







一. 准备工作
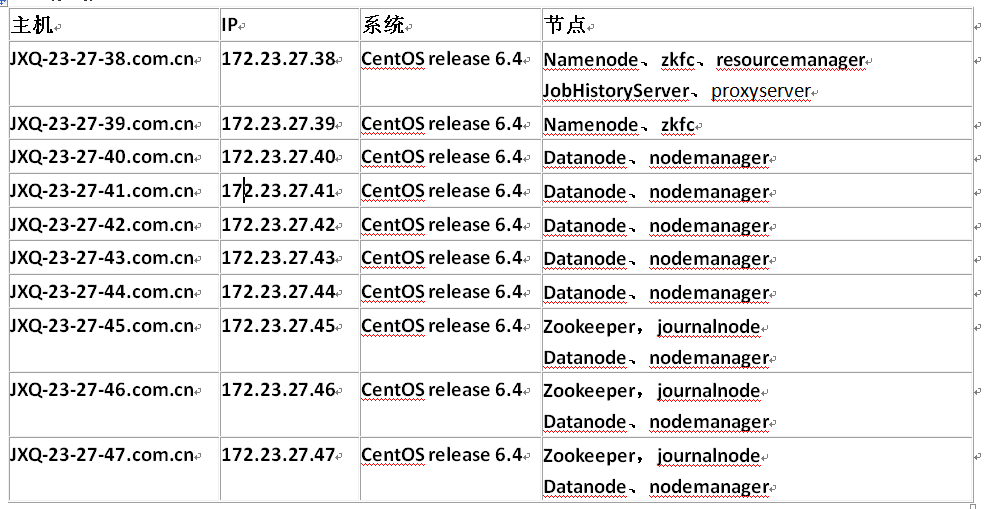
规划:
1 . CDH5的YUM源设置:
安装httpd作为http的yum源服务
[root@JXQ-23-27-48 ~]# yum install httpd
配置yum源(需要开通网络80端口)
[root@JXQ-23-27-38 ~]# cat /etc/yum.repos.d/cloudera-cdh5.repo
[cloudera-cdh5]
# Packages for Cloudera's Distribution for Hadoop, Version 5, on RedHat or CentOS 6 x86_64
name=Cloudera's Distribution for Hadoop, Version 5
baseurl=http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/5/
gpgkey = http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
gpgcheck = 0
[root@JXQ-23-27-38 ~]# cd /etc/yum.repos.d/
[root@JXQ-23-27-38yum.repos.d]# wget http://archive-primary.cloudera.com/gplextras5/redhat/6/x86_64/gplextras/cloudera-gplextras5.repo
下载cdh5源至本地:
[root@JXQ-23-27-48 ~]# reposync -r cloudera-cdh5
[root@JXQ-23-27-48 ~]# reposync -r cloudera-gplextras5
[root@JXQ-23-27-48 ~]#mkdir /var/www/html/repo/cdh/5 –pv
[root@JXQ-23-27-48 ~]# cp -r cloudera-cdh5/* /var/www/html/repo/cdh/5/
[root@JXQ-23-27-48 ~]# cp -r cloudera-gplextras5 /var/www/html/repo/
创建repo元数据文件
[root@JXQ-23-27-48 ~]# cd /var/www/html/repo/cdh/5/
[root@JXQ-23-27-48 5]# createrepo .
[root@JXQ-23-27-48 repo]# cd /var/www/html/repo/cloudera-gplextras5/
启动httpd
[root@JXQ-23-27-48 5]# service httpd start
集群yum配置:(要安装hadoop的所有机器将yum源指向自己本地http源)
[root@JXQ-23-27-49 ~]# cat /etc/yum.repos.d/cloudera.repo
[cdh]
name=cdh
baseurl=http://172.23.27.38/repo/cdh/5
enabled=1
gpgcheck=0
[ext]
name=ext
baseurl=http://172.23.27.38/repo/cloudera-gplextras5
enabled=1
gpgcheck=0
yum clean all
2 . 修改主机名:
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=JXQ-23-27-38.h.chinabank.com.cn
3 . 修改IP:
DEVICE=eth0
BOOTPROTO=static
IPADDR=172.23.27.38
NETMASK=255.255.254.0
NM_CONTROLLED=yes
ONBOOT=yes
TYPE=Ethernet
GATEWAY=172.23.27.254
4 . 配置/etc/hosts,修改主机与IP映射关系:
[root@JXQ-23-27-38 cdh5-test]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain
172.23.27.38 JXQ-23-27-38.h.chinabank.com.cn
172.23.27.39 JXQ-23-27-39.h.chinabank.com.cn
172.23.27.40 JXQ-23-27-40.h.chinabank.com.cn
172.23.27.41 JXQ-23-27-41.h.chinabank.com.cn
172.23.27.42 JXQ-23-27-42.h.chinabank.com.cn
172.23.27.43 JXQ-23-27-43.h.chinabank.com.cn
172.23.27.44 JXQ-23-27-44.h.chinabank.com.cn
172.23.27.45 JXQ-23-27-45.h.chinabank.com.cn
172.23.27.46 JXQ-23-27-46.h.chinabank.com.cn
172.23.27.47 JXQ-23-27-47.h.chinabank.com.cn
5 . 禁用IPV6方法:
$ vim /etc/sysctl.conf
#disable ipv6
net.ipv6.conf.all.disable_ipv6=1
net.ipv6.conf.default.disable_ipv6=1
net.ipv6.conf.lo.disable_ipv6=1
使其生效:
$ sysctl -p
最后确认是否已禁用:
$ cat /proc/sys/net/ipv6/conf/all/disable_ipv6
1
6 . 关闭防火墙:
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
7 . 关闭SElinux:
查看SElinux状态
getenforce
修改配置文件需要重启机器:
修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled
8 . 修改DNS(选做):
省略...9 . 配置ntp时钟同步(选做):
选择一台作为ntp时钟同步服务器,比如第一台
安装ntp:
$ yum install ntp
修改第一台/etc/ntp.conf
restrict default ignore
//默认不允许修改或者查询ntp,并且不接收特殊封包
restrict 127.0.0.1 //给于本机所有权限
restrict 192.168.56.0 mask 255.255.255.0 notrap nomodify
//给于局域网机的机器有同步时间的权限
server 192.168.56.121 # local clock
driftfile /var/lib/ntp/drift
fudge 127.127.1.0 stratum 10
启动 ntp:
$ service ntpd start
设置开机启动:
$ chkconfig ntpd on
-------------------------------------
ntpq用来监视ntpd操作,使用标准的NTP模式6控制消息模式,并与NTP服务器通信。
ntpq -p 查询网络中的NTP服务器,同时显示客户端和每个服务器的关系。
在子节点上执行下面操作:
$ ntpdate JXQ-23-27-11.h.chinabank.com.cn
Ntpd启动的时候通常需要一段时间大概5分钟进行时间同步,所以在ntpd刚刚启动的时候还不能正常提供时钟服务,
报错"no server suitable for synchronization found"。启动时候需要等待5分钟。
如果想定时进行时间校准,可以使用crond服务来定时执行。
00 1 * * * root /usr/sbin/ntpdate 192.168.56.121 >> /root/ntpdate.log 2>&1
这样,每天 1:00 Linux 系统就会自动的进行网络时间校准。
10 . 安装ssh服务:
安装SSH:
yum install ssh
启动SSH:
service sshd start
设置开机运行:
chkconfig sshd on
11 . 配置无密登录:
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
ssh-copy-id '-p 51899 pe@172.23.27.38'
ssh-copy-id '-p 51899 pe@172.23.27.39'
ssh-copy-id '-p 51899 pe@172.23.27.40'
....
需要注意的是:(至少保证)
38 ssh-copy-id 所有机器
39 ssh-copy-id 所有机器
40 ssh-copy-id 38/39/40
41 ssh-copy-id 38/39/41
42 ssh-copy-id 38/39/42
43 ssh-copy-id 38/39/43
44 ssh-copy-id 38/39/44
45 ssh-copy-id 38/39/45/46/47
46 ssh-copy-id 38/39/45/46/47
47 ssh-copy-id 38/39/45/46/47
12 . JDK安装:
rpm -ivh http://172.23.27.48/repo/jdk-7u51-linux-x64.rpm
alternatives --install /usr/bin/java java /usr/java/default/bin/java 3
alternatives --config java
alternatives --install /usr/bin/java java /usr/java/latest/bin/java 1600
alternatives --auto java
alternatives --install /usr/bin/jpsjps /usr/java/latest/bin/jps 1
或者jdk压缩包安装
12.1上传
12.2解压jdk
#创建文件夹
mkdir /usr/java
#解压
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /usr/java/
12.3将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/usr/java/jdk1.7.0_65
export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source /etc/profil
13 . 时区调整(选做):
rm -rf /etc/localtime
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
14 . hugepage配置(选做):
echo 'never' > /sys/kernel/mm/redhat_transparent_hugepage/enabled
echo 'never' > /sys/kernel/mm/redhat_transparent_hugepage/defrag
echo "echo 'never' > /sys/kernel/mm/redhat_transparent_hugepage/enabled" >> /etc/rc.d/rc.local
echo "echo 'never' > /sys/kernel/mm/redhat_transparent_hugepage/defrag" >> /etc/rc.d/rc.local
15 . blockdev(选做):
echo "blockdev --setra 16384 /dev/sd*">>/etc/rc.d/rc.local16 . ulimit设置:
sed -i '/^#/!d' /etc/security/limits.conf
sed -i '/^#/!d' /etc/security/limits.d/90-nproc.conf
echo '* soft nofile 65536' >>/etc/security/limits.conf
echo '* hard nofile 65536' >>/etc/security/limits.conf
echo '* soft nproc 131072' >>/etc/security/limits.conf
echo '* hard nproc 131072' >>/etc/security/limits.conf
echo '* soft nofile 65536' >>/etc/security/limits.d/90-nproc.conf
echo '* hard nofile 65536' >>/etc/security/limits.d/90-nproc.conf
echo '* soft nproc 131072' >>/etc/security/limits.d/90-nproc.conf
echo '* hard nproc 131072' >>/etc/security/limits.d/90-nproc.conf
17 . sudo设置:
sudo命令默认是不能在后台运行的,如果需要在后台运行(比如nagios的被监控服务器端),就需要将/etc/sudoers文件中以下一行注释掉
sed -i 's/Defaults requiretty/#Defaults requiretty/g' /etc/sudoers
18 . 网卡bonding(选做):
省略...19 . 格式化12块硬盘(选做):
省略...二. 开始安装zookeeper
Zookeeper 至少需要3个节点,并且节点数要求是奇数,这里在45,46,47
在每个节点上安装zookeeper
$ yum install zookeeper* -y
设置 zookeeper 配置 /etc/zookeeper/conf/zoo.cfg
maxClientCnxns=50
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/var/lib/zookeeper
clientPort=2181
server.1=cdh1:2888:3888
server.2=cdh3:2888:3888
server.3=cdh3:2888:3888同步配置文件
将配置文件同步到其他节点:
$ scp -r /etc/zookeeper/conf root@cdh2:/etc/zookeeper/
$ scp -r /etc/zookeeper/conf root@cdh3:/etc/zookeeper/初始化并启动服务
在每个节点上初始化并启动 zookeeper,注意 n 的值需要和 zoo.cfg 中的编号一致。
在 cdh1 节点运行
$ service zookeeper-server init --myid=1
$ service zookeeper-server start在 cdh2 节点运行
$ service zookeeper-server init --myid=2
$ service zookeeper-server start在 cdh3 节点运行
$ service zookeeper-server init --myid=3
$ service zookeeper-server start安装journalnode实现元数据的同步
yum -y install hadoop-hdfs-journalnode hadoop-lzo
三. 开始安装hadoop
主namenode:(172.23.27.38)
yum -y install hadoop-hdfs-namenode
hadoop-hdfs-zkfc
hadoop-lzo
hadoop-mapreduce-historyserver
hadoop-yarn-resourcemanager
hadoop-yarn-proxyserver辅namenode:(172.23.27.39)
um -y install hadoop-hdfs-namenode
hadoop-hdfs-zkfc
hadoop-lzo
datanode、nodemanager安装:(40,41,42,43,44,45,46,47)
yum -y install hadoop-yarn-nodemanager
hadoop-hdfs-datanode
hadoop-mapreduce
hadoop-lzo
四. HDFS目录创建,所有机器(一些中间数据,输出数据)
mkdir -pv /export/hdfs/{1..2}/mapred
mkdir -pv /export/hdfs/{1..2}/yarn
chown -R hdfs:hadoop /export/hdfs/
chown -R mapred:hadoop /export/hdfs/{1..2}/mapred
chown -R yarn:yarn /export/hdfs/{1..2}/yarn
五. hadoop激活配置文件
创建hadoop配置文件
cp -r /etc/hadoop/conf.dist /etc/hadoop/cdh5-test
或者从别处拷贝来一份
mv /tmp/cdh5-test /etc/hadoop/
激活新的配置文件
alternatives --install /etc/hadoop/conf hadoop-conf /etc/hadoop/cdh5-test 50
alternatives --set hadoop-conf /etc/hadoop/cdh5-test
alternatives --display hadoop-conf
chown root:root -R /etc/hadoop/conf/
六. 配置文件
1 . 集群允许加载的节点列表文件
[root@JXQ-23-27-38 cdh5-test]# cat allowed_hosts
172.23.27.40 JXQ-23-27-40.h.chinabank.com.cn
172.23.27.41 JXQ-23-27-41.h.chinabank.com.cn
172.23.27.42 JXQ-23-27-42.h.chinabank.com.cn
172.23.27.43 JXQ-23-27-43.h.chinabank.com.cn
172.23.27.44 JXQ-23-27-44.h.chinabank.com.cn
172.23.27.45 JXQ-23-27-45.h.chinabank.com.cn
172.23.27.46 JXQ-23-27-46.h.chinabank.com.cn
172.23.27.47 JXQ-23-27-47.h.chinabank.com.cn
2 . 容量模型资源调度
[root@JXQ-23-27-38 ~]# cat /etc/hadoop/cdh5-test/capacity-scheduler.xml
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
Maximum number of applications that can be pending and running.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>-1</value>
<description>
Number of missed scheduling opportunities after which the CapacityScheduler
attempts to schedule rack-local containers.
Typically this should be set to number of racks in the cluster, this
feature is disabled by default, set to -1.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,BI,DA,fxff,jrselect_user</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>75</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>75</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.DA.capacity</name>
<value>10</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.DA.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.DA.maximum-capacity</name>
<value>10</value>
<description>
The maximum capacity of the DA queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.DA.state</name>
<value>RUNNING</value>
<description>
The state of the DA queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.DA.acl_submit_applications</name>
<value>DA,supdev,dev DA,supdev,dev</value>
<description>
The ACL of who can submit jobs to the DA queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.DA.acl_administer_queue</name>
<value>DA,supdev,dev DA,supdev,dev</value>
<description>
The ACL of who can administer jobs on the DA queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.BI.capacity</name>
<value>5</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.BI.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.BI.maximum-capacity</name>
<value>5</value>
<description>
The maximum capacity of the BI queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.BI.state</name>
<value>RUNNING</value>
<description>
The state of the BI queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.BI.acl_submit_applications</name>
<value>BI,dwetl BI,dwetl</value>
<description>
The ACL of who can submit jobs to the BI queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.BI.acl_administer_queue</name>
<value>BI,dwetl BI,dwetl</value>
<description>
The ACL of who can administer jobs on the BI queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.fxff.capacity</name>
<value>5</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.fxff.maximum-capacity</name>
<value>5</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.jrselect_user.capacity</name>
<value>5</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.jrselect_user.maximum-capacity</name>
<value>5</value>
</property>
</configuration>3 . core-site.xml
[root@JXQ-23-27-38 ~]# cat /etc/hadoop/cdh5-test/core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cdh5-test</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>172.23.27.45:2181,172.23.27.46:2181,172.23.27.47:2181</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
<description>
10080mins=7day.
Number of minutes between trash checkpoints. If zero, the trash feature is disabled
</description>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>10080</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>fs.inmemory.size.mb</name>
<value>300</value>
</property>
<property>
<name>webinterface.private.actions</name>
<value>true</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<!-- Hue WebHDFS proxy user setting -->
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>mapred</value>
</property>
<!-- hue -->
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}-${hue.suffix}</value>
</property>
<!-- rack topology -->
<property>
<name>net.topology.script.file.name</name>
<value>/etc/hadoop/conf/topo.sh</value>
</property>
</configuration>4 . Hdfs-site.xml
[root@JXQ-23-27-38 ~]# cat /etc/hadoop/cdh5-test/hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>cdh5-test</value>
</property>
<property>
<name>dfs.ha.namenodes.cdh5-test</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cdh5-test.nn1</name>
<value>172.23.27.38:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cdh5-test.nn2</name>
<value>172.23.27.39:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.cdh5-test.nn1</name>
<value>172.23.27.38:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cdh5-test.nn2</name>
<value>172.23.27.39:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.23.27.45:8485;172.23.27.46:8485;172.23.27.47:8485/cdh5-test</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cdh5-test</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/var/lib/hadoop-hdfs/fencingscript.sh)</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--
fencingscript.sh
#!/bin/bash
isNNEmpty=`/usr/java/latest/bin/jps | grep NameNode`
if [ "X${isNNEmpty}" = "X" ]; then
service hadoop-hdfs-namenode start
fi
exit 0
-->
<!--
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence([[username][:port]])</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/hdfs/journalnode</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/export/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/export/hdfs/1/datanode,/export/hdfs/2/datanode</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>299</value>
<!--suggest <value>100</value> -->
<!--jd <value>299</value> -->
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>12</value>
</property>
<property>
<name>dfs.datanode.du.reserved</name>
<value>10474836480</value>
<!--jd <value>10474836480</value>-->
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.failed.volumes.tolerated</name>
<value>1</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>4194304</value>
</property>
<property>
<name>dfs.hosts</name>
<value>/etc/hadoop/conf/allowed_hosts</value>
<!-- all datanode node -->
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/etc/hadoop/conf/exclude_datanode_hosts</value>
</property>
<!--hbase-->
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<!--suggest <value>2048</value> -->
<value>65535</value>
</property>
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>600</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/mnt/hdfs/checkpoint</value>
</property>
<property>
<name>dfs.namenode.avoid.read.stale.datanode</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.avoid.write.stale.datanode</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.stale.datanode.interval</name>
<value>30000</value>
</property>
<!-- impala -->
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hadoop-hdfs/dn._PORT</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout</name>
<value>3000</value>
</property>
<property>
<name>dfs.block.local-path-access.user</name>
<value>impala</value>
</property>
<!-- zrr don't set this
<property>
<name>dfs.client.use.legacy.blockreader.local</name>
<value>true</value>
</property>
-->
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>750</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
<!-- impala -->
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50010</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.safemode.threshold-pct</name>
<value>0.999</value>
</property>
</configuration>5 . mapred-site.xml
[root@JXQ-23-27-38 ~]# cat /etc/hadoop/cdh5-test/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/mnt/hdfs/1/mapred,/mnt/hdfs/2/mapred</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/user/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>172.23.27.38:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>172.23.27.38:19888</value>
</property>
<property>
<name>mapreduce.job.reduces</name>
<value>256</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx4096M</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx3072M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx3072M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>1024</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>120</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>32</value>
</property>
<property>
<name>mapreduce.map.speculative</name>
<value>false</value>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>false</value>
</property>
<property>
<name>mapreduce.job.reduce.slowstart.completedmaps</name>
<value>0.95</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>8080</value>
</property>
<!-- MapReduce intermediate compression -->
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<!-- MapReduce final output compression -->
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>false</value>
</property>
<property>
<name>mapred.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>BLOCK</value>
</property>
<!-- MapReduce counter -->
<property>
<name>mapreduce.job.counters.max</name>
<value>250</value>
</property>
<!-- MapReduce retry -->
<property>
<name>mapreduce.am.max-attempts</name>
<value>2</value>
</property>
<property>
<name>mapreduce.map.maxattempts</name>
<value>3</value>
</property>
<property>
<name>mapreduce.reduce.maxattempts</name>
<value>3</value>
</property>
<property>
<name>mapreduce.map.failures.maxpercent</name>
<value>50</value>
</property>
</configuration>6 . yarn-site.xml
[root@JXQ-23-27-38 ~]# cat /etc/hadoop/cdh5-test/yarn-site.xml
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- CPU Cores -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>12</value>
</property>
<!-- Memory limits -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>7168</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>172.23.27.38:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>172.23.27.38:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>172.23.27.38:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>172.23.27.38:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>172.23.27.38:8088</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/*,
$HADOOP_COMMON_HOME/lib/*,
$HADOOP_HDFS_HOME/*,
$HADOOP_HDFS_HOME/lib/*,
$HADOOP_MAPRED_HOME/*,
$HADOOP_MAPRED_HOME/lib/*,
$HADOOP_YARN_HOME/*,
$HADOOP_YARN_HOME/lib/*
</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/export/hdfs/1/yarn/local,/export/hdfs/2/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/export/hdfs/1/yarn/logs,/export/hdfs/2/yarn/logs</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.aggregation.enable</name>
<value>true</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/var/log/hadoop-yarn/apps</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>21</value>
</property>
<!-- as part of resourcemanager -->
<property>
<name>yarn.web-proxy.address</name>
<value>172.23.27.38:54315</value>
</property>
<!-- zrr resoucemanager:8088 -->
<!-- Fair scheduling is a method of assigning resources to jobs such that all jobs get, on average, an equal
share of resources over time. When there is a single job running, that job uses the entire cluster. -->
<!--
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/etc/hadoop/conf/fair_scheduler.xml</value>
</property>
-->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>2</value>
</property>
</configuration>7 . topo.data
[root@JXQ-23-27-38 cdh5-test]# cat topo.data
172.23.27.40 /rack040
172.23.27.41 /rack041
172.23.27.42 /rack042
172.23.27.43 /rack043
172.23.27.44 /rack044
172.23.27.45 /rack045
172.23.27.46 /rack046
172.23.27.47 /rack047
8 . topo.sh
[root@JXQ-23-27-38 cdh5-test]# cat topo.sh
#!/bin/sh
HADOOP_CONF=/etc/hadoop/conf
echo `date` input: $@ >> /tmp/topology.log
while [ $# -gt 0 ] ; do
nodeArg=$1
exec< ${HADOOP_CONF}/topo.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ] ; then
result="${ar[1]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default/rack"
else
echo -n "$result"
fi
done
七. 同步文件(所有机器)
1 . 配置环境变量 /etc/profile
export HADOOP_HOME=/usr/lib/hadoop
export HADOOP_HDFS_HOME=/usr/lib/hadoop-hdfs
export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
export HADOOP_YARN_HOME=/usr/lib/hadoop-yarn
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_LIBEXEC_DIR=${HADOOP_HOME}/libexec
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
2 . 拷贝conf文件夹(就是/etc/hadoop/cdh5-test)
scp -P 51899 -r /etc/hadoop/conf pe@172.23.27.39:/tmp
scp -P 51899 -r /etc/hadoop/conf pe@172.23.27.40:/tmp
.....
scp -P 51899 -r /etc/hadoop/conf pe@172.23.27.46:/tmp
scp -P 51899 -r /etc/hadoop/conf pe@172.23.27.47:/tmp
因为环境权限原先,测试环境服务器的用户不能直接拷贝东西,
端口22被封闭,只给pe用户开放了51899
所以切换pe,先把数据拷贝到根目录tmp目录,然后再mv到/etc/hadoop
3 . 拷贝profile环境变量
scp -P 51899 /etc/profile pe@172.23.27.39:/tmp
scp -P 51899 /etc/profile pe@172.23.27.40:/tmp
.....
scp -P 51899 /etc/profile pe@172.23.27.41:/tmp
scp -P 51899 /etc/profile pe@172.23.27.42:/tmp
4 . 设置各个机器的conf
alternatives --install /etc/hadoop/conf hadoop-conf /etc/hadoop/cdh5-test 50
alternatives --set hadoop-conf /etc/hadoop/cdh5-test
检查hadoop-conf是否最优配置为cdh5-test
alternatives --display hadoop-conf
如果是显示:Current `best' version is /etc/hadoop/cdh5-test.
如果不是,修正vim /var/lib/alternatives/hadoop-conf
八. 启动集群
1 . 启动namenode(38)
[root@JXQ-23-27-38 conf]# su - hdfs
-bash-4.1$ hadoop namenode -format
-bash-4.1$ exit
[root@JXQ-23-27-48 conf]# service hadoop-hdfs-namenode start2 . 启动辅 namenode:(39)
注:初次启动时需要,以后通过Journalnode自动同步
[root@JXQ-23-27-39~]# sudo -u hdfs hadoop namenode -bootstrapStandby
[root@JXQ-23-27-39~]# service hadoop-hdfs-namenode start
[root@JXQ-23-27-38conf]# jps
20232NameNode
24067Jps
[root@JXQ-23-27-39~]# jps
19993NameNode
23701Jps
3 . 格式化zk并启动
[root@JXQ-23-27-38 conf]# su -hdfs
-bash-4.1$ hdfs zkfc -formatZK
在任意一个NameNode上下面命令,其会创建一个znode用于自动故障转移。
2个namenode都启动zkfc:
servicehadoop-hdfs-zkfc start 或者/etc/init.d/hadoop-hdfs-zkfc start
查看zk:
[root@JXQ-23-27-45~]# /usr/lib/zookeeper/bin/zkCli.sh
[zk:localhost:2181(CONNECTED) 5] ls /
[hadoop-ha,zookeeper]
[zk:localhost:2181(CONNECTED) 4] ls /hadoop-ha/cdh5-test
[ActiveBreadCrumb,ActiveStandbyElectorLock]
4 . 查看namenode状态:
[root@JXQ-23-27-38tmp]# sudo -u hdfs hdfs haadmin -getServiceState nn2
[root@JXQ-23-27-38tmp]# sudo -u hdfs hdfs haadmin -getServiceState nn1
手动切换命令:(把nn1变成standby,nn2变成actiove)
[root@JXQ-23-27-38tmp]# sudo -u hdfs hdfs haadmin -failover nn1 nn2
Failover to NameNode at JXQ-23-27-39.com.cn/172.23.27.39:8020successful
[root@JXQ-23-27-38tmp]# sudo -u hdfs hdfs haadmin -getServiceState nn1
standby
5 . 启动datanode:(40,41,42,43,44,45,46,47)
[root@JXQ-23-27-40~]# service hadoop-hdfs-datanode start
[root@JXQ-23-27-41~]# service hadoop-hdfs-datanode start
[root@JXQ-23-27-42~]# service hadoop-hdfs-datanode start
......
6 . 查看集群状态:
[root@JXQ-23-27-38 ~]# su hdfs
bash-4.1$ hdfs dfsadmin -report
Configured Capacity: 2247239327744 (2.04 TB)
Present Capacity: 2151480572928 (1.96 TB)
DFS Remaining: 2023802022912 (1.84 TB)
DFS Used: 127678550016 (118.91 GB)
DFS Used%: 5.93%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (8):
Name: 172.23.27.46:50010 (JXQ-23-27-46.h.chinabank.com.cn)
Hostname: JXQ-23-27-46.h.chinabank.com.cn
Rack: /rack046
Decommission Status : Normal
Configured Capacity: 280904915968 (261.61 GB)
DFS Used: 16360968192 (15.24 GB)
Non DFS Used: 11400506368 (10.62 GB)
DFS Remaining: 253143441408 (235.76 GB)
DFS Used%: 5.82%
DFS Remaining%: 90.12%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Thu Jul 16 12:14:11 CST 2015
Name: 172.23.27.42:50010 (JXQ-23-27-42.h.chinabank.com.cn)
Hostname: JXQ-23-27-42.h.chinabank.com.cn
Rack: /rack042
Decommission Status : Normal
Configured Capacity: 280904915968 (261.61 GB)
DFS Used: 4706304 (4.49 MB)
Non DFS Used: 0 (0 B)
DFS Remaining: 280900209664 (261.61 GB)
DFS Used%: 0.00%
DFS Remaining%: 100.00%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Thu Jul 16 12:14:13 CST 2015
Name: 172.23.27.44:50010 (JXQ-23-27-44.h.chinabank.com.cn)
Hostname: JXQ-23-27-44.h.chinabank.com.cn
Rack: /rack044
Decommission Status : Normal
Configured Capacity: 280904915968 (261.61 GB)
DFS Used: 18921238528 (17.62 GB)
Non DFS Used: 13897133056 (12.94 GB)
DFS Remaining: 248086544384 (231.05 GB)
DFS Used%: 6.74%
DFS Remaining%: 88.32%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Thu Jul 16 12:14:13 CST 2015
Name: 172.23.27.40:50010 (JXQ-23-27-40.h.chinabank.com.cn)
Hostname: JXQ-23-27-40.h.chinabank.com.cn
Rack: /rack040
Decommission Status : Normal
Configured Capacity: 280904915968 (261.61 GB)
DFS Used: 17528258560 (16.32 GB)
Non DFS Used: 13525408768 (12.60 GB)
DFS Remaining: 249851248640 (232.69 GB)
DFS Used%: 6.24%
DFS Remaining%: 88.95%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Thu Jul 16 12:14:14 CST 2015
Name: 172.23.27.47:50010 (JXQ-23-27-47.h.chinabank.com.cn)
Hostname: JXQ-23-27-47.h.chinabank.com.cn
Rack: /rack047
Decommission Status : Normal
Configured Capacity: 280904915968 (261.61 GB)
DFS Used: 18490130432 (17.22 GB)
Non DFS Used: 13529201664 (12.60 GB)
DFS Remaining: 248885583872 (231.79 GB)
DFS Used%: 6.58%
DFS Remaining%: 88.60%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Thu Jul 16 12:14:12 CST 2015
Name: 172.23.27.43:50010 (JXQ-23-27-43.h.chinabank.com.cn)
Hostname: JXQ-23-27-43.h.chinabank.com.cn
Rack: /rack043
Decommission Status : Normal
Configured Capacity: 280904915968 (261.61 GB)
DFS Used: 19790565376 (18.43 GB)
Non DFS Used: 15787650048 (14.70 GB)
DFS Remaining: 245326700544 (228.48 GB)
DFS Used%: 7.05%
DFS Remaining%: 87.33%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Thu Jul 16 12:14:12 CST 2015
Name: 172.23.27.41:50010 (JXQ-23-27-41.h.chinabank.com.cn)
Hostname: JXQ-23-27-41.h.chinabank.com.cn
Rack: /rack041
Decommission Status : Normal
Configured Capacity: 280904915968 (261.61 GB)
DFS Used: 20106006528 (18.73 GB)
Non DFS Used: 16102796288 (15.00 GB)
DFS Remaining: 244696113152 (227.89 GB)
DFS Used%: 7.16%
DFS Remaining%: 87.11%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Thu Jul 16 12:14:13 CST 2015
Name: 172.23.27.45:50010 (JXQ-23-27-45.h.chinabank.com.cn)
Hostname: JXQ-23-27-45.h.chinabank.com.cn
Rack: /rack045
Decommission Status : Normal
Configured Capacity: 280904915968 (261.61 GB)
DFS Used: 16476676096 (15.35 GB)
Non DFS Used: 11516058624 (10.73 GB)
DFS Remaining: 252912181248 (235.54 GB)
DFS Used%: 5.87%
DFS Remaining%: 90.03%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Thu Jul 16 12:14:11 CST 20157 . 启动yarn(resourcemanager、nodemanager):
(38/40/41/42/43/44/45/46/47)
[root@JXQ-23-27-38 ~]# servicehadoop-yarn-resourcemanager start
[root@JXQ-23-27-50 ~]# servicehadoop-yarn-nodemanager start
[root@JXQ-23-27-51 ~]# servicehadoop-yarn-nodemanager start
......
查看yarn状态:
yarn node -list -all
















 101
101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











