






根据信息论可知,等方差分布中高斯分布的熵最大。而根据概率论的中心极限定理可知,若一随机变量由许多相互独立的随机变量组成,只要具有有限的均值与方差,则无论其为何种分布,随机变量较更接近高斯分布。反之,对一个混合信号来说,如果完成对信号的分离,则会使得分离后的结果之间的非高斯性变大,即信号之间可看成相互独立的。故引入负熵来度量,其公式定义为
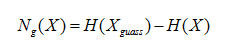
式中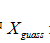

我们在看完其推导之后,往往会发现其实际编程的时候会有困难,基于此,我在这里详细讲解如何实现编程。编程的步骤一般如下:
1)对接收信号中心化与预白化
2)设置迭代次数,选择初始权
3)程序主体
4)正交化,这是避免提取出重复的源信号
5)对迭代权值归一化
6)判断是否收敛,没有的话返回3)继续,知道收敛为止。
好了,不多说,我们讲解如何编写:
我们分离正定信号,4个信源,4个传感器,2000个采样点;接收信号为X,其行列为4*2000。
%%去均值与预白化
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
上面处理过后,Z为白化之后的数据,接着我们处理白化后的数据即可
%设置收敛门限与最大的迭代次数
设置最大的迭代次数的迭代次数是防止收敛门限设置过小的时候程序达不到为陷入死循环。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
转载: http://blog.csdn.net/zf_suan/article/details/53039576 并主要修改并完善代码
另外参考:
http://blog.csdn.net/yjjat1989/article/details/22593489
https://www.cs.helsinki.fi/u/ahyvarin/whatisica.shtml
http://www.cnblogs.com/gisalameda/p/5336943.html
http://chunqiu.blog.ustc.edu.cn/?p=413
https://math.stackexchange.com/questions/695194/is-my-implementation-of-fastica-right
http://si.utia.cas.cz/CODE/FicaCPLX.html















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









