







由于网上资料很多,这里就不再对算法原理进行推导,仅给出博主用Python实现的代码,供大家参考
适用问题:多类分类
下面用改进的迭代尺度法(IIS)学习最大熵模型,将特征函数定义为:
与其他分类器不同的是,最大熵模型中的f(x,y)中的x是单独的一个特征,不是一个n维特征向量,因此我们需要对每个维度特征加一个区分标签;如X=(x0,x1,x2,…)变为X=(0_x0,1_x1,2_x2,…)
测试数据集:train.csv
实现代码:
# encoding=utf-8
import pandas as pd
import time
import math
from collections import defaultdict
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
class MaxEnt(object):
def init_params(self, X, Y):
self.X_ = X
self.Y_ = set()
self.cal_Vxy(X, Y)
self.N = len(X) # 训练集大小,如P59例子中为15
self.n = len(self.Vxy) # 数据集中(x,y)对数,如P59例子中为6+3+3+5=17对
self.M = 10000.0 # 设置P91中的M,可认为是学习速率
self.build_dict()
self.cal_Pxy()
def cal_Vxy(self, X, Y):
'''
计算v(X=x,Y=y),P82
'''
self.Vxy = defaultdict(int)
for i in range(len(X)):
x_, y = X[i], Y[i]
self.Y_.add(y)
for x in x_:
self.Vxy[(x, y)] += 1
def build_dict(self):
self.id2xy = {}
self.xy2id = {}
for i, (x, y) in enumerate(self.Vxy):
self.id2xy[i] = (x, y)
self.xy2id[(x, y)] = i
def cal_Pxy(self):
'''
计算P(X=x,Y=y),P82
'''
self.Pxy = defaultdict(float)
for id in range(self.n):
(x, y) = self.id2xy[id]
self.Pxy[id] = float(self.Vxy[(x, y)]) / float(self.N)
def cal_Zx(self, X, y):
'''
计算Zw(x/yi),根据P85公式6.23,Zw(x)未相加前的单项
'''
result = 0.0
for x in X:
if (x,y) in self.xy2id:
id = self.xy2id[(x, y)]
result += self.w[id]
return (math.exp(result), y)
def cal_Pyx(self, X):
'''
计算P(y|x),根据P85公式6.22
'''
Pyxs = [(self.cal_Zx(X, y)) for y in self.Y_]
Zwx = sum([prob for prob, y in Pyxs])
return [(prob / Zwx, y) for prob, y in Pyxs]
def cal_Epfi(self):
'''
计算Ep(fi),根据P83最上面的公式
'''
self.Epfi = [0.0 for i in range(self.n)]
for i, X in enumerate(self.X_):
Pyxs = self.cal_Pyx(X)
for x in X:
for Pyx, y in Pyxs:
if (x,y) in self.xy2id:
id = self.xy2id[(x, y)]
self.Epfi[id] += Pyx * (1.0 / self.N)
def train(self, X, Y):
'''
IIS学习算法
'''
self.init_params(X, Y)
# 第一步: 初始化参数值wi为0
self.w = [0.0 for i in range(self.n)]
max_iteration = 500 # 设置最大迭代次数
for times in range(max_iteration):
print("the number of iterater : %d " % times)
# 第二步:求δi
detas = []
self.cal_Epfi()
for i in range(self.n):
deta = 1 / self.M * math.log(self.Pxy[i] / self.Epfi[i]) # 指定的特征函数为指示函数,因此E~p(fi)等于Pxy
detas.append(deta)
# if len(filter(lambda x: abs(x) >= 0.01, detas)) == 0:
# break
# 第三步:更新Wi
self.w = [self.w[i] + detas[i] for i in range(self.n)]
def predict(self, testset):
results = []
for test in testset:
result = self.cal_Pyx(test)
results.append(max(result, key=lambda x: x[0])[1])
return results
def rebuild_features(features):
'''
最大熵模型中的f(x,y)中的x是单独的一个特征,不是一个n维特征向量,因此我们需要对每个维度特征加一个区分标签
具体地:将原feature的(a0,a1,a2,a3,a4,...) 变成 (0_a0,1_a1,2_a2,3_a3,4_a4,...)形式
'''
new_features = []
for feature in features:
new_feature = []
for i, f in enumerate(feature):
new_feature.append(str(i) + '_' + str(f))
new_features.append(new_feature)
return new_features
if __name__ == '__main__':
print("Start read data...")
time_1 = time.time()
raw_data = pd.read_csv('../data/train.csv', header=0) # 读取csv数据
data = raw_data.values
features = data[:5000:, 1::]
labels = data[:5000:, 0]
# 避免过拟合,采用交叉验证,随机选取33%数据作为测试集,剩余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
train_features = rebuild_features(train_features)
test_features = rebuild_features(test_features)
time_2 = time.time()
print('read data cost %f seconds' % (time_2 - time_1))
print('Start training...')
met = MaxEnt()
met.train(train_features, train_labels)
time_3 = time.time()
print('training cost %f seconds' % (time_3 - time_2))
print('Start predicting...')
test_predict = met.predict(test_features)
time_4 = time.time()
print('predicting cost %f seconds' % (time_4 - time_3))
score = accuracy_score(test_labels, test_predict)
print("The accruacy score is %f" % score)代码可从这里maxEnt/maxEnt.py获取
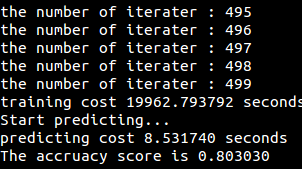
运行结果:















 2442
2442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









