









 本文档记录了在VMware环境中使用RTXA6000显卡进行VGPU实施的过程,包括环境要求(ESXI 7.0U2,VCSA 8.0)、显卡模式转换、Horizon配置修改等步骤。遇到的主要问题是RTXA6000需要通过NVIDIA提供的工具转换模式,并且Horizon需要手动添加配置支持新显卡。此外,还提到了DELL 740服务器需要在BIOS中开启SR-IOV选项。
本文档记录了在VMware环境中使用RTXA6000显卡进行VGPU实施的过程,包括环境要求(ESXI 7.0U2,VCSA 8.0)、显卡模式转换、Horizon配置修改等步骤。遇到的主要问题是RTXA6000需要通过NVIDIA提供的工具转换模式,并且Horizon需要手动添加配置支持新显卡。此外,还提到了DELL 740服务器需要在BIOS中开启SR-IOV选项。
1、前几天有个代理商客户要用6000做VGPU,一开始以为是要用RTX 6000,最后确定为RTXA6000,这个显卡比较新,我也没做过这个显卡的VGPU实施,但是看NVIDIA上,这个显卡是支持VGPU的,然后就开始实施。
首先是环境准备。
ESXI 和 VCSA 都要用7.0 U2(一定要用7.0U2,否则模板机加上显卡之后无法开机,很蛋疼)。
horzion 用最新的8.0.没有composer 安装更方便了。
licserver 和 VGPU的驱动,如果没有或不知道怎么找和安装的可以联系我, 微信在最下边放。。
下面开始讲所遇到的坑了!!
一、上面说到一定要用目前最新的esxi 和 vcsa 就是7.0U2 版本。官网都能下载。
二、RTXA6000 有两个模式,需要转换一下模式才可以使用。
可以看到NVIDIA user-guide 文件里面说明了,只有A40和A6000需要转换,工具是NVIDIA_Display_Mode_Selector_Tool(工具下载地址放在下方了)。

转换工具地址如下
https://cowtransfer.com/s/067e7fc498b341 873433
转换工具用法:
用PE进去之后,打开cmd,然后根据下面提示进行操作。
模式选择1

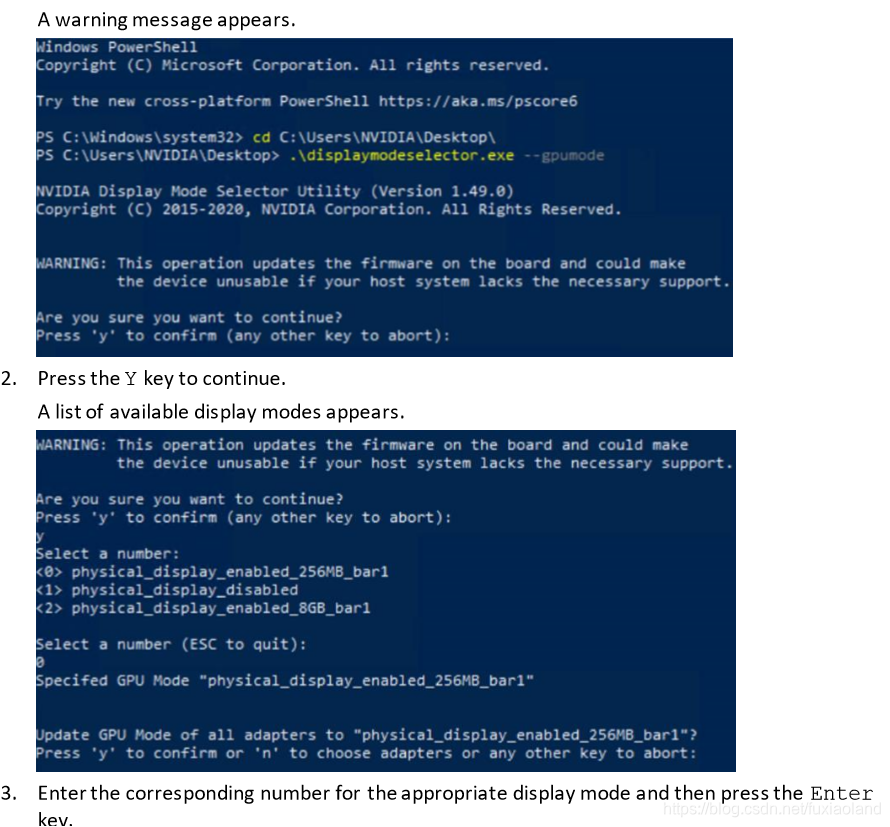
转换完走完百分比重启esxi 就ok 了。
三、horzion 还需要修改配置文件
因为A6000比较新所有horzion没有配置,所以要手动添加一个,需要参考KB59271。要修改graphic-profiles 这个文件,不过这个文件里面都是grid开头,我们的A6000的是nvidia_rtxa6000 后面接各种Q。
以上就是我遇到的小坑,大家可以继续补充,有什么问题可以加我v servant-king 大家继续探讨。
有高深道友关于VMware 的群,也可以邀请我加一下,一起学习进步。
四、有一位道友遇到一个问题关于DELL 740的,需要bios 打开 需要在BIOS中将SR-IOV修改成enabled,默认情况是disabled。

















 3503
3503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









