







算法专题开篇儿,闲话少说,直奔主题。
今天分别听了学校老师的课程以及MIT的《算法导论》,第一节算法复杂度就从他们两个人的相同点和不同点说起吧~
孙廷凯老师是一个一本正经的人,他给这节课定了一个主题,就是“复杂”;从我的理解,这里的复杂一语双关,一个只这门课程的难度上相对有一定难度;第二,算法学习首先从算法复杂度开始分析,这门课从始至终就是在围绕着算法复杂性的分析和优化。
MIT的老师同样提到了一个关键词“性能”,其实一切的技术优势存在的基础都是基于性能之上,所以算法可就晒通过分析一些相关的算法,尽可能掌握好的方法,甚至优化算法,提高性能,进而推进当前相关技术。
下来从算法复杂度的几个相关名词开始整理今天的思路吧~
首先是算法分析的三种结果:
1.给用户保证的底线:最坏分析
2.:平均分析
3.“骗人”:最优分析------几乎永远也不能达到,给用户的诱惑
之后,我们来看看算法分析的三种符号:
1."O"--渐进上界(姑且先这样称呼吧,有些不准确的随后再做更改)
2.“Ω”-渐进下界
3."θ"--同阶
ex:至于theta符号,我们从经典的归并排序开始感受它吧!
其实归并排序的基本思想就是分治思想,通过对两个较小规模的已排序序列进行常数次的比较,对每次比较出来较小的数(默认升序排列)添加到新数组的末尾,逐渐生成一个新的有序的规模更大的序列。那么,他的复杂度可以写成如下形式:
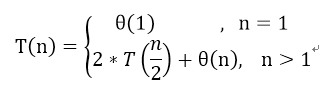
其中,这里的θ(n)并不准确(毕竟渐进符号是需要描述其增长时的情况),但是能表达我们想要说的意思,如此一来,我们还需引入“递归树”,帮助我们对算法复杂度做高效的分析。
以下是MergeSort所用到的的“递归树”:
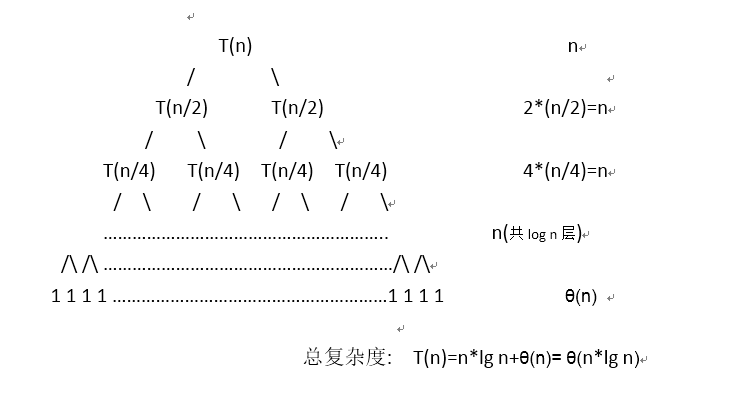
通过题归属,我们可以非常清楚的看到这种涉及递归的算法复杂度。关于这个MergeSort算法,总复杂度的常数项一般可以舍弃,所以我们一般所看到他的时间复杂度T(n)=n*log n就得到了!
PS:除此之外,关于MIT课上讲到的InsertionSort,我们会发现他有两个特点:
1.T(n)=O(n^2);
2.通过和MergeSort对比,发现在数字规模较小时他会有一定优势。
听了MIT的第二节课,内容是介绍有关复杂度的几种渐进符号(如上已归纳),以及借助对递归分析介绍了三种递归复杂度法分析方法:
1.代换法
这种方法其实就是数学上的替换法,基本步骤有三步:
1.Gusse;
2.Assume;
3.Prove
第一步就是凭经验先猜测一个比较接近的复杂度,进行分析证明,但猜不猜的准就得看自己的数学功力了,当然,一般分析时最好是先用递归树求出具体复杂度(测不准还是??),再用代换法证明。
第二第三步就是所谓的”数学归纳法“,想法设法证明出自己所希望的那个复杂度。
2.”递归树"法
看来这是很多人都比较喜欢的一种方法,比较直观。(具体见MergeSort分析;另外,在随后的Master Method里,证明他的正确性也用到了递归树,虽然还不是太明白,之后具体在看《算法导论》上的具体证明吧~~~)
3.Master Method
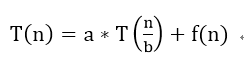
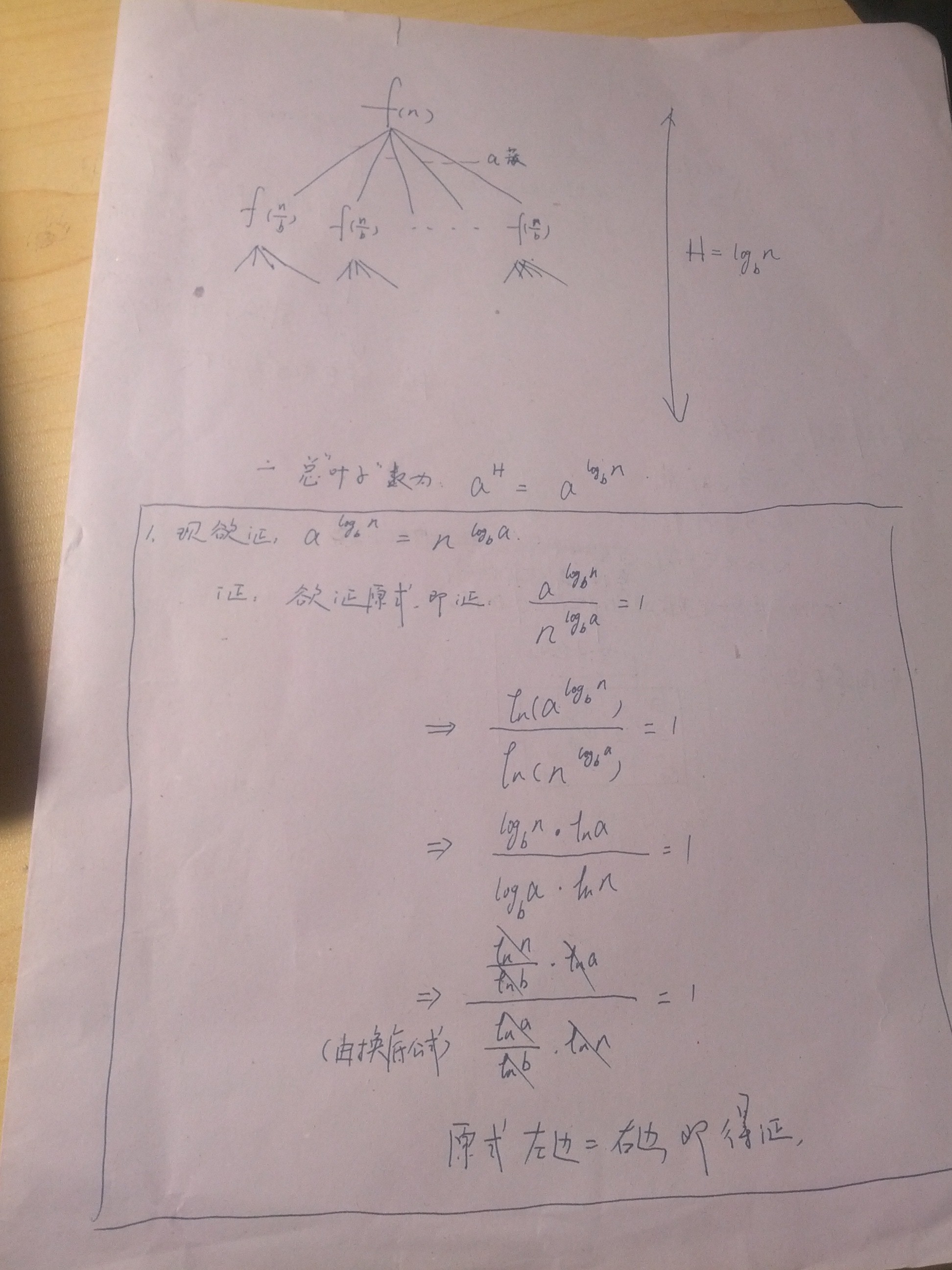
主方法证明如下:

这种方法主要就是根据上述式子中的f(n)与叶节点总数 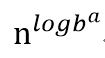
/*********************************************************我是分割线****************************************************************/
顺便证明一下:
/*************************************************************************************************************************************/















 7213
7213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









