




 本文档详述了数据平面开发工具包(DPDK)的软件架构、开发环境信息及优化指南,涵盖环境抽象层(EAL)、核心组件、网络包缓存管理、时钟管理等,适用于快速数据包处理应用。
本文档详述了数据平面开发工具包(DPDK)的软件架构、开发环境信息及优化指南,涵盖环境抽象层(EAL)、核心组件、网络包缓存管理、时钟管理等,适用于快速数据包处理应用。
1. Introduction(简介)(请读自行阅读)
This document provides software architecture information, development environment information and optimization guidelines.
本文档提供了软件架构信息、开发环境信息和优化指南。
For programming examples and for instructions on compiling and running each sample application, see the DPDK Sample Applications User Guide for details.
有关编程示例以及编译和运行每个示例应用程序的说明,请参阅DPDK示例应用程序用户指南了解详细信息。
For general information on compiling and running applications, see the DPDK Getting Started Guide.
有关编译和运行应用程序的一般信息,请参阅DPDK入门指南。
链接如下:
http://doc.dpdk.org/guides/prog_guide/intro.html#related-publications
2. Overview(概述)
This section gives a global overview of the architecture of Data Plane Development Kit (DPDK).
本节对数据平面开发工具包(DPDK)的体系结构进行了总体概述。
The main goal of the DPDK is to provide a simple, complete framework for fast packet processing in data plane applications. Users may use the code to understand some of the techniques employed, to build upon for prototyping or to add their own protocol stacks. Alternative ecosystem options that use the DPDK are available.
DPDK的主要目标是为数据平面应用程序中的快速数据包处理提供一个简单、完整的框架。用户可以使用这些代码来理解所使用的一些技术,以构建原型或添加自己的协议栈。可以使用DPDK的其他生态系统选项。
The framework creates a set of libraries for specific environments through the creation of an Environment Abstraction Layer (EAL), which may be specific to a mode of the Intel® architecture (32-bit or 64-bit), Linux* user space compilers or a specific platform. These environments are created through the use of make files and configuration files. Once the EAL library is created, the user may link with the library to create their own applications. Other libraries, outside of EAL, including the Hash, Longest Prefix Match (LPM) and rings libraries are also provided. Sample applications are provided to help show the user how to use various features of the DPDK.
框架创建一组特定的环境的库的集合从而创建了一个环境抽象层(EAL),此层可能是特定于Intel®体系结构模式(32位或64位),Linux用户空间*编译器或者一个特定的平台。这些环境是通过使用make文件和配置文件创建的。一旦创建了EAL库,用户可以链接该库来创建自己的应用程序。除了EAL之外,还提供了其他库,包括哈希、最长前缀匹配(LPM)和环库。本文提供了示例应用程序,以帮助用户了解如何使用DPDK的各种特性。
The DPDK implements a run to completion model for packet processing, where all resources must be allocated prior to calling Data Plane applications, running as execution units on logical processing cores. The model does not support a scheduler and all devices are accessed by polling. The primary reason for not using interrupts is the performance overhead imposed by interrupt processing.
DPDK为包处理实现了一个从运行到完成的模型,在这个模型中,在调用数据平面应用程序之前,必须分配所有资源,这些资源作为执行单元在逻辑处理核心上运行。该模型不支持调度程序,所有设备都通过轮询访问。不使用中断的主要原因是中断处理带来的性能开销。
In addition to the run-to-completion model, a pipeline model may also be used by passing packets or messages between cores via the rings. This allows work to be performed in stages and may allow more efficient use of code on cores.
除了运行到完成模型之外,管道模型还可用于通过环在内核之间传递数据包或消息。这允许分阶段执行工作,并允许更有效地在核心上使用代码。
2.1. Development Environment(开发环境)
The DPDK project installation requires Linux and the associated toolchain, such as one or more compilers, assembler, make utility, editor and various libraries to create the DPDK components and libraries.
DPDK项目的安装需要Linux和相关的工具链,如一个或多个编译器、汇编器、make实用程序、编辑器和各种库来创建DPDK组件和库。
Once these libraries are created for the specific environment and architecture, they may then be used to create the user’s data plane application.
一旦为特定的环境和体系结构创建了这些库,就可以使用它们来创建用户的数据平面应用程序。
When creating applications for the Linux user space, the glibc library is used. For DPDK applications, two environmental variables (RTE_SDK and RTE_TARGET) must be configured before compiling the applications. The following are examples of how the variables can be set:
在为Linux用户空间创建应用程序时,将使用glibc库。对于DPDK应用程序,在编译应用程序之前必须配置两个环境变量(RTE_SDK和RTE_TARGET)。以下是如何设置变量的例子:

2.2. Environment Abstraction Layer(环境抽象层)
The Environment Abstraction Layer (EAL) provides a generic interface that hides the environment specifics from the applications and libraries. The services provided by the EAL are:
环境抽象层(EAL)提供了一个通用接口,用于向应用程序和库隐藏环境细节。本处提供的服务包括:
- DPDK loading and launching
DPDK加载和启动 - Support for multi-process and multi-thread execution types
支持多进程和多线程执行类型 - Core affinity/assignment procedures
CPU亲和力/作业程序
译者注:CPU affinity 是一种调度属性(scheduler property), 它可以将一个进程"绑定" 到一个或一组CPU上.
- System memory allocation/de-allocation
系统内存分配/释放 - Atomic/lock operations
原子/锁操作 - Time reference
时间基准 - PCI bus access
PCI总线访问 - Trace and debug functions
跟踪和调试函数 - CPU feature identification
CPU功能认证 - Interrupt handling
中断处理 - Alarm operations
告警操作 - Memory management (malloc)
内存管理
The EAL is fully described in Environment Abstraction Layer.
详细地关于EAL的描述在第3章环境抽象层。
2.3. Core Components(核心组件)
The core components are a set of libraries that provide all the elements needed for high-performance packet processing applications.
核心组件是一组库,提供高性能数据包处理应用程序所需的所有元素。
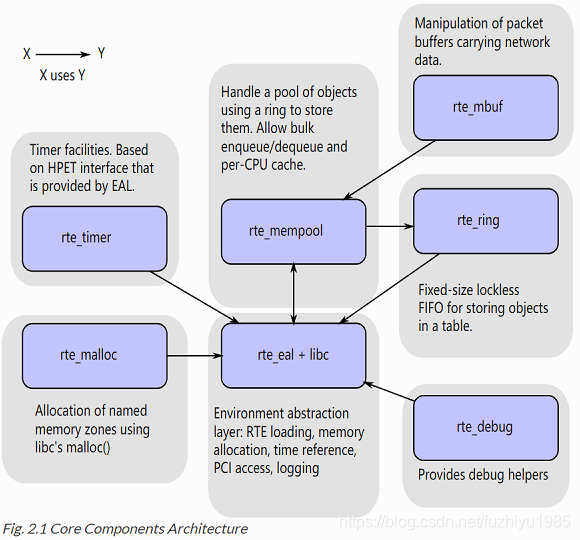
2.3.1. Ring Manager (librte_ring) 环管理
The ring structure provides a lockless multi-producer, multi-consumer FIFO API in a finite size table. It has some advantages over lockless queues; easier to implement, adapted to bulk operations and faster. A ring is used by the Memory Pool Manager (librte_mempool) and may be used as a general communication mechanism between cores and/or execution blocks connected together on a logical core.
环形结构在有限大小的表中提供了无锁的多生产者、多使用者FIFO API。
它比无锁队列有一些优势;易于实现,适应批量操作,速度更快。内存池管理器(librte_mempool)使用一个环,它可以用作连接在逻辑内核上的内核和/或执行块之间的通用通信机制。
This ring buffer and its usage are fully described in Ring Library.
环行结构的详细描述在第五章环形结构库
2.3.2. Memory Pool Manager (librte_mempool)(内存池管理)
The Memory Pool Manager is responsible for allocating pools of objects in memory. A pool is identified by name and uses a ring to store free objects. It provides some other optional services, such as a per-core object cache and an alignment helper to ensure that objects are padded to spread them equally on all RAM channels.
内存池管理器负责分配内存中的对象池。池按名称标识,并使用一个环来存储空闲对象。它还提供了其他一些可选服务,例如每个核心对象缓存和对齐助手,以确保填充对象,使其在所有RAM通道上均匀分布。
This memory pool allocator is described in Mempool Library.
内存池详细描述在第六章中。
2.3.3. Network Packet Buffer Management (librte_mbuf)
网络包缓存管理
The mbuf library provides the facility to create and destroy buffers that may be used by the DPDK application to store message buffers. The message buffers are created at startup time and stored in a mempool, using the DPDK mempool library.
mbuf库提供了创建和销毁DPDK应用程序用于存储消息缓冲区的缓冲区的功能.消息缓冲区在启动时创建,并使用DPDK mempool库存储在mempool中。
This library provides an API to allocate/free mbufs, manipulate packet buffers which are used to carry network packets.
这个库提供了一个API来分配/释放mbufs,操作用于传输网络数据包的数据包缓冲区。
Network Packet Buffer Management is described in Mbuf Library.
在Mbuf库中描述了网络数据包缓冲区管理
2.3.4. Timer Manager (librte_timer)时钟管理
This library provides a timer service to DPDK execution units, providing the ability to execute a function asynchronously. It can be periodic function calls, or just a one-shot call. It uses the timer interface provided by the Environment Abstraction Layer (EAL) to get a precise time reference and can be initiated on a per-core basis as required.
他的库为DPDK执行单元提供计时器服务,提供异步执行函数的能力。它可以是周期性的函数调用,也可以是一次性调用。它使用由环境抽象层(EAL)提供的定时器接口来获得精确的时间引用,并且可以根据需要在每个核的基础上启动。库文档可在定时器库中获得。
The library documentation is available in Timer Library详细.
该库的详细描述在第19章
2.4. Ethernet Poll Mode Driver Architecture
The DPDK includes Poll Mode Drivers (PMDs) for 1 GbE, 10 GbE and 40GbE, and para virtualized virtio Ethernet controllers which are designed to work without asynchronous, interrupt-based signaling mechanisms.
DPDK包括针对1个GbE、10个GbE和40个GbE的轮询模式驱动程序(PMDs),以及para虚拟virtio以太网控制器,其用于在没有异步、基于中断的信令机制的情况下工作。
译者注:virtio 是一种 I/O 半虚拟化解决方案,是一套通用 I/O 设备虚拟化的程序,是对半虚拟化 Hypervisor
中的一组通用 I/O 设备的抽象算法的
2.5. Packet Forwarding Algorithm Support (包转发算法的支持)
The DPDK includes Hash (librte_hash) and Longest Prefix Match (LPM,librte_lpm) libraries to support the corresponding packet forwarding algorithms.
DPDK包括哈希(librte_hash)和最长前缀匹配(LPM,librte_lpm)库,以支持相应的包转发算法。
See Hash Library and LPM Library for more information.
有关更多信息,请参见哈希库(20章)和LPM库(23章)。
2.6. librte_net
The librte_net library is a collection of IP protocol definitions and convenience macros. It is based on code from the FreeBSD* IP stack and contains protocol numbers (for use in IP headers), IP-related macros, IPv4/IPv6 header structures and TCP, UDP and SCTP header structures.
librte_net库是IP协议定义和convenience macros的集合。它基于FreeBSD* IP栈的代码,包含协议编号(用于IP报头)、与IP相关的宏、IPv4/IPv6报头结构和TCP、UDP和SCTP报头结构。
3. Environment Abstraction Layer(环境抽象层)
The Environment Abstraction Layer (EAL) is responsible for gaining access to low-level resources such as hardware and memory space. It provides a generic interface that hides the environment specifics from the applications and libraries. It is the responsibility of the initialization routine to decide how to allocate these resources (that is, memory space, devices, timers, consoles, and so on).
环境抽象层(EAL)负责访问底层资源,如硬件和内存空间。它提供了一个通用接口,用于向应用程序和库隐藏环境细节。初始化例程负责决定如何分配这些资源(即内存空间、设备、计时器、控制台等等)。
Typical services expected from the EAL are:
EAL的典型服务:
- DPDK Loading and Launching: The DPDK and its application are linked as a single application and must be loaded by some means.
加载和启动DPDK: DPDK及其应用程序作为单个应用程序链接,必须通过某种方式加载。 - Core Affinity/Assignment Procedures: The EAL provides mechanisms for assigning execution units to specific cores as well as creating execution instances.
核心关联/分配过程:EAL提供了将执行单元分配到特定CPU核心以及创建执行实例的机制。 - System Memory Reservation: The EAL facilitates the reservation of
different memory zones, for example, physical memory areas for device interactions.
系统内存保留:EAL可以方便地保留不同的内存区域,例如用于设备交互的物理内存区域。 - Trace and Debug Functions: Logs, dump_stack, panic and so on.
跟踪和调试函数:日志、dump_stack、panic等。 - Utility Functions: Spinlocks and atomic counters that are not
provided in libc.
工具程序函数:libc中没有提供的自旋锁和原子计数器。 - CPU Feature Identification: Determine at runtime if a particular
feature, for example, Intel® AVX is supported. Determine if the
current CPU supports the feature set that the binary was compiled
for.
CPU特性识别:在运行时确定某个特定的特性是否被支持,例如,英特尔®AVX。确定当前CPU是否支持已编译二进制文件的特性集。 - Interrupt Handling: Interfaces to register/unregister callbacks to specific interrupt sources.
中断处理:对特定中断源注册/取消注册回调的接口。 - Alarm Functions: Interfaces to set/remove callbacks to be run at a
specific time.
报警功能:设置/删除在特定时间运行的回调的接口。
3.1. EAL in a Linux-userland Execution Environment(EAL在Linux用户级环境中执行)
In a Linux user space environment, the DPDK application runs as a user-space application using the pthread library.
在Linux用户空间环境中,DPDK应用程序使用pthread库作为用户空间应用程序运行。
The EAL performs physical memory allocation using mmap() in hugetlbfs (using huge page sizes to increase performance). This memory is exposed to DPDK service layers such as the Mempool Library.
EAL在hugetlbfs文件系统中使用mmap()执行物理内存分配(使用巨大的页面大小来提高性能)。该内存公开给DPDK服务层,如Mempool库。
译者注:Linux 操作系统采用了基于 hugetlbfs 特殊文件系统
At this point, the DPDK services layer will be initialized, then through pthread setaffinity calls, each execution unit will be assigned to a specific logical core to run as a user-level thread.
此时,DPDK服务层将被初始化,然后通过 pthread setaffinity调用,将每个执行单元分配到一个特定的逻辑核心,作为用户级线程运行。
The time reference is provided by the CPU Time-Stamp Counter (TSC) or by the HPET kernel API through a mmap() call.
时间基准由CPU时间戳计数器(TSC)或HPET内核API通过mmap()调用提供。
Part of the initialization is done by the start function of glibc. A check is also performed at initialization time to ensure that the micro architecture type chosen in the config file is supported by the CPU. Then, the main() function is called. The core initialization and launch is done in rte_eal_init() (see the API documentation). It consist of calls to the pthread library (more specifically, pthread_self(), pthread_create(), and pthread_setaffinity_np()).
初始化的一部分是由glibc的start函数完成的。检查需要在初始化执行时被执行,以确保配置文件中选择的微体系结构类型得到CPU的支持。然后,调用main()函数。核心初始化和启动在rte_eal_init()中完成(请参阅API文档)。它由pthread库(更具体地说,pthread_self()、pthread_create()和pthread_setaffinity_np())的调用组成。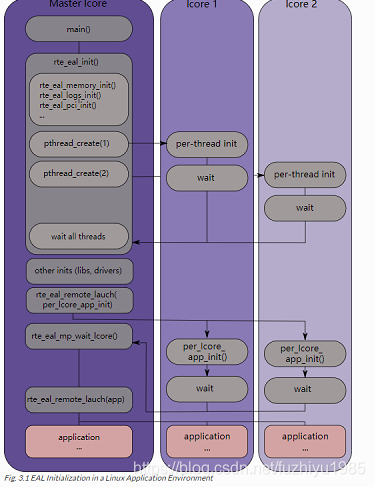
备注:Initialization of objects, such as memory zones, rings, memory pools, lpm tables and hash tables, should be done as part of the overall application initialization on the master lcore. The creation and initialization functions for these objects are not multi-thread safe. However, once initialized, the objects themselves can safely be used in multiple threads simultaneously.
对象(如内存区域、环、内存池、lpm表和散列表)的初始化应该作为主lcore上的整个应用程序初始化的一部分来完成。这些对象的创建和初始化函数不是多线程安全的。然而,一旦初始化,对象本身就可以安全地同时在多个线程中使用。
3.1.2. Shutdown and Cleanup
During the initialization of EAL resources such as hugepage backed memory can be allocated by core components. The memory allocated during rte_eal_init() can be released by calling the rte_eal_cleanup() function. Refer to the API documentation for details.
在EAL资源初始化过程中,可以通过核心组件来分配巨页内存等资源。在rte_eal_init()期间分配的内存可以通过调用rte_eal_cleanup()函数来释放。有关详细信息,请参阅API文档。
3.1.3. Multi-process Support
The Linuxapp EAL allows a multi-process as well as a multi-threaded (pthread) deployment model. See chapter Multi-process Support for more details.
Linuxapp EAL允许多进程以及多线程(pthread)部署模型。有关更多细节,请参见“3.3章多进程支持”一章
3.1.4. Memory Mapping Discovery and Memory Reservation
内存映射发现和内存分配
The allocation of large contiguous physical memory is done using the hugetlbfs kernel filesystem. The EAL provides an API to reserve named memory zones in this contiguous memory. The physical address of the reserved memory for that memory zone is also returned to the user by the memory zone reservation API.
大型连续物理内存的分配是使用hugetlbfs内核文件系统来完成的。EAL提供了一个API来在这个连续内存中分配已经被命名的内存区域。通过内存区域预留API接口将内存区域即用户预留的内存的物理地址返回给客户
There are two modes in which DPDK memory subsystem can operate: dynamic mode, and legacy mode. Both modes are explained below.
DPDK内存子系统可以运行两种模式:动态模式和预分配内存模式。下面将解释这两种模式。
备注:Memory reservations done using the APIs provided by rte_malloc are also backed by pages from the hugetlbfs filesystem.
使用rte_malloc提供的api完成的内存保留也得到hugetlbfs文件系统页面的支持。
- Dynamic memory mode
Currently, this mode is only supported on Linux.
In this mode, usage of hugepages by DPDK application will grow and shrink based on application’s requests. Any memory allocation through rte_malloc(), rte_memzone_reserve() or other methods, can potentially result in more hugepages being reserved from the system. Similarly, any memory deallocation can potentially result in hugepages being released back to the system.
在这种模式下,DPDK应用程序对hugepages的使用将根据应用程序的请求进行增长和收缩。通过rte_malloc()、rte_memzone_reserve()或其他方法分配的任何内存都可能导致从系统保留更多的大页面。类似地,任何内存重新分配都可能导致将hugepages里面的大量页面释放回系统。
Memory allocated in this mode is not guaranteed to be IOVA-contiguous. If large chunks of IOVA-contiguous are required (with “large” defined as “more than one page”), it is recommended to either use VFIO driver for all physical devices (so that IOVA and VA addresses can be the same, thereby bypassing physical addresses entirely), or use legacy memory mode.
在这种模式下分配的内存不能保证是IOVA-contiguous。如果需要大块连续的IOVA(“大”定义为“多个页面”),建议对所有物理设备使用VFIO驱动程序(这样IOVA和VA地址可以相同,从而完全绕过物理地址),或者使用遗留内存模式。
For chunks of memory which must be IOVA-contiguous, it is recommended to use rte_memzone_reserve() function with RTE_MEMZONE_IOVA_CONTIG flag specified. This way, memory allocator will ensure that, whatever memory mode is in use, either reserved memory will satisfy the requirements, or the allocation will fail.
对于必须是iova连续的内存块,建议使用rte_memzone_reserve()函数,并指定RTE_MEMZONE_IOVA_CONTIG标志。这样,内存分配器将确保,无论使用何种内存模式,保留的内存要么满足要求,要么分配失败。
There is no need to preallocate any memory at startup using -m or --socket-mem command-line parameters, however it is still possible to do so, in which case preallocate memory will be “pinned” (i.e. will never be released by the application back to the system). It will be possible to allocate more hugepages, and deallocate those, but any preallocated pages will not be freed. If neither -m nor --socket-mem were specified, no memory will be preallocated, and all memory will be allocated at runtime, as needed.
在启动时不需要使用-m或-socket-mem命令行参数预分配任何内存,但是仍然可以这样做,在使用-m或-socket-mem命令行参数预分配任何内存的情况下,预分配内存将“固定”(即应用程序永远不会释放回系统)。不预留内存可以分配更多的大页面,并释放它们,但是任何预先分配的页面都不会被释放。如果没有指定-m或——socket-mem,则不会预先分配内存,并且将根据需要在运行时分配所有内存。
Another available option to use in dynamic memory mode is --single-file-segments command-line option. This option will put pages in single files (per memseg list), as opposed to creating a file per page. This is normally not needed, but can be useful for use cases like userspace vhost, where there is limited number of page file descriptors that can be passed to VirtIO.
在动态内存模式下使用的另一个可用选项是–single-file-segments命令行选项。这个选项将页面放在单个文件中(每个memseg列表),而不是每个页面创建一个文件。通常不需要这样做,但是对于userspace vhost这样的用例非常有用,因为可以传递给VirtIO的页面文件描述符的数量是有限的。
If the application (or DPDK-internal code, such as device drivers) wishes to receive notifications about newly allocated memory, it is possible to register for memory event callbacks via rte_mem_event_callback_register() function. This will call a callback function any time DPDK’s memory map has changed.
如果应用程序(或dpdk内部代码,如设备驱动程序)希望接收关于新分配内存的通知,可以通过rte_mem_event_callback_register()函数注册内存事件回调。这将在DPDK的内存映射发生更改时调用回调函数。
If the application (or DPDK-internal code, such as device drivers) wishes to be notified about memory allocations above specified threshold (and have a chance to deny them), allocation validator callbacks are also available via rte_mem_alloc_validator_callback_register() function.
如果应用程序(或dpdk内部代码,如设备驱动程序)希望在超过指定阈值的内存分配上得到通知(并有机会拒绝它们),那么也可以通过rte_mem_alloc_validator_callback_register()函数获得分配验证器回调。
A default validator callback is provided by EAL, which can be enabled with a --socket-limit command-line option, for a simple way to limit maximum amount of memory that can be used by DPDK application.
EAL提供了一个默认的校验器回调函数,它可以通过—socket-limit命令行选项启用,这是一种限制DPDK应用程序可以使用的最大内存量的简单方法。
译者注:IOVA:IO virtual address,可以理解为计算机的输入输出设备的虚拟地址
- Legacy memory mode(预分配内存模式)
This mode is enabled by specifying --legacy-mem command-line switch to the EAL. This switch will have no effect on FreeBSD as FreeBSD only supports legacy mode anyway.
通过指定–legacy-mem命令行切换到EAL,可以启用此模式。这个切换对FreeBSD没有影响,因为FreeBSD只支持预分配内存模式。
This mode mimics historical behavior of EAL. That is, EAL will reserve all memory at startup, sort all memory into large IOVA-contiguous chunks, and will not allow acquiring or releasing hugepages from the system at runtime.
这种模式模仿了EAL的历史行为。也就是说,EAL将在启动时保留所有内存,将所有内存排序为大型iova连续块,并且不允许在运行时从系统获取或释放大型页面。
If neither -m nor --socket-mem were specified, the entire available hugepage memory will be preallocated.
如果没有指定-m或–socket-mem,则将重新分配整个可用的大分页内存。 - Hugepage allocation matching(大页面分配监控)
This behavior is enabled by specifying the --match-allocations command-line switch to the EAL. This switch is Linux-only and not supported with --legacy-mem nor --no-huge.
通过指定-match-allocations命令行切换到EAL,可以启用此行为。这个开关只支持linux,不支持–legacy-mem或–no-huge。
Some applications using memory event callbacks may require that hugepages be freed exactly as they were allocated. These applications may also require that any allocation from the malloc heap not span across allocations associated with two different memory event callbacks. Hugepage allocation matching can be used by these types of applications to satisfy both of these requirements. This can result in some increased memory usage which is very dependent on the memory allocation patterns of the application.
一些使用内存事件回调的应用程序可能需要完全按照应用程序分配的内存释放大型页面。这些应用程序还可能要求来自malloc堆的任何分配但是内存事件回调不能跨越与两个不同内存的分配。这些类型的应用程序可以使用大型页分配监控匹配来满足一些种需求。这可能导致内存使用的增加,而内存使用非常依赖于应用程序的内存分配模式。 - 32-bit support
Additional restrictions are present when running in 32-bit mode. In dynamic memory mode, by default maximum of 2 gigabytes of VA space will be preallocated, and all of it will be on master lcore NUMA node unless --socket-mem flag is used.
在32位模式下运行时还存在其他限制。在动态内存模式下,默认情况下将预分配最多2g的VA空间,所有这些空间都将位于主lcore NUMA节点上,除非使用socket-mem标志。所有这些都将在主lcore NUMA节点上,除非使用–socket-mem标志。
In legacy mode, VA space will only be preallocated for segments that were requested (plus padding, to keep IOVA-contiguousness).
在预分配内存模式下,VA空间只会预先分配给请求的段(加上填充,以保持iova的连续性)。 - Maximum amount of memory
All possible virtual memory space that can ever be used for hugepage mapping in a DPDK process is preallocated at startup, thereby placing an upper limit on how much memory a DPDK application can have. DPDK memory is stored in segment lists, each segment is strictly one physical page. It is possible to change the amount of virtual memory being preallocated at startup by editing the following config variables:
在DPDK进程中,所有可能用于大页面映射的虚拟内存空间都是在启动时预先分配的,从而设置了一个DPDK应用程序可以拥有多少内存设置上限。DPDK内存存储在段列表中,每个段严格来说是一个物理页面。可以通过编辑以下配置变量来更改在启动时预先分配的虚拟内存数量: - CONFIG_RTE_MAX_MEMSEG_LISTS :controls how many segment lists can DPDK have 控制DPDK可以有多少段列表
- CONFIG_RTE_MAX_MEM_MB_PER_LIST controls how much megabytes of memory each segment list can address 控制每个段列表可以寻址的内存大小
- CONFIG_RTE_MAX_MEMSEG_PER_LIST controls how many segments each segment can have controls how many segments each segment can have
- CONFIG_RTE_MAX_MEMSEG_PER_TYPE controls how many segments each memory type can have (where “type” is defined as “page size + NUMA node” combination) 控制每个内存类型可以有多少段(其中“类型”定义为“页面大小+ NUMA节点”组合)
- CONFIG_RTE_MAX_MEM_MB_PER_TYPE controls how much megabytes of memory each memory type can address 控制每种内存类型可以寻址的内存大小
- CONFIG_RTE_MAX_MEM_MB places a global maximum on the amount of memory DPDK can reserve 为DPDK可以保留的内存数量设置全局最大值
Normally, these options do not need to be changed
备注:Preallocated virtual memory is not to be confused with preallocated hugepage memory! All DPDK processes preallocate virtual memory at startup. Hugepages can later be mapped into that preallocated VA space (if dynamic memory mode is enabled), and can optionally be mapped into it at startup.
预分配的虚拟内存不能与预分配的大内存混淆!所有DPDK进程在启动时预分配虚拟内存。DPDK进程启动,Hugepages会被映射到预先分配的VA空间(如果启用了动态内存模式),也可以在启动时将其可选地映射到其中。
3.1.5. Support for Externally Allocated Memory支持外部分配内存
It is possible to use externally allocated memory in DPDK. There are two ways in which using externally allocated memory can work: the malloc heap API’s, and manual memory management.
可以在DPDK中使用外部分配的内存。使用外部分配的内存有两种方式可以工作:malloc堆API和手动内存管理。
- Using heap API’s for externally allocated memory(使用堆接口来分配外置内存)
Using using a set of malloc heap API’s is the recommended way to use externally allocated memory in DPDK. In this way, support for externally allocated memory is implemented through overloading the socket ID - externally allocated heaps will have socket ID’s that would be considered invalid under normal circumstances. Requesting an allocation to take place from a specified externally allocated memory is a matter of supplying the correct socket ID to DPDK allocator, either directly (e.g. through a call to rte_malloc) or indirectly (through data structure-specific allocation API’s such as rte_ring_create). Using these API’s also ensures that mapping of externally allocated memory for DMA is also performed on any memory segment that is added to a DPDK malloc heap.
推荐使用一组malloc堆API来在DPDK中外部分配的内存。通过这种方式,通过重载套接字ID来实现对外部分配内存的支持——外部分配的堆将具有套接字ID,在正常情况下这些套接字ID将被视为无效。请求从指定的外部分配内存进行分配需要向DPDK分配器提供正确的套接字ID,可以是直接(例如通过对rte_malloc的调用),也可以是间接(通过特定于数据结构的分配API,例如rte_ring_create)。使用这些API可以确保外部内存和DMA映射同时也可以。保证已经添加到DPDK malloc堆的任何内存段能够被执行。
Since there is no way DPDK can verify whether memory is available or valid, this responsibility falls on the shoulders of the user. All multiprocess synchronization is also user’s responsibility, as well as ensuring that all calls to add/attach/detach/remove memory are done in the correct order. It is not required to attach to a memory area in all processes - only attach to memory areas as needed.
由于DPDK无法验证内存是可用的还是有效的,所以这个责任就落在了用户的肩上。所有多进程同步也是用户的责任,并确保所有添加/附加/分离/删除内存的调用都按正确的顺序执行。不需要在所有进程中都附加到内存区域—只需在需要时附加到内存区域即可。
The expected workflow is as follows:(预期的工作流程如下)
-
Get a pointer to memory area
-
Create a named heap
-
Add memory area(s) to the heap
-
If IOVA table is not specified, IOVA addresses will be assumed to be unavailable, and DMA mappings will not be performed
如果没有指定IOVA表,则假定IOVA地址不可用,并且不执行DMA映射 -
Other processes must attach to the memory area before they can use it
如果没有指定IOVA表,则假定IOVA地址不可用,并且不执行DMA映射 -
Get socket ID used for the heap
-
Use normal DPDK allocation procedures, using supplied socket ID
-
If memory area is no longer needed, it can be removed from the heap
Other processes must detach from this memory area before it can be removed。
其他进程必须先从该内存区域分离,然后才能删除该内存区域 -
If heap is no longer needed, remove it
Socket ID will become invalid and will not be reused.
套接字ID将无效,不会被重用
For more information, please refer to rte_malloc API documentation, specifically the rte_malloc_heap_* family of function calls.
有关更多信息,请参考rte_malloc API文档,特别是rte_malloc_heap_*系列函数调用。
- Using externally allocated memory without DPDK API’s
While using heap API’s is the recommended method of using externally allocated memory in DPDK, there are certain use cases where the overhead of DPDK heap API is undesirable - for example, when manual memory management is performed on an externally allocated area. To support use cases where externally allocated memory will not be used as part of normal DPDK workflow, there is also another set of API’s under the rte_extmem_* namespace.
虽然使用堆API是在DPDK中使用外部分配的内存的推荐方法,但是在某些用例中,DPDK堆API的开销是不需要的——例如,当对外部分配的区域执行手动内存管理时。为了支持某些使用外部分配的内存但是不作为正常DPDK流程的用例,rte_extmem_*命名空间下还有另一组API。
These API’s are (as their name implies) intended to allow registering or unregistering externally allocated memory to/from DPDK’s internal page table, to allow API’s like rte_virt2memseg etc. to work with externally allocated memory. Memory added this way will not be available for any regular DPDK allocators; DPDK will leave this memory for the user application to manage.这些API(顾名思义)允许向DPDK的内部页表注册或注销外部分配的内存,允许像rte_virt2memseg等API处理外部分配的内存。以这种方式添加的内存对任何常规DPDK分配器都不可用;DPDK将把这些内存留给用户应用程序管理。
The expected workflow is as follows: - Get a pointer to memory area
- Register memory within DPDK
- If IOVA table is not specified, IOVA addresses will be assumed to be unavailable
如果未指定IOVA表,则假定IOVA地址不可用 - Other processes must attach to the memory area before they can use it
其他进程在使用内存区域之前必须附加到该内存区域
- If IOVA table is not specified, IOVA addresses will be assumed to be unavailable
- Perform DMA mapping with rte_vfio_dma_map if needed
如果需要,使用rte_vfio_dma_map执行DMA映射 - Use the memory area in your application
在应用程序中使用内存区域 - If memory area is no longer needed, it can be unregistered
如果内存区域不再需要,可以取消注册- If the area was mapped for DMA, unmapping must be performed before unregistering memory
如果为DMA映射了该区域,则必须在取消注册内存之前执行取消映射 - Other processes must detach from the memory area before it can be unregistered
其他进程必须从内存区域中分离,然后才能取消注册
Since these externally allocated memory areas will not be managed by DPDK, it is therefore up to the user application to decide how to use them and what to do with them once they’re registered.
由于这些外部分配的内存区域不会由DPDK管理,因此,用户应用程序将决定如何使用它们,以及在它们注册之后如何处理它们。
- If the area was mapped for DMA, unmapping must be performed before unregistering memory
3.1.6. Per-lcore and Shared Variables(每个CPU核的共享变量)
备注:lcore refers to a logical execution unit of the processor, sometimes called a hardware thread.
lcore是处理器的逻辑执行单元,有时也称为硬件线程。
译者注:Software threads are threads of execution managed by the operating system.
Hardware threads are a feature of some processors that allow better utilisation of the processor under some circumstances. They may be exposed to/by the operating system as appearing to be additional cores (“hyperthreading”).
关于CPU CPU核 硬件线程:https://software.intel.com/en-us/blogs/2008/10/29/on-processors-cores-and-hardware-threads
关于超线程:http://www.cs.virginia.edu/~mc2zk/cs451/vol6iss1_art01.pdf
Shared variables are the default behavior. Per-lcore variables are implemented using Thread Local Storage (TLS) to provide per-thread local storage.
共享变量是默认行为。Per-lcore(可以认为是每个CPU核)变量使用线程本地存储(TLS)实现,以提供每个线程的本地存储。
3.1.7. Logs
A logging API is provided by EAL. By default, in a Linux application, logs are sent to syslog and also to the console. However, the log function can be overridden by the user to use a different logging mechanism.
EAL提供了一个日志API。默认情况下,在Linux应用程序中,日志被发送到syslog和控制台。但是,用户可以重写日志函数以使用不同的日志记录机制。
3.1.7.1. Trace and Debug Functions
There are some debug functions to dump the stack in glibc. The
rte_panic() function can voluntarily provoke a SIG_ABORT, which can trigger the generation of a core file, readable by gdb.
在glibc中有一些调试函数可以转储堆栈。rte_panic()函数可以自动触发SIG_ABORT,它可以触发生成一个gdb可读的核心文件。
3.1.8. CPU Feature Identification
The EAL can query the CPU at runtime (using the rte_cpu_get_features() function) to determine which CPU features are available.
EAL可以在运行时查询CPU(使用rte_cpu_get_features()函数),以确定哪些CPU特性可用。
3.1.9. User Space Interrupt Event
- User Space Interrupt and Alarm Handling in Host Thread
The EAL creates a host thread to poll the UIO device file descriptors to detect the interrupts. Callbacks can be registered or unregistered by the EAL functions for a specific interrupt event and are called in the host thread asynchronously. The EAL also allows timed callbacks to be used in the same way as for NIC interrupts.
EAL创建一个主机线程来轮询UIO设备文件描述符以检测中断。EAL函数可以为特定的中断事件注册或取消回调,并在宿主线程中异步调用回调。EAL还允许以与NIC中断相同的方式使用定时回调。
备注:In DPDK PMD, the only interrupts handled by the dedicated host thread are those for link status change (link up and link down notification) and for sudden device removal. 在DPDK
PMD中,由专用主机线程处理的唯一中断是用于更改链接状态(链接上和链接下通知)和突然删除设备的中断。
- RX Interrupt Event接收中断事件
The receive and transmit routines provided by each PMD don’t limit themselves to execute in polling thread mode. To ease the idle polling with tiny throughput, it’s useful to pause the polling and wait until the wake-up event happens. The RX interrupt is the first choice to be such kind of wake-up event, but probably won’t be the only one.
每个PMD提供的接收和传输例程不限制自己在轮询线程模式下执行。为了使空闲轮询具有较小的吞吐量,可以暂停轮询并等待唤醒事件的发生。RX中断是此类唤醒事件的首选,但可能不是唯一的。
EAL provides the event APIs for this event-driven thread mode. Taking linuxapp as an example, the implementation relies on epoll. Each thread can monitor an epoll instance in which all the wake-up events’ file descriptors are added. The event file descriptors are created and mapped to the interrupt vectors according to the UIO/VFIO spec. From bsdapp’s perspective, kqueue is the alternative way, but not implemented yet.
EAL为这种事件驱动的线程模式提供了事件api。以linuxapp为例,其实现依赖于epoll。每个线程都可以监视epoll实例,其中添加了所有唤醒事件的文件描述符。事件文件描述符是根据UIO/VFIO规范创建并映射到中断向量的。从bsdapp的角度来看,kqueue是另一种方式,但尚未实现。
EAL initializes the mapping between event file descriptors and interrupt vectors, while each device initializes the mapping between interrupt vectors and queues. In this way, EAL actually is unaware of the interrupt cause on the specific vector. The eth_dev driver takes responsibility to program the latter mapping.
EAL初始化文件描述符和中断向量之间的映射,而每个设备初始化中断向量和队列之间的映射。这样,EAL实际上并不知道特定向量上的中断原因。eth_dev驱动程序负责编程后一种映射。
备注:Per queue RX interrupt event is only allowed in VFIO which supports multiple MSI-X vector. In UIO, the RX interrupt together with other interrupt causes shares the same vector. In this case, when RX interrupt and LSC(link status change) interrupt are both enabled(intr_conf.lsc == 1 && intr_conf.rxq == 1), only the former is capable.
每个队列RX中断事件仅仅在VFIO中支持多个MSI-X向量。在UIO中,RX中断与其他中断共享相同的向量。在这种情况下,当RX中断和LSC(链接状态改变)中断都被启用(intr_conf.lsc == 1 && intr_conf.rxq == 1),只有前者生效。
译者注:MSI-X:PCIe总线的中断机制
The RX interrupt are controlled/enabled/disabled by ethdev APIs - ‘rte_eth_dev_rx_intr_*’. They return failure if the PMD hasn’t support them yet. The intr_conf.rxq flag is used to turn on the capability of RX interrupt per device.
RX中断由ethdev APIs - ’ rte_eth_dev_rx_intr_* '控制/启用/禁用。如果PMD还不支持他们,他们就会返回失败。intr_conf.rxq标志用于打开每个设备的RX中断功能。
- Device Removal Event
This event is triggered by a device being removed at a bus level. Its underlying resources may have been made unavailable (i.e. PCI mappings unmapped). The PMD must make sure that on such occurrence, the application can still safely use its callbacks.
此事件被总线级别的删除设备的动作触发。它的底层资源可能已经不可用(即PCI映射未映射)。PMD必须确保在出现这种情况时,应用程序仍然可以安全地使用其回调。
This event can be subscribed to in the same way one would subscribe to a link status change event. The execution context is thus the same, i.e. it is the dedicated interrupt host thread.
可以以订阅链接状态更改事件的方式订阅此事件。因此,执行上下文是相同的,即它是专用中断主机线程。
Considering this, it is likely that an application would want to close a device having emitted a Device Removal Event. In such case, calling rte_eth_dev_close() can trigger it to unregister its own Device Removal Event callback. Care must be taken not to close the device from the interrupt handler context. It is necessary to reschedule such closing operation.
考虑到这一点,应用程序可能希望在发出设备删除事件后关闭设备。在这种情况下,调用rte_eth_dev_close()可以触发它注销自己的设备删除事件回调。必须注意不要从中断处理程序上下文中关闭设备。有必要重新安排这种关闭操作。
3.1.10. Blacklisting(黑名单)
The EAL PCI device blacklist functionality can be used to mark certain NIC ports as blacklisted, so they are ignored by the DPDK. The ports to be blacklisted are identified using the PCIe* description (Domain:Bus:Device.Function).
EAL PCI设备黑名单功能可以将某些网卡端口标记为黑名单,因此被DPDK忽略。使用PCIe* description (Domain:Bus:Device.Function)标识要列入黑名单的端口。
3.1.11. Misc Functions(混合功能)
Locks and atomic operations are per-architecture (i686 and x86_64).
锁和原子操作是按体系结构进行的(i686和x86_64)。
3.1.12. IOVA Mode Configuration
Auto detection of the IOVA mode, based on probing the bus and IOMMU configuration, may not report the desired addressing mode when virtual devices that are not directly attached to the bus are present. To facilitate forcing the IOVA mode to a specific value the EAL command line option --iova-mode can be used to select either physical addressing(‘pa’) or virtual addressing(‘va’).
当没虚拟设备没有直接连接到当前的总线的时候,基于探测总线和IOMMU配置可以自动检测IOVA模式,可能不会报告所需的寻址模式时。
为了方便将IOVA模式强制设置为特定值,EAL命令行选项–iova-mode可用于选择物理寻址(“pa”)或虚拟寻址(“va”)。
3.2. Memory Segments and Memory Zones (memzone)(内存段和内存区)
The mapping of physical memory is provided by this feature in the EAL. As physical memory can have gaps, the memory is described in a table of descriptors, and each descriptor (called rte_memseg ) describes a physical page.
物理内存的映射是由EAL提供的。由于物理内存可能有间隙,内存在描述符表中进行描述,每个描述符(称为rte_memseg)描述一个物理页面。
On top of this, the memzone allocator’s role is to reserve contiguous portions of physical memory. These zones are identified by a unique name when the memory is reserved.
在此之上,memzone分配器的作用是预留物理内存的连续部分。当内存被预留时,这些区域由唯一的名称标识。
The rte_memzone descriptors are also located in the configuration structure. This structure is accessed using rte_eal_get_configuration(). The lookup (by name) of a memory zone returns a descriptor containing the physical address of the memory zone.
rte_memzone描述符也位于配置结构中。使用rte_eal_get_configuration()访问该结构。内存区域的查找(按名称)返回一个描述符,其中包含内存区域的物理地址。
Memory zones can be reserved with specific start address alignment by supplying the align parameter (by default, they are aligned to cache line size). The alignment value should be a power of two and not less than the cache line size (64 bytes). Memory zones can also be reserved from either 2 MB or 1 GB hugepages, provided that both are available on the system.
通过提供align参数,可以使用特定的起始地址对齐来保留内存区域(默认情况下,它们与缓存行大小对齐)。对齐值应为2的幂,且不小于缓存行大小(64字节)。内存区域也可以从2 MB或1 GB的Hugepages中保留,前提是这两个区域在系统上都可用。
Both memsegs and memzones are stored using rte_fbarray structures. Please refer to DPDK API Reference for more information.
Memsegs和MemZone都使用rte_FBarray结构存储。有关详细信息,请参阅DPDK API参考。
3.3. Multiple pthread
DPDK usually pins one pthread per core to avoid the overhead of task switching. This allows for significant performance gains, but lacks flexibility and is not always efficient.
DPDK通常为每个内核固定一个pthread,以避免任务切换的开销。这可以显著提高性能,但缺乏灵活性,而且并不总是有效的。
Power management helps to improve the CPU efficiency by limiting the CPU runtime frequency. However, alternately it is possible to utilize the idle cycles available to take advantage of the full capability of the CPU.
电源管理通过限制CPU运行时频率有助于提高CPU效率。但是,也可以利用空闲周期来充分利用CPU的全部功能。
By taking advantage of cgroup, the CPU utilization quota can be simply assigned. This gives another way to improve the CPU efficiency, however, there is a prerequisite; DPDK must handle the context switching between multiple pthreads per core.
利用cgroup,可以简单地分配CPU利用率配额。这提供了另一种提高CPU效率的方法,但是,这是一个先决条件;DPDK必须处理每个核心多个pthread之间的上下文切换。
For further flexibility, it is useful to set pthread affinity not only to a CPU but to a CPU set.
为了进一步的灵活性,设置pthread亲合性不仅对CPU有用,而且对CPU集也有用。
3.3.1. EAL pthread and lcore Affinity
The term “lcore” refers to an EAL thread, which is really a Linux/FreeBSD pthread. “EAL pthreads” are created and managed by EAL and execute the tasks issued by remote_launch. In each EAL pthread, there is a TLS (Thread Local Storage) called _lcore_id for unique identification. As EAL pthreads usually bind 1:1 to the physical CPU, the _lcore_id is typically equal to the CPU ID.
术语“lcore”指的是EAL线程,它实际上是一个Linux/FreeBSD pthread。“EAL pthreads”由EAL创建和管理,并执行remote_launch发出的任务。在每个EAL pthread中,都有一个名为_lcore_id的TLS(线程本地存储)用于惟一标识。由于EAL pthreads通常将1:1绑定到物理CPU,所以_lcore_id通常等于CPU ID。
When using multiple pthreads, however, the binding is no longer always 1:1 between an EAL pthread and a specified physical CPU. The EAL pthread may have affinity to a CPU set, and as such the _lcore_id will not be the same as the CPU ID. For this reason, there is an EAL long option ‘–lcores’ defined to assign the CPU affinity of lcores. For a specified lcore ID or ID group, the option allows setting the CPU set for that EAL pthread.
然而,在使用多个pthread时,EAL pthread和指定的物理CPU之间的绑定不再总是1:1。EAL pthread可能与一个CPU集具有关联性,因此,lcore id将与CPU id不同。因此,定义了一个EAL long选项“–lcores”,以分配lcores的CPU亲和力。对于指定的lcore id或id组,该选项允许为该eal pthread设置CPU集。
The format pattern:
–lcores=’<lcore_set>[@cpu_set][,<lcore_set>[@cpu_set],…]’
‘lcore_set’ and ‘cpu_set’ can be a single number, range or a group.
a number is a “digit([0-9]+)”;
a range is “-”;
a group is “(<number|range>[,<number|range>,…])”.
If a ‘@cpu_set’ value is not supplied, the value of ‘cpu_set’ will default to the value of ‘lcore_set’.
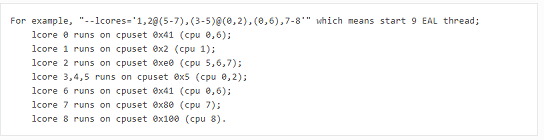
Using this option, for each given lcore ID, the associated CPUs can be assigned. It’s also compatible with the pattern of corelist(‘-l’) option.
使用此选项,可以为每个给定的LCore ID分配相关的CPU。它还与corelist(“-l”)选项的模式兼容。
3.3.2. non-EAL pthread support
It is possible to use the DPDK execution context with any user pthread (aka. Non-EAL pthreads). In a non-EAL pthread, the _lcore_id is always LCORE_ID_ANY which identifies that it is not an EAL thread with a valid, unique, _lcore_id. Some libraries will use an alternative unique ID (e.g. TID), some will not be impacted at all, and some will work but with limitations (e.g. timer and mempool libraries).
可以将DPDK执行上下文与任何用户pthread(也称为非EAL pthread)一起使用。在非EAL pthread中,_lcore_id始终为LCORE_ID_ANY,它标识它不是具有有效唯一的_lcore_id的EAL线程。 有些库将使用备用唯一ID(例如TID),有些库根本不受影响,有些库可以使用但有限制(例如计时器和mempool库)。
All these impacts are mentioned in Known Issues section.
所有这些影响都在“已知问题”部分中提到。
3.3.3. Public Thread API
There are two public APIs rte_thread_set_affinity() and rte_thread_get_affinity() introduced for threads. When they’re used in any pthread context, the Thread Local Storage(TLS) will be set/get.
为线程引入了两个公共API rte_thread_set_affinity()和rte_thread_get_affinity()。当它们在任何pthread上下文中使用时,将设置/获取线程本地存储(TLS)。
Those TLS include _cpuset and _socket_id:
- _cpuset stores the CPUs bitmap to which the pthread is affinitized.
_cpuset存储与pthread密切相关的cpu位图。 - _socket_id stores the NUMA node of the CPU set. If the CPUs in CPU set belong to different NUMA node, the _socket_id will be set to SOCKET_ID_ANY.
_socket_id存储CPU集的NUMA节点。 如果CPU集中的CPU属于不同的NUMA节点,则_socket_id将设置为SOCKET_ID_ANY。
3.3.4. Known Issues
-
rte_mempool
The rte_mempool uses a per-lcore cache inside the mempool. For non-EAL pthreads, rte_lcore_id() will not return a valid number. So for now, when rte_mempool is used with non-EAL pthreads, the put/get operations will bypass the default mempool cache and there is a performance penalty because of this bypass. Only user-owned external caches can be used in a non-EAL context in conjunction with rte_mempool_generic_put() and rte_mempool_generic_get() that accept an explicit cache parameter.
rte_mempool在mempool中使用每个lcore缓存。对于非eal pthreads, rte_lcore_id()将不返回有效的数字。所以现在,当rte_mempool与非EAL pthreads一起使用时,put / get操作将绕过默认的mempool缓存,并且由于这种旁路而存在性能损失。只有用户拥有外部缓存时才能在非EAL上下文中与rte_mempool_generic_put()和rte_mempool_generic_get()一起使用,并接受显式缓存参数。 -
rte_ring
rte_ring supports multi-producer enqueue and multi-consumer dequeue. However, it is non-preemptive, this has a knock on effect of making rte_mempool non-preemptable.
RTE-Ring支持多生产者排队和多消费者排队。但是,它是不可抢占的,这有一个使RTE内存池不可抢占的连锁反应。
备注:The “non-preemptive” constraint means:(“非抢占式”约束是指) -
a pthread doing multi-producers enqueues on a given ring must not be preempted by another pthread doing a multi-producer enqueue on the same ring.
在给定环上执行多个生产者排队的pthread不能被在同一环上执行多个生产者排队的另一个pthread抢先。 -
a pthread doing multi-consumers dequeues on a given ring must not be preempted by another pthread doing a multi-consumer dequeue on the same ring.
在给定环上执行多使用者出列的pthread不能被在同一环上执行多使用者出列的另一个pthread抢先。
Bypassing this constraint may cause the 2nd pthread to spin until the 1st one is scheduled again. Moreover, if the 1st pthread is preempted by a context that has an higher priority, it may even cause a dead lock.
绕过此约束可能会导致第二个pthread旋转,直到第一个pthread再次被调度。此外,如果第一个pthread被具有更高优先级的上下文抢先,它甚至可能导致死锁。
This means, use cases involving preemptible pthreads should consider using rte_ring carefully.
这意味着,涉及可抢占pthreads的用例应该仔细考虑使用rte-ring。
1 It CAN be used for preemptible single-producer and single-consumer use case.
它可以用于可抢占的单生产者和单消费者用例。
2 It CAN be used for non-preemptible multi-producer and preemptible single-consumer use case.
它可以用于不可抢占的多生产者和可抢占的单消费者用例。
3 It CAN be used for preemptible single-producer and non-preemptible multi-consumer use case.
它可以用于可抢占的单生产者和不可抢占的多消费者用例。
4 It MAY be used by preemptible multi-producer and/or preemptible multi-consumer pthreads whose scheduling policy are all SCHED_OTHER(cfs), SCHED_IDLE or SCHED_BATCH. User SHOULD be aware of the performance penalty before using it.
它可以由可抢占的多生产商和/或可抢占的多用户pthreads使用,其调度策略都是sched_other(cfs)、sched_idle或sched_batch。用户在使用前应注意性能惩罚。
5 多生产商/消费者pthreads不得使用它,其调度策略为sched_fifo或sched_rr。
多生产商/消费者pthreads不得使用它,其调度策略为sched_fifo或sched_rr。 -
rte_timer
Running rte_timer_manage() on a non-EAL pthread is not allowed. However, resetting/stopping the timer from a non-EAL pthread is allowed.
不允许在非eal pthread上运行rte_timer_manage()。但是,允许从非EAL pthread重置/停止计时器。 -
rte_log
In non-EAL pthreads, there is no per thread loglevel and logtype, global loglevels are used.
在非eal pthreads中,每个线程不存在个自的日志级别和日志类型,使用全局日志级别。 -
misc
The debug statistics of rte_ring, rte_mempool and rte_timer are not supported in a non-EAL pthread.
非eal pthread不支持rte_ring、rte_mempool和rte_timer的调试统计信息。
3.3.5. cgroup control
The following is a simple example of cgroup control usage, there are two pthreads(t0 and t1) doing packet I/O on the same core ($CPU). We expect only 50% of CPU spend on packet IO.
下面是使用cgroup control的一个简单示例,有两个pthread (t0和t1)在同一个内核(CPU)上执行包I/O。我们期望在包IO上只花费50%的CPU。
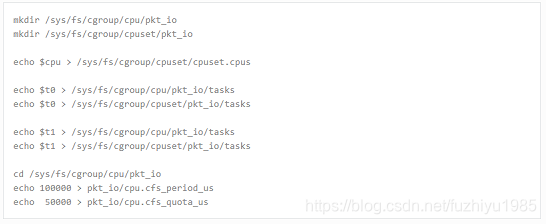
译者注:Cgroups是control groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO等等)的机制。
3.4. Malloc
The EAL provides a malloc API to allocate any-sized memory.
EAL提供了一个malloc API来分配任意大小的内存。
The objective of this API is to provide malloc-like functions to allow allocation from hugepage memory and to facilitate application porting. The DPDK API Reference manual describes the available functions.
此API的目标是提供类似malloc的函数,以允许从大页面内存进行分配并便于应用程序移植。DPDK API参考手册介绍了可用的功能。
Typically, these kinds of allocations should not be done in data plane processing because they are slower than pool-based allocation and make use of locks within the allocation and free paths. However, they can be used in configuration code.
通常,这些类型的分配不应该在数据平面处理中完成,因为它们比基于池的分配慢,并且在分配和自由路径中使用锁。但是,可以在配置代码中使用它们。
Refer to the rte_malloc() function description in the DPDK API Reference manual for more information.
有关更多信息,请参阅DPDK API参考手册中的rte_malloc()函数描述。
3.4.1. Cookies
When CONFIG_RTE_MALLOC_DEBUG is enabled, the allocated memory contains overwrite protection fields to help identify buffer overflows.
启用CONFIG_RTE_MALLOC_DEBUG时,分配的内存包含覆盖保护字段,以帮助识别缓冲区溢出。
3.4.2. Alignment and NUMA Constraints(对齐和NUMA约束)
The rte_malloc() takes an align argument that can be used to request a memory area that is aligned on a multiple of this value (which must be a power of two).
rte_malloc()接受一个align参数,该参数可用于请求与该值的倍数(必须是2的幂)对齐的内存区域
On systems with NUMA support, a call to the rte_malloc() function will return memory that has been allocated on the NUMA socket of the core which made the call. A set of APIs is also provided, to allow memory to be explicitly allocated on a NUMA socket directly, or by allocated on the NUMA socket where another core is located, in the case where the memory is to be used by a logical core other than on the one doing the memory allocation.
在支持numa的系统上,对rte_malloc()函数的调用将返回在调用核心的numa套接字上分配的内存。还提供了一组API,允许直接在一个NUMA套接字上显式分配内存,或者通过在另一个内核所在的NUMA套接字上分配内存,在这种情况下,内存将由一个逻辑内核使用,而不是由一个进行内存分配的内核使用。
3.4.3. Use Cases
This API is meant to be used by an application that requires malloc-like functions at initialization time.
此API用于初始化时需要类似malloc函数的应用程序。
For allocating/freeing data at runtime, in the fast-path of an application, the memory pool library should be used instead.
为了在运行时分配/释放数据,应在应用程序的快速路径中使用内存池库。
3.4.4. Internal Implementation
3.4.4.1. Data Structures
There are two data structure types used internally in the malloc library:
- struct malloc_heap - used to track free space on a per-socket basis
struct malloc_heap - 用于基于每个套接字跟踪可用空间 - struct malloc_elem - the basic element of allocation and free-space
tracking inside the library.
struct malloc_elem - 库内分配和自由空间跟踪的基本元素。
3.4.4.1.1. Structure: malloc_heap
The malloc_heap structure is used to manage free space on a per-socket basis. Internally, there is one heap structure per NUMA node, which allows us to allocate memory to a thread based on the NUMA node on which this thread runs. While this does not guarantee that the memory will be used on that NUMA node, it is no worse than a scheme where the memory is always allocated on a fixed or random node.
malloc_heap结构用于在每个套接字的基础上管理空闲空间。在内部,每个numa节点有一个堆结构,它允许我们根据运行该线程的numa节点为线程分配内存。虽然这不能保证内存将在该NUMA节点上使用,但它并不比总是在固定或随机节点上分配内存的方案差。
he key fields of the heap structure and their function are described below (see also diagram above):
堆结构的关键字段及其功能如下(参见上图):
- lock - the lock field is needed to synchronize access to the heap.
Given that the free space in the heap is tracked using a linked list,
we need a lock to prevent two threads manipulating the list at the
same time.
需要锁定字段来同步对堆的访问。 鉴于使用链表跟踪堆中的可用空间,我们需要一个锁以防止两个线程同时操作列表。 - free_head - this points to the first element in the list of free
nodes for this malloc heap.
free_head - 这指向此malloc堆的空闲节点列表中的第一个元素。 - first - this points to the first element in the heap.
这指向堆中的第一个元素。 - last - this points to the last element in the heap.
这指向堆中的最后一个元素。
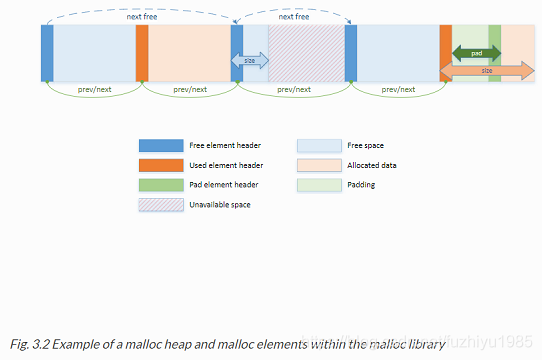
3.4.4.1.2. Structure: malloc_elem
The malloc_elem structure is used as a generic header structure for various blocks of memory. It is used in two different ways - all shown in the diagram above:
malloc-elem结构用作各种内存块的通用头结构。它有两种不同的使用方式-如上图所示:
1 As a header on a block of free or allocated memory - normal case
作为可用内存或已分配内存块上的头-通常情况
2 As a padding header inside a block of memory
作为内存块中的填充头
The most important fields in the structure and how they are used are described below.
结构中最重要的字段及其使用方式如下所述。
Malloc heap is a doubly-linked list, where each element keeps track of its previous and next elements. Due to the fact that hugepage memory can come and go, neighbouring malloc elements may not necessarily be adjacent in memory. Also, since a malloc element may span multiple pages, its contents may not necessarily be IOVA-contiguous either - each malloc element is only guaranteed to be virtually contiguous.
Malloc heap是一个双链表,其中每个元素跟踪它的上一个和下一个元素。由于巨大的页面内存可以创建和删除,所以相邻的malloc元素可能不一定在内存中相邻。此外,由于malloc元素可能跨越多个页面,因此其内容可能不一定是IOVA连续的 - 每个malloc元素仅保证几乎是连续的。
备注:If the usage of a particular field in one of the above three usages is not described, the field can be assumed to have an undefined value in that situation, for example, for padding headers only the “state” and “pad” fields have valid values.
如果在上述三种用法之一中没有描述特定字段的用法,则可以假定该字段在这种情况下具有未定义的值,例如,对于填充头,只有“state”和“pad”字段具有有效值。
- heap - this pointer is a reference back to the heap structure from
which this block was allocated. It is used for normal memory blocks
when they are being freed, to add the newly-freed block to the heap’s
free-list.
该指针是对分配此块的堆结构的引用。当正常内存块被释放时,它用于将新释放的块添加到堆的空闲列表中。 - prev - this pointer points to previous header element/block in
memory. When freeing a block, this pointer is used to reference the
previous block to check if that block is also free. If so, and the
two blocks are immediately adjacent to each other, then the two free
blocks are merged to form a single larger block.
此指针指向内存中以前的头元素/块。释放块时,此指针用于引用上一个块,以检查该块是否也可用。释放块时,此指针用于引用上一个块,以检查该块是否也可用。如果是这样,两个块立即相邻,那么两个空闲块合并成一个更大的块。 - next - this pointer points to next header element/block in memory.
When freeing a block, this pointer is used to reference the next
block to check if that block is also free. If so, and the two blocks
are immediately adjacent to each other, then the two free blocks are
merged to form a single larger block.
此指针指向内存中的下一个头元素/块。释放块时,此指针用于引用下一个块,以检查该块是否也可用。如果是这样,两个块立即相邻,那么两个空闲块合并成一个更大的块。 - free_list - this is a structure pointing to previous and next
elements in this heap’s free list. It is only used in normal memory
blocks; on malloc() to find a suitable free block to allocate and on
free() to add the newly freed element to the free-list.
这是指向堆空闲列表中前一个和下一个元素的结构。仅在正常内存块中使用;在malloc()上查找要分配的合适的空闲块,在free()上将新释放的元素添加到空闲列表中。 - state - This field can have one of three values: FREE, BUSY or PAD.
The former two are to indicate the allocation state of a normal
memory block and the latter is to indicate that the element structure
is a dummy structure at the end of the start-of-block padding, i.e.
where the start of the data within a block is not at the start of the
block itself, due to alignment constraints. In that case, the pad
header is used to locate the actual malloc element header for the
block.
此字段可以有三个值之一:空闲、忙碌或填充。前两个用于指示正常内存块的分配状态,后者用于指示元素结构在块起始填充结束时是虚拟结构,即块内数据的开始位置 由于对齐限制,不在块本身的开头。在这种情况下,pad头用于定位块的实际malloc元素头。 - pad - this holds the length of the padding present at the start of
the block. In the case of a normal block header, it is added to the
address of the end of the header to give the address of the start of
the data area, i.e. the value passed back to the application on a
malloc. Within a dummy header inside the padding, this same value is stored, and is subtracted from the address of the dummy header to yield the address of the actual block header.
将保留块开始处存在的填充长度。在普通块头的情况下,将其添加到头的末尾的地址以给出数据区的开始的地址,即在malloc上传递回应用程序的值。在填充内部的虚拟头中,存储该相同值,并从虚头的地址中减去该值以产生实际块头的地址。 - size - the size of the data block, including the header itself.
数据块的大小,包括头本身。
3.4.4.2. Memory Allocation
On EAL initialization, all preallocated memory segments are setup as part of the malloc heap. This setup involves placing an element header with FREE at the start of each virtually contiguous segment of memory. The FREE element is then added to the free_list for the malloc heap.
在EAL初始化时,所有预分配的内存段都设置为malloc堆的一部分。这个设置包括在每个几乎连续的内存段的开头放置一个带有free的元素头。然后将free元素添加到malloc堆的free_列表中。
This setup also happens whenever memory is allocated at runtime (if supported), in which case newly allocated pages are also added to the heap, merging with any adjacent free segments if there are any.
每当在运行时分配内存(如果支持)时,也会发生这种设置,在这种情况下,新分配的页面也会添加到堆中,如果存在任何相邻的空闲段,则会与之合并。
When an application makes a call to a malloc-like function, the malloc function will first index the lcore_config structure for the calling thread, and determine the NUMA node of that thread. The NUMA node is used to index the array of malloc_heap structures which is passed as a parameter to the heap_alloc() function, along with the requested size, type, alignment and boundary parameters.
When an application makes a call to a malloc-like function, the malloc function will first index the lcore_config structure for the calling thread, and determine the NUMA node of that thread. The NUMA node is used to index the array of malloc_heap structures which is passed as a parameter to the heap_alloc() function, along with the requested size, type, alignment and boundary parameters.
When an application makes a call to a malloc-like function, the malloc function will first index the lcore_config structure for the calling thread, and determine the NUMA node of that thread. The NUMA node is used to index the array of malloc_heap structures which is passed as a parameter to the heap_alloc() function, along with the requested size, type, alignment and boundary parameters.
当应用程序调用类似malloc的函数时,malloc函数将首先索引调用线程的lcore-config结构,并确定该线程的numa节点。numa节点用于索引作为参数传递给heap_alloc()函数的malloc_堆结构数组,以及请求的大小、类型、对齐方式和边界参数。
The heap_alloc() function will scan the free_list of the heap, and attempt to find a free block suitable for storing data of the requested size, with the requested alignment and boundary constraints.
When a suitable free element has been identified, the pointer to be returned to the user is calculated. The cache-line of memory immediately preceding this pointer is filled with a struct malloc_elem header. Because of alignment and boundary constraints, there could be free space at the start and/or end of the element, resulting in the following behavior:
当识别出要释放的元素时,计算要返回给用户的指针。 紧接在该指针之前的内存的高速缓存行用struct malloc_elem头填充。 由于对齐和边界约束,元素的开头和/或结尾可能有释放的空间,导致以下行为:
- Check for trailing space. If the trailing space is big enough,
i.e. > 128 bytes, then the free element is split. If it is not, then
we just ignore it (wasted space).
检查后部的空格。 如果后部的空间足够大,即> 128字节,则要释放的元素被分割。 如果不是,那么我们就忽略它(浪费的空间) - Check for space at the start of the element. If the space at the start is small, i.e. <=128 bytes, then a pad header is used, and the
remaining space is wasted. If, however, the remaining space is
greater, then the free element is split.
检查元素开头的空间。 如果起始处的空间很小,即<= 128字节,则使用填充头部,剩余空间被浪费。 但是,如果剩余空间更大,则要释放的元素被分割
The advantage of allocating the memory from the end of the existing element is that no adjustment of the free list needs to take place - the existing element on the free list just has its size value adjusted, and the next/previous elements have their “prev”/”next” pointers redirected to the newly created element.
从现有元素的末尾分配内存的优点是不需要调整空闲列表 - 空闲列表中的现有元素只调整其大小值,而下一个/前一个元素具有“prev” “/”next“指针重定向到新创建的元素。
In case when there is not enough memory in the heap to satisfy allocation request, EAL will attempt to allocate more memory from the system (if supported) and, following successful allocation, will retry reserving the memory again. In a multiprocessing scenario, all primary and secondary processes will synchronize their memory maps to ensure that any valid pointer to DPDK memory is guaranteed to be valid at all times in all currently running processes.
如果堆中没有足够的内存来满足分配请求,EAL将尝试从系统分配更多内存(如果支持),并且在成功分配后,将重试再次保留内存。 在多处理方案中,所有主进程和辅助进程将同步其内存映射,以确保任何有效的DPDK内存指针在所有当前正在运行的进程中始终保证有效。
Failure to synchronize memory maps in one of the processes will cause allocation to fail, even though some of the processes may have allocated the memory successfully. The memory is not added to the malloc heap unless primary process has ensured that all other processes have mapped this memory successfully.
无法在其中一个进程中同步内存映射将导致分配失败,即使某些进程可能已成功分配内存。 除非主进程确保所有其他进程已成功映射此内存,否则不会将内存添加到malloc堆中。
Any successful allocation event will trigger a callback, for which user applications and other DPDK subsystems can register. Additionally, validation callbacks will be triggered before allocation if the newly allocated memory will exceed threshold set by the user, giving a chance to allow or deny allocation.
任何成功的分配事件都将触发回调,用户应用程序和其他DPDK子系统可以为此注册。此外,如果新分配的内存将超过用户设置的阈值,则在分配之前将触发验证回调,从而提供允许或拒绝分配的机会。
备注:Any allocation of new pages has to go through primary process. If the primary process is not active, no memory will be allocated even if it was theoretically possible to do so. This is because primary’s process map acts as an authority on what should or should not be mapped, while each secondary process has its own, local memory map.Secondary processes do not update the shared memory map, they only copy its contents to their local memory map.
任何新页面的分配都必须经过主进程。 如果主进程未激活,即使理论上可以这样做,也不会分配任何内存。 这是因为主进程的映射充当应该或不应映射的权限,而每个辅助进程都有自己的本地内存映射。 辅助进程不更新共享内存映射,它们只将其内容复制到本地内存映射。
3.4.4.3. Freeing Memory
To free an area of memory, the pointer to the start of the data area is passed to the free function. The size of the malloc_elem structure is subtracted from this pointer to get the element header for the block. If this header is of type PAD then the pad length is further subtracted from the pointer to get the proper element header for the entire block.
要释放一个内存区域,指向数据区域开头的指针将传递给free函数。从这个指针中减去malloc元素结构的大小,得到块的元素头。如果这个头是pad类型,那么pad长度将从指针中进一步减去,以得到整个块的正确元素头。
To free an area of memory, the pointer to the start of the data area is passed to the free function. The size of the malloc_elem structure is subtracted from this pointer to get the element header for the block. If this header is of type PAD then the pad length is further subtracted from the pointer to get the proper element header for the entire block.
从这个元素头中,我们得到指向分配块的堆以及必须释放块的位置的指针,以及指向前一个和下一个元素的指针。然后检查这些下一个和上一个元素,以查看它们是否也是空闲的,并且是否与当前元素相邻;如果是,则将它们与当前元素合并。这意味着我们永远不能让两个空闲内存块彼此相邻,因为它们总是合并到一个块中。
If deallocating pages at runtime is supported, and the free element encloses one or more pages, those pages can be deallocated and be removed from the heap. If DPDK was started with command-line parameters for preallocating memory (-m or --socket-mem), then those pages that were allocated at startup will not be deallocated.
如果支持在运行时释放页面,并且free元素包含一个或多个页面,则可以释放这些页面并将其从堆中删除。如果DPDK是用预分配内存的命令行参数(-m或–socket mem)启动的,那么在启动时分配的那些页将不会被释放。
Any successful deallocation event will trigger a callback, for which user applications and other DPDK subsystems can register.
任何成功的释放事件都将触发回调,用户应用程序和其他DPDK子系统可以为此注册。

















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









