









前言
往期有讲解过某团字体反爬,感觉效果不太好,所以本章重新找了个例子,希望能帮助大家理解透彻!再遇到直接手撕。
特此说明
如果涉及到版权问题,请立刻联系博主删除!
分析
首先,我们看题目,要求是找出胜点最高的召唤师,意思我们需要先获取胜点

找到数据接口,发现字体都加密了,怎么破呢?这就是本文所要讲解的核心内容!


先找到字体文件,他这里是动态加载的,每次请求结果都不一样,请求一次就保存一次,实时获取!

这里就已经保存本地了,pycharm不能直接读取woff文件,所以需要通过fontTools库操作woff
pip install fontTools
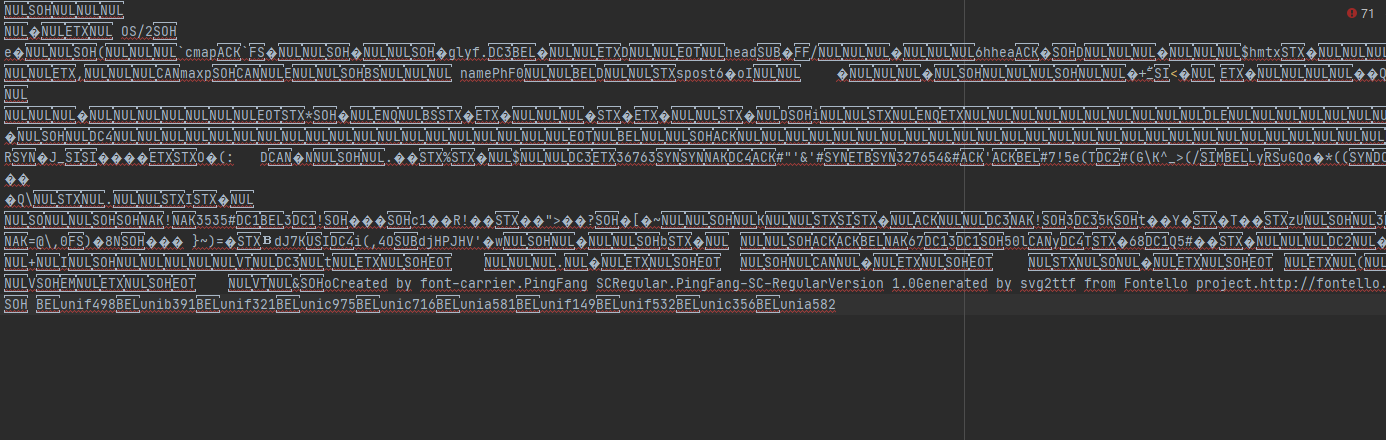
解密之后,保存为xml文件,为后面找出字体与编码的对应关系
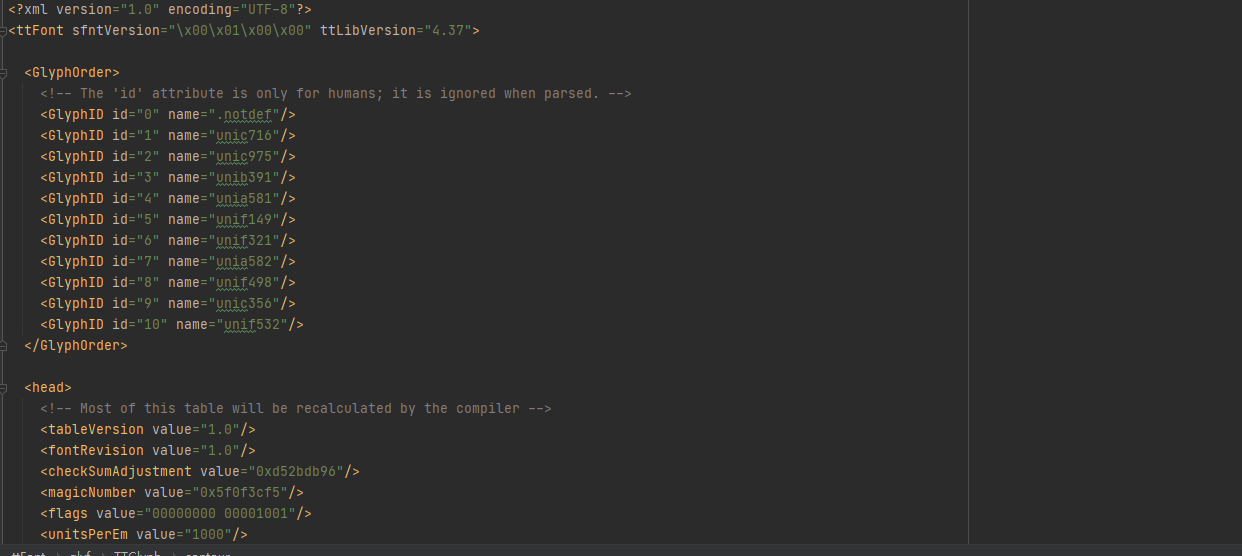
代码过程
-
请求数据接口
def get_html(page): headers = { "user-agent": "yuanrenxue.project" # 题目要求,必须加上请求头 } url = f"https://match.yuanrenxue.com/api/match/7?page={page}" # 数据有5页,通过遍历实现 print(url) req = requests.get(url=url, headers=headers) return req.json() # 返回json格式 -
获取woff字体文件
def with_ttf(woff): b64_code = woff with open('font.woff', 'wb') as f: f.write(base64.decodebytes(b64_code.encode())) # 解码
解析字体文件,处理编码与字体的对应关系,这一步是关键点,所以着重说明:接口中字体前三位字符是&#x,而woff文件中前三位是uni,后面四位字符则其对应,所以我们需要将一方转换成另一方,这样才方便我们后续匹配
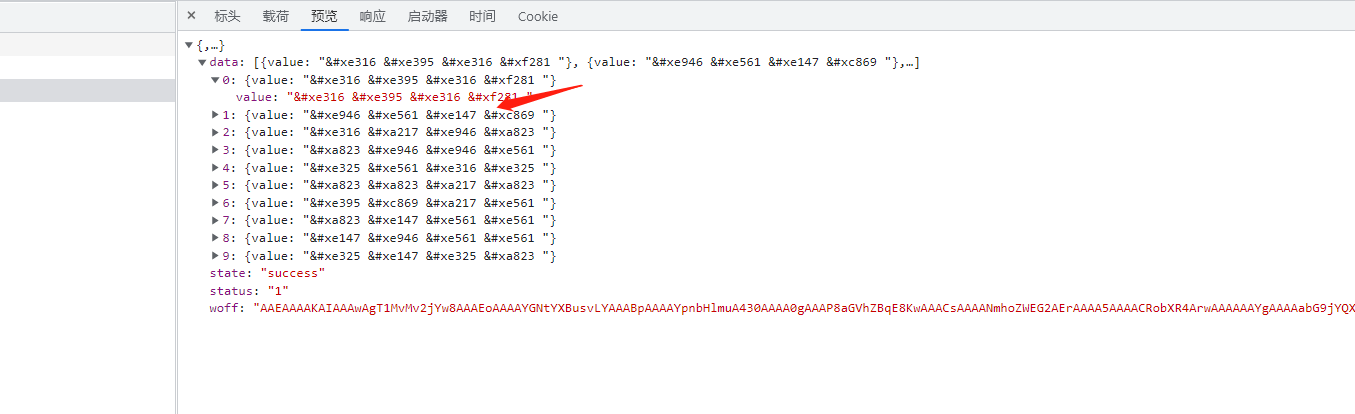

处理对应关系,我们根据编码找出对应的glfy值,无论编码如何变化,值是不会改变的
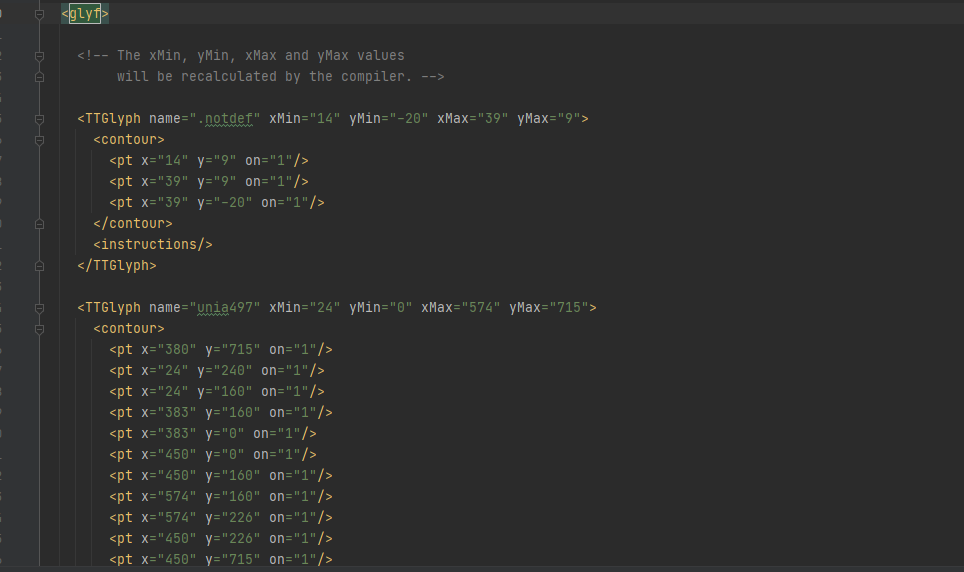
- 保存xml文件
def get_xml(data):
font = TTFont('font.woff') # 打开woff文件
font.saveXML('movie.xml') # 保存xml文件
data_value = data.get('value').strip().replace('&#x', 'uni') # 替换&#x为uni
data_value_list = data_value.split(" ") # 去除空格
map_num_list = []
for data_v in data_value_list:
flags_num = list(font['glyf'][data_v].flags) # 得到编码映射的值
flags_num_str = "".join([str(flag) for flag in flags_num]) # 列表推导式
print(flags_num_str)
结果:通过得到的值对比网页数据,就能找到对应的关系


下面就是对应的字体,然后我们进行匹配
map_num = {
"10100100100101010010010010": '0',
"100110101001010101011110101000": '2',
"111111111111111": '4',
"1110101001001010110101010100101011111": '5',
"1001101111": '1',
"10010101001110101011010101010101000100100": '9',
"101010101101010001010101101010101010010010010101001000010": '8',
"10101100101000111100010101011010100101010100": '3',
"1111111": '7',
"10101010100001010111010101101010010101000": '6'
}
- 获取字体编码映射值
def get_xml(data):
font = TTFont('font.woff') # 打开woff文件
font.saveXML('movie.xml') # 保存xml文件
data_value = data.get('value').strip().replace('&#x', 'uni') # 替换&#x为uni
data_value_list = data_value.split(" ") # 去除空格
map_num_list = []
for data_v in data_value_list:
map_num = {
"10100100100101010010010010": '0',
"100110101001010101011110101000": '2',
"111111111111111": '4',
"1110101001001010110101010100101011111": '5',
"1001101111": '1',
"10010101001110101011010101010101000100100": '9',
"101010101101010001010101101010101010010010010101001000010": '8',
"10101100101000111100010101011010100101010100": '3',
"1111111": '7',
"10101010100001010111010101101010010101000": '6'
} # 映射值
flags_num = list(font['glyf'][data_v].flags) # 每个编码对应的值
flags_num_str = "".join([str(flag) for flag in flags_num]) # 列表推导式
map_num_list.append(map_num[flags_num_str]) # 匹配成功后,添加到刘表
return "".join(map_num_list)
成果
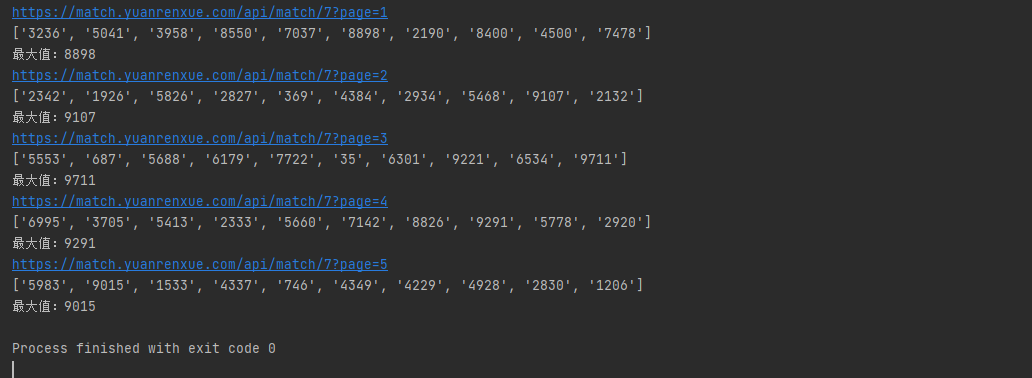
完整源码
from fontTools.ttLib import TTFont
import requests
import json
import base64
def get_html(page):
headers = {
"user-agent": "yuanrenxue.project",
}
url = f"https://match.yuanrenxue.com/api/match/7?page={page}"
print(url)
req = requests.get(url=url, headers=headers).json()
return req
def with_ttf(woff):
b64_code = woff
with open('font.woff', 'wb') as f:
f.write(base64.decodebytes(b64_code.encode()))
def get_xml(data):
font = TTFont('font.woff')
font.saveXML('movie.xml')
data_value = data.get('value').strip().replace('&#x', 'uni')
data_value_list = data_value.split(" ")
map_num_list = []
for data_v in data_value_list:
map_num = {
"10100100100101010010010010": '0',
"100110101001010101011110101000": '2',
"111111111111111": '4',
"1110101001001010110101010100101011111": '5',
"1001101111": '1',
"10010101001110101011010101010101000100100": '9',
"101010101101010001010101101010101010010010010101001000010": '8',
"10101100101000111100010101011010100101010100": '3',
"1111111": '7',
"10101010100001010111010101101010010101000": '6'
}
flags_num = list(font['glyf'][data_v].flags)
flags_num_str = "".join([str(flag) for flag in flags_num])
map_num_list.append(map_num[flags_num_str])
return "".join(map_num_list)
if __name__ == '__main__':
for page in range(1,6):
res = get_html(page)
woff = res.get('woff')
with_ttf(woff)
data_num = []
for data in res.get('data'):
map_num_str = get_xml(data)
data_num.append(map_num_str)
print(data_num)
print(f'最大值:{max(data_num)}')
点关注不迷路,本文若对你有帮助,烦请三连支持一下 ❤️❤️❤️
各位的支持和认可就是我最大的动力❤️❤️❤️

















 2917
2917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









