







线程概念
这里讲的线程是程序线程,首先我们要把程序的线程和CPU的线程以及进程这几个概念理顺清楚
-
CPU线程
是CPU调度和分派的基本单位
-
进程
是程序在执行过程中分配和管理资源的基本单位

我们经常听说的一句话是CPU有几核几线程,这句话怎么理解。打个比方假如把计算机运行程序看做是工厂流水线生产,就可以把CPU看做车间,CPU核可以看做流水线工位,CPU线程就可以看做是流水线的工人而程序的线程相当于传送带上的待加工零件,进程就是一件产品的生产任务。
| 名称 | 比喻 | 数量 |
|---|---|---|
| cpu | 车间 | 固定 |
| 核 | 工位 | 固定 |
| CPU线程 | 工人 | 固定 |
| 程序线程 | 待加工零件 | 不固定 |
| 进程 | 生产任务(单一产品订单) | 不固定 |
| 其它硬件 | 原材料(资源:内存,硬盘等I/O设备) | 不固定 |
-
执行单线程程序
就是将一份订单交给一个工人独自完成(单线程独占资源)
-
执行多线程程序
就是把一份订单交给多个工人一起生产,工人们可以共享这件产品的原材料(进程可以包含多个程序线程,多CPU线程共享程序资源)
在生产过程中一个工人可以在不同的工位上工作,但一个工位同一时间只能有一个工人坐在上面;一个工人可以加工同一产品的不同部件,也可以加工不同的产品,但更换加工的产品需要重新备料(CPU线程可以在多核间调配,一个核心同一时间只能处理一个CPU线程;线程切换开销小,进程切换开销大)。
多线程JAVA程序
每个程序执行过程至少是一个单线程,JAVA程序也是一样。那么怎么让JAVA开启一个多线程程序呢?
- 通过继承Thread类,覆盖run方法
class ThreadDemo extends Thread {
private String threadName;
ThreadDemo( String name) {
threadName = name;
System.out.println("Creating " + threadName );
}
@Override
public void run() {
System.out.println("Running " + threadName );
try {
for(int i = 4; i > 0; i--) {
System.out.println("Thread: " + threadName + ", " + i);
// 让线程睡眠一会
Thread.sleep(50);
}
}catch (InterruptedException e) {
System.out.println("Thread " + threadName + " interrupted.");
}
System.out.println("Thread " + threadName + " exiting.");
}
public static void main(String[] args) {
ThreadDemo demo1 = new ThreadDemo("testDemo-1");
ThreadDemo demo2 = new ThreadDemo("testDemo-2");
//demo1.run();
//demo2.run();
demo1.start();
demo2.start();
}
}
//start方法输出
Creating testDemo-1
Creating testDemo-2
Running testDemo-1
Running testDemo-2
Thread: testDemo-2, 4
Thread: testDemo-1, 4
Thread: testDemo-1, 3
Thread: testDemo-2, 3
Thread: testDemo-1, 2
Thread: testDemo-2, 2
Thread: testDemo-2, 1
Thread: testDemo-1, 1
Thread testDemo-2 exiting.
Thread testDemo-1 exiting.
//run方法输出
Creating testDemo-1
Creating testDemo-2
Running testDemo-1
Thread: testDemo-1, 4
Thread: testDemo-1, 3
Thread: testDemo-1, 2
Thread: testDemo-1, 1
Thread testDemo-1 exiting.
Running testDemo-2
Thread: testDemo-2, 4
Thread: testDemo-2, 3
Thread: testDemo-2, 2
Thread: testDemo-2, 1
Thread testDemo-2 exiting.
- 通过Runnable接口和Thread类
@Test
public void test2(){
Runnable r = ()->{
try {
log.info("{} start",Thread.currentThread().getName());
Thread.sleep(1000);
log.info("{} end",Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
};
Thread t = new Thread(r);
t.start();
Thread t2 = new Thread(r);
t2.start();
while (true){}
}
- 通过Callable接口和Feature类,这种方式在JAVA8中已经被更新的CompletionStage接口和CompletableFeature类替代就不举例了
线程并发
并发是指在同一时间范围内有多个执行同一任务的线程在运行。还以上面的例子做比较,并发相当于给多个工人同时下达了同样的生产任务,这就提高了工人的工作要求,要保证每个产品由正确的组装顺序还有所有产品的零件数量正确不能有的零件多做了有的零件没有做。
举个简单例子,假设使用100资源进行零件加工,每加工完成一个产品扣除对应的资源数量:
@Slf4j
public class ThreadTest {
int i = 100;//总库存
@Test
public void test(){
Runnable r = ()->{
while (i - 40 >= 0) {
minusI(40);
log.info("i剩余 = {}", i);
}
};
Thread t = new Thread(r);
t.start();
Thread t2 = new Thread(r);
t2.start();
Thread t3 = new Thread(r);
t3.start();
while (true){}
}
//生产方法
private void minusI(int num){
if (i - num >= 0) {
log.info("i减{}",num);
//模拟生产过程中的延时
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//扣库存
i -= num;
}
}
}
[Thread-0] INFO thread.ThreadTest - i减40
[Thread-1] INFO thread.ThreadTest - i减40
[Thread-2] INFO thread.ThreadTest - i减40
[Thread-0] INFO thread.ThreadTest - i剩余 = 60
[Thread-0] INFO thread.ThreadTest - i减40
[Thread-2] INFO thread.ThreadTest - i剩余 = -20
[Thread-1] INFO thread.ThreadTest - i剩余 = 20
[Thread-0] INFO thread.ThreadTest - i剩余 = -60
当线程并发时,对相同资源的操作会出现以上不合理的情况
synchronized
为了解决上面的问题,可以采用在方法上加synchronized修饰,这种方案就是当a工人做种某零件时其他所有人都不能生产这零种件,只有当a做完时其他工人才能做,即同一种零件只能有一个工人在做。
private synchronized void minusI(int num){
if (i - num >= 0) {
log.info("i减{}",num);
//模拟生产过程中的延时
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//扣库存
i -= num;
}
}
[Thread-0] INFO thread.ThreadTest - i减40
[Thread-0] INFO thread.ThreadTest - i剩余 = 60
[Thread-2] INFO thread.ThreadTest - i减40
[Thread-1] INFO thread.ThreadTest - i剩余 = 20
[Thread-0] INFO thread.ThreadTest - i剩余 = 20
[Thread-2] INFO thread.ThreadTest - i剩余 = 20
LinkedBlockingQueue
类似于synchronized还可以使用阻塞队列LinkedBlockingQueue处理并发,LinkedBlockingQueue是一个是先进先出的顺序的队列,对它操作是线程阻塞的,即同一时刻只能进行一个操作,要么添加要么移除。这种方案好比把当前资源放到先一个袋子里再一个一个拿出来,让所有工人去“抢”,手快的人拿到资源进行加工,所有工人一直”抢“直到资源耗尽。
@Slf4j
public class BlockQueueTest {
//阻塞队列
LinkedBlockingQueue<Integer> queue;
//资源总量
int i = 100;
//单件零件所需资源
int need = 40;
@Test
public void test2(){
int size = i / need;
queue = new LinkedBlockingQueue<>(size);
try {
queue.put(i);//把资源放入队列
} catch (InterruptedException e) {
e.printStackTrace();
}
Runnable r = ()->{
try {
if(queue.size()>0){
log.info("抢单");
i = queue.take();
log.info("抢单成功,当前剩余 = {}", i);
if (i - need >= 0) {
minusI(need);
queue.put(i);
}
log.info("i剩余 = {}", i);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
};
Thread t = new Thread(r);
t.start();
Thread t2 = new Thread(r);
t2.start();
Thread t3 = new Thread(r);
t3.start();
Thread t4 = new Thread(r);
t4.start();
Thread t5 = new Thread(r);
t5.start();
while (true){}
}
private void minusI(int num){
log.info("i减{}",num);
//模拟生产过程中的延时
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//扣库存
i -= num;
}
}
[Thread-4] INFO thread.BlockQueueTest - 抢单
[Thread-1] INFO thread.BlockQueueTest - 抢单
Thread-2] INFO thread.BlockQueueTest - 抢单
[Thread-3] INFO thread.BlockQueueTest - 抢单
[Thread-0] INFO thread.BlockQueueTest - 抢单
[Thread-1] INFO thread.BlockQueueTest - 抢单成功,当前剩余 = 100
[Thread-1] INFO thread.BlockQueueTest - i减40
[Thread-4] INFO thread.BlockQueueTest - 抢单成功,当前剩余 = 60
[Thread-1] INFO thread.BlockQueueTest - i剩余 = 60
[Thread-4] INFO thread.BlockQueueTest - i减40
[Thread-4] INFO thread.BlockQueueTest - i剩余 = 20
[Thread-2] INFO thread.BlockQueueTest - 抢单成功,当前剩余 = 20
[Thread-2] INFO thread.BlockQueueTest - i剩余 = 20
ThreadLocal
上面的的场景是多线程共享资源的情况,每个线程“排队”处理,还有种场景可以提前按线程数量把资源划给每个线程独享,多线程处理自己的资源时互不相干。
我们可以使用ThreadLocal类,每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
@Slf4j
public class ThreadLocalTest {
//把100资源分给两个线程,每个线程得50
ThreadLocal<Integer> i = ThreadLocal.withInitial(() -> 50);
@Test
public void test(){
Runnable r = ()->{
while (i.get() - 40 >= 0) {
minusI(40);
log.info("i剩余 = {}", i.get());
}
};
Thread t = new Thread(r);
t.start();
Thread t2 = new Thread(r);
t2.start();
while (true){}
}
private void minusI(int num){
if (i.get() - num >= 0) {
log.info("i减{}",num);
//模拟生产过程中的延时
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//扣库存
i.set(i.get() - num);
}
}
}
[Thread-1] INFO thread.ThreadLocalTest - i减40
Thread-0] INFO thread.ThreadLocalTest - i减40
Thread-1] INFO thread.ThreadLocalTest - i剩余 = 10
Thread-0] INFO thread.ThreadLocalTest - i剩余 = 10
线程池
为什么要使用线程池,我们先来看一个简单的例子
@Test
public void test() throws InterruptedException {
Long start = System.currentTimeMillis();
final Random random = new Random();
final List<Integer> list = new ArrayList<>();
int size = 100000;//10万
for (int i = 0; i < size; i++) {
Runnable r = ()->{
list.add(random.nextInt());
};
Thread t = new Thread(r);
t.start();
}
log.info("时间:{}",System.currentTimeMillis()-start);
log.info("size:{}",list.size());
}
来看一下程序的几次输出
[main] INFO thread.ThreadPoolTest - 时间:6522
[main] INFO thread.ThreadPoolTest - size:99938
[main] INFO thread.ThreadPoolTest - 时间:6386
[main] INFO thread.ThreadPoolTest - size:99945
可以看到list的长度并没有达到预期的10万,因为程序中创建的线程都是子线程,通常情况下主线程结束时不会关心子线程的状态,也就是说在某些子线程执行结束之前之段代码的运行已经结束了。那么如何达到我们的预期目标呢?
@Test
public void test() throws InterruptedException {
Long start = System.currentTimeMillis();
final Random random = new Random();
final List<Integer> list = new ArrayList<>();
int size = 100000;
for (int i = 0; i < size; i++) {
Runnable r = ()->{
list.add(random.nextInt());
};
Thread t = new Thread(r);
t.start();
t.join();//等到子线程返回后再进入主线程
}
log.info("时间:{}",System.currentTimeMillis()-start);
log.info("size:{}",list.size());
}
使用join()方法,将产生线程阻塞,主线程会等到子线程结束后再往下执行,看一下结果
[main] INFO thread.ThreadPoolTest - 时间:13265
[main] INFO thread.ThreadPoolTest - size:100000
预期目标是达到了,但是时间增加一倍。那么有没有一套高效又完整的解决方案呢?答案就是使用线程池,来看以下代码
@Test
public void test2() throws InterruptedException {
Long start = System.currentTimeMillis();
final Random random = new Random();
final List<Integer> list = new ArrayList<>();
//声明线程池对象
ExecutorService executorService = Executors.newSingleThreadExecutor();
for (int i = 0; i < 100000; i++) {
Runnable r = ()->{
list.add(random.nextInt());
};
//加入线程池
executorService.execute(r);
}
//关闭线程池,开始执行任务
executorService.shutdown();
//阻塞线程直到完成
executorService.awaitTermination(1, TimeUnit.MINUTES);
log.info("时间:{}",System.currentTimeMillis()-start);
log.info("size:{}",list.size());
}
看一下结果
[main] INFO thread.ThreadPoolTest - 时间:78
[main] INFO thread.ThreadPoolTest - size:100000
上面例程中通过使用executorService.awaitTermination(1, TimeUnit.MINUTES)阻塞主线保证业务在1分钟内完成,如果实际业务中无法估计运行时间,还可以通过executorService.submit()方法返回一个Future对象来实现
public void test3() throws InterruptedException {
Long start = System.currentTimeMillis();
final Random random = new Random();
final List<Integer> list = new ArrayList<>();
ExecutorService executorService = Executors.newSingleThreadExecutor();
//Future列表
List<Future<?>> futureList = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
Runnable r = ()->{
list.add(random.nextInt());
};
//加入Future列表
futureList.add(executorService.submit(r));
}
executorService.shutdown();
//得到所有Future的返回
futureList.forEach(future -> {
try {
future.get();//阻塞主直到方法返回
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
log.info("时间:{}",System.currentTimeMillis()-start);
log.info("size:{}",list.size());
}
/***
如果你觉得Future<?>不优雅可以使用Callable来代替Runnable
与Runnable的run()方法不同的时,Callabler的call()方法可以得到返回值
List<Future<Void>> futureList = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
Callable<Void> r = ()->{
list.add(random.nextInt());
return null;
};
futureList.add(executorService.submit(r));
}
*/
[main] INFO thread.ThreadPoolTest - 时间:82
[main] INFO thread.ThreadPoolTest - size:100000
为什么使用线程池效率会提高呢?原因在于线程池是一种对象池,它可以高效地管理线程资源,我们知道JAVA对象的创建和销毁都是要消耗资源的,用对象池可以大大减少JAVA对象的重复创建和销毁从而提高了程序的运行效率。
JAVA的Executors类提供了四种线程池的快捷获取方法,四种方法提供的是配置不同的线程池,而它们都是同一种对象ThreadPoolExecutor。
SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
FixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
CachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
ScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
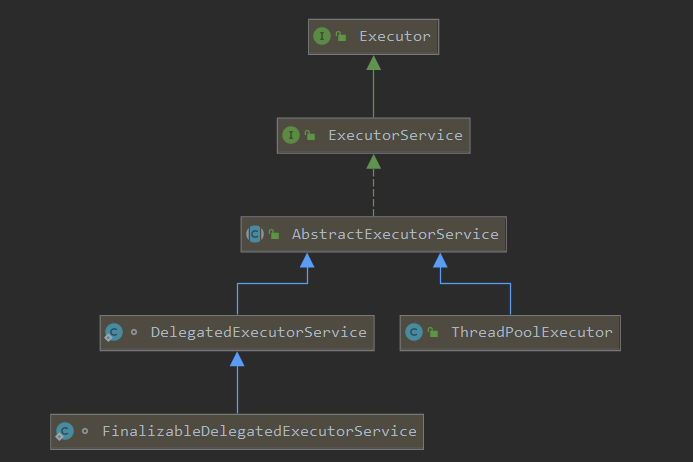
ThreadPoolExecutor的构造参数
| 参数 | 数据类型 | 作用 |
|---|---|---|
| corePoolSize | int | 核心线程数 |
| maximumPoolSize | int | 非核心线程数 |
| keepAliveTime | long | 线程空闲时间长度 |
| unit | TimeUnit | 时间单位 |
| workQueue | BlockingQueue | 任务队列 |
线程池的运行方式
- corePoolSize
- 核心线程会一直存活,即使没有任务需要执行
- 当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理
- 设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭
- workQueue
- 当线程数>=corePoolSize,且workQueue未满时,任务会加入任务队列
- maximumPoolSize
- 当线程数>=corePoolSize,且workQueue已满时。线程池会创建新线程来处理任务
- 当线程数=maxPoolSize,且workQueue已满时,线程池会拒绝处理任务而抛出异常
- keepAliveTime
- 当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize
- 如果设置allowCoreThreadTimeout=true,则会直到线程数量=0
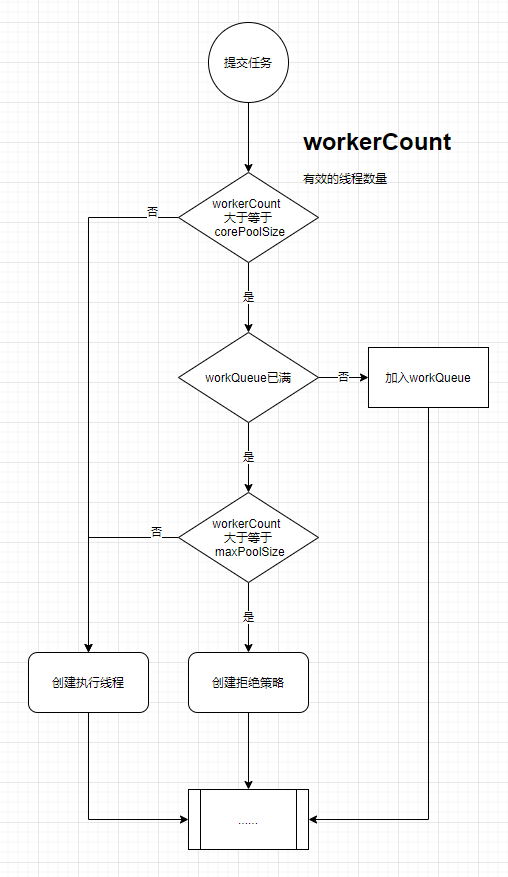
我们可以把线程池的运行方式理解成一个工厂的人力管理:
- corePoolSize是合同工的数量
- workQueue是生产排期
- maximumPoolSize是临时工的数量
- keepAliveTime是工人的最长休假时间
当工厂接到一笔新订单时
- 先评估一下合同工的人力(corePoolSize),如果有空闲的合同工人就把订单分配给他;如果没有合同工人空闲,那么看一下工厂的排单规则是否允许排期(workQueue),如果允许把订单加入队列排队。
- 如果全部合同工和生产排期都满了,那就根据工厂的临时工招募规则(maximumPoolSize),招临时工处理订单
- 当临时完成生产任务后工厂就给他们放假,如果临时工的休假时长达到了最长休假时间(keepAliveTime),那么工厂就将他们解聘
- 合同工人完成任务工厂也给他们放假(无限期休假),如果规定最长休假时间也适用于合同工人(allowCoreThreadTimeout),那么合同工人也会被解聘
线程池的拒绝策略
当线程池的任务队列已满并且线程池中的线程数目达到maximumPoolSize后,如果还有新任务提交就会触发拒绝策略
ThreadPoolExecutor的另一种构造参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler);
| 参数 | 数据类型 | 作用 |
|---|---|---|
| threadFactory | ThreadFactory | 线程池中线程的创建工厂 |
| handler | RejectedExecutionHandler | 线程池的拒绝策略 |
RejectedExecutionHandler是一个策略接口,JDK默认提供了四种拒绝策略:
-
AbortPolicy
丢弃任务,并抛出拒绝执行 RejectedExecutionException 异常信息。线程池默认的拒绝策略。必须处理好抛出的异常,否则会打断当前的执行流程,影响后续的任务执行。
-
DiscardPolicy
直接丢弃,不抛出异常。
-
DiscardOldestPolicy
丢弃阻塞队列 workQueue 中最老的一个任务,然后重新提交被拒绝的任务。
-
CallerRunsPolicy
使用调用线程直接运行任务,一般并发比较小,性能要求不高,不允许失败。但是,由于调用者自己运行任务,如果任务提交速度过快,可能导致程序阻塞,性能效率上必然的损失较大。
Executors默认线程池的问题
阿里巴巴Java开发手册中提到,使用Executors创建线程池可能会导致OOM(内存溢出),导致内存溢出的原因之一就是因为对象实例太多而不回收,上面说过线程池有自己的拒绝策略,当达到阈值时将不会继续向池内添加对象。为什么有这样的机制还会有OOM的情况呢?我们来看几个可以决定池大小的参数:corePoolSize,maximumPoolSize,workQueue
| 方法 | corePoolSize | maximumPoolSize | workQueue |
|---|---|---|---|
| newSingleThreadExecutor | 1 | 1 | LinkedBlockingQueue |
| newFixedThreadPool | 指定 | 指定 | LinkedBlockingQueue |
| newCachedThreadPool | 0 | Integer.MAX_VALUE | SynchronousQueue1 |
| newScheduledThreadPool | 1 | Integer.MAX_VALUE | DelayedWorkQueue2 |
回顾一下上面的流程图
-
可以看到
newCachedThreadPool,newScheduledThreadPool的maximumPoolSize参数都使用Integer.MAX_VALUE,Integer.MAX_VALUE的值是一个21亿多的数值,理论上这两种线程池的临时线程数量可以高到21亿,这就非常容易使内存溢出了。 -
再看另外两个方法
newSingleThreadExecutor和newFixedThreadPool,他们的maximumPoolSize参数应该是安全的,问题出在workQueue参数,JAVA中的BlockingQueue主要有两种实现,分别是ArrayBlockingQueue和LinkedBlockingQueue。-
ArrayBlockingQueue是一个用数组实现的有界阻塞队列,必须设置容量。 -
LinkedBlockingQueue是一个用链表实现的有界阻塞队列,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度也是Integer.MAX_VALUE。
-
也就是说Executors默认的四个方法,永远不会触发拒绝策略,安全使用线程池的方式是自己指定构造参数,比如:
private static ExecutorService executor = new ThreadPoolExecutor(10, 100,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue(20));
















 6148
6148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









