







在公众号「python风控模型」里回复关键字:学习资料
大家好!大家好,今天我们将看到机器学习技术中一个有趣的算法,称为逻辑回归。因此,在进入主题之前,我们需要复习一些基本术语,以便清楚地理解它。
什么是机器学习?
机器学习算法可以访问数据(分类、数字、图像、视频或任何东西)并使用它来自行学习,而无需任何显式编程。但是机器学习技术是如何工作的呢?仅通过观察数据(通过指令观察模式并做出决定或预测)
机器学习的类型:
机器学习算法技术可以大致分为三种类型,
-
监督机器学习——任务驱动(分类和回归)
-
无监督机器学习——数据驱动(聚类)
-
强化机器学习——从错误中学习(奖励或惩罚)
监督机器学习:
利用标记数据集在监督学习中训练算法,其中算法学习每个类别的输入。训练阶段完成后,将根据测试数据(训练集的子集)评估算法并预测结果。监督机器学习分为两种类型,
回归
如果输入变量和输出变量之间存在联系,则应用回归程序。它用于预测连续变量,如天气、市场趋势等。
分类
当输出变量是分类变量时,如 Yes-No、Male-Female、True-False、Normal-Abnormal 等,则使用分类方法。
什么是逻辑回归?
我希望前面的讨论能让我们更好地了解机器学习及其各种类型。逻辑回归是一种用于解决分类问题的机器学习方法。它是一种基于概率思想的预测分析技术。分类算法 Logistic 回归用于预测分类因变量的似然性。逻辑回归中的因变量是二进制变量,数据编码为 1(是、真、正常、成功等)或 0(否、假、异常、失败等)。
Logistic 回归的目标是发现特征与特定结果的可能性之间的联系。例如,当根据学习的小时数预测学生是否通过考试时,响应变量有两个值:通过和失败。
Logistic 回归模型类似于线性回归模型,不同之处在于 Logistic 回归使用更复杂的成本函数,称为“Sigmoid 函数”或“逻辑函数”而不是线性函数。
很多人可能会有一个疑问,Logistic Regression 是分类还是回归范畴。逻辑回归假设表明成本函数被限制在 0 和 1 之间的值。因此,线性函数无法描述它,因为它可能具有大于 1 或小于 0 的值,根据逻辑逻辑,这是不可能的回归假设。
每一位伟大领袖的背后,都有一个更伟大的后勤人员。

为了回答这个问题,逻辑回归也被认为是一种回归模型。该模型创建了一个回归模型来预测给定数据条目属于标记为“1”的类别的可能性。逻辑回归使用 sigmoid 函数对数据进行建模,就像线性回归假设数据服从线性分布一样。
它被称为“逻辑回归”,因为其背后的技术与线性回归非常相似。“Logistic”这个名字来自 Logit 函数,它被用于这种分类方法。
为什么我们不能使用线性回归而不是逻辑回归?
在回答这个问题之前,我们先从线性回归的概念来解释,从头开始才能更好地理解它。虽然逻辑回归是线性回归的兄弟,但它是一种分类技术,尽管它的名字。数学线性回归可以解释为,
y = mx + c
y – 预测值
m – 线的斜率
x – 输入数据
c- Y 轴截距或斜率
我们可以预测 y 值,例如使用这些值。现在观察下图以便更好地理解,
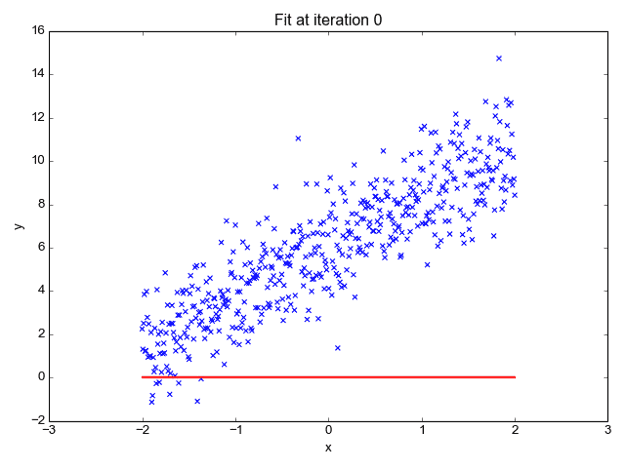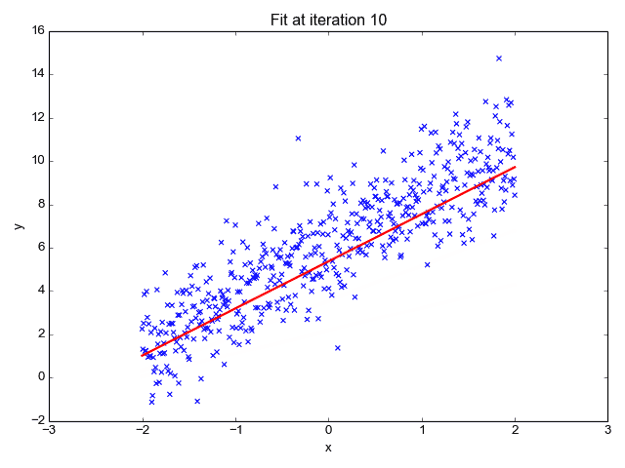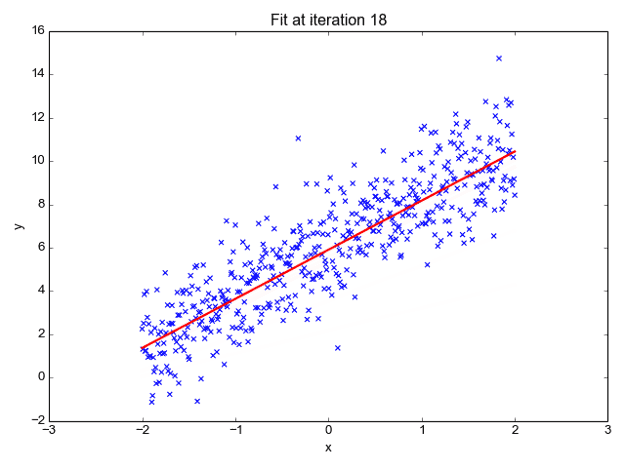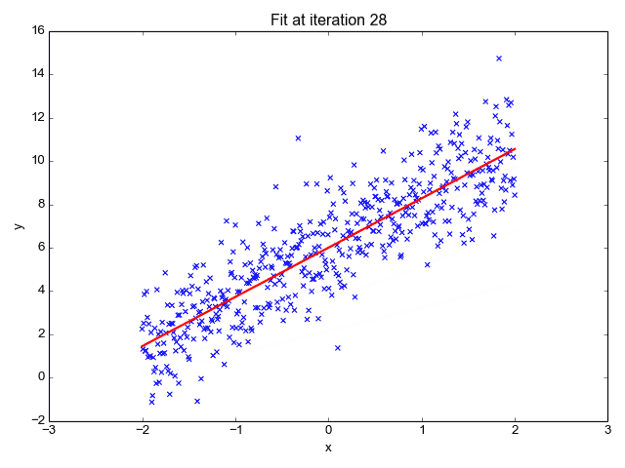
x 值由蓝点(输入数据)表示。我们现在可以使用输入数据计算斜率和 y 坐标,以确保我们的投影线(红线)覆盖大部分位置。我们现在可以使用这条线预测给定 x 值的 y 的任何值。
关于线性回归要记住的一件事是它只适用于连续数据。如果我们想在我们的分类方法中包含线性回归,我们将不得不稍微调整我们的算法。首先,我们必须选择一个阈值,如果我们的预测值小于阈值,则属于第 1 类;否则,它属于第 2 类。
现在,如果您在想,“哦,这很简单,只需创建带有阈值的线性回归,欢呼吧!分类方法,”有一个问题。我们必须手动指定阈值,对于庞大的数据集计算阈值将是不可能的。此外,即使我们的预期值有所不同,阈值也将保持不变。另一方面,逻辑回归产生的逻辑曲线的值限制为 0 和 1。逻辑回归中的曲线是使用目标变量“几率”的自然对数生成的,而不是线性回归中的概率。此外,预测变量不需要有规律地分布或在每组中具有相同的方差。
现在的问题是?
这个著名的标题问题由我们敬爱的人 Andrew Ng 解释,假设我们有关于肿瘤大小和恶性程度的信息。因为这是一个分类问题,我们可以看到所有的值都在 0 和 1 之间。而且,通过拟合最佳回归线并假设阈值为 0.5,我们可以很好地处理这条线。
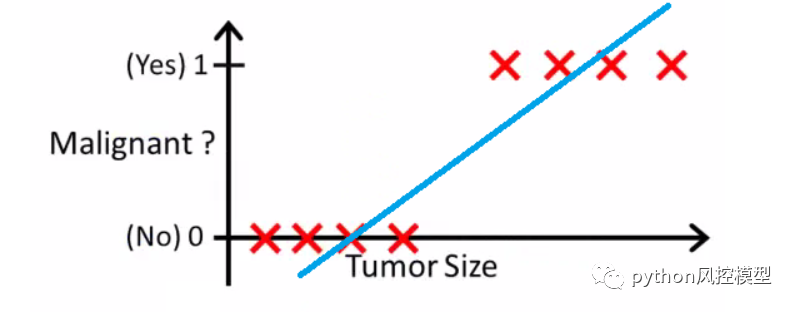
我们可以在 x 轴上选择一个点,从该点左侧的所有值都被视为负值,而右侧的所有值都被视为正值。
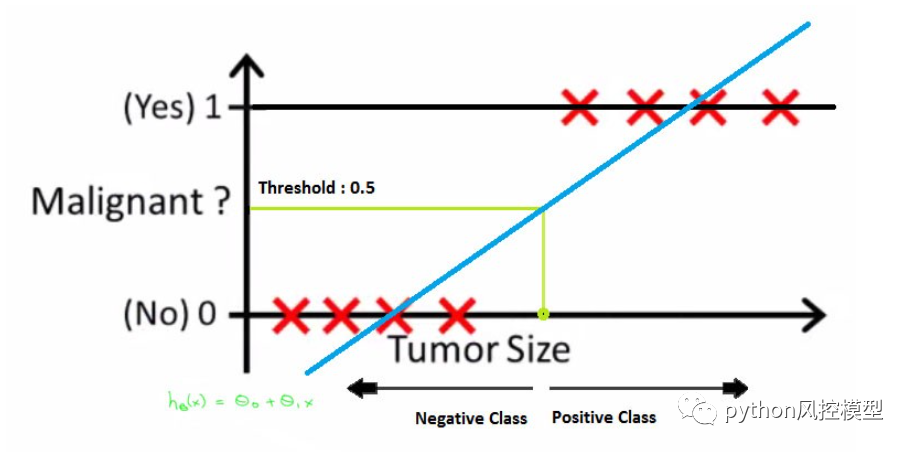
但是如果数据包含异常值怎么办?事情会变得一团糟。例如,对于 0.5 个阈值,
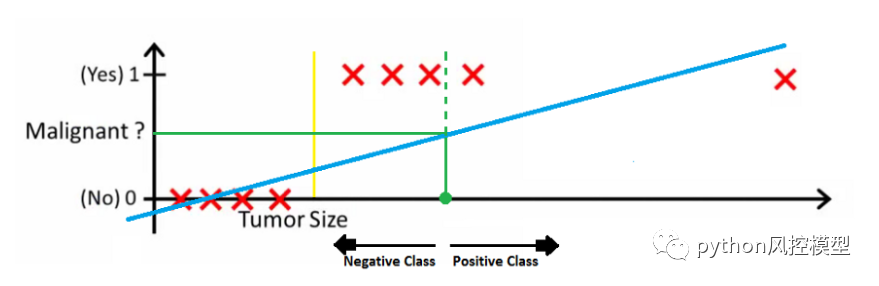
即使我们拟合了最佳回归线,我们也无法确定可以区分类别的任何点。它将正类中的一些实例插入到负类中。绿色虚线(决策边界)将恶性和良性肿瘤分开,但是,它应该是一条明确区分阳性和阴性病例的黄线。结果,即使是单个异常值也可能使线性回归估计无效。在这里,逻辑回归发挥了作用。
Logit 函数到 Sigmoid 函数 - Logistic 回归:
逻辑回归可以表示为,
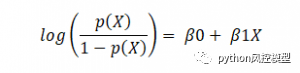
其中 p(x)/(1-p(x)) 称为赔率,左侧称为 logit 或 log-odds 函数。几率是成功几率与失败几率的比值。因此,在逻辑回归中,输入的线性组合被转换为 log(odds),输出为 1。
以下是上述函数的反函数
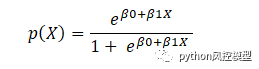
这是 Sigmoid 函数,它产生 S 形曲线。它总是返回一个介于 0 和 1 之间的概率值。Sigmoid 函数用于将期望值转换为概率。该函数将任何实数转换为 0 到 1 之间的数字。我们利用 sigmoid 将预测转换为机器学习中的概率。
数学上的 sigmoid 函数可以是,
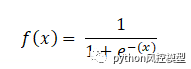
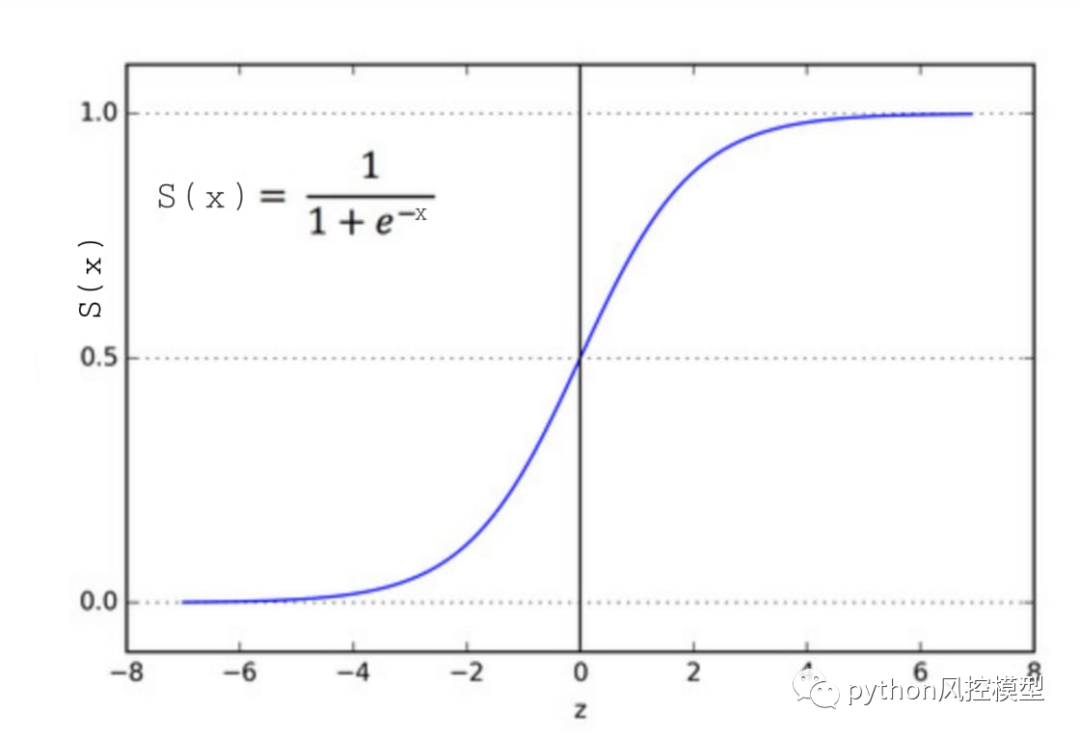
逻辑回归的类型:
大体上可以分为,
1. 二元逻辑回归——两个或二元结果,如是或否
2. 多项 Logistic 回归 - 三个或更多结果,如一等、二等和三等或无学位
3.序数逻辑回归——三个或更多类似于多项逻辑回归,但这里的顺序是超市中的顾客评分从 1 到 5
Logistic 回归正常工作的要求
该模型适用于所有数据集,但是,如果您需要良好的性能,则需要考虑一些假设,
1.二元逻辑回归中的因变量必须是二元的。
2. 只应包括相关的变量。
3. 自变量必须彼此无关。也就是说,模型中的多重共线性应该很小或没有。
4. 对数几率与自变量成正比。
5.逻辑回归需要大样本量。
决策边界 - Logistic 回归
可以建立一个阈值来预测数据属于哪个类。导出的估计概率基于该阈值被分类成类。
如果预测值小于 0.5,则将特定学生归类为通过;否则,将其标记为失败。有两种类型的决策边界:线性和非线性。为了提供复杂的决策边界,可以提高多项式阶数。
为什么用于线性的成本函数不能用于物流?
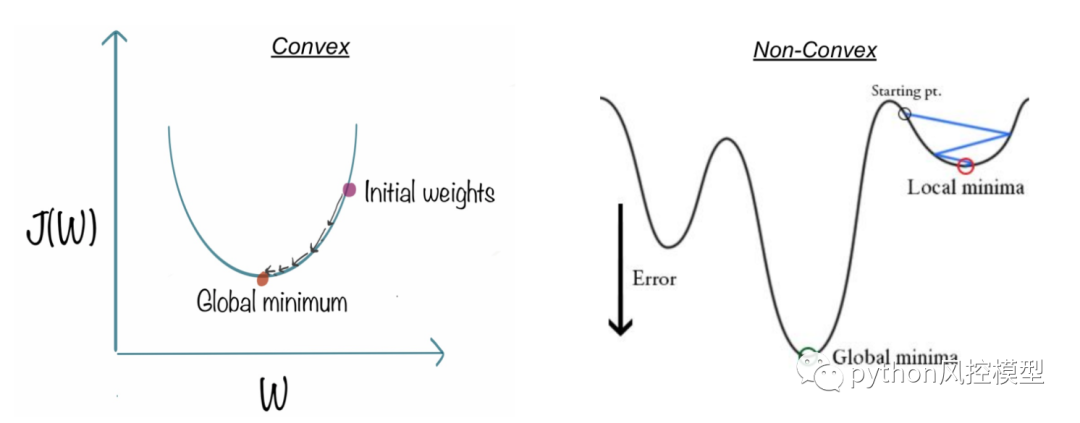
线性回归的成本函数是均方误差。如果这用于逻辑回归,参数的函数将是非凸的。只有当函数是凸函数时,梯度下降才会导致全局最小值。
成本函数 - 线性回归与逻辑回归
线性回归使用最小二乘误差作为损失函数,这会产生一个凸网络,然后我们可以通过将顶点识别为全局最小值来优化它。然而,对于逻辑回归,它不再是可能的。由于假设已被修改,因此在原始模型输出上使用 sigmoid 函数计算最小二乘误差将导致具有局部最小值的非凸图。
什么是成本函数?机器学习中使用成本函数来估计模型的性能有多差。简单地说,成本函数是衡量模型在估计 X 和 y 之间的联系方面有多不准确的度量。这通常表示为预期值和实际值之间的差异或分离。机器学习模型的目标是发现参数、权重或最小化成本函数的结构。
凸函数表示曲线上任意两点之间不会有交点,但非凸函数至少会有一个交点。在成本函数方面,凸类型总是保证全局最小值,而非凸类型仅保证局部最小值。
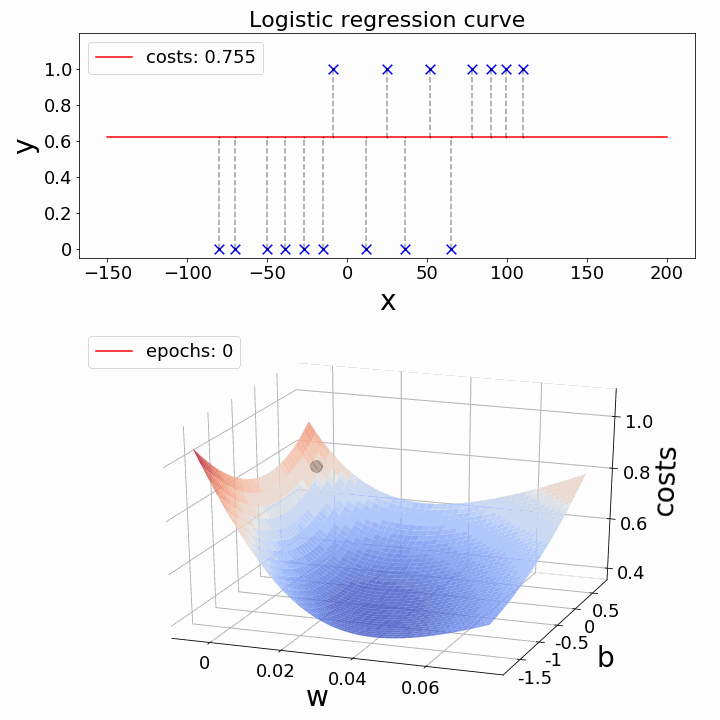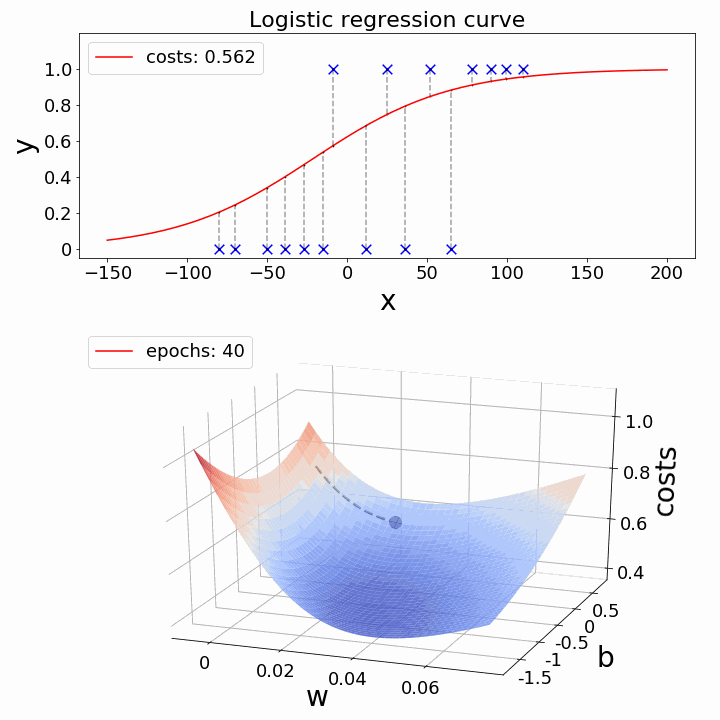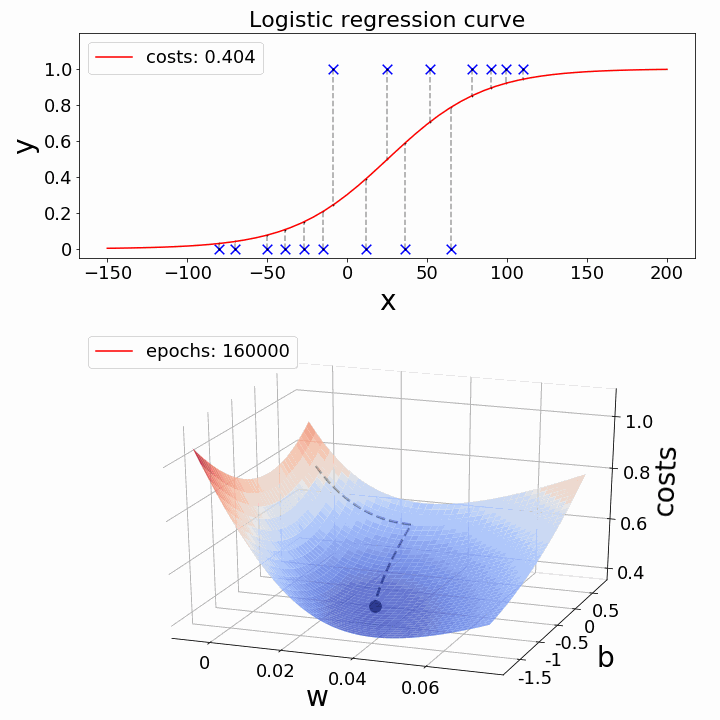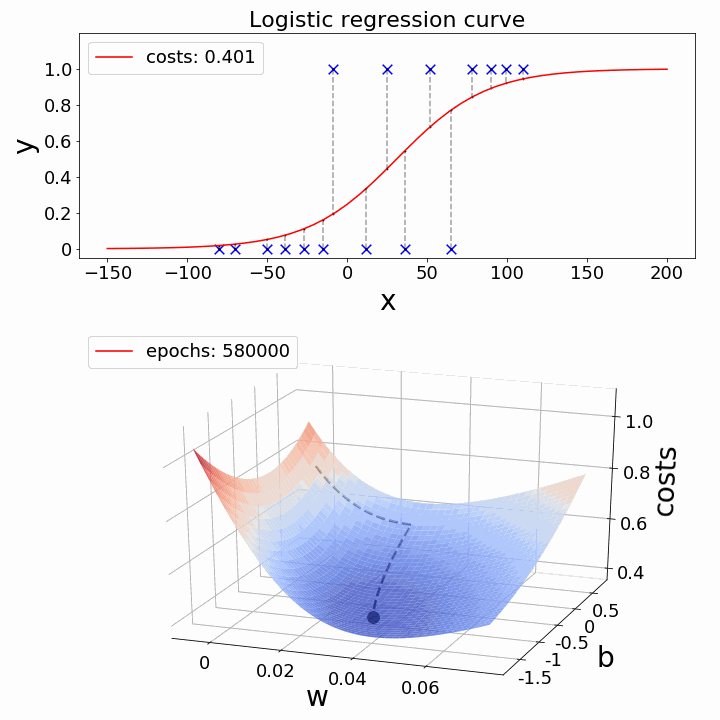
如何降低成本函数?- 梯度下降
现在的挑战是:如何降低成本价值?可以使用梯度下降来实现这一点。梯度下降的主要目标是降低成本值。
正则化
让我们也快速讨论正则化以减少成本函数以将参数与训练数据匹配。L1 (Lasso) 和 L2 (Lasso) 是两种最常见的正则化类型 (Ridge)。正则化不是简单地最大化上述成本函数,而是对系数的大小施加限制以避免过度拟合。L1 和 L2 使用不同的方法来定义系数的上限,允许 L1 通过将系数设置为 0 来进行特征选择,以减少相关性较低的特征并减少多重共线性,而 L2 惩罚非常大的系数,但不会将任何系数设置为 0。还有调节约束权重 λ 的参数,以确保系数不会受到过于严厉的惩罚,从而导致欠拟合。
研究为什么 L1 和 L2 由于“平方”和“绝对”值而具有不同的容量,以及 λ 如何影响正则化和原始拟合项的权重,这是一个有趣的话题。我们不会在这里介绍所有内容,但值得您花时间和精力来了解。以下步骤演示了如何将原始成本函数转换为正则化成本函数。
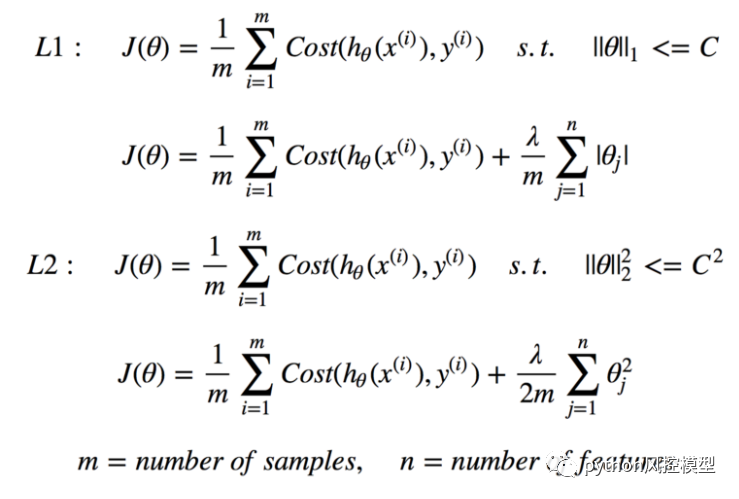
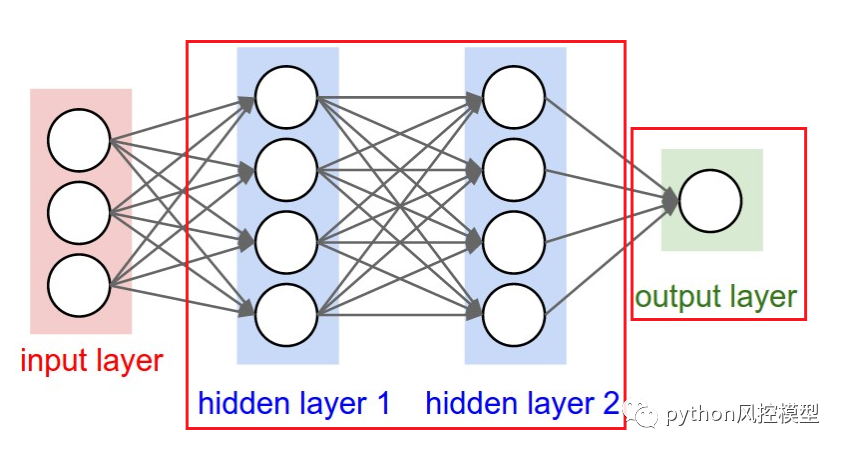
Logistic 回归如何与神经网络联系起来?
我们都知道神经网络是深度学习的基础。最好的部分是逻辑回归与神经网络密切相关。网络中的每个神经元都可以被认为是一个逻辑回归;它包含输入、权重和偏差,在应用任何非线性函数之前,您需要对所有这些进行点积。此外,神经网络的最后一层是一个基本的线性模型(大部分时间)。这可以通过如下图所示的可视化来理解,

深入研究“输出层”,您会注意到它是一个基本的线性(或逻辑)回归:我们有输入(隐藏层 2)、权重、点积,最后是非线性功能,取决于任务。考虑神经网络的一种有用方法是将它们分为两部分:表示和分类/回归。第一部分(左侧)旨在开发一个体面的数据表示,这将有助于第二部分(右侧)进行线性分类/回归。
超参数微调——逻辑回归
在逻辑回归中没有需要调整的基本超参数。尽管它有很多参数,但以下三个参数可能有助于微调以获得更好的结果,
正则化(惩罚)有时可能是有益的。
惩罚 - {‘l1’, ‘l2’, ‘elasticnet’, ‘none’}, default=‘l2’
惩罚强度由 C 参数控制,这可能很有用。
C –浮点数,默认值 = 1.0
使用不同的求解器,您有时可能会观察到有用的性能或收敛变化。
求解器 - {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default=‘lbfgs’
注意:要使用的算法由惩罚决定:求解器支持的惩罚:
1. ‘newton-cg’ – [‘l2’, ‘none’]
2. ‘lbfgs’ – [‘l2’, ‘none’]
3.‘liblinear’ - [‘l1’, ‘l2’]
4. ‘sag’ – [‘l2’, ‘none’]
5. ‘saga’ – [‘elasticnet’, ‘l1’, ‘l2’, ‘none’]
Python 实现
数据集:https : //www.kaggle.com/uciml/breast-cancer-wisconsin-data
每当我们开始编写程序时,我们的第一步总是从导入库开始,
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
在导入库旁边,是我们要导入的数据,无论是从本地磁盘还是从 url 链接
dataset = pd.read_csv('Data.csv')
在进入建模之前,我们需要了解统计重要性以便更好地理解,
如果你了解特征之间的相关性,就会很容易处理,比如添加用于建模或删除
corr_var=dataset.corr()
print(corr_var)
plt.figure(figsize=(10,7.5))
sns.heatmap(corr_var, annot=True, cmap='BuPu')
我们需要在建模之前分离依赖和独立的特征,
X = dataset.iloc[:,:-1].values
y = dataset.iloc[:,-1].values
我们需要拆分为标准格式(70:30 或 80:20),以便在建模过程中对数据进行训练和测试,以提高准确性
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split (X, y, test_size=0.2, random_state=0)
print('Total no. of samples: Training and Testing dataset separately!')
print('X_train:', np.shape(X_train))
print('y_train:', np.shape(y_train))
print('X_test:', np.shape(X_test))
print('y_test:', np.shape(y_test))
由于我们有不同的特征,每个都有不同的缩放或范围,我们需要在训练和新数据集期间进行缩放以获得更好的准确性
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
从 scikit learn 导入逻辑回归
from sklearn.linear_model import LogisticRegression
classifier7 = LogisticRegression()
classifier7.fit(X_train,y_train)
从测试数据集预测最终结果
y_pred7 = classifier7.predict(X_test)
print(np.concatenate((y_pred7.reshape(len(y_pred7),1), y_test.reshape(len(y_test),1)),1))
最后,我们需要通过混淆矩阵、准确率和 roc-auc 分数等分类指标对其进行评估,
from sklearn.metrics import confusion_matrix, accuracy_score, roc_auc_score
cm7 = confusion_matrix(y_test, y_pred7)
print(cm7)
可视化混淆矩阵以获得更好的视图,
from mlxtend.plotting import plot_confusion_matrix
fig, ax = plot_confusion_matrix(conf_mat=cm7, figsize=(6, 6), cmap=plt.cm.Greens)
plt.xlabel('Predictions', fontsize=18)
plt.ylabel('Actuals', fontsize=18)
plt.title('Confusion Matrix', fontsize=18)
plt.show()
我们模型的准确性
logreg=accuracy_score(y_test,y_pred7)
logreg
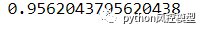
然后最后,AUC-ROC 得分值,越接近 1 使系统更准确
roc_auc_score(y_test, y_pred7)
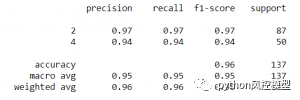
Precision、Recall、F1 Score 的逻辑回归的总体指标报告通过我们的模型预测数据的详细程度可以更好地理解
import sklearn.metrics as metrics
print(metrics.classification_report(y_test, y_pred7))
超参数使我们的模型可以更好地微调参数,并且我们可以手动微调我们的参数以获得稳健的模型,并且可以看到使用参数的重要性的差异
from sklearn.model_selection import GridSearchCV
parameters_lr = [{'penalty':['l1','l2'],'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]}]
grid_search_lr = GridSearchCV(estimator = classifier7,
param_grid = parameters_lr,
scoring = 'accuracy',
cv = 10,
n_jobs = -1)
grid_search_lr.fit(X_train, y_train)
best_accuracy_lr = grid_search_lr.best_score_
best_paramaeter_lr = grid_search_lr.best_params_
print("Best Accuracy of LR: {:.2f} %".format(best_accuracy_lr.mean()*100))
print("Best Parameter of LR:", best_paramaeter_lr)

Logistic 回归的优点
1. 逻辑回归不太可能过度拟合,尽管它可能发生在高维数据集中。在这些情况下,可以使用正则化(L1 和 L2)技术来最小化过拟合。
2.当数据集线性可分时效果很好,对很多基础数据集都有很好的准确率。
3. 应用、理解和培训更直接。
4. 关于每个特征的相关性的推断是基于预期的参数(训练的权重)。协会的方向,积极的或消极的,也被指定。因此,可以使用逻辑回归来确定特征之间的联系。
5. 与决策树或支持向量机不同,该技术允许轻松更改模型以合并新数据。随机梯度下降可用于更新数据。
6. 在具有足够训练实例的低维数据集中不太容易过拟合。
7. 当数据集包含线性可分特征时,Logistic Regression 表现出非常高效。
8. 它与神经网络非常相似。神经网络表示可以被认为是堆叠在一起的小型逻辑回归分类器的集合。
9. 由于其简单的概率解释,逻辑回归方法的训练时间比大多数复杂算法(例如人工神经网络)的训练时间要小得多。
10. 多项 Logistic 回归是一种方法的名称,该方法可以使用 softmax 分类器轻松扩展到多类分类。
逻辑回归的缺点
1. 如果观察数少于特征数,则不应使用 Logistic 回归;否则,可能会导致过拟合。
2. 因为它创建了线性边界,所以在处理复杂或非线性数据时我们不会获得更好的结果。
3. 只对预测离散函数有用。因此,Logistic 回归因变量仅限于离散数集。
4.逻辑回归要求自变量之间存在平均或不存在多重共线性。
5. 逻辑回归需要一个大数据集和足够的训练样本来识别所有类别。
6. 由于此方法对异常值敏感,数据集中存在与预期范围不同的数据值可能会导致错误结果。
7. 仅应利用重要和相关的特征来构建模型;否则,模型的概率预测可能不准确,其预测值可能会受到影响。
8. 复杂的连接很难用逻辑回归表示。这种技术很容易被更强大和更复杂的算法(如神经网络)所超越。
9. 由于逻辑回归具有线性决策面,因此无法解决非线性问题。在现实世界中,线性可分的数据并不常见。因此,必须对非线性特征进行转换,这可以通过增加特征的数量来完成,以便数据可以在更高维度上线性分离。
10. 基于自变量,统计分析模型旨在预测准确的概率结果。在高维数据集上,这可能会导致模型在训练集上过度拟合,夸大训练集预测的准确性,从而阻止模型准确预测测试集上的结果。当模型在少量具有许多特征的训练数据上进行训练时,这是最常见的。应该在高维数据集上探索正则化策略,以最大限度地减少过度拟合(但这会使模型变得复杂)。如果正则化参数过高,模型可能在训练数据上欠拟合。
逻辑回归的应用
逻辑回归涵盖了所有必须将数据分类为多个组的用例。考虑下图:
-
信用卡欺诈检测
-
电子邮件垃圾邮件
-
Twitter分析中的情绪分析
-
图像分割、识别和分类 – X 射线、扫描
-
通过视频进行物体检测
-
手写识别
-
疾病预测——糖尿病、癌症、帕金森等……
机器学习之逻辑回归(Logistic Regression)就为大家介绍到这里了,
欢迎各位同学报名<python金融风控评分卡模型和数据分析微专业课>,学习更多相关知识。
















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











