







原始SQL如下:
- select * from (
- select t.zxid,t.gh,t.xm,t.bm,t.fzjgdm,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH) slzl,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='0') 无评价,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='1') 满意,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='2') 较满意,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='3') 一般,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='4') 较不满意,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='5') 不满意
- from xxx t
- WHERE t.yxbz='Y'
- )where slzl<>0 ;
不用看执行计划就知道,表test_v会被扫描多次,所以这个SQL必须改写。如何改写这个SQL呢?请看下面分析:
首先,这个SQL语句是拼出来的,我们可以把复杂的问题简单化,所以我先看这个SQL:
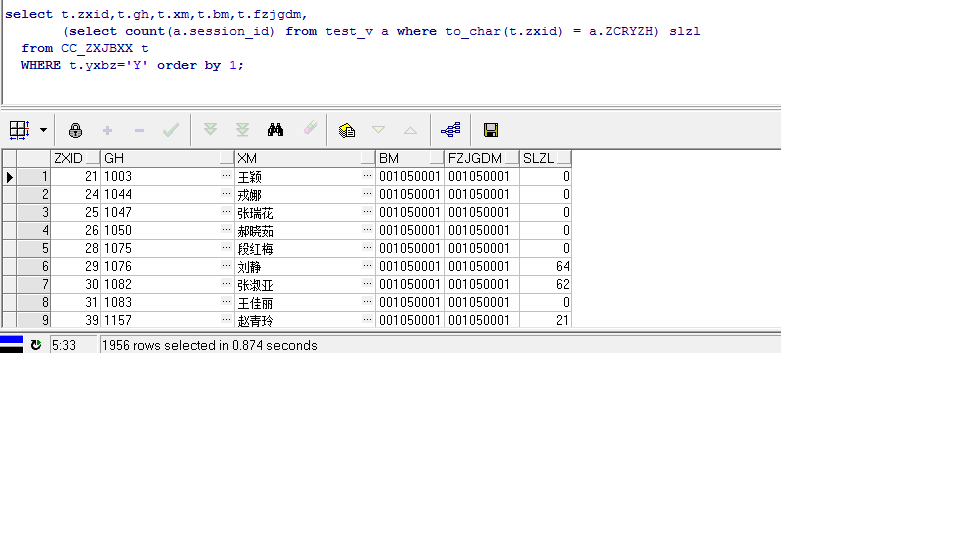
- select t.zxid,t.gh,t.xm,t.bm,t.fzjgdm,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH) slzl
- from CC_ZXJBXX t
- WHERE t.yxbz='Y';
执行计划如下:
- SQL> select t.zxid,t.gh,t.xm,t.bm,t.fzjgdm,
- 2 (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH) slzl
- 3 from CC_ZXJBXX t
- 4 WHERE t.yxbz='Y';
- 已选择1956行。
- 已用时间: 00: 00: 00.37
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 4286326665
- --------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- --------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1956 | 105K| 11 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 22 | | |
- |* 2 | TABLE ACCESS FULL| TEST_V | 4 | 88 | 5 (0)| 00:00:01 |
- |* 3 | TABLE ACCESS FULL | CC_ZXJBXX | 1956 | 105K| 11 (0)| 00:00:01 |
- --------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("A"."ZCRYZH"=TO_CHAR(:B1))
- 3 - filter("T"."YXBZ"='Y')
上面的SQL语句会返回1956行,根据执行计划可以看到它进行的是filter操作,讲上面的SQL改写,初步改写如下:
- SQL> select t.zxid,t.gh,t.xm,t.bm,t.fzjgdm,count(*) from
- 2 CC_ZXJBXX t,test_v a where to_char(t.zxid) = a.ZCRYZH
- 3 and t.yxbz='Y' group by t.zxid,t.gh,t.xm,t.bm,t.fzjgdm;
- 已选择20行。
- 已用时间: 00: 00: 00.03
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 2833546679
- ---------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ---------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 32157 | 2418K| 22 (28)| 00:00:01 |
- | 1 | HASH GROUP BY | | 32157 | 2418K| 22 (28)| 00:00:01 |
- |* 2 | HASH JOIN | | 32157 | 2418K| 17 (6)| 00:00:01 |
- | 3 | TABLE ACCESS FULL| TEST_V | 411 | 9042 | 5 (0)| 00:00:01 |
- |* 4 | TABLE ACCESS FULL| CC_ZXJBXX | 1956 | 105K| 11 (0)| 00:00:01 |
- ---------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("A"."ZCRYZH"=TO_CHAR("T"."ZXID"))
- 4 - filter("T"."YXBZ"='Y')
改写之后,SQL只返回了20条数据,但是原始SQL要返回1956条数据,问题出在哪里呢? 问题在于,第一个SQL是filter,它是过滤,并且是count过滤
而第二个SQL是等值jion,第一个SQL里面的count 不管你过滤成功与否,都会返回数据,过滤失败,count=0 即可,所以对第二个SQL应该用 left join 于是SQL 更改如下:
- SQL> select t.zxid,t.gh,t.xm,t.bm,t.fzjgdm,count(*) from
- 2 CC_ZXJBXX t,test_v a where to_char(t.zxid) = a.ZCRYZH(+)
- 3 and t.yxbz='Y' group by t.zxid,t.gh,t.xm,t.bm,t.fzjgdm;
- 已选择1956行。
- 已用时间: 00: 00: 00.12
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3281235561
- ------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 32157 | 2418K| 22 (28)| 00:00:01 |
- | 1 | HASH GROUP BY | | 32157 | 2418K| 22 (28)| 00:00:01 |
- |* 2 | HASH JOIN RIGHT OUTER| | 32157 | 2418K| 17 (6)| 00:00:01 |
- | 3 | TABLE ACCESS FULL | TEST_V | 411 | 9042 | 5 (0)| 00:00:01 |
- |* 4 | TABLE ACCESS FULL | CC_ZXJBXX | 1956 | 105K| 11 (0)| 00:00:01 |
- ------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("A"."ZCRYZH"(+)=TO_CHAR("T"."ZXID"))
- 4 - filter("T"."YXBZ"='Y')
这样改写之后,返回记录条数是对了,但是SQL逻辑有点点改变,第一个SQL是过滤的,count()如果不匹配会返回0,但是第二个SQL是 join的,如果不匹配,会返回1
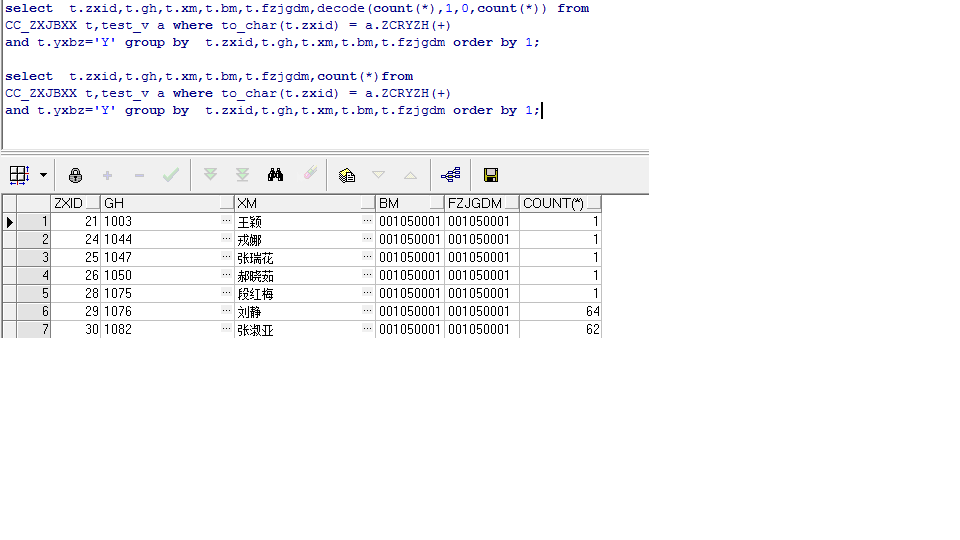
所以SQL需要改写如下:
- select t.zxid,t.gh,t.xm,t.bm,t.fzjgdm,decode(count(*),1,0,count(*)) from
- CC_ZXJBXX t,test_v a where to_char(t.zxid) = a.ZCRYZH(+)
- and t.yxbz='Y' group by t.zxid,t.gh,t.xm,t.bm,t.fzjgdm order by 1;
改写完了一个,后面的就简单了,所以整体的SQL可以改写如下:
- select t.zxid,
- t.gh,
- t.xm,
- t.bm,
- t.fzjgdm,
- decode(count(*), 1, 0, count(*)),
- SUM(DECODE(A.MYD, '0', 1, 0)) 无评价,
- SUM(DECODE(A.MYD, '1', 1, 0)) 满意,
- SUM(DECODE(A.MYD, '2', 1, 0)) 较满意,
- SUM(DECODE(A.MYD, '3', 1, 0)) 一般,
- SUM(DECODE(A.MYD, '4', 1, 0)) 较不满意,
- SUM(DECODE(A.MYD, '5', 1, 0)) 不满意
- from CC_ZXJBXX t, test_v a
- where to_char(t.zxid) = a.ZCRYZH(+)
- and t.yxbz = 'Y'
- group by t.zxid, t.gh, t.xm, t.bm, t.fzjgdm ;
上面的SQL等价于
- select t.zxid,t.gh,t.xm,t.bm,t.fzjgdm,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH) slzl,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='0') 无评价,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='1') 满意,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='2') 较满意,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='3') 一般,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='4') 较不满意,
- (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='5') 不满意
- from xxx t
- WHERE t.yxbz='Y';
由于原始SQL要去掉 slzl <>0 所以再包装一下
- select * from
- (select t.zxid,
- t.gh,
- t.xm,
- t.bm,
- t.fzjgdm,
- decode(count(*), 1, 0, count(*))slzl,
- SUM(DECODE(A.MYD, '0', 1, 0)) 无评价,
- SUM(DECODE(A.MYD, '1', 1, 0)) 满意,
- SUM(DECODE(A.MYD, '2', 1, 0)) 较满意,
- SUM(DECODE(A.MYD, '3', 1, 0)) 一般,
- SUM(DECODE(A.MYD, '4', 1, 0)) 较不满意,
- SUM(DECODE(A.MYD, '5', 1, 0)) 不满意
- from CC_ZXJBXX t, test_v a
- where to_char(t.zxid) = a.ZCRYZH(+)
- and t.yxbz = 'Y'
- group by t.zxid, t.gh, t.xm, t.bm, t.fzjgdm
- ) where slzl<>0;
原始SQL的执行计划 以及 更改后的执行计划对比:
- SQL> select * from (
- 2 select t.zxid,t.gh,t.xm,t.bm,t.fzjgdm,
- 3 (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH) slzl,
- 4 (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='0') 无评价,
- 5 (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='1') 满意,
- 6 (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='2') 较满意,
- 7 (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='3') 一般,
- 8 (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='4') 较不满意,
- 9 (select count(a.session_id) from test_v a where to_char(t.zxid) = a.ZCRYZH and a.myd='5') 不满意
- 10 from xxx t
- 11 WHERE t.yxbz='Y'
- 12 ) where slzl<>0;
- 已选择20行。
- 已用时间: 00: 00: 00.28
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 2669170809
- ------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1956 | 76284 | 17 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 4 | | |
- |* 2 | TABLE ACCESS FULL | TEST_V | 16 | 64 | 5 (0)| 00:00:01 |
- | 3 | SORT AGGREGATE | | 1 | 6 | | |
- |* 4 | TABLE ACCESS FULL | TEST_V | 9 | 54 | 5 (0)| 00:00:01 |
- | 5 | SORT AGGREGATE | | 1 | 6 | | |
- |* 6 | TABLE ACCESS FULL | TEST_V | 5 | 30 | 5 (0)| 00:00:01 |
- | 7 | SORT AGGREGATE | | 1 | 6 | | |
- |* 8 | TABLE ACCESS FULL | TEST_V | 1 | 6 | 5 (0)| 00:00:01 |
- | 9 | SORT AGGREGATE | | 1 | 6 | | |
- |* 10 | TABLE ACCESS FULL | TEST_V | 2 | 12 | 5 (0)| 00:00:01 |
- | 11 | SORT AGGREGATE | | 1 | 6 | | |
- |* 12 | TABLE ACCESS FULL | TEST_V | 1 | 6 | 5 (0)| 00:00:01 |
- | 13 | SORT AGGREGATE | | 1 | 6 | | |
- |* 14 | TABLE ACCESS FULL | TEST_V | 1 | 6 | 5 (0)| 00:00:01 |
- |* 15 | FILTER | | | | | |
- |* 16 | TABLE ACCESS FULL | XXX | 1956 | 76284 | 12 (0)| 00:00:01 |
- | 17 | SORT AGGREGATE | | 1 | 4 | | |
- |* 18 | TABLE ACCESS FULL| TEST_V | 16 | 64 | 5 (0)| 00:00:01 |
- ------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("A"."ZCRYZH"=TO_CHAR(:B1))
- 4 - filter("A"."ZCRYZH"=TO_CHAR(:B1) AND "A"."MYD"='0')
- 6 - filter("A"."ZCRYZH"=TO_CHAR(:B1) AND "A"."MYD"='1')
- 8 - filter("A"."ZCRYZH"=TO_CHAR(:B1) AND "A"."MYD"='2')
- 10 - filter("A"."ZCRYZH"=TO_CHAR(:B1) AND "A"."MYD"='3')
- 12 - filter("A"."ZCRYZH"=TO_CHAR(:B1) AND "A"."MYD"='4')
- 14 - filter("A"."ZCRYZH"=TO_CHAR(:B1) AND "A"."MYD"='5')
- 15 - filter( (SELECT COUNT(*) FROM "TEST_V" "A" WHERE
- "A"."ZCRYZH"=TO_CHAR(:B1))<>0)
- 16 - filter("T"."YXBZ"='Y')
- 18 - filter("A"."ZCRYZH"=TO_CHAR(:B1))
- 统计信息
- ----------------------------------------------------------
- 1 recursive calls
- 0 db block gets
- 33261 consistent gets
- 0 physical reads
- 0 redo size
- 2011 bytes sent via SQL*Net to client
- 411 bytes received via SQL*Net from client
- 3 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 20 rows processed
原始SQL需要消耗33261个逻辑读,扫描TEST_V表8次,更改之后的SQL
- SQL> select * from
- 2 (select t.zxid,
- 3 t.gh,
- 4 t.xm,
- 5 t.bm,
- 6 t.fzjgdm,
- 7 decode(count(*), 1, 0, count(*))slzl,
- 8 SUM(DECODE(A.MYD, '0', 1, 0)) 无评价,
- 9 SUM(DECODE(A.MYD, '1', 1, 0)) 满意,
- 10 SUM(DECODE(A.MYD, '2', 1, 0)) 较满意,
- 11 SUM(DECODE(A.MYD, '3', 1, 0)) 一般,
- 12 SUM(DECODE(A.MYD, '4', 1, 0)) 较不满意,
- 13 SUM(DECODE(A.MYD, '5', 1, 0)) 不满意
- 14 from CC_ZXJBXX t, test_v a
- 15 where to_char(t.zxid) = a.ZCRYZH(+)
- 16 and t.yxbz = 'Y'
- 17 group by t.zxid, t.gh, t.xm, t.bm, t.fzjgdm
- 18 ) where slzl<>0;
- 已选择20行。
- 已用时间: 00: 00: 00.01
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 1348291491
- -------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 98 | 4410 | 18 (12)| 00:00:01 |
- |* 1 | FILTER | | | | | |
- | 2 | HASH GROUP BY | | 98 | 4410 | 18 (12)| 00:00:01 |
- |* 3 | HASH JOIN RIGHT OUTER| | 1956 | 88020 | 17 (6)| 00:00:01 |
- | 4 | TABLE ACCESS FULL | TEST_V | 411 | 2466 | 5 (0)| 00:00:01 |
- |* 5 | TABLE ACCESS FULL | CC_ZXJBXX | 1956 | 76284 | 11 (0)| 00:00:01 |
- -------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter(DECODE(COUNT(*),1,0,COUNT(*))<>0)
- 3 - access("A"."ZCRYZH"(+)=TO_CHAR("T"."ZXID"))
- 5 - filter("T"."YXBZ"='Y')
- 统计信息
- ----------------------------------------------------------
- 0 recursive calls
- 0 db block gets
- 62 consistent gets
- 0 physical reads
- 0 redo size
- 1958 bytes sent via SQL*Net to client
- 411 bytes received via SQL*Net from client
- 3 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 20 rows processed
逻辑读降低到62,表TEST_V只扫描1次,其实这个SQL只是一个汇总的SQL,稍微有点开发常识的人都知道,最开始写SQL的那个人绝对是在乱写SQL。SQL的优化到这里还没完,
因为我们已经知道这个SQL的目的其实就是汇总,所以直接抛弃刚才的优化思路,直接重写SQL如下:
- SQL> SELECT *
- 2 FROM (SELECT T.ZXID,
- 3 T.GH,
- 4 T.XM,
- 5 T.BM,
- 6 T.FZJGDM,
- 7 SUM(1) SLZL,
- 8 SUM(DECODE(A.MYD, '0', 1, 0)) 无评价,
- 9 SUM(DECODE(A.MYD, '1', 1, 0)) 满意,
- 10 SUM(DECODE(A.MYD, '2', 1, 0)) 较满意,
- 11 SUM(DECODE(A.MYD, '3', 1, 0)) 一般,
- 12 SUM(DECODE(A.MYD, '4', 1, 0)) 较不满意,
- 13 SUM(DECODE(A.MYD, '5', 1, 0)) 不满意
- 14 FROM CC_ZXJBXX T ,test_v A
- 15 where A.ZCRYZH=T.ZXID
- 16 and T.YXBZ = 'Y'
- 17 GROUP BY T.ZXID, T.GH, T.XM, T.BM, T.FZJGDM) order by 1;
- 已选择20行。
- 已用时间: 00: 00: 00.01
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 1317439664
- ---------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ---------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 411 | 18495 | 18 (12)| 00:00:01 |
- | 1 | SORT GROUP BY | | 411 | 18495 | 18 (12)| 00:00:01 |
- |* 2 | HASH JOIN | | 411 | 18495 | 17 (6)| 00:00:01 |
- | 3 | TABLE ACCESS FULL| TEST_V | 411 | 2466 | 5 (0)| 00:00:01 |
- |* 4 | TABLE ACCESS FULL| CC_ZXJBXX | 1956 | 76284 | 11 (0)| 00:00:01 |
- ---------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("T"."ZXID"=TO_NUMBER("A"."ZCRYZH"))
- 4 - filter("T"."YXBZ"='Y')
- 统计信息
- ----------------------------------------------------------
- 0 recursive calls
- 0 db block gets
- 62 consistent gets
- 0 physical reads
- 0 redo size
- 1945 bytes sent via SQL*Net to client
- 411 bytes received via SQL*Net from client
- 3 SQL*Net roundtrips to/from client
- 1 sorts (memory)
- 0 sorts (disk)
- 20 rows processed
有时候开发人员,为了完成任务,他才不管你SQL写得好不好呢,能完成功能就行了,相信各位DBA深有体会。















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









