






由于迭代器只能对每一个元素分别进行处理,但是某些时候,却需要获取所有元素后再进行处理。所以打算把迭代器中的所有值存储在数组中,然后再进行相应的运算。
下边是两种将迭代器内的数值存储在array中的过程
1.
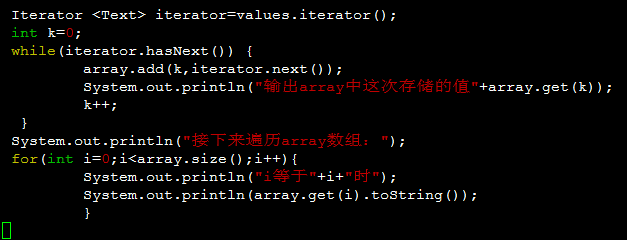
2.
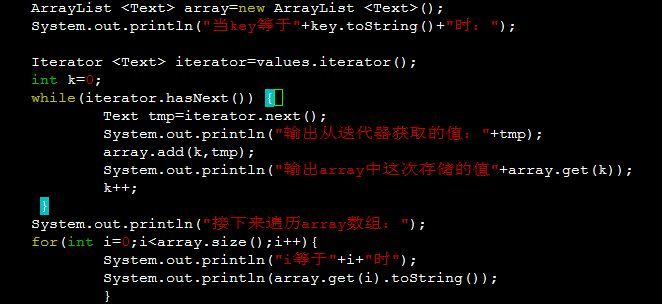
两种做法均不正确。如果按照上边的代码执行。结果array中所有元素的值将等于迭代器的最后一个元素的值。
这是由于iterate.next()被单独分到了一个内存空间。而将iterate.next()赋值给array的过程传递的是iterate.next()的地址。这时array中所有元素保存的是iterate.next()的地址。
当最后一个迭代器中的内容将iterate.next()中存储的值改变后。array中元素的值都变为了迭代器的最后一个值。
正确的做法是:
Text tmp=new Text(iterator.next().toString());如果使用:
for (Text val : values) {
} 













 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









