







前几篇博文降到如何安装配置hadoop2.7.2分布式环境,现在环境已经搭建好了,接下来我们可以通过搭建好的环境来跑一些小例子。
我们都知道学习java的时候,我们写的第一个程序就是HelloWorld,在hadoop里面也有一个类似HelloWorld的例子,它的名字就叫做WordCount。
WordCount是hadoop官方给出的一个例子,该例子是通过mapreduce来统计文本中单词的出现次数。
通俗的讲就是有一个或者若干个文本,文本里面有很多个单词,单词之间用空格来间隔,然后跑这WorldCount的程序,就可以统计分析出这若干个文本中每个单词出现的个数。
下面我们来尝试一把看。
1.首先登陆master节点,切换到hadoop用户。
cd /hmoe/hadoop/hadoop-2.7.2/sbin目录下
接着启动hadoop: ./start-all.sh
然后 cd /home/hadoop/hadoop-2.7.2/share/hadoop/mapreduce 目录下面
share目录下面存放了很多hadoop官方的小例子,我们在学习hadoop的时候可以从这个目录下面去学习,还包括hadoop的API文档也在这个目录下面。
今天我们先学习mapreduce,所以我们先到mapreduce目录下
先创建一个examples目录
mkdir examples
然后cd examples目录下面,接着创建一个wordcount目录
mkdir wordcount
cd wordcount
然后 vi file1.txt
hello zhm
hello hadoop
hello cz
以上写到file1.txt中,保存并退出vivi file2.txt
hadoop is ok
hadoop is newbee
hadoop 2.7.2
保存并退出。在hdfs上创建 /examples/wordcount/input目录,并把本地两个文件put到目录中
hadoop fs -mkdir -p /examples/wordcount/input
hadoop fs -put -f file1.txt file2.txt /examples/wordcount/input
之后可以在界面上看到put到hdfs中的文件,如下图:
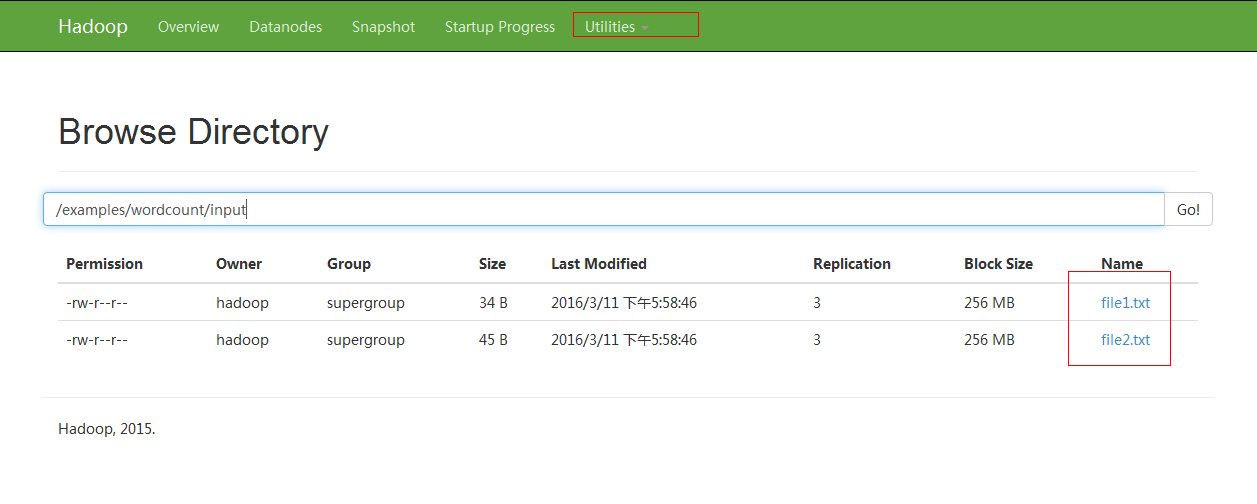
运行wordcount例子
执行命令:
hadoop jar /home/hadoop/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount/examples/wordcount/input/examples/wordcount/output
注意:jar包的地址必须填写好正确的路径,即使你已经cd到jar包的目录下,也不可以省略路径,必须要绝对路径。
执行成功过之后可以通过集群页面访问。
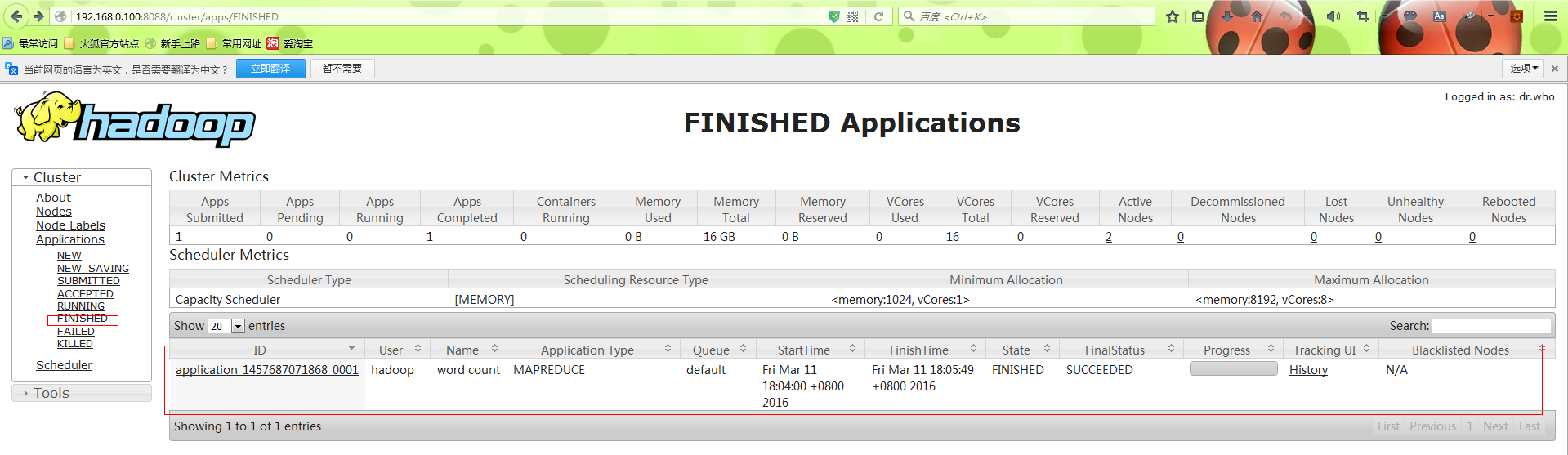
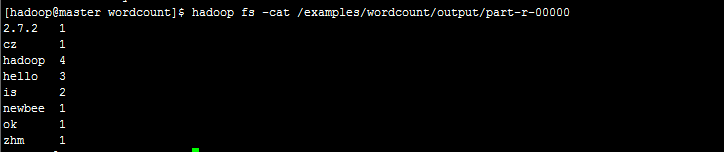
然后可以执行命令查看结果:
hadoop fs -cat /examples/wordcount/output/part-r-00000















 2240
2240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









