







索引命中效果不佳,采用IK分词与二元分词的效果都不是特别好,于是设计了新的自定义分词器,先将句子用IK分词分开,再对长度超过3的词进行二元分词。
以下是分词器的实现效果图。
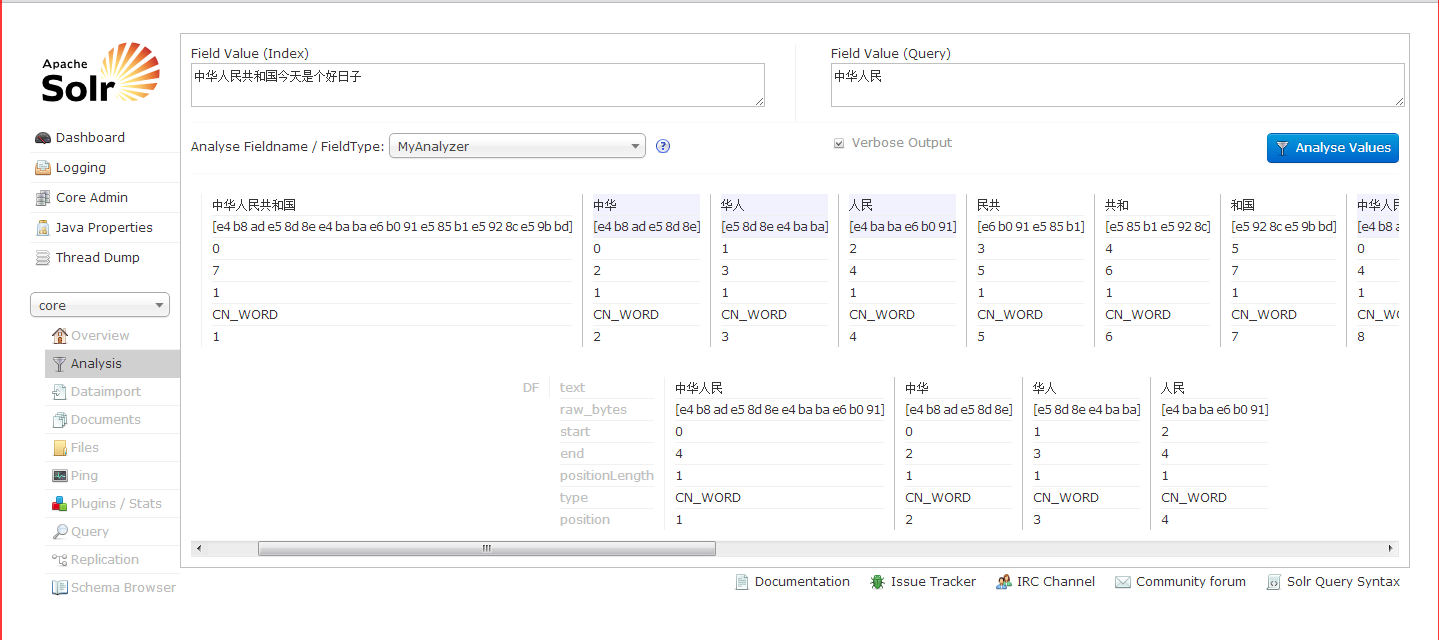
实现思路先建立IK分词器,在通过第一层filter将IK分的词截留,长度大于等于3的词置入CJK分词器进行处理,然后得到的结果送入第二层filter中进行去重。因为在上一层中会出现大量重复词.下面贴代码。
package com.huang.analyzer;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.Reader;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.analysis.cjk.CJKBigramFilter;
import org.apache.lucene.analysis.cjk.CJKTokenizer;
import org.apache.lucene.analysis.cjk.CJKWidthFilter;
import org.apache.lucene.analysis.core.LowerCaseFilter;
import org.apache.lucene.analysis.core.LowerCaseTokenizer;
import org.apache.lucene.analysis.core.UpperCaseFilter;
import org.apache.lucene.analysis.standard.StandardFilter;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.search.Filter;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
import org.wltea.analyzer.lucene.IKTokenizer;
public class MyAnalyzer extends Analyzer {
private static final String text = "今天是个好日子";
//private static final String text = "How are you";
@Override
protected TokenStreamComponents createComponents(String fieldname, Reader in) {
// TODO Auto-generated method stub
// Tokenizer token = new LowerCaseTokenizer(in);
// TokenStreamComponents components = new TokenStreamComponents(token);
// TokenStream ts = components.getTokenStream();
//Tokenizer tokenizer = new IKBinaryTokenizer(in);
//Tokenizer tokenizer = new CJKTokenizer(in);
//TokenStream filter = new UpperCaseFilter(tokenizer);
//TokenStream filter = new CJKWidthFilter(tokenizer);
//Tokenizer tokenizer = new IkCjkTokenizer(in);
Tokenizer tokenizer = new IKTokenizer(in, false);
TokenStream normsFilter = new NormsFilter(tokenizer);
TokenStream distinctFilter = new DistinctFilter(normsFilter);
TokenStreamComponents components = new TokenStreamComponents(tokenizer, distinctFilter);
return components;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
MyAnalyzer myAnalyzer = null;
myAnalyzer = new MyAnalyzer();
StringReader reader = new StringReader(text);
//开始分词
try {
TokenStream ts = myAnalyzer.tokenStream("", reader);
ts.addAttribute(CharTermAttribute.class);
ts.reset();
int i = 0;
while(ts.incrementToken()){
CharTermAttribute cta = null;
cta = ts.getAttribute(CharTermAttribute.class);
OffsetAttribute offsetAtt = ts.getAttribute(OffsetAttribute.class);
System.out.println(cta.toString() + "(" + offsetAtt.startOffset() + "-" + offsetAtt.endOffset() + ")");
}
ts.end();
ts.close();
reader.close();
System.out.println();
}
catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
package com.huang.analyzer;
import java.io.IOException;
import java.io.StringReader;
import java.nio.CharBuffer;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.analysis.cjk.CJKTokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.apache.lucene.util.AttributeSource;
public class NormsFilter extends TokenFilter{
/**中文词组长度过滤,默认超过2位长度的中文才转换拼音*/
private int minTermLength;
/**当前输入是否已输出*/
private boolean hasCurOut;
/**词元输入缓存*/
private char[] curTermBuffer;
/**词元输入长度*/
private int curTermLength;
private final CharTermAttribute termAtt = (CharTermAttribute) addAttribute(CharTermAttribute.class);
/**位置增量属性*/
private final PositionIncrementAttribute posIncrAtt = addAttribute(PositionIncrementAttribute.class);
private final TypeAttribute typeAtt = addAttribute(TypeAttribute.class);
private final OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
/**cjk分词结果集*/
private Collection<String> terms;
/**结果集迭代器*/
private Iterator<String> termIte;
/**主词在字符串中的偏移量*/
private int firstStartOffset;
/**副词在主词中的偏移量*/
private int secondStartOffset;
private boolean norms;
protected NormsFilter(TokenStream input) {
super(input);
}
@Override
public boolean incrementToken() throws IOException {
// TODO Auto-generated method stub
//开始处理或上一词元已经处理完成
while (true) {
if (this.curTermBuffer == null) {
//获取下一词元输入
if (!this.input.incrementToken()) {
// 没有后继词元输入,处理完成,返回false,结束上层调用
return false;
}
this.curTermBuffer = ((char[]) this.termAtt.buffer().clone());
this.curTermLength = this.termAtt.length();
}
//处理原输入词元
if (!hasCurOut && (this.termIte == null)) {
// 标记以保证下次循环不会输出
this.hasCurOut = true;
// 写入原输入词元
this.termAtt.copyBuffer(this.curTermBuffer, 0, this.curTermLength);
this.posIncrAtt.setPositionIncrement(this.posIncrAtt.getPositionIncrement());
this.typeAtt.setType("CN_WORD");
if (curTermLength <= 2) {
this.curTermBuffer = null;
this.hasCurOut = false;
}
return true;
}
String text = this.termAtt.toString();
//norms为true表示在第二层中
if (norms == false) {
if (text.length() >= 3) {
//主词相对句子的偏移量
this.firstStartOffset = offsetAtt.startOffset();
//开始第二层
norms = true;
//用容器来装cjk分好的二元分词
Collection<String> coll = new ArrayList<String>();
/**开始cjk分词*/
StringReader reader = new StringReader(text);
Tokenizer cjk = new CJKTokenizer(reader);
cjk.reset();
while (cjk.incrementToken()) {
coll.add(cjk.getAttribute(CharTermAttribute.class).toString());
}
cjk.end();
cjk.close();
this.terms = coll;
if (this.terms != null) {
this.termIte = this.terms.iterator();
}
}else {
this.termAtt.copyBuffer(curTermBuffer, 0, curTermLength);
this.posIncrAtt.setPositionIncrement(this.posIncrAtt.getPositionIncrement());
this.typeAtt.setType("CN_WORD");
this.curTermBuffer = null;
return true;
}
}
if (norms == true) {
// 有拼音结果集且未处理完成
while (this.termIte.hasNext()) {
String pinyin = this.termIte.next();
this.termAtt.copyBuffer(pinyin.toCharArray(), 0, pinyin.length());
this.posIncrAtt.setPositionIncrement(this.posIncrAtt.getPositionIncrement());
this.typeAtt.setType("CN_WORD");
this.offsetAtt.setOffset(this.firstStartOffset, this.firstStartOffset + pinyin.length());
this.firstStartOffset++;
if (!this.termIte.hasNext()) {
// 没有中文或转换拼音失败,不用处理,
// 清理缓存,下次取新词元
this.curTermBuffer = null;
this.termIte = null;
this.hasCurOut = false;
this.firstStartOffset = 0;
norms = false;
}
return true;
}
}
}
}
}package com.huang.analyzer;
import java.io.IOException;
import java.util.Collection;
import java.util.LinkedList;
import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
public class DistinctFilter extends TokenFilter{
private Collection<String> terms;
/**词元输入缓存*/
private char[] curTermBuffer;
/**词元输入长度*/
private int curTermLength;
/**词元文字属性*/
private final CharTermAttribute termAtt = (CharTermAttribute) addAttribute(CharTermAttribute.class);
/**位置增量属性*/
private final PositionIncrementAttribute posIncrAtt = addAttribute(PositionIncrementAttribute.class);
/**词元类型属性*/
private final TypeAttribute typeAtt = addAttribute(TypeAttribute.class);
protected DistinctFilter(TokenStream input) {
super(input);
// TODO Auto-generated constructor stub
this.terms = new LinkedList<String>();
}
@Override
public boolean incrementToken() throws IOException {
// TODO Auto-generated method stub
while (true) {
if (this.curTermBuffer == null) {
//获取下一词元输入
if (!this.input.incrementToken()) {
// 没有后继词元输入,处理完成,返回false,结束上层调用
return false;
}
this.curTermBuffer = ((char[]) this.termAtt.buffer().clone());
this.curTermLength = this.termAtt.length();
}
String text = this.termAtt.toString();
if (terms.contains(text)) {
//this.curTermBuffer = "重复".toCharArray();
this.curTermBuffer = null;
continue;
}else {
terms.add(text);
}
/***/
this.termAtt.copyBuffer(this.curTermBuffer, 0, this.curTermLength);
this.posIncrAtt.setPositionIncrement(this.posIncrAtt.getPositionIncrement());
this.typeAtt.setType("CN_WORD");
/***/
this.curTermBuffer = null;
return true;
}
}
@Override
public void reset() throws IOException {
// TODO Auto-generated method stub
super.reset();
this.curTermBuffer = null;
terms.clear();
}
}















 1114
1114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









