







业务背景
因为公司业务,需要进行国内-海外部分业务数据的同步,早期本来方案选定直接做MySQL主从,但是考虑到同步过程中不需要同步所有数据库表,且单表中也需要根据业务情况,筛选出海外的数据,因此MYSQL直接做主从复制不符合预期。最终选型了kettle。Kettle是Pentaho的一个组件,主要用于数据库间的数据迁移,我们使用的是6.1版本,目前网上对该版本的介绍还比较少,所以很多功能还是靠自己摸索使用。
功能介绍
在kettle中,需要使用到transformation和job,transformation支持使用各种组件用于完成ETL过程(Extraction-Transformation-Loading)。转换包括主对象树和核心对象树,主对象树用于配置转换参数,包括数据库连接等,而核心对象树则是用于完成具体操作。
主对象树包括
- DB连接:显示当前transformation中的数据库连接,每一个–transformation的数据库连接都需要单独配置;
- Steps:一个transformation中应用到的环节列表;
- Hops:一个transformation中应用到的节点连接列表。
核心对象树则包括
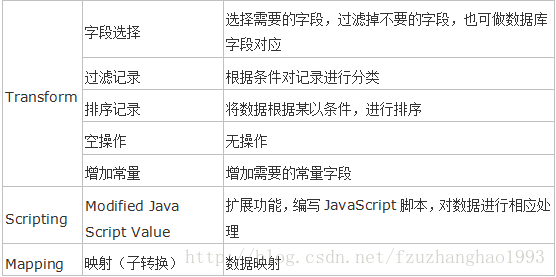
- Input:输入环节
- Output:输出环节
- Lookup:查询环节
- Transform:转化环节
- Joins:连接环节
- Scripting:脚本环节
在核心对象中,我们利用输入、输出来实现数据的传输,主要涉及到的操作有:

场景分析
要设计转换首先要明确具体的使用场景,我公司同步的核心业务就是将国内每日变动的敏感数据(卡片数据)同步到国外,同时将国外的数据变动同步回国内,而这个变动仅仅只涉及到修改,新增的变动逻辑由国内数据库来完成。
这里我们仅分析卡片数据来作为例子。首先卡片具有密码这一属性,国内工厂,国外工厂都会定期对其进行修改,修改操作同时会影响到卡片密码变更时间以及卡片状态等信息,明确了这一点设计同步逻辑便得心应手了。
同步逻辑设计
kettle对事务的控制比较差,因此数据的同步需要事先进行设计,与其他表关联程度低的数据优先进行同步,存在外键依赖关系的,则优先同步被参照表,从而避免脏数据的产生。
在kettle的每一个转换中,都存在步骤的概念,步骤也决定了数据的流向。数据就像在管道中的流一样,从一个步骤流向另一个步骤。而对于转换的划分,建议将数据库中关联度比较高的业务归在同一转换下,一方面便于管理控制,另一方面有利于数据流的高效利用。
在同步过程中,首先第一步需要读出源表的相关数据,这是输入步骤,利用核心对象中的表输入来完成,可以通过自定义SQL来决定所需要的源数据,然后,确定输出的对象,也就是目标连接,目标库,目标表,以及目标操作;目标操作有多种,包括删除、插入/更新、数据同步等。插入/更新是将流中的数据按照规则与目标表数据比对,如果目标表存在该数据,则更新配置的字段,否则进行插入操作;而数据同步操作主要是将目标表数据完全清空,再将流里的数据全部插入。
源表读出来的数据可以流向多个输出步骤,因此可以执行如下操作,在A表中读出数据后,分别插入B,C,D表,而不需要每插入一张表就查询一次。
信息配置
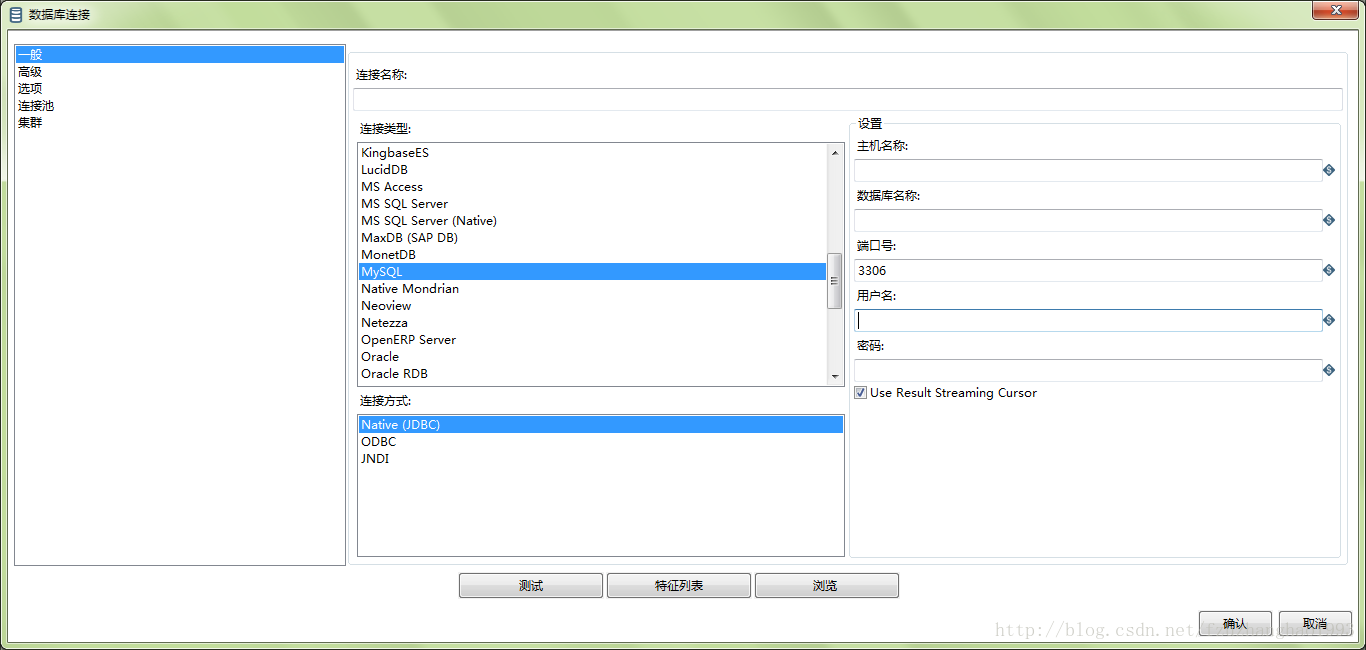
首先需要新建一个transformation,即转换。然后配置相应的库连接信息,确定源库、目标库。通过配置主对象树下的DB连接,分别建立源库、目标库相关数据,并且可以进行连接测试以检测连接的有效性。
数据流转
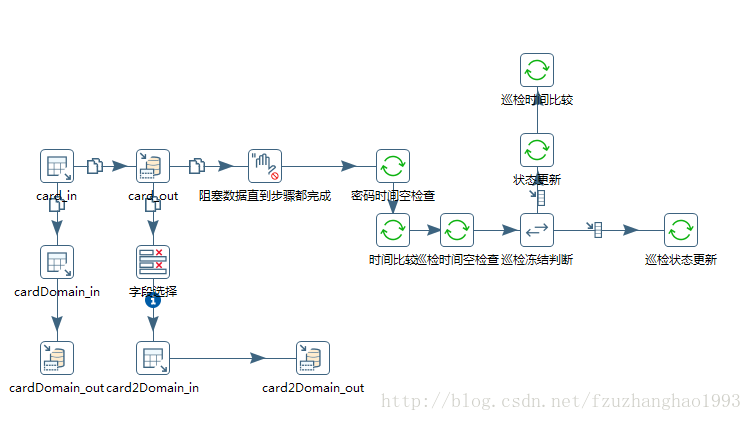
根据业务逻辑,我们设计我们需要的数据流程过程,以刚才卡片数据为例,我们首先需要从国内库中读取卡片数据,这里使用到了“表输入”。
通过输入流获取到了数据,这时候可以根据自己业务对其进行处理,在本例中,我使用到了字段筛选,分支,数据阻塞。
- 字段筛选:本例中将卡片字段ID提取出来作为下一个输入流的筛选过滤条件,具体使用只需要新增“转换-字段选择”即可。而下一个输入流在设置SQL语句时,将需要嵌入的条件设置为?,并勾选“替换SQL语句里的变量”即可从上一步骤获取条件值。
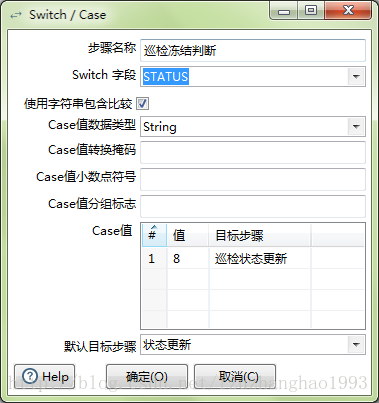
- 分支:分支顾名思义,就是一个switch/case,新增“流程-switch/case”,然后设置用于判断的字段,并给出不同条件的下一步骤即可。
- 数据阻塞:执行到这一步会阻塞所有步骤,直到这一步完成。
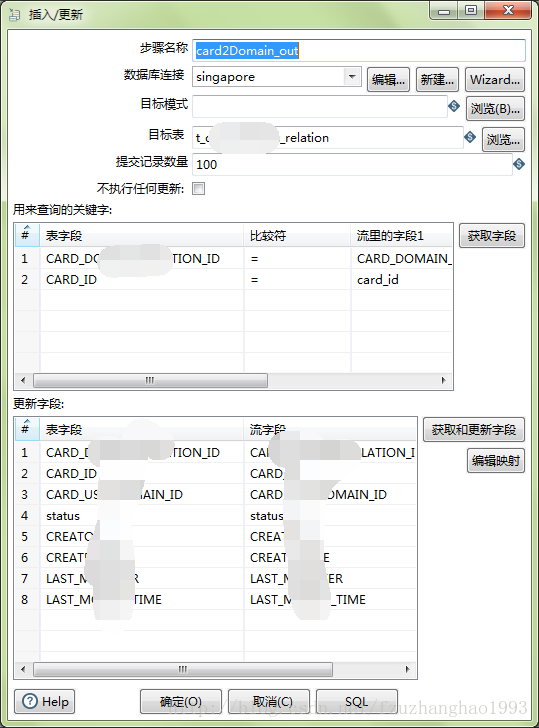
最后数据需要进行插入/更新来同步到国外数据库中,我们新建“输出-插入/更新”,然后配置流入的数据值,流出的字段值,以及条件即可。在“输出”这一操作树中有“插入/更新”和“更新”两个操作,二者区别在于“插入/更新”会根据设置w的比较条件进行判断,如果比较条件成立,则进行更新,否则进行插入。
最终转换流程预览:
执行调度
利用kettle的job来进行转换的调度,job可以用于定制各个转换执行的顺序,控制执行流程,利用job的时间控制,来决定其执行的规则。
我们通过文件-新建-作业(job)即可设置我们自己的调度,调度可以设置执行一次,也可以设置循环执行。如果直接使用kettle job的start进行计划执行,则需要kettle客户端一直保持运行,如果遇到服务器意外重启就比较麻烦,这时候我们可以把他配置为windows bat,然后利用windows计划任务调度执行。这里给个demo参考一下:
@echo off
set KETTLE_PATH=D:\pdi-ce-6.1.0.1-196\data-integration
set JOB_PATH=D:\pdi-ld\pdi-ce-6.1.0.1-196\data-integration\works\国内到国外
rem 默认T+1方式参数传递
CALL %KETTLE_PATH%\Kitchen.bat -file=%JOB_PATH%\intoout.kjb >>%JOB_PATH%\log\syn_%date:~0,4%%date:~5,2%%date:~8,2%.log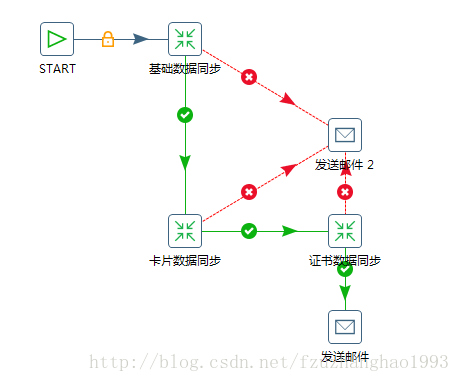
邮件简介
在调度和转换执行过程中,我们需要知道具体的执行结果,最好是能有一个通知,这时候我们就用到了邮件功能。
我们可以通过选择job核心组件树中的“发送邮件”来实现邮件发送功能。几个主要字段一定要进行配置,否则发送失败。
1)、地址栏
收件人地址:填写收件地址,多个收件地址,可以使用空格隔开
发件人地址:填写发件地址
回复名称:发件人名,建议填写
2)、服务器栏
SMTP服务器
端口号
3)、邮件消息
主题、注释建议填写















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









