,以及基于项目的资源访问控制、工单管理、独立区域管理等功能。
2)灵活易用:以多层级组织架构方式管控企业中不同角色的操作权限,角色权限管控细粒度至API级别。
3)节约成本:企业内部有各自行政部门,在传统IT系统中,一般会根据行政部门划分资源,设立权限。在企业上云大环境中,实现云上行政部门管理,最大程度节约管理成本。
计费管理
云平台提供准公有云计费方式体验,将各资源计费单价汇总为一份计费价目,绑定到项目/账户即可按量生成计费账单。目前支持计费的资源类型包括:处理器、内存、根云盘、数据云盘、GPU设备、公网IP(云主机IP)、公网IP(虚拟IP)、弹性裸金属实例。
功能优势
- 通过计费价目形式,对一组资源的计费单价进行集中高效管理。
- 计费价目包含多个资源的计费单价,且根云盘/数据云盘支持按磁盘性能单独设置计费单价。
- 计费价目设置完成后,以项目/账户为单位实时生成计费账单。将项目加载到部门,以部门为单位生成统计账单。
- 支持创建多份计费价目,项目/账户使用各自计费价目进行计费,同一计费价目支持绑定多个项目/账户。
- 支持自定义定时输出账单明细,以资源为粒度查看计费详情。
- 支持在全局设置中修改计费货币符号,更换货币单位显示符号。包括:人民币 ¥、美元 $ 、欧元 € 、英镑 £ 、澳元 A$ 、港元 HK$ 、日元 ¥ 、瑞士法郎 CHF 、加拿大元 C$、印尼卢比 Rp。
可靠性
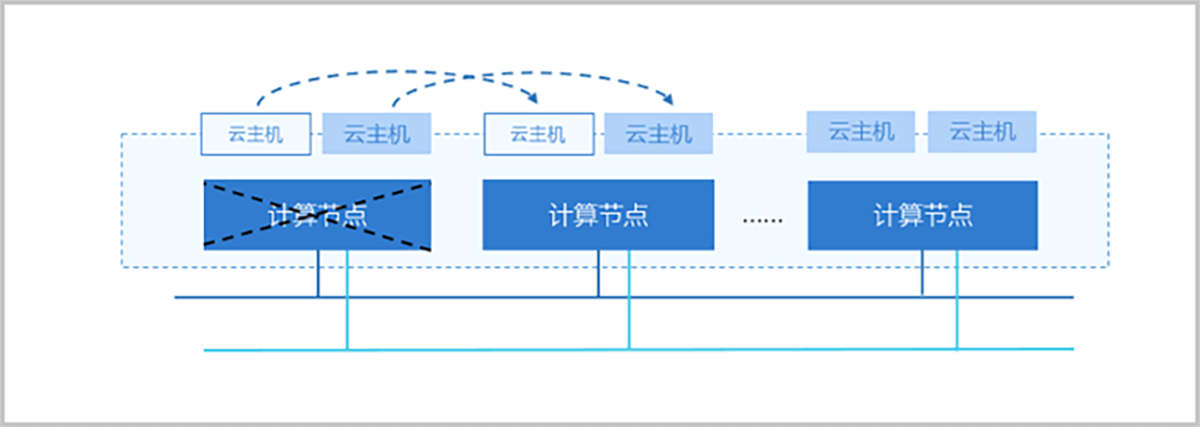
计算高可用
云平台采用基于KVM的硬件虚拟化技术,将一组硬件服务器虚拟化为一个逻辑资源池,并以集群进行划分管理。云平台持续对集群内所有物理主机与云主机运行状况进行检测。一旦某台物理机发生故障,云平台管理节点会持续进行检测,确定此物理机宕机后,会立即在集群内另一台物理机上重启所有受影响的云主机,保障业务连续性。云平台计算高可用无需专门的备用硬件或集成其它软件,就可将停机时间和IT服务中断时间降至最低程度,并且避免了因特定操作系统或特定应用程序做故障切换带来的成本和复杂性。
如图 1所示:
图 1. 计算高可用
存储高可用
这里主要介绍自研分布式存储的高可用性。详情参考:
网络高可用
虚拟网络高可用
扁平网络通过网桥连接到服务器Bond口,高可用依赖于服务器网卡。
VPC网络采用定制的路由器镜像创建一台云主机作为VPC路由器,三层流量均经过VPC路由器进行转发。一旦VPC路由器所在物理机宕机,数分钟之后会在其他正常节点重新启动,保证业务连续性。不同租户使用不同的VPC路由器,即使有物理机宕机,也仅影响其上运行VPC路由器的租户数分钟,对其他租户无任何影响,缩小故障影响范围。
VPC路由器双机主备
VPC路由器支持双机主备模式,可在创建VPC路由器时按需选择。主备路由器会不断进行心跳检测,若主路由器发生故障,备路由器将提升为主路由器,所有流量秒级进行切换,最大程度保障业务连续性。
VPC路由器高可用组
VPC路由器高可用组主备切换基于Linux Keepalived实现。Keepalived用于检测服务器状态。若有一台Web服务器宕机或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器工作,当服务器工作正常后,Keepalived自动将服务器加入到服务器群中。这些工作全部自动完成,无需人工干涉,仅需人工做的是修复故障服务器。网络服务各自独立。
管理高可用
管理节点负责整个云平台的资源管控、监控、调度、分配和回收。管理节点若出现宕机,管理服务将不可用,直接影响到云平台的运维管理、监控报警、租户访问、自动化任务执行等,对平台或租户的运维工作产生较大影响。因此,云平台管理服务保证高可用性十分重要。
双管理节点高可用
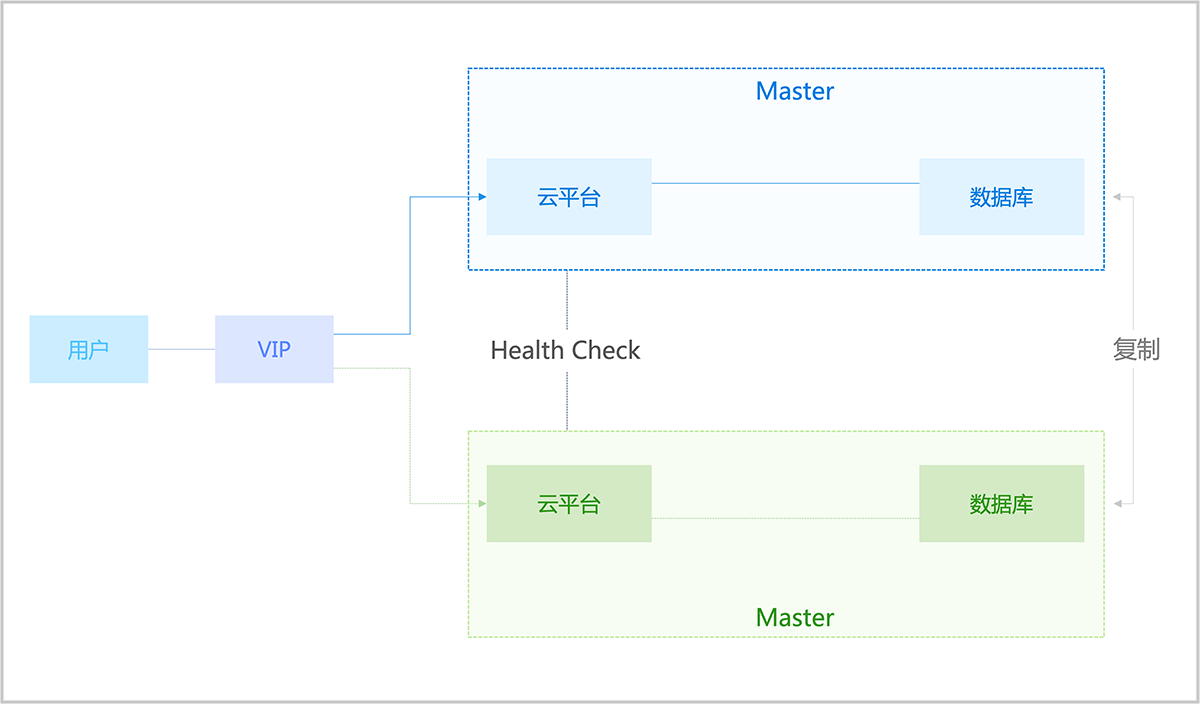
云平台提供双管理节点高可用方案,实现如下目标:
- 安装两个管理节点,其中任何一个节点掉电不影响系统工作,UI能够正常使用并执行各种任务。
- 数据库(包括MySQL和监控数据库)在掉电的节点恢复后能自动同步,无需人工参与。
- 系统能长时间在单节点情况下工作。
- 双管理节点的部署运维和单管理节点一样简单方便。
为解决管理节点高可用难题,我们提供一个HA进程在管理节点上运行。该进程负责整个管理节点环境的初始化、配置、运维、Watchdog等功能。
- HA进程提供系统配置功能,提供命令行接口,可调用HA命令将系统配置成高可用环境。
- HA进程负责监控管理节点上的关键服务(管理节点进程、UI进程、MySQL)。当任何一个服务宕机,立即通过Keepalived触发VIP迁移,然后尝试恢复宕机服务。
- HA进程对Keepalived进程进行Watchdog,确保该进程持续运行。
- HA进程提供命令,打印出集群的健康信息。
- 引入一个网关做仲裁,避免双管理节点的脑裂问题。
如图 1所示:
图 1. 双管理节点HA机制
管理节点监控
管理节点监控支持显示多个管理节点的管理节点IP、节点状态、VIP和管理服务状态。详情参考:管理节点监控。
管理节点监控数据采集
管理节点监控数据采集机制,详情参考:监控报警。
系统配置备份
系统配置备份对于云平台来说至关重要。当云平台发生异常,或相关配置丢失时,可通过系统配置的备份数据进行恢复。
云平台提供备份服务模块,支持本地灾备、异地灾备、公有云灾备多种灾备方案,详情参考:灾备服务。
业务高可用
云主机调度策略
云主机调度策略可为云主机分配物理机资源编排策略,用于保障业务高性能和高可用。详情参考:云主机调度策略。
双机热备
对于需要实时在线的业务系统,支持通过镜像/快照、CDP等技术,部署主备业务系统,在主业务系统故障时,实现秒级故障切换。详情参考:镜像/快照、CDP服务。
负载均衡
基于业务软件自身的高可用架构,业务软件、数据库等组件高可用多机部署,应用前端基于负载均衡访问,在应用服务器故障时,实现自主故障切换。 详情参考:负载均衡。
安全性
计算安全
HTTPS加密登录UI
支持HTTPS方式登录UI管理界面,进一步提升系统安全性。
- HTTPS方式默认不启用。
- 启用HTTPS后,系统默认支持5443端口,且支持自定义指定其它端口登录。
- 启用HTTPS后,如使用HTTP方式的5000端口登录,将会自动重定向到HTTPS方式。目前仅支持HTTP的5000端口自动重定向到HTTPS。
- 系统默认支持PKCS12格式证书。目前仅提供PKCS12/JKS格式证书支持,如使用其它格式证书,请自行格式转换。
云主机控制台
云主机控制台为用户提供了快捷监控管理云主机的入口,用户必须具有相应权限才可登录云主机控制台。提供两种认证方式登录云主机控制台:SSH密钥方式、用户名/密码方式。
1)SSH密钥方式
- 支持SSH密钥方式登录云主机,目前仅适用于Linux云主机。
- SSH密钥是通过一种加密算法生成的一对密钥:一个为公钥,对外公开,一个为私钥,由用户自己保留。
- 云主机绑定公钥后,用户可在另一台云主机中,通过私钥SSH登录已注入公钥的云主机,而无需输入密码。
- 如在创建云主机时绑定公钥,前提需确保云主机镜像已预先安装cloud-init,且cloud-init推荐版本为:0.7.9、17.1、19.4、19.4以后版本。
- 如在云主机创建完成后绑定公钥,前提需确保云主机处于运行中状态,且已安装Qemu Guest Agent (QGA),QGA需同处于运行中状态。QGA可通过性能优化工具安装,如通过其他方式安装,需安装2.5及以上版本。
2)用户名/密码方式
- 支持用户名/密码方式登录云主机。
- Linux云主机固定用户名root,Windows云主机固定用户名administrator。
- 云主机注入密码后,用户可在另一台云主机中,通过用户名/密码SSH登录已注入密码的云主机。
- 前提需确保云主机镜像已预先安装cloud-init,且cloud-init推荐版本为:0.7.9、17.1、19.4、19.4以后版本。
高可用性
云主机高可用
云主机支持设置高可用模式,当云主机因日常维护(计划)或突发异常(非计划)导致停机时,该策略可触发云主机自动重启,提高云主机可用性。
NeverStop云主机高可用机制:
1)通过轮询、触发等机制检测云主机状态,如果确定云主机已停止,设置高可用的云主机将直接自动重启。
2)通过轮询、触发等机制检测云主机状态,如果不能确定云主机状态,将根据以下步骤进行检测:
2.1)根据已有网络配置,选择最精准的方式探测云主机所在的物理机状态。
2.2)如果物理机状态异常,设置高可用的云主机将尝试自动重启。
负载均衡
多台云主机可使用负载均衡服务组成集群,消除单点故障,提升应用的可用性。
防IP/MAC/ARP欺诈
在传统网络里,IP/MAC/ARP欺骗一直是网络面临的严峻考验。通过IP/MAC/ARP欺骗,黑客可以扰乱网络环境,窃听网络机密。
在物理机数据链路层隔离由云主机向外发起的异常协议访问,并阻断云主机MAC/ARP欺骗,在物理机网络层防止云主机IP欺骗。
镜像/快照
镜像
支持对云主机/云盘创建镜像。云主机/云盘的数据信息完整包含在镜像中,通过镜像可快捷复制相应资源。
云平台支持对镜像的完整性和安全性保护:
- 镜像采用加密算法保护完整性。当镜像从镜像仓库下载至主存储时,需通过加密算法校验,只有校验成功才可下载镜像。
- 镜像文件以切片方式存储于镜像仓库,切片的镜像文件需通过云平台拼接完整后,才能读取具体内容,从而实现镜像数据的安全性保护。
快照
支持对云主机/云盘创建快照。快照实质为某一时间点某一磁盘的数据状态文件。做重要操作前,对云主机/云盘创建快照,可保留特定时间点的数据状态(包括内存状态),方便出现故障后迅速回滚。如需长期备份,建议使用灾备服务。
快照包括手动快照和自动快照两种类型:
- 手动快照:用户随时手动对云主机根云盘或数据云盘创建快照。
- 自动快照:通过定时任务创建快照,或系统在特定场景触发一次性自动快照。
快照功能适用于以下应用场景:
- 故障迅速还原:当生产环境出现异常故障,可使用快照回滚功能迅速还原至正常状态。该手段为临时方案,考虑到数据的长期完善保护,建议使用灾备服务。
- 数据开发:通过对生产数据创建快照,从而为数据挖掘、报表查询和开发测试等应用提供近实时的真实生产数据。
- 提高操作容错率:在系统升级或业务数据迁移等重大操作前,建议创建一份或多份快照。一旦升级或者迁移过程中出现任何问题,可以通过快照及时恢复到正常的系统数据状态。
密码加密存放
支持对云平台所有明文密码加密存放,从而保护用户数据的隐私性和自主性。
支持的密码加密存放场景包括但不限于:
- 物理机密码:非明文展示。
- 主存储密码:非明文展示。
- 数据库密码:通过密钥加密存放,直接对用户隐藏。
- 日志密码:云平台所有日志密码非明文展示或直接对用户隐藏。
资源删除保护
删除策略控制
支持对重要资源进行删除策略控制,降低误操作风险。
目前删除策略包括:立刻删除、延时删除、永不删除。
- 立刻删除:资源直接被物理删除,并在数据库中删除,无法恢复。
- 延时删除:资源首先在数据库中被标记为删除,但不会物理删除。在一定时间内,用户可通过UI界面的回收站功能或使用云平台API恢复资源。在此期间,资源仍物理存在,仍会占用物理空间(例如磁盘空间)。超过一定时间后,资源会被物理删除,无法再恢复。
- 永不删除:资源在数据库中标记为删除,永不会被物理删除,会一直占用物理空间。
目前支持删除策略控制的资源包括:云主机、云盘、镜像、裸金属主机、弹性裸金属实例。
1)云主机删除策略:立刻删除、延时删除、永不删除。默认为延时删除。
2)云盘删除策略:立刻删除、延时删除、永不删除。默认为延时删除。
3)镜像删除策略:立刻删除、延时删除、永不删除。默认为延时删除。
4)裸金属主机删除策略:立刻删除、延时删除。默认为延时删除。
5)弹性裸金属实例删除策略:立刻删除、延时删除、永不删除。默认为延时删除。
说明:
弹性裸金属实例是一个定制的云主机,弹性裸金属实例与云主机受同一套删除策略控制。若云主机删除策略发生变更,则弹性裸金属实例删除策略同步变更。
UI删除提醒
在UI界面对重要资源删除提供保护机制,系统会提醒删除此资源的后果,并展示与此资源直接关联的云主机、云盘数量。用户需确认后才能进行删除,降低误操作风险。
国密数据保护
提供基于国密算法(SM3、HMAC-SM3和SM4)的数据保护功能,开启该功能后,可对日志、口令、镜像等重要数据进行加密保护,保护数据的机密性和完整性。
如需使用该功能,需确保已安装密评合规模块许可证并开启平台密评合规。
监控报警
主要通过监控系统以及通知系统提供监控报警功能,监控系统对时序化数据和事件进行监控,通知系统推送报警消息至指定的接收端。
通过监控系统提供包括系统性能、资源用量在内的监控数据指标,以大屏监控/仪表盘/可视化图表/横幅提示等形式,让用户全面了解云平台资源使用情况、系统运行状态以及健康度。用户还可自定义报警器以及接收端,实现细粒度灵活监控,及时发现并诊断相关问题。
监控系统功能特点:
- 时序化监控:目前支持监控两种时序化数据类型。
- 资源负载数据:例如云主机CPU使用率、物理机内存使用率等。
- 资源容量数据:例如可用IP数量、运行中云主机的总数量等。
- 事件收集:收集云平台中发生的预定义事件,例如物理机失联,云主机高可用功能启动等。
- 报警功能:对时序化数据或事件进行报警,并针对重要资源进行全局提示,例如主存储可用物理容量等。
- 审计功能:记录所有操作并提供搜索。
- 自定义功能:用户可自定义设置报警器和报警消息模板。
通知系统功能特点:
- 推送报警消息至指定的接收端。
- 系统默认提供一个系统类型接收端,用户可自行设置邮箱/钉钉/HTTP应用/短信/Microsoft Teams类型接收端。
安全场景封装
为安全场景提供一键全局设置封装,方便快速将云平台设置为所需状态,满足用户实际生产环境的安全需求。
| 名称 | 描述 |
|---|---|
| 云平台登录IP黑白名单 | 默认为false,用于设置是否开启IP黑白名单功能,开启后,云平台将对登录IP进行防护。 |
| 物理机密码加密存储开关 | 默认为None,用于设置物理机密码在数据库中的加密存储策略。可选策略为:None、LocalEncryption。
说明: 如已开启平台密评合规功能,“当前生效值”会变为SecurityResourceEncryption,表示使用密码机进行加密。此时不支持更换加密存储策略。 |
| 禁止同一用户多会话连接开关 | 默认为false,用于设置是否禁止同一用户多会话连接。若为true,则同一用户只能存在一个登录会话,历史会话将强制退出。 |
| 会话超时时间 | 默认为7200,单位为s/m/h/d(即:秒/分/小时/天)。 说明: 当前会话登录超过该会话时间后,系统将不可用,需重新登录。 |
| SSL证书检查开关 | 默认为false,用于设置是否开启跳过LDAP SSL证书的所有检查的开关。若为true,表示跳过所有LDAP SSL证书的检查。 |
| 云平台登录验证码策略 | 默认为false,用于设置是否启用登录控制中的验证码功能。开启后连续登录失败次数超过上限将触发验证码保护机制,要求输入正确的账户名、密码以及验证码才能成功登录云平台。 |
| 云平台登录密码更新周期 | 默认为false,用于设置是否开启按周期修改密码功能。若设置为true,密码使用时间达到所设置的密码更新周期后,重新登录将提示修改密码。 |
| 云平台登录密码不重复次数 | 默认为false,若设置为true,则在重新设置密码时,新密码不能与之前已使用过的历史密码重复,不重复次数可配置。 |
| 云平台连续登录失败锁定用户 | 默认为false,用于设置是否启用连续登录失败锁定用户。若设置为true,则用户连续登录失败数次,账户会被锁定一段时间。 |
| 云平台登录密码强度 | 默认为false,若设置为true,则可以手动设置密码的长度和选择是否启用数字、大小写和特殊字符组合的策略。 |
| 云平台登录双因子认证开关 | 默认为false,登录云平台时,是否开启双因子认证。 |
| VNC控制台密码强度 | 默认为false,用于设置是否启用密码登录VNC控制台。 说明: VNC密码长度范围格式为m~n,取值范围[6,8]的整数,默认为6~8,并支持选择是否启用数字、大小写和特殊字符组合的策略。 |
| 云主机密码强度 | 默认为false,用于设置是否启用密码登录云主机。说明:
|
灾备服务
灾备服务以业务为中心,融合定时增量备份、定时全量备份等多种灾备技术到云平台中,支持本地灾备、异地灾备、公有云灾备多种灾备方案,用户可根据自身业务特点,灵活选择合适的灾备方式。以单独的功能模块形式提供灾备服务。
典型场景
本地灾备:
- 支持将本地部署的镜像仓库作为本地备份服务器,用于存放本地云主机/云盘/管理节点数据库(简称数据库)的定时备份数据。同时本地备份服务器支持主备无缝切换,有效保障业务连续性。
- 当发生本地数据误删,或本地主存储中数据损坏等情况,可将本地备份服务器中的备份数据还原至本地。
- 当本地数据中心发生灾难时,完全可依赖本地备份服务器重建数据中心并恢复业务。
异地灾备:
- 支持将异地机房的存储服务器作为异地备份服务器,用于存放本地云主机/云盘/数据库的定时备份数据。备份数据需通过本地备份服务器同步至异地备份服务器。
- 当发生本地数据误删,或本地主存储中数据损坏等情况,可将异地备份服务器中的备份数据还原至本地。
- 当本地数据中心发生灾难时,完全可依赖异地备份服务器重建数据中心并恢复业务。
公有云灾备:
- 支持将公有云上的存储服务器作为公有云备份服务器,用于存放本地云主机/云盘/数据库的定时备份数据。备份数据需通过本地备份服务器同步至公有云备份服务器。
- 当发生本地数据误删,或本地主存储中数据损坏等情况,可将公有云备份服务器中的备份数据还原至本地。
- 当本地数据中心发生灾难时,完全可依赖公有云备份服务器备份服务器重建数据中心并恢复业务。
CDP服务
CDP服务为云主机中的重要业务系统提供秒级细粒度的持续备份,即可以将云主机数据恢复到指定时间状态,又可以在不恢复系统的情况下找回文件。CDP恢复支持新建云主机和恢复到原云主机两种策略,用户可根据自身业务需求,灵活选择合适的恢复方式。以单独的功能模块形式提供持续数据保护(CDP)服务。
典型场景
本地CDP恢复|恢复到原云主机
- 支持将本地部署的镜像仓库作为本地备份服务器,用于存放本地云主机数据。
- 支持为多台云主机创建CDP任务,对批量云主机提供统一CDP保护。创建CDP任务时,支持秒/分钟级别的RPO设置。进行重要业务调整时,用户可对恢复点进行标记和锁定,长期保存重要恢复点数据。
- 当发生本地数据误删,或突发故障导致数据损坏,由于用户的业务应用有硬件授权,为快速验证业务的可用性,可找到锁定恢复点,将数据恢复到原云主机查看应用是否正常。支持通过新建云盘方式恢复到原云主机,恢复前的云盘支持全部保留并重新加载回云主机,最大限度保证数据安全。
- CDP恢复时,云主机会快速拉起,RTO最低可达到秒级,有效保障业务连续性。
本地CDP恢复|新建云主机
- 支持将本地部署的镜像仓库作为本地备份服务器,用于存放本地云主机数据。
- 支持为多台云主机创建CDP任务,对批量云主机提供统一CDP保护。创建CDP任务时,支持秒/分钟级别的RPO设置。
- 进行重要恢复演练时,可在不影响当前云主机正常运行的情况下,基于所选恢复点新建云主机,确认数据无误后再恢复到原环境中。
- CDP恢复时,云主机会快速拉起,RTO最低可达到秒级,有效保障业务连续性。
功能优势
简单:
- 软件定义,不依赖硬件,可扩展。
- 无需恢复系统,即可预览和下载备份文件。
- 操作向导化以及参数智能推荐,大幅降低使用门槛以及使用出错概率。
强大:
- 云主机无需安装代理,不受操作系统限制,对云主机性能无损耗。
- 为云主机提供细粒度至秒级的持续数据保护,RPO最低可达1秒。
- 支持任一恢复点快速还原云主机,业务环境立即可用,RTO最低可达1秒。
- 精简备份,智能识别磁盘分区和有效数据,以较小量数据和较快速度备份有效数据。
灵活:
- 支持备份频率、RPO、保留策略等灵活设置,满足不同场景需求。
- 支持多种恢复级别,如整机恢复和文件级恢复。
- 整机恢复支持多种策略,支持新建云主机和恢复到原云主机两种策略。
- 不受云平台主存储类型限制,满足不同存储场景下的CDP需求。
可靠:
- UI界面提供CDP概览,支持统一查看CDP状态以及相关告警。
- 数据恢复支持保留当前云盘数据,较大限度保证数据安全,有利于故障事后分析。
- 支持基于所选恢复点新建云主机,确认数据无误后再恢复到原环境中,满足恢复演练需求。
- 支持对恢复点进行标记和锁定,长期保存重要恢复点数据。
- 提供恢复任务列表,支持查看恢复记录和恢复进度,方便后续审计和追溯。
网络安全
安全组
为云主机提供三层网络安全组控制,控制TCP/UDP/ICMP等数据包进行有效过滤,对指定网卡流量按照指定的安全规则进行有效控制。
VPC防火墙
支持对VPC路由器配置防火墙。VPC防火墙创建后,系统为VPC路由器自动配置入方向规则集,用户可灵活配置出方向规则集。VPC路由器的每个接口方向允许应用一个规则集,通过对VPC路由器接口处的南北向流量进行过滤,可有效保护整个VPC的通信安全以及VPC路由器安全。与作用于云主机虚拟网卡、侧重于保护VPC内部东西向通信安全的安全组相辅相成。
VPC路由器高可用组
支持VPC路由器高可用组功能。可在一个VPC路由器高可用组内部署一对互为主备的VPC路由器,当主VPC路由器状态异常,会秒级触发高可用切换,自动切换至备VPC路由器工作,从而保障业务持续稳定运行。
Netflow
支持VPC路由器定向导出Netflow网络流分析监控。通过Netflow对VPC路由器网卡的进出流量进行分析监控,从而快速定位整个网络的流量瓶颈,优化网络拓扑以及网络带宽,防止恶意攻击,增强网络安全。目前支持Netflow V5、V9两种数据流输出格式。
端口镜像
支持端口镜像功能。将云主机网卡的出入流量转发至另一台云主机上,在不影响源端口正常业务吞吐的情况下,可获取云主机端口上的业务报文进行分析,方便企业对内部网络数据进行监控管理,快速定位网络故障。端口镜像需使用单独的流量网络,不与其它网络复用,确保传输效率。
权限管理安全
三员分立
支持三员分立权限管理,将超级管理员(admin)权限分解并赋予系统管理员、安全管理员和安全审计员。其中,系统管理员负责云平台资源管理、安全管理员负责云平台权限管理、安全审计员负责云平台审计管理,三者之间相互独立,相互制约。
三员分立将超级管理员的超级权限分解,由三员分而治之,可有效降低因超级管理员权限过大带来的安全风险,进一步加强云平台安全。
租户管理权限
租户管理主要为企业用户提供组织架构管理,以及基于项目的资源访问控制、工单管理、独立区域管理等功能。以单独的功能模块形式提供租户管理功能。
租户管理权限功能特点:
- 用户与角色分离,角色作为一组权限的集合,可灵活绑定到租户管理用户或从租户管理用户解绑。
- 角色分为系统角色和自定义角色,系统角色是云平台默认提供的预定义权限范围的角色,自定义角色是用户按需自行创建的角色。
- UI界面支持API级别的权限控制,灵活适配各种场景的权限配置需求。
国密证书登录
提供基于国密算法(SM2)的证书登录功能。开启该功能后,需使用UKey进行登录认证,确保身份的真实性。
如需使用该功能,需确保已安装密评合规模块许可证并开启平台密评合规。
支持为admin或租户开启证书登录。若需为租户开启证书登录,需确保云平台已安装租户管理模块许可证。
双因子认证
在静态密码认证基础上支持第二层防护:双因子认证。当云平台开启双因子认证后,每次登录均需正确输入身份验证器APP提供的6位动态安全码才能成功登录。
当开启双因子认证并首次成功登录后,不再展示登录二维码,有效防止恶意登录,进一步提升系统安全。
AccessKey认证
支持AccessKey认证功能。
AccessKey包括:
- 本地AccessKey:包括AccessKey ID和AccessKey Secret,是云平台授权第三方用户调用云平台API来访问云平台云资源的安全凭证,需严格保密。
- 第三方AccessKey:包括AccessKey ID和AccessKey Secret,是第三方用户授权用户调用第三方API来访问第三方云资源的安全凭证,需严格保密。
操作审计
为用户提供统一的操作日志管理,记录云平台各类账号下的用户登录及资源操作,包括:操作描述、任务结果、操作员、登录IP、任务创建/完成时间,以及操作返回详情。通过操作日志审计,可满足用户进行安全分析、入侵检测、资源变更追踪以及合规性审计等需求。
开放兼容性
开放API
ZStack Cloud给开发者提供了全面友好的API支持。我们不仅提供原生的RESTful支持,开发者可通过REST定义的架构设计原则和约束条件,并使用支持HTTP的编程预研进行开发,同时也提供Java SDK和Python SDK支持,开发者可通过SDK方式调用ZStack Cloud API,实现对应的功能。
产品配套开发手册详述了RESTful API以及SDK的使用规范,并提供所有API的详细定义。为了进一步降低开发者的使用门槛,我们还提供可视化的API Inspector功能,开发者可在 UI 界面快速查看查询类/操作类 API 调用情况,API信息尽在掌握。同时,开发者可将调用语句一键复制到第三方工具中调试使用,极大提高效率,改善开发者体验。
硬件兼容性
ZStack Cloud支持软件与硬件松耦合方式部署。用户可根据实际需求,提供合理的硬件配置清单以及云平台软件清单,对于具体的硬件品牌,ZStack Cloud无任何限制以及特殊要求。若用户有现存的服务器设备希望利旧,ZStack Cloud支持兼容利旧,统一通过云平台进行管理。

















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









