









有很多想学习大数据的朋友,但苦于找不到系统的学习资料,搭建一个hadoop集群都要耽搁很多时间。下面我给大家一个搭建大数据的图文教程。教程中需要用到的软件和资料我已经准备好了,下面是分享链接,直接下载即可。
链接:http://pan.baidu.com/s/1c1PWFc8 密码:hytk
注意:下面的配置文件中出现的“qinke”是我的虚拟机主机名,必须改成你自己虚拟机的名字或者你的虚拟机的ip地址,可以使用hostname命令查看主机名
将上面链接的软件现在下来,先安装vmware10,这个软件的安装很简单,和一般的.exe没什么区别,这里就不浪费篇幅了,不会的同学自己找一下度娘
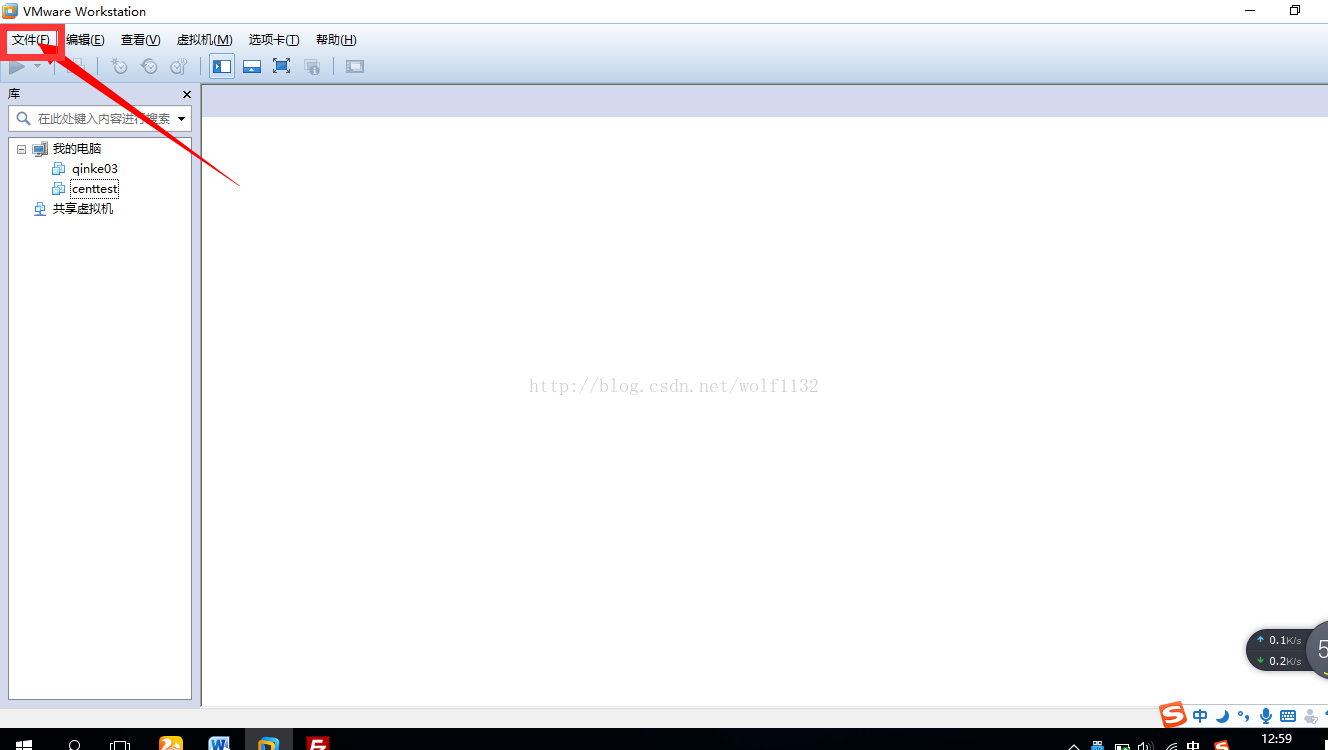
1、打开vmware,然后选择【文件】下拉菜单中选择【打开】
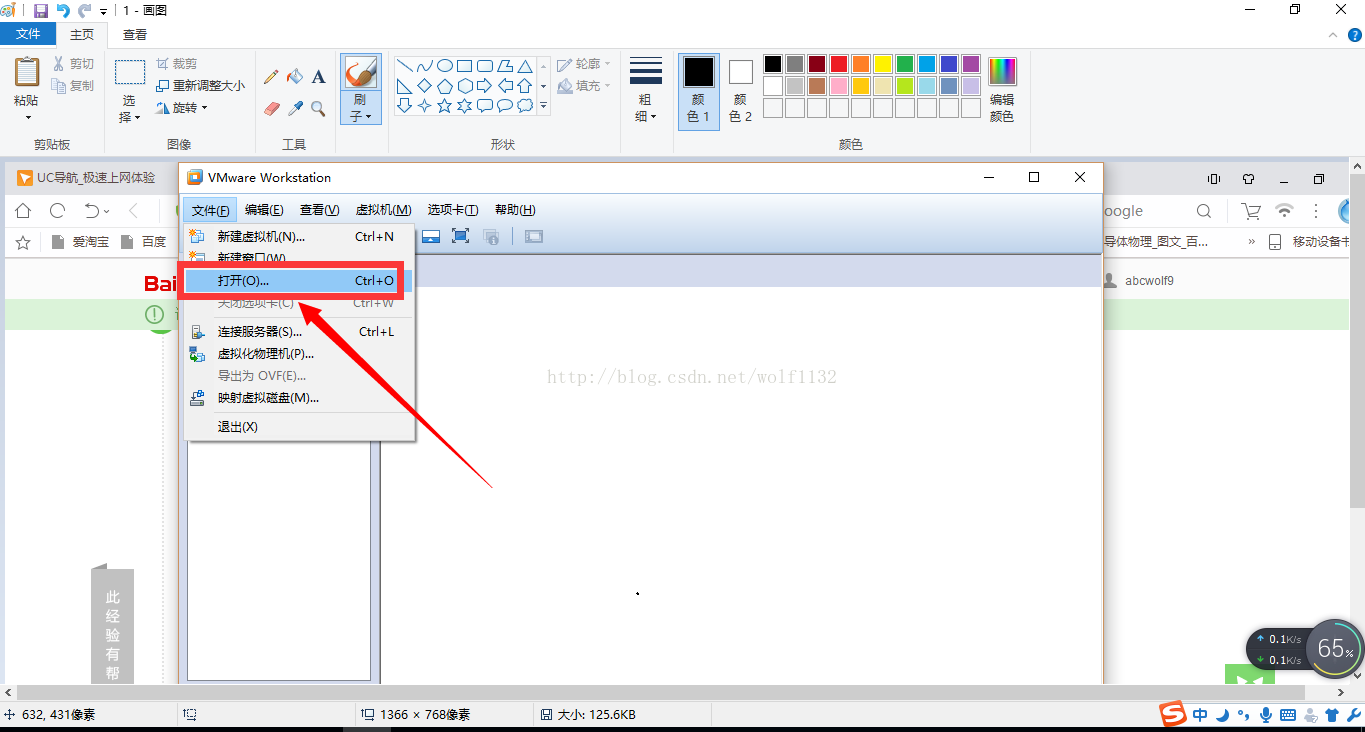
2、在弹出的路径选框中定位到下载的“hadoop-linux”文件夹下,选中文件夹下的虚拟机,点击打开按钮
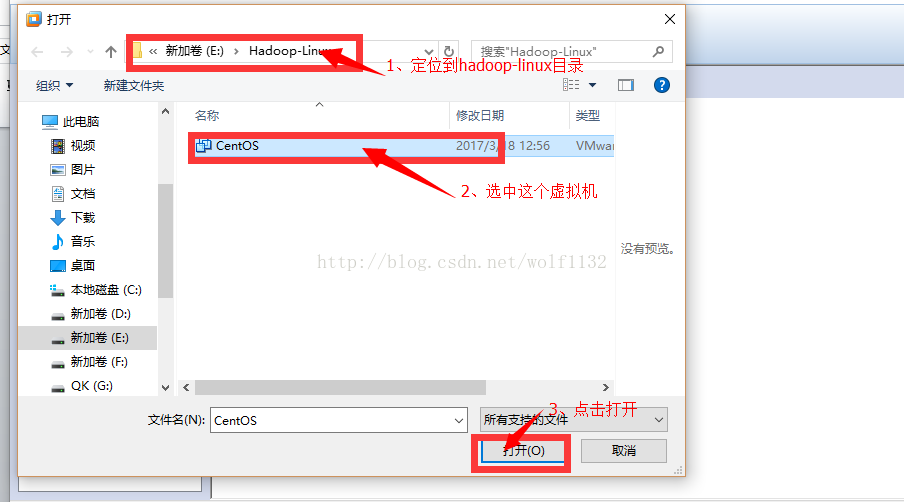
3、点击开启此虚拟机
4、第一次开启会有一个警告,点击【我已移动该虚拟机】
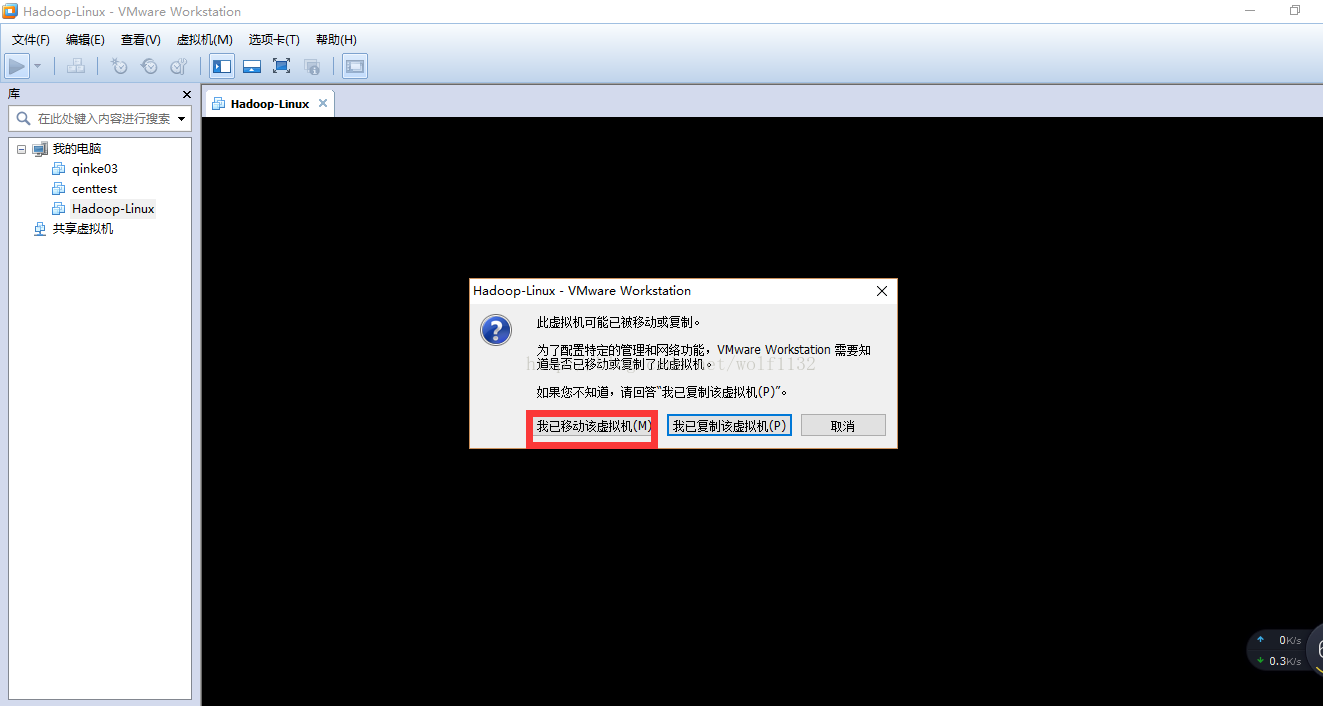
5、启动起来之后需要输入用户名和密码,这里为了方便起见,我直接用root用户登录,但是在实际生产环境中一般需要创建一个专门管理大数据框架的用户和用户组,这里需要注意一下,密码是123456
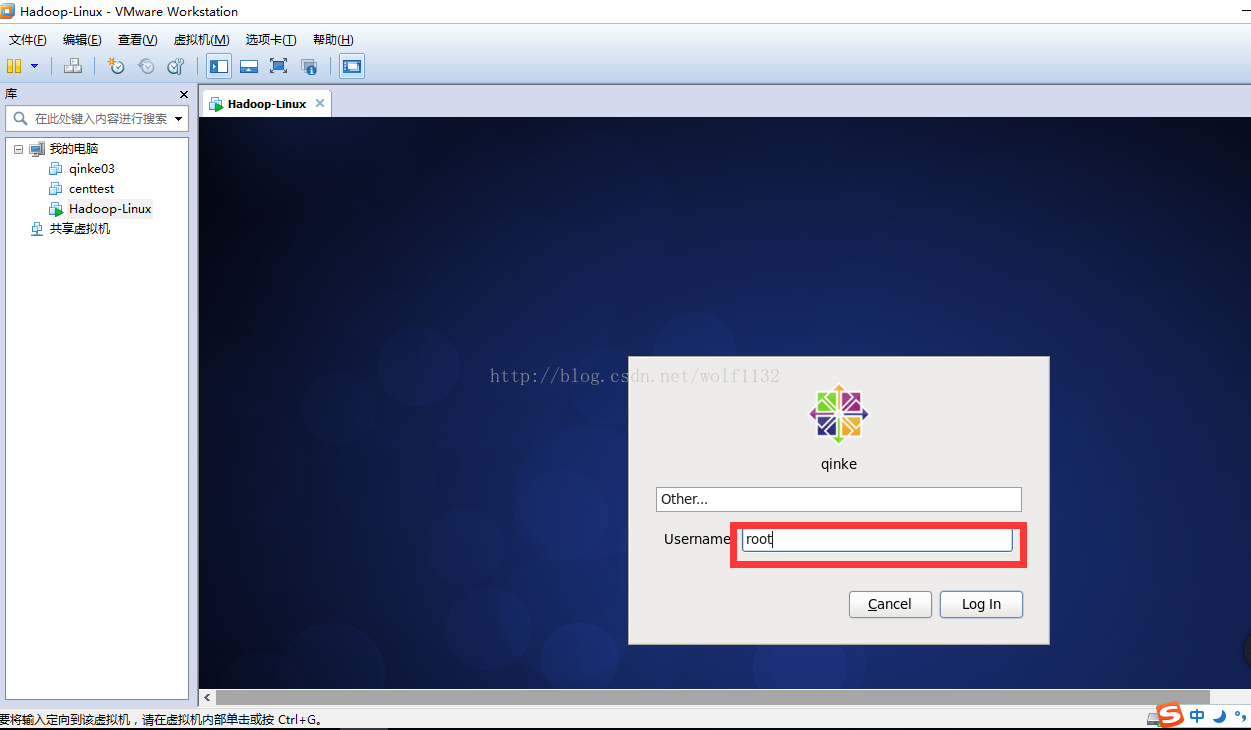
6、登陆进去以后,右键,选择【open interminal】,打开命令行窗口
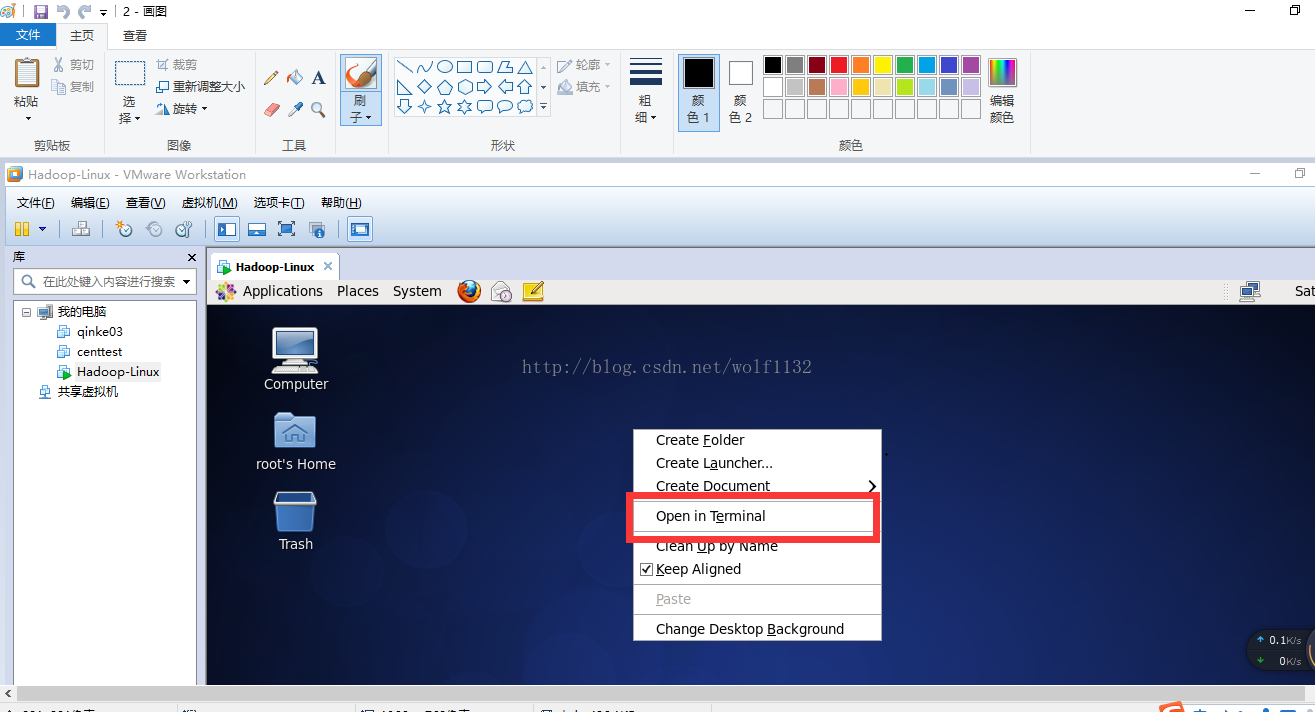
7、定位到/usr/software目录下,可以看到已经准备好的hadoop安装包,cdh版本的,方便与其他组件集成使用
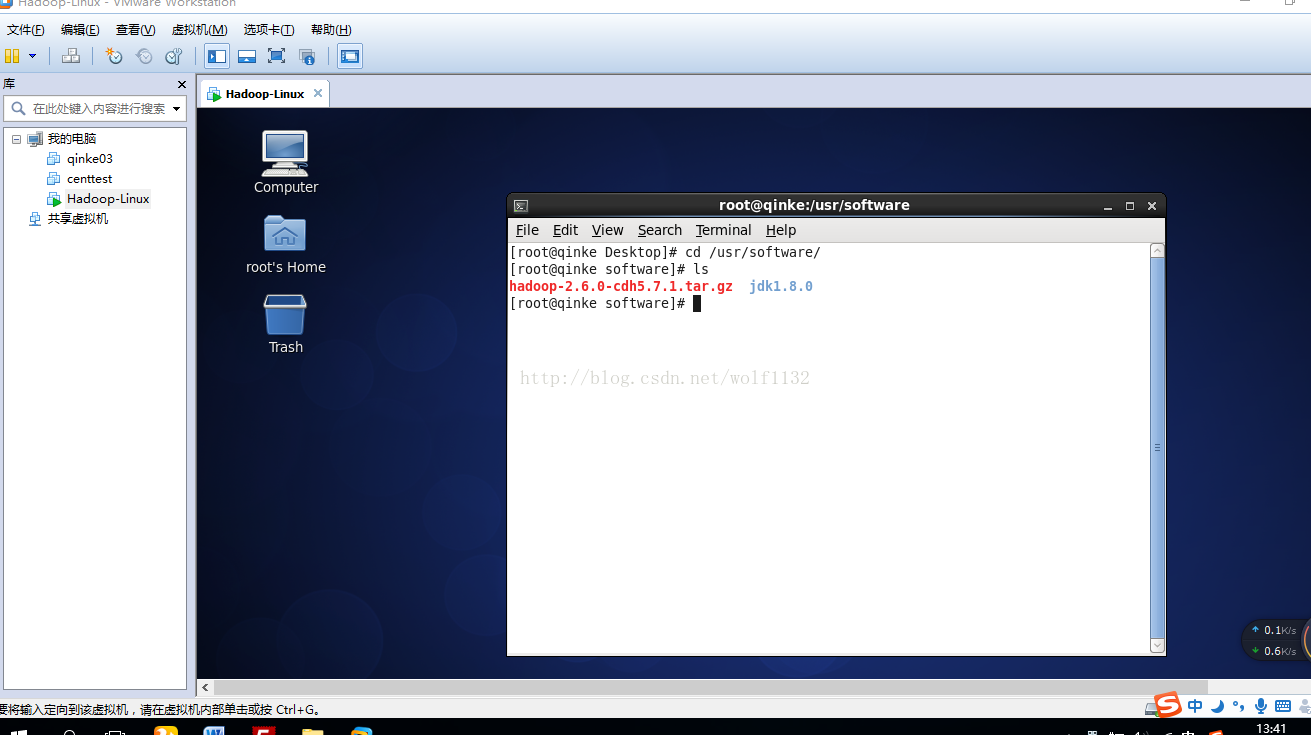
8、解压安装包到当前目录
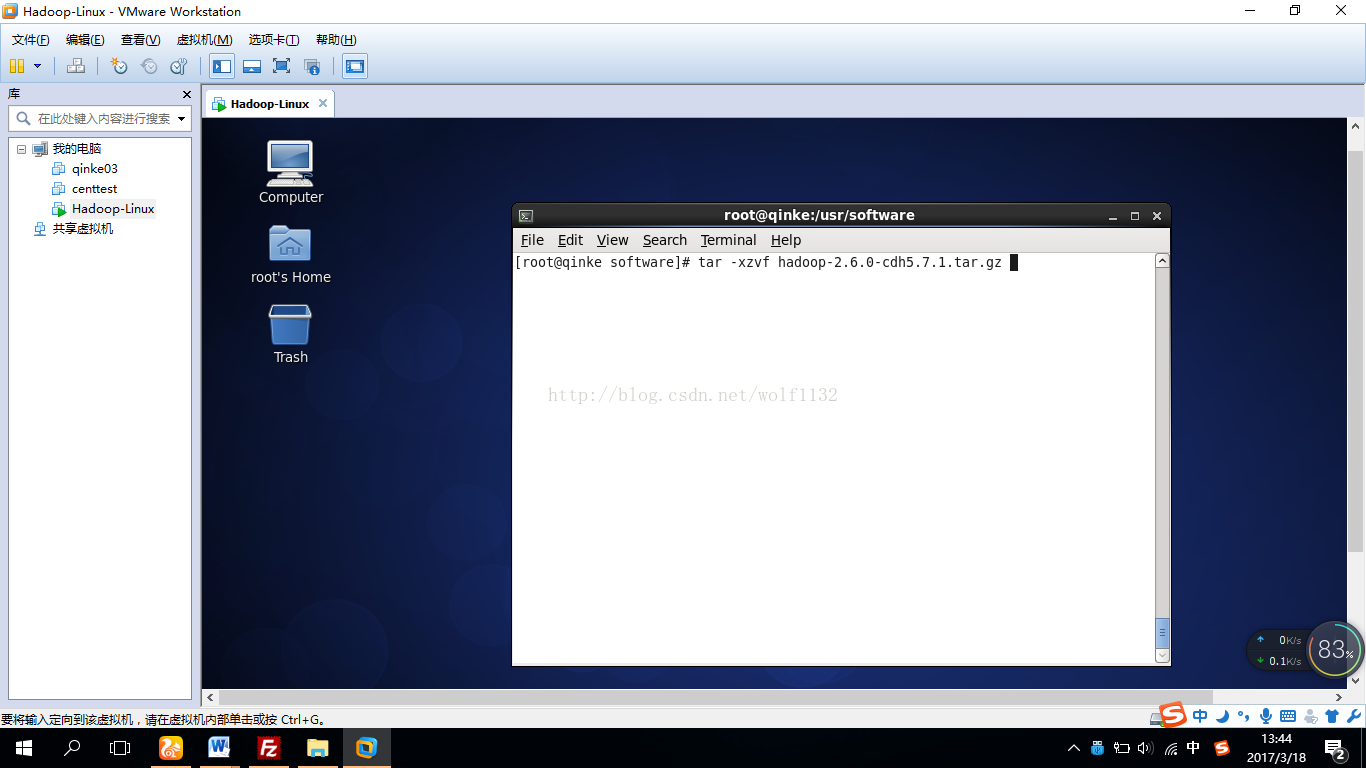
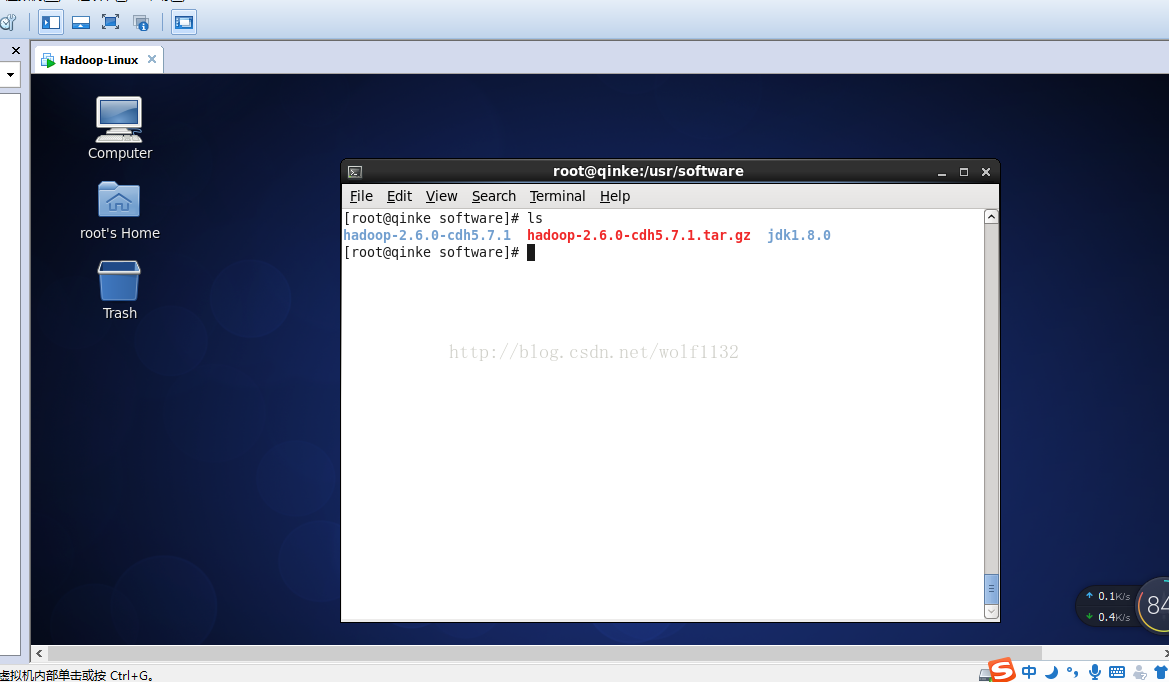
ls查看一下,已经解压好了,而且jdk我也已经为大家安装好了
9、接下来可以配置hadoop的配置文件了,在这里需要说一下,修改配置文件最好用notipad修改比较方便,也可以用vi,或者vim命令直接修改,但这样很慢,而且容易出错,notipad怎样远程修改linux主机上的文件,下一次再分享,可以关注【大数据之佳】微信公众平台,本教程最后面有二维码,平台上有更多其他大数据从入门到精通的图文教程。
首先定位到配置文件所在目录
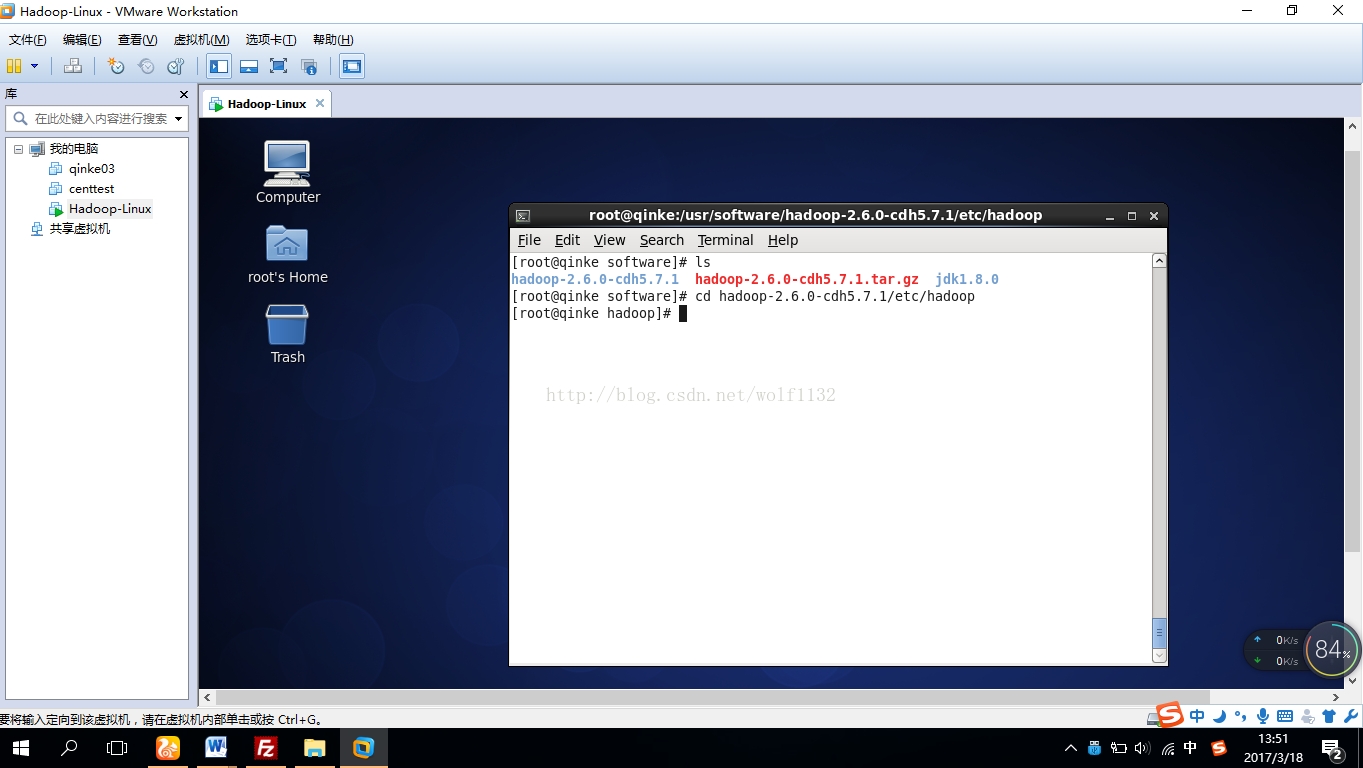
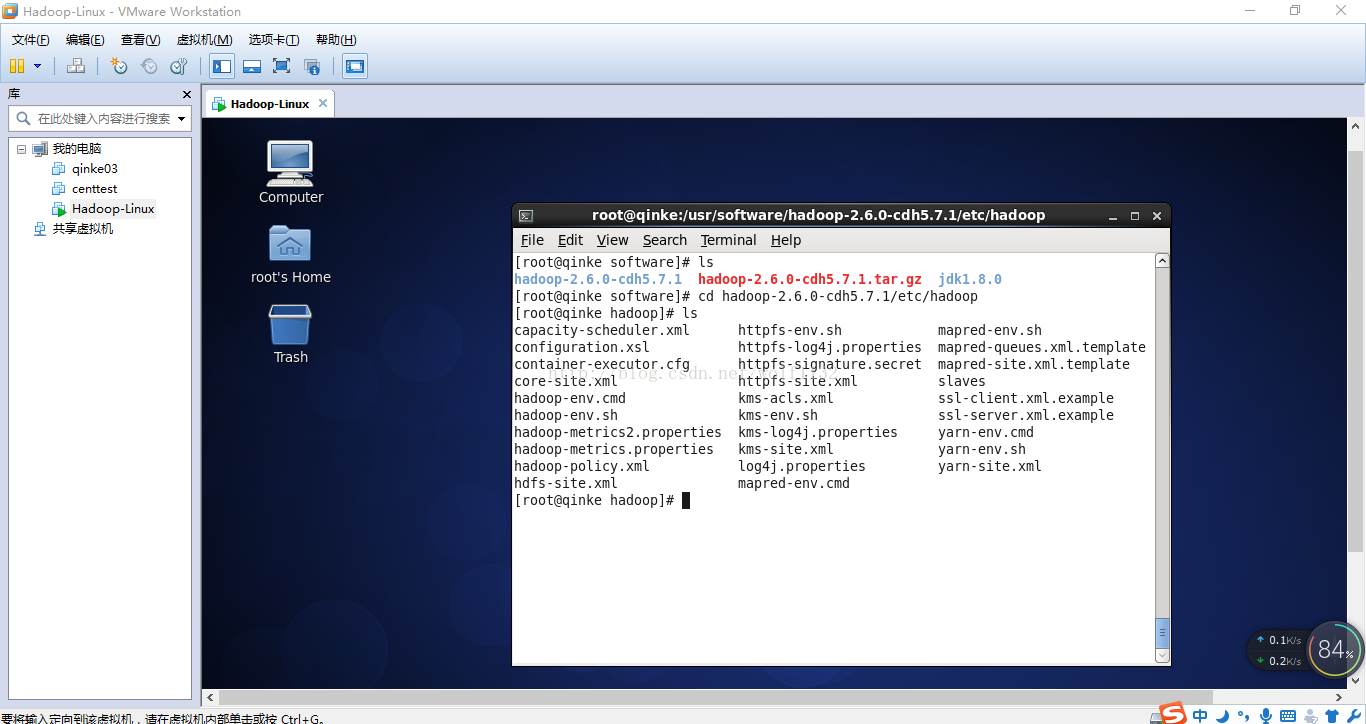
10、修改配置文件。为方便起见,我们用notipad对配置文件远程修改,【大数据之佳】公众平台有notipad远程连接服务器的教程,新手也可以百度一下,
(1、)首先我们用notipad打开core-site.xml配置文件,添加以下配置信息:
<property>
<name>fs.defaultFS</name>
<value>hdfs://qinke:8020/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/software/hadoop-2.6.0-cdh5.7.1/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>qinke</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
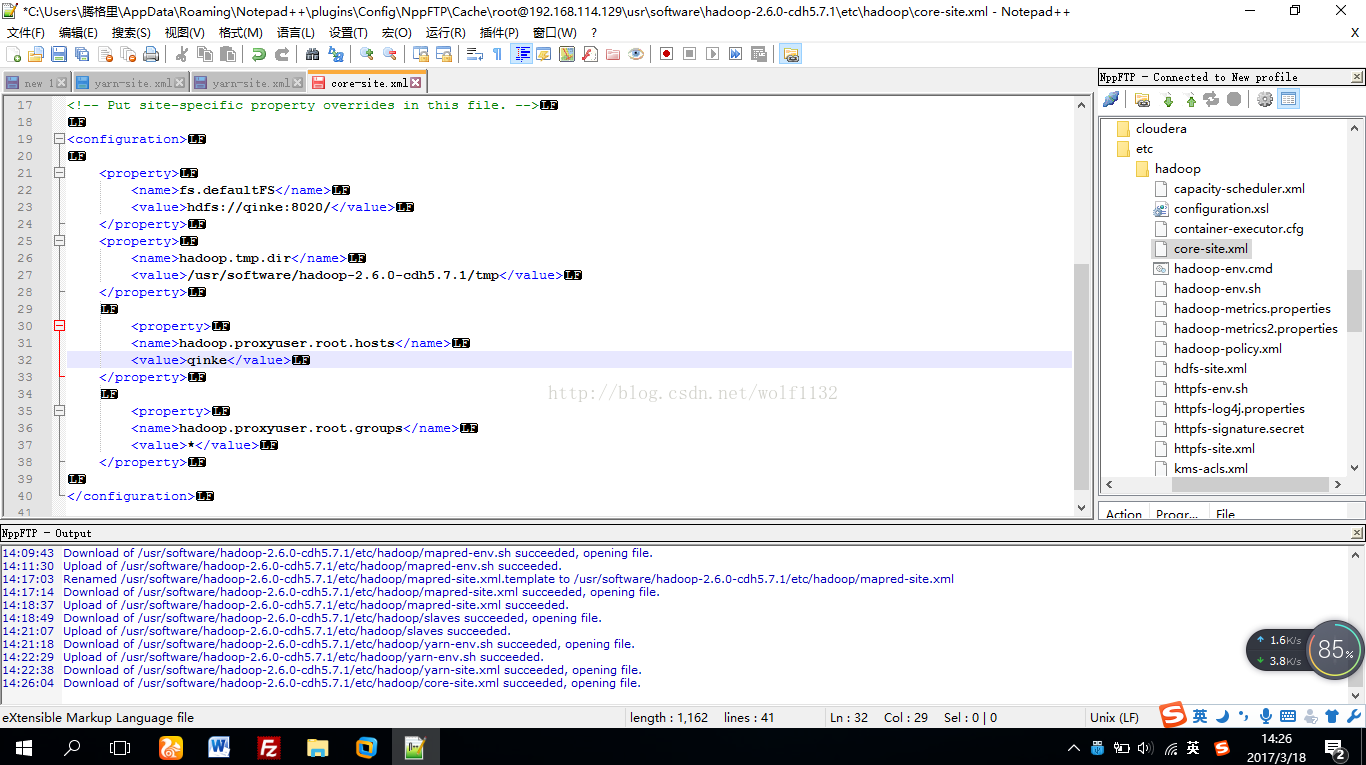
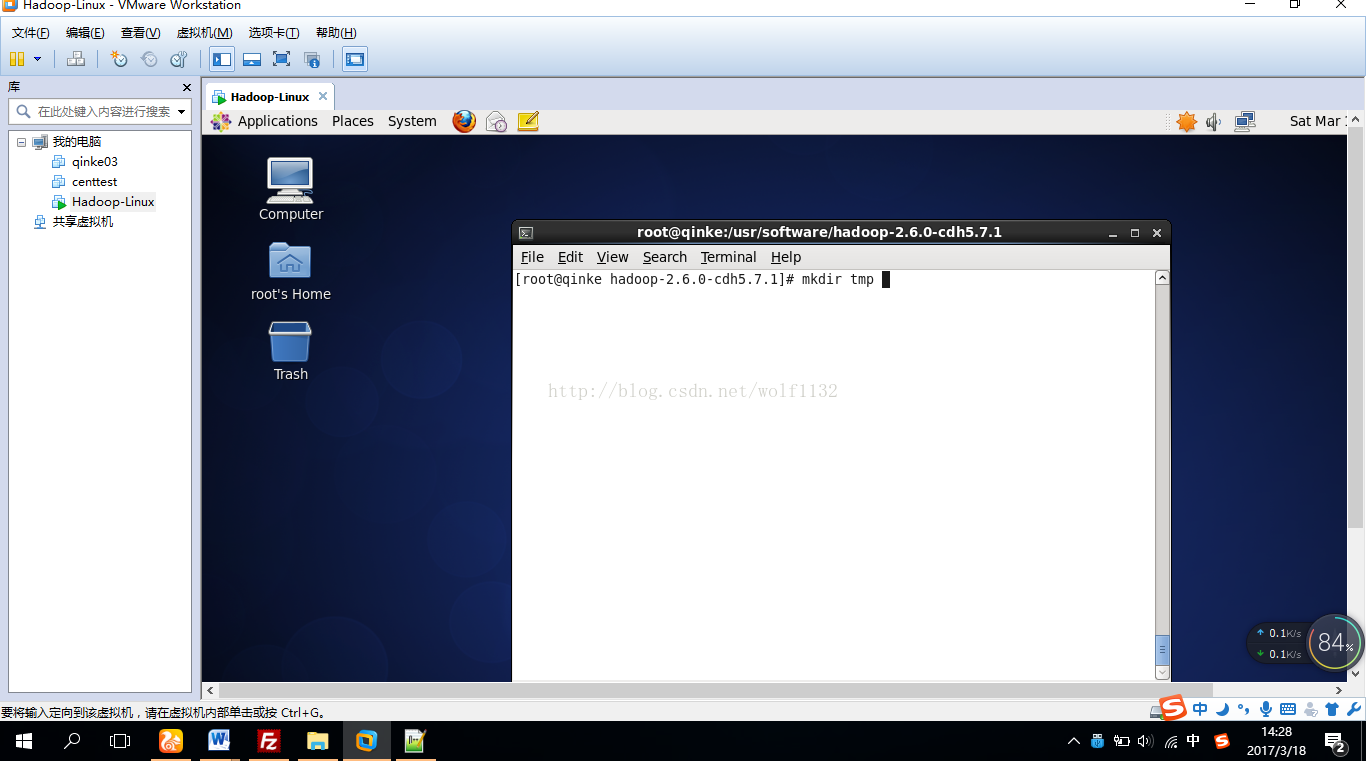
这个目录是文件系统元数据和文件数据的存放地址,我们需要创建这些目录,直接到hadoop的安装目录下,创建tmp目录即可
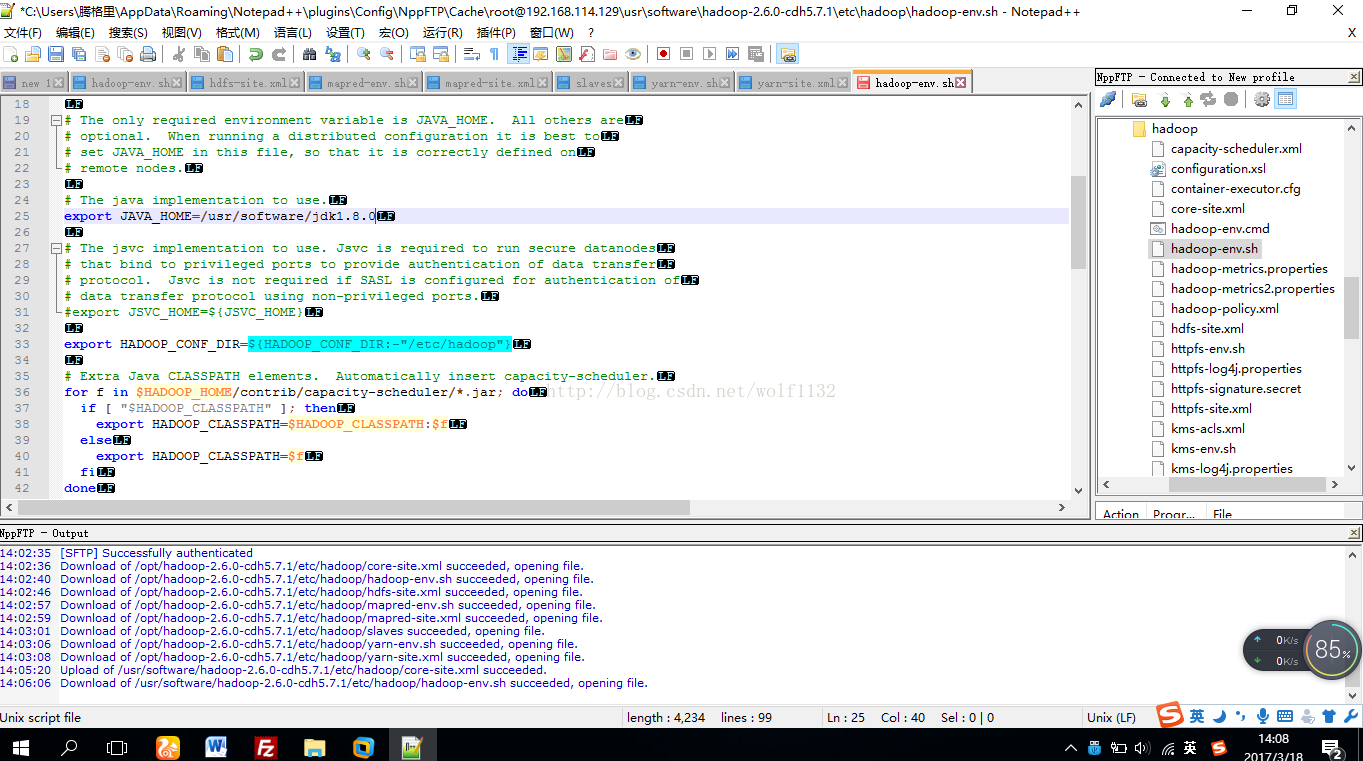
(2)修改hadoop-env.sh
把java的环境变量添加到配置文件中
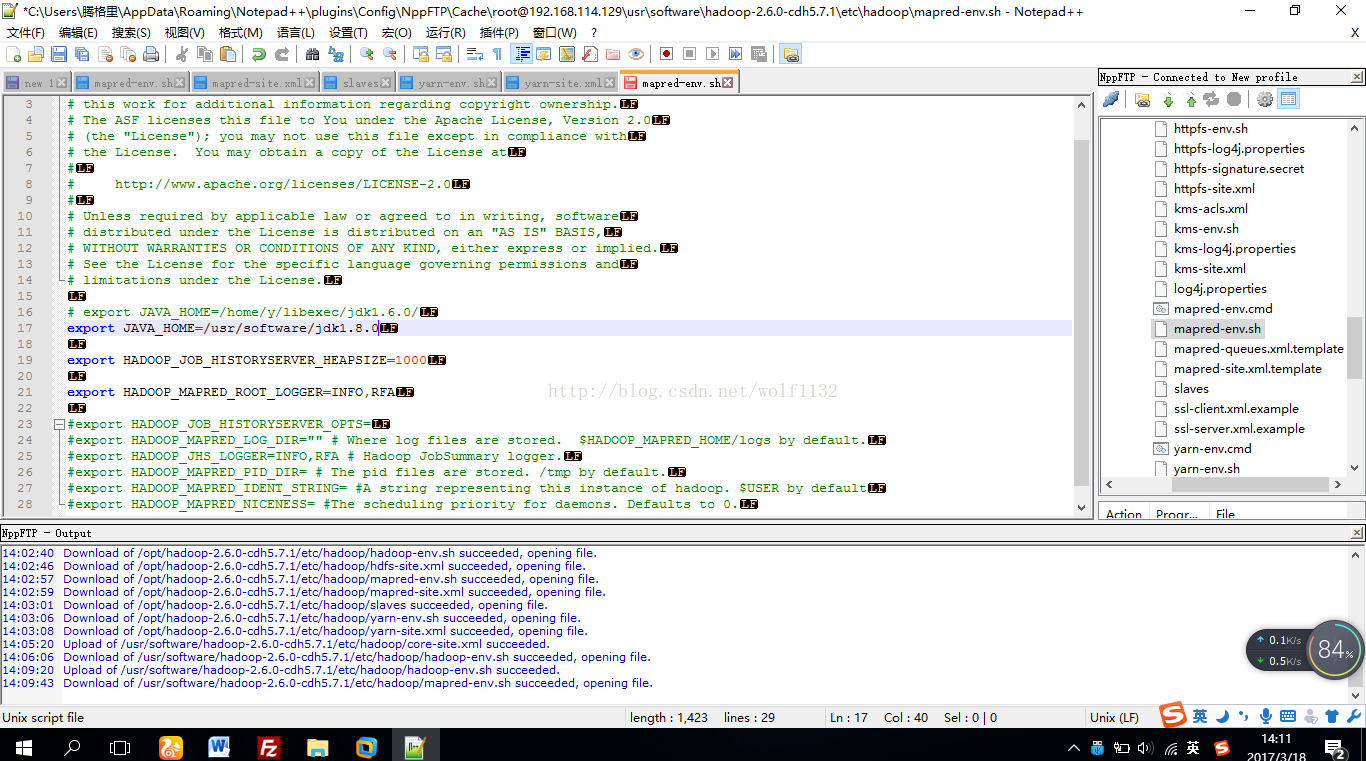
(3)修改mapred-env.sh文件,将java环境变量添加到文件中即可
(4)修改mapred-site.xml文件,配置中没有这个文件,我们可以自己创建一个新的文件,文件名为mapred-site.xml,或者直接将原来的mapred-site.xml.template文件改名为mapred-site.xml,
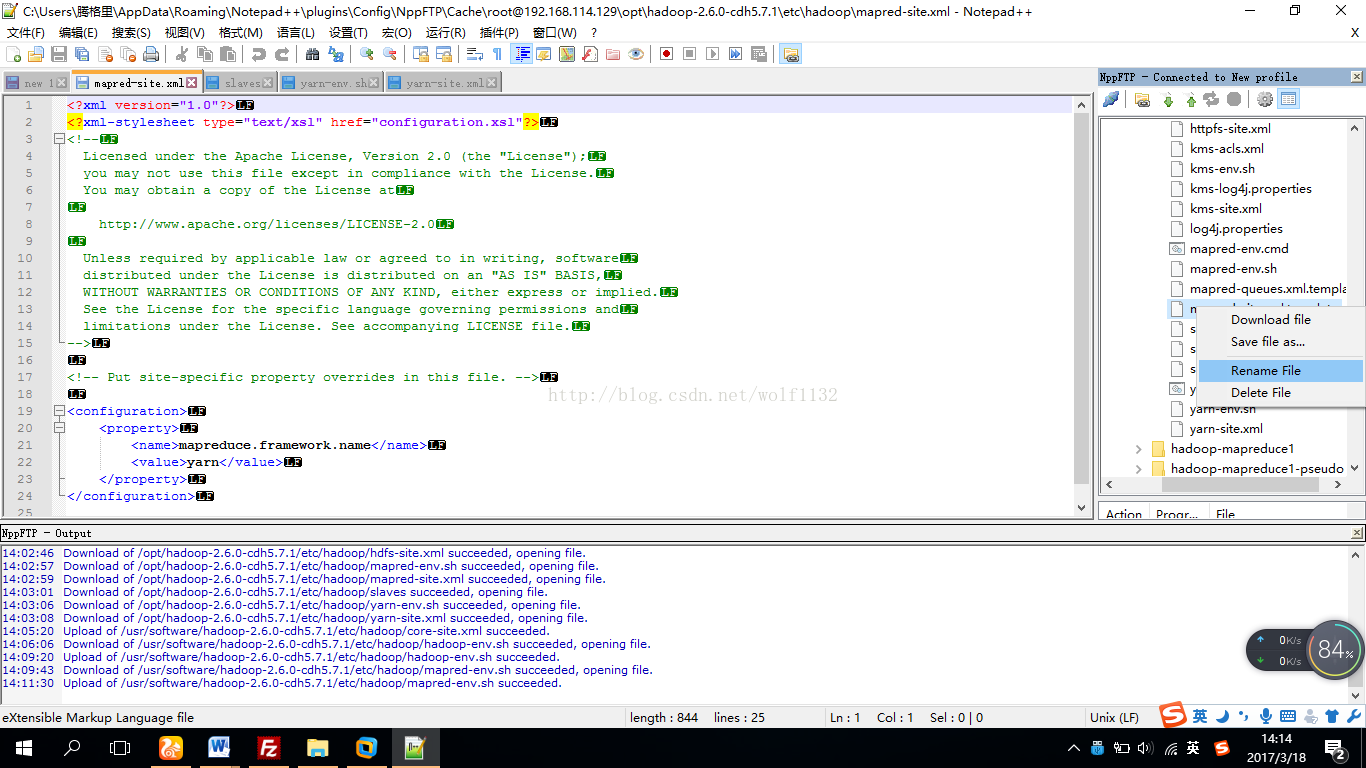
在notipad中右键点击该文件,选择重命名,如果是直接使用vi或vim命令修改的同学可以在配置文件目录下使用命令:mv mapred-site.xml.template mapred-site.xml修改
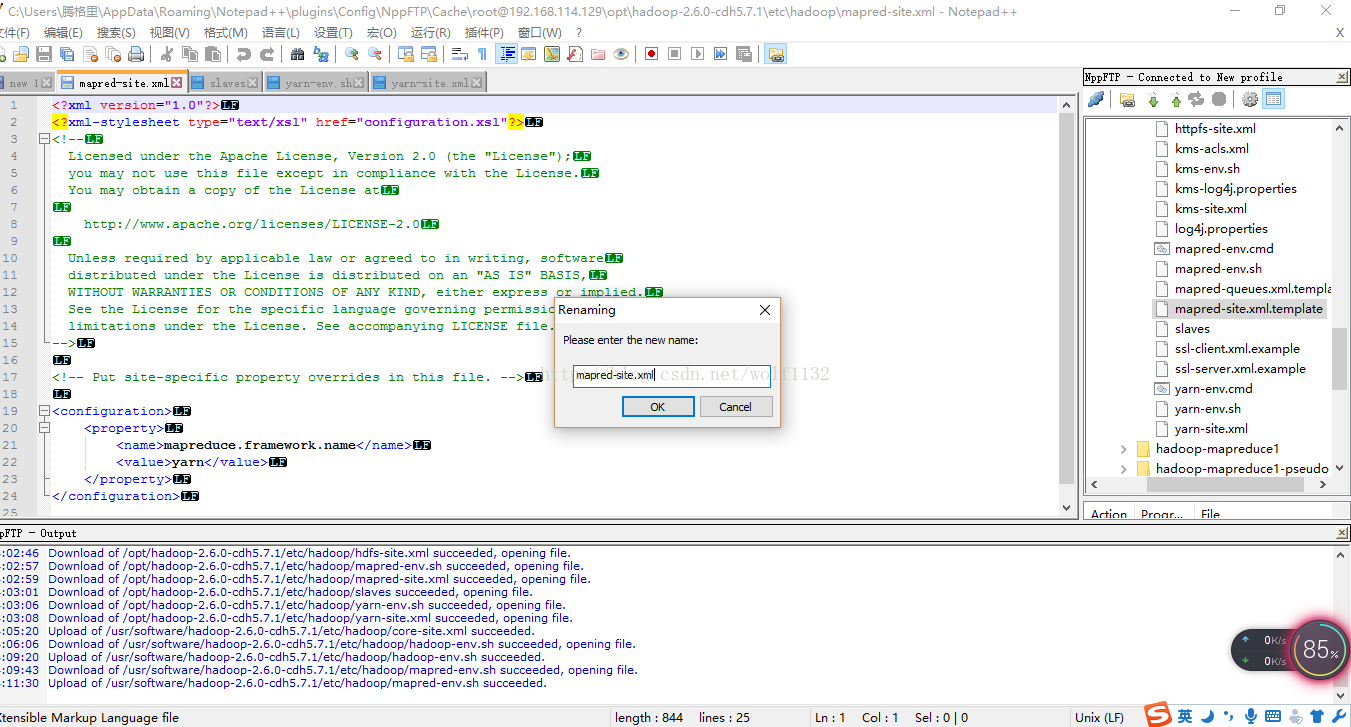
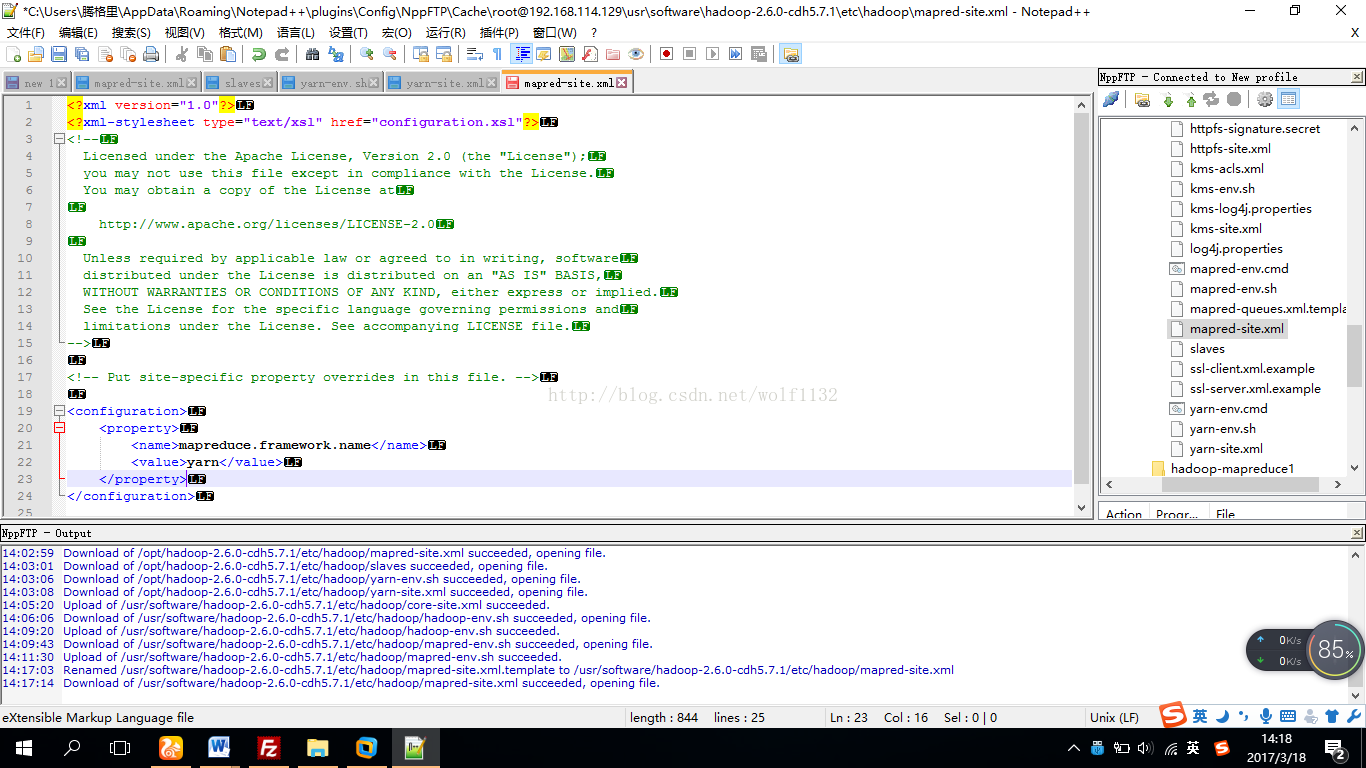
然后添加如下配置信息,说明我们使用yarn进行资源管理
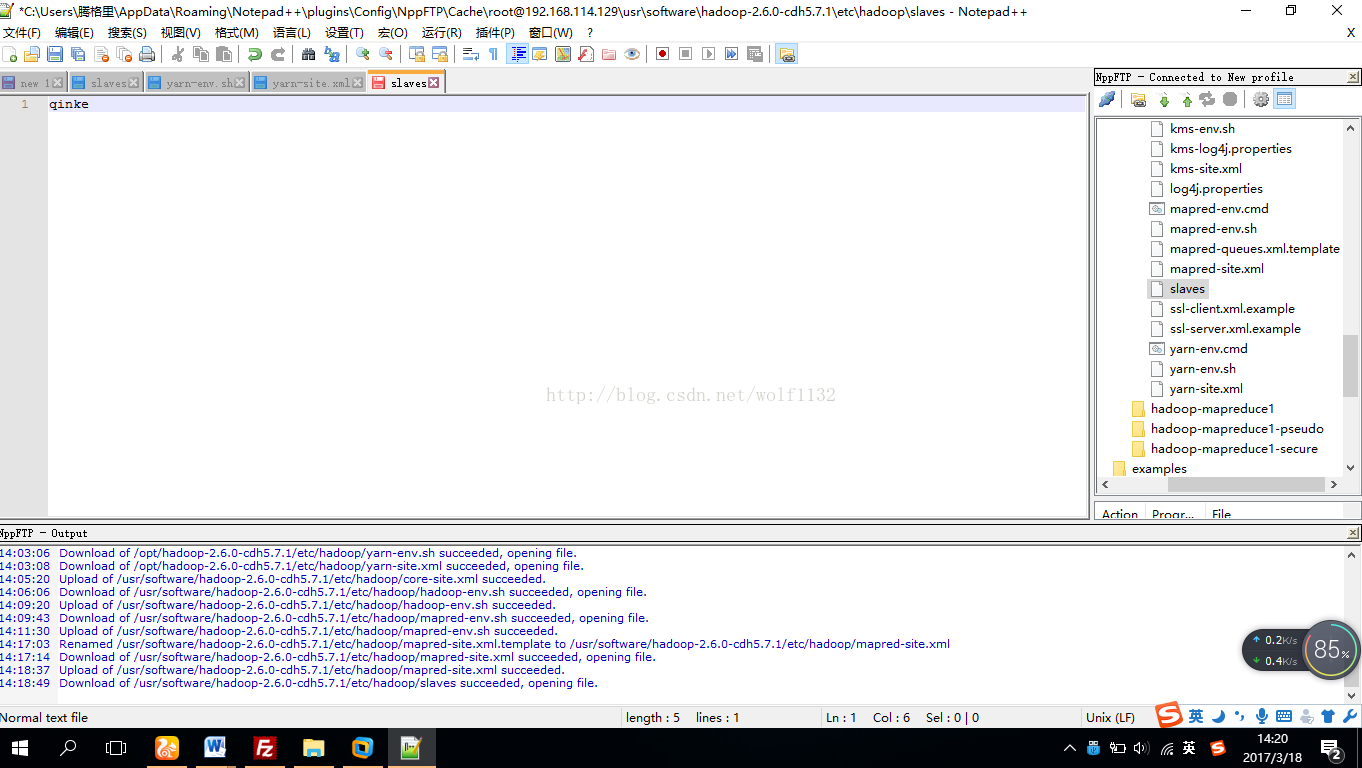
(5)修改slaves配置文件,由于我们只有一台虚拟机,只需要把本机的ip地址或者主机名添加到slaves文件中即可,这里我们只需要把虚拟机的ip地址写上即可,或者主机名
我的主机名是qinke,
(6)修改yarn-env.sh配置文件,添加java的路径信息即可
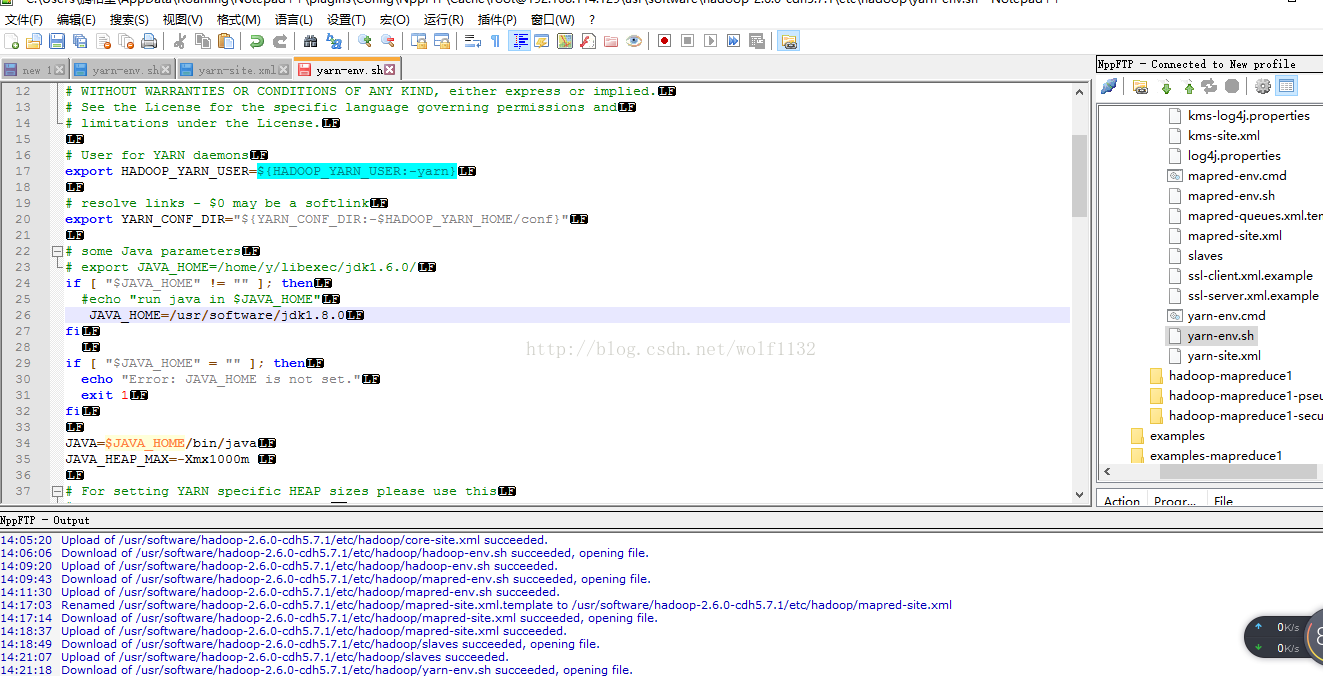
(7)配置yarn-site.xml文件,添加以下配置信息
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>qinke</value>
</property>
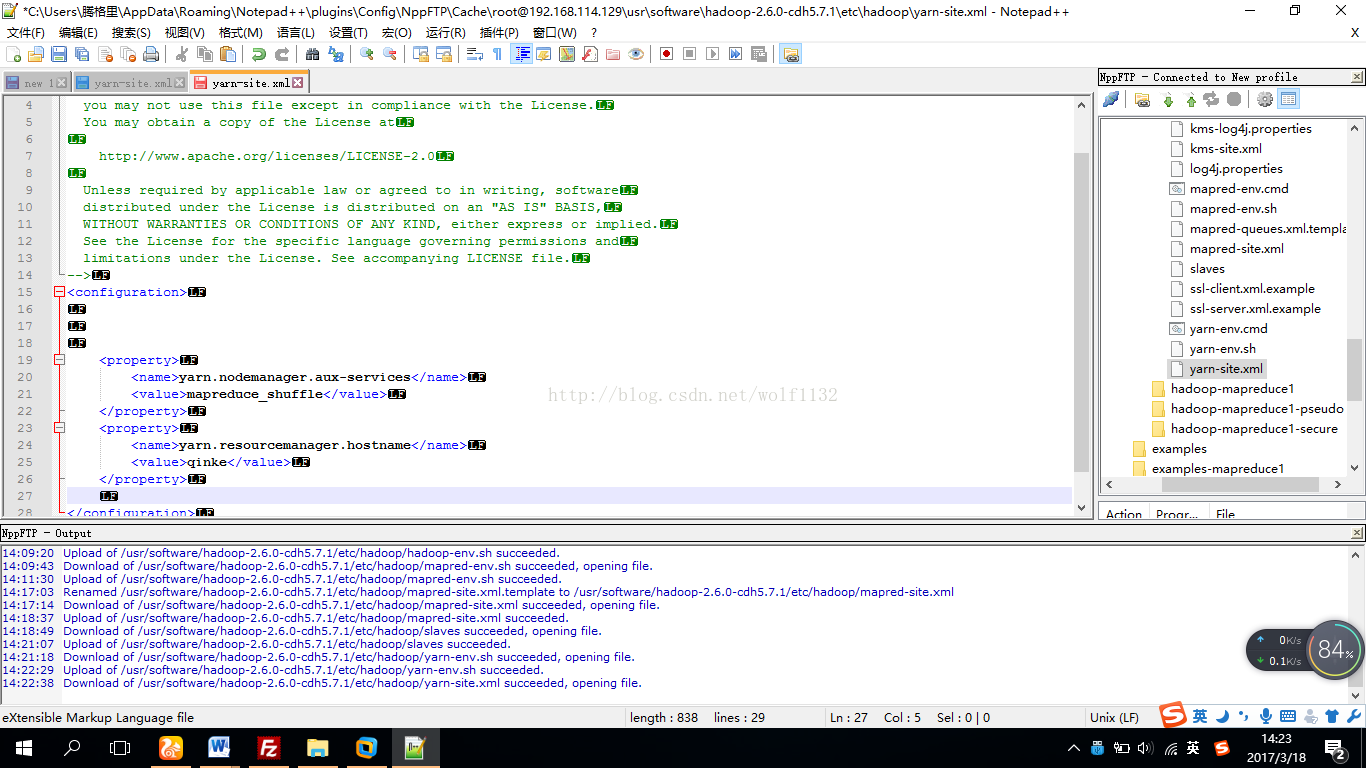
到这里我们的配置信息就配置好了,接下来初始化文件系统
11、初始化文件系统:在hadoop的安装目录下使用命令bin/hdfsnamenode –format
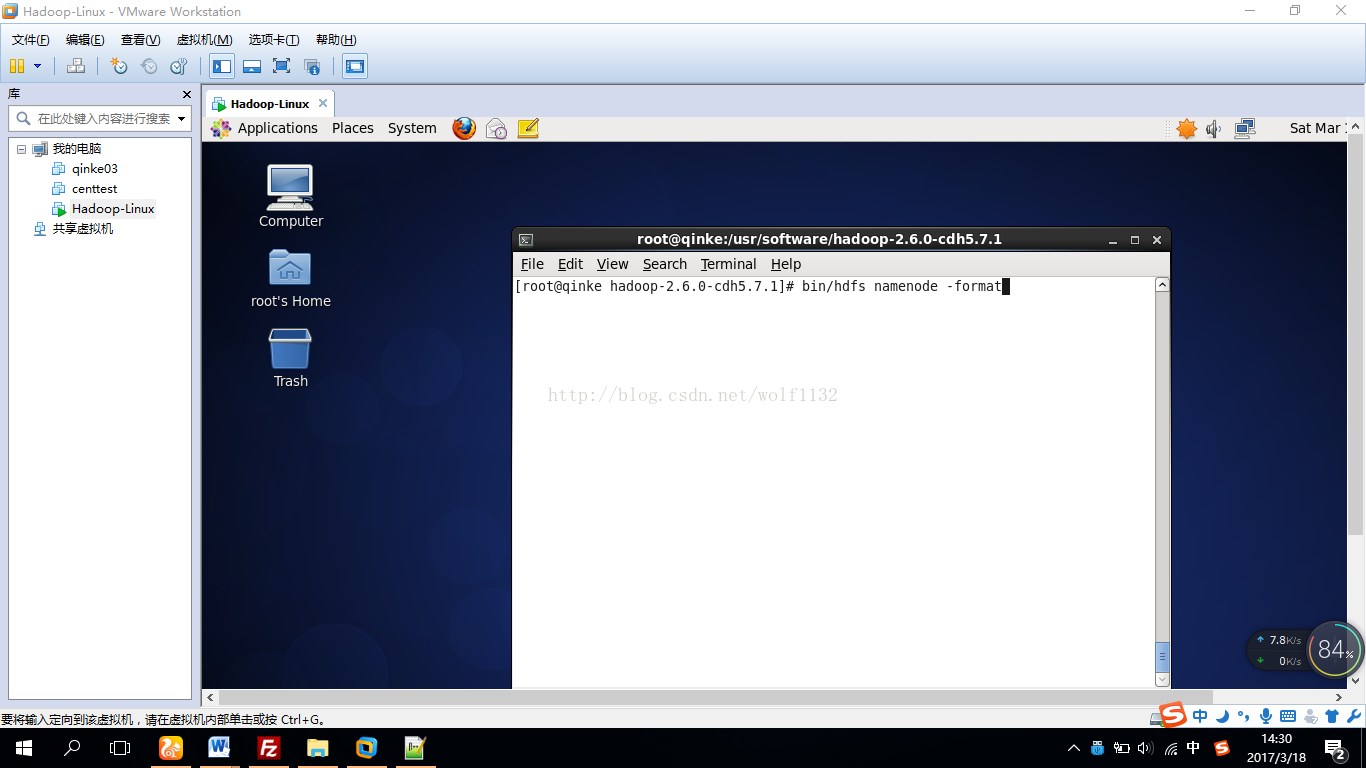
初始化过程中会有一些提示信息,需要你出入大写的Y,注意一定是大写的Y,以前的版本用同学输入小写的y死活初始化不了,他没注意这个细节,不知道现在的版本有没有解决的这个问题,大家还是输入大写的Y保险一点
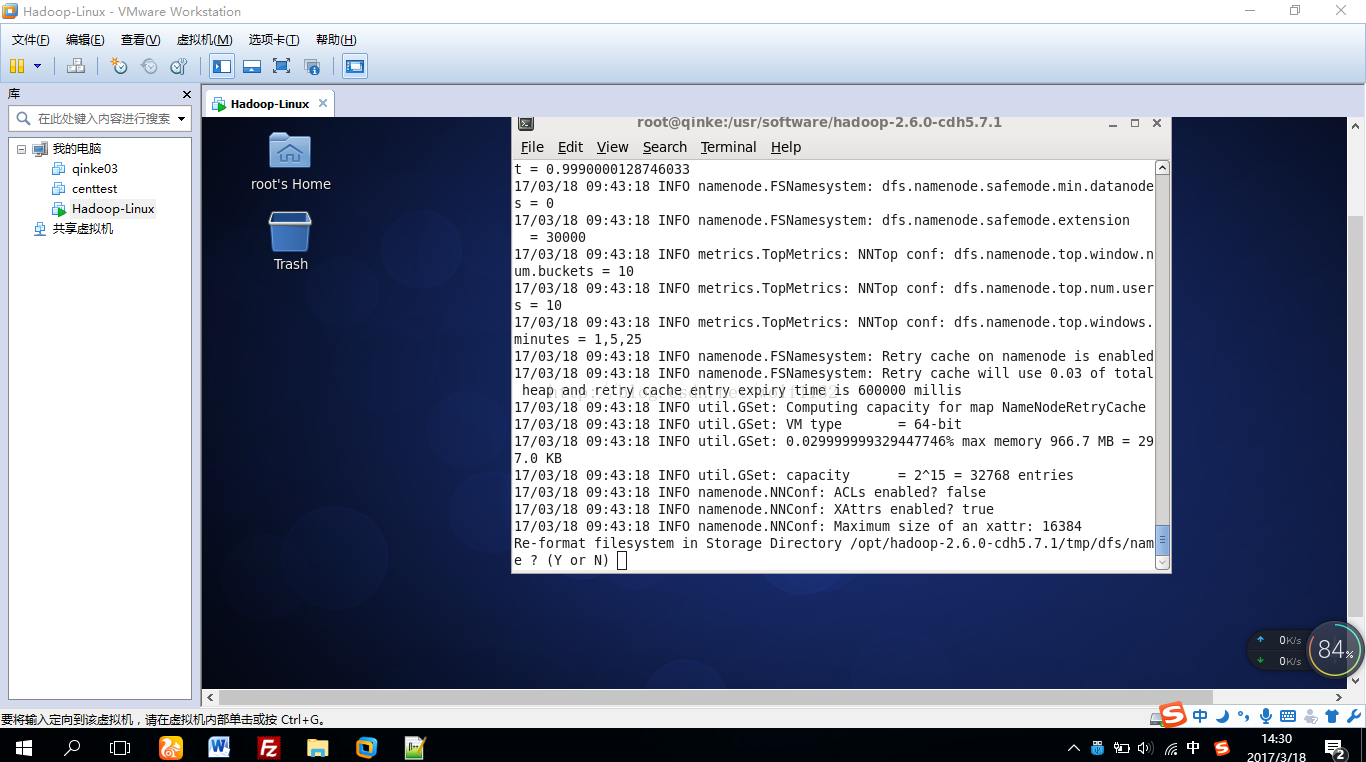
回车以后就可以看到初始化成功还是失败的提示信息了
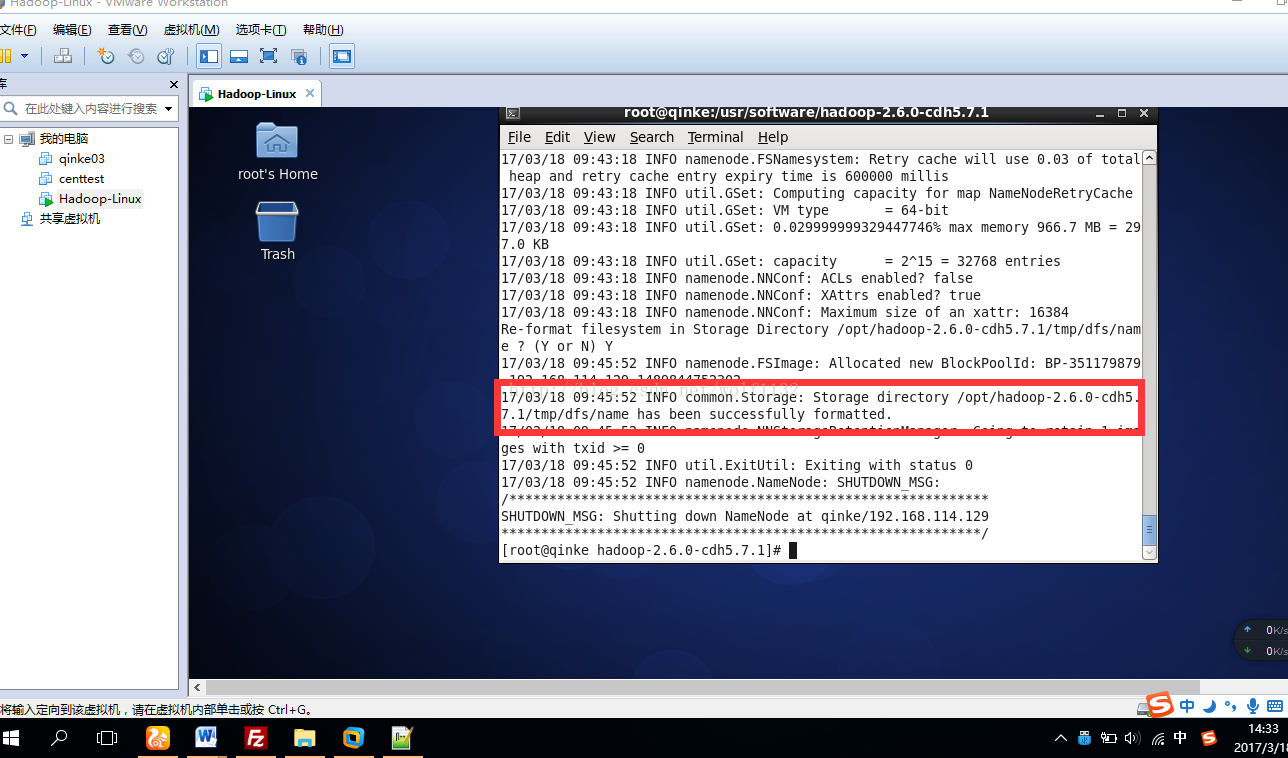
到这里我们的hadoop为分布式集群就搭建好了
下面我们来启动namenode,datanode看看,
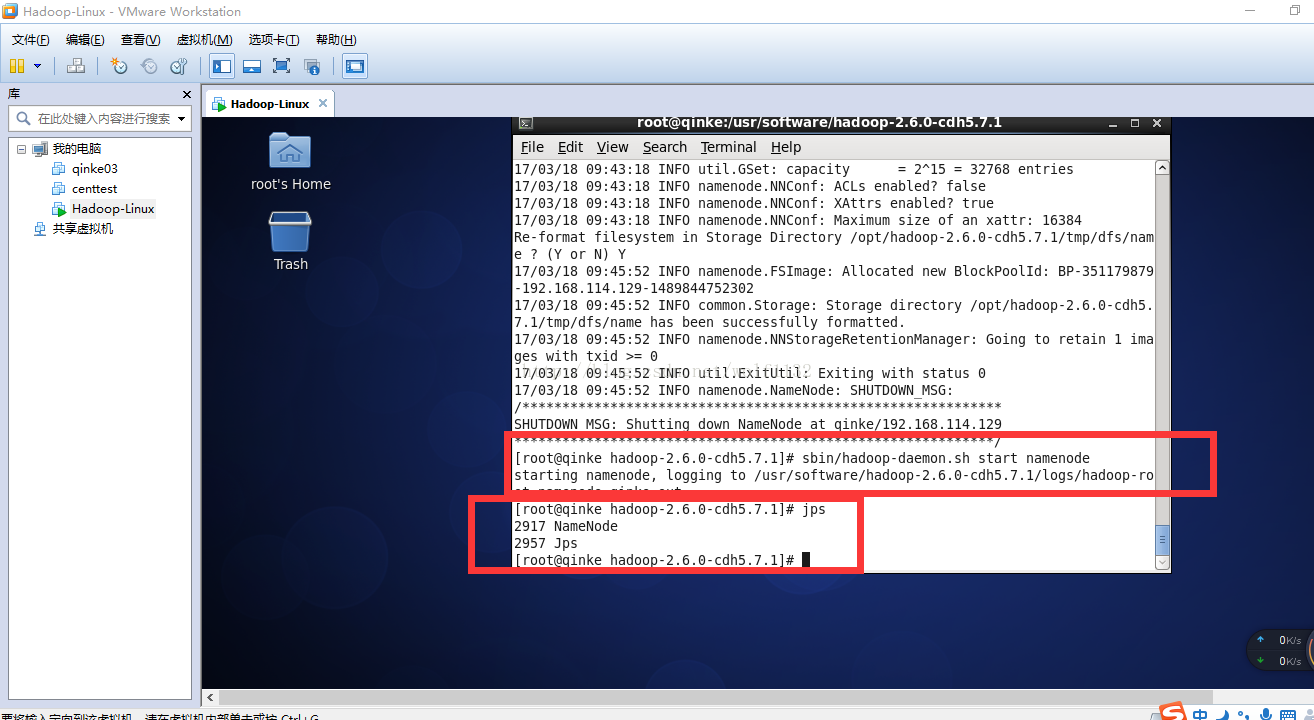
Namenode成功启动了,再来启动datanode,
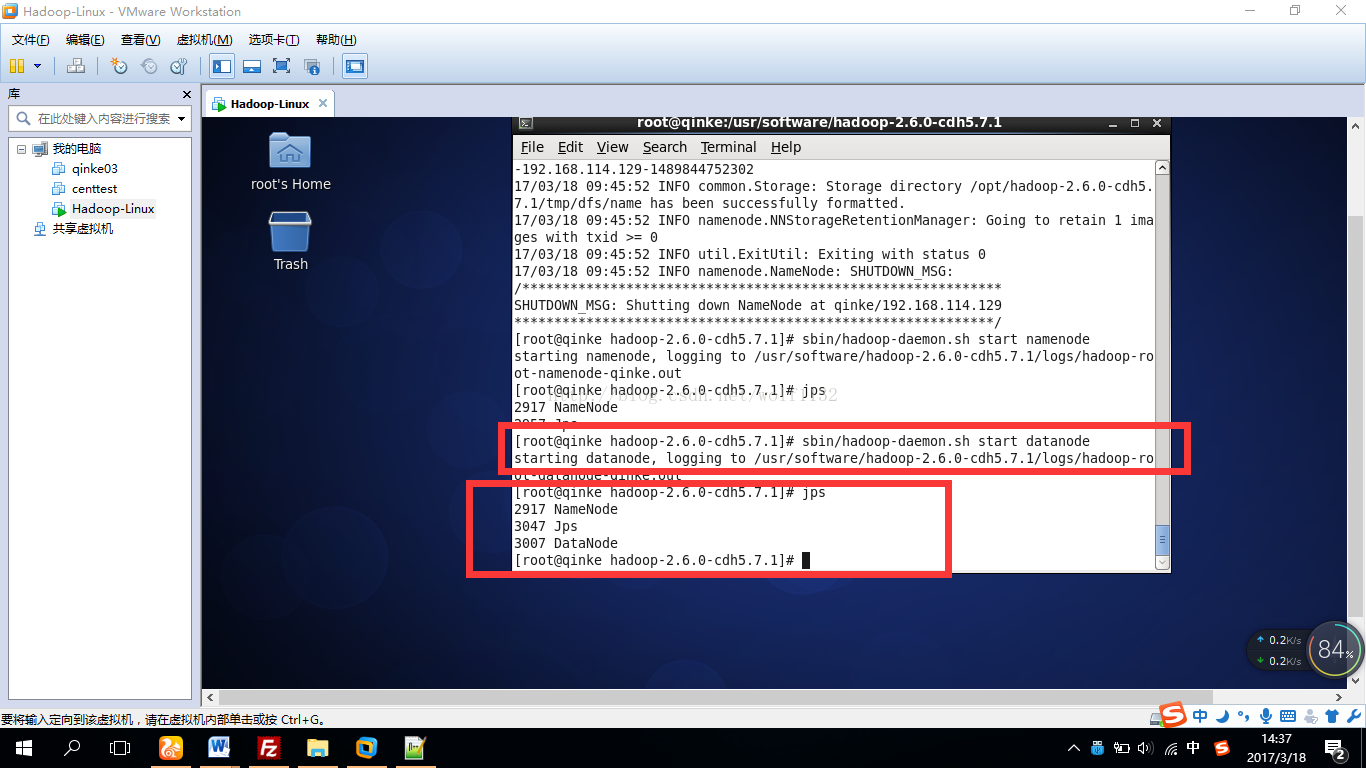
启动yarn和其他组件
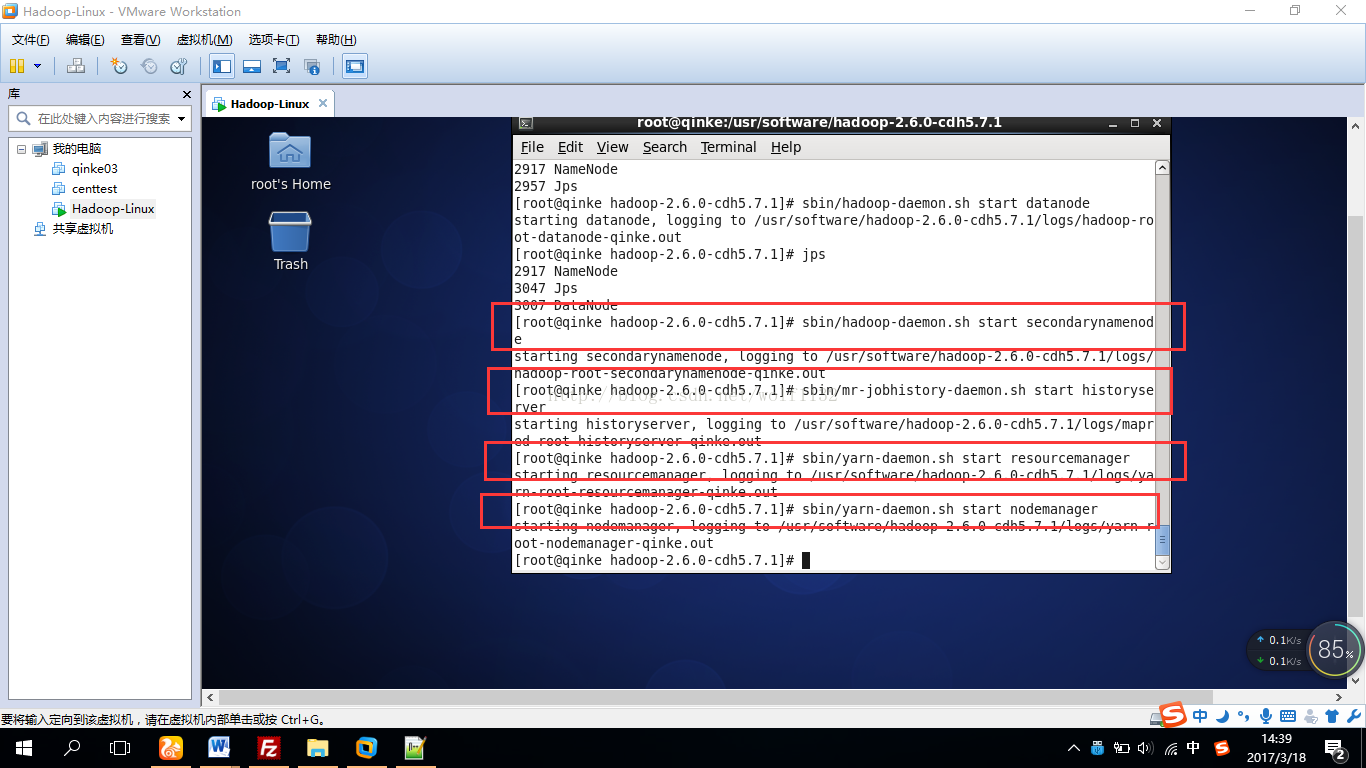
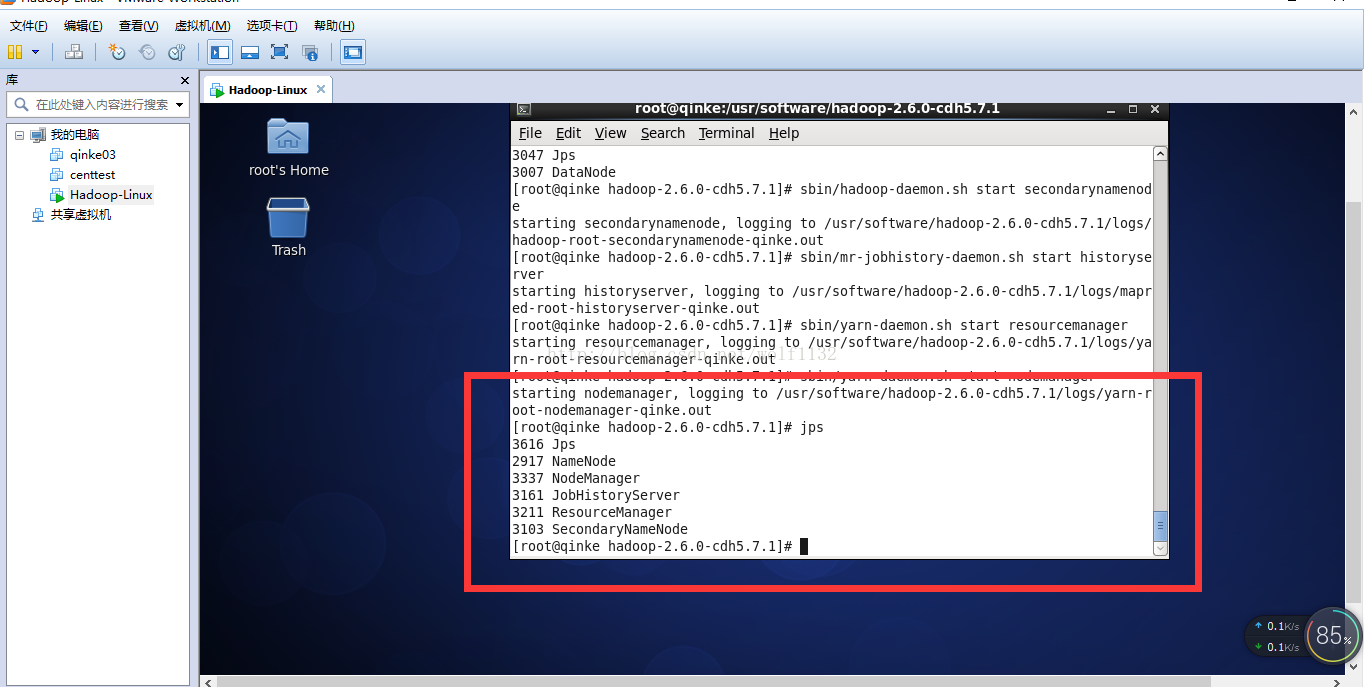
全部启动成功,下面是【大数据之佳】的微信公众号二维码,上面有更多的大数据图文教程
也可以添加我的个人微信账号【tenggeliwolf】一起交流学习
















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









