







上一篇文章信用评分卡模型分析(理论部分)已经介绍了信用评分卡模型的数据预处理、探索性数据分析、变量分箱和变量选择等。接下来使用Python建立信用评分卡,对用户行为进行打分,继续讨论信用评分卡的模型python实现和分析,信用评分的方法和自动评分系统。(建立ABC卡则需要对自变量和因变量有针对性的进行调整,流程大体一致)
流程:
- 导入数据
- 数据预处理
- 探索分析
- 特征选择
- 模型训练
- 模型评估
- 模型结果转评分
- 计算用户总分
一、导入数据
import pandas as pd
import numpy as np
path=r’/Volumes/win/1/DataStudy/dataset/Give Me Some Credit/cs-training.csv’
df=pd.read_csv(path)
df.head()

查看各字段名
df.info()

有12列数据,将ID列设置为索引列
df=df.set_index('ID',drop=True) #设置id列为索引列
df.head()

将各英文字段转为中文字段名方便理解
states={'SeriousDlqin2yrs':'好坏客户',
'RevolvingUtilizationOfUnsecuredLines':'可用额度比值',
'age':'年龄',
'NumberOfTime30-59DaysPastDueNotWorse':'逾期30-59天笔数',
'DebtRatio':'负债率',
'MonthlyIncome':'月收入',
'NumberOfOpenCreditLinesAndLoans':'信贷数量',
'NumberOfTimes90DaysLate':'逾期90天笔数',
'NumberRealEstateLoansOrLines':'固定资产贷款量',
'NumberOfTime60-89DaysPastDueNotWorse':'逾期60-89天笔数',
'NumberOfDependents':'家属数量'}
df.rename(columns=states,inplace=True)
df.head() #修改英文字段名为中文字段名

坏客户是1,好客户对应0,
二、数据预处理
- 缺失值处理
- 异常值处理
1、缺失值处理
查看各字段数据缺失情况
df.info()

月收入和家属数量存在缺失
print("月收入缺失比:{:.2%}".format(df['月收入'].isnull().sum()/df.shape[0]))
print(“家属数量缺失比:{:.2%}”.format(df[‘家属数量’].isnull().sum()/df.shape[0]))
月收入缺失较大,使用平均值进行填充,家属数量缺失较少,将缺失的删掉,另外,如果字段缺失过大,将失去分析意义,可以将整个字段删除
df=df.fillna({‘月收入’:df[‘月收入’].mean()})
df1=df.dropna()
df1.shape
**2、异常值处理**
可以通过箱线图观察异常值```
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
x1=df['可用额度比值']
x2=df['负债率']
x3=df1["年龄"]
x4=df1["逾期30-59天笔数"]
x5=df1["逾期60-89天笔数"]
x6=df1["逾期90天笔数"]
x7=df1["信贷数量"]
x8=df1["固定资产贷款量"]
fig=plt.figure(figsize=(20,15))
ax1=fig.add_subplot(221)
ax2=fig.add_subplot(222)
ax3=fig.add_subplot(223)
ax4=fig.add_subplot(224)
ax1.boxplot([x1,x2])
ax1.set_xticklabels(["可用额度比值","负债率"], fontsize=20)
ax2.boxplot(x3)
ax2.set_xticklabels("年龄", fontsize=20)
ax3.boxplot([x4,x5,x6])
ax3.set_xticklabels(["逾期30-59天笔数","逾期60-89天笔数","逾期90天笔数"], fontsize=20)
ax4.boxplot([x7,x8])
ax4.set_xticklabels(["信贷数量","固定资产贷款量"], fontsize=20)

异常值处理消除不合逻辑的数据和超级离群的数据,可用额度比值应该小于1,年龄为0的是异常值,逾期天数笔数大于80的是超级离群数据,固定资产贷款量大于50的是超级离群数据,将这些离群值过滤掉,筛选出剩余部分数据。
df1=df1[df1['可用额度比值']<1]
df1=df1[df1['年龄']>0]
df1=df1[df1['逾期30-59天笔数']<80]
df1=df1[df1['逾期60-89天笔数']<80]
df1=df1[df1['逾期90天笔数']<80]
df1=df1[df1['固定资产贷款量']<50]
df1.shape
三、探索分析
探索分析在整个流程当中对数据的变动不大,主要起到了一种催化的作用,作为一种“启动”开展后续工作,可以更好的了解到数据之间的一些联系和变化规律。同时在多变量分析中通过相关性也可以过滤掉一部分变量。
- 单变量分析
- 多变量分析
1、单变量分析
是分析一个自变量和因变量之间的联系,此处以年龄和好坏客户为例进行分析。
将年龄均分成5组,求出每组的总的用户数
age_cut=pd.cut(df1['年龄'],5)
age_cut_group=df1['好坏客户'].groupby(age_cut).count()
age_cut_group

求各组的坏客户数
age_cut_grouped1=df1["好坏客户"].groupby(age_cut).sum()
age_cut_grouped1

联结
df2=pd.merge(pd.DataFrame(age_cut_group),pd.DataFrame(age_cut_grouped1),left_index=True,right_index=True)
df2.rename(columns={'好坏客户_x':'总客户数','好坏客户_y':'坏客户数'},inplace=True)
df2

加一列好客户数
df2.insert(2,"好客户数",df2["总客户数"]-df2["坏客户数"])
df2

再加一列坏客户占比
df2.insert(2,"坏客户占比",df2["坏客户数"]/df2["总客户数"])
df2

ax1=df2[["好客户数","坏客户数"]].plot.bar(figsize=(10,5))
ax1.set_xticklabels(df2.index,rotation=15)
ax1.set_ylabel("客户数")
ax1.set_title("年龄与好坏客户数分布图")

ax11=df2["坏客户占比"].plot(figsize=(10,5))
ax11.set_xticklabels([0,20,29,38,47,55,64,72,81,89,98,107])
ax11.set_ylabel("坏客户率")
ax11.set_title("坏客户率随年龄的变化趋势图")

可以看出随着年龄的增长,坏客户率在降低,其中38~55之间变化幅度最大
2、多变量分析
多变量分析就是对各个变量之间的相关性进行探索,线性回归模型中的特征之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确,相关系数为1或者-1变量之间的相关性最大,对于相关性大的两组变量可以择一处理```
import seaborn as sns
corr = df1.corr()#计算各变量的相关性系数
xticks = list(corr.index)#x轴标签
yticks = list(corr.index)#y轴标签
fig = plt.figure(figsize=(15,10))
ax1 = fig.add_subplot(1, 1, 1)
sns.heatmap(corr, annot=True, cmap=“rainbow”,ax=ax1,linewidths=.5, annot_kws={‘size’: 9, ‘weight’: ‘bold’, ‘color’: ‘blue’})
ax1.set_xticklabels(xticks, rotation=35, fontsize=15)
ax1.set_yticklabels(yticks, rotation=0, fontsize=15)
plt.show()

可以看到各变量之间的相关性比较小,所以不需要操作,一般相关系数大于0.6可以进行变量剔除。
#### 四、特征选择
这里使用IV值进行特征选择
* WOE分箱
* WOE值计算
* IV值计算
* WOE值替换
**1、WOE分箱**
将连续变量离散化,特征离散化后,模型会更稳定,降低了模型过拟合的风险。同时由于逻辑回归模型的每个变量的每种情况都会有对应的特征权值,使用分箱之后可以降低数据量,使模型泛化能力增强。
在学习笔记(一)中提到woe分箱可以先进行等频分箱,然后按照woe的单调性进行调整,保持单调性可以使连续数据转化为离散时数据之间能有一定的联系和趋势而不是孤立的几个数据(另外单调从系数的正负上也反映的单变量对结果的影响趋势),当然woe不一定保证完全单调递增或递减,保持一定趋势即可,这种趋势一般不会发生完全逆转(通过调整分箱值使得单调递增转为递减),所以按照客观事实进行调整即可,我们将按照此方法求取woe 值。
此处取分箱值可以先把数据导出使用excel进行调整
也可以使用python自动分箱woe转化,见[风控数据分析学习笔记(三)Python实现woe自动分箱转化](https://www.jianshu.com/p/24c0884cbcbc)
cut1=pd.qcut(df1[“可用额度比值”],4,labels=False)
cut2=pd.qcut(df1[“年龄”],8,labels=False)
bins3=[-1,0,1,3,5,13]
cut3=pd.cut(df1[“逾期30-59天笔数”],bins3,labels=False)
cut4=pd.qcut(df1[“负债率”],3,labels=False)
cut5=pd.qcut(df1[“月收入”],4,labels=False)
cut6=pd.qcut(df1[“信贷数量”],4,labels=False)
bins7=[-1, 0, 1, 3,5, 20]
cut7=pd.cut(df1[“逾期90天笔数”],bins7,labels=False)
bins8=[-1, 0,1,2, 3, 33]
cut8=pd.cut(df1[“固定资产贷款量”],bins8,labels=False)
bins9=[-1, 0, 1, 3, 12]
cut9=pd.cut(df1[“逾期60-89天笔数”],bins9,labels=False)
bins10=[-1, 0, 1, 2, 3, 5, 21]
cut10=pd.cut(df1[“家属数量”],bins10,labels=False)
**2、WOE值计算**
rate=df1[“好坏客户”].sum()/(df1[“好坏客户”].count()-df1[“好坏客户”].sum())
def get_woe_data(cut):
grouped=df1[“好坏客户”].groupby(cut,as_index = True).value_counts()
woe=np.log(grouped.unstack().iloc[:,1]/grouped.unstack().iloc[:,0]/rate)
return woe
cut1_woe=get_woe_data(cut1)
cut2_woe=get_woe_data(cut2)
cut3_woe=get_woe_data(cut3)
cut4_woe=get_woe_data(cut4)
cut5_woe=get_woe_data(cut5)
cut6_woe=get_woe_data(cut6)
cut7_woe=get_woe_data(cut7)
cut8_woe=get_woe_data(cut8)
cut9_woe=get_woe_data(cut9)
cut10_woe=get_woe_data(cut10)
随便挑几个变量看下woe
cut1_woe.plot.bar(color=‘b’,alpha=0.3,rot=0)

cut2_woe.plot.bar(color=‘b’,alpha=0.3,rot=0)

cut3_woe.plot.bar(color=‘b’,alpha=0.3,rot=0)

可以看出woe已调整到具有单调性
**3、IV值计算**```
def get_IV_data(cut,cut_woe):
grouped=df1["好坏客户"].groupby(cut,as_index = True).value_counts()
cut_IV=((grouped.unstack().iloc[:,1]/df1["好坏客户"].sum()-grouped.unstack().iloc[:,0]/(df1["好坏客户"].count()-df1["好坏客户"].sum()))*cut_woe).sum()
return cut_IV
#计算各分组的IV值
cut1_IV=get_IV_data(cut1,cut1_woe)
cut2_IV=get_IV_data(cut2,cut2_woe)
cut3_IV=get_IV_data(cut3,cut3_woe)
cut4_IV=get_IV_data(cut4,cut4_woe)
cut5_IV=get_IV_data(cut5,cut5_woe)
cut6_IV=get_IV_data(cut6,cut6_woe)
cut7_IV=get_IV_data(cut7,cut7_woe)
cut8_IV=get_IV_data(cut8,cut8_woe)
cut9_IV=get_IV_data(cut9,cut9_woe)
cut10_IV=get_IV_data(cut10,cut10_woe)
IV=pd.DataFrame([cut1_IV,cut2_IV,cut3_IV,cut4_IV,cut5_IV,cut6_IV,cut7_IV,cut8_IV,cut9_IV,cut10_IV],index=['可用额度比值','年龄','逾期30-59天笔数','负债率','月收入','信贷数量','逾期90天笔数','固定资产贷款量','逾期60-89天笔数','家属数量'],columns=['IV'])
iv=IV.plot.bar(color='b',alpha=0.3,rot=30,figsize=(10,5),fontsize=(10))
iv.set_title('特征变量与IV值分布图',fontsize=(15))
iv.set_xlabel('特征变量',fontsize=(15))
iv.set_ylabel('IV',fontsize=(15))

IV

一般选取IV大于0.02的特征变量进行后续训练,从以上可以看出所有变量均满足,所以选取全部的
4、WOE值替换```
df_new=pd.DataFrame() #新建df_new存放woe转换后的数据
def replace_data(cut,cut_woe):
a=[]
for i in cut.unique():
a.append(i)
a.sort()
for m in range(len(a)):
cut.replace(a[m],cut_woe.values[m],inplace=True)
return cut
df_new[“好坏客户”]=df1[“好坏客户”]
df_new[“可用额度比值”]=replace_data(cut1,cut1_woe)
df_new[“年龄”]=replace_data(cut2,cut2_woe)
df_new[“逾期30-59天笔数”]=replace_data(cut3,cut3_woe)
df_new[“负债率”]=replace_data(cut4,cut4_woe)
df_new[“月收入”]=replace_data(cut5,cut5_woe)
df_new[“信贷数量”]=replace_data(cut6,cut6_woe)
df_new[“逾期90天笔数”]=replace_data(cut7,cut7_woe)
df_new[“固定资产贷款量”]=replace_data(cut8,cut8_woe)
df_new[“逾期60-89天笔数”]=replace_data(cut9,cut9_woe)
df_new[“家属数量”]=replace_data(cut10,cut10_woe)
df_new.head()

#### 五、模型训练
信用评分卡主要使用的算法模型是逻辑回归。logistic模型客群变化的敏感度不如其他高复杂度模型,因此稳健更好,鲁棒性更强。另外,模型直观,系数含义好阐述、易理解,使用逻辑回归优点是可以得到一个变量之间的线性关系式和对应的特征权值,方便后面将其转成一一对应的分数形式。

使用sklearn库
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
x=df_new.iloc[:,1:]
y=df_new.iloc[:,:1]
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.6,random_state=0)
model=LogisticRegression()
clf=model.fit(x_train,y_train)
print(‘测试成绩:{}’.format(clf.score(x_test,y_test)))
求特征权值系数coe,后面训练结果转分值时会用到:
coe=clf.coef_ #特征权值系数,后面转换为打分规则时会用到
coe
y_pred=clf.predict(x_test)
```
#### 六、模型评估
模型评估主要看AUC和K-S值
```
from sklearn.metrics import roc_curve, auc
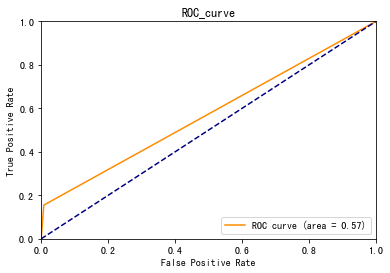
fpr, tpr, threshold = roc_curve(y_test, y_pred)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, color='darkorange',label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC_curve')
plt.legend(loc="lower right")
plt.show()
```
```
roc_auc
fig, ax = plt.subplots()
ax.plot(1 - threshold, tpr, label=‘tpr’) # ks曲线要按照预测概率降序排列,所以需要1-threshold镜像
ax.plot(1 - threshold, fpr, label=‘fpr’)
ax.plot(1 - threshold, tpr-fpr,label=‘KS’)
plt.xlabel(‘score’)
plt.title(‘KS Curve’)
plt.ylim([0.0, 1.0])
plt.figure(figsize=(20,20))
legend = ax.legend(loc=‘upper left’)
plt.show()

max(tpr-fpr)
ROC0.57, K-S值0.15左右,建模效果一般
#### 七、模型结果转评分

由此可知每个变量不同分段对应的分数是B、β、ω这三个值的乘积,其中β(特征权值系数coe)和ω(WOE值)在前面已知,所以只要知道了AB的值就可以给用户打分了,这里要求AB的值要预先设定几个阈值,
偏移量A=offset
比例因子B=factor
b=offset+factor\*log(o)
b+p=offset+factor \*log(2o)

假设好坏比为20的时候分数为600分,每高20分好坏比翻一倍
现在我们求每个变量不同woe值对应的分数刻度可得:
factor = 20 / np.log(2)
offset = 600 - 20 * np.log(20) / np.log(2)
def get_score(coe,woe,factor):
scores=[]
for w in woe:
score=round(coewfactor,0)
scores.append(score)
return scores
x1 = get_score(coe[0][0], cut1_woe, factor)
x2 = get_score(coe[0][1], cut2_woe, factor)
x3 = get_score(coe[0][2], cut3_woe, factor)
x4 = get_score(coe[0][3], cut4_woe, factor)
x5 = get_score(coe[0][4], cut5_woe, factor)
x6 = get_score(coe[0][5], cut6_woe, factor)
x7 = get_score(coe[0][6], cut7_woe, factor)
x8 = get_score(coe[0][7], cut8_woe, factor)
x9 = get_score(coe[0][8], cut9_woe, factor)
x10 = get_score(coe[0][9], cut10_woe, factor)
print(“可用额度比值对应的分数:{}”.format(x1))
print(“年龄对应的分数:{}”.format(x2))
print(“逾期30-59天笔数对应的分数:{}”.format(x3))
print(“负债率对应的分数:{}”.format(x4))
print(“月收入对应的分数:{}”.format(x5))
print(“信贷数量对应的分数:{}”.format(x6))
print(“逾期90天笔数对应的分数:{}”.format(x7))
print(“固定资产贷款量对应的分数:{}”.format(x8))
print(“逾期60-89天笔数对应的分数:{}”.format(x9))
print(“家属数量对应的分数:{}”.format(x10))

可以看出分数越高,成为坏客户的可能性越大。像年龄越大坏客率越低,可用额度比值、逾期笔数这几个变量的分数跨度较大对最后的总分有更大的影响,这些都印证了前面探索分析的结果。
#### 八、计算用户总分
_1.取自动分箱的边界分割点_
_cu1=pd.qcut(df1\["可用额度比值"\],4,labels=False,retbins=True)_
_bins1=cu1\[1\]_
_cu2=pd.qcut(df1\["年龄"\],8,labels=False,retbins=True)_
_bins2=cu2\[1\]_
_\# bins3=\[-1,0,1,3,5,13\]_
_\# cut3=pd.cut(df1\["逾期30-59天笔数"\],bins3,labels=False)_
_cu4=pd.qcut(df1\["负债率"\],3,labels=False,retbins=True)_
_bins4=cu4\[1\]_
_cu5=pd.qcut(df1\["月收入"\],4,labels=False,retbins=True)_
_bins5=cu5\[1\]_
_cu6=pd.qcut(df1\["信贷数量"\],4,labels=False,retbins=True)_
_bins6=cu6\[1\]_
2.各变量对应的分数求和,算出每个用户的总分
def compute_score(series,bins,score):
list = []
i = 0
while i < len(series):
value = series[i]
j = len(bins) - 2
m = len(bins) - 2
while j >= 0:
if value >= bins[j]:
j = -1
else:
j -= 1
m -= 1
list.append(score[m])
i += 1
return list
_path2=r'/Volumes/win/1/DataStudy/dataset/Give Me Some Credit/cs-test.csv'_
_`test1 = pd.read_csv(path2)`_
test1[‘x1’] = pd.Series(compute_score(test1[‘RevolvingUtilizationOfUnsecuredLines’], bins1, x1))
test1[‘x2’] = pd.Series(compute_score(test1[‘age’], bins2, x2))
test1[‘x3’] = pd.Series(compute_score(test1[‘NumberOfTime30-59DaysPastDueNotWorse’], bins3, x3))
test1[‘x4’] = pd.Series(compute_score(test1[‘DebtRatio’], bins4, x4))
test1[‘x5’] = pd.Series(compute_score(test1[‘MonthlyIncome’], bins5, x5))
test1[‘x6’] = pd.Series(compute_score(test1[‘NumberOfOpenCreditLinesAndLoans’], bins6, x6))
test1[‘x7’] = pd.Series(compute_score(test1[‘NumberOfTimes90DaysLate’], bins7, x7))
test1[‘x8’] = pd.Series(compute_score(test1[‘NumberRealEstateLoansOrLines’], bins8, x8))
test1[‘x9’] = pd.Series(compute_score(test1[‘NumberOfTime60-89DaysPastDueNotWorse’], bins9, x9))
test1[‘x10’] = pd.Series(compute_score(test1[‘NumberOfDependents’], bins10, x10))
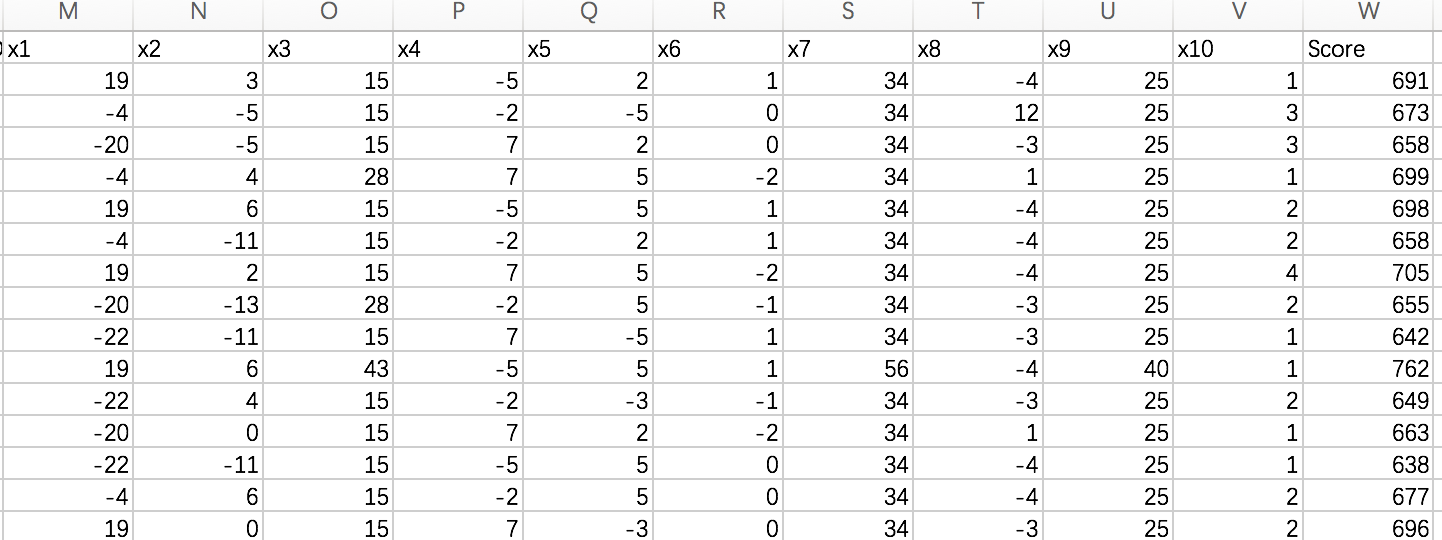
test1[‘Score’] = test1[‘x1’]+test1[‘x2’]+test1[‘x3’]+test1[‘x4’]+test1[‘x5’]+test1[‘x6’]+test1[‘x7’]+test1[‘x8’]+test1[‘x9’]+test1[‘x10’]+600
test1.to\_csv(r'/Volumes/win/1/DataStudy/dataset/Give Me Some Credit/ScoreData.csv', index=False)
评分结果:
九、总结以及展望
========
本文通过对kaggle上的[Give Me Some Credit](https://link.jianshu.com/?t=https://www.kaggle.com/c/GiveMeSomeCredit/data)数据的挖掘分析,结合信用评分卡的建立原理,从数据的预处理、变量选择、建模分析到创建信用评分,创建了一个简单的信用评分系统。
基于AI 的机器学习评分卡系统可通过把旧数据(某个时间点后)剔除掉后再进行自动建模、模型评估、并不断优化特征变量,使得系统更加强大。
* * *
转载:https://www.cnblogs.com/daliner/p/10268350.html
数据来源:[https://www.kaggle.com/c/GiveMeSomeCredit/data](https://www.kaggle.com/c/GiveMeSomeCredit/data)
**在公众号「python风控模型」里回复关键字:学习资料,就可免费领取。**
基于Python的信用评分卡模型-give me some credit就为大家介绍到这里了,欢迎各位同学报名<[python金融风控评分卡模型和数据分析微专业课](https://edu.csdn.net/combo/detail/1927)>
[https://edu.csdn.net/combo/detail/1927](https://edu.csdn.net/combo/detail/1927)















 2350
2350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









