









【大语言模型】ACL2024论文-02 非监督多模态聚类用于多模态话语中语义发现
目录
文章目录
1. 论文信息

文章标题翻译
无监督多模态聚类:在多模态话语中发现语义
摘要
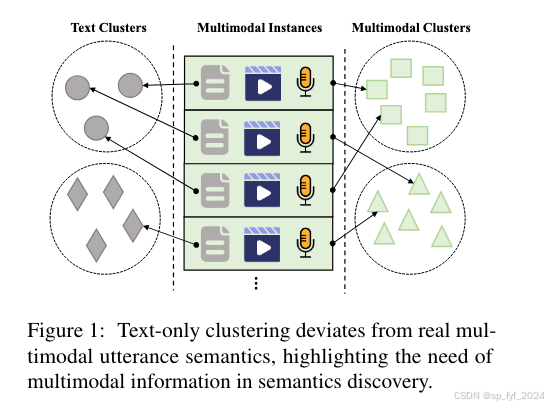
本文提出了一种新颖的无监督多模态聚类方法(UMC),旨在通过整合文本、视频和音频等多种模态信息来发现多模态话语中的复杂语义。UMC通过构建多模态数据的增强视图进行预训练,以建立良好的初始化表示,用于后续的聚类。该方法还提出了一种创新策略,动态选择高质量样本作为表示学习的指导,并自动确定每个聚类中top-K参数的最优值以优化样本选择。实验结果表明,UMC在多模态意图和对话行为数据集上相较于现有方法有2-6%的聚类指标显著提升。
创新点
- 多模态数据增强:UMC引入了一种独特的方法来构建多模态数据的增强视图,通过掩盖视频或音频模态来创建正增强样本,这有助于模型捕捉多模态间的隐含相似性。
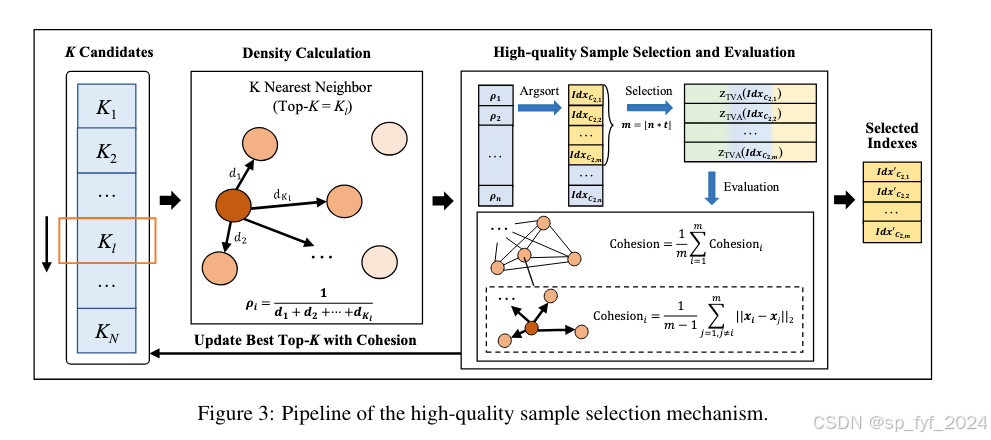
- 高质量样本选择策略:提出了一种基于样本密度的动态样本选择策略,用于在每次迭代中选择最高质量的样本进行训练,这有助于提高聚类的质量。
- 自动确定top-K参数:UMC能够自动确定每个聚类中top-K参数的最优值,以精细化样本选择。
- 迭代表示学习:提出了一种迭代过程,先从高质量样本学习,然后利用无监督对比损失优化剩余的低质量样本,这种双策略有助于提升聚类效果。
算法模型
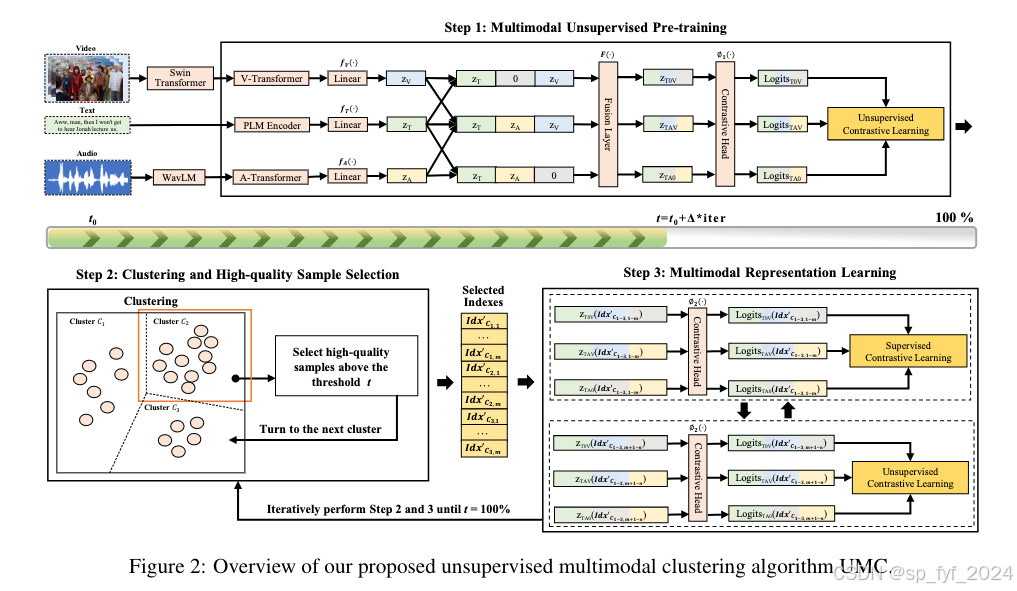
UMC算法模型包含以下几个关键步骤:
- 多模态表示:使用预训练的语言模型处理文本数据,使用深度特征提取方法处理视频和音频数据,然后通过Transformer编码器捕获这些特征的深层语义。
- 多模态无监督预训练:通过无监督对比学习损失,利用数据增强视图来初始化表示,为后续聚类提供良好的起点。
- 聚类和高质量样本选择:使用K-Means++算法进行聚类,并引入基于密度的样本选择机制来选择高质量样本。
- 多模态表示学习:使用监督对比损失从高质量样本中学习,然后使用无监督对比损失优化低质量样本,迭代进行直到样本选择阈值满足条件。
实验效果
重要数据与结论
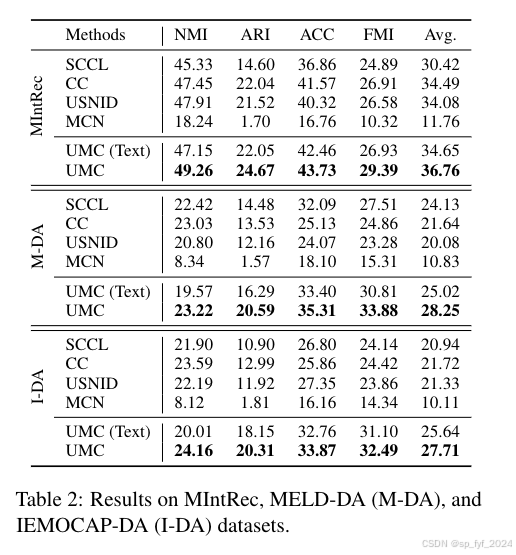
- 数据集:MIntRec、MELD-DA和IEMOCAP-DA,这些数据集涵盖了多模态意图识别和对话行为识别任务。
- 评估指标:使用标准化互信息(NMI)、准确率(ACC)、调整兰德指数(ARI)和Fowlkes-Mallows指数(FMI)来评估聚类性能。
- 结果:UMC在所有数据集上相较于现有最先进方法在各项指标上均有2-6%的显著提升,特别是在ARI、ACC和FMI指标上提升更为显著。
相关工作与参考文献
- 多模态聚类:如XDC和DMC,这些方法侧重于深度神经网络,有效处理多模态数据。
- 多视图聚类:包括CDD、COMIC等算法,这些方法在处理高维数据时可能效率较低。
- 多模态语言分析:涉及多模态数据集和融合方法的研究,如MOSI、CMU-MOSEI等。
- 意图发现:早期方法使用弱监督信号辅助聚类,近期方法利用有限的标记数据指导聚类的特征学习过程。
UMC的潜在应用包括:
- 视频内容推荐:通过分析用户生成的多模态内容,发现用户意图,以改善视频推荐系统。
- 多模态数据注释:快速对大量多模态数据进行聚类,辅助识别新模式并加速注释过程。
- 虚拟人技术:使虚拟人能够更准确地捕捉人类意图,提供更自然流畅的交互体验。
推荐阅读指数:★★★★☆
后记
Rule1: 如果您对我的博客内容感兴趣,欢迎三连击(关注、点赞和评论),我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。
Rule2: 如果我的文章帮助或者触动了你,可以自愿赞赏我一瓶快乐肥宅水:) , 点击打赏,为每个努力的技术人点赞!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











