







第四章 数据预处理
【有问题或错误,请私信我将及时改正;借鉴文章标明出处,谢谢】
第四章相关代码看我的文章:
《Python数据分析与挖掘实战》第四章案例代码总结与修改分析
数据预处理一方面是要提高数据 的质量,另一方面是要让数据更好地适应特定的挖掘技术或工具。
数据预处理的主要内容包括数据清洗、数据集成、数据变换和数据规约。
一、数据清洗
1.缺失值处理
(1)缺失值的处理方法分为三类:删除记录、数据插补、和不处理
(2)常用的插补方法:
①均值/中位数/众数插补:根据属性值的类型,用该属性取值的平均数/中位数/众数进行插补
②使用固定值:将确实的属性值用一个常量替换:用广州的基本工资来替换一个外来务工人员的工资的缺失值
③最近临插补:在记录中找到与缺失值样本最接近的样本的该属性值插补
④回归方法:对带有缺失值的变量,根据已有数据和逾期有关的其他变量(因变量)的数据进行建立拟合模型来预测确实的属性值
⑤插值法:插值法是利用已知点建立合适的插补函数f(x),未知值对应点xi求出的函数值f(xi)近似代替
⑥插值方法:拉格朗日插值法和牛顿插值法
案例介绍拉格朗日插值:

2.异常值处理
在数据预处理时,异常值是否剔除,要视具体情况而定。
异常值处理常用方法
1>删除含有异常值的记录:直接将含有异常值的记录删除
2>视为缺失值:将异常值视为缺失值,利用缺失值处理的方法进行处理
3>平均值修正:可用前后两个观测值的平均值修正改异常值
4>不处理:直接在具有异常值的数据集上进行挖掘
在很多情况下,要先分析异常值出现的可能原因,在判断异常值是否应该舍弃,如果是正确数据,可直接在具有异常值的数据集上进行挖掘建模。
二、数据集成
数据集成就是将多个数据源合并存放在一个一直的数据存储(如数据仓库)中的过程。
在数据集成时,来自多个数据源的现实世界实体的表达形式是不一样的,有可能不匹配,要考虑实体识别问题和属性冗余问题,从而将源数据在最底层上加以转换、提炼和集成
1.实体识别
实体识别是指从不同数据源识别出现实世界的实体,它的任务是统一不同源数据的矛盾之处,常见形式:
(1)同名异义
数据源A中的属性ID和数据源B中的ID分别描述的是菜品编号和订单编号,即描述不同的实体。
(2)异名同义
数据源A中的sales_dt和数据源B中的sales_date都是描述销售日期的,即A.sales_dt=B.sales_date
(3)单位不统一
描述同一个实体分别用的是国际单位和中国传统的计量单位。
检测和解决这些冲突就是实体识别的任务。
2.冗余属性识别
数据集成往往导致数据冗余,例如:
(1)同一属性多次出现
(2)同一属性命名不一致导致重复
对于冗余属性要先分析,检测到后再将其删除。有些冗余属性可以用相关分析检测。
三、数据变换
1.简单函数变换
简单函数变换是对原始数据进行某些数学变换,常用的变换包括平方、开方、取对数、差分运算等
2.规范化
数据规范化(归一化)处理是数据挖掘的一项基础工作。不同评价指标往往具有不同的量纲,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果。为了消除指标间的量纲和取值范围差异的影响,进行标准化处理,将数据按照比例进行缩放,是指落到一个特定区域,便于进行综合分析。
(1)最小-最大规范化
(2)零-均值规范化
(3)小数定标规范化
数据规范化:

3.连续属性离散化
将连续属性变换成分类属性,即连续属性离散化。
(1)离散化的过程
连续属性的离散化就是在数据的取值范围内设定若千个离散的划分点,将取值范围划分为一些离散化的区 间,最后用不同的符号或整数值代表落在每个子区间中的数据值。所以,离散化涉及两个子任务:确定分类数 以及如何将连续属性值映射到这些分类值。
(2)常用的离散化方法
常用的离散化方法有等宽法、等频法和(一维)聚类。
1>等宽法
将属性的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定,或者由用户指定,类似于制作 频率分布表。
2>等频法
将相同数量的记录放进每个区间。
3>基于聚类分析的方法
一维聚类的方法包括两个步骤,首先将连续属性的值用聚类算法(如K-Means算法)进行聚类,然后再将聚类 得到的簇进行处理,合并到一个簇的连续属性值并做同- -标记。聚类分析的离散化方法也需要用户指定簇的 个数,从而决定产生的区间数。
数据离散化案例:

4.属性构造
利用已有的属性构造出新的属性,并加入到现有的属性集合中。
比如,进行防窃露电诊断建模时,已有的属性包括供入电量、供出电量。理论上供入电量=供出电量,但是传输过程中存在电能损耗,使得供入电量>供出电量,如果这条线路上的一个或多个大用户存在窃漏电行为,会使得供入电量明显大于供出电量。
为判断是否有大用户存在窃漏电行为,构造新指标-线损率,该过程就是构造属性。
线损率属性构造:

5.小波变换
小波变换的同是一种新型的数据分析工具,是近年来兴起的信号分析手段。小波分析的理论和方法在信号处理、图像处理、语音处理、模式识别、量子物理等领域得到越来越广泛的应用,它被认为是近年来在工具及方法上的重大突破。小波变换具有多分辨率的特点,在时域和频域都具有表征信号局部特征的能力,通过伸缩和平移等运算过程对信号进行多尺度聚焦分析,提供了一种非平稳信号的时频分析手段,可以由粗及细地逐步观察信号,从中提取有用信息。
(1)基于小波变换的特征提取方法
基于小波变换的多尺度空间能量分布特征提取方法:
各尺度空间内的平滑信号和细节信号能提供原始信号的时频局域信息,特别是能提供不同频段上信号的构成信息。把不同分解尺度上信号的能量求解出来,就可以将这些能量尺度顺序排列,形成特征向量供识别用
基于小波变换的多尺度空间的模极大值特征提取方法:
利用小波变换的信号局域化分析能力,求解小波变换的模极大值特性来检测信号的局部奇异性,将小波变换模极大值的尺度参数s、平移参数t及其幅值作为目标的特征量
基于小波包变换的特征提取方法:
利用小波分解,可将时域随机信号序列映射为尺度域各子空间内的随机系数序列,按小波包分解得到的最佳子空间内随机系数序列的不确定性程度最低,将最佳子空间的嫡值及最佳子空间在完整二叉树中的位置参数作为特征量,可以用于目标识别
基于适应性小波神经网络的特征提取方法:
基于适应性小波神经网络的特征提取方法可以把信号通过分析小波拟合表示,进行特征提取
(2)小波基函数
(3)小波变换
(4) 基于小波变换的多尺度空间能量分布特征提取方法
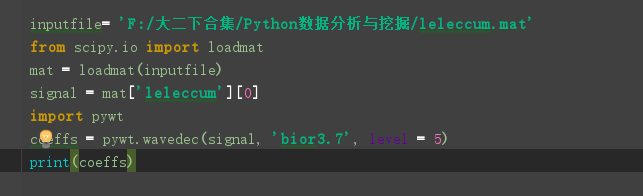
小波变换特征提取代码:
四、数据规约
在大数据集.上进行复杂的数据分析和挖掘需要很长的时间,数据规约产生更小但保持原数据完整性的新数据集。在规约后的数据集上进行分析和挖掘将更有效率。
数据规约的意义在于:
①降低无效、错误数据对建模的影响,提高建模的准确性;
②少量且具代表性的数据将大幅缩减数据挖掘所需的时间;
③降低储存数据的成本。
1.属性规约
属性规约通过属性合并来创建新属性维数,或者直接通过删除不相关的属性(维)来减少数据维数,从而提高数 据挖掘的效率、降低计算成本。属性规约的目标是寻找出最小的属性子集并确保新数据子集的概率分布尽可 能地接近原来数据集的概率分布。
属性规约常用方法:
合并属性、逐步向前选择、逐步向后删除、决策树归纳、主成分分析
主成分分析降维案例:

2.数值规约
数值规约是指通过选择替代的、较小的数据来减少数据量,包括有参数方法和无参数方法两类。
有参数方法:使用一个模型来评估数据,只存放参数,而不是存放实际数据,如:回归和对数线性模型。
无参数方法:需要存放实际数据,如:直方图、聚类、抽样(采样)。
(1)直方图
(2)聚类
聚类技术奖数据元组(即记录,数据表中的一行)视为对象。将对象划分为簇,使一个簇中的对象相互“相似”,与其他簇中的对象“相异”。
(3)抽样
①简单随机抽样
②聚类抽样
③分层抽样
(4)参数回归
五、Python主要数据预处理函数
Interpolate:一维、高维数据插值
Unique:去除数据中的重复元素,得到单值元素列表,它是对象的方法名
Isnull:判断是否空值
Notnull:判断是否非空值
PCA:对指标变量矩阵进行主成分分析
Random:生成随机矩阵
【有问题或错误,请私信我将及时改正;借鉴文章标明出处,谢谢】
















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











